Hai Nama saya Sergey, saya bekerja sebagai chief engineer di Sbertekh. Saya telah berkecimpung di bidang IT selama sekitar 10 tahun, dimana 6 di antaranya terlibat dalam database, proses ETL, DWH, dan segala sesuatu yang terkait dengan data. Pada artikel ini saya akan berbicara tentang Vertica - DBMS analitis dan benar-benar kolumnis yang secara efisien memampatkan, menyimpan, dengan cepat mengirimkan data, dan hebat sebagai solusi data besar.

Informasi umum
Data besar mulai berkembang pada tahun 2000-an, dan dibutuhkan mesin yang dapat mencernanya semua. Menanggapi hal ini, sejumlah DBMS kolom yang dimaksudkan untuk tujuan ini muncul - termasuk Vertica.
Vertica tidak hanya menyimpan data dalam kolom, tetapi melakukannya secara rasional, dengan tingkat kompresi yang tinggi, juga secara efisien menjadwalkan pertanyaan dan dengan cepat memberikan data. Informasi, yang dalam DBMS huruf kecil klasik membutuhkan sekitar 1 TB ruang disk, pada Vertica akan memakan waktu sekitar 200-300 GB, sehingga kami mendapatkan penghematan yang baik pada disk.
Awalnya Vertica dirancang sebagai kolom DBMS. Basis lain pada dasarnya hanya mencoba meniru berbagai mekanisme kolom, tetapi mereka tidak selalu berhasil karena mesin masih dirancang untuk memproses string. Sebagai aturan, peniru hanya memindahkan tabel dan kemudian memprosesnya dengan mekanisme garis biasa.
Vertica toleran terhadap kesalahan, tidak memiliki node kontrol - semua node sama. Jika ada masalah dengan salah satu server di kluster, kami masih akan menerima data. Sangat sering, menerima data tepat waktu sangat penting bagi pelanggan bisnis, terutama pada saat pelaporan ditutup dan Anda perlu memberikan informasi kepada otoritas keuangan.
Area aplikasi
Vertica terutama merupakan gudang data analitik. Anda tidak boleh menulis kepadanya dalam transaksi kecil, Anda tidak boleh mengacaukannya ke situs mana pun, dll. Vertica harus dianggap sebagai semacam lapisan batch, di mana ada baiknya merendam data dalam paket besar. Jika perlu, Vertica siap untuk memberikan data ini dengan sangat cepat - permintaan jutaan saluran diselesaikan dalam hitungan detik.
Di mana ini bisa bermanfaat? Ambil contoh, perusahaan telekomunikasi. Vertica dapat digunakan di dalamnya untuk geoanalitik, pengembangan jaringan, manajemen kualitas, pemasaran yang ditargetkan, mempelajari informasi dari pusat kontak, mengelola arus keluar klien dan solusi anti-penipuan / anti-spam.

Di sektor bisnis lain, semuanya hampir sama - analisis yang tepat waktu dan andal penting untuk mendapatkan keuntungan. Dalam perdagangan, misalnya, setiap orang mencoba untuk mempersonalisasi pelanggan, mendistribusikan kartu diskon untuk ini, mengumpulkan data di mana, apa dan kapan seseorang membeli, dll. Dengan menganalisis susunan informasi dari semua saluran ini, kita dapat membandingkannya, membangun model dan membuat keputusan yang mengarah pada pertumbuhan laba.
Ambang entri
Saat ini, majikan mana pun membutuhkan analis untuk memahami apa itu SQL. Jika Anda tahu ANSI SQL, maka Anda bisa disebut pengguna Vertica yang percaya diri. Jika Anda dapat membangun model dengan Python dan R, maka Anda hanyalah "tukang pijat" data. Jika Anda telah menguasai Linux dan memiliki pengetahuan dasar tentang administrasi Vertica, maka Anda dapat bekerja sebagai administrator. Secara umum, ambang pintu masuk di Vertica rendah, tetapi, tentu saja, semua nuansa hanya dapat ditemukan dengan mengisi tangan selama operasi.
Arsitektur perangkat keras
Pertimbangkan Vertica level-klaster. DBMS ini menyediakan pemrosesan data paralel besar-besaran (MPP) dalam arsitektur komputasi terdistribusi - "shared-nothing" - di mana, pada prinsipnya, setiap node siap untuk mengambil fungsi dari node lainnya. Sifat utama:
- Tidak ada titik kegagalan tunggal
- setiap node independen dan independen,
- Tidak ada titik koneksi tunggal untuk seluruh sistem,
- node infrastruktur digandakan,
- data pada node cluster disalin secara otomatis.
Cluster berskala linear tanpa masalah. Kami cukup meletakkan server di rak dan menghubungkannya melalui antarmuka grafis. Selain server serial, penyebaran ke mesin virtual juga dimungkinkan. Apa yang bisa dicapai dengan ekstensi?
- Volume bertambah untuk data baru
- Tambah beban kerja maksimum
- Meningkatkan daya tahan. Semakin banyak node dalam cluster, semakin kecil kemungkinan cluster gagal karena kegagalan, dan oleh karena itu, semakin dekat kita untuk memastikan ketersediaan 24/7.
Tetapi ada beberapa hal yang perlu dipertimbangkan. Secara berkala, node harus dihapus dari cluster untuk pemeliharaan. Kasus lain yang cukup umum di organisasi besar adalah server tidak lagi bergaransi dan beralih dari lingkungan produktif ke semacam pengujian. Di tempat mereka ada yang baru di bawah garansi pabrik. Berdasarkan hasil dari semua operasi ini, penyeimbangan diperlukan. Ini adalah proses di mana data didistribusikan kembali antara node - sesuai, beban kerja didistribusikan kembali. Ini adalah proses yang intensif sumber daya, dan pada kelompok dengan sejumlah besar data, ini dapat sangat mengurangi kinerja. Untuk menghindari ini, Anda harus memilih jendela layanan - waktu ketika beban minimal, dalam hal ini pengguna tidak akan melihatnya.
Proyeksi
Untuk memahami bagaimana data disimpan di Vertica, Anda perlu berurusan dengan salah satu konsep dasar - proyeksi.
Unit logis dari penyimpanan informasi adalah diagram, tabel, dan tampilan. Unit fisik adalah proyeksi. Proyeksi datang dalam beberapa jenis:
- Proyeksi super
- Proyeksi-Permintaan Khusus
- Proyeksi Agregat
Saat membuat tabel apa pun,
proyeksi super dibuat secara otomatis yang berisi semua kolom tabel kami. Jika Anda perlu mempercepat proses biasa, kami dapat membuat
proyeksi berorientasi permintaan khusus yang akan berisi, katakanlah, 3 dari 10 kolom.
Tipe ketiga juga ditujukan untuk
proyeksi akselerasi -
agregat . Saya tidak akan masuk ke subclass mereka - ini tidak terlalu menarik. Saya ingin segera memperingatkan Anda bahwa tidak ada gunanya untuk terus-menerus menyelesaikan masalah Anda dengan eksekusi permintaan melalui pembuatan proyeksi baru. Akhirnya, cluster akan mulai melambat.
Saat membuat proyeksi, kita perlu mengevaluasi apakah permintaan kita memiliki cukup proyeksi super. Jika kami masih ingin bereksperimen, kami secara ketat menambahkan satu proyeksi baru. Jika masalah muncul, akan lebih mudah untuk menemukan akar masalahnya. Untuk tabel besar, buat proyeksi tersegmentasi. Ini dibagi menjadi beberapa segmen yang didistribusikan di beberapa node, yang meningkatkan toleransi kesalahan dan meminimalkan beban pada satu node. Jika tablet kecil, maka lebih baik melakukan proyeksi non-segmentasi. Mereka sepenuhnya disalin ke setiap node, dan dengan demikian kinerja meningkat. Saya akan melakukan reservasi: dalam hal Vertica, meja "kecil" adalah sekitar 1 juta baris.
Toleransi kesalahan
Toleransi kesalahan di Vertica diimplementasikan menggunakan mekanisme K-Safety. Ini cukup sederhana dalam hal deskripsi, tetapi rumit dalam hal bekerja di level mesin. Ini dapat dikontrol menggunakan parameter K-Safety - dapat memiliki nilai 0, 1 atau 2. Parameter ini menetapkan jumlah salinan data proyeksi tersegmentasi.
Salinan proyeksi disebut proyeksi teman. Saya mencoba menerjemahkan frasa ini melalui Yandex-translator dan ternyata seperti “sidekick projection”. Google menawarkan opsi dan lebih menarik. Biasanya, proyeksi ini disebut pasangan atau tetangga, sesuai dengan tujuan fungsionalnya. Ini adalah proyeksi yang hanya disimpan pada node tetangga dan dengan demikian dicadangkan. Proyeksi non-segmented tidak memiliki proyeksi teman - mereka disalin sepenuhnya.
Bagaimana cara kerjanya? Pertimbangkan sekelompok lima mesin. Biarkan K-safety sama dengan 1.

Node diberi nomor, dan di bawahnya adalah proyeksi mitra tertulis yang disimpan pada mereka. Misalkan kita memiliki satu simpul yang terputus. Apa yang akan terjadi

Node 1 berisi proyeksi node 2. Oleh karena itu, beban pada node 1 akan bertambah, tetapi cluster tidak akan berhenti bekerja. Dan sekarang situasi ini:
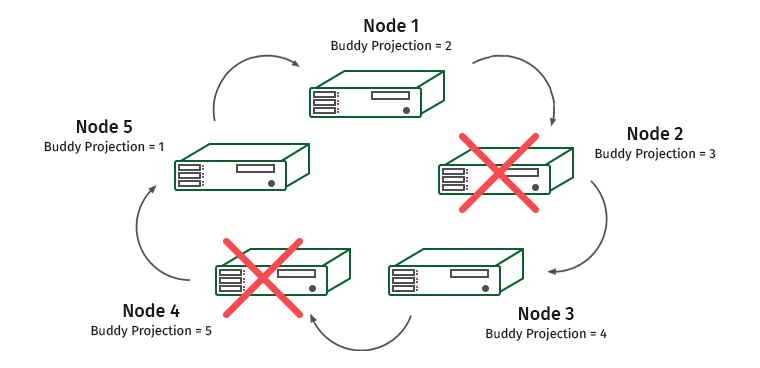
Node 3 berisi proyeksi node 4, dan node 1 dan 3 akan kelebihan beban.
Kami menyulitkan tugas. K-Safety = 2, nonaktifkan dua node yang berdekatan.
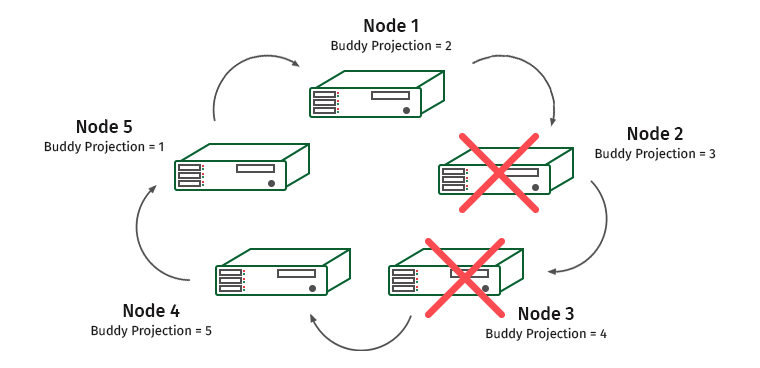
Di sini simpul 1 dan 4 akan kelebihan beban (simpul 2 berisi proyeksi simpul 1, dan simpul 3 berisi proyeksi simpul 4).
Dalam situasi seperti itu, mesin sistem mengakui bahwa salah satu node tidak merespons, dan beban ditransfer ke node tetangga. Ini akan digunakan sampai node dikembalikan lagi. Setelah ini terjadi, beban dan data didistribusikan kembali. Segera setelah kami kehilangan lebih dari setengah cluster atau node yang berisi semua salinan beberapa data, cluster bangun.
Penyimpanan data logis
Vertica memiliki area penyimpanan yang dioptimalkan untuk penulisan, area yang dioptimalkan untuk membaca, dan mekanisme Tuple Mover yang memungkinkan data mengalir dari yang pertama ke yang kedua.
Saat menggunakan operasi COPY, INSERT, UPDATE, kami secara otomatis berakhir di WOS (Write Optimized Store), area di mana data tidak dioptimalkan untuk dibaca dan diurutkan hanya jika diminta, disimpan tanpa kompresi atau pengindeksan. Jika volume data terlalu besar untuk area WOS, maka menggunakan pernyataan DIRECT tambahan, mereka harus segera ditulis ke ROS. Kalau tidak, WOS akan penuh dan kita akan crash.
Setelah waktu yang ditentukan dalam pengaturan berakhir, data dari WOS mengalir ke ROS (Read Optimized Store) - struktur penyimpanan disk yang dioptimalkan dan berorientasi baca. ROS menyimpan sebagian besar data, di sini disortir dan dikompresi. Data ROS dibagi ke dalam wadah penyimpanan. Wadah adalah serangkaian garis yang dibuat oleh operator terjemahan (COPY DIRECT), dan disimpan dalam kelompok file tertentu.
Terlepas dari di mana data ditulis - dalam WOS atau di ROS - mereka segera tersedia. Tetapi membaca dari WOS lebih lambat karena data tidak dikelompokkan di sana.

Tuple Mover adalah alat pembersih yang melakukan dua operasi:
- Moveout - memampatkan dan mengurutkan data dalam WOS, memindahkannya ke ROS dan membuat wadah baru untuk mereka di ROS.
- Mergeout - menyapu di belakang kami saat kami menggunakan DIRECT. Kami tidak selalu dapat memuat begitu banyak informasi untuk mendapatkan wadah ROS yang besar. Oleh karena itu, secara berkala menggabungkan wadah ROS kecil menjadi yang lebih besar, membersihkan data yang ditandai untuk dihapus, sambil bekerja di latar belakang (sesuai dengan waktu yang ditentukan dalam konfigurasi).
Apa manfaat dari penyimpanan kolom?
Jika kita membaca baris, maka, misalnya, untuk menjalankan perintah
SELECT 1,11,15 from table1
kita harus membaca seluruh tabel. Ini adalah sejumlah besar informasi. Dalam hal ini, pendekatan kolom lebih menguntungkan. Ini memungkinkan Anda untuk menghitung hanya tiga kolom yang kami butuhkan, menghemat memori dan waktu.

Alokasi sumber daya
Untuk menghindari masalah, pengguna perlu dibatasi sedikit. Selalu ada kemungkinan bahwa pengguna akan menulis permintaan berat yang akan melahap semua sumber daya. Secara default, Vertica menempati bagian penting dari area Umum, dan di samping itu, area terpisah untuk Tuple Mover, WOS dan proses sistem (pemulihan, dll.) Disorot.
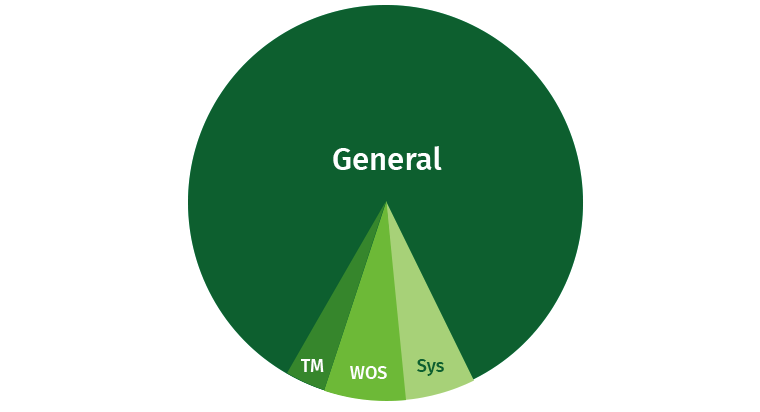
Mari kita coba berbagi sumber daya ini. Kami membuat area untuk penulis, untuk pembaca, dan untuk pertanyaan yang lambat, prioritas rendah.

Jika kita melihat tabel sistem di mana sumber daya kita disimpan - sumber daya kolam - maka kita akan melihat banyak parameter yang Anda dapat menyesuaikan semuanya dengan lebih halus. Pada awalnya, Anda tidak harus mempelajari ini, lebih baik membatasi diri Anda untuk memotong memori untuk tugas-tugas tertentu. Ketika Anda mendapatkan pengalaman dan 100% yakin bahwa Anda melakukan semuanya dengan benar, Anda dapat bereksperimen.
Pengaturan yang tipis termasuk prioritas eksekusi, sesi kompetitif, dan jumlah memori yang dialokasikan. Dan bahkan dengan prosesor, kami dapat memperbaiki sesuatu. Untuk bekerja dengan pengaturan ini, Anda perlu kepercayaan penuh pada kebenaran tindakan Anda, jadi lebih baik untuk meminta dukungan bisnis dan memiliki hak untuk melakukan kesalahan.
Di bawah ini adalah contoh permintaan yang dengannya Anda dapat melihat pengaturan kumpulan General:
dbadmin => select * FROM resource_pools WHERE NAME = 'general';
-[ RECORD 1 ]------------+---------------
pool_id | 45035996273721212
name | general
is_internal | t
memorysize |
maxmemorysize | 30G
executionparallelism | AUTO
priority | 0
runtimepriority | MEDIUM
runtimeprioritythreshold | 2
queuetimeout | 0:05
plannedconcurrency | 10
maxconcurrency | 20
runtimecap |
singleinitiator | f
cpuaffinityset |
cpuaffinitymode | ANY
cascadeto |ANSI SQL dan fitur lainnya
- Vertica memungkinkan Anda untuk menulis dalam SQL-99 - semua fungsi didukung.
- Verica memiliki kemampuan analitik yang hebat - bahkan alat pembelajaran mesin disertakan
- Vertica dapat mengindeks teks
- Vertica memproses data semi-terstruktur
Integrasi
Vertica, seperti semua alat saat ini, terintegrasi secara serius dengan sistem lain. Mampu bekerja dengan baik dengan HDFS (Hadoop). Pada versi sebelumnya, Vertica hanya dapat mengunduh data dari HDFS dari format tertentu, tetapi sekarang ia dapat melakukan segalanya, bekerja dengan semua format, misalnya, ORC dan Parket. Ia bahkan dapat melampirkan file sebagai tabel eksternal dan menyimpan datanya dalam wadah ROS langsung pada HDFS. Dalam versi kedelapan Vertica, optimasi signifikan dari kecepatan bekerja dengan HDFS, katalog metadata dan penguraian format ini dilakukan. Anda bisa membangun cluster Vertica langsung di cluster Hadoop.
Dimulai dengan versi 7.2 Vertica dapat bekerja dengan Apache Kafka - jika seseorang membutuhkan broker pesan.
Vertica 8 memiliki dukungan penuh untuk Spark. Dimungkinkan untuk menyalin data dari Spark ke Vertica dan sebaliknya.
Kesimpulan
Vertica adalah pilihan yang baik untuk bekerja dengan data besar yang tidak memerlukan banyak pengetahuan input. DBMS ini memiliki kemampuan analitis yang luas. Dari minus - solusi ini bukan open source, tetapi Anda dapat mencoba menggunakan secara gratis dengan batas 1 TB dan tiga node - ini cukup untuk memahami apakah Anda memerlukan Vertica atau tidak.