Untuk mengetahui apa itu cache, apa itu Hasil Cache, bagaimana itu dibuat di Oracle dan di database lain tidak terlalu menarik dan cukup sederhana. Tapi semuanya mengambil warna yang sangat berbeda ketika datang ke contoh spesifik.
Alexander Tokarev (
shtock ) membuat laporannya di Highload ++ 2017 berdasarkan kasus. Dan justru atas dasar kasus-kasus itu dia mengatakan kapan cache buatan mungkin nyaman, apa rasa sakit dari Cache Hasil sisi server dan bagaimana menggantinya dengan yang sisi klien, dan secara umum dia membawa sejumlah tips yang berguna untuk mengatur Hasil Cache di Oracle.
Tentang pembicara: Alexander Tokarev bekerja di DataArt dan menangani masalah yang terkait dengan database, baik dalam hal membangun sistem dari awal dan mengoptimalkan yang sudah ada.
Mari kita mulai dengan beberapa pertanyaan retoris. Sudahkah Anda bekerja dengan Oracle Result Cache? Apakah Anda percaya bahwa Oracle adalah basis data yang cocok untuk semua kesempatan? Menurut pengalaman Alexander, kebanyakan orang menjawab pertanyaan terakhir dalam negatif,
seratus pemimpi memiliki satu pemimpi . Namun berkat keyakinannya, kemajuan terus bergerak.
Omong-omong, Oracle sudah memiliki 14 basis data - sejauh ini 14 - apa yang akan terjadi di masa depan tidak diketahui.
Seperti yang telah disebutkan, semua masalah dan solusi akan diilustrasikan dengan kasus-kasus spesifik. Ini akan menjadi dua kasus dari proyek DataArt, dan satu contoh pihak ketiga.
Tembolok basis data
Untuk memulainya, cache mana yang ada di database. Semuanya jelas di sini:
- Cache penyangga - cache data - cache untuk halaman data / blok data;
- Cache pernyataan - cache pernyataan dan rencananya - cache rencana kueri;
- Cache hasil - cache hasil baris - baris dari kueri;
- OS cache - cache sistem operasi.
Selain itu, cache Hasil, pada umumnya, hanya digunakan di Oracle. Dia pernah di MySQL, tapi kemudian dia dengan heroik dipotong. Dalam PostgreSQL juga tidak ada, ia hadir dalam satu bentuk atau lainnya hanya dalam produk pgpool pihak ketiga.
Kasus 1. Gudang Pengecer
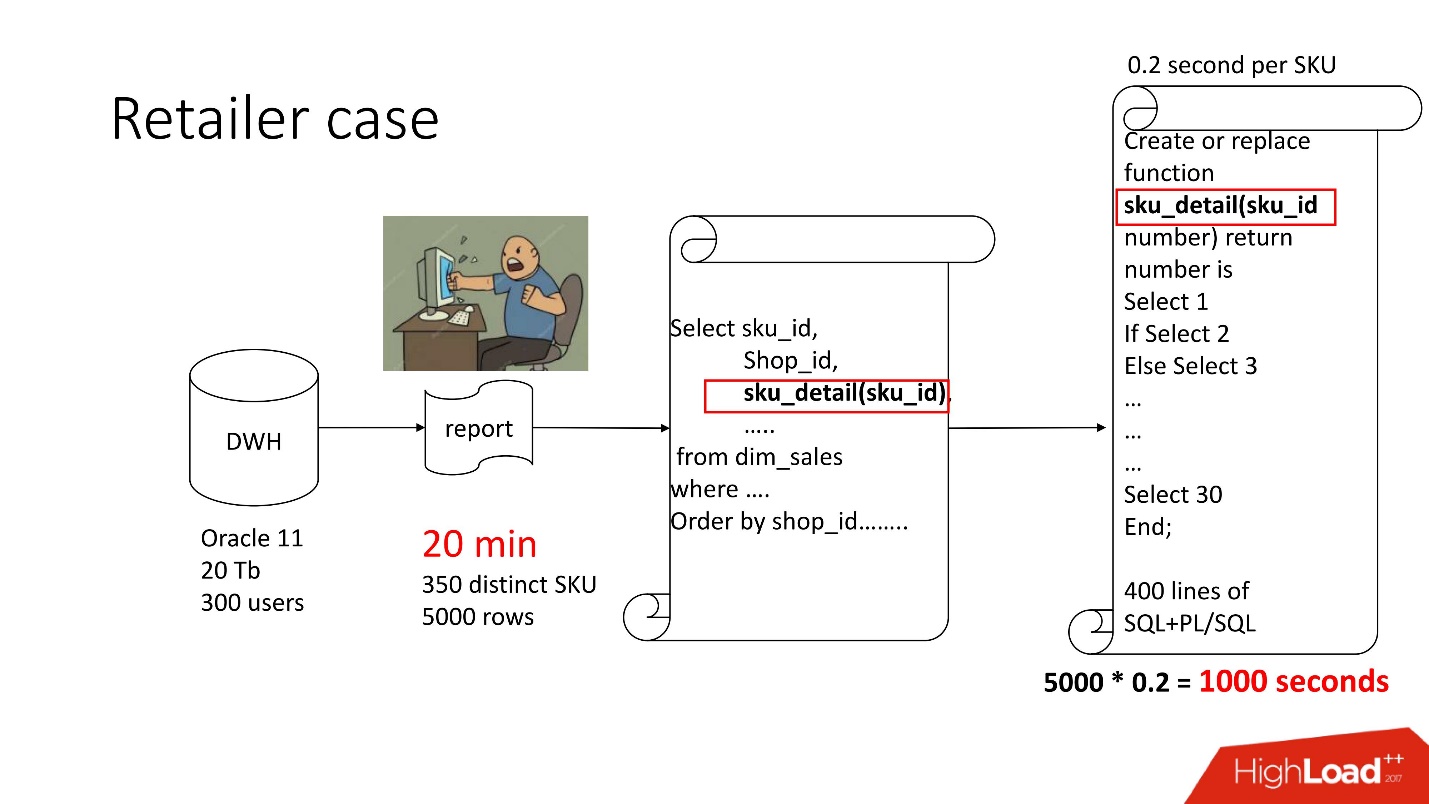
Di atas adalah diagram produk yang kami sertai - repositori (pengguna Oracle 11, 20 Tb, 300), dan berisi beberapa jenis laporan suram, di mana terdapat 350 produk unik per 5.000 jalur data. Diperlukan waktu sekitar 20 menit, dan para pengguna merasa sedih.
Presentasi laporan ini, seperti orang lain, tersedia di situs konferensi Highload ++.
Laporan ini memiliki SELECT, JOINs, dan sebuah fungsi. Suatu fungsi sebagai fungsi, semuanya akan baik-baik saja, hanya saja ia menghitung parameter misterius yang disebut "nilai harga transfer", ia bekerja selama 0,2 detik - sepertinya tidak ada apa-apa, tetapi ia dipanggil berkali-kali karena ada baris dalam tabel. Fungsi ini memiliki 400 baris SQL + PL / SQL, sejak produk ini dalam dukungan, itu menakutkan untuk mengubahnya.
Untuk alasan yang sama, result_cache tidak dapat digunakan.
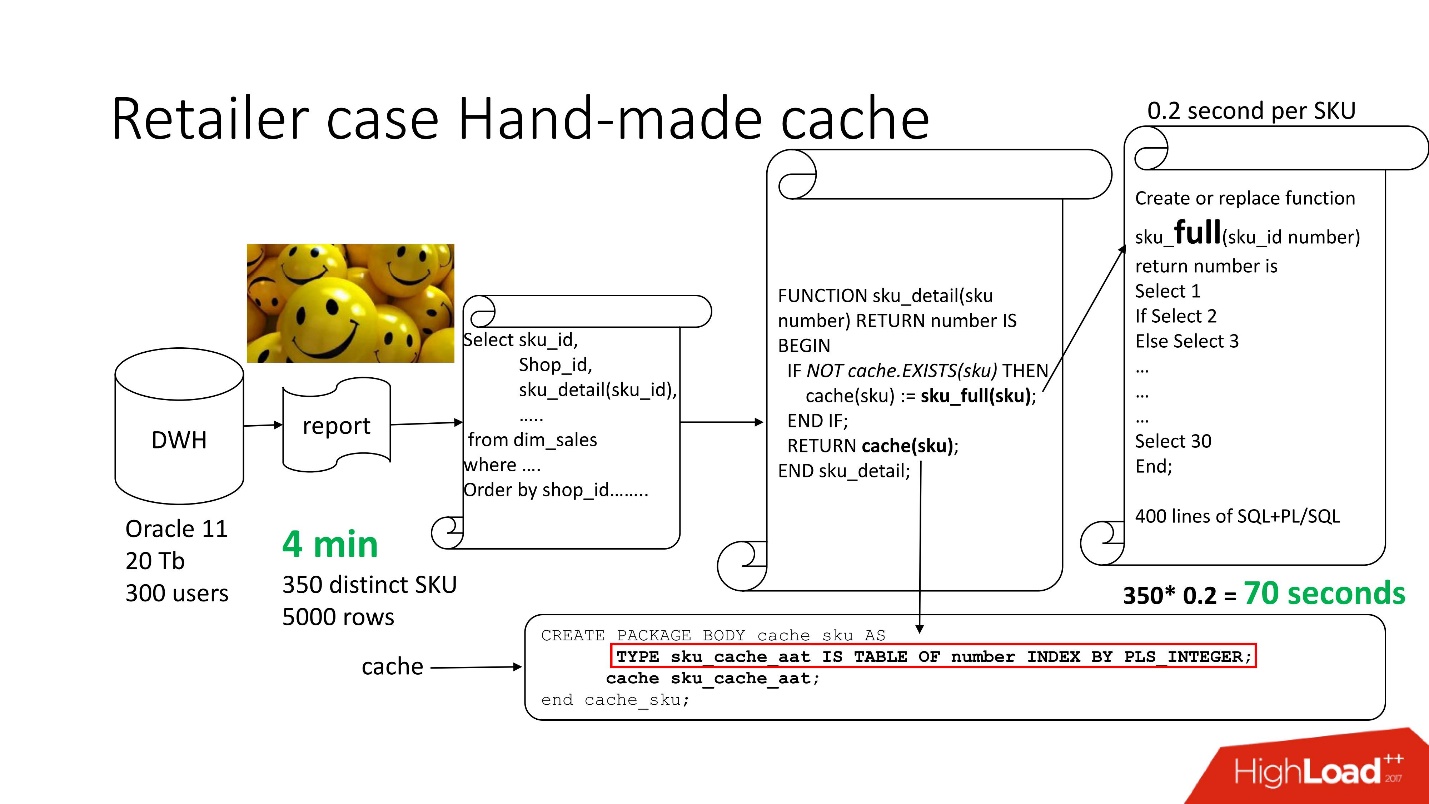
Untuk mengatasi masalah tersebut, kami menggunakan
pendekatan standar
dengan caching buatan tangan : kami membiarkan 3 blok pertama dari rangkaian, seperti sebelumnya, cukup ganti nama fungsi sku_detail () menjadi sku_full () dan deklarasikan array asosiatif, di mana masing-masing:
- kuncinya adalah SKU kami (barang komoditas),
- Nilai adalah harga konversi transfer yang dihitung.
Kami membuat fungsi cache (sku) menjadi jelas: jika tidak ada id seperti itu di array asosiatif kami, fungsi kami diluncurkan, hasilnya di-cache, disimpan, dan dikembalikan. Dengan demikian, jika id seperti itu, maka semua ini tidak terjadi. Bahkan, kami mendapat
permintaan cache .
Dengan demikian, kami telah mengurangi jumlah pemanggilan fungsi ke jumlah yang sebenarnya dibutuhkan.
Waktu pemrosesan laporan menurun menjadi 4 menit , semua pengguna merasa senang.
Memori Cache Buatan Tangan
Kerugian dan keuntungan dari sistem ini jelas dari gambar pintar yang besar ini, yang akan kita bahas banyak - ini adalah arsitektur memori.
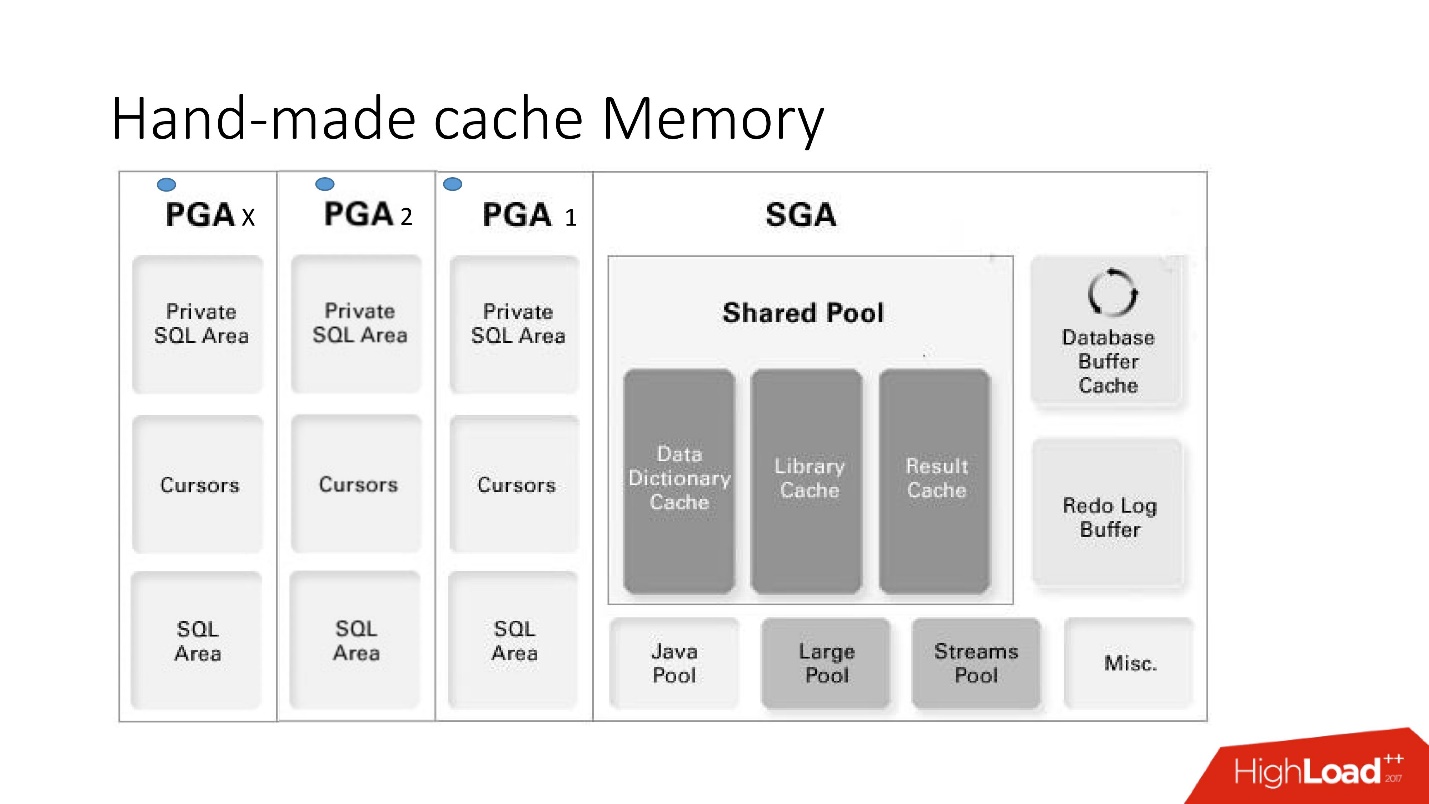
Penting untuk memahami di mana area memori koleksi berada. Mereka ditempatkan di area memori yang disebut PGA.
Program area global dipakai pada setiap koneksi ke database. Inilah yang menentukan kelebihan dan kekurangan, karena lebih banyak koneksi - lebih banyak memori, dan
memori mahal, server , admin lunak.

- Pro: semuanya bekerja sangat cepat, sangat mudah dilakukan, tidak ada konfigurasi yang diperlukan, tidak ada masalah dengan keterlibatan antarproses.
- Kontra dapat dimengerti: jika logika yang disimpan dilarang dalam proyek, mereka tidak dapat digunakan, tidak ada mekanisme untuk pembatalan otomatis, dan karena memori pada cache dialokasikan dalam satu sesi basis data, bukan sebuah instance, konsumsinya terlalu dilebih-lebihkan . Selain itu, dalam kasus penggunaan kasus koneksi pool, Anda harus ingat untuk menyiram cache jika harus ada caching yang berbeda untuk setiap sesi.
Ada opsi lain untuk cache buatan tangan berdasarkan pandangan material, tabel sementara, tetapi dari mereka ada beban besar pada sistem input-output, jadi di sini kita tidak mempertimbangkannya. Mereka lebih berlaku untuk database lain di mana masalah seperti itu biasanya diselesaikan dengan menyimpan prosedur tersimpan di beberapa tabel perantara dan mengambil data dari itu sebelum mengakses permintaan yang berat. Dan hanya jika tidak ditemukan apa yang dibutuhkan, maka permintaan awal dipanggil.

Di atas adalah ilustrasi dari pendekatan ini untuk masalah caching untuk mendapatkan daftar produk terkait di MsSQL. Secara umum, pendekatannya relatif sama, tetapi tidak bekerja dalam memori database baik dalam hal memperoleh data dan pengisian primer, karena ini
bisa lebih lambat .
Secara umum, result_cache buatan sendiri digunakan secara aktif, tetapi in-database result_cache adalah pendekatan yang berbeda untuk pelaksanaan tugas ini. Itu dan bagaimana itu tidak berhasil, kita akan mempertimbangkan lebih lanjut.
Kasus 2. Pemrosesan dokumentasi keuangan
Jadi, kasus kedua kami.
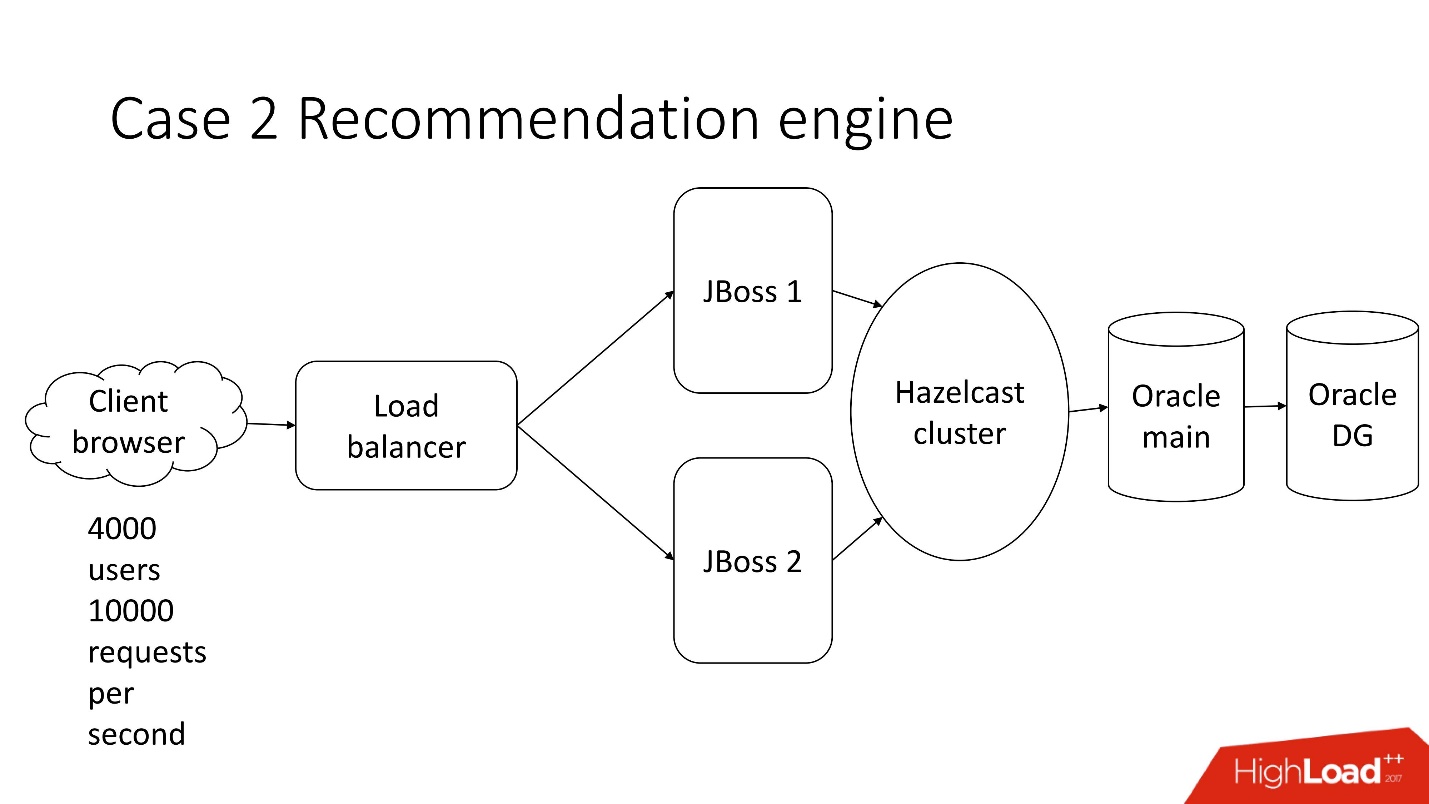
Ini adalah sistem pemrosesan dokumentasi keuangan semi-otomatis - perusahaan suram dengan arsitektur klasik, yang meliputi:
- klien kurus;
- 4.000 pengguna yang tinggal di berbagai belahan dunia;
- penyeimbang;
- 2 JBoss untuk menghitung logika bisnis;
- in-memory cluster;
- inti Oracle;
- Cadangan Oracle
Salah satu dari banyak tugas sistem ini adalah
perhitungan rekomendasi .

Ada beberapa dokumen, untuk setiap indikator yang tidak secara otomatis dikenali oleh sistem, serangkaian indikator ditawarkan baik dari dokumen klien sebelumnya, atau dari industri serupa, atau oleh profitabilitas yang serupa, sementara indikator tersebut dibandingkan dengan nilai yang diakui sehingga tidak menawarkan terlalu banyak. Yang penting,
dokumen-dokumen itu multibahasa .
Pengguna memilih nilai yang diinginkan dan mengulangi operasi untuk setiap baris kosong.
Sederhana, tugas ini terdiri dari yang berikut: dokumen tiba dalam bentuk pasangan kunci-nilai dari sistem pengenalan yang berbeda, dan parameter dikenali di suatu tempat, tetapi tidak di suatu tempat. Penting untuk memastikan bahwa pada akhirnya pengguna memproses dokumen dan semua nilai diakui. Rekomendasi tersebut tepat ditujukan untuk menyederhanakan tugas ini dan mempertimbangkan:
- Multilingualisme - sekitar 30 bahasa. Setiap bahasa memiliki stemming, sinonim dan fitur lainnya sendiri.
- Data sebelumnya dari klien ini, atau, jika tidak ada, data klien dari industri yang sama atau klien yang serupa dalam laba.
Sebenarnya, ini adalah sekitar 12 aturan yang sangat kompleks.
Asumsi awal:- Tidak lebih dari 100 pengguna sekaligus;
- 2-3 kolom untuk pengakuan;
- 100 baris.
Tidak ada beban sama sekali - semuanya membosankan.
Jadi, saatnya untuk rilis. Terjadi pembekuan kode, Java takut disentuh, dan dibutuhkan setidaknya 5 menit untuk memproses dokumen.
Mereka datang ke tim pengembangan basis data untuk meminta bantuan. Tentu saja, karena
jika sesuatu melambat di JVM, maka dengan sendirinya, Anda perlu mengubah atau memperbaiki database .

Kami mempelajari dokumen-dokumen dan menyadari bahwa dalam pasangan kunci-nilai, nilai sering diulang - 5-10 kali. Oleh karena itu, kami memutuskan untuk menggunakan basis data untuk menyimpan cache, karena sudah diuji.
Kami memutuskan untuk menggunakan Cache Hasil sisi server Oracle, karena:
- peluang untuk mengoptimalkan SQL telah habis, karena menggunakan mesin pencari teks lengkap Oracle;
- cache akan digunakan untuk parameter duplikat;
- sebagian besar data untuk rekomendasi dihitung ulang sekali per jam, karena mereka menggunakan indeks teks lengkap;
- PL / SQL dilarang .
Cache Hasil Oracle
Cache hasil - caching hasil Oracle - memiliki properti berikut:
- Ini adalah area memori tempat semua hasil pencarian digeledah;
- membaca konsisten, dan pembatalan otomatis terjadi;
- diperlukan perubahan minimal pada aplikasi. Anda dapat membuat aplikasi tidak perlu diubah sama sekali;
- bonus - Anda dapat men-cache logika PL / SQL, tetapi dilarang di sini.
Bagaimana cara mengaktifkannya?Metode nomor 1
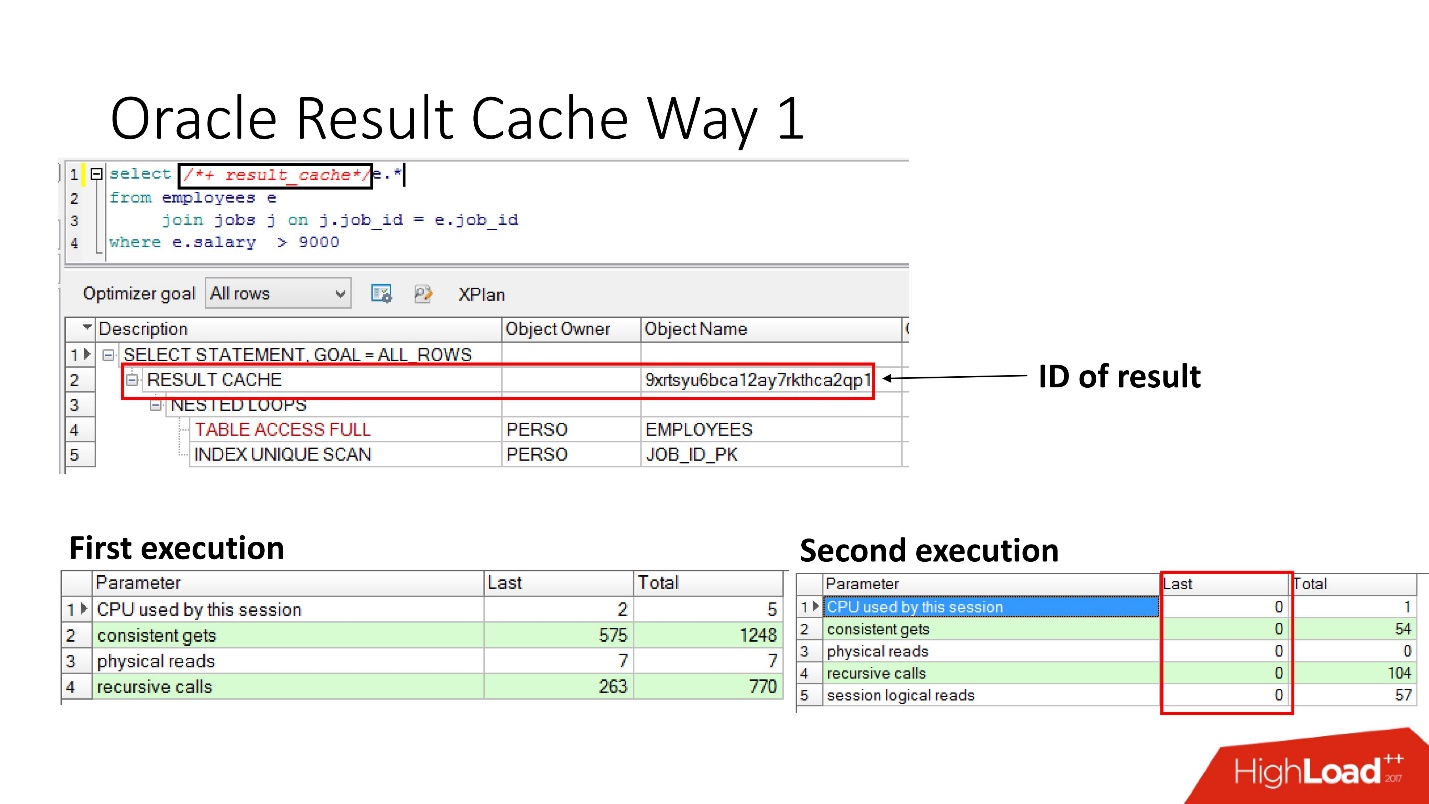
Sangat sederhana untuk
menentukan pernyataan result_cache . Slide menunjukkan bahwa pengidentifikasi hasil telah muncul. Dengan demikian, pertama kali kueri dieksekusi, database akan melakukan beberapa pekerjaan, selama eksekusi berikutnya, dalam hal ini tidak ada pekerjaan yang diperlukan. Semuanya baik-baik saja.
Metode nomor 2
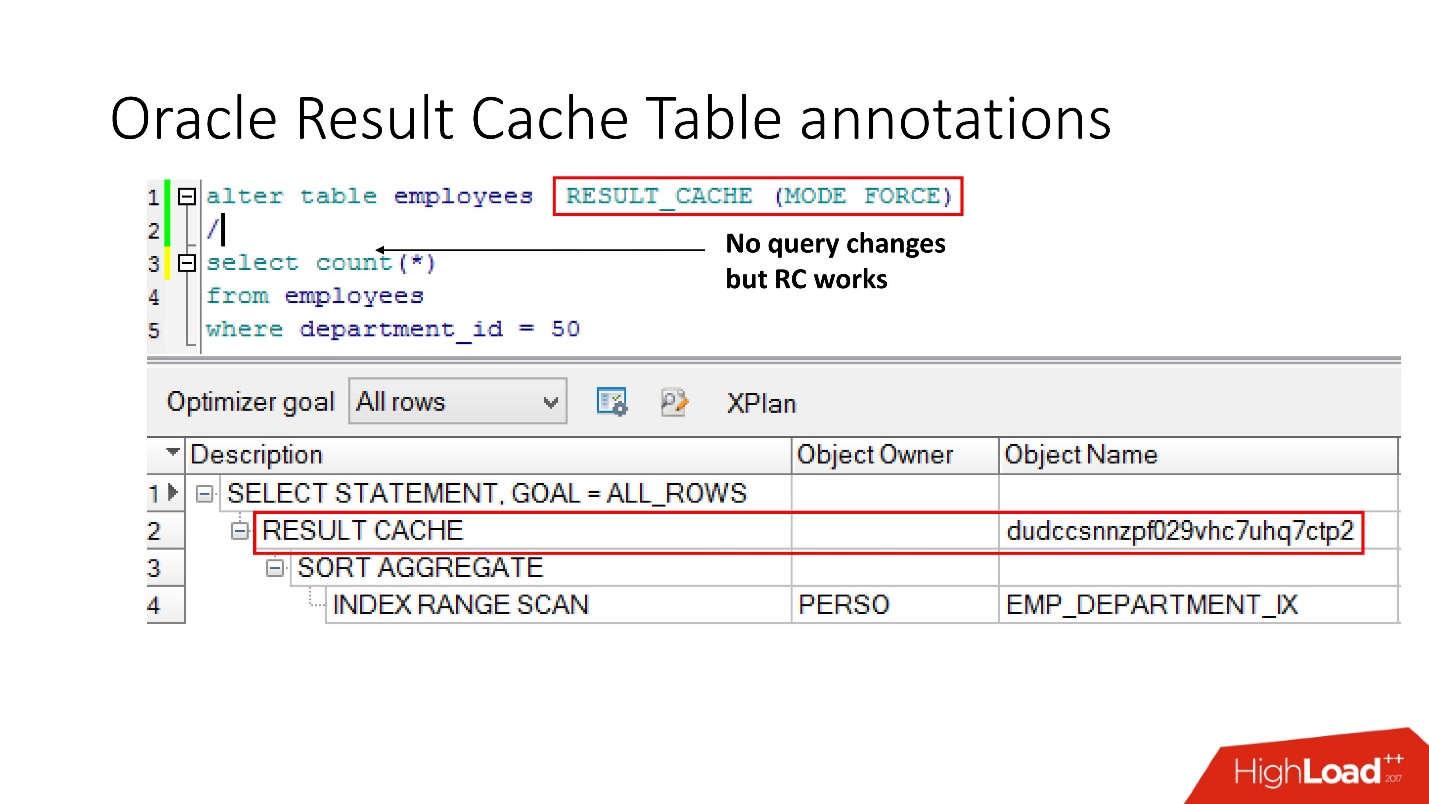
Cara kedua memungkinkan pengembang aplikasi untuk tidak melakukan apa pun - ini adalah apa yang disebut anotasi. Kami menunjukkan tanda centang untuk tabel yang permintaannya harus ditempatkan di result_cache. Dengan demikian, tidak ada petunjuk, kami tidak menyentuh aplikasi, dan semuanya sudah ada di result_cache.
Omong-omong, bagaimana menurut Anda, jika kueri merujuk ke dua tabel, yang satu ditandai sebagai result_cache, dan yang kedua tidak, apakah hasil kueri tersebut di-cache?
Jawabannya adalah tidak, tidak sama sekali.
Agar bisa di-cache, semua tabel yang berpartisipasi dalam kueri harus memiliki anotasi result_cache.
Pelacakan ketergantungan
Ada pandangan yang relevan di mana Anda bisa melihat apa dependensi itu.
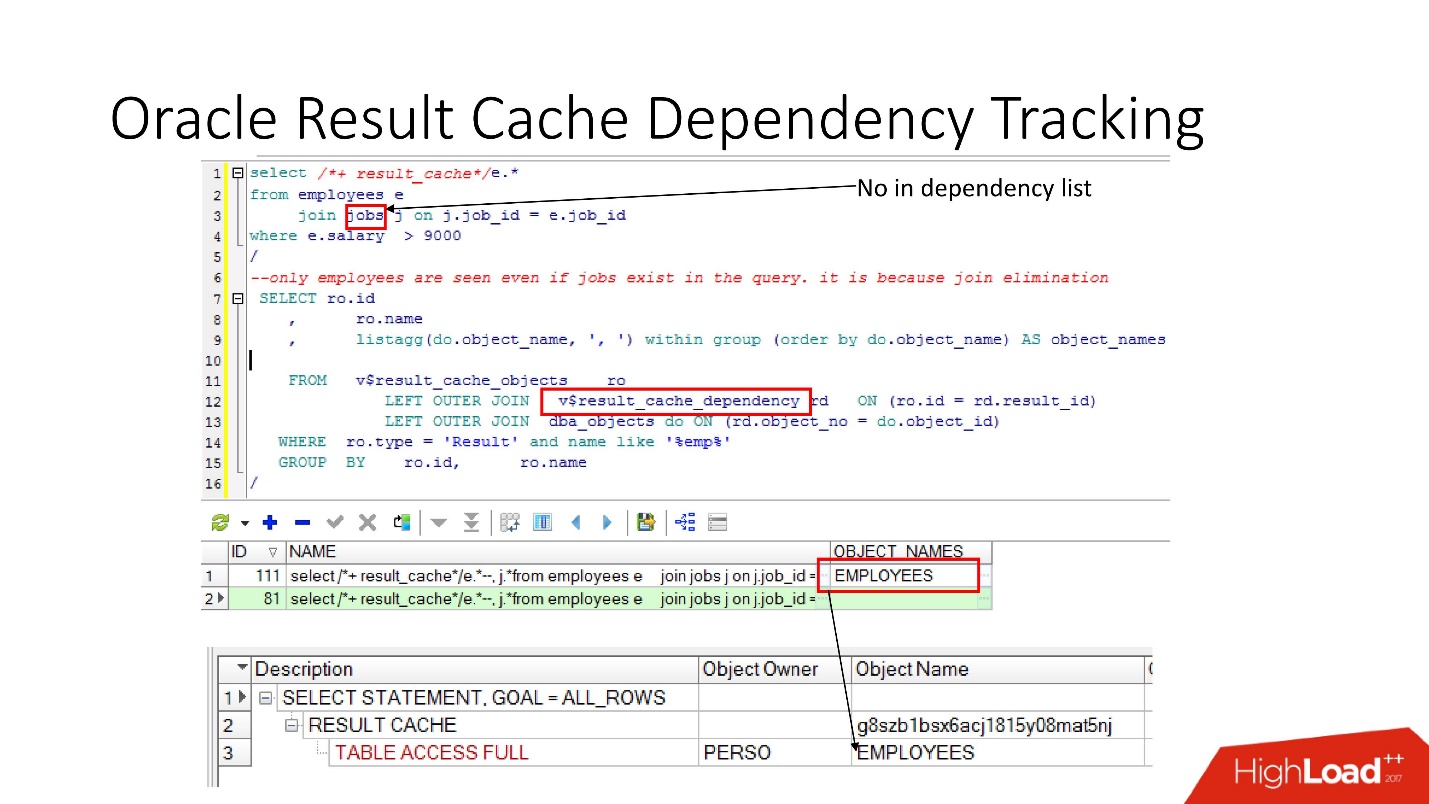
Dalam contoh di atas, permintaan GABUNG adalah beberapa tabel di mana ada satu ketergantungan. Mengapa Karena Oracle menentukan ketergantungan tidak hanya dengan parsing, tetapi mengimplementasikannya
sesuai dengan hasil rencana kerja .
Dalam kasus ini, rencana seperti itu dipilih karena hanya satu tabel yang digunakan, dan pada kenyataannya tabel pekerjaan terkait dengan tabel karyawan melalui batasan kunci asing. Jika kita menghapus batasan kunci asing yang memungkinkan transformasi eliminasi gabungan ini, maka kita akan melihat dua dependensi, karena rencana akan berubah dengan cara ini.
Oracle tidak melacak apa yang tidak perlu dilacak .
Dalam PL / SQL, dependensi berjalan pada saat run-time sehingga Anda dapat menggunakan SQL dinamis dan melakukan hal-hal lain.
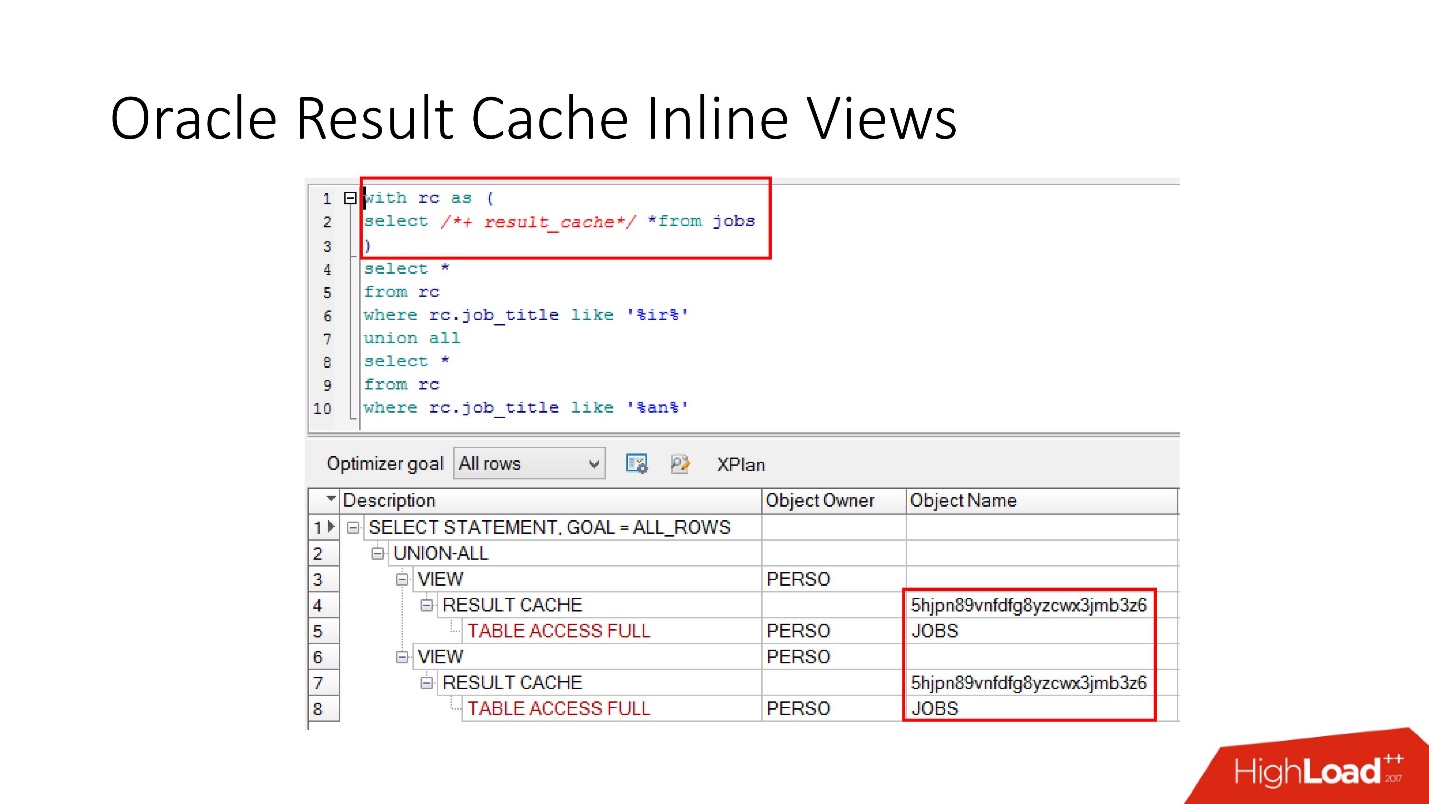
Harap perhatikan bahwa Anda dapat men-cache tidak hanya seluruh permintaan, tetapi
Anda juga dapat men-cache tampilan inline dengan dan dari . Misalkan untuk satu hal kita perlu cache, dan yang lain akan lebih baik untuk membaca dari database agar tidak memaksanya. Kami mengambil tampilan inline, sekali lagi mendeklarasikannya sebagai result_cache dan melihat bahwa hanya satu bagian yang di-cache, dan untuk yang kedua kami mengakses database setiap kali.
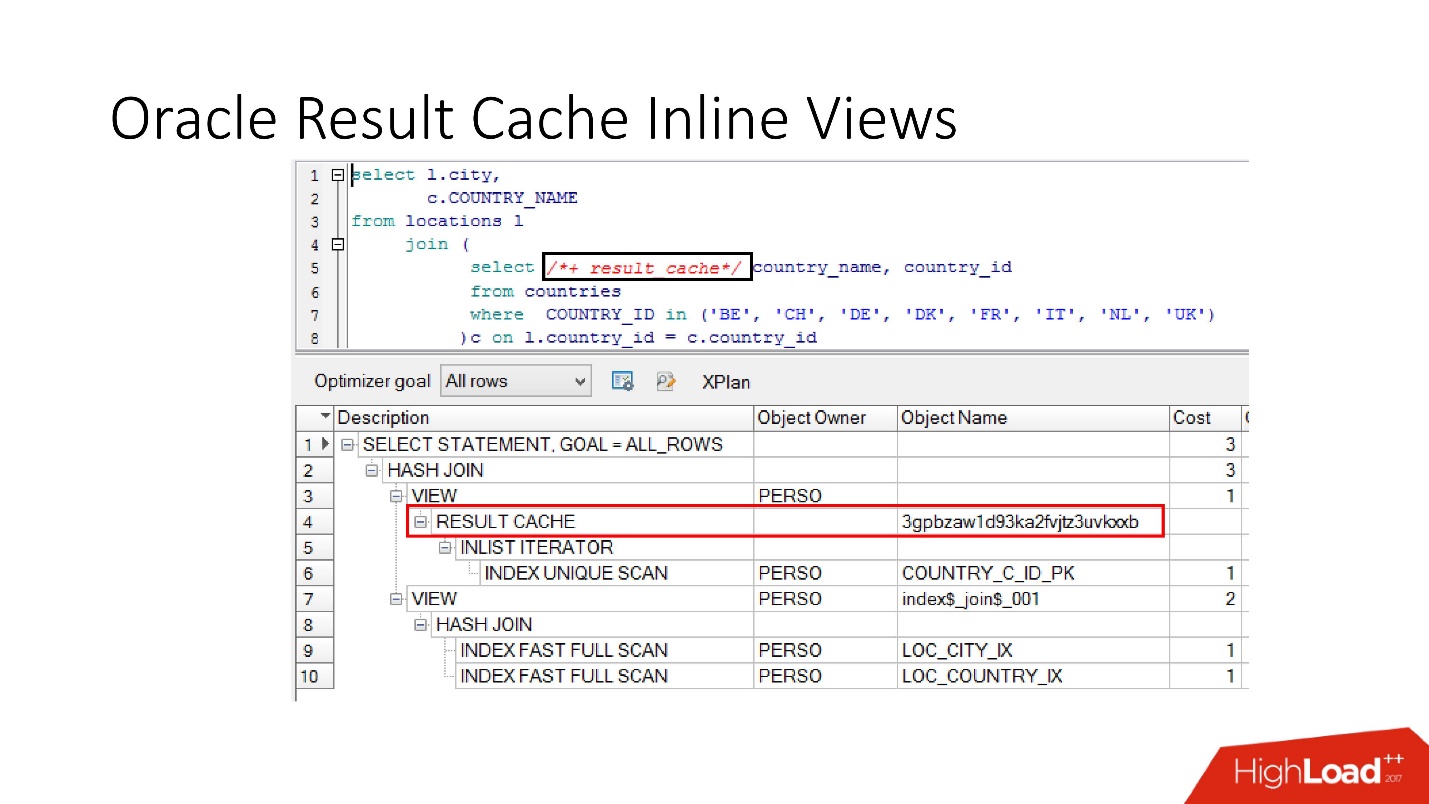
Dan akhirnya,
database juga memiliki enkapsulasi , meskipun tidak ada yang percaya. Kami mengambil pandangan, memasukkan result_cache di dalamnya, dan programmer kami bahkan tidak menyadari bahwa itu di-cache. Di bawah ini kita melihat bahwa sebenarnya hanya satu bagian yang berfungsi.
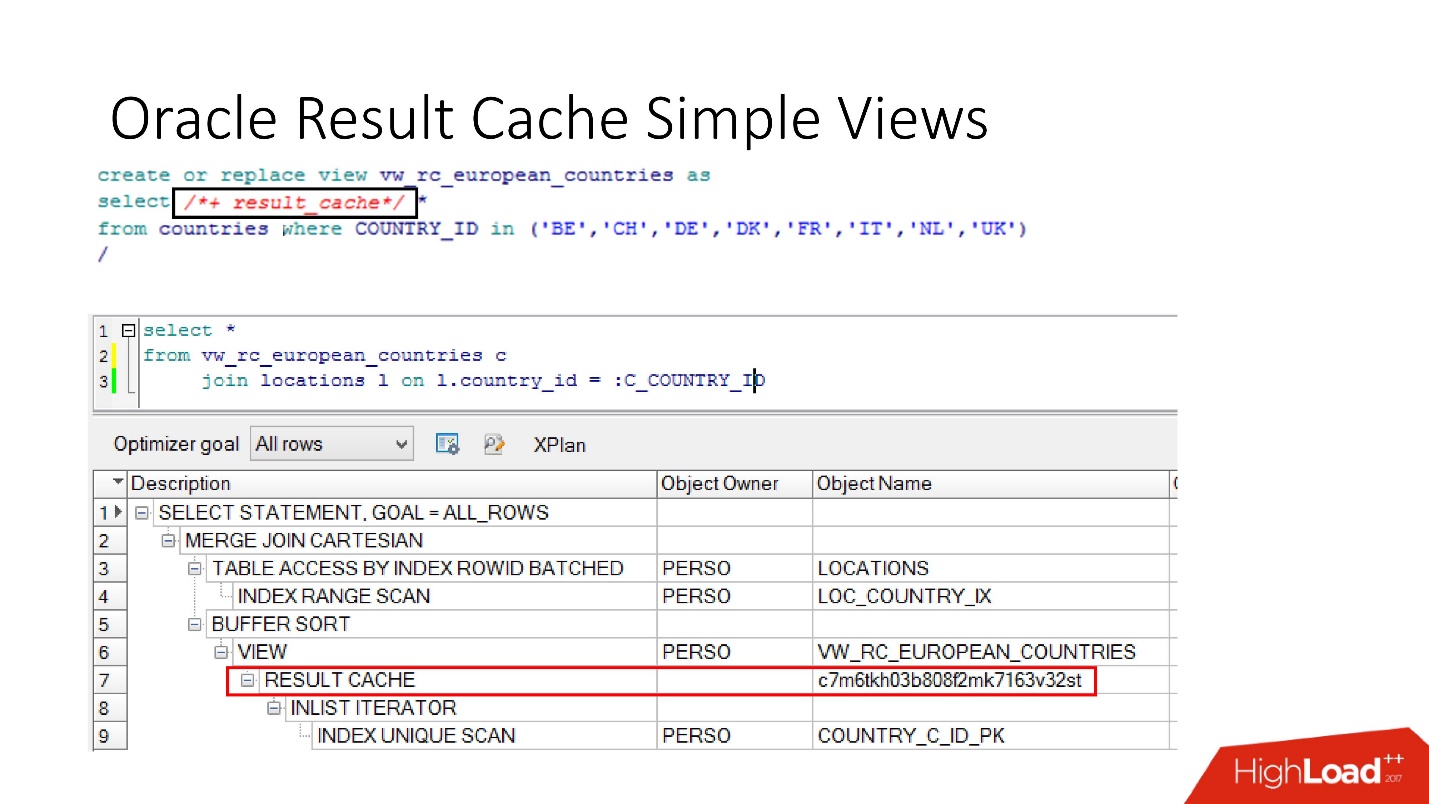
Cacat
Jadi, mari kita lihat ketika Oracle membatalkan result_cache. Status yang Diterbitkan menunjukkan status validitas cache saat ini. Ketika permintaan untuk result_cache, seperti yang saya katakan, tidak ada pekerjaan di database
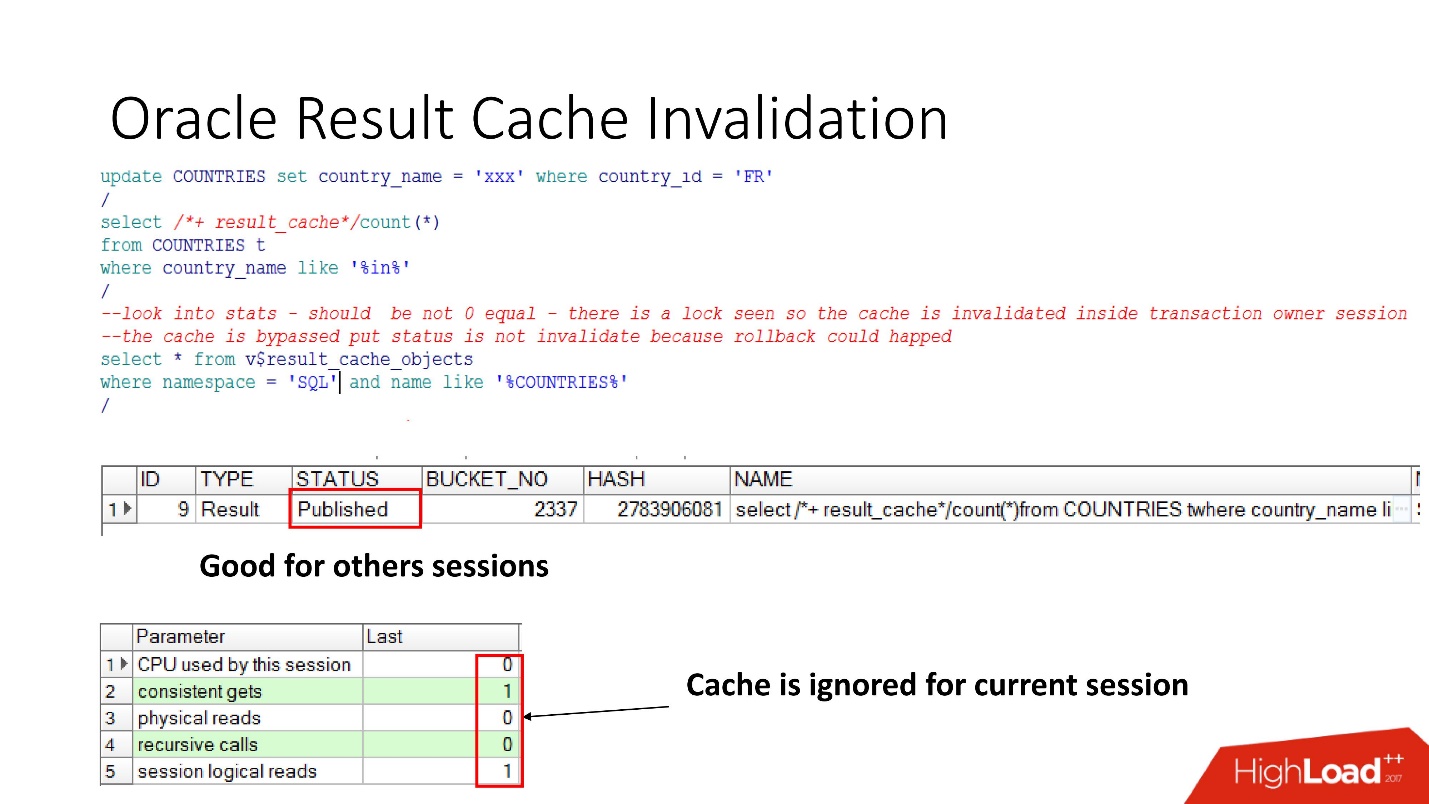
Ketika kami melakukan pembaruan, statusnya masih Diterbitkan, karena pembaruan belum dilakukan dan sesi lain akan melihat result_cache yang lama. Ini adalah konsistensi membaca yang terkenal buruk.
Tetapi dalam sesi saat ini kita akan melihat bahwa beban telah hilang, karena pada sesi ini cache diabaikan. Ini cukup masuk akal, mari kita komit - hasilnya akan menjadi tidak valid, semuanya bekerja dengan sendirinya.

Tampaknya - mimpi! Ketergantungan dianggap benar - hanya tergantung pada permintaan. Namun tidak, sejumlah nuansa terungkap.
Oracle menghasilkan cacat dan dalam sejumlah kasus yang tidak terlihat :
- Dengan panggilan SELECT FOR UPDATE, dependensi terbang.
- Jika tabel memiliki kunci asing yang tidak diindeks, dan pembaruan terjadi pada tabel yang ditandai result_cache, yang tidak memengaruhi apa pun, tetapi sesuatu telah berubah di tabel induk, cache juga akan menjadi tidak valid.
- Ini adalah hal yang paling menarik yang merusak kehidupan sebanyak mungkin - jika ada beberapa pembaruan yang gagal pada tabel yang ditandai sebagai result_cache, tidak ada yang berhasil, tetapi kemudian dalam transaksi yang sama setiap perubahan lain diterapkan yang entah bagaimana memengaruhi tabel pertama, bagaimanapun juga result_cache akan diatur ulang.
Masih ada antipattern tentang result_cache, ketika pengembang, setelah mendengar ada hal yang sangat keren, pikirkan: “Oh, ada penyimpanan! Sekarang kami akan mengambil beberapa permintaan yang berfungsi pada 2-3 partisi - pada tanggal saat ini dan yang sebelumnya, tandai sebagai result_cache, dan itu akan selalu diambil dari memori! "
Tetapi ketika Anda mengubah patricia di belakang, seluruh cache terbang, karena sebenarnya unit pelacakan ketergantungan di result_cache selalu berupa tabel, dan saya tidak tahu apakah akan ada partisi atau tidak.
Kami berpikir dan memutuskan bahwa kami akan membuat sistem rekomendasi dengan hal-hal berikut:
- Kami tidak akan melakukan cache semua tabel kami, kami hanya akan mengambil yang diperlukan.
- Setel result_cache untuk kueri yang sudah berjalan lama.
Kami memeriksa semuanya, melakukan tes kinerja,
waktu pemrosesan - 30 detik . Semuanya bagus, pergi ke produksi!
Lari - pergi tidur. Kami tiba di pagi hari. Kami melihat surat: "Pengakuan membutuhkan setidaknya 20 menit, sesi membeku." Mengapa mereka membeku? Bagaimana
30 detik berubah menjadi 20 menit ?
Mereka mulai mengerti, lihat database:
- sesi aktif - 400;
- pada garis rata-rata dalam dokumen untuk pengakuan - 500;
- minimum kolom - 5-8;
- jumlah sesi dalam basis data selalu sama dengan jumlah aplikasi pengguna dikalikan 3! Dan result_cache tidak suka sering mengaksesnya.
Setelah melakukan penyelidikan internal, kami menemukan bahwa pengembang Java membuat pengakuan dalam 3 utas.
Kami kesal - beban 5 kali lipat, jatuh, degradasi, dan bahkan dengan parameter seperti itu seharusnya tidak terjadi penurunan muka tanah.
Jelas, Anda harus mengerti.
Pemantauan

Untuk pemantauan, kami memiliki dua hal utama:
- V $ RESULT_CACHE_OBJECTS - daftar semua objek;
- V $ RESULT_CACHE_STATISTICS - statistik agregat dari result_cache secara keseluruhan.
MEMORY_REPORT adalah variasi pada suatu tema, kami tidak akan membutuhkannya.
Oracle ajaib! Ada dokumentasi yang bagus, tetapi dirancang untuk mereka yang beralih dari database lain sehingga mereka membaca dan berpikir bahwa Oracle sangat keren! Tetapi
semua informasi pada result_cache hanya terletak pada dukungan .

Ada nuansa yang terdiri dari kenyataan bahwa begitu kita beralih ke objek-objek ini untuk menyelesaikan masalah, kita memperburuknya dengan akhirnya mengubur diri kita sendiri! Sampai Oracle12.2, sebelum tambalan yang dirilis pada Oktober tahun lalu, permintaan ini membuat result_cache tidak dapat diakses untuk status dan untuk menulis sampai mereka benar-benar dihitung.
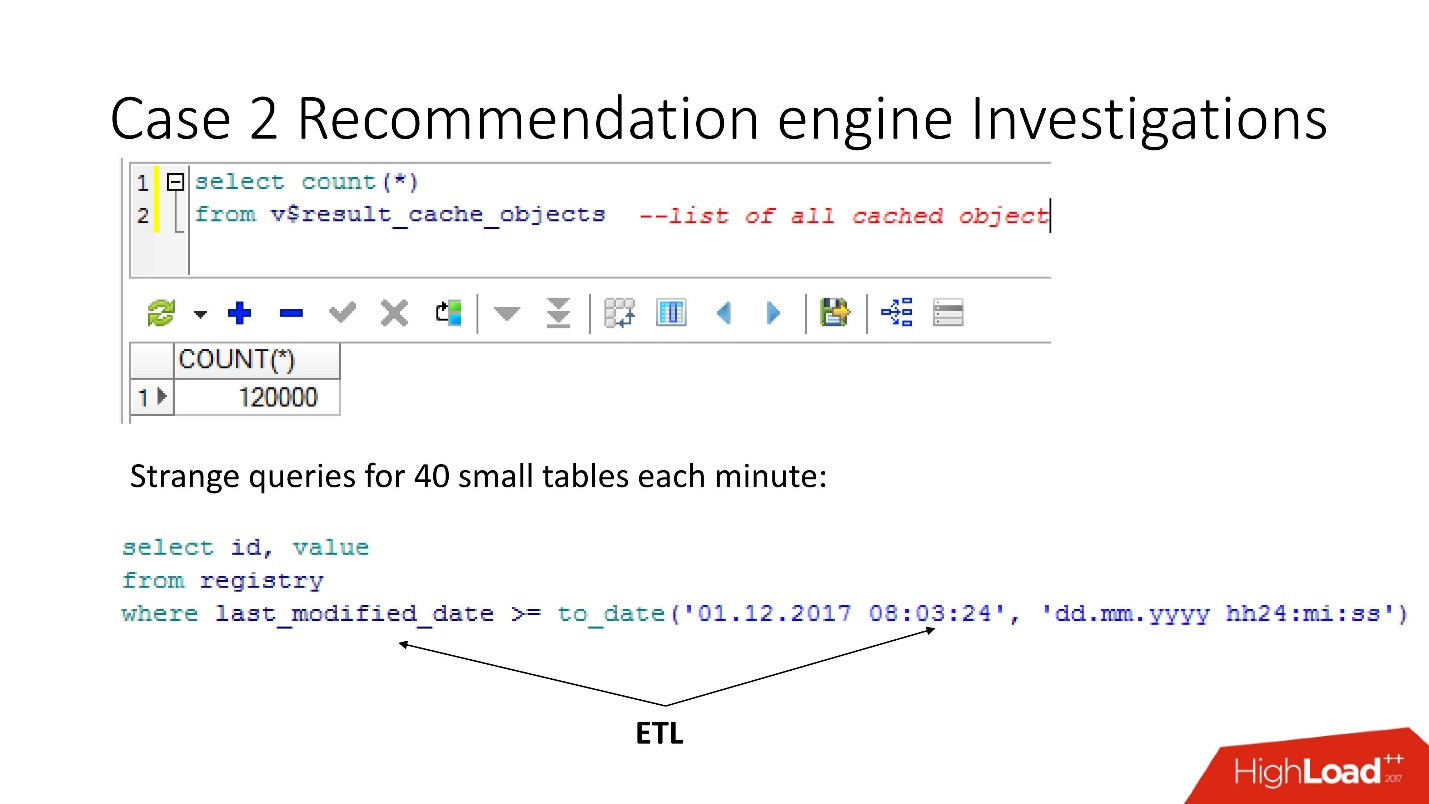
Jadi, dengan menggunakan tampilan v $ result_cache_objects, kami menemukan bahwa ada ribuan entri dalam daftar objek yang di-cache - lebih dari yang kami harapkan. Selain itu, ini adalah objek dari beberapa kueri kami di tabel aneh - tablet kecil, dan kueri last_modified_date. Jelas,
seseorang menetapkan ETL di pangkalan kami .
Sebelum bersumpah pada pengembang ETL, kami memeriksa bahwa opsi force result_cache diaktifkan untuk tabel ini, dan ingat bahwa kami menyalakannya sendiri, karena beberapa data ini sering diperlukan oleh aplikasi dan caching sesuai.
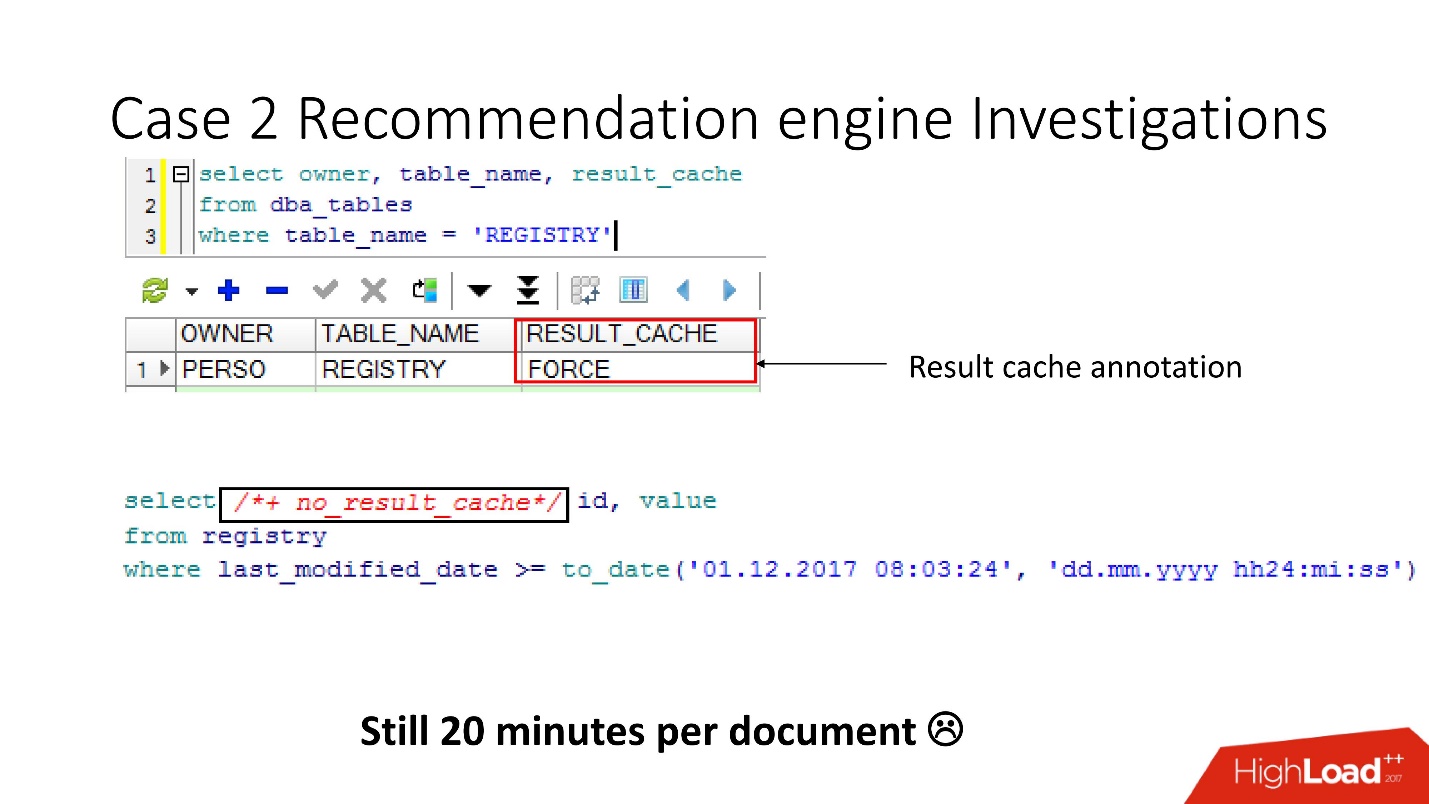
Tetapi ternyata
semua permintaan ini hanya mengambil dan mencuci cache kami . Untungnya, pengembang memiliki kesempatan untuk mempengaruhi ETL dalam produksi, jadi kami dapat mengubah result_cache untuk mengecualikan permintaan menit ini.
Apakah Anda pikir ini lebih mudah? - Jangan merasa lebih baik! Jumlah objek yang di-cache menurun, dan kemudian naik lagi menjadi 12.000. Kami terus mempelajari apa yang di-cache, karena kecepatannya tidak berubah.

Kami melihat - banyak permintaan, dan sangat pintar, tetapi semua tidak bisa dipahami. Meskipun siapa pun yang telah bekerja dengan Oracle 12 tahu bahwa DS SVC adalah statistik adaptif. Itu diperlukan untuk meningkatkan kinerja, tetapi ketika ada result_cache, ternyata itu membunuhnya karena persaingan sedang terjadi. Ini, tentu saja,
hanya ditulis
sebagai dukungan .
Kami tahu bagaimana beban kerja diatur dan dipahami bahwa dalam kasus kami, statistik adaptif tidak akan secara radikal memperbaiki rencana kami. Oleh karena itu, kami mematikannya secara heroik - hasilnya, seperti yang tertulis dalam manual rahasia, adalah 10 menit per dokumen. Tidak buruk, tetapi tidak cukup.
Kait
Persaingan antara result_cache dan DS SVC disebabkan oleh fakta bahwa Oracle memiliki kait - kunci kecil yang ringan.

Tanpa merinci bagaimana cara kerjanya, kami mencoba untuk memasang kait bernama beberapa kali - tidak berhasil - Oracle mengambil dan tertidur
Siapa pun yang berada dalam subjek dapat mengatakan bahwa dalam result_cache, dua kait ditempatkan pada setiap blok dengan mengambil. Ini adalah detailnya. Ada dua jenis kait di result_cache:
1. Kait untuk periode sementara kami menulis data di result_cache.

Artinya, jika permintaan Anda telah bekerja selama 8 detik, untuk periode 8 detik ini, permintaan lain yang sama (kata kunci "sama") tidak akan dapat melakukan apa pun, karena mereka menunggu sampai data ditulis ke result_cache. Permintaan lain akan dicatat, tetapi permintaan itu hanya akan menunggu kunci di baris pertama. Berapa banyak mereka harus menunggu tidak diketahui, ini adalah parameter hasil_cache_timeout tidak berdokumen. Setelah itu, mereka mulai mengabaikan result_cache, seolah-olah, dan bekerja perlahan. Namun, begitu kunci dari baris terakhir di pintu telah dirilis, mereka secara otomatis mulai bekerja dengan result_cache lagi.
2. Jenis kunci kedua - untuk menerima dari result_cache juga dari baris 1 hingga yang terakhir.
Tetapi karena mengambil berasal dari memori instan, mereka dihapus dengan sangat cepat.

Pastikan untuk diingat bahwa ketika DBA melihat kait di database, itu mulai berkata: "Kait! Waktu tunggu - semuanya hilang! »Dan di sini permainan yang paling menarik dimulai:
meyakinkan DBA bahwa waktu tunggu dari kait sebenarnya jauh lebih pendek daripada waktu coba lagi permintaan .

Seperti yang ditunjukkan oleh pengalaman kami, pengukuran kami,
terkait dengan result_cache menempati 10% dari permintaan itu sendiri .
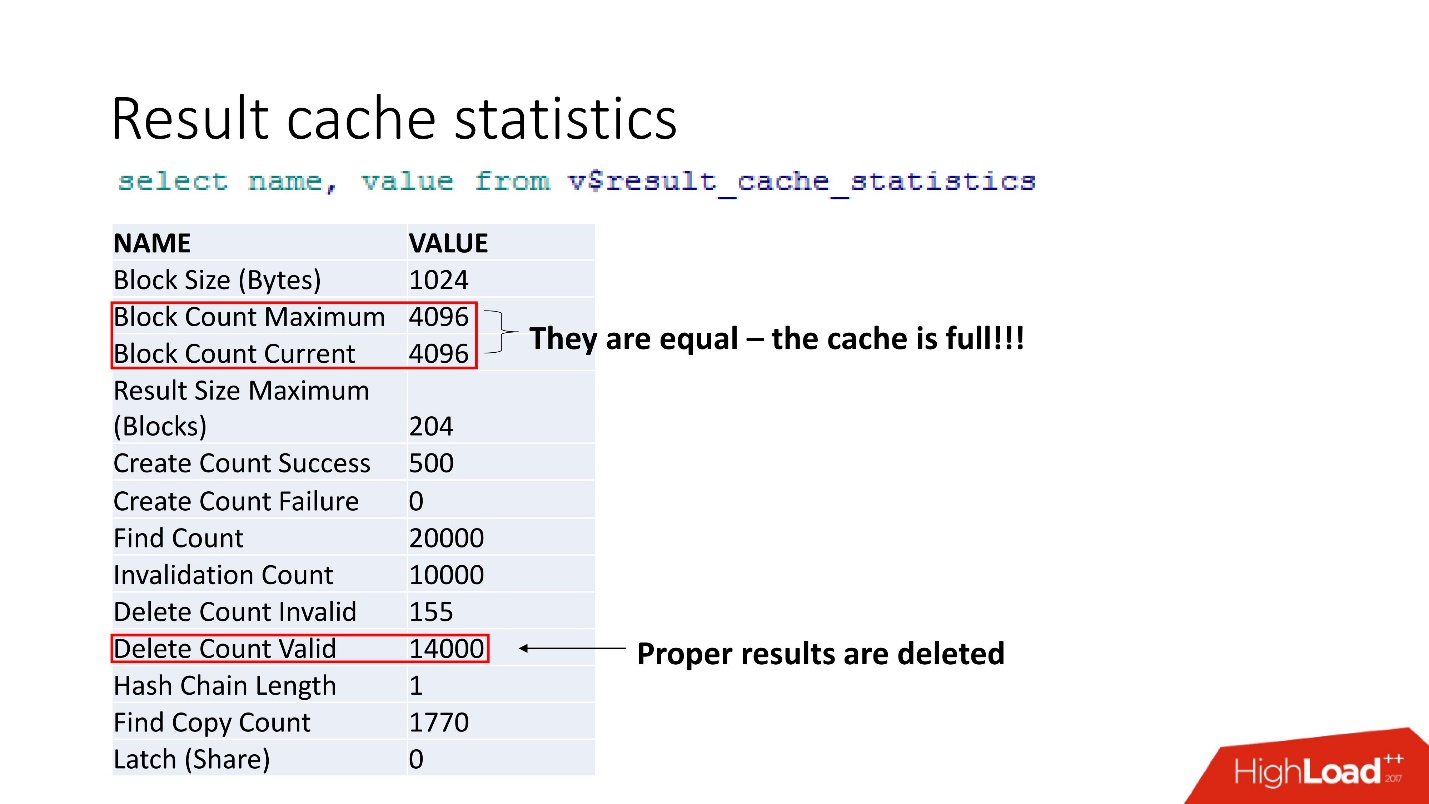
Ini adalah statistik gabungan. Fakta bahwa semuanya buruk dapat dipahami oleh fakta bahwa cache tersumbat. Konfirmasi lain adalah hasil yang tepat dihapus. Yaitu,
cache ditimpa . Tampaknya kami cerdas dan selalu mempertimbangkan ukuran memori - kami mengambil ukuran garis hasil cache kami untuk rekomendasi kami, dikalikan dengan jumlah garis, dan ada yang salah.

support 2 , ,
result_cache . .
, . , , , workload 5 . , , .
?: . , .
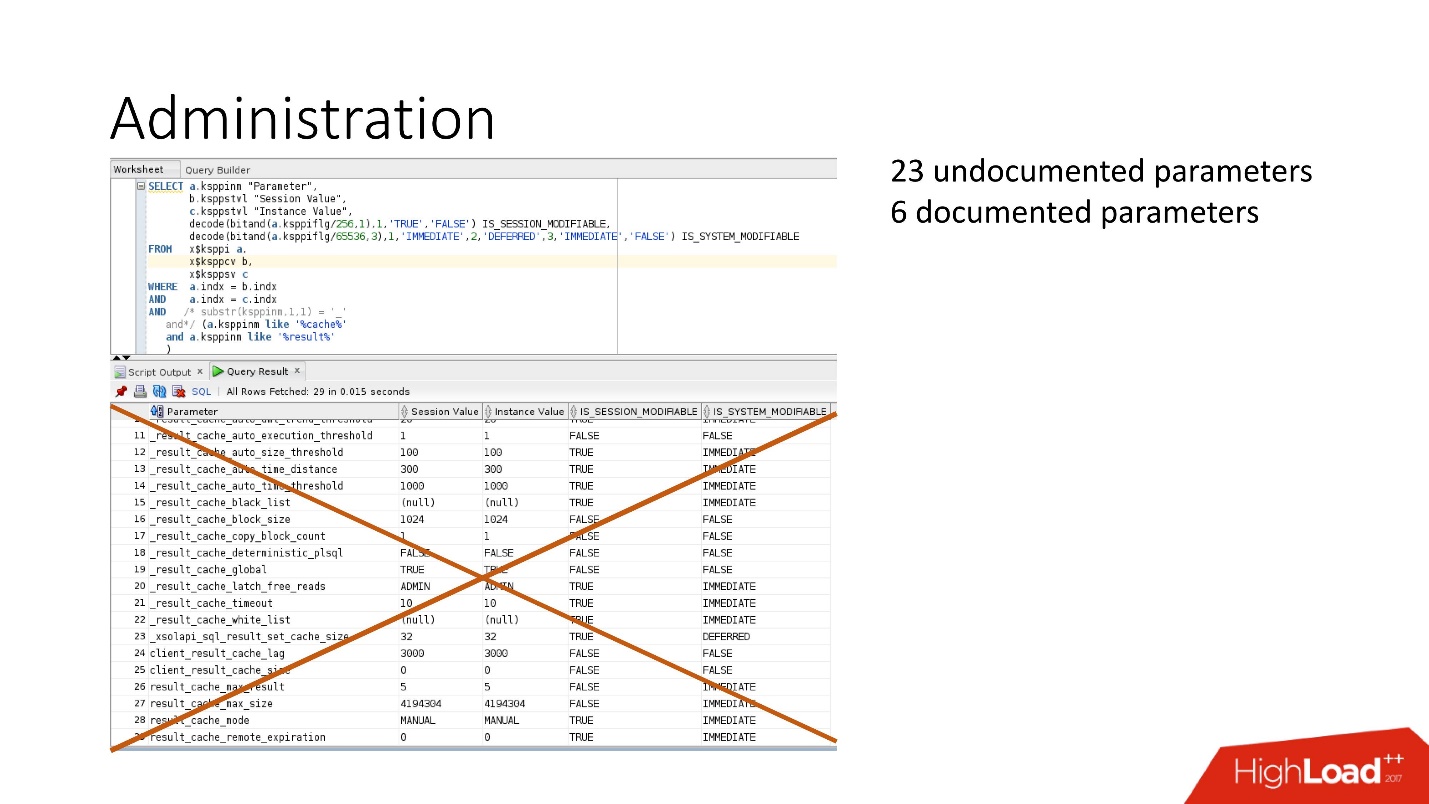
4 :
- RESULT_CACHE_MAX_SIZE;
- RESULT_CACHE_MAX_RESULT;
- RESULT_CACHE_MODE;
- _RESULT_CACHE_MAX_TIMEOUT.
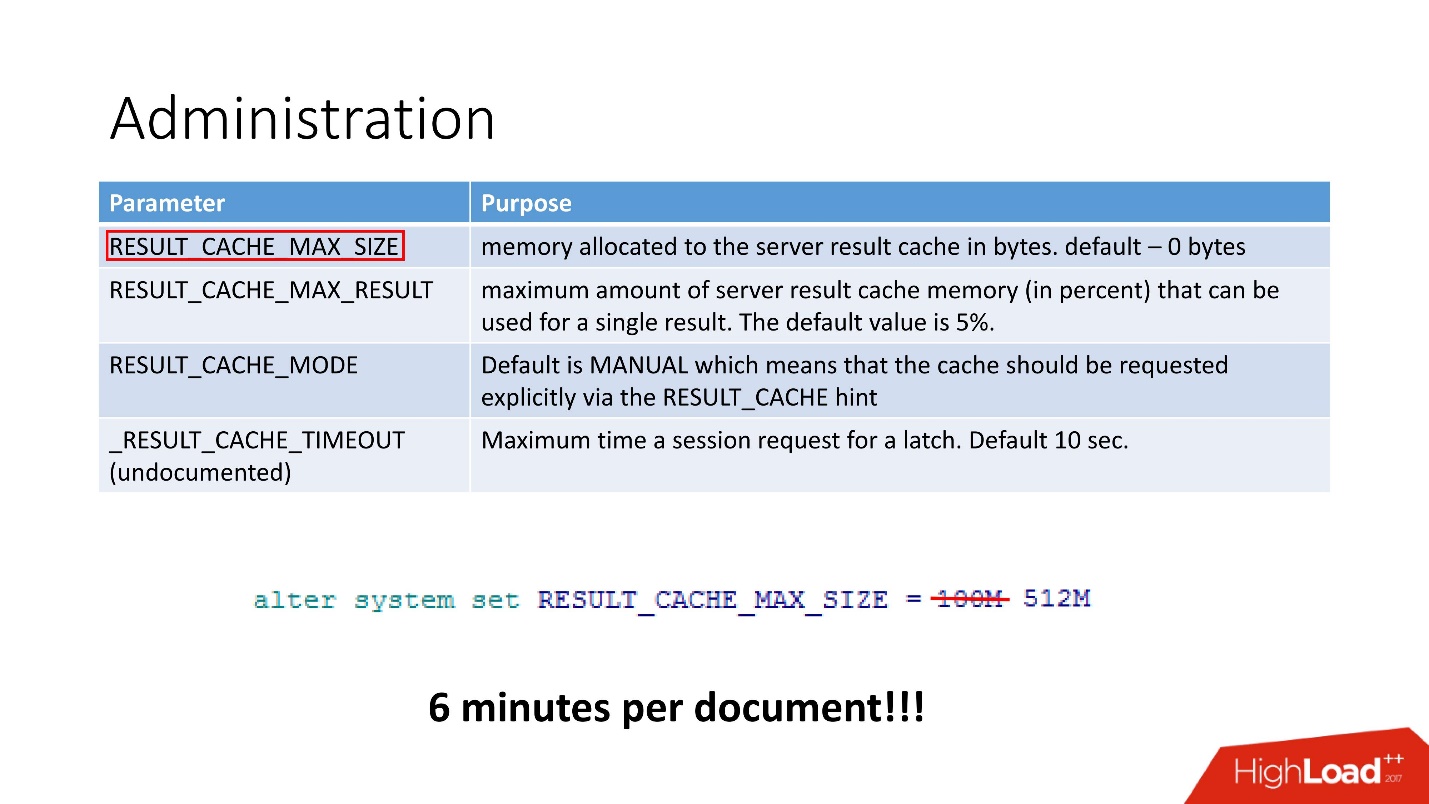
— . , 100 512, 6 .
, - . , Invalidation Count = 10000.
, . , job , . , . job , , .
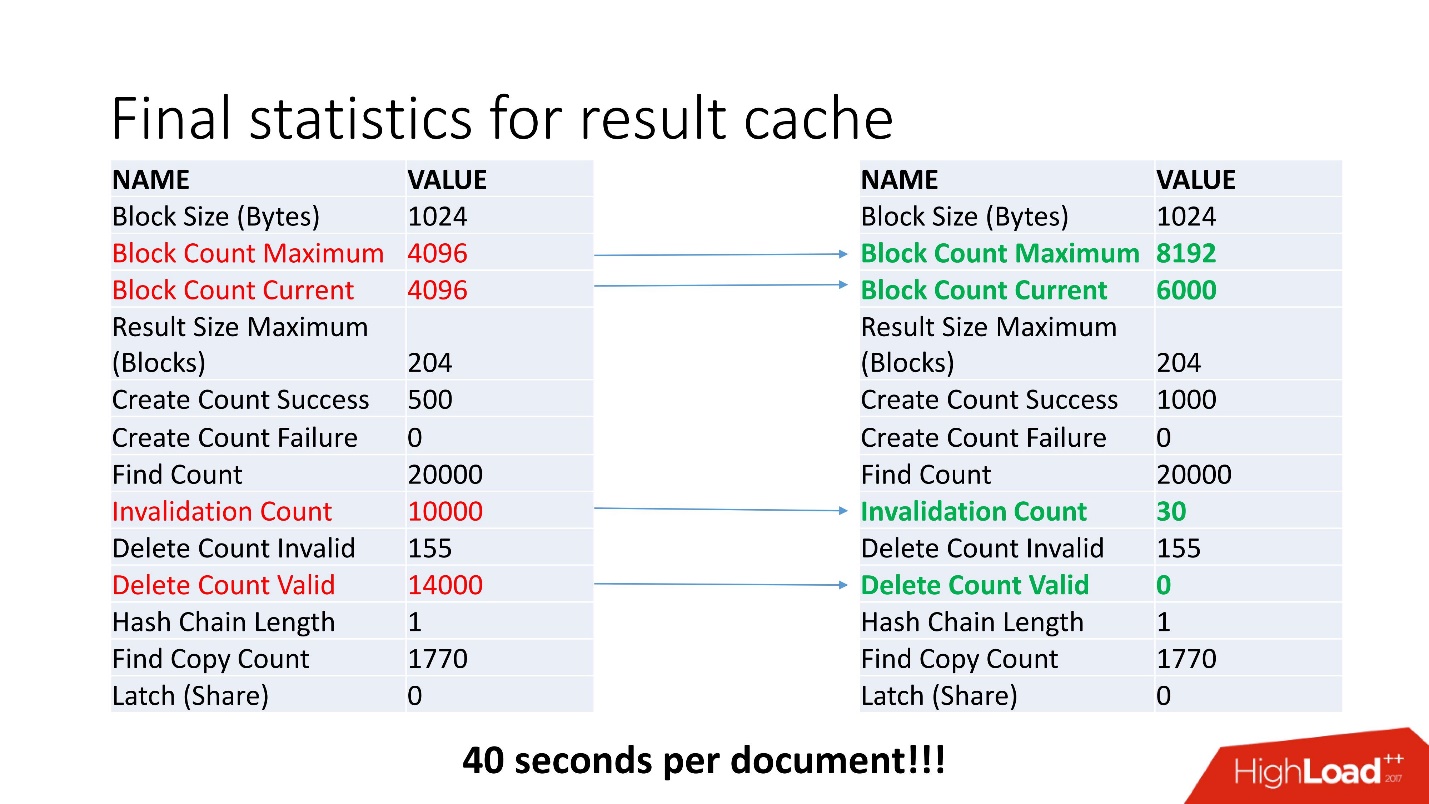
, invalid , .
40 .
, . , , Oracle. !
 SHELFLIVE
SHELFLIVE — , read-consistent , 10 , . . , , .
—
SNAPSHOT . , , read-consistent — .
:

- — SYS.
- . , , Oracle , , . , Oracle , , 12.2 . , external - support, .
- sql pl/sql : current_date, current_time . , current_time, .
- .
- , CLOB, BLOB .
Result cache inside Oracle
Result_cache — Oracle Core. , , job result_cache (, hint, ) , APEX.

, Dynamic sampling , , , result_cache.

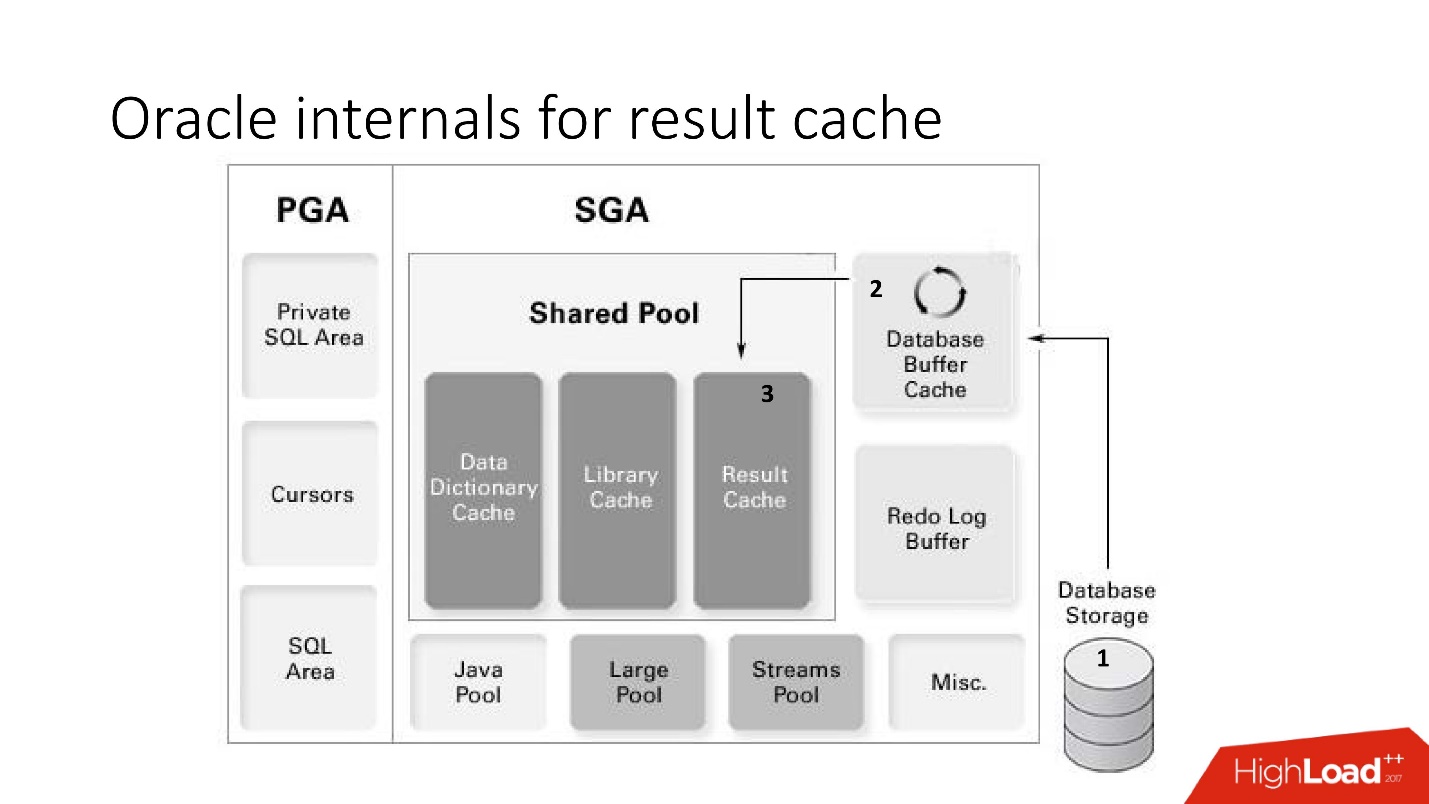
Oracle internals for result cache
result_cache:
- (storage) ;
- result_cache;
- result_cache shared pool.
 :
:- .
- read-consistent.
- Result_cache, , .
:!
, . support Oracle, , 29 2017 .: Oracle E-Business suite result_cache, .

, , . support , , .

:
- - ;
- , , , , v$result_cache_memory dbms_result_cache.memory_report, .
, , , v_result_cache_objects .
, support note — support , .

, , : - . , , :
- hint result_cache;
- hint no result_cache;
- black_list, , , -.
?,
— . Oracle , .
Client side result cache

Diagram perangkatnya ditunjukkan di atas, ini adalah komponen utama dari database dan driver.
Pertama kali sisi klien diakses, Cache Hasil pergi ke database, yang sudah dikonfigurasi sebelumnya, menerima ukuran cache klien dari database dan menginstal cache ini pada klien satu kali pada koneksi pertama. Query cache pertama-tama mengakses database dan menulis data ke cache. Utas yang tersisa meminta cache driver bersama, sehingga menghemat memori server dan sumber daya. Ngomong-ngomong, kadang-kadang tergantung pada beban, driver mengirim statistik tentang penggunaan cache ke database, yang kemudian dapat dilihat.
Pertanyaan yang menarik adalah, bagaimana kecacatan terjadi?Ada dua mode invalidation, yang dipertajam oleh parameter Invalidation lag. Ini adalah seberapa banyak Oracle memungkinkan cache driver menjadi tidak konsisten.
Mode pertama digunakan ketika permintaan sering pergi dan jeda pembatalan tidak terjadi. Dalam hal ini, stream akan menuju ke database, memperbarui cache dan membaca data darinya.
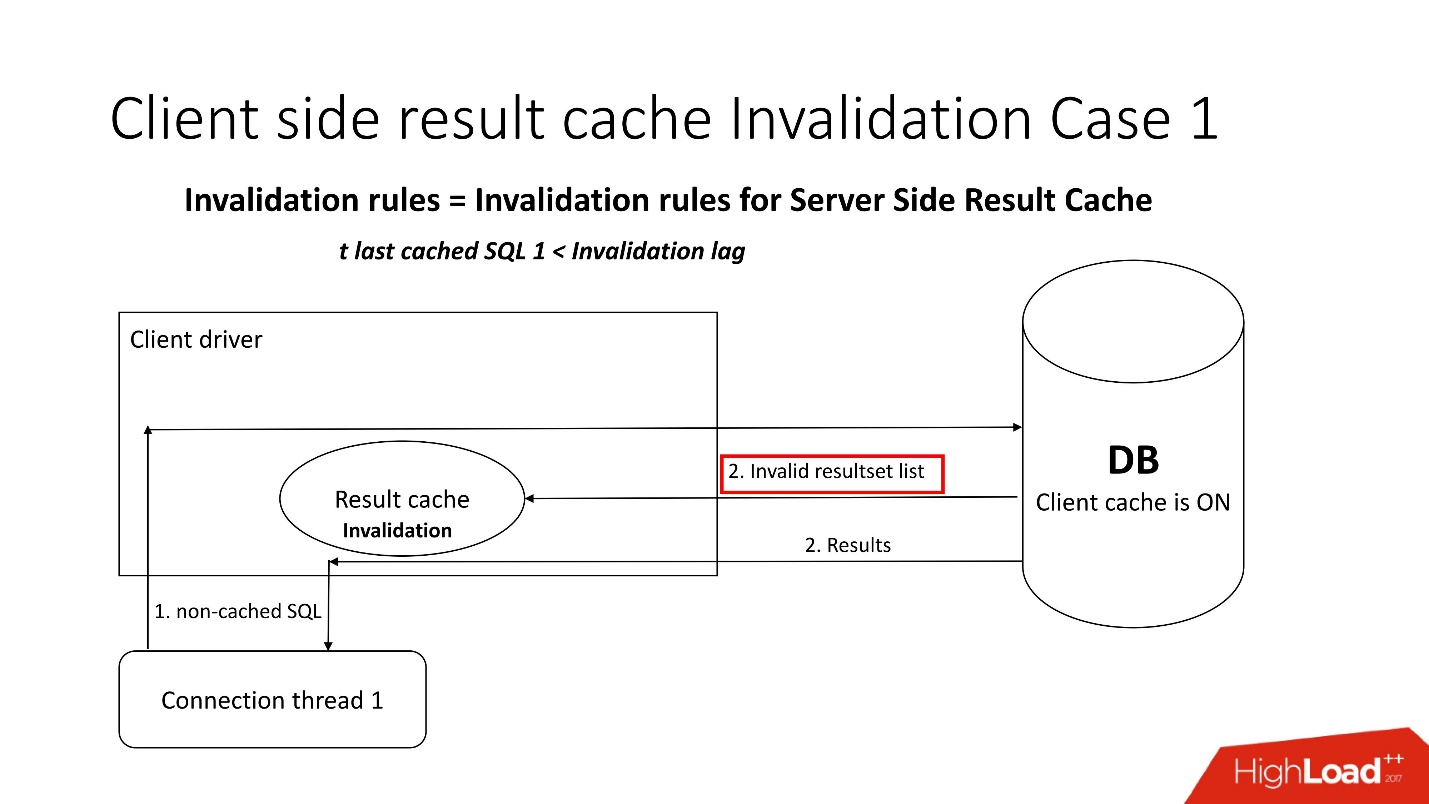
Jika kelambatan validasi gagal, maka setiap permintaan yang tidak di-cache, merujuk ke database, di samping hasil kueri, membawa daftar objek yang tidak valid. Dengan demikian, mereka ditandai sebagai tidak valid dalam cache, dan semuanya berfungsi seperti pada gambar dari skenario pertama.
Dalam kasus kedua, jika lebih banyak waktu telah berlalu daripada jeda validasi, maka client result_cache itu sendiri pergi ke database dan berkata: "Beri aku daftar perubahan!" Artinya, dia sendiri mempertahankan kondisinya yang memadai.
Mengkonfigurasi Cache Hasil sisi klien sangat sederhana . Ada 2 opsi:
- CLIENT_RESULT_CACHE_LAG - nilai lag cache;
- CLIENT_RESULT_CACHE_SIZE - ukuran (minimum 32 Kb, maksimum - 2 GB).

Dari sudut pandang pengembang aplikasi, cache klien tidak jauh berbeda dari cache server, mereka juga memasukkan petunjuk result_cache. Jika ya, maka itu hanya akan mulai digunakan oleh klien - baik di .Net dan di Jawa.

Setelah melakukan 10 iterasi dari kueri, saya mendapatkan yang berikut ini.

Daya tarik pertama adalah pembuatan, lalu 9 akses cache. Tabel menunjukkan bahwa memori juga dialokasikan dalam blok. Juga perhatikan SELECT - ini tidak terlalu intuitif. Sejujurnya, sebelum saya mulai berurusan dengan ini, saya bahkan tidak tahu bahwa ada representasi seperti
GV$SESSION_CONNECT_INFO . Mengapa Oracle tidak membawanya langsung ke tabel ini (dan ini adalah tabel, bukan tampilan), saya tidak bisa mengerti. Tapi itu sebabnya saya percaya bahwa fungsi ini tidak terlalu populer, meskipun, menurut saya, ini sangat berguna.
Keuntungan dari caching klien:- memori klien murah;
- driver apa pun yang tersedia - JDBC, .NET, dll.
- dampak minimal dalam kode aplikasi.
- Mengurangi beban pada CPU, I / O dan umumnya database;
- tidak perlu belajar dan menggunakan segala macam lapisan caching pintar dan API;
- tidak ada kait.
Kekurangan:- konsistensi dalam membaca dengan penundaan - pada prinsipnya, sekarang ini adalah tren;
- membutuhkan klien Oracle OCI;
- batasan 2 GB per klien, tetapi secara umum 2 GB banyak;
- Bagi saya pribadi, batasan utama adalah sedikit informasi tentang produksi.
Pada dukungan, yang selalu kami gunakan ketika bekerja dengan result_cache, saya hanya menemukan 5 bug. Ini menunjukkan bahwa, kemungkinan besar, hanya sedikit orang yang membutuhkannya.
Jadi, kami menyatukan semua yang dikatakan di atas.
Tembolok buatan tangan
Skenario buruk:- Perubahan instan - jika setelah mengubah data, cache harus segera menjadi tidak relevan. Untuk singgahan buatan sendiri, sulit untuk membuat pembatalan yang benar jika terjadi perubahan pada objek di mana mereka dibangun.
- Jika penggunaan logika yang disimpan dalam database dilarang oleh kebijakan pengembangan.
Skenario yang bagus:- Ada tim pengembangan basis data yang kuat.
- Menerapkan logika PL / SQL.
- Ada batasan yang mencegah teknik caching lainnya digunakan.
Tembolok hasil sisi server
Skenario buruk:- Banyak hasil berbeda yang hanya mencuci seluruh cache;
- Permintaan membutuhkan waktu lebih lama dari _RESULT_CACHE_TIMEOUT atau parameter ini tidak dikonfigurasi dengan benar.
- Hasil dari sesi yang sangat besar dimuat ke dalam cache di thread paralel.
Skenario yang bagus:- Jumlah hasil cache yang masuk akal.
- Kumpulan data yang relatif kecil (200–300 baris).
- SQL yang cukup mahal, jika tidak, semua waktu akan ke latch.
- Tabel kurang lebih statis.
- Ada DBA, yang dalam hal sesuatu akan datang dan menyelamatkan semua orang.
Tembolok hasil sisi klien
Skenario buruk:- Ketika masalah kecacatan instan muncul.
- Dibutuhkan driver yang tipis.
Skenario yang bagus:- Ada tim pengembangan lapisan tengah normal.
- Banyak SQL sudah digunakan tanpa menggunakan lapisan caching eksternal yang dapat dengan mudah dihubungkan.
- Ada batasan pada kelenjar.
Kesimpulan
Saya percaya bahwa cerita saya adalah tentang nyeri cache hasil sisi server, jadi kesimpulannya adalah sebagai berikut:
- Selalu evaluasi ukuran memori dengan benar dengan mempertimbangkan jumlah kueri, dan bukan jumlah hasil, yaitu: blok, APEX, pekerjaan, statistik adaptif, dll.
- Jangan takut untuk menggunakan opsi pembilasan cache otomatis (snapshot + shelflife).
- Jangan membebani cache dengan permintaan saat memuat sejumlah besar data; nonaktifkan result_cache sebelum ini. Lakukan pemanasan cache.
- Pastikan _result_cache_timeout memenuhi harapan Anda.
- JANGAN PERNAH menggunakan FORCE untuk seluruh basis data. Membutuhkan database dalam memori - gunakan solusi khusus dalam memori.
- Periksa apakah opsi FORCE digunakan secara tepat untuk setiap tabel sehingga tidak berfungsi seperti yang kami lakukan dengan ETL pihak ketiga.
- Putuskan apakah statistik adaptif sebaik dijelaskan oleh Oracle (_optimizer_ads_use_result_cache = false).
Highload ++ Siberia Senin depan, jadwal siap dan dipublikasikan di situs. Ada beberapa laporan dalam topik artikel ini:
- Alexander Makarov (CFT GC) akan menunjukkan metode untuk mengidentifikasi kemacetan di sisi server perangkat lunak menggunakan database Oracle sebagai contoh.
- Ivan Sharov dan Konstantin Poluektov akan memberi tahu Anda masalah apa yang muncul saat memigrasi produk ke versi baru dari basis data Oracle, dan juga berjanji untuk memberikan rekomendasi tentang pengorganisasian dan melakukan pekerjaan seperti itu.
- Nikolay Golov akan memberi tahu Anda cara memastikan integritas data dalam arsitektur layanan mikro tanpa transaksi terdistribusi dan konektivitas yang ketat.
Temui aku di Novosibirsk!