Semua sistem moderasi modern menggunakan
crowdsourcing atau pembelajaran mesin yang sudah menjadi klasik. Pada pelatihan ML berikutnya di Yandex, Konstantin Kotik, Igor Galitsky dan Alexey Noskov berbicara tentang partisipasi mereka dalam kontes untuk identifikasi massa komentar ofensif. Kompetisi diadakan di platform Kaggle.
- Halo semuanya! Nama saya Konstantin Kotik, saya seorang ilmuwan data di perusahaan Button of Life, seorang mahasiswa dari departemen fisika dan Sekolah Pascasarjana Bisnis dari Universitas Negeri Moskow.
Hari ini, kolega kami, Igor Galitsky dan Alexei Noskov, akan memberi tahu Anda tentang kompetisi Toxic Comment Classification Challenge, di mana tim DecisionGuys kami berada di posisi 10 di antara 4.551 tim.
Diskusi daring tentang topik yang penting bagi kami bisa jadi sulit. Penghinaan, agresi, dan pelecehan yang terjadi online sering memaksa banyak orang untuk meninggalkan pencarian berbagai pendapat yang sesuai tentang masalah yang menarik bagi mereka, untuk menolak mengekspresikan diri.
Banyak platform berjuang untuk berkomunikasi secara efektif secara online, tetapi ini sering menyebabkan banyak komunitas menutup komentar pengguna.
Satu tim peneliti dari Google dan perusahaan lain sedang mengerjakan alat untuk membantu meningkatkan diskusi online.
Salah satu trik yang mereka fokuskan adalah mengeksplorasi perilaku negatif online seperti komentar beracun. Ini adalah komentar yang bisa menyinggung, tidak sopan, atau bisa memaksa pengguna untuk meninggalkan diskusi.

Hingga saat ini, grup ini telah mengembangkan API publik yang dapat menentukan tingkat toksisitas suatu komentar, tetapi model mereka saat ini masih membuat kesalahan. Dan dalam kompetisi ini, kami, para Kegglers, ditantang untuk membangun model yang mampu mengidentifikasi komentar yang berisi ancaman, kebencian, penghinaan dan sejenisnya. Dan idealnya, model ini harus lebih baik daripada model saat ini untuk API mereka.
Kami memiliki tugas pemrosesan teks: untuk mengidentifikasi dan kemudian mengklasifikasikan komentar. Sebagai sampel pelatihan dan pengujian, komentar diberikan dari halaman diskusi Wikipedia. Ada sekitar 160 ribu komentar di kereta, 154 ribu di tes.

Sampel pelatihan ditandai sebagai berikut. Setiap komentar memiliki enam label. Label mengambil nilai 1 jika komentar mengandung toksisitas jenis ini, 0 sebaliknya. Dan mungkin semua labelnya nol, sebuah kasus komentar yang memadai. Atau mungkin satu komentar mengandung beberapa jenis toksisitas, yang segera menjadi ancaman dan kecabulan.
Karena kenyataan bahwa kami sedang mengudara, saya tidak dapat menunjukkan contoh spesifik dari kelas-kelas ini. Mengenai sampel uji, untuk setiap komentar perlu diprediksi kemungkinan masing-masing jenis toksisitas.
Metrik kualitas adalah ROC AUC rata-rata untuk jenis-jenis toksisitas, yaitu rata-rata aritmatika ROC AUC untuk setiap kelas secara terpisah.
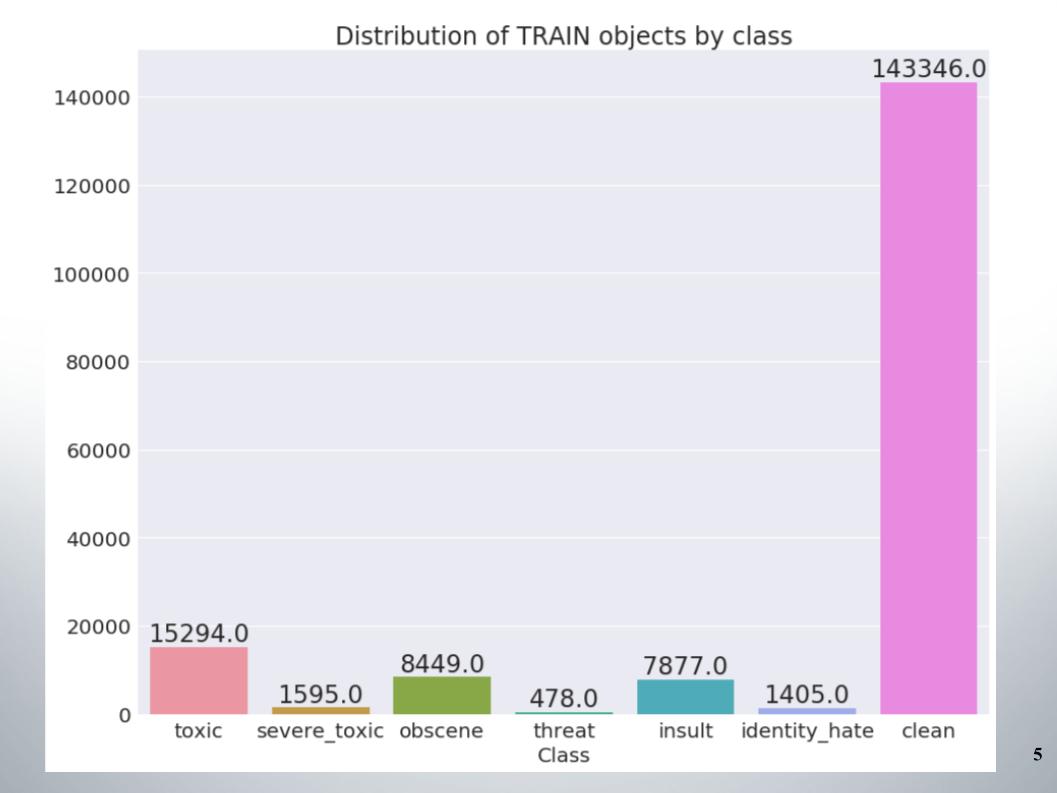
Berikut adalah distribusi objek berdasarkan kelas dalam set pelatihan. Dapat dilihat bahwa data tersebut sangat tidak seimbang. Saya harus segera mengatakan bahwa tim kami mencetak sampel metode untuk bekerja dengan data yang tidak seimbang, misalnya, oversampling atau undersampling.

Saat membangun model, saya menggunakan preprocessing data dua tahap. Tahap pertama adalah preprocessing dasar data, ini adalah transformasi tampilan pada slide, ini membawa teks ke huruf kecil, menghapus tautan, alamat IP, angka dan tanda baca.

Untuk semua model, preprocessing data dasar ini digunakan. Pada tahap kedua, sebagian pra-pemrosesan data dilakukan - mengganti emotikon dengan kata-kata yang sesuai, menguraikan singkatan, mengoreksi kesalahan ketik dalam kata-kata kotor, membawa berbagai jenis tikar ke bentuk yang sama, dan juga menghapus gambar. Di beberapa komentar, tautan ke gambar ditunjukkan, kami cukup menghapusnya.
Untuk masing-masing model, preprocessing data parsial dan berbagai elemen yang digunakan. Semua ini dilakukan agar model dasar untuk mengurangi korelasi silang antara model dasar ketika membangun komposisi lebih lanjut.
Mari kita beralih ke bagian yang paling menarik - membangun model.
Saya segera meninggalkan pendekatan tas kata-kata klasik. Karena kenyataan bahwa dalam pendekatan ini setiap kata adalah atribut yang terpisah. Pendekatan ini tidak memperhitungkan urutan kata umum, diasumsikan bahwa kata-kata itu independen. Dalam pendekatan ini, generasi teks terjadi sehingga ada beberapa distribusi kata-kata, kata dipilih secara acak dari distribusi ini dan dimasukkan ke dalam teks.
Tentu saja, ada proses generatif yang lebih kompleks, tetapi esensinya tidak berubah - pendekatan ini tidak memperhitungkan urutan kata umum. Anda dapat membuka engrams, tetapi hanya urutan kata yang akan diperhitungkan di sana, dan tidak umum. Oleh karena itu, saya juga memahami rekan tim saya bahwa mereka perlu menggunakan sesuatu yang lebih pintar.
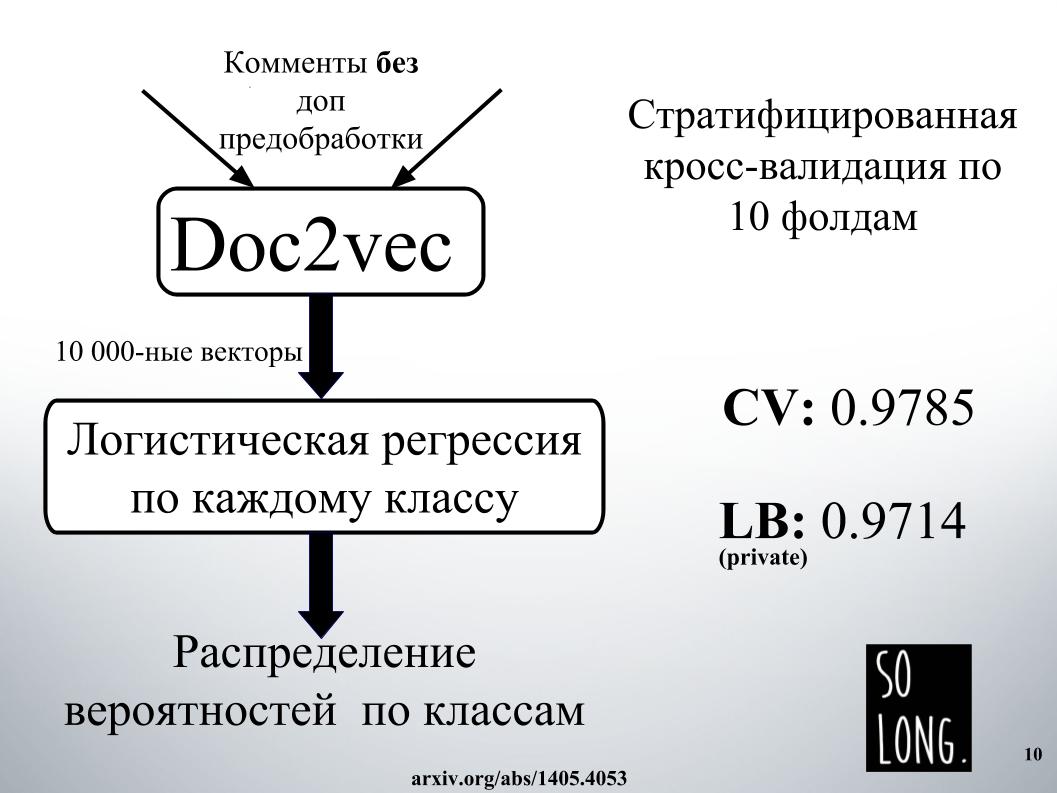
Hal pintar pertama yang terpikir oleh saya adalah menggunakan representasi vektor menggunakan Doc2vec. Ini adalah Word2vec plus vektor yang memperhitungkan keunikan dokumen tertentu. Dalam artikel aslinya, vektor ini disebut sebagai paragraf id.
Kemudian, menurut representasi vektor seperti itu, regresi logistik dipelajari, di mana setiap dokumen diwakili oleh vektor 10.000 dimensi. Penilaian kualitas dilakukan pada validasi silang sepuluh kali lipat, itu bertingkat, dan penting untuk dicatat bahwa regresi logistik dipelajari untuk setiap kelas, enam masalah klasifikasi dipecahkan secara terpisah. Dan pada akhirnya, hasilnya adalah distribusi probabilitas berdasarkan kelas.
Regresi logistik telah dilatih untuk waktu yang sangat lama. Saya biasanya tidak masuk ke dalam RAM. Di fasilitas Igor, mereka menghabiskan satu hari di suatu tempat untuk mendapatkan hasilnya, seperti pada slide. Untuk alasan ini, kami segera menolak untuk menggunakan Doc2vec karena harapan yang tinggi, meskipun dapat ditingkatkan 1000 jika komentar dengan preprocessing data tambahan dilakukan.

Yang lebih pintar yang kami dan kompetitor lain gunakan adalah jaringan saraf berulang. Mereka secara berurutan menerima kata-kata di pintu masuk, memperbarui keadaan tersembunyi mereka setelah setiap kata. Igor dan saya menggunakan jaringan berulang GRU untuk fastText kata embedding, yang khusus karena memecahkan banyak masalah klasifikasi biner independen. Memprediksi ada atau tidak adanya kata konteks secara mandiri.
Kami juga melakukan penilaian kualitas pada validasi silang sepuluh kali lipat, itu tidak bertingkat di sini, dan di sini distribusi probabilitas segera diperoleh oleh kelas. Setiap masalah klasifikasi biner tidak diselesaikan secara terpisah, tetapi vektor enam dimensi segera dihasilkan. Itu adalah salah satu model tunggal terbaik kami.
Anda bertanya, apa rahasia kesuksesan?
Itu terdiri dari campuran, ada banyak, dengan susun, dan jaringan dalam pendekatan. Pendekatan jaringan perlu digambarkan sebagai grafik terarah.
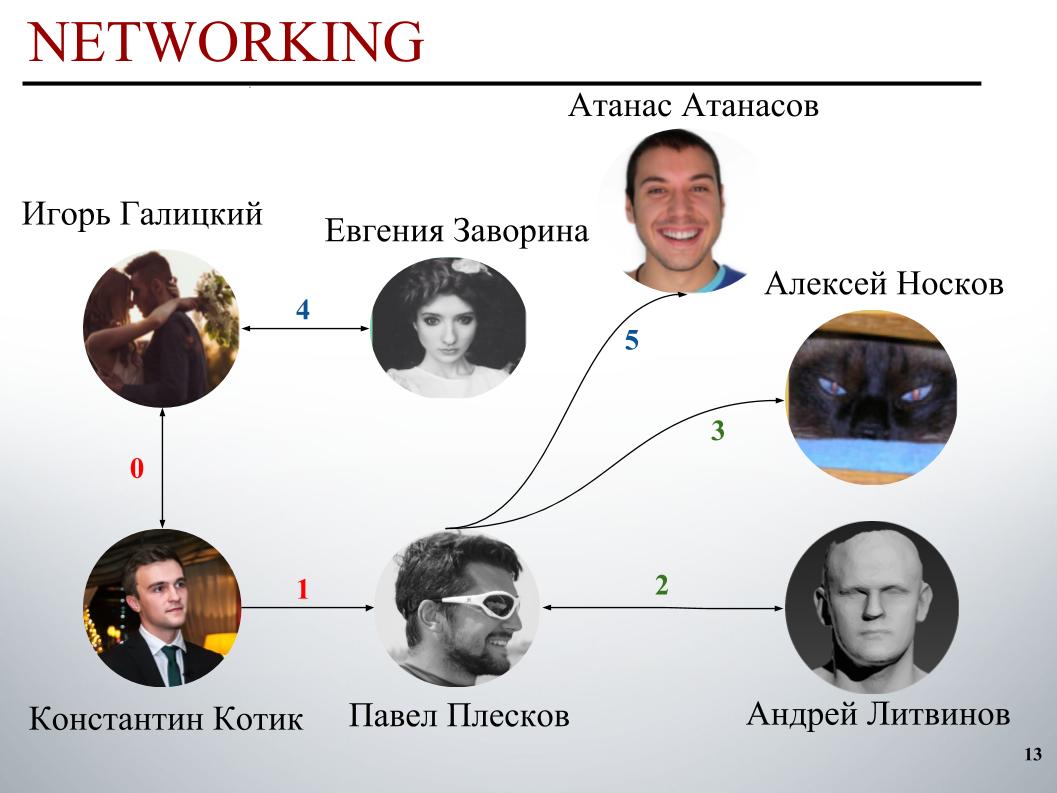
Pada awal kompetisi, tim DecisionGuys terdiri dari dua orang. Kemudian Pavel Pleskov di saluran ODS Slack menyatakan keinginan bahwa ia ingin bekerja sama dengan seseorang dari 200 teratas. Pada saat itu kami berada di suatu tempat di tempat ke 157, dan Pavel Pleskov di tempat ke 154, di suatu tempat di lingkungan itu. Igor memperhatikan keinginannya untuk bergabung, dan saya mengundangnya ke tim. Kemudian Andrey Litvinov bergabung dengan kami, lalu Pavel mengundang Grandmaster Alexei Noskov ke tim kami. Igor - Eugene. Dan mitra terakhir tim kami adalah Bulgaria Atanas Atanasov, dan ini adalah hasil dari ansambel internasional manusia.
Sekarang Igor Galitsky akan menceritakan bagaimana ia mengajar gru, secara lebih rinci ia akan berbicara tentang ide dan pendekatan Pavel Pleskov, Andrei Litvinov dan Atanas Atanasov.
Igor Galitsky:
- Saya seorang ilmuwan data di Epoch8, dan saya akan berbicara tentang sebagian besar arsitektur yang kami gunakan.
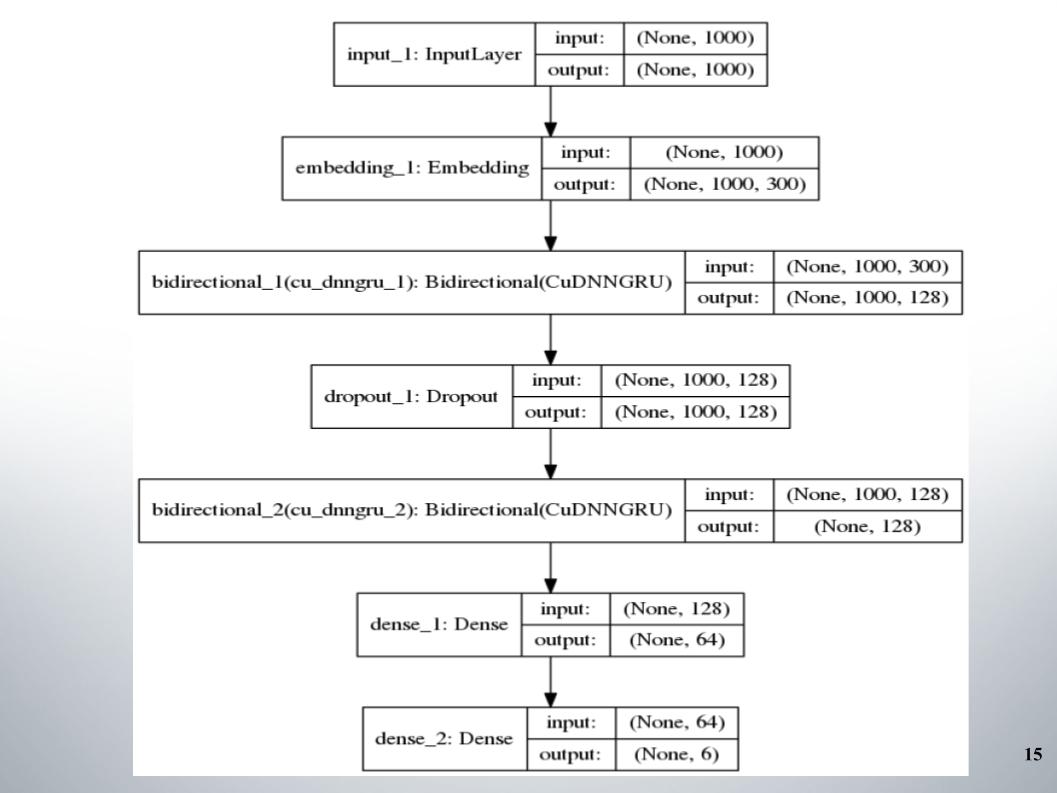
Semuanya dimulai dengan standar gru directional dengan dua lapisan, hampir semua tim menggunakannya, dan fastText, fungsi aktivasi EL, digunakan sebagai embedding.
Tidak ada yang istimewa untuk dikatakan, arsitektur sederhana, tanpa embel-embel. Mengapa dia memberi kami hasil yang begitu baik sehingga kami tetap berada di posisi 150 selama beberapa waktu? Kami memiliki preprocessing teks yang baik. Itu perlu untuk melanjutkan.
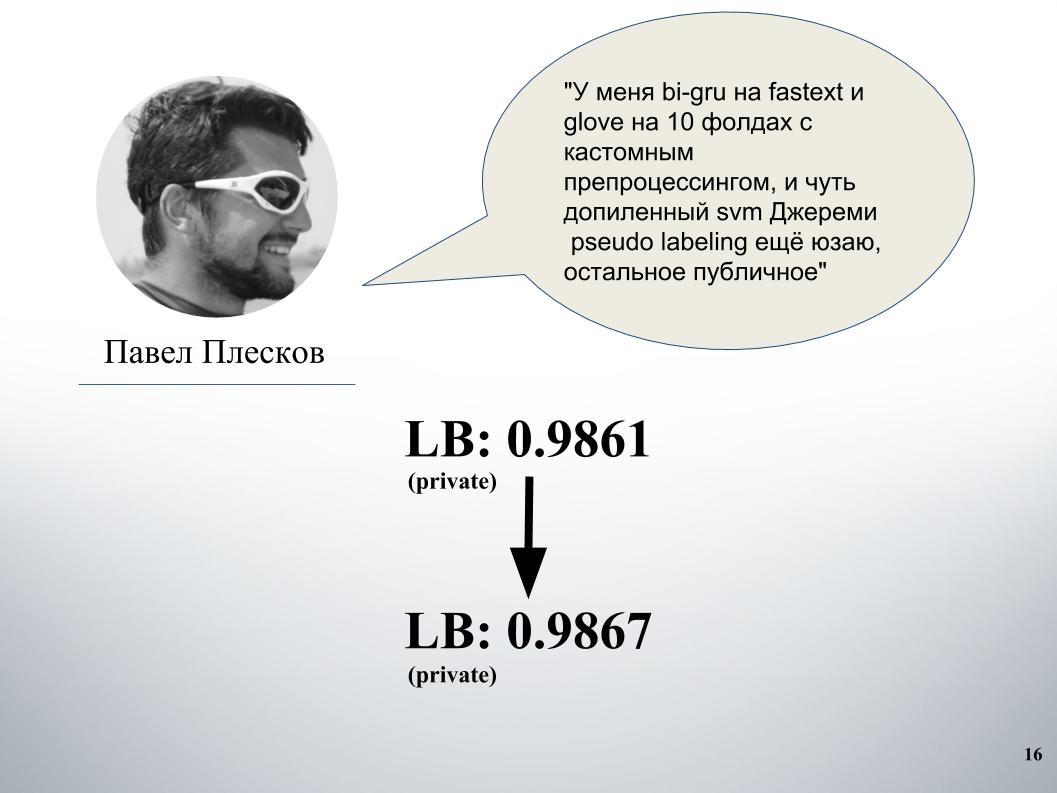
Paul punya pendekatan sendiri. Setelah menyatu dengan kami, ini memberikan peningkatan yang signifikan. Sebelum itu, kami memiliki gru dan model blending di Doc2vec, itu memberi 61 LB.
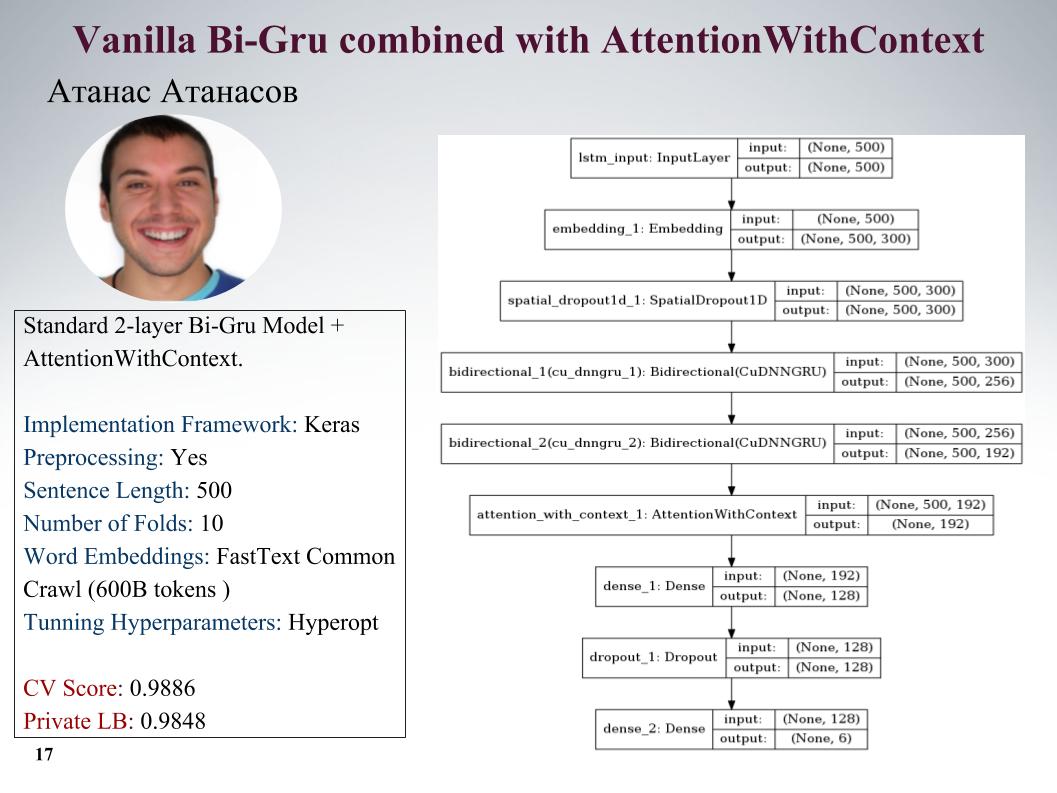
Saya akan memberi tahu Anda tentang pendekatan Atanas Atanasov, ia secara langsung penggemar artikel baru. Di sini adalah gru dengan perhatian, semua parameter pada slide. Dia memiliki banyak pendekatan yang sangat keren, tetapi sampai saat terakhir dia menggunakan preprocessing-nya, dan semua laba diratakan. Kecepatan pada slide.
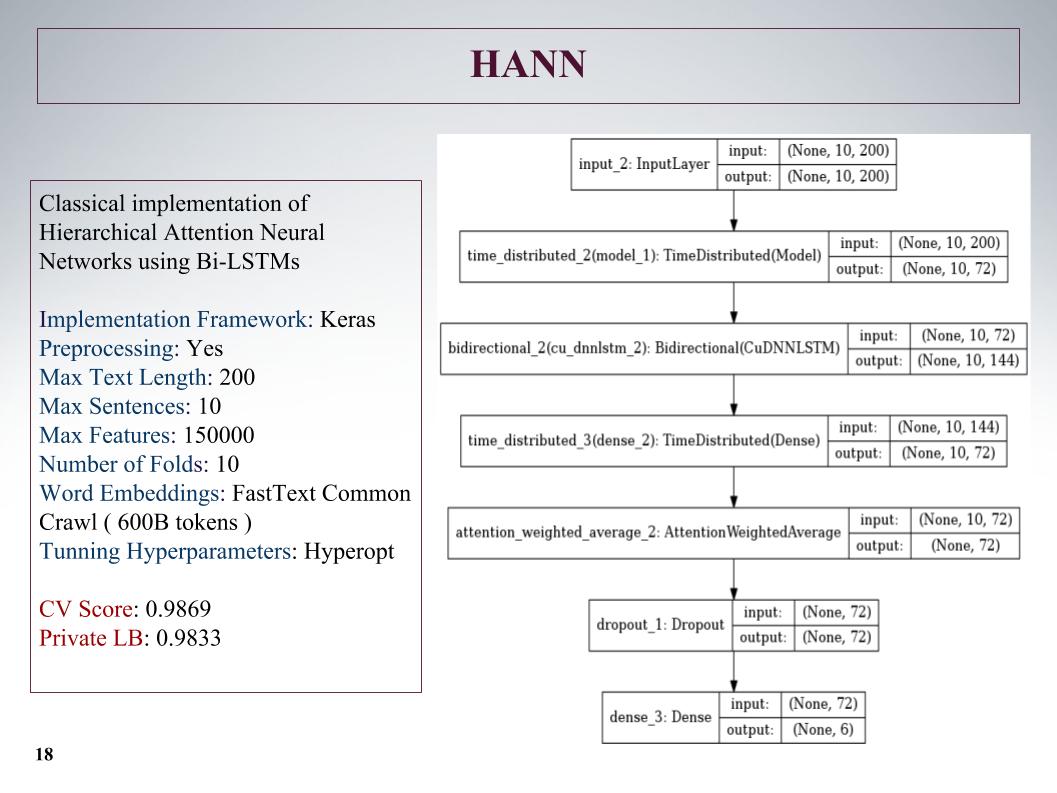
Lalu ada perhatian hierarkis, itu menunjukkan hasil yang lebih buruk, karena pada awalnya itu adalah jaringan untuk mengklasifikasikan dokumen yang terdiri dari kalimat. Dia mengacaukannya, tetapi pendekatannya tidak terlalu.
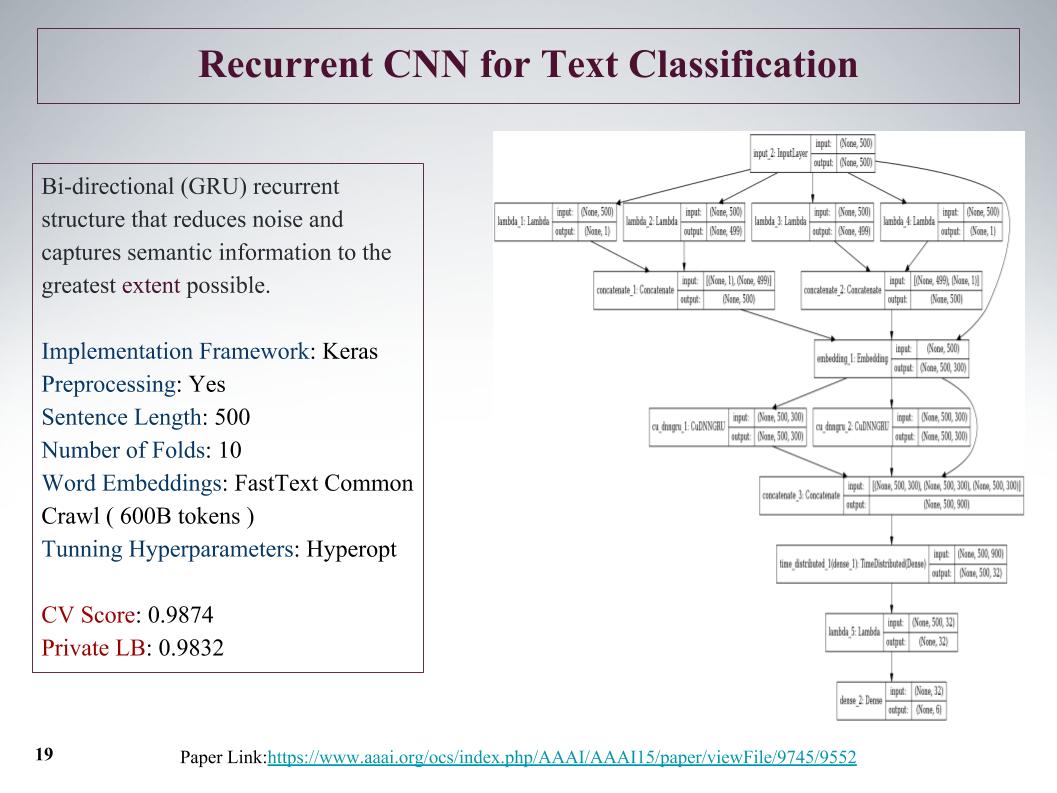
Ada pendekatan yang menarik, kami awalnya bisa mendapatkan fitur dari penawaran dari awal dan dari akhir. Dengan bantuan konvolusi, lapisan konvolusional, kami secara terpisah mendapatkan fitur di kiri dan kanan pohon. Ini dari awal dan akhir kalimat, kemudian mereka bergabung dan kembali dijalankan melalui gru.

Juga Bi-GRU dengan blok perhatian. Ini adalah salah satu yang terbaik pada jaringan pribadi yang cukup dalam, menunjukkan hasil yang baik.

Pendekatan selanjutnya adalah menyoroti fitur sebanyak mungkin? Setelah lapisan jaringan berulang, kami membuat tiga lapisan konvolusi paralel. Dan di sini kami mengambil kalimat yang tidak terlalu lama, memotongnya menjadi 250, tetapi karena tiga belokan ini memberikan hasil yang baik.

Itu adalah jaringan terdalam. Seperti yang dikatakan Atanas, dia hanya ingin mengajarkan sesuatu yang besar dan menarik. Kisi konvolusional biasa yang dipelajari dari fitur teks, hasilnya tidak ada yang istimewa.

Ini adalah pendekatan baru yang agak menarik, pada 2017 ada artikel tentang topik ini, itu digunakan untuk ImageNet, dan di sana itu memungkinkan kami untuk meningkatkan hasil sebelumnya sebesar 25%. Fitur utamanya adalah lapisan kecil diluncurkan sejajar dengan blok konvolusional, yang mengajarkan bobot untuk setiap konvolusi di blok ini. Dia memberikan pendekatan yang sangat keren, meskipun memotong kalimat.
Masalahnya adalah bahwa panjang maksimum kalimat dalam tugas-tugas ini mencapai 1.500 kata, ada komentar yang sangat besar. Tim lain juga memiliki pemikiran tentang bagaimana menangkap tawaran besar ini, bagaimana menemukan, karena semuanya tidak terlalu didorong. Dan banyak yang mengatakan bahwa pada akhir kalimat ada INFA yang sangat penting. Sayangnya, dalam semua pendekatan ini, ini tidak diperhitungkan, karena awalnya diambil. Mungkin ini akan memberikan peningkatan lebih lanjut.

Berikut adalah arsitektur AC-BLSTM. Intinya adalah bahwa jika pembagian yang lebih rendah menjadi dua bagian, di samping perhatian, adalah penarikan yang cerdas, tetapi secara paralel masih ada yang normal, dan ini semua dikonkretkan. Hasil juga bagus.

Dan Atanas seluruh kebun binatang model, maka itu campuran keren. Selain model itu sendiri, saya menambahkan beberapa fitur teks, biasanya panjang, jumlah huruf kapital, jumlah kata-kata buruk, jumlah karakter, semuanya ditambahkan. Validasi silang lima kali lipat, dan mendapat hasil yang sangat baik pada LB pribadi 0,9867.
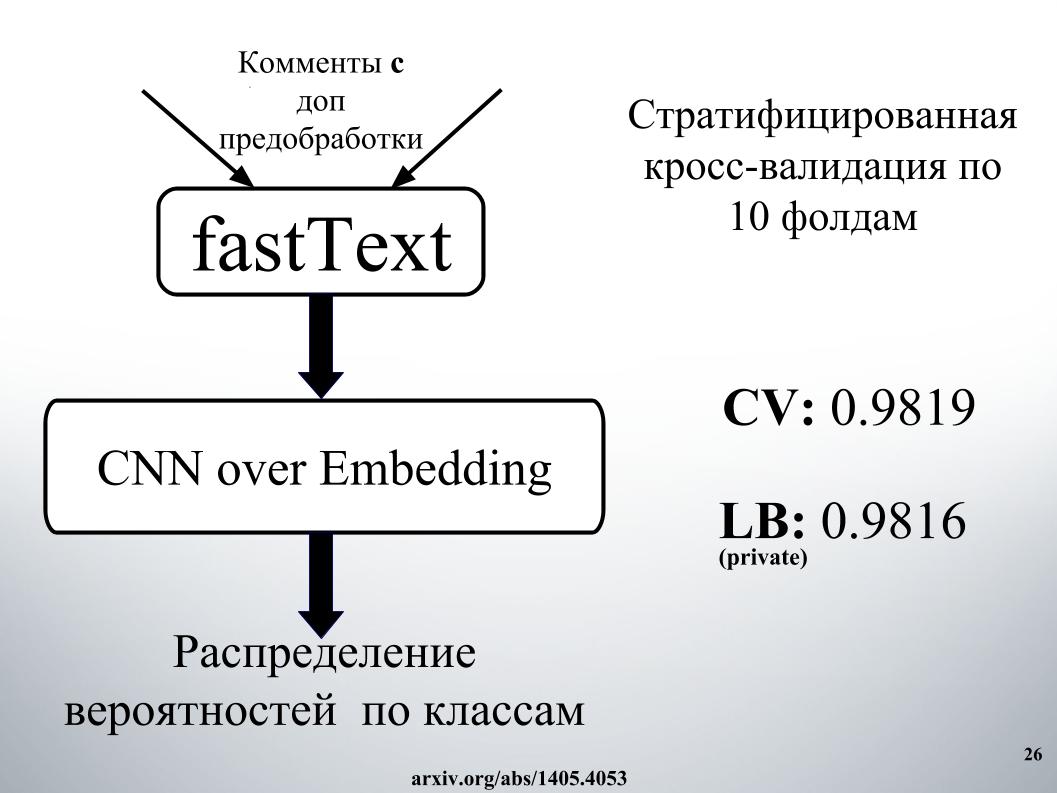
Dan pendekatan kedua, dia mengajar dengan embedding yang berbeda, tetapi hasilnya lebih buruk. Sebagian besar semua orang menggunakan fastText.
Saya ingin berbicara tentang pendekatan rekan kami yang lain, Andrei, dengan julukan Laol di ODS. Dia mengajar banyak kernel publik, dia meminumnya seolah-olah dia keluar dari dirinya sendiri, dan ini benar-benar menghasilkan hasil yang sangat keren. Anda tidak bisa melakukan semua ini, tetapi hanya mengambil sekelompok kernel publik yang berbeda, bahkan pada id-idf, ada semua jenis konvolusi gru.
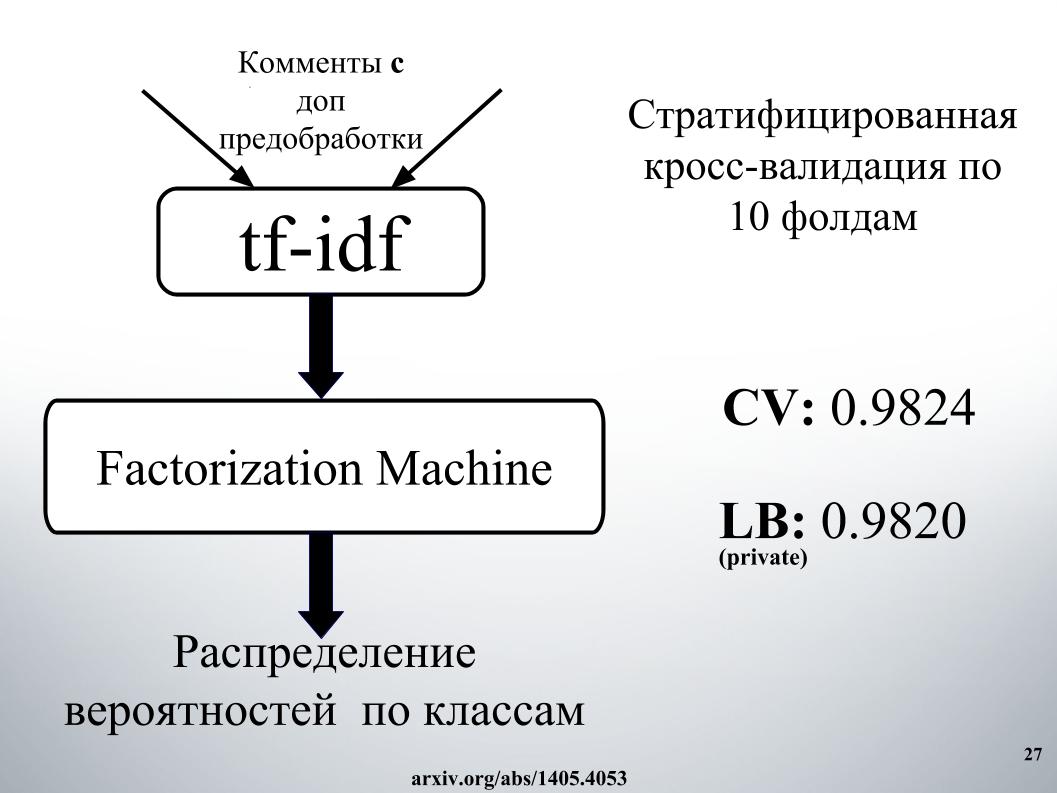
Dia memiliki salah satu pendekatan terbaik, dengan yang kami tinggal untuk waktu yang lama di 15 besar, sampai Alexey dan Atanas bergabung dengan kami, ia menggabungkan campuran dan penumpukan semua ini. Dan juga momen yang sangat keren, yang, seperti yang saya pahami, tidak ada tim yang digunakan, kami kemudian juga membuat fitur dari hasil API penyelenggara. Tentang hal ini lebih lanjut beritahu Alex.
Alexey Noskov:
- hai Saya akan memberi tahu Anda tentang pendekatan yang saya gunakan, dan bagaimana kami menyelesaikannya.

Semuanya cukup sederhana bagi saya: 10 lipatan validasi silang, model yang telah dilatih sebelumnya pada vektor yang berbeda dengan preprocessing yang berbeda, sehingga mereka memiliki lebih banyak keragaman dalam ansambel, sedikit augmentasi dan dua siklus pengembangan. Yang pertama, yang pada dasarnya bekerja di awal, melatih sejumlah model, melihat kesalahan validasi silang, tentang contoh apa yang membuat kesalahan jelas, dan memperbaiki preprocessing berdasarkan ini, karena hanya lebih jelas bagaimana cara memperbaikinya.
Dan pendekatan kedua, yang lebih banyak digunakan pada akhirnya, mengajarkan beberapa set model, melihat korelasi, menemukan blok model yang berkorelasi lemah satu sama lain, memperkuat bagian yang terdiri dari mereka. Ini adalah matriks korelasi validasi silang antara model saya.
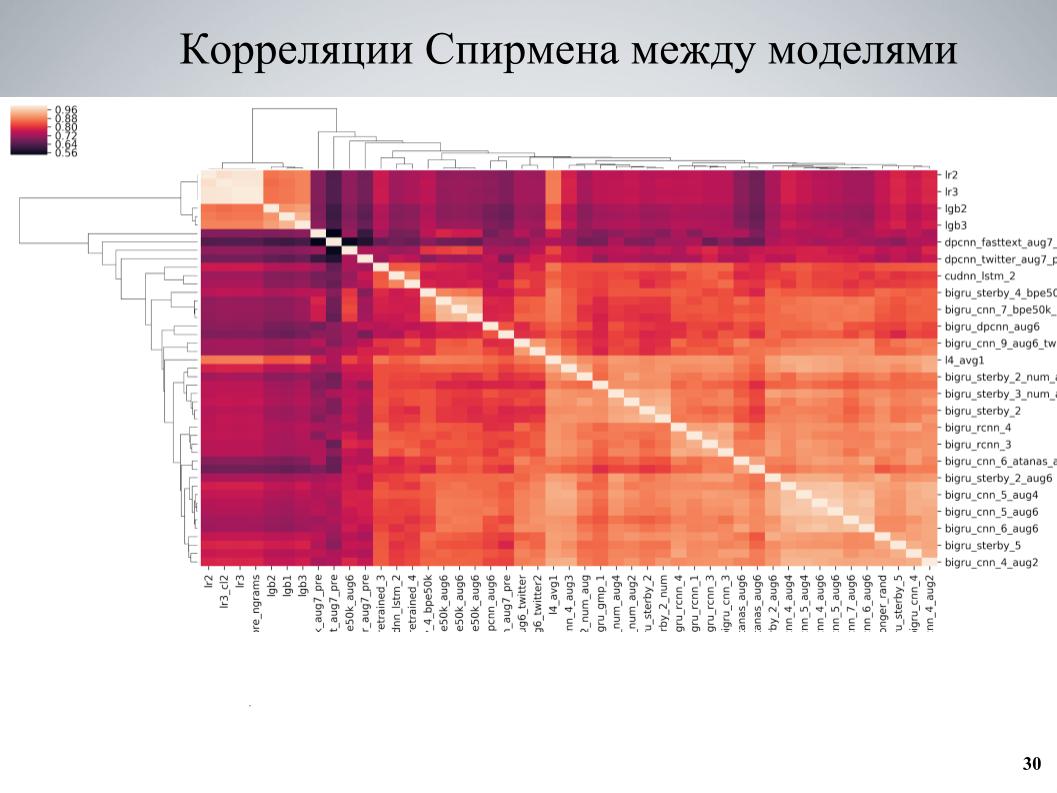
Dapat dilihat bahwa ia memiliki struktur balok di beberapa tempat, sementara beberapa model memiliki kualitas yang baik, mereka berkorelasi lemah dengan yang lain, dan hasil yang sangat baik diperoleh ketika saya mengambil model ini sebagai dasar, mengajari mereka beberapa variasi berbeda yang berbeda dalam berbagai hyperparameter atau preprocessing, dan kemudian ditambahkan ke ansambel.

Untuk augmentasi, ide yang dipublikasikan di forum oleh Pavel Ostyakov paling mencetuskan. Itu terdiri dari fakta bahwa kita dapat mengambil komentar, menerjemahkannya ke bahasa lain, dan kemudian kembali. Sebagai hasil dari terjemahan ganda, sebuah reformulasi diperoleh, ada sesuatu yang sedikit hilang, tetapi secara keseluruhan teks yang sedikit berbeda diperoleh, yang juga dapat diklasifikasikan dan dengan demikian memperluas dataset.
Dan pendekatan kedua, yang tidak banyak membantu, tetapi juga membantu, adalah Anda dapat mencoba untuk mengambil dua komentar sewenang-wenang, biasanya tidak terlalu lama, merekatkan mereka dan mengambil sebagai label pada target kombinasi label atau sedikit semangat di mana hanya ada satu dari mereka berisi label.
Kedua pendekatan ini bekerja dengan baik jika mereka tidak diterapkan sebelumnya ke seluruh set perangkat, tetapi untuk mengubah set contoh yang augmentasi harus diterapkan setiap era. Setiap era dalam proses pembentukan batch, kami memilih, katakanlah, 30% dari contoh yang dijalankan melalui terjemahan. Alih-alih, sebelumnya, di suatu tempat secara paralel sudah ada dalam memori, kami cukup memilih versi terjemahan berdasarkan itu, dan menambahkannya ke batch selama pelatihan.

Perbedaan yang menarik adalah model yang dilatih di BPE. Ada SentencePiece - tokenizer Google yang memungkinkan Anda untuk dipecah menjadi token di mana tidak akan ada UNK sama sekali. Kamus terbatas tempat string dipecah menjadi beberapa token. Jika jumlah kata dalam teks asli lebih besar dari ukuran target kamus, kata-kata itu mulai pecah menjadi potongan-potongan yang lebih kecil, dan pendekatan antara diperoleh antara level karakter dan model level kata.
Dua algoritma konstruksi utama digunakan di sana: BPE dan Unigram. Untuk algoritme BPE, cukup mudah untuk menemukan embeddings pra-trainable di jaringan, dan dengan beberapa kosakata tetap - Saya hanya memiliki kosakata 50k yang baik - Saya juga bisa melatih model yang memberikan yang baik (tidak terdengar - kira-kira. Ed.), Sedikit lebih buruk, dari biasanya di fastText, tetapi mereka berkorelasi sangat lemah dengan yang lainnya dan memberikan dorongan yang baik.
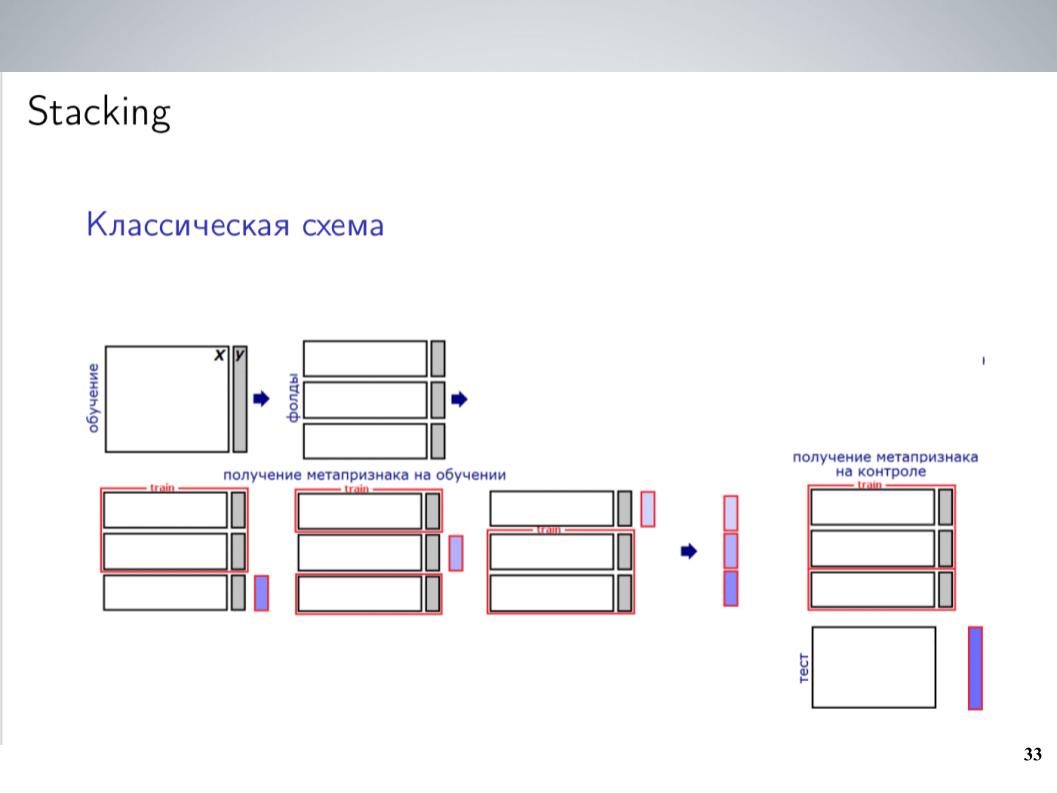
Ini adalah skema penumpukan klasik. Sebagai aturan, untuk sebagian besar kompetisi, sebelum menggabungkan, saya biasa memadukan semua model saya tanpa beban. Ini memberikan hasil terbaik. Tetapi setelah merger, saya bisa mendapatkan skema yang sedikit lebih kompleks, yang pada akhirnya memberi dorongan yang baik.

Saya punya banyak model. Buang saja semuanya di semacam penumpuk? Itu tidak bekerja dengan baik, dia melatih kembali, tetapi karena model adalah kelompok yang sangat berkorelasi, saya hanya menyatukan mereka ke dalam kelompok-kelompok ini, dalam setiap kelompok saya rata-rata dan menerima 5-7 kelompok model yang sangat mirip, dari mana sebagai fitur untuk Tingkat selanjutnya menggunakan nilai rata-rata. Saya melatih LightGBM dalam hal ini, menyadap 20 peluncuran dengan berbagai sampel, mengunggah sedikit fungsi meta yang serupa dengan apa yang dilakukan Atanas, dan pada akhirnya itu mulai bekerja, memberi dorongan pada rata-rata sederhana.

Yang paling penting, saya menambahkan API yang ditemukan Andrei dan yang berisi serangkaian label serupa. Penyelenggara membuat model untuk mereka pada awalnya. Karena awalnya berbeda, para peserta tidak menggunakannya, tidak mungkin untuk hanya membandingkannya dengan yang perlu kami prediksi. Tetapi jika itu melemparkan dirinya ke susunan yang berfungsi dengan baik sebagai fitur meta, maka itu akan memberikan dorongan yang luar biasa, terutama di kelas TOXIC, yang, tampaknya, adalah yang paling sulit di papan peringkat, dan memungkinkan kami untuk melompat ke beberapa tempat pada akhirnya, secara harfiah pada hari terakhir .

Karena kami menemukan bahwa penumpukan dan API bekerja sangat baik bagi kami, sebelum pengiriman akhir, kami memiliki sedikit keraguan tentang seberapa baik ini akan diangkut ke pribadi. Itu bekerja dengan sangat mencurigakan, jadi kami memilih dua pengiriman sesuai dengan prinsip berikut: satu - perpaduan model tanpa API yang diterima sebelumnya, ditambah susun dengan metafisika dari API. Di sini ternyata 0,9880 untuk umum dan 0,9874 untuk pribadi. Di sini tanda saya bingung.

Dan yang kedua adalah campuran model tanpa API, tanpa menggunakan susun dan tanpa menggunakan LightGBM, karena ada kekhawatiran bahwa ini semacam pelatihan ulang kecil untuk umum, dan kita bisa terbang dengan itu. Itu terjadi, mereka tidak terbang, dan sebagai hasilnya, dengan hasil 0,9876 secara pribadi kami mendapat posisi kesepuluh. Itu saja.