Pada festival data 2 di Minsk, Vladimir Iglovikov, insinyur visi mesin di Lyft, dengan
sempurna mengatakan bahwa cara terbaik untuk mempelajari Ilmu Data adalah dengan berpartisipasi dalam kompetisi, menjalankan solusi orang lain, menggabungkannya, mencapai hasil dan menunjukkan pekerjaan Anda. Sebenarnya, dalam kerangka paradigma ini, saya memutuskan untuk melihat lebih dekat pada
kompetisi penilaian risiko kredit Home Credit dan menjelaskan (kepada para pemula, Ilmuwan, dan pertama-tama kepada diri saya sendiri) bagaimana menganalisis dengan benar set data tersebut dan membuat model untuk mereka.
(gambar
dari sini )

Home Credit Group adalah sekelompok bank dan organisasi kredit non-bank yang melakukan operasi di 11 negara (termasuk Rusia sebagai Home Credit dan Finance Bank LLC). Tujuan dari kompetisi adalah untuk menciptakan metodologi untuk menilai kelayakan kredit dari peminjam yang tidak memiliki sejarah kredit. Yang terlihat agak mulia - peminjam dari kategori ini sering tidak dapat memperoleh kredit dari bank dan dipaksa untuk beralih ke scammers dan pinjaman mikro. Sangat menarik bahwa pelanggan tidak menetapkan persyaratan untuk transparansi dan interpretabilitas model (seperti yang biasanya terjadi pada bank), Anda dapat menggunakan apa pun, bahkan jaringan saraf.
Sampel pelatihan terdiri dari 300+ ribu catatan, ada cukup banyak tanda - 122, di antaranya ada banyak yang kategorikal (non-numerik). Tanda-tanda menggambarkan peminjam dengan cukup rinci, sampai ke bahan dari mana dinding rumahnya dibuat. Bagian dari data terkandung dalam 6 tabel tambahan (data pada biro kredit, saldo kartu kredit dan pinjaman sebelumnya), data ini juga harus diproses entah bagaimana dan dimuat ke yang utama.
Persaingan terlihat seperti tugas klasifikasi standar (1 di bidang TARGET berarti kesulitan dengan pembayaran, 0 berarti tidak ada kesulitan). Namun, bukan 0/1 yang harus diprediksi, tetapi probabilitas masalah (yang, secara kebetulan, dapat dengan mudah dipecahkan dengan metode prediksi probabilitas predict_proba yang dimiliki semua model kompleks).
Pada pandangan pertama, dataset ini cukup standar untuk tugas pembelajaran mesin, panitia menawarkan hadiah besar $ 70k, sebagai hasilnya, lebih dari 2.600 tim berpartisipasi dalam kompetisi hari ini, dan pertarungannya dalam seperseribu persen. Namun, di sisi lain, popularitas seperti itu berarti bahwa dataset telah diperiksa atas dan ke bawah dan banyak kernel telah dibuat dengan EDA yang baik (Analisis Data Eksplorasi - penelitian dan analisis data dalam jaringan, termasuk grafis), rekayasa fitur (bekerja dengan atribut) dan dengan model yang menarik. (Kernel adalah contoh bekerja dengan dataset yang dapat ditata siapa saja untuk menunjukkan hasil kerjanya kepada kuggler lain.)
Kernel layak mendapat perhatian:
Untuk bekerja dengan data, rencana berikut ini biasanya disarankan, yang akan kami coba ikuti.
- Memahami masalah dan berkenalan dengan data
- Pembersihan dan pemformatan data
- EDA
- Model dasar
- Perbaikan Model
- Model interpretasi
Dalam hal ini, Anda perlu mempertimbangkan fakta bahwa data tersebut cukup luas dan tidak dapat dikalahkan segera, masuk akal untuk bertindak secara bertahap.
Mari kita mulai dengan mengimpor perpustakaan yang kita butuhkan dalam analisis untuk bekerja dengan data dalam bentuk tabel, membuat grafik, dan bekerja dengan matriks.
import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns %matplotlib inline
Unduh datanya. Mari kita lihat apa yang kita semua miliki. Lokasi ini di direktori "../input/", omong-omong, terhubung dengan persyaratan untuk meletakkan kernel Anda di Kaggle.
import os PATH="../input/" print(os.listdir(PATH))
['application_test.csv', 'application_train.csv', 'bureau.csv', 'bureau_balance.csv', 'credit_card_balance.csv', 'HomeCredit_columns_description.csv', 'installments_payments.csv', 'POS_CASH_balance.csv', 'previous_application.csv']Ada 8 tabel dengan data (tidak termasuk tabel HomeCredit_columns_description.csv, yang berisi deskripsi bidang), yang saling berhubungan sebagai berikut:
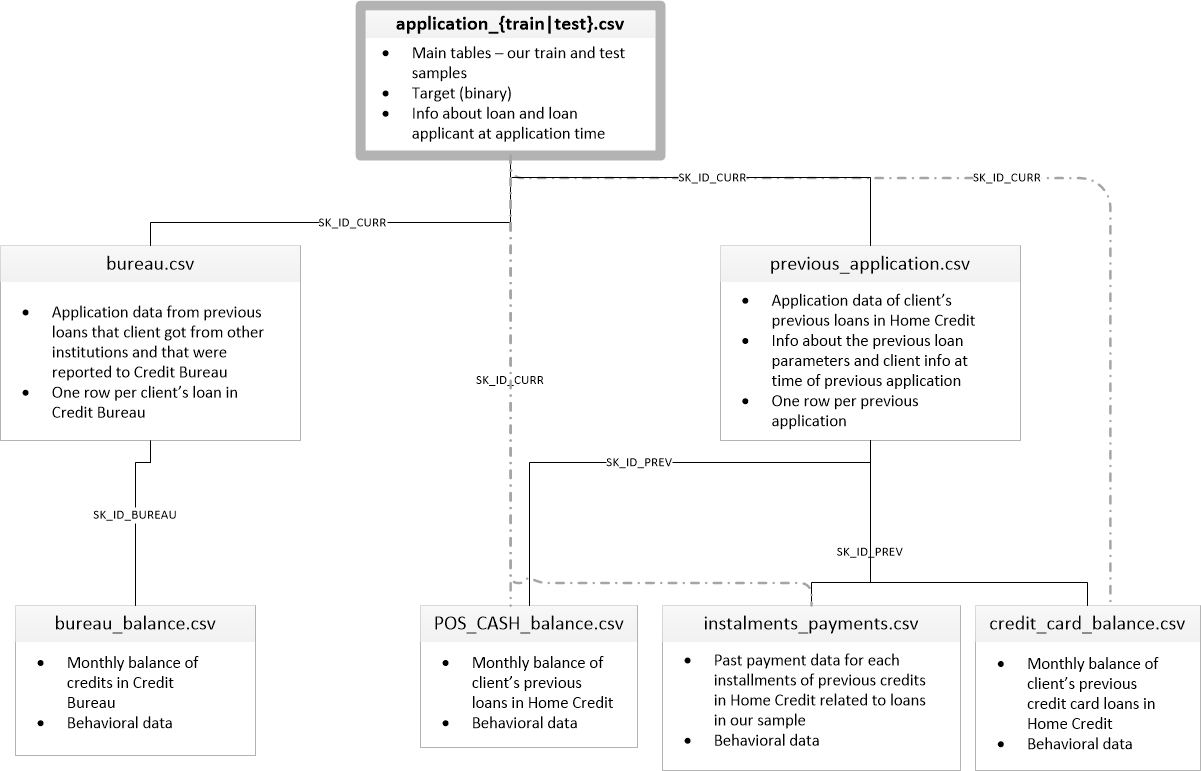
application_train / application_test: Data master, peminjam diidentifikasi oleh bidang SK_ID_CURR
biro: Data pinjaman sebelumnya dari lembaga kredit lain dari biro kredit
bureau_balance: Data bulanan tentang pinjaman biro sebelumnya. Setiap baris adalah bulan menggunakan pinjaman
Aplikasi sebelumnya: Aplikasi sebelumnya untuk pinjaman Kredit Rumah, masing-masing memiliki bidang unik SK_ID_PREV
POS_CASH_BALANCE: Data bulanan tentang pinjaman dalam Home Credit dengan penerbitan uang tunai dan pinjaman untuk pembelian barang
credit_card_balance: Data saldo kartu kredit bulanan di Home Credit
installments_payment: Riwayat pembayaran pinjaman sebelumnya di Home Credit.
Pertama-tama, mari kita fokus pada sumber data utama dan melihat informasi apa yang dapat diekstrak darinya dan model mana yang akan dibangun. Unduh data dasar.
- app_train = pd.read_csv (PATH + 'application_train.csv',)
- app_test = pd.read_csv (PATH + 'application_test.csv',)
- print ("format set pelatihan:", app_train.shape)
- print ("format sampel uji:", app_test.shape)
- format sampel pelatihan: (307511, 122)
- format sampel uji: (48744, 121)
Secara total, kami memiliki 307 ribu catatan dan 122 tanda dalam sampel pelatihan dan 49 ribu catatan dan 121 tanda dalam tes. Perbedaan ini jelas disebabkan oleh fakta bahwa tidak ada atribut target TARGET dalam sampel uji, dan kami akan memprediksinya.
Mari kita lihat lebih dekat data
pd.set_option('display.max_columns', None)
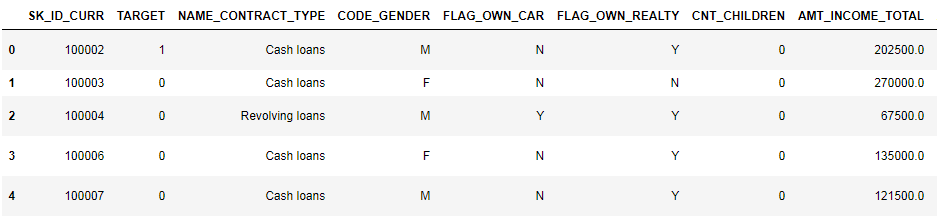
(8 kolom pertama ditampilkan)
Sangat sulit untuk menonton data dalam format ini. Mari kita lihat daftar kolom:
app_train.info(max_cols=122)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entries, 0 to 307510
Data columns (total 122 columns):
SK_ID_CURR 307511 non-null int64
TARGET 307511 non-null int64
NAME_CONTRACT_TYPE 307511 non-null object
CODE_GENDER 307511 non-null object
FLAG_OWN_CAR 307511 non-null object
FLAG_OWN_REALTY 307511 non-null object
CNT_CHILDREN 307511 non-null int64
AMT_INCOME_TOTAL 307511 non-null float64
AMT_CREDIT 307511 non-null float64
AMT_ANNUITY 307499 non-null float64
AMT_GOODS_PRICE 307233 non-null float64
NAME_TYPE_SUITE 306219 non-null object
NAME_INCOME_TYPE 307511 non-null object
NAME_EDUCATION_TYPE 307511 non-null object
NAME_FAMILY_STATUS 307511 non-null object
NAME_HOUSING_TYPE 307511 non-null object
REGION_POPULATION_RELATIVE 307511 non-null float64
DAYS_BIRTH 307511 non-null int64
DAYS_EMPLOYED 307511 non-null int64
DAYS_REGISTRATION 307511 non-null float64
DAYS_ID_PUBLISH 307511 non-null int64
OWN_CAR_AGE 104582 non-null float64
FLAG_MOBIL 307511 non-null int64
FLAG_EMP_PHONE 307511 non-null int64
FLAG_WORK_PHONE 307511 non-null int64
FLAG_CONT_MOBILE 307511 non-null int64
FLAG_PHONE 307511 non-null int64
FLAG_EMAIL 307511 non-null int64
OCCUPATION_TYPE 211120 non-null object
CNT_FAM_MEMBERS 307509 non-null float64
REGION_RATING_CLIENT 307511 non-null int64
REGION_RATING_CLIENT_W_CITY 307511 non-null int64
WEEKDAY_APPR_PROCESS_START 307511 non-null object
HOUR_APPR_PROCESS_START 307511 non-null int64
REG_REGION_NOT_LIVE_REGION 307511 non-null int64
REG_REGION_NOT_WORK_REGION 307511 non-null int64
LIVE_REGION_NOT_WORK_REGION 307511 non-null int64
REG_CITY_NOT_LIVE_CITY 307511 non-null int64
REG_CITY_NOT_WORK_CITY 307511 non-null int64
LIVE_CITY_NOT_WORK_CITY 307511 non-null int64
ORGANIZATION_TYPE 307511 non-null object
EXT_SOURCE_1 134133 non-null float64
EXT_SOURCE_2 306851 non-null float64
EXT_SOURCE_3 246546 non-null float64
APARTMENTS_AVG 151450 non-null float64
BASEMENTAREA_AVG 127568 non-null float64
YEARS_BEGINEXPLUATATION_AVG 157504 non-null float64
YEARS_BUILD_AVG 103023 non-null float64
COMMONAREA_AVG 92646 non-null float64
ELEVATORS_AVG 143620 non-null float64
ENTRANCES_AVG 152683 non-null float64
FLOORSMAX_AVG 154491 non-null float64
FLOORSMIN_AVG 98869 non-null float64
LANDAREA_AVG 124921 non-null float64
LIVINGAPARTMENTS_AVG 97312 non-null float64
LIVINGAREA_AVG 153161 non-null float64
NONLIVINGAPARTMENTS_AVG 93997 non-null float64
NONLIVINGAREA_AVG 137829 non-null float64
APARTMENTS_MODE 151450 non-null float64
BASEMENTAREA_MODE 127568 non-null float64
YEARS_BEGINEXPLUATATION_MODE 157504 non-null float64
YEARS_BUILD_MODE 103023 non-null float64
COMMONAREA_MODE 92646 non-null float64
ELEVATORS_MODE 143620 non-null float64
ENTRANCES_MODE 152683 non-null float64
FLOORSMAX_MODE 154491 non-null float64
FLOORSMIN_MODE 98869 non-null float64
LANDAREA_MODE 124921 non-null float64
LIVINGAPARTMENTS_MODE 97312 non-null float64
LIVINGAREA_MODE 153161 non-null float64
NONLIVINGAPARTMENTS_MODE 93997 non-null float64
NONLIVINGAREA_MODE 137829 non-null float64
APARTMENTS_MEDI 151450 non-null float64
BASEMENTAREA_MEDI 127568 non-null float64
YEARS_BEGINEXPLUATATION_MEDI 157504 non-null float64
YEARS_BUILD_MEDI 103023 non-null float64
COMMONAREA_MEDI 92646 non-null float64
ELEVATORS_MEDI 143620 non-null float64
ENTRANCES_MEDI 152683 non-null float64
FLOORSMAX_MEDI 154491 non-null float64
FLOORSMIN_MEDI 98869 non-null float64
LANDAREA_MEDI 124921 non-null float64
LIVINGAPARTMENTS_MEDI 97312 non-null float64
LIVINGAREA_MEDI 153161 non-null float64
NONLIVINGAPARTMENTS_MEDI 93997 non-null float64
NONLIVINGAREA_MEDI 137829 non-null float64
FONDKAPREMONT_MODE 97216 non-null object
HOUSETYPE_MODE 153214 non-null object
TOTALAREA_MODE 159080 non-null float64
WALLSMATERIAL_MODE 151170 non-null object
EMERGENCYSTATE_MODE 161756 non-null object
OBS_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
OBS_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DAYS_LAST_PHONE_CHANGE 307510 non-null float64
FLAG_DOCUMENT_2 307511 non-null int64
FLAG_DOCUMENT_3 307511 non-null int64
FLAG_DOCUMENT_4 307511 non-null int64
FLAG_DOCUMENT_5 307511 non-null int64
FLAG_DOCUMENT_6 307511 non-null int64
FLAG_DOCUMENT_7 307511 non-null int64
FLAG_DOCUMENT_8 307511 non-null int64
FLAG_DOCUMENT_9 307511 non-null int64
FLAG_DOCUMENT_10 307511 non-null int64
FLAG_DOCUMENT_11 307511 non-null int64
FLAG_DOCUMENT_12 307511 non-null int64
FLAG_DOCUMENT_13 307511 non-null int64
FLAG_DOCUMENT_14 307511 non-null int64
FLAG_DOCUMENT_15 307511 non-null int64
FLAG_DOCUMENT_16 307511 non-null int64
FLAG_DOCUMENT_17 307511 non-null int64
FLAG_DOCUMENT_18 307511 non-null int64
FLAG_DOCUMENT_19 307511 non-null int64
FLAG_DOCUMENT_20 307511 non-null int64
FLAG_DOCUMENT_21 307511 non-null int64
AMT_REQ_CREDIT_BUREAU_HOUR 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_DAY 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_WEEK 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_MON 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_QRT 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_YEAR 265992 non-null float64
dtypes: float64(65), int64(41), object(16)
memory usage: 286.2+ MBIngat anotasi terperinci menurut bidang di file HomeCredit_columns_description. Seperti yang dapat Anda lihat dari info, bagian dari data tidak lengkap dan sebagian bersifat kategoris, mereka ditampilkan sebagai objek. Sebagian besar model tidak bekerja dengan data seperti itu, kita harus melakukan sesuatu dengannya. Pada ini, analisis awal dapat dianggap selesai, kami akan langsung pergi ke EDA
Analisis Data Eksplorasi atau penambangan data primer
Dalam proses EDA, kami menghitung statistik dasar dan menggambar grafik untuk menemukan tren, anomali, pola, dan hubungan dalam data. Tujuan EDA adalah untuk mencari tahu data apa yang bisa diceritakan. Biasanya, analisis berjalan dari atas ke bawah - dari tinjauan umum ke studi tentang masing-masing zona yang menarik perhatian dan mungkin menarik. Selanjutnya, temuan ini dapat digunakan dalam konstruksi model, pemilihan fitur untuk itu dan dalam interpretasinya.
Distribusi Variabel Target
app_train.TARGET.value_counts()
0 282686
1 24825
Name: TARGET, dtype: int64 plt.style.use('fivethirtyeight') plt.rcParams["figure.figsize"] = [8,5] plt.hist(app_train.TARGET) plt.show()
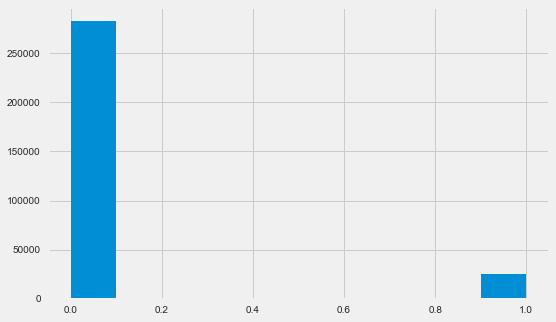
Biarkan saya mengingatkan Anda bahwa 1 berarti masalah apa pun dengan pengembalian, 0 berarti tidak ada masalah. Seperti yang Anda lihat, sebagian besar peminjam tidak memiliki masalah dengan pembayaran, bagian bermasalah adalah sekitar 8%. Ini berarti bahwa kelas tidak seimbang dan ini mungkin perlu dipertimbangkan ketika membangun model.
Penelitian Data Hilang
Kami telah melihat bahwa kurangnya data cukup besar. Mari kita lihat lebih detail di mana dan apa yang hilang.
122 .
67 .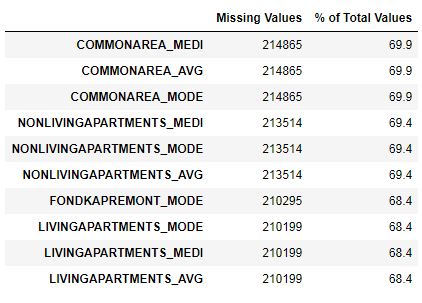
Dalam format grafis:
plt.style.use('seaborn-talk') fig = plt.figure(figsize=(18,6)) miss_train = pd.DataFrame((app_train.isnull().sum())*100/app_train.shape[0]).reset_index() miss_test = pd.DataFrame((app_test.isnull().sum())*100/app_test.shape[0]).reset_index() miss_train["type"] = "" miss_test["type"] = "" missing = pd.concat([miss_train,miss_test],axis=0) ax = sns.pointplot("index",0,data=missing,hue="type") plt.xticks(rotation =90,fontsize =7) plt.title(" ") plt.ylabel(" %") plt.xlabel("")
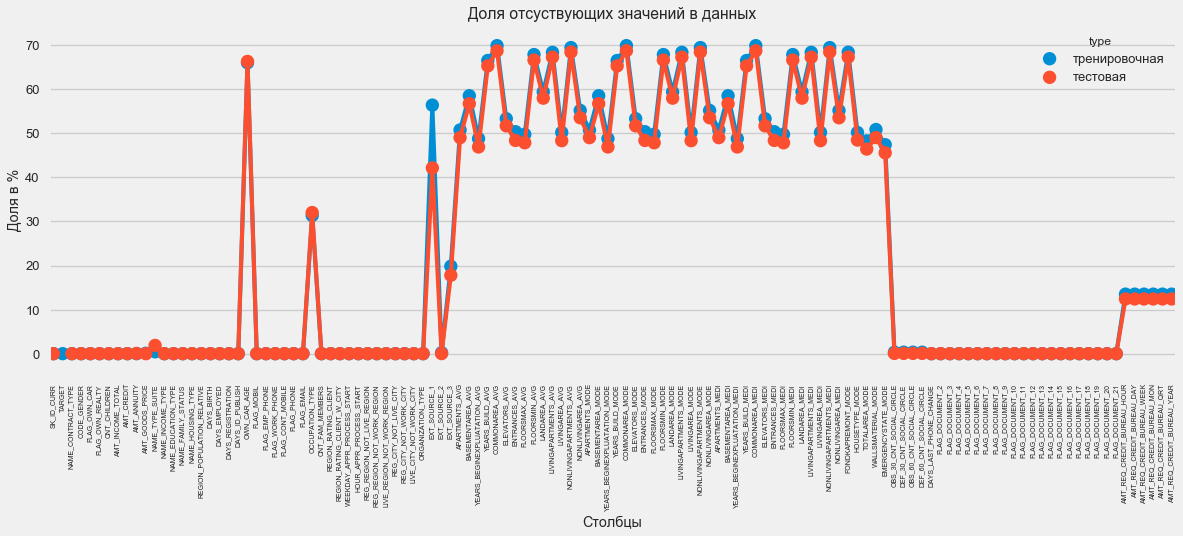
Ada banyak jawaban untuk pertanyaan "apa yang harus dilakukan dengan semua ini". Anda dapat mengisinya dengan nol, Anda dapat menggunakan nilai median, Anda bisa menghapus baris tanpa informasi yang diperlukan. Itu semua tergantung pada model yang kami rencanakan untuk digunakan, karena beberapa dari mereka secara sempurna mengatasi nilai yang hilang. Sementara kita mengingat fakta ini dan meninggalkan semuanya apa adanya.
Jenis Kolom dan Pengodean Kategorikal
Seperti yang kita ingat. bagian dari kolom adalah tipe objek, yaitu tidak memiliki nilai numerik, tetapi mencerminkan beberapa kategori. Mari kita lihat kolom ini lebih dekat.
app_train.dtypes.value_counts()
float64 65
int64 41
object 16
dtype: int64 app_train.select_dtypes(include=[object]).apply(pd.Series.nunique, axis = 0)
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64Kami memiliki 16 kolom, masing-masing dengan 2 hingga 58 opsi nilai yang berbeda. Secara umum, model pembelajaran mesin tidak dapat melakukan apa pun dengan kolom seperti itu (kecuali untuk beberapa, seperti LightGBM atau CatBoost). Karena kami berencana untuk mencoba model yang berbeda pada dataset, sesuatu perlu dilakukan dengan ini. Pada dasarnya ada dua pendekatan:
- Pengkodean Label - kategori diberikan digit 0, 1, 2 dan seterusnya dan ditulis dalam kolom yang sama
- One-Hot-encoding - satu kolom didekomposisi menjadi beberapa sesuai dengan jumlah opsi dan kolom ini menunjukkan opsi mana yang dimiliki catatan ini.
Di antara yang populer, perlu dicatat
berarti pengkodean target (terima kasih atas
kloryorangepants klarifikasi).
Ada masalah kecil dengan Pengkodean Label - ini memberikan nilai numerik yang tidak ada hubungannya dengan kenyataan. Misalnya, jika kita berurusan dengan nilai numerik, maka penghasilan peminjam sebesar 100.000 pasti lebih besar dan lebih baik daripada pendapatan 20.000. Tetapi dapat dikatakan bahwa, misalnya, satu kota lebih baik dari yang lain karena satu diberi nilai 100 dan yang lainnya 200 ?
One-Hot-encoding, di sisi lain, lebih aman, tetapi dapat menghasilkan kolom "ekstra". Misalnya, jika kita menyandikan jenis kelamin yang sama menggunakan One-Hot, kita mendapatkan dua kolom, "jenis kelamin laki-laki" dan "jenis kelamin perempuan", meskipun satu akan cukup, "apakah itu laki-laki".
Untuk dataset yang baik, perlu untuk memberi tanda kode dengan variabilitas rendah menggunakan Pengkodean Label, dan yang lainnya - One-Hot, tetapi untuk kesederhanaan kami menyandikan semuanya sesuai dengan One-Hot. Praktis tidak akan mempengaruhi kecepatan perhitungan dan hasilnya. Proses penyandian panda itu sendiri sangat sederhana.
app_train = pd.get_dummies(app_train) app_test = pd.get_dummies(app_test) print('Training Features shape: ', app_train.shape) print('Testing Features shape: ', app_test.shape)
Training Features shape: (307511, 246)
Testing Features shape: (48744, 242)Karena jumlah opsi di kolom pilihan tidak sama, jumlah kolom sekarang tidak cocok. Penyelarasan diperlukan - Anda harus menghapus kolom dari set pelatihan yang tidak ada dalam set tes. Ini membuat metode penyelarasan, Anda perlu menentukan sumbu = 1 (untuk kolom).
: (307511, 242)
: (48744, 242)Korelasi data
Cara yang baik untuk memahami data adalah dengan menghitung koefisien korelasi Pearson untuk data relatif terhadap atribut target. Ini bukan metode terbaik untuk menunjukkan relevansi fitur, tetapi sederhana dan memungkinkan Anda mendapatkan gambaran tentang data. Koefisien dapat diartikan sebagai berikut:
- 00-.19 “sangat lemah”
- 20-.39 "lemah"
- 40-0,59 "rata-rata"
- 60-, 79 kuat
- 80-1.0 “sangat kuat”
:
DAYS_REGISTRATION 0.041975
OCCUPATION_TYPE_Laborers 0.043019
FLAG_DOCUMENT_3 0.044346
REG_CITY_NOT_LIVE_CITY 0.044395
FLAG_EMP_PHONE 0.045982
NAME_EDUCATION_TYPE_Secondary / secondary special 0.049824
REG_CITY_NOT_WORK_CITY 0.050994
DAYS_ID_PUBLISH 0.051457
CODE_GENDER_M 0.054713
DAYS_LAST_PHONE_CHANGE 0.055218
NAME_INCOME_TYPE_Working 0.057481
REGION_RATING_CLIENT 0.058899
REGION_RATING_CLIENT_W_CITY 0.060893
DAYS_BIRTH 0.078239
TARGET 1.000000
Name: TARGET, dtype: float64
:
EXT_SOURCE_3 -0.178919
EXT_SOURCE_2 -0.160472
EXT_SOURCE_1 -0.155317
NAME_EDUCATION_TYPE_Higher education -0.056593
CODE_GENDER_F -0.054704
NAME_INCOME_TYPE_Pensioner -0.046209
ORGANIZATION_TYPE_XNA -0.045987
DAYS_EMPLOYED -0.044932
FLOORSMAX_AVG -0.044003
FLOORSMAX_MEDI -0.043768
FLOORSMAX_MODE -0.043226
EMERGENCYSTATE_MODE_No -0.042201
HOUSETYPE_MODE_block of flats -0.040594
AMT_GOODS_PRICE -0.039645
REGION_POPULATION_RELATIVE -0.037227
Name: TARGET, dtype: float64Dengan demikian, semua data berkorelasi lemah dengan target (kecuali untuk target itu sendiri, yang, tentu saja, sama dengan dirinya sendiri). Namun, usia dan beberapa "sumber data eksternal" dibedakan dari data. Ini mungkin beberapa data tambahan dari organisasi kredit lain. Sangat lucu bahwa meskipun tujuannya dinyatakan sebagai independensi dari data tersebut dalam membuat keputusan kredit, pada kenyataannya kita akan didasarkan terutama pada mereka.
Usia
Jelas bahwa semakin tua klien, semakin tinggi kemungkinan pengembalian (tentu saja hingga batas tertentu). Tetapi untuk beberapa alasan, usia diindikasikan pada hari-hari negatif sebelum pinjaman dikeluarkan, oleh karena itu, usia tersebut berkorelasi positif dengan tidak adanya pembayaran kembali (yang terlihat agak aneh). Kami membawanya ke nilai positif dan melihat korelasinya.
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH']) app_train['DAYS_BIRTH'].corr(app_train['TARGET'])
-0.078239308309827088Mari kita lihat variabel lebih dekat. Mari kita mulai dengan histogram.
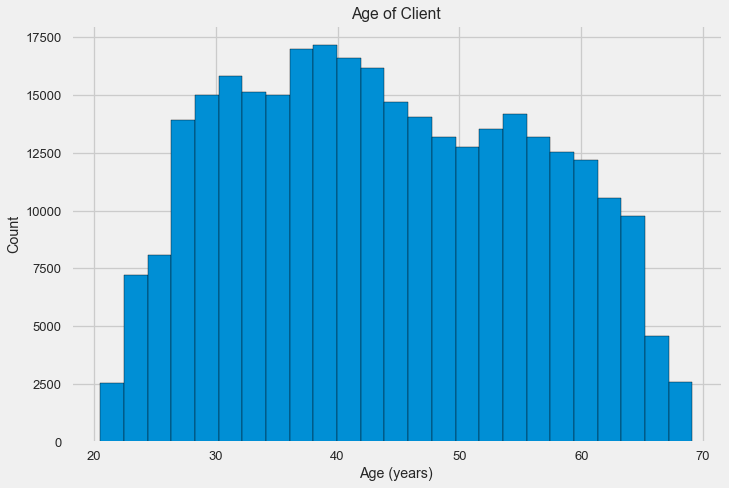
Histogram distribusi itu sendiri mungkin mengatakan sedikit berguna, kecuali bahwa kita tidak melihat outlier khusus dan semuanya terlihat lebih atau kurang dapat dipercaya. Untuk menunjukkan pengaruh pengaruh usia pada hasil, kita dapat membuat grafik estimasi kepadatan kernel (KDE) - distribusi kepadatan nuklir, dicat dengan warna atribut target. Ini menunjukkan distribusi dari satu variabel dan dapat diartikan sebagai histogram yang dihaluskan (dihitung sebagai kernel Gaussian untuk setiap titik, yang kemudian dirata-rata untuk dihaluskan).
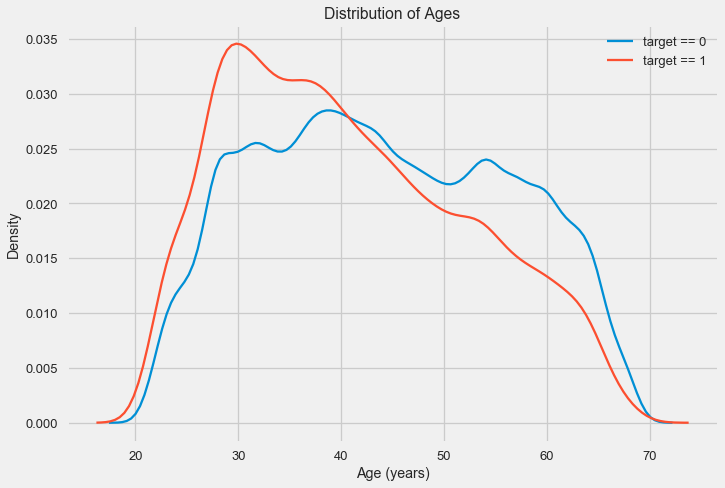
Seperti yang dapat dilihat, bagian default adalah lebih tinggi untuk kaum muda dan menurun dengan bertambahnya usia. Ini bukan alasan untuk selalu menolak kredit kepada kaum muda, "rekomendasi" semacam itu hanya akan menyebabkan hilangnya pendapatan dan pasar bagi bank. Ini adalah kesempatan untuk memikirkan pemantauan yang lebih menyeluruh atas pinjaman, penilaian dan, mungkin, bahkan semacam pendidikan keuangan untuk peminjam muda.
Sumber eksternal
Mari kita lihat lebih dekat "sumber data eksternal" EXT_SOURCE dan korelasinya.
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']] ext_data_corrs = ext_data.corr() ext_data_corrs
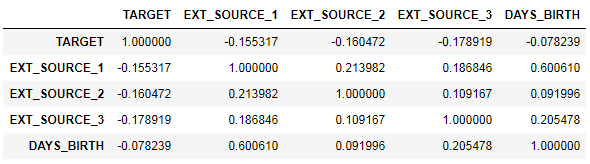
Juga nyaman untuk menampilkan korelasi menggunakan heatmap
sns.heatmap(ext_data_corrs, cmap = plt.cm.RdYlBu_r, vmin = -0.25, annot = True, vmax = 0.6) plt.title('Correlation Heatmap');
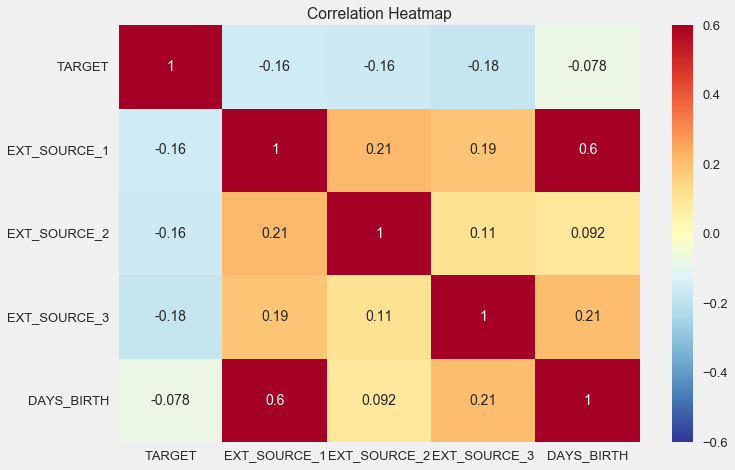
Seperti yang Anda lihat, semua sumber menunjukkan korelasi negatif dengan target. Mari kita lihat distribusi KDE untuk setiap sumber.
plt.figure(figsize = (10, 12))
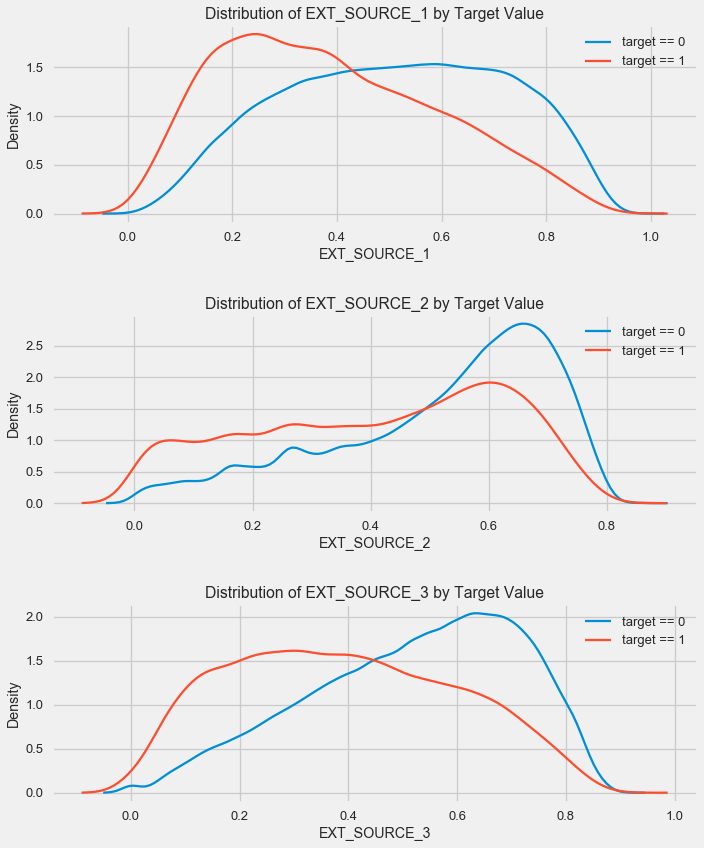
Gambarannya mirip dengan distribusi berdasarkan usia - dengan peningkatan indikator, kemungkinan pengembalian pinjaman meningkat. Sumber ketiga adalah yang paling kuat dalam hal ini. Meskipun secara absolut korelasinya dengan variabel target masih dalam kategori “sangat rendah”, sumber dan usia data eksternal akan menjadi yang paling penting dalam membangun model.
Jadwal berpasangan
Untuk lebih memahami hubungan variabel-variabel ini, Anda bisa membuat bagan pasangan, di dalamnya kita bisa melihat hubungan masing-masing pasangan dan histogram distribusi sepanjang diagonal. Di atas diagonal, Anda dapat menunjukkan scatterplot, dan di bawah - 2d KDE.
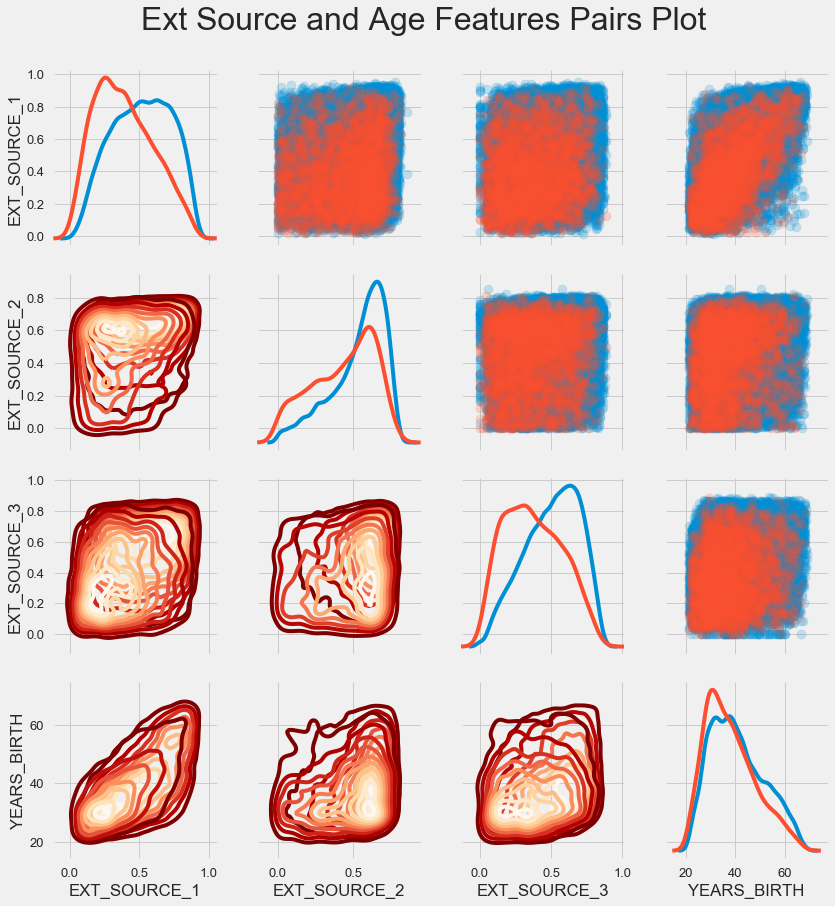
Pinjaman yang dibayar kembali ditunjukkan dengan warna biru, tidak dapat dikembalikan dalam warna merah. Untuk menginterpretasikan semua ini agak sulit, tetapi cetakan yang baik pada T-shirt atau gambar di museum seni modern dapat keluar dari gambar ini.
Pemeriksaan tanda-tanda lain
Mari kita pertimbangkan lebih detail fitur-fitur lain dan ketergantungannya pada variabel target. Karena ada banyak yang kategorikal (dan kami sudah berhasil menyandikannya), kami kembali memerlukan data awal. Mari kita sebut mereka sedikit berbeda untuk menghindari kebingungan
application_train = pd.read_csv(PATH+"application_train.csv") application_test = pd.read_csv(PATH+"application_test.csv")
Kami juga akan membutuhkan beberapa fungsi untuk menampilkan distribusi dan pengaruhnya pada variabel target. Banyak terima kasih
kepada mereka untuk
penulis kernel ini
def plot_stats(feature,label_rotation=False,horizontal_layout=True): temp = application_train[feature].value_counts() df1 = pd.DataFrame({feature: temp.index,' ': temp.values})
Jadi, kami akan mempertimbangkan tanda-tanda utama klien
Jenis pinjaman
plot_stats('NAME_CONTRACT_TYPE')
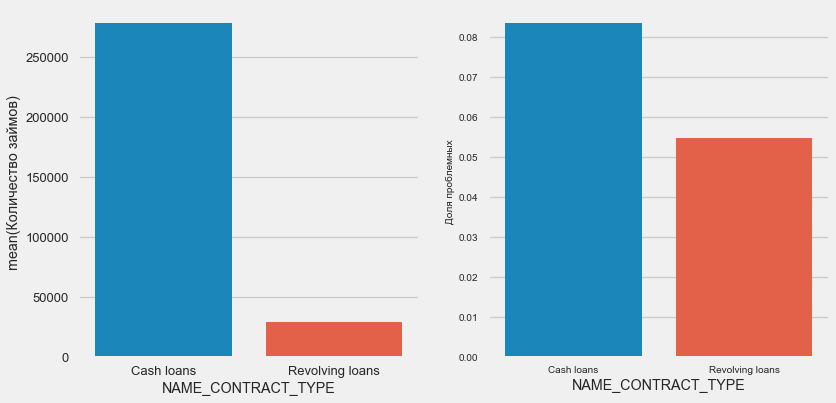
Menariknya, pinjaman bergulir (mungkin cerukan atau sesuatu seperti itu) membentuk kurang dari 10% dari total jumlah pinjaman. Pada saat yang sama, persentase tidak-kembali di antara mereka jauh lebih tinggi. Alasan yang baik untuk merevisi metodologi bekerja dengan pinjaman ini, dan bahkan mungkin mengabaikannya.
Jenis kelamin pelanggan
plot_stats('CODE_GENDER')
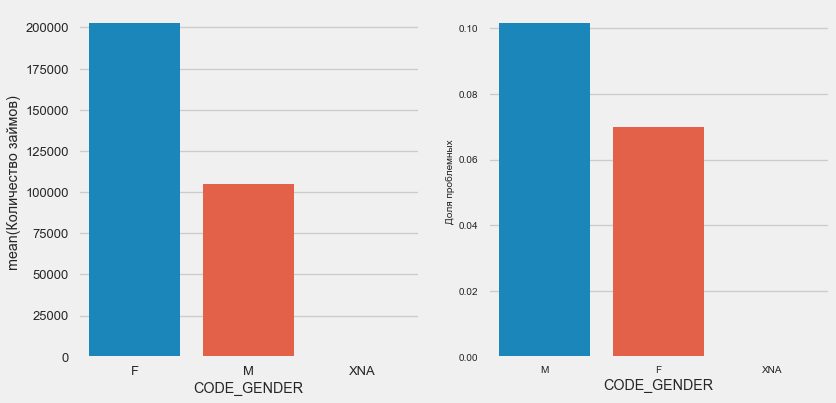
Ada hampir dua kali lebih banyak klien wanita daripada pria, dengan pria menunjukkan risiko yang jauh lebih tinggi.
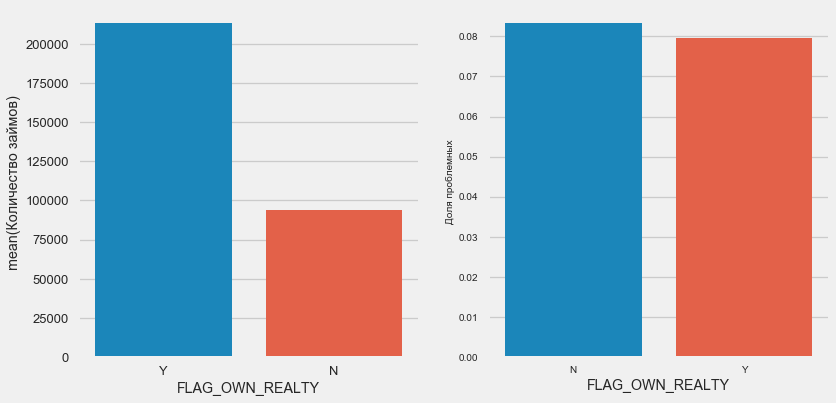
Kepemilikan mobil dan properti
plot_stats('FLAG_OWN_CAR') plot_stats('FLAG_OWN_REALTY')
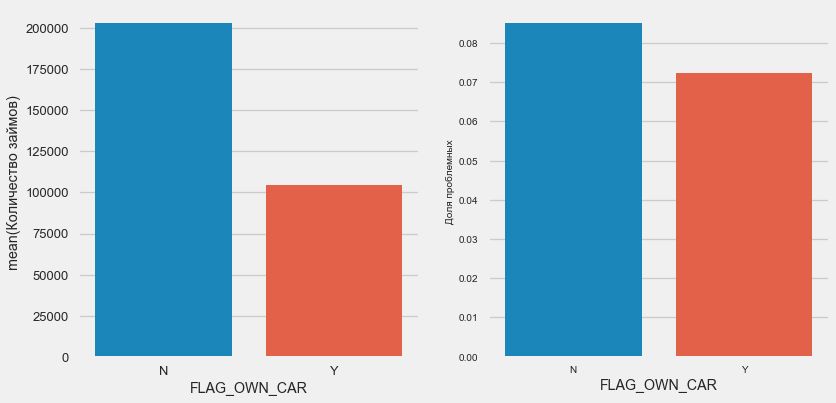
Klien dengan mobil setengah dari "tidak punya kuda". Risikonya hampir sama, pelanggan dengan mesin membayar sedikit lebih baik.
Untuk real estat, yang terjadi adalah sebaliknya - hanya ada sedikit pelanggan tanpa itu. Risiko untuk pemilik properti juga sedikit lebih sedikit.
Status pernikahan
plot_stats('NAME_FAMILY_STATUS',True, True)
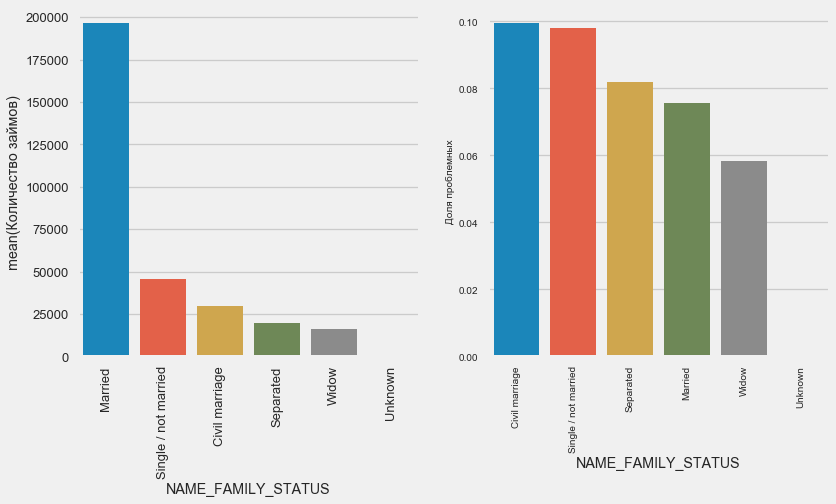
Sementara sebagian besar klien sudah menikah, yang paling berisiko adalah klien sipil dan lajang. Duda menunjukkan risiko minimal.
Jumlah anak
plot_stats('CNT_CHILDREN')
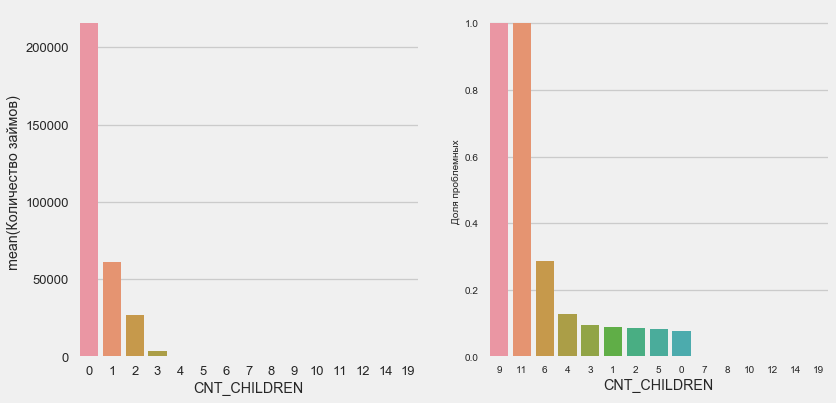
Sebagian besar pelanggan tidak memiliki anak. Pada saat yang sama, pelanggan dengan 9 dan 11 anak-anak menunjukkan pengembalian dana yang tidak lengkap
application_train.CNT_CHILDREN.value_counts()
0 215371
1 61119
2 26749
3 3717
4 429
5 84
6 21
7 7
14 3
19 2
12 2
10 2
9 2
8 2
11 1
Name: CNT_CHILDREN, dtype: int64Seperti yang ditunjukkan oleh perhitungan nilai, data ini tidak signifikan secara statistik - hanya 1-2 klien dari kedua kategori. Namun, ketiganya menjadi default, seperti halnya setengah dari pelanggan dengan 6 anak.
Jumlah anggota keluarga
plot_stats('CNT_FAM_MEMBERS',True)
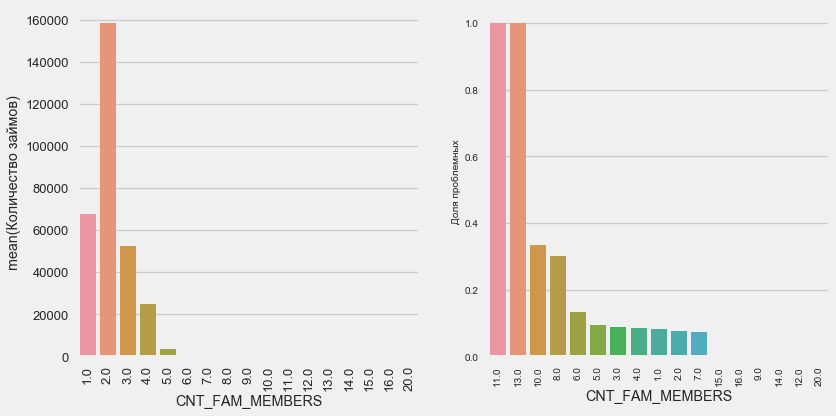
Situasinya mirip - semakin sedikit mulut, semakin tinggi pengembaliannya.
Jenis penghasilan
plot_stats('NAME_INCOME_TYPE',False,False)
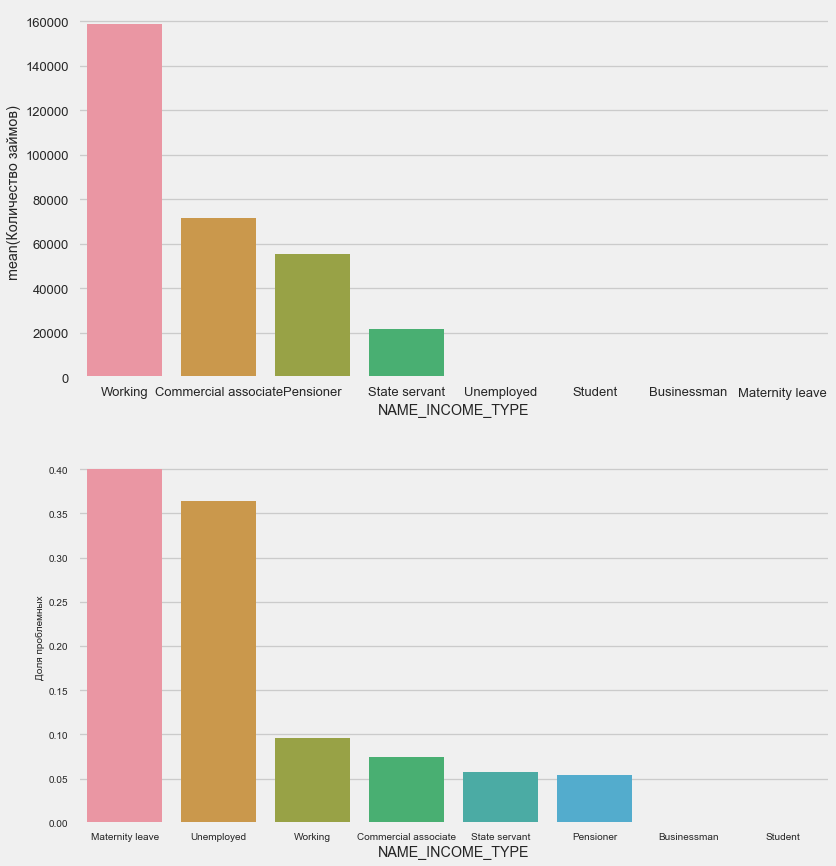
Ibu tunggal dan penganggur cenderung terputus pada tahap aplikasi - ada terlalu sedikit dari mereka dalam sampel. Tetapi masalah secara stabil menunjukkan.
Jenis kegiatan
plot_stats('OCCUPATION_TYPE',True, False)
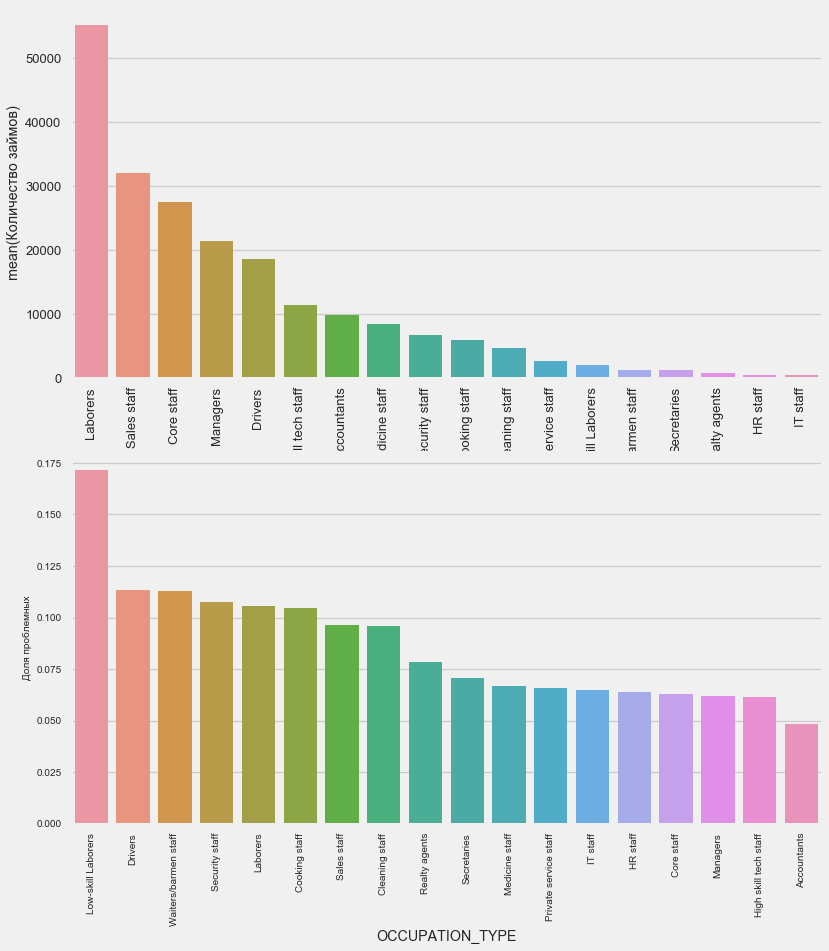
application_train.OCCUPATION_TYPE.value_counts()
Laborers 55186
Sales staff 32102
Core staff 27570
Managers 21371
Drivers 18603
High skill tech staff 11380
Accountants 9813
Medicine staff 8537
Security staff 6721
Cooking staff 5946
Cleaning staff 4653
Private service staff 2652
Low-skill Laborers 2093
Waiters/barmen staff 1348
Secretaries 1305
Realty agents 751
HR staff 563
IT staff 526
Name: OCCUPATION_TYPE, dtype: int64Sangat menarik bagi pengemudi dan petugas keamanan yang cukup banyak dan menghadapi masalah lebih sering daripada kategori lainnya.
Pendidikan
plot_stats('NAME_EDUCATION_TYPE',True)
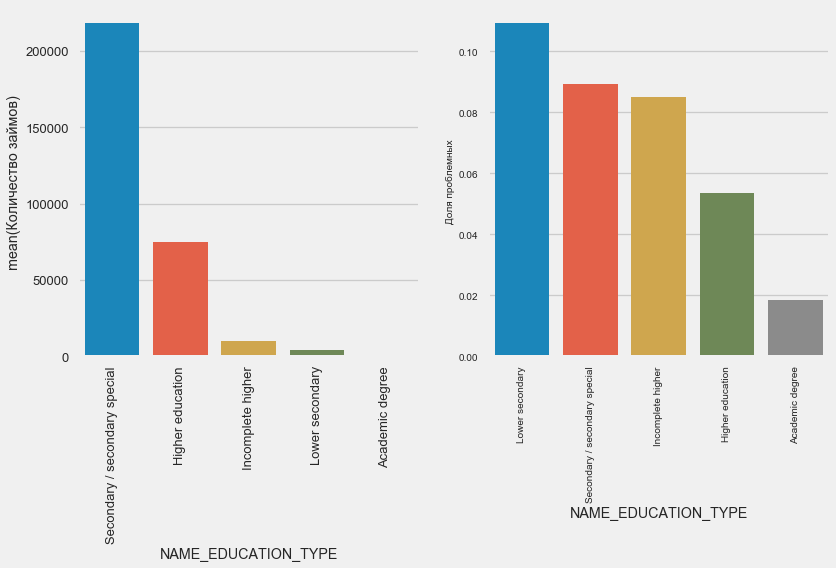
Semakin tinggi pendidikan, semakin baik perulangannya, jelas.
Jenis organisasi - majikan
plot_stats('ORGANIZATION_TYPE',True, False)
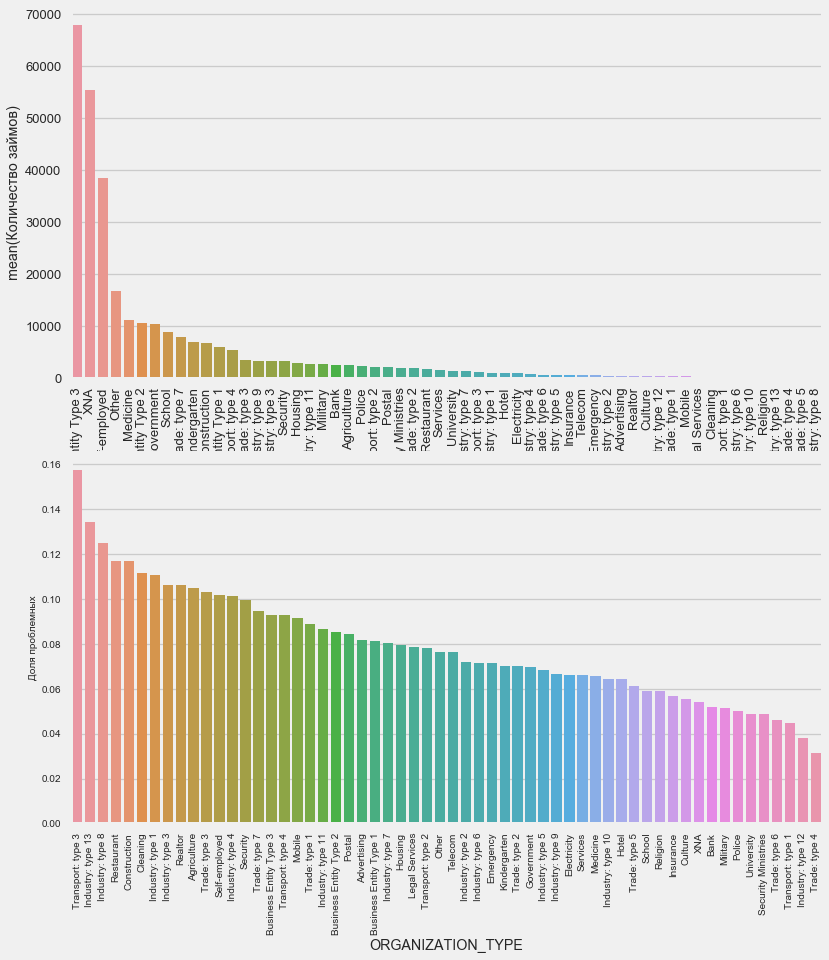
Persentase tertinggi non-pengembalian diamati di Transportasi: tipe 3 (16%), Industri: tipe 13 (13,5%), Industri: tipe 8 (12,5%) dan Restoran (hingga 12%).
Alokasi pinjaman
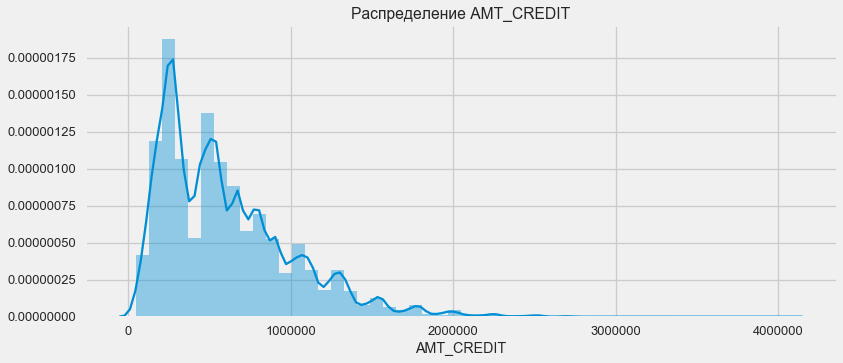
Pertimbangkan distribusi jumlah pinjaman dan dampaknya terhadap pembayaran
plt.figure(figsize=(12,5)) plt.title(" AMT_CREDIT") ax = sns.distplot(app_train["AMT_CREDIT"])
plt.figure(figsize=(12,5))
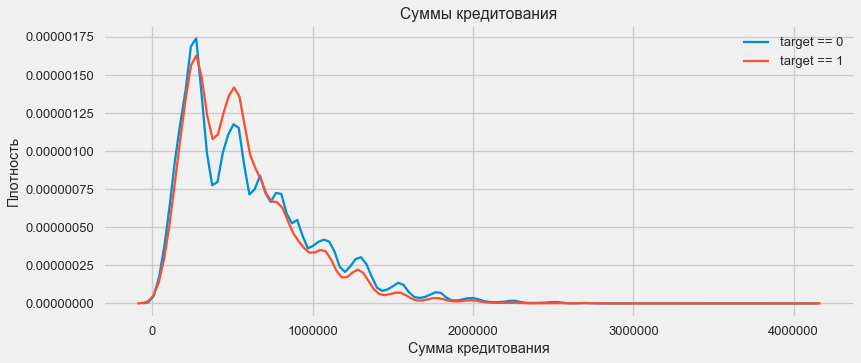
Seperti yang ditunjukkan grafik kepadatan, jumlah yang kuat akan dikembalikan lebih sering
Distribusi kepadatan
plt.figure(figsize=(12,5)) plt.title(" REGION_POPULATION_RELATIVE") ax = sns.distplot(app_train["REGION_POPULATION_RELATIVE"])
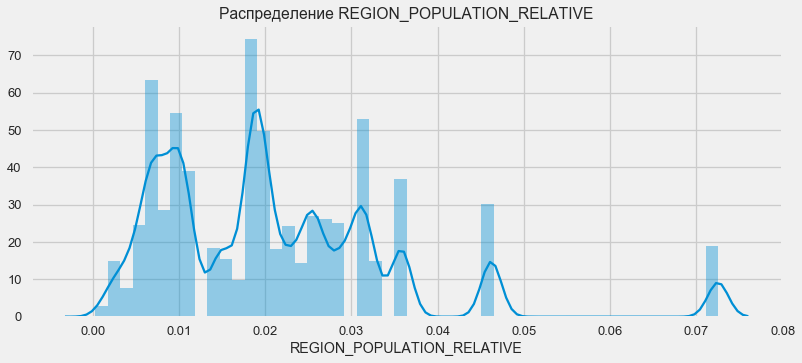
plt.figure(figsize=(12,5))
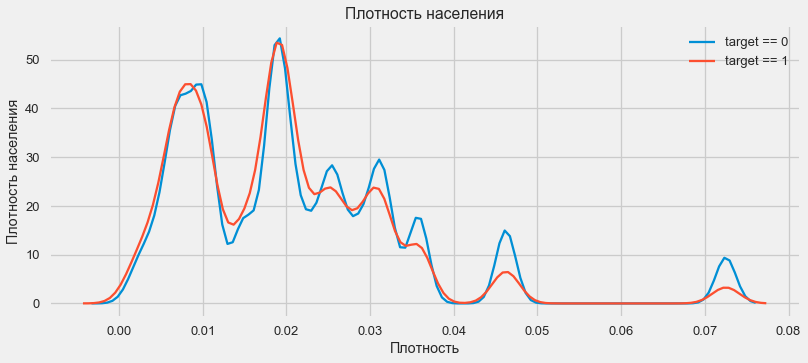
Pelanggan dari daerah yang lebih padat cenderung membayar pinjaman lebih baik.
Jadi, kami mendapat ide tentang fitur utama dataset dan pengaruhnya terhadap hasilnya. Kami tidak akan melakukan apa pun secara khusus dengan yang tercantum dalam artikel ini, tetapi mereka dapat menjadi sangat penting dalam pekerjaan di masa depan.
Rekayasa Fitur - Konversi Fitur
Kompetisi di Kaggle dimenangkan oleh transformasi tanda - orang yang bisa membuat tanda paling berguna dari data yang menang. Setidaknya untuk data terstruktur, model yang menang pada dasarnya adalah opsi peningkatan gradien yang berbeda. Lebih sering daripada tidak, itu lebih efisien untuk menghabiskan waktu mengonversi atribut daripada mengatur hyperparameters atau memilih model. Model masih dapat belajar hanya dari data yang telah ditransfer ke sana. Memastikan bahwa data itu relevan dengan tugas adalah tanggung jawab utama dari tanggal Scientist.
Proses transformasi karakteristik dapat mencakup pembuatan data baru yang tersedia, pemilihan yang paling penting yang tersedia, dll. Kami akan mencoba tanda polinomial kali ini.
Tanda-tanda jumlahnya banyak
Metode polinomial membangun fitur adalah bahwa kami hanya membuat fitur yang tingkat fitur yang tersedia dan produk mereka. Dalam beberapa kasus, fitur yang dibangun tersebut mungkin memiliki korelasi yang lebih kuat dengan variabel target daripada "orang tua" mereka. Meskipun metode seperti itu sering digunakan dalam model statistik, mereka jauh kurang umum dalam pembelajaran mesin. Namun demikian. tidak ada yang menghalangi kita untuk mencobanya, terutama karena Scikit-Learn memiliki kelas khusus untuk tujuan ini - PolynomialFeatures - yang menciptakan fitur polinomial dan produknya, Anda hanya perlu menentukan fitur asli sendiri dan tingkat maksimum yang perlu ditingkatkan. Kami menggunakan efek paling kuat pada hasil 4 atribut dan derajat 3 agar tidak terlalu menyulitkan model dan menghindari overfitting (overtraining model - penyesuaian berlebihan pada sampel pelatihan).
: (307511, 35)
get_feature_names poly_transformer.get_feature_names(input_features = ['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH'])[:15]
['1',
'EXT_SOURCE_1',
'EXT_SOURCE_2',
'EXT_SOURCE_3',
'DAYS_BIRTH',
'EXT_SOURCE_1^2',
'EXT_SOURCE_1 EXT_SOURCE_2',
'EXT_SOURCE_1 EXT_SOURCE_3',
'EXT_SOURCE_1 DAYS_BIRTH',
'EXT_SOURCE_2^2',
'EXT_SOURCE_2 EXT_SOURCE_3',
'EXT_SOURCE_2 DAYS_BIRTH',
'EXT_SOURCE_3^2',
'EXT_SOURCE_3 DAYS_BIRTH',
'DAYS_BIRTH^2']Sebanyak 35 fitur polinomial dan turunannya. Periksa korelasinya dengan target.
EXT_SOURCE_2 EXT_SOURCE_3 -0.193939
EXT_SOURCE_1 EXT_SOURCE_2 EXT_SOURCE_3 -0.189605
EXT_SOURCE_2 EXT_SOURCE_3 DAYS_BIRTH -0.181283
EXT_SOURCE_2^2 EXT_SOURCE_3 -0.176428
EXT_SOURCE_2 EXT_SOURCE_3^2 -0.172282
EXT_SOURCE_1 EXT_SOURCE_2 -0.166625
EXT_SOURCE_1 EXT_SOURCE_3 -0.164065
EXT_SOURCE_2 -0.160295
EXT_SOURCE_2 DAYS_BIRTH -0.156873
EXT_SOURCE_1 EXT_SOURCE_2^2 -0.156867
Name: TARGET, dtype: float64
DAYS_BIRTH -0.078239
DAYS_BIRTH^2 -0.076672
DAYS_BIRTH^3 -0.074273
TARGET 1.000000
1 NaN
Name: TARGET, dtype: float64Jadi, beberapa tanda menunjukkan korelasi yang lebih tinggi dari aslinya. Masuk akal untuk mencoba belajar dengan mereka dan tanpa mereka (seperti banyak pembelajaran mesin, ini dapat ditentukan secara eksperimental). Untuk melakukan ini, buat salinan kerangka data dan tambahkan fitur baru di sana.
: (307511, 277)
: (48744, 277)Pelatihan model
Tingkat dasar
Dalam perhitungan, Anda harus mulai dari beberapa level dasar model, di bawah ini tidak mungkin lagi jatuh. Dalam kasus kami, ini bisa menjadi 0,5 untuk semua klien uji - ini menunjukkan bahwa kami tidak tahu sama sekali apakah klien akan membayar pinjaman atau tidak. Dalam kasus kami, pekerjaan pendahuluan telah dilakukan dan model yang lebih kompleks dapat digunakan.Regresi Logistik
Untuk menghitung regresi logistik, kita perlu mengambil tabel dengan fitur kategorikal berkode, mengisi data yang hilang dan menormalkannya (membawanya ke nilai dari 0 hingga 1). Semua ini menjalankan kode berikut: from sklearn.preprocessing import MinMaxScaler, Imputer
: (307511, 242)
: (48744, 242)Kami menggunakan regresi logistik dari Scikit-Learn sebagai model pertama. Mari kita ambil model defolasi dengan satu koreksi - kita menurunkan parameter regularisasi C untuk menghindari overfitting. Sintaksnya normal - kita membuat model, melatihnya dan memprediksi probabilitas menggunakan predict_proba (kita perlu probabilitas, bukan 0/1) from sklearn.linear_model import LogisticRegression
Sekarang Anda dapat membuat file untuk diunggah ke Kaggle. Buat bingkai data dari ID pelanggan dan kemungkinan tidak ada pengembalian dan unggah. submit = app_test[['SK_ID_CURR']] submit['TARGET'] = log_reg_pred submit.head()
SK_ID_CURR TARGET
0 100001 0.087954
1 100005 0.163151
2 100013 0.109923
3 100028 0.077124
4 100038 0.151694 submit.to_csv('log_reg_baseline.csv', index = False)
Jadi, hasil karya raksasa kami: 0,673, dengan hasil terbaik untuk hari ini adalah 0,802.Model yang Ditingkatkan - Hutan Acak
Logreg tidak menunjukkan dirinya dengan sangat baik, mari kita coba menggunakan model yang lebih baik - hutan acak. Ini adalah model yang jauh lebih kuat yang dapat membangun ratusan pohon dan menghasilkan hasil yang jauh lebih akurat. Kami menggunakan 100 pohon. Skema bekerja dengan model adalah sama, sepenuhnya standar - memuat classifier, pelatihan. prediksi. from sklearn.ensemble import RandomForestClassifier
hasil hutan acak sedikit lebih baik - 0,683Model pelatihan dengan fitur polinomial
Sekarang kita punya model. yang setidaknya melakukan sesuatu - saatnya untuk menguji tanda-tanda jumlahnya banyak. Mari kita lakukan hal yang sama dengan mereka dan bandingkan hasilnya. poly_features_names = list(app_train_poly.columns)
hasil hutan acak dengan fitur polinom menjadi lebih buruk - 0,633. Yang sangat mempertanyakan perlunya penggunaan mereka.Peningkatan Gradien
Meningkatkan gradien adalah "model serius" untuk pembelajaran mesin. Hampir semua kompetisi terbaru "diseret" dengan tepat. Mari kita membangun model sederhana dan menguji kinerjanya. from lightgbm import LGBMClassifier clf = LGBMClassifier() clf.fit(train, train_labels) predictions = clf.predict_proba(test)[:, 1]
Hasil dari LightGBM adalah 0.735, yang meninggalkan semua model lainnya.Interpretasi Model - Pentingnya Atribut
Cara termudah untuk menafsirkan model adalah dengan melihat pentingnya fitur (yang tidak semua model bisa lakukan). Karena classifier kami memproses array, dibutuhkan beberapa pekerjaan untuk mengatur ulang nama kolom sesuai dengan kolom array ini.
Seperti yang diharapkan, yang paling penting untuk model semua 4 fitur yang sama. Pentingnya atribut bukan metode interpretasi model terbaik, tetapi memungkinkan Anda untuk memahami faktor utama yang digunakan model untuk prediksifeature importance
28 EXT_SOURCE_1 310
30 EXT_SOURCE_3 282
29 EXT_SOURCE_2 271
7 DAYS_BIRTH 192
3 AMT_CREDIT 161
4 AMT_ANNUITY 142
5 AMT_GOODS_PRICE 129
8 DAYS_EMPLOYED 127
10 DAYS_ID_PUBLISH 102
9 DAYS_REGISTRATION 69
0.01 = 158
Menambahkan data dari tabel lain
Sekarang kita akan dengan cermat mempertimbangkan tabel tambahan dan apa yang dapat dilakukan dengannya. Segera mulai menyiapkan tabel untuk pelatihan lebih lanjut. Tapi pertama-tama, hapus tabel voluminous masa lalu dari memori, hapus memori menggunakan pengumpul sampah, dan impor perpustakaan yang diperlukan untuk analisis lebih lanjut. import gc
Impor data, segera hapus kolom target di kolom terpisah data = pd.read_csv('../input/application_train.csv') test = pd.read_csv('../input/application_test.csv') prev = pd.read_csv('../input/previous_application.csv') buro = pd.read_csv('../input/bureau.csv') buro_balance = pd.read_csv('../input/bureau_balance.csv') credit_card = pd.read_csv('../input/credit_card_balance.csv') POS_CASH = pd.read_csv('../input/POS_CASH_balance.csv') payments = pd.read_csv('../input/installments_payments.csv')
Segera mengkodekan fitur-fitur kategorikal. Kami sudah melakukan ini sebelumnya, dan kami membuat kode pelatihan dan menguji sampel secara terpisah, dan kemudian menyelaraskan data. Mari kita coba pendekatan yang sedikit berbeda - kita akan menemukan semua tanda kategorikal ini, menggabungkan bingkai data, mengkodekan dari daftar yang ditemukan, dan kemudian lagi membagi sampel menjadi pelatihan dan pengujian. categorical_features = [col for col in data.columns if data[col].dtype == 'object'] one_hot_df = pd.concat([data,test]) one_hot_df = pd.get_dummies(one_hot_df, columns=categorical_features) data = one_hot_df.iloc[:data.shape[0],:] test = one_hot_df.iloc[data.shape[0]:,] print (' ', data.shape) print (' ', test.shape)
(307511, 245)
(48744, 245)Data biro kredit pada saldo pinjaman bulanan.
buro_balance.head()
 MONTHS_BALANCE - jumlah bulan sebelum tanggal permohonan pinjaman. Lihatlah lebih dekat pada "status"
MONTHS_BALANCE - jumlah bulan sebelum tanggal permohonan pinjaman. Lihatlah lebih dekat pada "status" buro_balance.STATUS.value_counts()
C 13646993
0 7499507
X 5810482
1 242347
5 62406
2 23419
3 8924
4 5847
Name: STATUS, dtype: int64Status berarti yang berikut:- ditutup, yaitu, pinjaman dibayar kembali. X adalah status yang tidak dikenal. 0 - pinjaman saat ini, tidak ada kenakalan. 1 - penundaan 1-30 hari, 2 - penundaan 31-60 hari, dan seterusnya hingga status 5 - pinjaman dijual kepada pihak ketiga atau dihapusbukukan.Di sini, misalnya, tanda-tanda berikut dapat dibedakan: buro_grouped_size - jumlah entri dalam database buro_grouped_max - saldo pinjaman maksimum buro_grouped_min - saldo pinjaman minimum.Dan semua status pinjaman ini dapat dikodekan (kami menggunakan metode unstack, sejak kami menggunakan metode unstack, karena SK_ID_BUREAU sama di sana-sini. buro_grouped_size = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].size() buro_grouped_max = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].max() buro_grouped_min = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].min() buro_counts = buro_balance.groupby('SK_ID_BUREAU')['STATUS'].value_counts(normalize = False) buro_counts_unstacked = buro_counts.unstack('STATUS') buro_counts_unstacked.columns = ['STATUS_0', 'STATUS_1','STATUS_2','STATUS_3','STATUS_4','STATUS_5','STATUS_C','STATUS_X',] buro_counts_unstacked['MONTHS_COUNT'] = buro_grouped_size buro_counts_unstacked['MONTHS_MIN'] = buro_grouped_min buro_counts_unstacked['MONTHS_MAX'] = buro_grouped_max buro = buro.join(buro_counts_unstacked, how='left', on='SK_ID_BUREAU') del buro_balance gc.collect()
Informasi umum tentang biro kredit
buro.head()
 (7 kolom pertama diperlihatkan) Adacukup banyak data yang, secara umum, Anda dapat mencoba menyandikan dengan One-Hot-Encoding, grup dengan SK_ID_CURR, rata-rata dan, dengan cara yang sama, bersiap untuk bergabung dengan tabel utama
(7 kolom pertama diperlihatkan) Adacukup banyak data yang, secara umum, Anda dapat mencoba menyandikan dengan One-Hot-Encoding, grup dengan SK_ID_CURR, rata-rata dan, dengan cara yang sama, bersiap untuk bergabung dengan tabel utama buro_cat_features = [bcol for bcol in buro.columns if buro[bcol].dtype == 'object'] buro = pd.get_dummies(buro, columns=buro_cat_features) avg_buro = buro.groupby('SK_ID_CURR').mean() avg_buro['buro_count'] = buro[['SK_ID_BUREAU', 'SK_ID_CURR']].groupby('SK_ID_CURR').count()['SK_ID_BUREAU'] del avg_buro['SK_ID_BUREAU'] del buro gc.collect()
Data pada aplikasi sebelumnya
prev.head()
 Demikian pula, kami menyandikan fitur-fitur kategorikal, rata-rata dan bergabung di atas ID saat ini.
Demikian pula, kami menyandikan fitur-fitur kategorikal, rata-rata dan bergabung di atas ID saat ini. prev_cat_features = [pcol for pcol in prev.columns if prev[pcol].dtype == 'object'] prev = pd.get_dummies(prev, columns=prev_cat_features) avg_prev = prev.groupby('SK_ID_CURR').mean() cnt_prev = prev[['SK_ID_CURR', 'SK_ID_PREV']].groupby('SK_ID_CURR').count() avg_prev['nb_app'] = cnt_prev['SK_ID_PREV'] del avg_prev['SK_ID_PREV'] del prev gc.collect()
Saldo kartu kredit
POS_CASH.head()

POS_CASH.NAME_CONTRACT_STATUS.value_counts()
Active 9151119
Completed 744883
Signed 87260
Demand 7065
Returned to the store 5461
Approved 4917
Amortized debt 636
Canceled 15
XNA 2
Name: NAME_CONTRACT_STATUS, dtype: int64Kami menyandikan fitur kategorikal dan menyiapkan tabel untuk digabungkan le = LabelEncoder() POS_CASH['NAME_CONTRACT_STATUS'] = le.fit_transform(POS_CASH['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() POS_CASH['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] POS_CASH['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] POS_CASH.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
Data Kartu
credit_card.head()
 (7 kolom pertama)Pekerjaan serupa
(7 kolom pertama)Pekerjaan serupa credit_card['NAME_CONTRACT_STATUS'] = le.fit_transform(credit_card['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() credit_card['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] credit_card['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] credit_card.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
Data Pembayaran
payments.head()
 (7 kolom pertama ditampilkan)Mari kita buat tiga tabel - dengan nilai rata-rata, minimum dan maksimum dari tabel ini.
(7 kolom pertama ditampilkan)Mari kita buat tiga tabel - dengan nilai rata-rata, minimum dan maksimum dari tabel ini. avg_payments = payments.groupby('SK_ID_CURR').mean() avg_payments2 = payments.groupby('SK_ID_CURR').max() avg_payments3 = payments.groupby('SK_ID_CURR').min() del avg_payments['SK_ID_PREV'] del payments gc.collect()
Meja gabung
data = data.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') del avg_prev, avg_buro, POS_CASH, credit_card, avg_payments, avg_payments2, avg_payments3 gc.collect() print (' ', data.shape) print (' ', test.shape) print (' ', y.shape)
(307511, 504)
(48744, 504)
(307511,)Dan, sebenarnya, kita akan mencapai tabel ganda ini dengan peningkatan gradien! from lightgbm import LGBMClassifier clf2 = LGBMClassifier() clf2.fit(data, y) predictions = clf2.predict_proba(test)[:, 1]
hasilnya adalah 0,770.Oke, akhirnya, mari kita coba teknik yang lebih kompleks dengan melipat menjadi lipatan, validasi silang dan memilih iterasi terbaik. folds = KFold(n_splits=5, shuffle=True, random_state=546789) oof_preds = np.zeros(data.shape[0]) sub_preds = np.zeros(test.shape[0]) feature_importance_df = pd.DataFrame() feats = [f for f in data.columns if f not in ['SK_ID_CURR']] for n_fold, (trn_idx, val_idx) in enumerate(folds.split(data)): trn_x, trn_y = data[feats].iloc[trn_idx], y.iloc[trn_idx] val_x, val_y = data[feats].iloc[val_idx], y.iloc[val_idx] clf = LGBMClassifier( n_estimators=10000, learning_rate=0.03, num_leaves=34, colsample_bytree=0.9, subsample=0.8, max_depth=8, reg_alpha=.1, reg_lambda=.1, min_split_gain=.01, min_child_weight=375, silent=-1, verbose=-1, ) clf.fit(trn_x, trn_y, eval_set= [(trn_x, trn_y), (val_x, val_y)], eval_metric='auc', verbose=100, early_stopping_rounds=100
Full AUC score 0.785845Skor terakhir pada kaggle 0.783Ke mana harus pergi selanjutnya
Jelas terus bekerja dengan tanda-tanda. Jelajahi data, pilih beberapa tanda, gabungkan, lampirkan tabel tambahan dengan cara yang berbeda. Anda dapat bereksperimen dengan hyperparameters Mogheli - banyak arah.Saya harap kompilasi kecil ini telah menunjukkan kepada Anda metode modern untuk meneliti data dan menyiapkan model prediksi. Pelajari datasaens, berpartisipasi dalam kompetisi, menjadi keren!Dan lagi tautan ke kernel yang membantu saya menyiapkan artikel ini. Artikel ini juga diposting dalam bentuk laptop di Github , Anda dapat mengunduhnya, dataset , dan jalankan serta percobaan.Will Koehrsen. Mulai Di Sini: Pengantar Lembut. HomeCreditRisk: EDA + Baseline Luas [0,772]Gabriel Preda. Home Credit Default Risk Extensive EDAPavan Raj. Loan repayers v/s Loan defaulters — HOME CREDITLem Lordje Ko. 15 lines: Just EXT_SOURCE_xShanth. HOME CREDIT — BUREAU DATA — FEATURE ENGINEERINGDmitriy Kisil. Good_fun_with_LigthGBM