Saya diberitahu bahwa di komputer baru, beberapa tes regresi menjadi lebih lambat. Suatu hal yang biasa terjadi. Konfigurasi yang salah di suatu tempat di Windows atau bukan nilai-nilai paling optimal di BIOS. Tetapi kali ini kami tidak dapat menemukan pengaturan "knock down" yang sama. Karena perubahannya signifikan: 9 vs 19 detik (pada tabel, biru adalah besi tua dan oranye adalah yang baru), saya harus menggali lebih dalam.
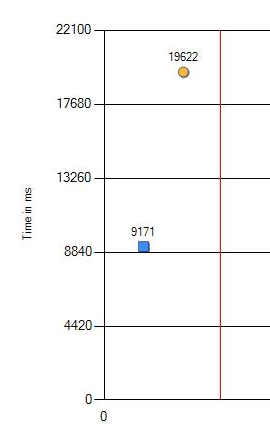
OS yang sama, perangkat keras yang sama, prosesor yang berbeda: 2 kali lebih lambat
Penurunan kinerja dari 9,1 ke 19,6 detik pasti bisa disebut signifikan. Kami melakukan pemeriksaan tambahan dengan perubahan dalam versi program yang diuji, pengaturan Windows dan BIOS. Tapi tidak, hasilnya tidak berubah. Satu-satunya perbedaan hanya muncul pada prosesor yang berbeda. Di bawah ini adalah hasil dari CPU terbaru.
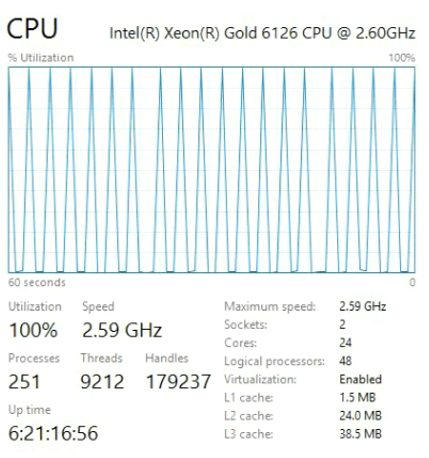
Dan inilah yang digunakan untuk perbandingan.

Xeon Gold berjalan pada arsitektur yang berbeda yang disebut Skylake, yang umum untuk prosesor Intel baru sejak pertengahan 2017. Jika Anda membeli perangkat keras terbaru, Anda akan mendapatkan prosesor dengan arsitektur Skylake. Ini adalah mobil yang bagus, tetapi, seperti yang ditunjukkan oleh tes, kebaruan dan kecepatan bukanlah hal yang sama.
Jika tidak ada yang membantu, maka Anda perlu menggunakan profiler untuk penelitian mendalam. Mari kita uji pada peralatan lama dan baru dan dapatkan sesuatu seperti ini:
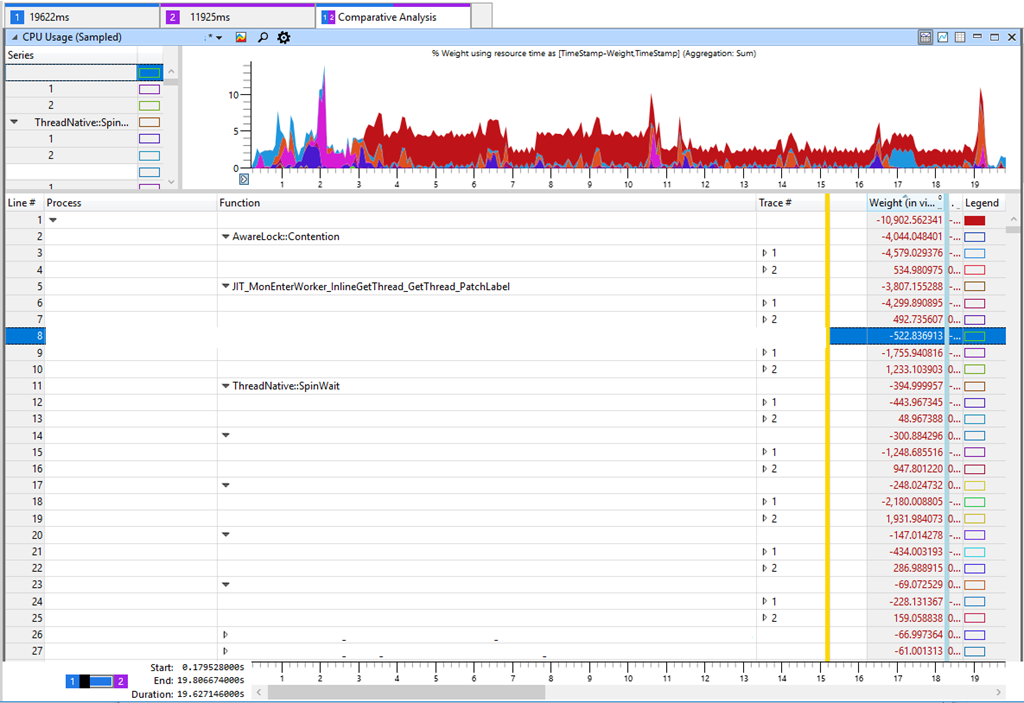
Tab di Windows Performance Analyzer (WPA) menunjukkan dalam tabel perbedaan antara Jejak 2 (11 detik) dan Jejak 1 (19 detik). Perbedaan negatif dalam tabel terkait dengan peningkatan konsumsi CPU dalam tes yang lebih lambat. Jika Anda melihat perbedaan paling signifikan dalam konsumsi CPU, kita akan melihat
AwareLock :: Contention ,
JIT_MonEnterWorker_InlineGetThread_GetThread_GetThread_PatchLabel dan
ThreadNative.SpinWait . Semuanya menunjukkan "berputar" dalam CPU [berputar - upaya siklus untuk mendapatkan kunci, kira-kira. per.], saat utas bertarung untuk memblokir. Tetapi ini adalah tanda yang salah, karena pemintalan bukanlah alasan utama penurunan produktivitas. Meningkatnya persaingan untuk kunci berarti bahwa sesuatu dalam perangkat lunak kami telah melambat dan mempertahankan kunci, yang akibatnya menyebabkan peningkatan pemintalan dalam CPU. Saya memeriksa waktu kunci dan indikator kunci lainnya, seperti kinerja disk, tetapi saya tidak dapat menemukan sesuatu yang berarti yang dapat menjelaskan penurunan kinerja. Meskipun ini tidak logis, tetapi saya kembali meningkatkan beban pada CPU dalam berbagai metode.
Akan menarik untuk menemukan di mana prosesor macet. WPA memiliki kolom # dan baris # file, tetapi hanya bekerja dengan karakter pribadi, yang tidak kami miliki, karena ini adalah kode .NET Framework. Hal terbaik berikutnya yang bisa kita lakukan adalah mendapatkan alamat dll di mana instruksi yang disebut Image RVA berada. Jika Anda memuat dll ini ke debugger dan lakukan
u xxx.dll+ImageRVAmaka kita akan melihat instruksi yang membakar sebagian besar siklus CPU, karena itu akan menjadi satu-satunya alamat "panas".
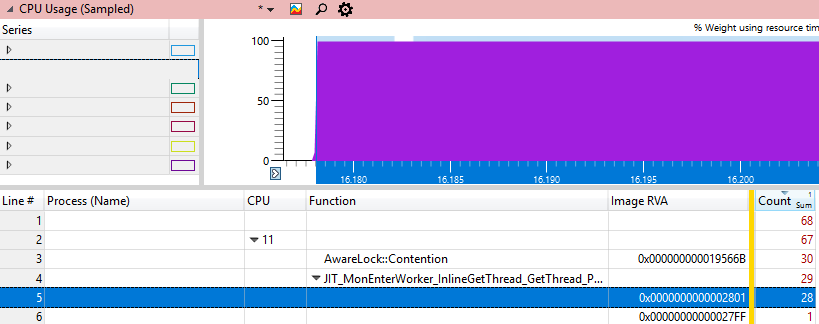
Kami akan memeriksa alamat ini menggunakan berbagai metode Windbg:
0:000> u clr.dll+0x19566B-10
clr!AwareLock::Contention+0x135:
00007ff8`0535565b f00f4cc6 lock cmovl eax,esi
00007ff8`0535565f 2bf0 sub esi,eax
00007ff8`05355661 eb01 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664)
00007ff8`05355663 cc int 3
00007ff8`05355664 83e801 sub eax,1
00007ff8`05355667 7405 je clr!AwareLock::Contention+0x144 (00007ff8`0535566e)
00007ff8`05355669 f390 pause
00007ff8`0535566b ebf7 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664)Dan dengan berbagai metode JIT:
0:000> u clr.dll+0x2801-10
clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x124:
00007ff8`051c27f1 5e pop rsi
00007ff8`051c27f2 c3 ret
00007ff8`051c27f3 833d0679930001 cmp dword ptr [clr!g_SystemInfo+0x20 (00007ff8`05afa100)],1
00007ff8`051c27fa 7e1b jle clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x14a (00007ff8`051c2817)
00007ff8`051c27fc 418bc2 mov eax,r10d
00007ff8`051c27ff f390 pause
00007ff8`051c2801 83e801 sub eax,1
00007ff8`051c2804 75f9 jne clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x132 (00007ff8`051c27ff)Sekarang kami memiliki templat. Dalam satu kasus, alamat panas adalah pernyataan lompatan, dan dalam kasus lain, itu adalah pengurangan. Namun kedua instruksi panas tersebut didahului oleh pernyataan jeda umum yang sama. Metode yang berbeda menjalankan instruksi prosesor yang sama, yang karena alasan tertentu membutuhkan waktu yang sangat lama. Mari kita mengukur kecepatan eksekusi pernyataan jeda dan melihat apakah kita beralasan dengan benar.
Jika masalah didokumentasikan, maka itu menjadi fitur.
| CPU | jeda dalam nanodetik |
| Xeon E5 1620v3 3.5 GHz | 4 |
| Xeon® Gold 6126 @ 2.60 GHz | 43 |
Jeda dalam prosesor Skylake baru membutuhkan urutan besarnya lebih lama. Tentu saja, apa pun bisa menjadi lebih cepat, dan kadang-kadang sedikit lebih lambat. Tapi
sepuluh kali lebih lambat? Ini lebih seperti bug. Pencarian kecil di Internet tentang jeda instruksi mengarah ke
manual Intel , yang secara eksplisit menyebutkan mikroarsitektur Skylake dan instruksi jeda:

Tidak, ini bukan kesalahan, ini adalah fungsi yang terdokumentasi. Bahkan ada
halaman yang menunjukkan waktu pelaksanaan hampir semua instruksi prosesor.
- Jembatan berpasir 11
- Ivy Bridege 10
- Haswell 9
- Broadwell 9
- SkylakeX 141
Jumlah siklus prosesor ditunjukkan di sini. Untuk menghitung waktu aktual, Anda perlu membagi jumlah siklus dengan frekuensi prosesor (biasanya dalam GHz) dan mendapatkan waktu dalam nanodetik.
Ini berarti bahwa jika Anda menjalankan aplikasi yang sangat banyak-ulir di .NET pada perangkat keras terakhir, maka mereka dapat bekerja jauh lebih lambat. Seseorang sudah memperhatikan ini dan pada Agustus 2017
mendaftarkan bug . Masalah telah
diperbaiki di .NET Core 2.1 dan .NET Framework 4.8 Pratinjau.
Spin-wait yang ditingkatkan di beberapa primitif sinkronisasi untuk kinerja yang lebih baik pada Intel Skylake dan mikroarsitektur selanjutnya. [495945, mscorlib.dll, Bug]
Tetapi karena masih ada satu tahun sebelum rilis. NET 4.8, saya diminta untuk mendukung perbaikan sehingga .NET 4.7.2 kembali ke kecepatan normal pada prosesor baru. Karena ada kunci yang saling eksklusif (spinlocks) di banyak bagian. NET, Anda harus melacak peningkatan beban CPU ketika Thread.SpinWait dan metode pemintalan lainnya berfungsi.

Sebagai contoh, Task.Result secara internal menggunakan pemintalan, jadi saya mengantisipasi peningkatan beban CPU yang signifikan dan kinerja yang lebih rendah dalam pengujian lain.
Seberapa buruk itu?
Saya melihat kode .NET Core untuk berapa lama prosesor akan terus berputar jika kunci tidak dilepaskan sebelum memanggil WaitForSingleObject untuk membayar untuk saklar konteks "mahal". Switch konteks membutuhkan mikrodetik atau lebih jika banyak thread mengharapkan objek kernel yang sama.
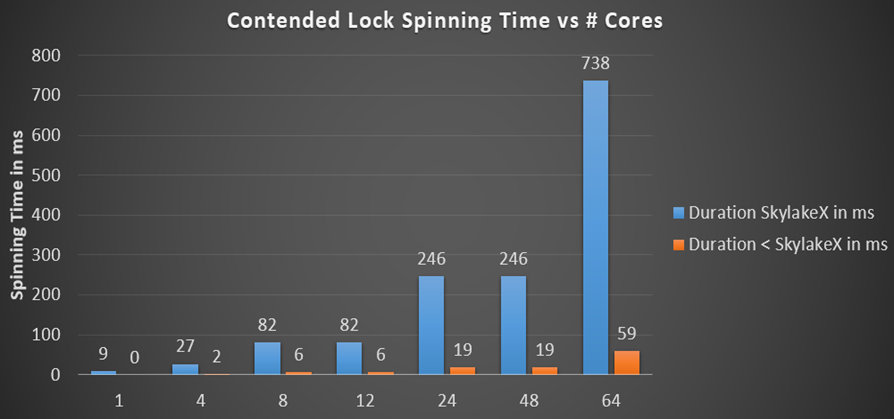
.NET mengunci kalikan durasi pemintalan maksimum dengan jumlah inti, jika kita mengambil kasus absolut di mana utas pada setiap inti mengharapkan kunci yang sama dan pemintalan berlanjut cukup lama bagi setiap orang untuk bekerja sedikit sebelum membayar untuk panggilan kernel. Spinning in .NET menggunakan algoritma penuaan eksponensial ketika dimulai dengan siklus 50 panggilan jeda, di mana untuk setiap iterasi jumlah putaran tiga kali lipat hingga spin counter berikutnya melebihi durasi maksimumnya. Saya menghitung total durasi pemintalan per prosesor untuk berbagai prosesor dan jumlah core yang berbeda:
Di bawah ini adalah kode pemintalan yang disederhanakan dalam .NET Locks:
/// <summary> /// This is how .NET is spinning during lock contention minus the Lock taking/SwitchToThread/Sleep calls /// </summary> /// <param name="nCores"></param> void Spin(int nCores) { const int dwRepetitions = 10; const int dwInitialDuration = 0x32; const int dwBackOffFactor = 3; int dwMaximumDuration = 20 * 1000 * nCores; for (int i = 0; i < dwRepetitions; i++) { int duration = dwInitialDuration; do { for (int k = 0; k < duration; k++) { Call_PAUSE(); } duration *= dwBackOffFactor; } while (duration < dwMaximumDuration); } }
Sebelumnya, waktu pemintalan berada dalam interval milidetik (19 ms untuk 24 core), yang sudah banyak dibandingkan dengan waktu perpindahan konteks yang disebutkan sebelumnya, yang merupakan urutan besarnya lebih cepat. Tetapi dalam prosesor Skylake, total waktu pemintalan untuk prosesor hanya meledak hingga 246 ms pada mesin 24-bit atau 48-core, hanya karena instruksi jeda melambat 14 kali. Benarkah ini? Saya menulis tester kecil untuk memeriksa keseluruhan pemintalan pada CPU - dan angka yang dihitung sesuai dengan harapan. Berikut adalah 48 utas pada CPU 24-inti menunggu satu kunci, yang saya sebut Monitor.PulseAll:
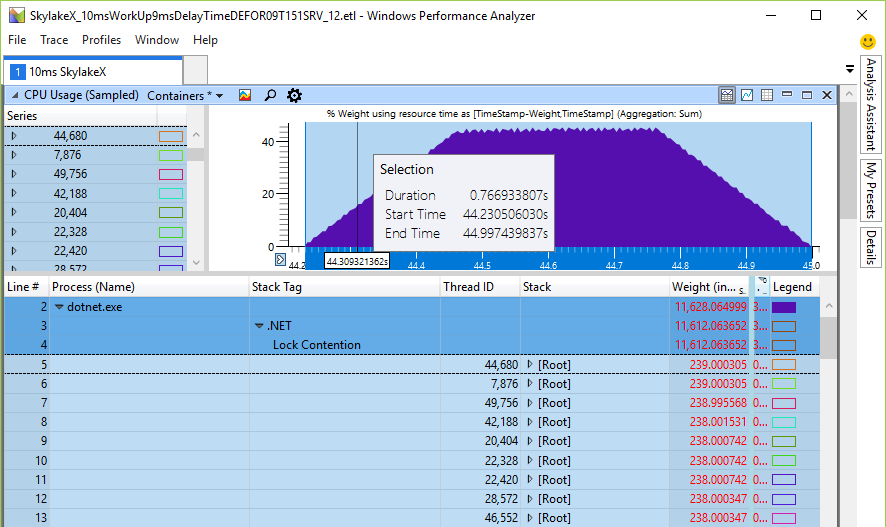
Hanya satu utas yang akan memenangkan perlombaan, tetapi 47 akan terus berputar sampai mereka kehilangan detak jantung. Ini adalah bukti eksperimental bahwa kami benar-benar memiliki masalah beban CPU dan pemintalan yang sangat lama adalah nyata. Ini merongrong skalabilitas, karena siklus ini bukan pekerjaan yang bermanfaat dari utas lainnya, meskipun instruksi jeda membebaskan beberapa sumber daya bersama CPU, menyediakan tidur untuk waktu yang lebih lama. Alasan pemintalan adalah upaya untuk mendapatkan kunci lebih cepat tanpa mengakses kernel. Jika demikian, maka meningkatkan beban pada CPU hanya akan nominal, tetapi tidak mempengaruhi kinerja sama sekali, karena kernel terlibat dalam tugas-tugas lain. Tetapi tes menunjukkan penurunan kinerja dalam operasi berulir tunggal hampir, di mana satu utas menambahkan sesuatu ke antrian kerja, sedangkan utas kerja mengharapkan hasilnya, dan kemudian melakukan tugas tertentu dengan item kerja.
Alasannya paling mudah ditunjukkan dalam diagram. Putaran permusuhan terjadi dengan tiga kali lipat pemintalan di setiap langkah. Setelah setiap putaran, kunci diperiksa kembali untuk melihat apakah utas saat ini dapat menerimanya. Meskipun pemintalan mencoba untuk jujur dan beralih dari waktu ke waktu ke utas lainnya untuk membantu mereka menyelesaikan pekerjaan mereka. Ini meningkatkan kemungkinan melepaskan kunci pada cek berikutnya. Masalahnya adalah bahwa cek untuk take hanya mungkin dilakukan pada akhir putaran penuh:

Misalnya, jika pada awal putaran kelima sebuah kunci menandakan ketersediaan, Anda hanya dapat membawanya pada akhir putaran. Setelah menghitung durasi putaran putaran terakhir, kami dapat memperkirakan kasus keterlambatan terburuk untuk aliran kami:

Banyak milidetik menunggu hingga pemintalan berakhir. Apakah ini masalah nyata?
Saya membuat aplikasi pengujian sederhana yang mengimplementasikan antrian produsen konsumen, di mana alur kerja melakukan setiap item pekerjaan selama 10 ms, dan konsumen memiliki keterlambatan 1-9 ms sebelum item pekerjaan berikutnya. Ini cukup untuk melihat efeknya:
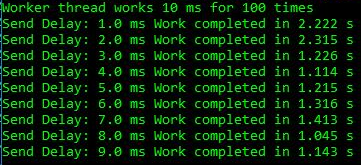
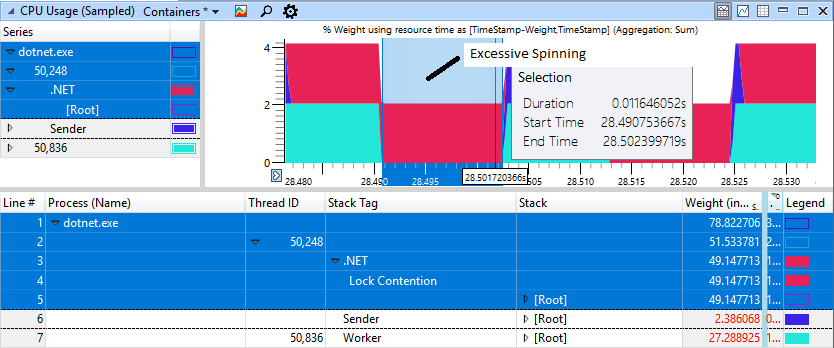
Kami melihat untuk keterlambatan 1-2 ms, total durasi adalah 2.2-2.3 dtk, sementara dalam kasus lain pekerjaan lebih cepat hingga 1.2 dtk. Ini menunjukkan bahwa pemintalan yang berlebihan pada CPU bukan hanya masalah kosmetik dalam aplikasi berlebih. Ini benar-benar membahayakan threading sederhana dari produsen-konsumen, yang hanya mencakup dua utas. Untuk proses di atas, data ETW berbicara sendiri: peningkatan pemintalanlah yang menyebabkan keterlambatan yang diamati:
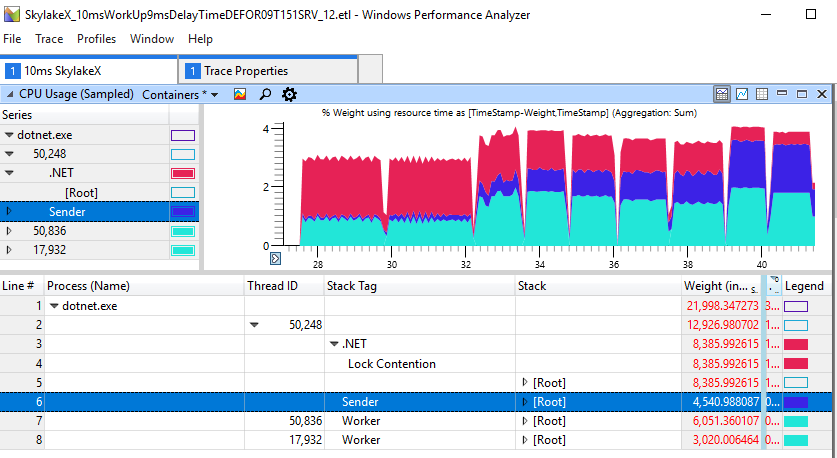
Jika Anda hati-hati melihat bagian dengan "rem", kita akan melihat 11 ms berputar di area merah, meskipun pekerja (biru muda) telah menyelesaikan pekerjaannya dan telah memberikan kunci itu sejak lama.
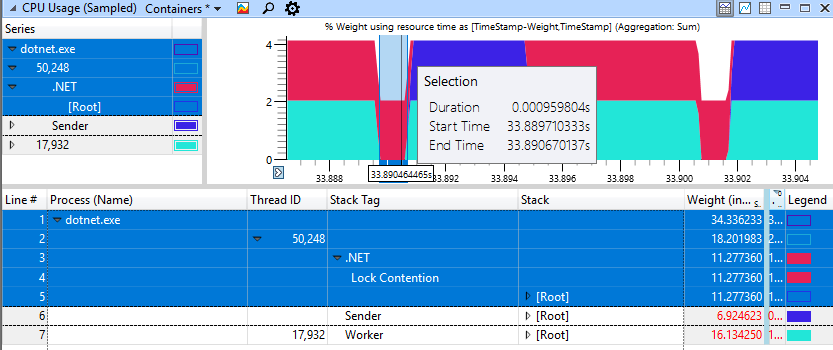
Kasing cepat non-degeneratif terlihat jauh lebih baik, di sini hanya 1 ms yang dihabiskan untuk memintal blokir.
Saya menggunakan aplikasi uji
SkylakeXPause .
Arsip zip berisi kode sumber dan binari untuk .NET Core dan .NET 4.5. Sebagai perbandingan, saya menginstal .NET 4.8 Pratinjau dengan perbaikan dan .NET Core 2.0, yang masih menerapkan perilaku lama. Aplikasi ini dirancang untuk .NET Standard 2.0 dan .NET 4.5, menghasilkan exe dan dll. Sekarang Anda dapat memeriksa perilaku berputar lama dan baru secara berdampingan tanpa perlu memperbaiki apa pun, itu sangat nyaman.
readonly object _LockObject = new object(); int WorkItems; int CompletedWorkItems; Barrier SyncPoint; void RunSlowTest() { const int processingTimeinMs = 10; const int WorkItemsToSend = 100; Console.WriteLine($"Worker thread works {processingTimeinMs} ms for {WorkItemsToSend} times"); // Test one sender one receiver thread with different timings when the sender wakes up again // to send the next work item // synchronize worker and sender. Ensure that worker starts first double[] sendDelayTimes = { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; foreach (var sendDelay in sendDelayTimes) { SyncPoint = new Barrier(2); // one sender one receiver var sw = Stopwatch.StartNew(); Parallel.Invoke(() => Sender(workItems: WorkItemsToSend, delayInMs: sendDelay), () => Worker(maxWorkItemsToWork: WorkItemsToSend, workItemProcessTimeInMs: processingTimeinMs)); sw.Stop(); Console.WriteLine($"Send Delay: {sendDelay:F1} ms Work completed in {sw.Elapsed.TotalSeconds:F3} s"); Thread.Sleep(100); // show some gap in ETW data so we can differentiate the test runs } } /// <summary> /// Simulate a worker thread which consumes CPU which is triggered by the Sender thread /// </summary> void Worker(int maxWorkItemsToWork, double workItemProcessTimeInMs) { SyncPoint.SignalAndWait(); while (CompletedWorkItems != maxWorkItemsToWork) { lock (_LockObject) { if (WorkItems == 0) { Monitor.Wait(_LockObject); // wait for work } for (int i = 0; i < WorkItems; i++) { CompletedWorkItems++; SimulateWork(workItemProcessTimeInMs); // consume CPU under this lock } WorkItems = 0; } } } /// <summary> /// Insert work for the Worker thread under a lock and wake up the worker thread n times /// </summary> void Sender(int workItems, double delayInMs) { CompletedWorkItems = 0; // delete previous work SyncPoint.SignalAndWait(); for (int i = 0; i < workItems; i++) { lock (_LockObject) { WorkItems++; Monitor.PulseAll(_LockObject); } SimulateWork(delayInMs); } }
Kesimpulan
Ini bukan masalah .NET. Semua implementasi spinlock menggunakan pernyataan jeda dipengaruhi. Saya dengan cepat memeriksa inti Windows Server 2016, tetapi tidak ada masalah seperti itu di permukaan. Tampaknya Intel cukup baik - dan mengisyaratkan bahwa beberapa perubahan dalam pendekatan untuk pemintalan diperlukan.
Bug untuk .NET Core dilaporkan pada Agustus 2017, dan pada September 2017
patch dan versi .NET Core 2.0.3 dirilis. Tautan tidak hanya menunjukkan reaksi yang sangat baik dari grup .NET Core, tetapi juga fakta bahwa beberapa hari yang lalu masalah telah diperbaiki di cabang utama, serta diskusi tentang optimasi pemintalan tambahan. Sayangnya, Desktop .NET Framework tidak bergerak begitu cepat, tetapi dalam menghadapi Pratinjau .NET Framework 4.8, kami memiliki setidaknya bukti konseptual bahwa perbaikan di sana juga dapat diterapkan. Sekarang saya sedang menunggu backport untuk. NET 4.7.2 untuk menggunakan. NET dengan kecepatan penuh dan pada perangkat keras terakhir. Ini adalah bug pertama yang saya temukan yang berhubungan langsung dengan perubahan kinerja karena satu instruksi CPU. ETW tetap menjadi profiler utama di Windows. Jika saya bisa, saya akan meminta Microsoft untuk port infrastruktur ETW ke Linux, karena profiler Linux saat ini masih omong kosong. Mereka baru-baru ini menambahkan fitur kernel yang menarik, tetapi masih belum ada alat analisis seperti WPA.
Jika Anda bekerja dengan .NET Core 2.0 atau desktop .NET Framework pada prosesor terbaru yang telah dirilis sejak pertengahan 2017, maka jika terjadi masalah dengan penurunan kinerja, Anda harus memeriksa aplikasi Anda dengan profiler - dan meningkatkan ke .NET Core dan, mudah-mudahan, segera untuk .NET Desktop Aplikasi pengujian saya akan memberi tahu Anda tentang ada atau tidaknya masalah.
D:\SkylakeXPause\bin\Release\netcoreapp2.0>dotnet SkylakeXPause.dll -check
Did call pause 1,000,000 in 3.5990 ms, Processors: 8
No SkylakeX problem detectedatau
D:\SkylakeXPause\SkylakeXPause\bin\Release\net45>SkylakeXPause.exe -check
Did call pause 1,000,000 in 3.6195 ms, Processors: 8
No SkylakeX problem detectedAlat ini akan melaporkan masalah jika Anda bekerja pada .NET Framework tanpa pembaruan yang sesuai dan pada prosesor Skylake.
Saya harap Anda menemukan penyelidikan masalah ini semenarik yang saya lakukan. Untuk benar-benar memahami masalah, Anda perlu membuat cara mereproduksinya, memungkinkan Anda untuk bereksperimen dan mencari faktor-faktor yang memengaruhi. Sisanya hanya pekerjaan yang membosankan, tetapi sekarang saya jauh lebih baik dalam memahami penyebab dan konsekuensi dari upaya siklus untuk mendapatkan kunci pada CPU.