
Halo, Habr! Nama saya Alexey Pristavko, saya direktur proyek web di DataLine. Artikel saya hari ini adalah tentang cara memperbaiki atau mencegah masalah kinerja backend aplikasi web.
Ini akan fokus pada bagaimana mengoptimalkan aplikasi web yang menderita masalah kronis dengan skalabilitas, kinerja, atau keandalan.
Siapa pun yang tertarik - selamat datang di bawah luka!
Terminologi
Mari kita mulai dengan melihat terminologi. Berbicara tentang kinerja proyek web atau sistem web, yang saya maksud adalah komponen back-end dan server. Apa yang terjadi ketika memuat halaman di browser adalah cerita yang sama sekali berbeda, yang, kemungkinan besar, akan dikhususkan untuk artikel terpisah.
- Ukuran kinerja aplikasi akan menjadi jumlah permintaan yang diproses per detik (RPS) dan kecepatan eksekusi (TTFB - Time to First Byte).
- Oleh karena itu, dengan skalabilitas sistem yang kami maksud adalah kumpulan peluang untuk meningkatkan RPS.
Sekarang soal reliabilitas. Di sini perlu untuk memisahkan dua konsep: toleransi kesalahan dan toleransi bencana.
- Ketahanan Kegagalan - kemampuan suatu sistem untuk gagal jika satu atau lebih server gagal untuk terus bekerja dalam parameter yang diperlukan.
- Sistem dengan cadangan cadangan penuh (disebut bahu kedua) dan mampu bekerja tanpa drawdown yang kuat dengan kegagalan total salah satu pusat data dianggap tahan bencana .
Pada saat yang sama, sistem yang tahan bencana adalah sistem yang gagal-aman. Situasi di mana sistem yang toleran terhadap bencana, tetapi bukan sistem yang tahan terhadap kesalahan terus bekerja hanya pada satu "bahu" yang cukup normal. Tetapi jika salah satu server gagal, sistem juga akan gagal.
Sekarang kita telah menemukan konsep-konsep kunci dan menyegarkan terminologi saat ini, saatnya untuk pindah langsung ke dasar-dasar optimasi dan peretasan kehidupan.
Di mana memulai optimasi

Bagaimana cara memahami di mana memulai optimasi? Sebelum Anda terburu-buru untuk mengoptimalkan, ambil napas dalam-dalam dan habiskan waktu untuk meneliti aplikasi.
Pastikan untuk menggambar diagram terperinci. Tampilkan semua komponen aplikasi dan hubungannya. Setelah memeriksa skema ini, Anda dapat menemukan kerentanan yang sebelumnya tidak mencolok dan kemungkinan titik kegagalan.
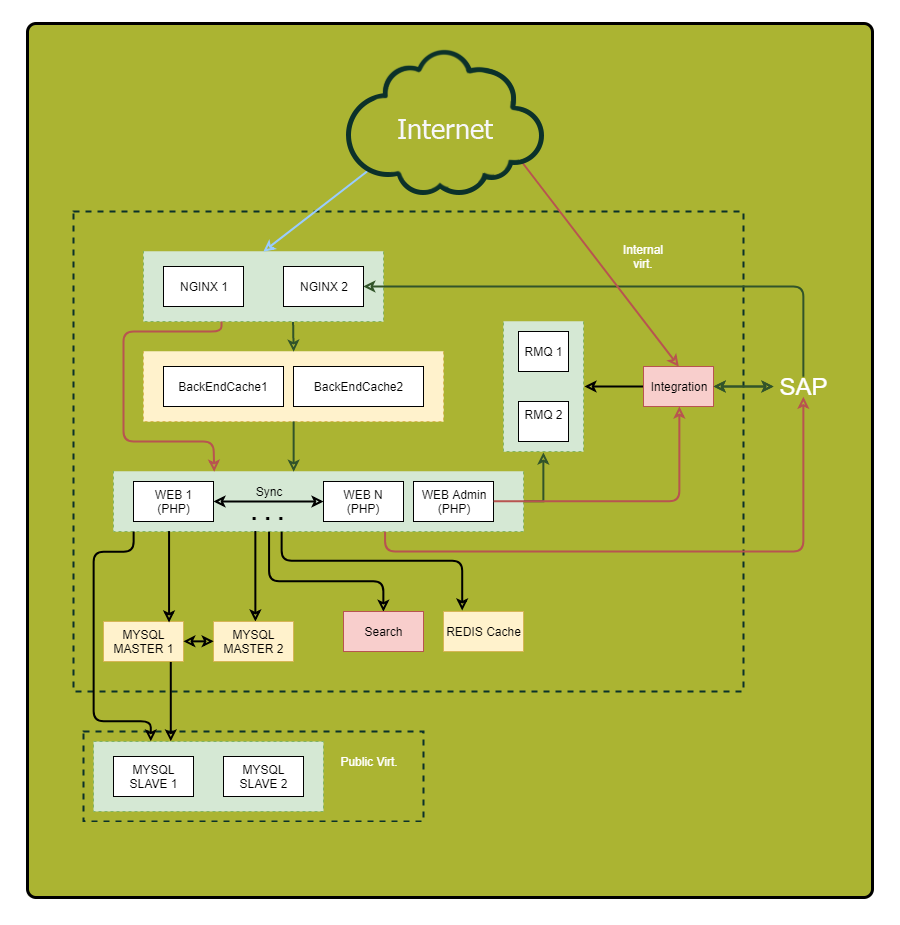
"Apa? Dimana? Kapan? ” - mengoptimalkan kueri
Berikan perhatian khusus pada permintaan sinkron. Biarkan saya mengingatkan Anda, ini adalah permintaan seperti itu ketika kami mengirim permintaan di utas yang sama dan menunggu tanggapan di atasnya. Di sinilah alasan untuk rem serius terletak ketika ada yang salah di sisi lain. Oleh karena itu, jika Anda dapat mengurangi jumlah permintaan sinkron atau menggantinya dengan yang tidak sinkron, lakukanlah.
Berikut adalah beberapa trik untuk membantu Anda melacak permintaan Anda:
- Tetapkan pengidentifikasi unik untuk setiap permintaan yang masuk. Nginx memiliki variabel $ request_id bawaan untuk ini. Lewati pengidentifikasi di header di bagian belakang dan tulis ke semua log. Jadi, Anda dapat dengan mudah melacak permintaan.
- Log tidak hanya akhir permintaan ke komponen eksternal, tetapi juga permulaannya. Jadi, Anda mengukur durasi panggilan eksternal yang sebenarnya. Ini bisa sangat berbeda dari apa yang Anda lihat di sistem jarak jauh, misalnya, karena masalah jaringan atau rem DNS.
Jadi, data dikumpulkan. Sekarang mari kita menganalisis poin masalah. Definisikan:
- Di mana waktu paling banyak dihabiskan?
- Dari mana datangnya sebagian besar permintaan?
- Dari mana permintaan terlama datang?
Sebagai hasilnya, Anda akan mendapatkan daftar bagian yang paling menarik dari sistem untuk optimasi.
Kiat: Jika ada titik "mengumpulkan" banyak kueri kecil, coba gabungkan menjadi satu kueri besar untuk mengurangi overhead. Hasil kueri panjang sering kali masuk akal di cache.
Kami melakukan cache dengan bijak
Ada aturan caching umum yang harus Anda andalkan saat mengoptimalkan:
- Semakin dekat cache ke konsumen, semakin cepat pekerjaannya. Untuk aplikasi, tempat "terdekat" adalah RAM. Untuk pengguna, browser-nya.
- Caching mempercepat akuisisi data dan mengurangi beban pada sumber.
Jika sepuluh server web membuat kueri basis data yang sama, cache perantara terpusat, misalnya di Redis, akan memberikan persentase klik yang lebih tinggi (dibandingkan dengan cache lokal) dan mengurangi beban keseluruhan pada basis data, yang secara signifikan akan meningkatkan gambaran keseluruhan.
Tips 1: Lakukan caching komponen pada halaman yang selesai di sisi Nginx menggunakan Edge Side Include. Ini cocok dengan arsitektur microservice / SOA dan membongkar sistem secara keseluruhan, sangat meningkatkan kecepatan respons.
Tip 2: Melacak ukuran objek dalam cache, hit ratio, dan volume tulis / baca. Semakin besar objek, semakin lama prosesnya. Jika Anda menulis ke cache lebih sering atau lebih banyak daripada yang Anda baca, cache seperti itu bukan teman Anda. Ada baiknya menghapus atau berpikir tentang meningkatkan efektivitasnya.
Tip 3: Gunakan cache basis data Anda sendiri jika memungkinkan. Konfigurasi yang tepat dapat mempercepat pekerjaan.
Muat profil
Kami lolos memuat profil. Seperti yang Anda ketahui, ada dua jenis utama: OLAP dan OLTP.
- Untuk OLAP (Pemrosesan Analitik Daring), jumlah lalu lintas yang dihabiskan per detik adalah penting.
- Untuk OLTP (Pemrosesan Transaksi Online), indikator utamanya adalah kecepatan respons, waktu milidetik.
Paling sering, efektif untuk memisahkan kedua jenis beban ini. Minimal, Anda akan memerlukan penyetelan terpisah dari basis data dan, mungkin, komponen lain dari sistem.
Tip: Membaca permintaan dari panel admin biasanya diproses menggunakan tipe OLAP. Buat salinan terpisah dari database dan server web untuk tugas ini untuk membongkar sistem utama.
Basis data

Jadi, kami secara alami mendekati salah satu tahap paling sulit dari optimasi - yaitu, optimasi database.
Biarkan saya mengingatkan Anda tentang aturan umum: semakin kecil basis data, semakin cepat kerjanya. Organisasi basis data sangat penting dalam hal kecepatan.
Jika memungkinkan, simpan
data historis , log aplikasi, dan data yang
sering digunakan di berbagai basis data. Lebih baik lagi, mempostingnya di server yang berbeda. Ini tidak hanya akan memudahkan umur basis data utama, tetapi juga memberikan lebih banyak ruang untuk optimasi lebih lanjut, misalnya, dalam beberapa kasus akan memungkinkan penggunaan indeks yang berbeda untuk beban yang berbeda. Juga, "keseragaman" dari beban menyederhanakan kehidupan penjadwal dan pengoptimal permintaan server database.
Dan lagi tentang pentingnya perencanaan
Agar tidak memikirkan optimasi yang sebenarnya tidak diperlukan, pilih perangkat keras berdasarkan tugas.
- Untuk permintaan kecil tapi sering, lebih baik mengambil lebih banyak core prosesor.
- Untuk permintaan berat - core lebih sedikit dengan kecepatan clock lebih tinggi.
Cobalah untuk memasukkan volume kerja database ke dalam RAM. Jika ini tidak memungkinkan atau ada sejumlah besar permintaan penulisan, saatnya untuk melihat ke arah mentransfer database ke SSD. Mereka akan memberikan peningkatan yang signifikan dalam kecepatan bekerja dengan disk.
Scaling

Di atas, saya menggambarkan mekanisme utama untuk meningkatkan kinerja aplikasi tanpa meningkatkan sumber daya fisiknya.
Sekarang kita akan berbicara tentang bagaimana memilih strategi penskalaan dan meningkatkan ketahanan.
Ada dua jenis penskalaan sistem:
- vertikal - pertumbuhan sumber daya sambil mempertahankan jumlah entitas;
- horisontal - peningkatan jumlah entitas.
Tumbuh tinggi
Mari kita mulai dengan memilih strategi penskalaan vertikal.
Pertama, pertimbangkan
peningkatan daya sistem . Jika sistem Anda bekerja dalam satu server, Anda harus membuat pilihan antara meningkatkan kapasitas server saat ini atau membeli yang lain.
Tampaknya opsi pertama lebih mudah dan aman. Tetapi akan jauh lebih jauh untuk membeli satu server lagi dan menerima toleransi kesalahan yang besar sebagai bonus terhadap produktivitas. Saya membicarakan hal ini di awal artikel.
Jika sistem Anda memiliki beberapa server dan pilihannya adalah untuk meningkatkan kapasitas yang sudah ada atau membeli lebih banyak lagi, perhatikan sisi keuangannya. Sebagai contoh, satu server yang kuat mungkin lebih mahal daripada dua "lemah" 50%. Oleh karena itu, masuk akal untuk memikirkan opsi kompromi kedua. Pada saat yang sama, dengan sejumlah besar server, rasio kinerja, konsumsi daya dan biaya rak penuh sangat penting.
Tumbuh lebar
Penskalaan horizontal adalah cerita tentang toleransi kesalahan dan pengelompokan. Dalam kasus umum, semakin banyak contoh dari satu entitas yang kita miliki, semakin tinggi toleransi kesalahan dari seluruh solusi.
Mungkin hal pertama yang Anda ingin skala adalah
server aplikasi . Kendala pertama untuk ini adalah organisasi kerja dengan sumber data terpusat. Selain database, itu juga data sesi dan konten statis. Inilah yang saya sarankan Anda lakukan:
- Untuk menyimpan sesi, gunakan Couchbase, bukan Memcached biasa, karena ia bekerja dengan protokol yang sama, tetapi, tidak seperti memcached, ia mendukung pengelompokan.
- Semua statika , terutama gambar dan dokumen dalam volume besar, disimpan secara terpisah dan disajikan menggunakan Nginx, dan bukan dari kode aplikasi. Ini akan menghemat uang Anda pada arus dan menyederhanakan manajemen infrastruktur.
"Menarik" database
Sulit untuk skala basis data. Ada dua teknik utama untuk ini: sharding dan replikasi. Pertimbangkan mereka.
Selama
replikasi, kami menambahkan salinan yang benar-benar identik dari database ke sistem, sementara pecahan, bagian yang terpisah secara logis, pecahan. Pada saat yang sama, sangat diinginkan untuk melakukan sharding secara paralel dengan replikasi (replikasi) dari setiap shard agar tidak kehilangan toleransi kesalahan.
Ingat: sering sebuah kluster basis data terdiri dari satu simpul master yang mengambil alih aliran tulis dan beberapa simpul budak yang digunakan untuk membaca. Dari sudut pandang toleransi kesalahan, ini sedikit lebih baik daripada server tunggal, karena toleransi kesalahan keseluruhan ditentukan oleh elemen sistem yang paling tidak stabil.
Skema dengan lebih dari dua penyihir basis data (topologi cincin) tanpa mengonfirmasi catatan pada setiap server, sangat sering mengalami inkonsistensi. Jika terjadi kegagalan pada salah satu server, akan sangat sulit untuk mengembalikan integritas logis dari data di cluster.
Kiat: Jika dalam kasus Anda tidak rasional untuk memiliki beberapa server master, pertimbangkan kemungkinan arsitektural dari sistem yang bekerja tanpa master setidaknya selama satu jam. Jika terjadi kecelakaan, ini akan memberi Anda waktu untuk mengganti server tanpa downtime seluruh sistem.
Kiat: Jika Anda perlu menyimpan lebih dari 2 penyihir basis data, saya sarankan Anda mempertimbangkan solusi NoSQL, karena banyak dari mereka memiliki mekanisme bawaan untuk membawa data ke keadaan yang konsisten.
Dalam mengejar toleransi kesalahan, jangan lupa bahwa replikasi menjamin Anda
hanya terhadap kegagalan server fisik . Itu tidak akan menyimpan dari korupsi data logis karena kesalahan pengguna.
Ingat: Setiap data penting harus dicadangkan dan disimpan sebagai salinan independen yang tidak dapat diedit.
Alih-alih sebuah kesimpulan
Terakhir, beberapa tips kinerja untuk membuat cadangan:
Tips 1: Tarik data dari replika database terpisah sehingga Anda tidak membebani server aktif.
Kiat 2: Dapatkan replika basis data waktu, sedikit "tertinggal". Jika terjadi kecelakaan, ini akan membantu mengurangi jumlah data yang hilang.
Metode dan teknik yang disajikan dalam artikel ini tidak boleh digunakan secara membabi buta, tanpa menganalisis situasi saat ini dan memahami apa yang ingin Anda capai. Anda mungkin mengalami "optimasi berlebihan", dan sistem yang dihasilkan hanya 10% lebih cepat, tetapi 50% lebih rentan terhadap kecelakaan.
Itu saja. Jika Anda memiliki pertanyaan, saya akan dengan senang hati menjawabnya di komentar.