Setelah membaca artikel “
Terjemahan Mesin Neural Google ”, saya mengingat terjemahan mesin epic-fail terbaru dari Google yang berjalan di Internet akhir-akhir ini. Siapa yang tidak bisa menunggu terlalu lama, kami segera beralih ke bagian bawah artikel.
Sebagai permulaan, sedikit teori:
GNMT adalah sistem Terjemahan Mesin Neural Google (
NMT ) yang menggunakan jaringan saraf (
JST ) untuk meningkatkan akurasi dan kecepatan terjemahan, dan khususnya untuk menciptakan opsi terjemahan yang lebih baik, lebih alami untuk teks dalam Google Translate.
Dalam kasus GNMT, ini disebut metode terjemahan berbasis contoh (
EBMT ), yaitu
JST yang mendasari metode belajar dari jutaan contoh terjemahan, dan tidak seperti sistem lain, metode ini memungkinkan apa yang disebut terjemahan
tanpa-gambar , yaitu menerjemahkan dari satu bahasa ke bahasa lain tanpa contoh-contoh eksplisit untuk pasangan bahasa tertentu ini. dalam proses pembelajaran (dalam sampel pelatihan).
 Fig. 1. Terjemahan Tanpa Potret
Fig. 1. Terjemahan Tanpa PotretSelain itu, GNMT dirancang terutama untuk meningkatkan terjemahan frasa dan kalimat, karena hanya dalam terjemahan kontekstual, Anda tidak dapat menggunakan versi literal terjemahan, dan seringkali kalimat tersebut diterjemahkan dengan sangat berbeda.
Selain itu, kembali ke terjemahan tanpa suntikan, Google mencoba menyoroti beberapa komponen umum yang berlaku untuk beberapa bahasa sekaligus (baik ketika mencari dependensi dan ketika membangun hubungan untuk kalimat dan frasa).
Misalnya, pada Gambar 2, "komunitas" interlingua ini ditampilkan di antara semua pasangan yang memungkinkan untuk bahasa Jepang, Korea, dan Inggris.
 Fig. 2. Interlingua. Presentasi data jaringan 3 dimensi untuk bahasa Jepang, Korea dan Inggris
Fig. 2. Interlingua. Presentasi data jaringan 3 dimensi untuk bahasa Jepang, Korea dan Inggris .
Bagian (a) menunjukkan "geometri" umum dari terjemahan semacam itu, di mana titik-titiknya diwarnai oleh makna (dan warna yang sama untuk makna yang sama dalam beberapa pasangan bahasa).
Bagian (b) menunjukkan peningkatan dalam salah satu kelompok, bagian © dalam warna bahasa aslinya.
GNMT menggunakan pembelajaran mendalam
JST besar (
DNN ), yang, belajar dari jutaan contoh, harus meningkatkan kualitas terjemahan, menerapkan pendekatan abstrak kontekstual untuk opsi terjemahan yang paling cocok. Secara kasar, ia memilih yang terbaik, dalam arti tata bahasa manusia yang paling tepat, hasil, sambil memperhitungkan kesamaan dari tautan bangunan, frasa dan kalimat untuk beberapa bahasa (mis., Secara terpisah menyoroti dan mengajarkan model atau lapisan interlingua).
Namun, DNN, baik dalam proses pembelajaran dan dalam proses kerja, biasanya mengandalkan inferensi statistik (probabilistik) dan jarang terikat oleh algoritma non-probabilistik tambahan. Yaitu Untuk menilai hasil terbaik yang telah keluar dari variator, pilihan terbaik secara statistik (mungkin) akan dipilih.
Semua ini, tentu saja, juga tergantung pada kualitas sampel pelatihan (dan / atau kualitas algoritma dalam hal model pembelajaran mandiri).
Mengingat metode terjemahan tanpa-tembakan dan mengingat beberapa komponen umum (interlingua), di hadapan beberapa koneksi logis yang dalam untuk satu bahasa, dan tidak adanya komponen negatif untuk bahasa lain, beberapa kesalahan abstrak muncul dalam proses pembelajaran dan, sebagai hasilnya, terjemahan frasa tertentu untuk satu bahasa kemungkinan besar akan diulang untuk bahasa lain atau bahkan pasangan bahasa.
Sebenarnya epik baru gagal
Semua gambar dapat diklik (sebagai bukti pada halaman Google Translate yang sesuai).Jerman: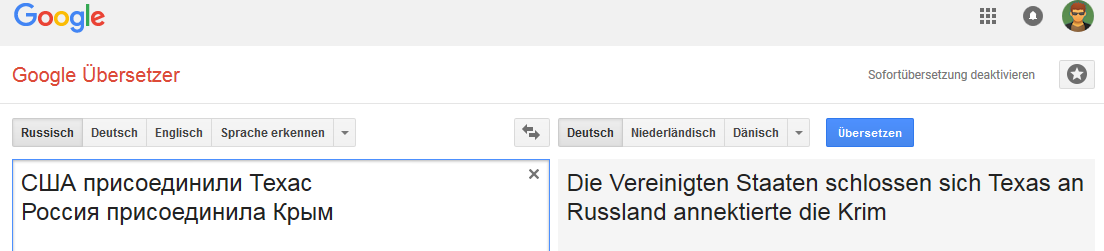 Inggris:
Inggris: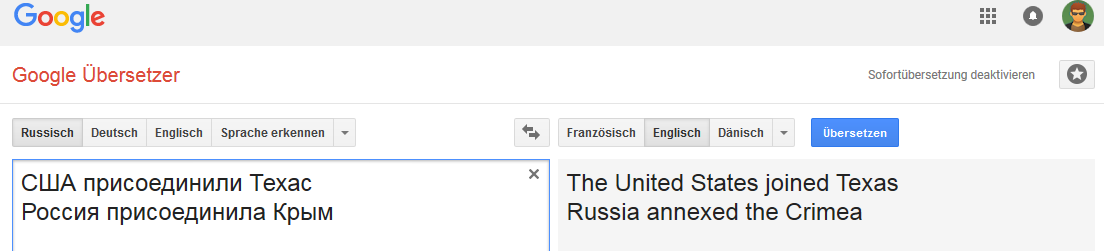 Belanda:
Belanda: Denmark:
Denmark: Prancis:
Prancis:
Dll
Alih-alih sebuah kesimpulan
Koneksi stabil untuk kata Rusia (dalam arti bahwa ketika Rusia diganti, misalnya, oleh Kekaisaran Rusia, opsi "transfer" berubah).
Dan itu tidak terlalu stabil dengan perubahan-perubahan tertentu pada frasa yang tidak khas untuk diterjemahkan ke dalam bahasa Inggris, tetapi umum, misalnya, untuk Rusia, Jerman dan Belanda.
Sayangnya ini jauh dari satu-satunya kasus dan Internet penuh dengan semua jenis kesalahan Google Terjemahan.
Dan bagi saya kelihatannya sebagian besar kesalahan yang ada dimanifestasikan karena kombinasi beberapa faktor, mulai dari kualitas sampel pelatihan hingga kualitas algoritma analisis semantik dan morfologi untuk bahasa tertentu (dan model pembelajaran khususnya).
Suatu hari, seorang kolega menyarankan untuk berpartisipasi dalam Tantangan Normalisasi Teks Google (untuk bahasa Rusia dan Inggris) di ...
Sebelum menyetujui, saya kemudian melakukan analisis kecil terhadap kualitas sampel uji pelatihan untuk semua kelas token untuk kedua bahasa ... dan sebagai hasilnya saya menolak untuk berpartisipasi sama sekali, karena semakin saya gali, semakin kuat perasaan bahwa kompetisi akan seperti lotre atau orang yang menang akan menang paling akurat akan mampu mengulangi semua kesalahan yang dibuat selama pembuatan semi-manual set pelatihan Google.
Saya bahkan ingin menulis artikel dengan topik "Cara mudah melempar 50K ...", tetapi waktu - baiklah.
Jika ada yang tiba-tiba tertarik - saya akan mencoba mengukir sedikit.
[UPD] Kenapa ini sebenarnya file. Tanpa terganggu oleh lirik, subteks "politik" dan segala macam upaya untuk membenarkan "seseorang akan menerjemahkan dengan cara ini", dll topik.
1. Ini adalah terjemahan yang salah. Intinya.
2. Dalam kasus ilustratif ini, GNMT menunjukkan tidak adanya model klasifikasi apa pun (dalam arti
CADM , di mana Google harus bersinar, karena mereka memiliki banyak data dari mana-mana). Sejauh subjek dalam kedua kasus adalah negara / negara bagian, dan pelengkapnya adalah entitas geografis (wilayah).
Bahkan aturan masuk akal paling bodoh dari beberapa klasifikasi K-nn fuzzy tidak akan pernah membuat kesalahan seperti itu. Kami sudah diam tentang algoritma modern untuk klasifikasi dan pembangunan hubungan (semantik).
Seperti kata pepatah pribadi, matematika sederhana ... Ya, jika Google memutuskan secara membabi buta untuk memberi makan jaringannya dengan kliping dari pers tabloid, maka saya punya berita buruk untuknya.
PS Namun, sebagai seorang profesor, saya menghormati suatu ketika berkata kepada saya, "Kadang-kadang sangat sulit untuk membuktikan burung pelatuk bahwa ia burung pelatuk, terutama jika ia yakin bahwa ia lebih pintar daripada seorang profesor."