Artikel ini akan fokus pada beberapa algoritma pencarian dan deskripsi poin gambar tertentu. Di sini topik ini telah
diangkat , dan lebih
dari sekali . Saya akan mempertimbangkan bahwa definisi dasar sudah akrab bagi pembaca, kami akan memeriksa secara detail algoritma heuristik CEPAT, CEPAT-9, CEPAT-ER, SINGKAT, rBRIEF, ORB, dan membahas ide-ide cemerlang yang mendasari mereka. Sebagian, ini akan menjadi terjemahan gratis dari esensi beberapa artikel [1,2,3,4,5], akan ada beberapa kode untuk "coba".

Algoritma CEPAT
FAST, pertama kali diusulkan pada 2005 di [1], adalah salah satu metode heuristik pertama untuk menemukan titik tunggal, yang memperoleh popularitas besar karena efisiensi komputasinya. Untuk membuat keputusan tentang mempertimbangkan suatu titik C sebagai istimewa atau tidak, metode ini menganggap kecerahan piksel pada lingkaran yang berpusat pada titik C dan jari-jari 3:

Membandingkan kecerahan piksel lingkaran dengan kecerahan pusat C, untuk masing-masing kita mendapatkan tiga kemungkinan hasil (tampaknya lebih terang, lebih gelap):
$ sebaris $ \ begin {array} {l} {I_p}> {I_C} + t \\ {I_p} <{I_C} -t \\ {I_C} -t <{I_p} <{I_C} + t \ end {array} $ inline $
Di sini saya adalah kecerahan piksel, t adalah ambang batas kecerahan yang telah ditentukan.
Suatu titik ditandai sebagai spesial jika ada n = 12 piksel dalam satu baris yang lebih gelap, atau 12 piksel yang lebih terang dari pusat.
Seperti yang telah ditunjukkan oleh praktik, secara rata-rata, untuk membuat keputusan, perlu memeriksa sekitar 9 poin. Untuk mempercepat proses, penulis menyarankan terlebih dahulu memeriksa hanya empat piksel dengan angka: 1, 5, 9, 13. Jika di antara mereka ada 3 piksel lebih terang atau lebih gelap, maka pemeriksaan penuh dilakukan pada 16 titik, jika tidak, titik tersebut segera ditandai sebagai " tidak spesial. " Ini sangat mengurangi waktu kerja, untuk membuat keputusan rata-rata cukup untuk polling hanya sekitar 4 poin lingkaran.
Sedikit kode naif terletak
di siniParameter variabel (dijelaskan dalam kode): jari-jari lingkaran (mengambil nilai 1,2,3), parameter n (dalam aslinya, n = 12), parameter t. Kode membuka file in.bmp, memproses gambar, menyimpannya ke out.bmp. Gambar biasa 24-bit.
Membangun pohon keputusan, Pohon CEPAT, CEPAT-9
Pada tahun 2006, pada [2], adalah mungkin untuk mengembangkan ide orisinal menggunakan pembelajaran mesin dan pohon keputusan.
CEPAT asli memiliki kelemahan berikut:
- Beberapa piksel yang berdekatan dapat ditandai sebagai titik khusus. Kami membutuhkan beberapa ukuran "kekuatan" fitur. Salah satu langkah pertama yang diusulkan adalah nilai maksimum t di mana titik tersebut masih diambil sebagai tindakan khusus.
- Tes 4-titik cepat tidak digeneralisasikan untuk n kurang dari 12. Jadi, misalnya, secara visual hasil terbaik dari metode ini dicapai dengan n = 9, bukan 12.
- Saya juga ingin mempercepat algoritme!
Alih-alih menggunakan kaskade dua tes dari 4 dan 16 poin, itu diusulkan untuk melakukan segalanya dalam satu melewati pohon keputusan. Demikian pula dengan metode asli, kita akan membandingkan kecerahan titik tengah dengan titik-titik pada lingkaran, tetapi dalam urutan ini untuk membuat keputusan secepat mungkin. Dan ternyata Anda bisa membuat keputusan hanya untuk perbandingan ~ 2 (!!!) rata-rata.
Garam utama adalah bagaimana menemukan urutan yang tepat untuk membandingkan poin. Temukan menggunakan pembelajaran mesin. Misalkan seseorang terkenal untuk kita dalam gambar banyak poin khusus. Kami akan menggunakannya sebagai satu set contoh pelatihan, dan idenya adalah untuk
dengan penuh semangat memilih yang akan memberikan jumlah informasi terbesar pada langkah ini sebagai poin berikutnya. Sebagai contoh, misalkan pada awalnya dalam sampel kami ada 5 poin tunggal dan 5 poin non-tunggal. Dalam bentuk tablet seperti ini:
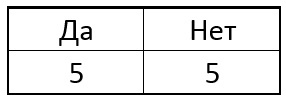
Sekarang kita memilih salah satu piksel p dari lingkaran dan untuk semua titik singular kita membandingkan piksel pusat dengan yang dipilih. Bergantung pada kecerahan piksel yang dipilih di dekat setiap titik tertentu, tabel mungkin memiliki hasil sebagai berikut:
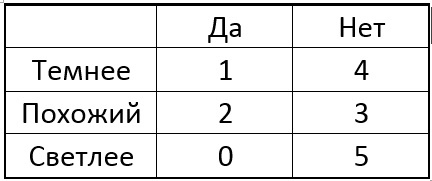
Idenya adalah untuk memilih titik p sehingga angka-angka di kolom tabel berbeda mungkin. Dan jika sekarang untuk titik yang tidak diketahui baru kita mendapatkan hasil perbandingan "Lebih Ringan", maka kita sudah dapat langsung mengatakan bahwa titik itu "tidak istimewa" (lihat tabel). Proses ini berlanjut secara rekursif sampai titik-titik dari hanya satu kelas jatuh ke masing-masing kelompok setelah dibagi menjadi "gelap-seperti-lebih ringan". Ternyata pohon dengan bentuk berikut:
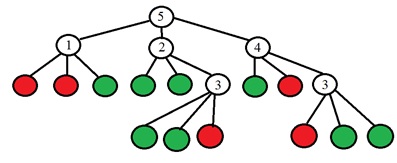
Nilai biner ada di daun pohon (merah adalah khusus, hijau tidak istimewa), dan di simpul lain dari pohon adalah jumlah titik yang perlu dianalisis. Lebih khusus lagi, dalam artikel asli, mereka mengusulkan membuat pilihan nomor poin dengan mengubah entropi. Entropi himpunan poin dihitung:
$$ menampilkan $$ H = \ kiri ({c + \ overline c} \ kanan) {\ log _2} \ kiri ({c + \ overline c} \ kanan) - c {\ log _2} c - \ overline c {\ log _2} \ overline c $$ menampilkan $$
c adalah jumlah titik tunggal,
$ inline $ {\ bar c} $ inline $ Apakah jumlah titik non-tunggal himpunan
Ubah entropi setelah titik pemrosesan p:
$$ tampilkan $$ \ Delta H = H - {H_ {dark}} - {H_ {equal}} - {H_ {bright}} $$ tampilkan $$
Dengan demikian, suatu titik dipilih dimana perubahan dalam entropi akan menjadi maksimum. Proses pemisahan berhenti ketika entropi nol, yang berarti bahwa semua titik adalah tunggal, atau sebaliknya - semua tidak istimewa. Dengan implementasi perangkat lunak, setelah semua ini, pohon keputusan yang ditemukan dikonversi menjadi seperangkat konstruksi dari tipe "jika-lain".
Langkah terakhir dari algoritma adalah operasi menekan non-maksimum untuk mendapatkan satu dari beberapa titik yang berdekatan. Pengembang menyarankan menggunakan ukuran asli berdasarkan jumlah perbedaan mutlak antara titik pusat dan titik-titik lingkaran dalam formulir ini:
$$ menampilkan $$ V = \ maks \ kiri ({\ jumlah \ limit_ {x \ dalam {S_ {cerah}}} {\ kiri | {{I_x} - {I_p}} \ kanan | - t, \ jumlah \ limit_ {x \ in {S_ {dark}}} {\ kiri | {{I_p} - {I_x}} \ kanan | - t}}} \ kanan) $$ tampilkan $$
Di sini
$ inline $ {S_ {bright}} $ inline $ dan
$ inline $ {S_ {dark}} $ inline $ masing-masing, kelompok piksel lebih terang dan lebih gelap, t adalah nilai kecerahan ambang,
$ inline $ {I_p} $ inline $ - Kecerahan piksel pusat,
$ inline $ {{I_x}} $ inline $ - Kecerahan piksel pada lingkaran. Anda dapat mencoba algoritme dengan
kode berikut . Kode diambil dari OpenCV dan dibebaskan dari semua dependensi, jalankan saja.
Mengoptimalkan pohon keputusan - FAST-ER
FAST-ER [3] adalah algoritma dari penulis yang sama dengan yang sebelumnya, detektor cepat dibangun dengan cara yang sama, urutan titik yang optimal juga dicari untuk perbandingan, pohon keputusan juga dibangun, tetapi menggunakan metode yang berbeda - metode optimisasi.
Kami sudah memahami bahwa detektor dapat direpresentasikan sebagai pohon keputusan. Jika kita memiliki kriteria untuk membandingkan kinerja pohon yang berbeda, maka kita dapat memaksimalkan kriteria ini dengan memilah-milah varian pohon yang berbeda. Dan sebagai kriteria seperti itu, diusulkan untuk menggunakan "Repeatability".
Repeatability menunjukkan seberapa baik titik-titik singular dari suatu adegan terdeteksi dari sudut yang berbeda. Untuk sepasang gambar, suatu titik disebut "berguna" jika ditemukan pada satu bingkai dan secara teoritis dapat ditemukan pada yang lain, mis. Jangan menghalangi elemen adegan. Dan intinya disebut "diulang" (diulang), jika ditemukan di bingkai kedua juga. Karena optik kamera tidak ideal, titik pada frame kedua mungkin tidak dalam piksel yang dihitung, tetapi di suatu tempat di sekitarnya. Pengembang mengambil lingkungan 5 piksel. Kami mendefinisikan pengulangan sebagai rasio jumlah poin berulang dengan jumlah poin yang berguna:
$$ menampilkan $$ R = \ frac {{{N_ {diulang}}}} {{{N_ {berguna}}}} $$ menampilkan $$
Untuk menemukan detektor terbaik, metode simulasi anil digunakan. Sudah ada
artikel bagus tentang Habré tentang dia. Secara singkat, inti dari metode ini adalah sebagai berikut:
- Beberapa solusi awal untuk masalah dipilih (dalam kasus kami, ini adalah semacam pohon detektor).
- Pengulangan dianggap.
- Pohon itu dimodifikasi secara acak.
- Jika versi modifikasi lebih baik dengan kriteria pengulangan, maka modifikasi diterima, dan jika lebih buruk, itu dapat diterima atau tidak, dengan beberapa kemungkinan, yang tergantung pada bilangan real yang disebut "suhu". Saat jumlah iterasi meningkat, suhu turun ke nol.
Selain itu, konstruksi detektor sekarang tidak melibatkan 16 titik lingkaran, seperti sebelumnya, tetapi 47, tetapi artinya tidak berubah sama sekali:

Menurut metode anil simulasi, kami mendefinisikan tiga fungsi:
• Fungsi biaya k. Dalam kasus kami, kami menggunakan pengulangan sebagai nilai. Tapi ada satu masalah. Bayangkan bahwa semua titik pada masing-masing dari dua gambar terdeteksi sebagai tunggal. Kemudian ternyata pengulangan 100% - absurditas. Di sisi lain, bahkan jika kita telah menemukan satu titik tertentu dalam dua gambar, dan titik-titik ini bertepatan - pengulangan juga 100%, tetapi ini juga tidak menarik bagi kita. Dan oleh karena itu, penulis mengusulkan untuk menggunakan ini sebagai kriteria kualitas:
$$ menampilkan $$ k = \ kiri ({1 + {{\ kiri ({\ frac {{{w_r}}} {R}} \ kanan)} ^ 2}} \ kanan) \ kiri ({1 + \ frac {1} {N} \ jumlah \ Limit_ {i = 1} {{{\ kiri ({\ frac {{{d_i}}} {{{w_n}}}} kanan)} ^ 2}}} \ kanan) \ kiri ({1 + {{\ kiri ({\ frac {s} {{{w_s}}}} kanan)} ^ 2}} \ kanan) $$ tampilkan $$
r adalah pengulangan
$ inline $ {{d_i}} $ inline $ Apakah jumlah sudut yang terdeteksi pada frame i, N adalah jumlah frame, dan s adalah ukuran pohon (jumlah simpul). W adalah parameter metode khusus.]
• Fungsi perubahan suhu seiring waktu:
$$ menampilkan $$ T \ kiri (I \ kanan) = \ beta \ exp \ kiri ({- \ frac {{\ alpha I}} {{{I _ {\ max}}}} \ kanan) $$ tampilan $$
dimana
$ inline $ \ alpha, \ beta $ inline $ Apakah koefisien, Imax adalah jumlah iterasi.
• Fungsi yang menghasilkan solusi baru. Algoritma membuat modifikasi acak ke pohon. Pertama, pilih beberapa titik. Jika simpul yang dipilih adalah daun pohon, maka dengan probabilitas yang sama kita lakukan hal berikut:
- Ganti vertex dengan subtree acak dengan kedalaman 1
- Ubah kelas sheet ini (poin singular-nonsingular)
Jika ini BUKAN selembar:
- Ganti jumlah titik yang diuji dengan angka acak dari 0 hingga 47
- Ganti simpul dengan lembar dengan kelas acak
- Tukar dua subtree dari vertex ini
Probabilitas P menerima perubahan pada iterasi I adalah:
$ inline $ P = \ exp \ kiri ({\ frac {{k \ kiri ({i - 1} \ kanan) - k \ kiri (i \ kanan)}} {T}} \ kanan) $ inline $
k adalah fungsi biaya, T adalah suhu, i adalah angka iterasi.
Modifikasi pada pohon ini memungkinkan pertumbuhan pohon dan pengurangannya. Metode ini acak, tidak menjamin bahwa pohon terbaik akan diperoleh. Jalankan metode berkali-kali, pilih solusi terbaik. Dalam artikel asli, misalnya, mereka menjalankan 100 kali per 100.000 iterasi masing-masing, yang membutuhkan waktu prosesor 200 jam. Seperti yang ditunjukkan hasilnya, hasilnya lebih baik daripada Tree FAST, terutama pada gambar yang berisik.
Deskriptor SINGKAT
Setelah titik tunggal ditemukan, deskriptornya dihitung, mis. set fitur yang menandai lingkungan dari setiap titik tunggal. SINGKAT [4] adalah deskriptor heuristik yang cepat, dibangun dari 256 perbandingan biner antara kecerahan piksel dalam gambar
buram . Tes biner antara titik x dan y didefinisikan sebagai berikut:
$$ menampilkan $$ \ tau \ kiri ({P, x, y} \ kanan): = \ kiri \ {{\ begin {array} {* {20} {c}} {1: p \ kiri (x \ kanan) <p \ kiri (y \ kanan)} \\ {0: p \ kiri (x \ kanan) \ ge p \ kiri (y \ kanan)} \ end {array}} \ kanan. $$ display $$

Dalam artikel asli, beberapa metode untuk memilih poin untuk perbandingan biner dipertimbangkan. Ternyata, salah satu cara terbaik adalah memilih titik secara acak menggunakan distribusi Gaussian di sekitar piksel pusat. Urutan titik acak ini dipilih satu kali dan tidak berubah lebih lanjut. Ukuran lingkungan yang dianggap sebagai titik adalah 31x31 piksel, dan aperture blur adalah 5.
Deskriptor biner yang dihasilkan tahan terhadap perubahan pencahayaan, distorsi perspektif, cepat dihitung dan dibandingkan, tetapi sangat tidak stabil terhadap rotasi pada bidang gambar.
ORB - cepat dan efisien
Pengembangan semua ide ini adalah algoritma ORB (Oriented FAST dan Rotated BRIEF) [5], di mana upaya dilakukan untuk meningkatkan kinerja BRIEF selama rotasi gambar. Diusulkan untuk pertama-tama menghitung orientasi titik singular dan kemudian melakukan perbandingan biner sesuai dengan orientasi ini. Algoritma bekerja seperti ini:
1) Poin fitur terdeteksi dengan menggunakan pohon CEPAT cepat pada gambar asli dan dalam beberapa gambar dari piramida gambar kecil.
2) Untuk titik yang terdeteksi, pengukuran Harris dihitung, kandidat dengan nilai rendah pengukuran Harris dibuang.
3) Sudut orientasi titik singular dihitung. Untuk ini, momen kecerahan untuk lingkungan titik singular pertama kali dihitung:
$ inline $ {m_ {pq}} = \ jumlah \ limit_ {x, y} {{x ^ p} {y ^ q} I \ kiri ({x, y} \ kanan)} $ inline $
koordinat x, y - pixel, I - brightness. Dan kemudian sudut orientasi titik singular:
$ inline $ \ theta = {\ rm {atan2}} \ kiri ({{m_ {01}}, {m_ {10}}} \ kanan) $ inline $
Semua ini, penulis menyebutnya "orientasi centroid." Sebagai hasilnya, kami memperoleh arah tertentu untuk lingkungan titik singular.
4) Memiliki sudut orientasi titik singular, urutan titik untuk perbandingan biner dalam deskriptor BRIEF berputar sesuai dengan sudut ini, misalnya:
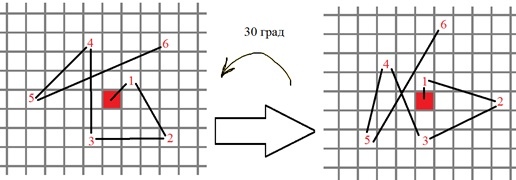
Secara lebih formal, posisi baru untuk titik uji biner dihitung sebagai berikut:
$$ menampilkan $$ \ kiri ({\ begin {array} {* {20} {c}} {{x_i} '} \\ {{y_i}'} \ end {array}} \ kanan) = R \ kiri (\ theta \ kanan) \ cdot \ kiri ({\ begin {array} {* {20} {c}} {{x_i}} \\ {{y_i}} \ end {array}} \ kanan) $$ tampilan $$
5) Berdasarkan poin yang diterima, deskriptor biner SINGKAT dihitung
Dan itu ... tidak semua! Ada detail menarik lainnya di ORB yang membutuhkan penjelasan terpisah. Faktanya adalah bahwa pada saat kita "mengubah" semua titik tunggal ke sudut nol, pilihan acak perbandingan biner dalam deskriptor berhenti menjadi acak. Ini mengarah pada fakta bahwa, pertama, beberapa perbandingan biner ternyata saling bergantung satu sama lain, dan kedua, rata-rata mereka tidak lagi sama dengan 0,5 (1 lebih ringan, 0 lebih gelap ketika pilihannya acak, itu rata-rata 0,5) semua ini secara signifikan mengurangi kemampuan deskriptor untuk membedakan titik tunggal di antara mereka sendiri.
Solusi - Anda perlu memilih tes biner "benar" dalam proses pembelajaran, ide ini meniup rasa yang sama dengan pelatihan pohon untuk algoritma FAST-9. Misalkan kita memiliki banyak titik tunggal yang sudah ditemukan. Pertimbangkan semua opsi yang memungkinkan untuk pengujian biner. Jika lingkungan adalah 31 x 31, dan uji biner adalah sepasang subset 5 x 5 (karena kabur), maka ada banyak pilihan untuk memilih N = (31-5) ^ 2. Algoritma pencarian untuk tes "baik" adalah sebagai berikut:
- Kami menghitung hasil semua tes untuk semua poin tunggal
- Atur seluruh rangkaian tes sesuai dengan jaraknya dari rata-rata 0,5
- Buat daftar yang akan berisi tes "baik" yang dipilih, mari panggil daftar R.
- Tambahkan ke R tes pertama dari set yang diurutkan
- Kami mengambil tes berikutnya dan membandingkannya dengan semua tes dalam R. Jika korelasinya lebih besar dari ambang, maka kami membuang tes baru, jika tidak kami menambahkannya.
- Ulangi langkah 5 hingga kami mengetik jumlah tes yang diperlukan.
Ternyata tes dipilih sehingga, di satu sisi, nilai rata-rata tes ini sedekat mungkin menjadi 0,5, di sisi lain, sehingga korelasi antara tes yang berbeda minimal. Dan inilah yang kami butuhkan. Bandingkan bagaimana itu dan bagaimana jadinya:
Untungnya, algoritma ORB diimplementasikan di perpustakaan OpenCV di kelas cv :: ORB. Saya menggunakan versi 2.4.13. Konstruktor kelas menerima parameter berikut:
nfeatures - jumlah poin singular maksimum
scaleFactor - pengganda untuk piramida gambar, lebih dari satu. Nilai 2 mengimplementasikan piramida klasik.
nlevels - jumlah level dalam piramida gambar.
edgeThreshold - jumlah piksel di batas gambar tempat titik tunggal tidak terdeteksi.
firstLevel - biarkan nol.
WTA_K - jumlah poin yang diperlukan untuk satu elemen deskriptor. Jika sama dengan 2, maka kecerahan dua piksel yang dipilih secara acak dibandingkan. Inilah yang dibutuhkan.
scoreType - jika 0, maka harris digunakan sebagai ukuran fitur, jika tidak - ukuran CEPAT (berdasarkan jumlah moduli dari perbedaan kecerahan pada titik-titik lingkaran). Ukuran FAST sedikit kurang stabil, tetapi lebih cepat.
patchSize - ukuran lingkungan tempat piksel acak dipilih untuk perbandingan. Kode mencari dan membandingkan titik-titik tunggal dalam dua gambar, "templ.bmp" dan "img.bmp"
Kodecv::Mat img_object=cv::imread("templ.bmp", 0); std::vector<cv::KeyPoint> keypoints_object, keypoints_scene; cv::Mat descriptors_object, descriptors_scene; cv::ORB orb(500, 1.2, 4, 31, 0, 2, 0, 31);
Jika seseorang membantu memahami esensi dari algoritma, maka itu tidak sia-sia. Untuk semua Habr.
Referensi:
1.
Fusing Points dan Lines untuk Pelacakan Berkinerja Tinggi2.
Pembelajaran mesin untuk deteksi sudut kecepatan tinggi3.
Lebih cepat dan lebih baik: pendekatan pembelajaran mesin untuk deteksi sudut4.
SINGKAT: Fitur Dasar Biner Independen5.
ORB: alternatif efisien untuk SIFT atau SURF