Bisnis besar dan perusahaan berdarah telah lama menemukan pengganti rdbds dewasa untuk DWH dan analitik. DWH secara besar-besaran bergerak menuju DataLake dan Hadoop. Tampaknya perusahaan kecil tidak lagi masuk akal untuk meluncurkan analitik pada rsbd yang serius. Dengan semakin banyaknya core yang tersedia bahkan untuk bisnis kecil, mencoba melisensikan versi lengkap dari sub-tipe dewasa seperti Oracle tidak masuk akal. Edisi Standar Oracle, meskipun dilisensikan untuk soket, tetapi pada saat yang sama memotong fungsi yang paling penting. Pertama, dalam edisi standar tidak ada partisi
, hanya ada tampilan partisi - pembagian tabel dengan cara Postgres, yang dapat membantu hanya dalam beberapa situasi. Kedua, tidak ada siaga penuh, operasi paralel terputus. Cluster RAC terbatas pada empat soket. Sebagai hasilnya, dengan pertumbuhan data modern, Anda dengan cepat mulai mengalami keterbatasan edisi Standar, dan harga lisensi edisi Enterprise membuat tugas ini sia-sia. Dalam Oracle perlu untuk melisensikan tidak hanya server pertempuran, tetapi juga server siaga, sementara edisi Perusahaan dilisensikan oleh inti. Opsi Cluster, partisi, dan DataGuard / Standby memerlukan lisensi terpisah dan juga inti. Akibatnya, bahkan server entry level dengan 16 core dan stanby-nya sudah untuk lisensi EE menarik ratusan ribu dolar, dan bahkan pingsan manajemen perusahaan berdarah.
Kita harus mencari alternatif di khadupov. Saya mencoba membandingkan beberapa permintaan untuk menampilkan data yang dibangun di atas file parket di cadangan, terhadap Oracle Standard pada 8 xeon core, 196 GB frame, toko perusahaan tertentu dengan HDD dan cache SSD, yang dapat digeledah dengan beberapa sistem lebih. Kueri pertama mempengaruhi 4 tabel, di Oracle mereka menempati 62, 12, 6.5 dan 3.5 GB. Di piring yang lebih besar dari sekitar 880 juta baris. Dalam rencana permintaan itu seperti:
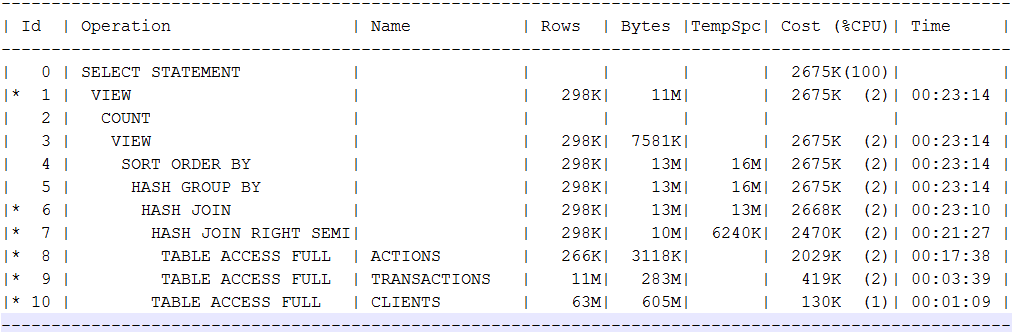
Dalam rencana itu, saya secara khusus ingin melihat fullscans dan hashjoins yang khas dalam pertanyaan analitis saya. Pada kenyataannya, permintaan untuk edisi standar Oracle membutuhkan waktu sekitar 7 menit. Spark 2.3 diluncurkan melalui spark2-submit ke 14 eksekutor dengan 4 core / 16 GB frame memberikan jawaban untuk permintaan yang hampir sama dari disk HDD 10k dalam satu menit. Cloudera Impala mendorong dengan benang dan percikan pada kluster yang sama (impalad pada 8 node, sumber daya yang sebanding dengan 14 eksekutor dengan 4 core) secara stabil memberikan jawaban dalam 11-12 detik. Pada saat yang sama, Impala terus berjalan secara paralel dengan beban, yang seharusnya mencuci data yang di-cache.
Game dengan ukuran blok, pindah ke edisi Oracle EE dengan paralelisme dan partisi orang dewasa mungkin akan mengurangi waktu eksekusi beberapa kali, tapi saya sedikit ragu bahwa waktu akan sebanding bahkan dengan apa yang saya dapatkan di Spark. Di sisi lain, hanya 3-4 node dari Cloudera Hadoop yang praktis gratis yang pada dasarnya memungkinkan Anda untuk masuk ke SQL yang biasa, kecepatan Oracle mendapatkan uang yang jauh lebih besar.
Oracle harus serius memikirkan kebijakan lisensi, jika penggemar besar, seperti saya, tidak menemukan alasan untuk membayar edisi Enterprise.