Baru-baru ini, kompetisi iMaterialist Challenge (Furniture) berakhir di Kaggle, di mana tugasnya adalah untuk mengklasifikasikan gambar menjadi 128 jenis furnitur dan barang-barang rumah tangga (yang disebut klasifikasi berbutir halus, di mana kelasnya sangat dekat satu sama lain).
Pada artikel ini saya akan menjelaskan pendekatan yang membawa kami di tempat ketiga dengan
m0rtido , tetapi sebelum melanjutkan ke titik, saya mengusulkan menggunakan jaringan saraf alami di kepala saya untuk memecahkan masalah ini dan membagi kursi di foto di bawah ini menjadi tiga kelas.

Sudahkah Anda menebak dengan benar? Saya juga tidak.
Tapi hentikan, hal pertama yang pertama.
Pernyataan masalah
Dalam kompetisi, kami diberi set data yang menyajikan 128 kelas objek sehari-hari biasa, seperti kursi, televisi, wajan dan bantal dalam bentuk karakter anime.
Bagian pelatihan dari dataset terdiri dari ~ 190 ribu gambar (sulit untuk menentukan jumlah pastinya karena para peserta hanya diberikan satu set URL unduhan, beberapa di antaranya, tentu saja, tidak berfungsi), dan distribusi kelas jauh dari seragam (lihat gambar yang dapat diklik di bawah) .

Dataset tes diwakili oleh 12800 gambar, dan sangat seimbang: ada 100 gambar untuk setiap kelas. Dataset validasi juga dikeluarkan, yang juga memiliki distribusi kelas yang seimbang dan persis setengah dari ukuran satu tes.
Metrik penilaian tugas adalah
.
Bagaimana kami memutuskan?
Pertama-tama, kami mengunduh data dan melihat sebagian kecil dengan mata kami. Alih-alih banyak gambar, gambar 1x1 atau pengganti dengan kesalahan diunduh. Kami segera menghapus gambar tersebut dengan skrip.
Transfer belajar
Jelas bahwa dengan jumlah gambar dan batas waktu yang tersedia, itu bukan ide yang baik untuk melatih jaringan saraf dari awal pada dataset ini. Alih-alih, kami menggunakan pendekatan transfer pembelajaran, gagasannya adalah sebagai berikut: bobot jaringan yang dilatih pada satu tugas dapat digunakan untuk sekumpulan data yang sama sekali berbeda dan mendapatkan kualitas yang layak, atau bahkan peningkatan akurasi dibandingkan dengan belajar dari awal.
Bagaimana cara kerjanya? Lapisan tersembunyi di jaringan saraf dalam bertindak sebagai ekstraktor fitur, mengekstraksi fitur yang kemudian digunakan oleh lapisan atas secara langsung untuk klasifikasi.
Kami mengambil keuntungan dari ini dengan menyelesaikan serangkaian CNN mendalam yang sebelumnya dilatih di ImageNet. Untuk tujuan ini, kami menggunakan Keras dan kebun binatang modelnya, di mana kode berikut cukup untuk memuat arsitektur yang sudah jadi:
base_model = densenet.DenseNet201(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg')
Setelah itu, kami mengekstrak apa yang disebut tanda bottleneck (fitur di pintu keluar dari lapisan convolutional terakhir) dari jaringan dan melatih softmax dengan
dropout di atasnya.
Kemudian, kami menghubungkan bobot "atas" yang terlatih ke bagian konvolusional jaringan dan melatih seluruh jaringan sekaligus.
Lihat kode. for layer in base_model.layers: layer.trainable = True top_model = Sequential() top_model.add(Dropout(0.5, name='top_dropout', input_shape=base_model.output_shape[1:])) top_model.add(Dense(128, activation='softmax', name='top_softmax')) top_model.load_weights('top-weights-densenet.hdf5', by_name=True) model = Model(inputs=base_model.input, outputs=top_model(base_model.output)) initial_lrate = 0.0005 model.compile(optimizer=Adam(lr=initial_lrate), loss='categorical_crossentropy', metrics=['accuracy'])
Dengan fine tuning jaringan, kami berhasil mencoba peretasan berikut:
- Augmentasi Data . Untuk mengatasi overfitting, kami menggunakan augmentasi yang sangat ketat: refleksi horizontal, zoom, shift, rotasi, miring, menambahkan noise warna, shift saluran warna, pelatihan lima garis krop (sudut dan tengah gambar). Kami juga ingin mencoba FancyPCA , tetapi gagal karena kurangnya sumber daya komputasi.
- TTA Untuk memprediksi kelas pada validasi dan tes, kami menggunakan augmentasi, sedikit kurang agresif daripada selama pelatihan, dan rata-rata hasil prediksi untuk meningkatkan akurasi.
- Tingkat Belajar Bersepeda . Peningkatan siklus dan penurunan kecepatan pelatihan membantu model tidak terjebak dalam posisi terendah lokal.
- Pelatihan model pada subset kelas . Seperti yang Anda lihat dari gambar di atas potongan, dataset berisi kelas yang sangat dekat satu sama lain. Begitu dekat sehingga pada kelompok objek tertentu (misalnya, di kursi dan kursi, yang diwakili sebanyak 8 kelas), model kami jauh lebih keliru daripada jenis objek lainnya. Kami mencoba untuk melatih CNN yang terpisah untuk mengenali hanya kursi, berharap bahwa jaringan seperti itu akan belajar membedakan varietas kursi lebih baik daripada jaringan tujuan umum, tetapi pendekatan ini tidak memberikan peningkatan akurasi.
Mengapa Bagian dari jawaban untuk pertanyaan ini disajikan dalam gambar sebelum pemotongan - kelas-kelasnya sangat mirip sehingga bahkan dengan markup awal data, orang-orang yang meletakkan label kelas tidak dapat membedakan antara mereka, sehingga tidak mungkin untuk memeras data ini dengan akurasi yang baik. - Jaringan Transformer Spasial . Terlepas dari kenyataan bahwa kami melatih salah satu jaringan dengan itu dan mendapatkan akurasi yang cukup baik, sayangnya, itu tidak termasuk dalam pengiriman akhir.
- Fungsi penurunan berat badan . Untuk mengkompensasi distribusi kelas yang tidak seimbang, kami menggunakan penurunan tertimbang. Ini membantu baik dalam pelatihan softmax "atasan" dan dalam pelatihan lebih lanjut dari seluruh jaringan. Bobot dihitung menggunakan fungsi dari scikit-learn dan kemudian diteruskan ke metode fit model:
train_labels = utils.to_categorical(train_generator.classes) y_integers = np.argmax(train_labels, axis=1) class_weights = compute_class_weight('balanced', np.unique(y_integers), y_integers)
Jaringan yang dilatih dengan cara ini menyumbang 90% dari ansambel akhir kami.
Menumpuk tag bottleneck
Penafian: tidak pernah mengulangi teknik yang dijelaskan kemudian dalam kehidupan nyata.
Jadi, seperti yang kami tentukan di bagian sebelumnya, fitur bottleneck dari jaringan yang dilatih di ImageNet dapat digunakan untuk klasifikasi pada tugas lain.
m0rtido memutuskan untuk melangkah lebih jauh dan mengusulkan strategi berikut:
- Kami mengambil semua arsitektur pra-pelatihan yang tersedia untuk kami (khususnya, NasNet Besar, InceptionV4, Vgg19, Vgg16, InceptionVesnetV2, Resnet-50, Resnet-101, Resnet-152, Xception, Densenet-169, Densenet-121, Densenet-201) diambil ) dan ekstrak tanda-tanda kemacetan dari mereka. Kami juga akan menghitung tanda untuk versi gambar yang dipantulkan (augmentasi minimalis seperti itu).
- Kurangi dimensi fitur masing-masing model sebanyak tiga kali dengan bantuan SAR sehingga mereka masuk secara normal ke dalam RAM 16 Gb yang tersedia bagi kami.
- Gabungkan fitur-fitur ini menjadi satu vektor fitur besar.
- Kami akan mengajarkan satu multilayer perceptron di atas semua ini dan menghasilkan prediksi. Kami juga akan berlatih dengan membobol lipatan dan rata-rata semua prediksi ini.
Tumpukan raksasa yang dihasilkan memberikan peningkatan besar dalam akurasi untuk keseluruhan ensemble.
Ensemble model
Setelah semua hal di atas, kami memiliki sekitar dua lusin jaringan konvolusional yang tidak jelas, serta dua perceptron di atas tanda-tanda hambatan. Pertanyaannya adalah: bagaimana cara mendapatkan satu prediksi dari semua ini?
Dalam cara yang baik, dalam tradisi Kaggle terbaik, kami harus
menumpuk di atas semua ini, tetapi untuk melakukan penumpukan OOF, kami tidak punya waktu atau GPU, dan melatih model tingkat atas tentang pengesahan validasi menghasilkan pakaian yang sangat besar. Karena itu, kami memutuskan untuk mengimplementasikan algoritma yang agak sederhana untuk pembuatan ensemble serakah:
- Inisialisasi ansambel kosong.
- Kami mencoba menambahkan setiap model secara bergantian dan mempertimbangkan skor. Kami memilih model yang paling banyak menambah metrik dan menambahkannya ke ansambel. Hasil prediksi model dalam ansambel rata-rata.
- Jika tidak ada model yang meningkatkan kinerja, kami melalui ansambel dan mencoba untuk menghapus model dari itu. Jika ternyata menghapus beberapa model sehingga skor meningkat, kami melakukan ini dan kembali ke langkah 2.
Sebagai metrik dipilih
. Formula ini dipilih secara empiris sedemikian rupa
dan
ternyata sekitar skala yang sama. Metrik integral seperti itu berkorelasi dengan baik
baik pada validasi dan pada leaderboard publik.
Selain itu, fakta bahwa pada setiap iterasi kami menambahkan atau menghapus satu model (mis., Bobot model selalu tetap bilangan bulat) memainkan peran semacam regularisasi, tidak memungkinkan ensemble untuk mengenakan setelan data validasi yang ditetapkan.
Akibatnya, ansambel menyertakan model-model berikut:
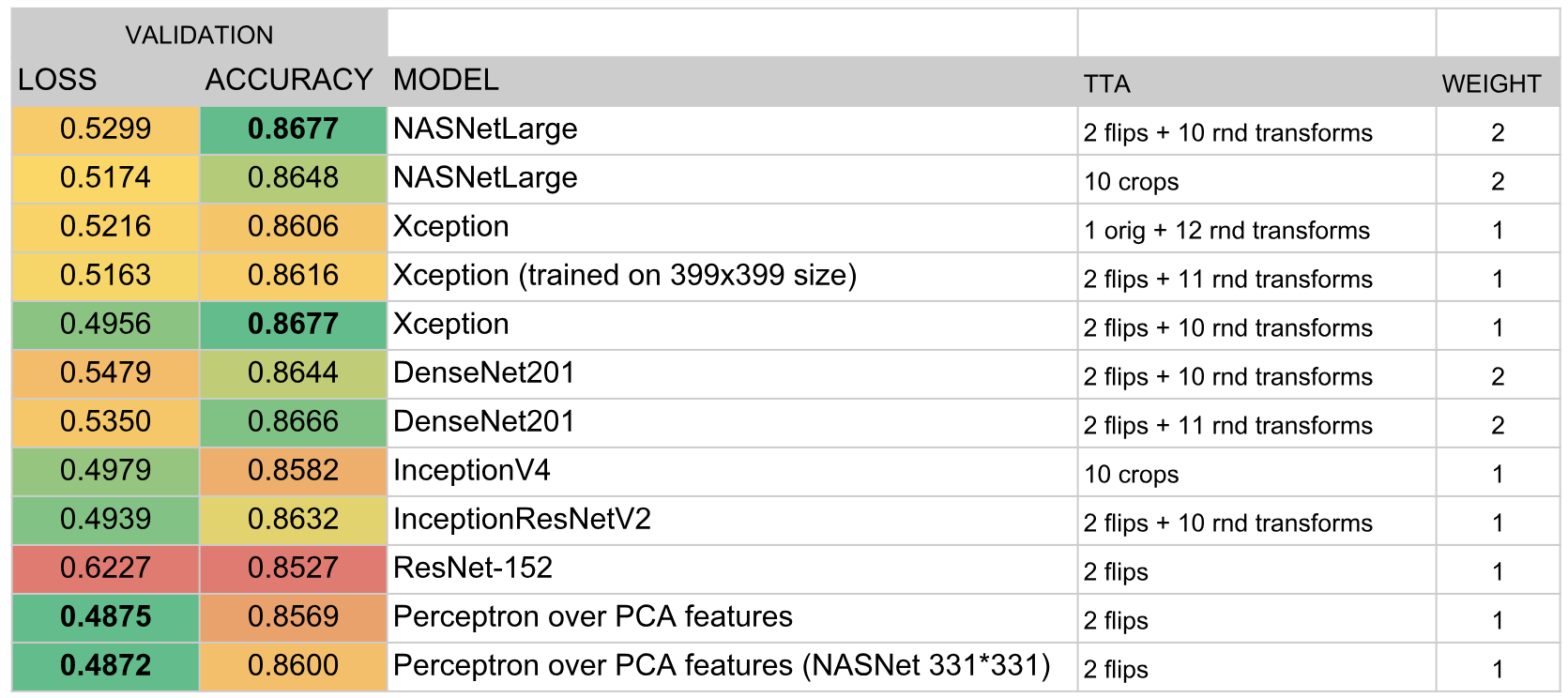
Hasil
Menurut hasil kompetisi, kami mengambil tempat ketiga. Menurut saya, kunci kesuksesan adalah pilihan sukses dari algoritma ensemble dan banyaknya waktu yang saya dan
m0rtido investasikan untuk melatih sejumlah besar model.
