
Pada bulan Maret, tim pengembangan kami dengan nama bangga "Hands-Auki" berjuang keras selama dua hari di bidang digital hackathon AI.HACK. Secara total, lima tugas dari berbagai perusahaan diusulkan. Kami fokus pada tugas Gazpromneft: memperkirakan permintaan bahan bakar dari klien B2B. Menurut data anonim, perlu dipelajari bagaimana memperkirakan berapa banyak pelanggan tertentu akan membeli di masa depan, sesuai dengan wilayah pembelian bahan bakar, jumlah bahan bakar, jenis bahan bakar, harga, tanggal, dan ID klien. Ke depan - tim kami memecahkan masalah ini dengan akurasi tertinggi. Pelanggan dibagi menjadi tiga segmen: besar, sedang dan kecil. Dan di samping tugas utama, kami juga membuat perkiraan konsumsi total untuk masing-masing segmen.
Bongkar berisi data tentang pembelian pelanggan untuk periode dari November 2016 hingga 15 Maret 2018 (untuk periode dari 1 Januari 2018 hingga 15 Maret 2018, data TIDAK termasuk volume).
Data sampel:
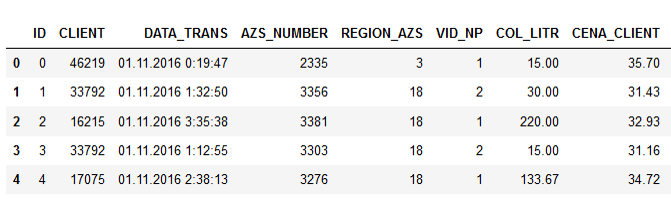
Nama-nama kolom berbicara sendiri, saya pikir tidak masuk akal untuk menjelaskan.
Selain sampel pelatihan, panitia menyediakan sampel uji selama tiga bulan tahun ini. Harga berlaku untuk klien korporat, dengan mempertimbangkan diskon khusus, yang bergantung pada konsumsi klien tertentu, pada penawaran khusus, dan poin lainnya.
Setelah menerima data awal, kami, seperti orang lain, mulai mencoba metode klasik pembelajaran mesin, mencoba membangun model yang sesuai, merasakan korelasi beberapa tanda. Kami mencoba mengekstrak fitur tambahan, membangun model regresi (XGBoost, CatBoost, dll.).
Pernyataan masalah itu sendiri awalnya menyiratkan bahwa harga bahan bakar entah bagaimana mempengaruhi permintaan, dan perlu untuk lebih akurat memahami ketergantungan ini. Tetapi ketika kami mulai menganalisis data yang diberikan, kami melihat bahwa permintaan tidak berkorelasi dengan harga.

Tanda korelasi:
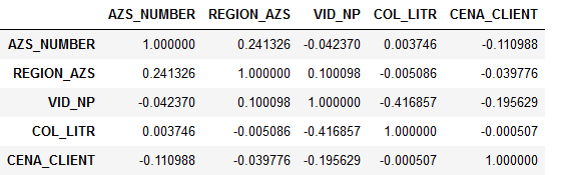
Ternyata jumlah liter praktis tidak tergantung pada harga. Ini dijelaskan secara logis. Sopir pergi di jalan raya, dia perlu mengisi bahan bakar. Dia punya pilihan: apakah akan mengisi bahan bakar di pompa bensin tempat perusahaan bekerja sama, atau di tempat lain. Tetapi pengemudi tidak peduli berapa biaya bahan bakar - organisasi membayar untuk itu. Karena itu, ia hanya mematikan ke pompa bensin terdekat dan mengisi tangki.
Namun, terlepas dari semua upaya dan model yang dicoba-dan-diuji, tidak mungkin untuk mencapai akurasi perkiraan minimum (baseline), yang dihitung dengan menggunakan rumus ini (Kesalahan persentase absolut simetris):
Kami mencoba semua opsi, tidak ada yang berhasil. Dan kemudian terpikir oleh salah satu dari kita untuk meludahi pembelajaran mesin dan beralih ke statistik lama yang baik: ambil saja nilai rata-rata untuk jenis bahan bakar, validasi dan lihat akurasi yang Anda dapatkan.
Jadi kami pertama kali melebihi nilai ambang.
Kami mulai berpikir bagaimana cara meningkatkan hasilnya. Kami mencoba mengambil nilai median berdasarkan kelompok pelanggan, jenis bahan bakar, wilayah, dan nomor pompa bensin. Masalahnya adalah bahwa dalam data uji sekitar 30% dari ID klien yang ada dalam sampel pelatihan hilang. Artinya, klien baru muncul dalam ujian. Ini adalah kesalahan yang tidak diperiksa oleh panitia. Tapi kami harus menyelesaikan sendiri masalahnya. Kami tidak tahu konsumsi pelanggan baru, dan karena itu tidak dapat membuat perkiraan untuk mereka. Dan di sini pembelajaran mesin hanya membantu.
Pada tahap pertama, data yang hilang diisi dengan nilai rata-rata atau median untuk seluruh sampel. Dan kemudian muncul ide: mengapa tidak membuat profil pelanggan baru berdasarkan data yang ada? Kami memiliki pemotongan berdasarkan wilayah, berapa banyak pelanggan membeli bahan bakar di sana, dengan frekuensi apa, jenis apa. Kami mengelompokkan pelanggan yang sudah ada, menyusun profil spesifik untuk wilayah yang berbeda, dan melatih XGBoost pada mereka, yang kemudian "melengkapi" profil pelanggan baru.
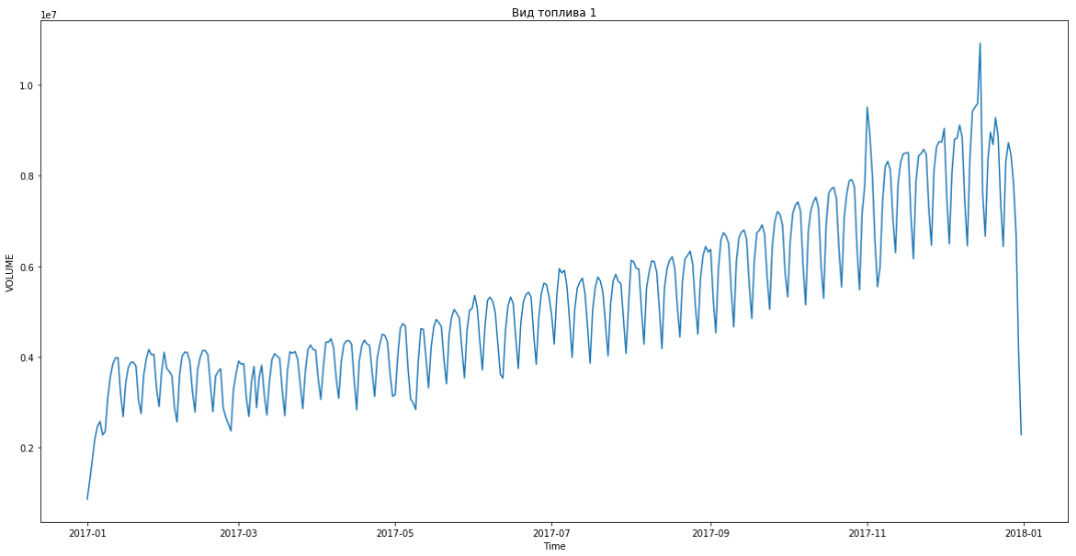
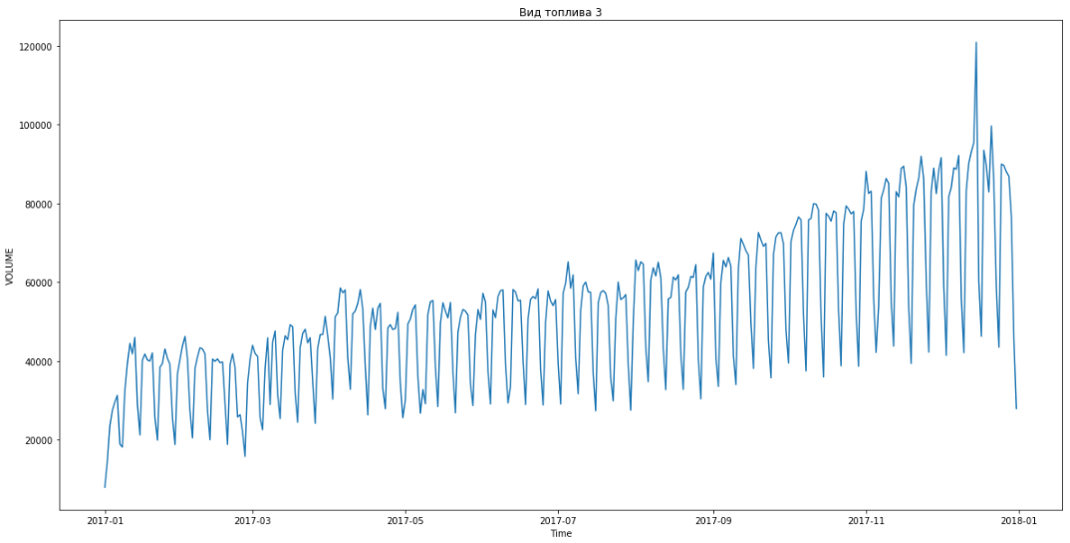
Ini memungkinkan kami untuk masuk ke tempat pertama. Masih ada tiga jam lagi sebelum menyimpulkan hasilnya. Kami senang dan mulai memecahkan masalah bonus - meramalkan berdasarkan segmen selama tiga bulan sebelumnya.
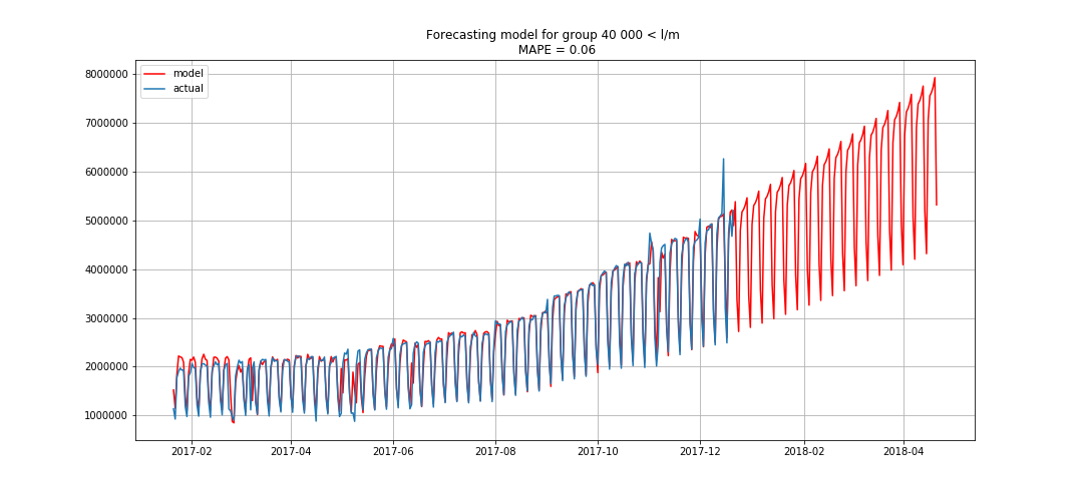
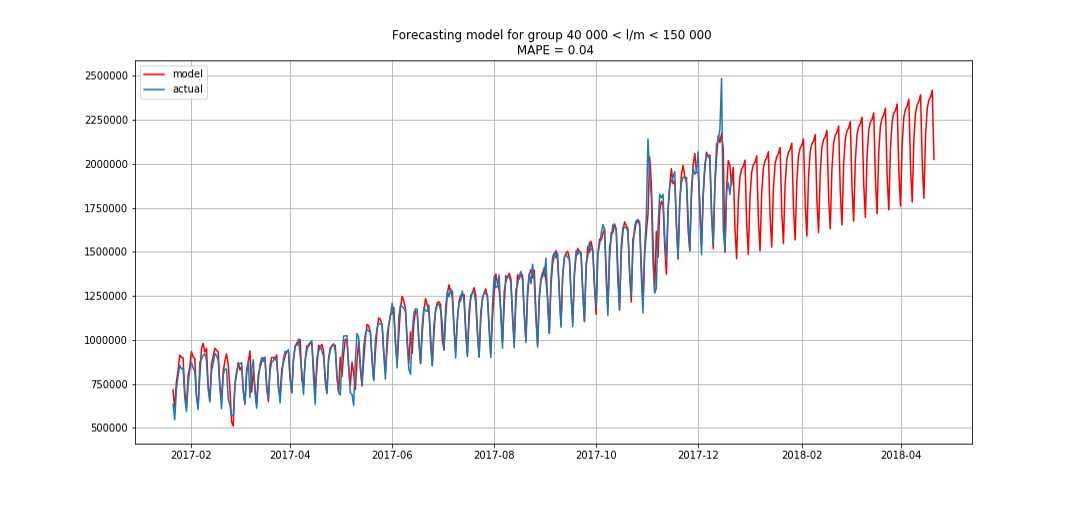
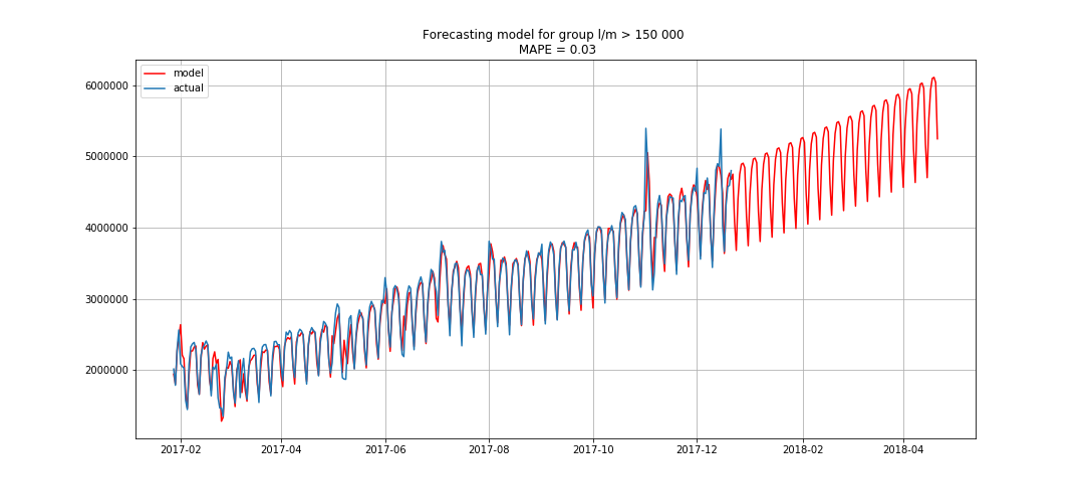
Biru menunjukkan data nyata, perkiraan merah. Kesalahan berkisar antara 3% hingga 6%. Dapat dihitung bahkan lebih akurat, misalnya, dengan memperhitungkan puncak musiman dan hari libur.
Sementara kami melakukan ini, satu tim mulai mengejar ketinggalan kami, meningkatkan hasil kami setiap 15-20 menit. Kami juga mulai ribut dan memutuskan untuk melakukan sesuatu kalau-kalau mereka menyusul kami.
Mereka mulai membuat model lain secara paralel, yang memeringkat statistik berdasarkan tingkat signifikansi, akurasinya sedikit lebih rendah daripada yang pertama. Dan ketika pesaing mengalahkan kami, kami mencoba menggabungkan kedua model. Ini memberi kami sedikit peningkatan dalam metrik - hingga 37,24671%, sebagai hasilnya, kami mendapatkan kembali tempat pertama kami dan mempertahankannya sampai akhir.
Untuk kemenangan itu, tim Ruki-Auki kami menerima sertifikat untuk 100 ribu rubel, kehormatan, rasa hormat, dan ... penuh harga diri, saya pergi ke spa! ;)
Tim Pengembangan Jet Infosystems