Kami melanjutkan topik, yang mulai dipertimbangkan di bagian
pertama . Hari ini kita akan berbicara tentang koneksi jaringan dan server target, menyajikan opsi yang memungkinkan dan opsi perencanaan infrastruktur untuk pemulihan optimal dari VM Pemulihan Instan. Jadi selamat datang di kucing.
Tentang koneksi jaringan
Tentu saja, ada baiknya memiliki saluran dengan bandwidth 10 Gbit / dtk, melalui mana data ditransfer selama pencadangan. Namun, saluran lebih sederhana untuk dipulihkan dari cadangan, tetapi disarankan untuk menggunakan NIC yang bekerja sama dengan LACP atau SMB Multichannel, atau beberapa opsi lain dengan agregasi bandwidth. Anda dapat menggunakan, misalnya, port LOM dalam versi 4x1 Gbit / s. Konfigurasi ini direkomendasikan untuk koneksi "beberapa perangkat sumber - 1 perangkat cadangan target", yaitu, saat menghubungkan "banyak ke satu". (Demikian juga, pemulihan paralel dari satu penyimpanan cadangan ke perangkat target - sebagai suatu peraturan, ini adalah yang pertama yang sama dengan yang dilakukan pencadangan - adalah koneksi satu-ke-banyak.)
Misalnya, Anda dapat mengonfigurasi beberapa pekerjaan cadangan dari beberapa host Hyper-V / LUN dan menyimpan cadangan ke penyimpanan target yang sama. Jika Anda memiliki 10 host seperti itu dengan bandwidth saluran total 4x1 Gbit / s, maka jika Anda memiliki pipa 10Gbit / s pada perangkat target, ini merupakan konfigurasi yang cukup memadai.
Dalam kasus ketika penyimpanan cadangan adalah bagian SMB, multichannel berfungsi dengan sangat baik (dapat ditambah oleh SMB Direct jika Anda memiliki NIC dengan dukungan RDMA yang dikonfigurasi). Kemampuan ini sekarang didukung di banyak penyebaran cluster Hyper-V. Namun, komponen solusi Veeam yang bertanggung jawab untuk penggerak data dapat menggunakan SMB Multichannel dan SMB Direct (sekali lagi, dengan NIC yang dikonfigurasi dengan dukungan RDMA) hanya dalam skenario ketika Anda menggunakan VM yang disimpan pada berbagi File SMB untuk dicadangkan. proxy di luar host. Veeam Data Mover ini bekerja masing-masing pada proksi cadangan di luar host dan di repositori. Skenario seperti itu dijelaskan secara rinci di
sini .
Poin penting lainnya: saat menggunakan Windows NIC bekerja sama dalam
mode Independen , transfer data diperbolehkan dari semua peserta, dan hanya menerima dari satu peserta. Jika Anda ingin mendapatkan throughput yang optimal di kedua arah untuk satu proses, maka Anda tidak perlu menggunakan LACP. Tetapi dalam hal ini, Anda perlu memastikan bahwa beberapa restorasi dilakukan pada host yang sama.
Seperti yang Anda lihat, agregasi bandwidth memiliki sejumlah batasan dan tidak sepenuhnya identik dengan memiliki satu saluran yang baik. Dalam kasus apa pun, Anda perlu membangun skenario penggunaan yang direncanakan.
Meringkas: tergantung pada infrastruktur Anda, Anda dapat menggunakan Windows NIC timing dalam LACP atau Beralih mode Independen / mode Multichannel SMB. Opsi terakhir berguna jika Anda bekerja dengan berbagi file SMB dan ingin menggunakan SMB Direct (jangan lupa tentang fitur pekerjaan yang disebutkan di atas).
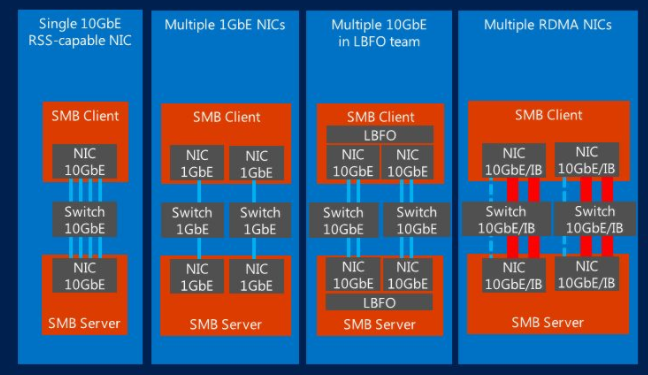
Bandwidth tinggi dan latensi rendah diperlukan untuk memberikan kinerja terbaik selama pemasangan disk virtual, saat mengakses dan menyalin data selama Pemulihan VM Instan.
Anda dapat melakukan beberapa operasi pemulihan secara bersamaan dan masih tidak menghentikan pekerjaan pencadangan. Sekali lagi, di hadapan saluran yang layak, peran utama dimainkan oleh sumber daya komputasi dan penyimpanan. Jika semua ini dirancang dengan benar untuk cadangan, maka pemulihan akan efektif.
Rekomendasi untuk perangkat target
Pertimbangkan beberapa opsi, yang mana, sangat mungkin, Anda akan memilih yang terbaik untuk diri Anda sendiri.
Opsi 1: Pulihkan ke host Hyper-V dan langsung ke LUN di infrastruktur produksi
Bahkan jika Anda memiliki sistem penyimpanan berkinerja tinggi dengan cache baca / tulis atau level 1 yang dikonfigurasi, maka, seperti yang disebutkan
dalam posting sebelumnya , Anda harus berhati-hati untuk tidak meluap. Jika tidak, VM produksi akan terpengaruh. Dan ini bisa terjadi, misalnya, jika Anda mencoba menulis data dalam jumlah besar ke sistem penyimpanan secepat mungkin - ini terjadi ketika memigrasi sistem penyimpanan. Dalam operasi semacam itu, kami mencoba menghindari penggunaan sistem penyimpanan level 1. Pertimbangan serupa berlaku untuk pemulihan VM besar.
Anda dapat merekomendasikan memulihkan ke LUN terpisah dengan profil yang berbeda. VM yang dipulihkan kemudian dapat dimigrasi secara perlahan ke CSV produksi. Untuk memastikan ketersediaan tinggi, Anda dapat menggunakan cluster menggunakan migrasi migrasi penyimpanan ("migrasi migrasi" fungsi). Secara alami, Anda perlu fokus pada kinerja array penyimpanan Anda.
Opsi 2: Pemulihan ke host Hyper-V dengan drive SSD / NMVe lokal
Skenario pemulihan lain dalam produksi, cukup efektif: menggunakan host Hyper-V dari penyimpanan lokal ke SSD atau NVMe. Ukuran ruang disk tergantung pada berapa banyak VM yang ingin Anda pulihkan selama periode waktu tertentu dan seberapa besar VM ini.
Secara teori, Anda tidak perlu mengembalikan semua orang dan segalanya, sehingga konfigurasi ini harus cukup ekonomis. Misalnya, Anda dapat menggunakan satu SSD di masing-masing node cluster, atau hanya dalam beberapa, atau secara umum hanya dalam satu. Semakin banyak SSD / NVMe yang Anda gunakan, semakin banyak anggaran mereka, dengan tetap mempertahankan distribusi beban yang cukup efisien di seluruh host. Pada tahap akhir prosedur pemulihan instan, mesin virtual dapat dengan mudah ditransfer ke CSV produksi, menggunakan fungsionalitas migrasi langsung Storage yang sama.
Diagram menunjukkan opsi perencanaan infrastruktur. Tentu saja, Anda dapat menggabungkan pendekatan di atas sesuai kebijaksanaan Anda.
Opsi 3: Pulihkan ke host Hyper-V khusus dengan drive SSD / NVMe lokal
Dalam opsi ini, kami mengalokasikan satu atau lebih host secara khusus untuk mendukung pemulihan. Ini menghindari kemungkinan kekurangan sumber daya dan dampak pada operasi host produksi di cluster. Anda dapat menggunakan drive NVMe. Kami menyarankan Anda menguji kemampuan pemulihan dalam konfigurasi ini sebelumnya untuk memahami bagaimana sumber daya habis.
Jika Anda berencana untuk meningkatkan konsumsinya, maka untuk migrasi akhir dari mesin rekondisi ke dalam produksi, Anda dapat menggunakan migrasi yang disebut tanpa berbagi sumber daya. (Untuk ini, Anda harus mengatur pengaturan keamanan tambahan.) Adapun sumber daya jaringan, Anda dapat menggunakan, misalnya, kemampuan SMB Multichannel dan SMB Direct untuk migrasi ke CSV / Live Migration / S2D Hyper-V.
Ya, migrasi sistem penyimpanan (Migrasi penyimpanan penyimpanan) bukan proses tercepat, ini minus. Tetapi ada nilai tambah - mesin virtual Anda dipulihkan dan terus bekerja selama proses ini.
Kesimpulannya
Tentu saja, semua orang memilih opsi yang disukai tergantung pada apa yang menjadi hambatan dalam infrastruktur tertentu (server sumber, server target, sumber daya jaringan). Selain itu, sangat mungkin bahwa studi yang cermat akan diperlukan hanya untuk merencanakan pemulihan VM paling kritis atau bagi konsumen yang membayar layanan tersebut.
Bagaimanapun, tujuan utama akan selalu menjadi pemulihan tercepat yang mungkin.
Setelah itu, sudah dimungkinkan untuk bermigrasi dengan aman ke sistem penyimpanan cluster, memastikan ketersediaan tinggi dan toleransi kesalahan. Dan, tentu saja, mesin virtual harus dilindungi dalam bentuk replikasi \ cadangan jika mereka perlu dikembalikan lagi di beberapa titik.
Apa lagi yang harus dibaca: