Baru-baru ini, kami mencari ilmuwan data di tim (dan menemukan - halo,
nik_son , dan Arseny!). Saat berbicara dengan para kandidat, kami menyadari bahwa banyak orang ingin mengubah pekerjaan mereka karena mereka melakukan sesuatu "di meja".
Sebagai contoh, mereka mengambil peramalan kompleks yang diusulkan kepala, tetapi proyek berhenti karena perusahaan tidak mengerti apa dan bagaimana untuk memasukkan dalam produksi, bagaimana membuat keuntungan, bagaimana "menangkap kembali" sumber daya yang dihabiskan untuk model baru.

HeadHunter tidak memiliki kekuatan komputasi yang besar, seperti Yandex atau Google. Kami memahami betapa sulitnya untuk meluncurkan ML kompleks ke dalam produksi. Oleh karena itu, banyak perusahaan berkutat pada fakta bahwa model linier paling sederhana sedang diluncurkan ke dalam produksi.
Dalam proses implementasi ML berikutnya dalam sistem rekomendasi dan dalam pencarian lowongan, kami menemukan sejumlah "garu" klasik. Perhatikan mereka jika Anda berniat menerapkan ML di rumah: mungkin daftar ini akan membantu Anda untuk tidak menggunakannya
dan menemukan rake pribadi Anda sendiri .
Rake No. 1: Ilmuwan Data - Artis Gratis
Di setiap perusahaan yang mulai memperkenalkan pembelajaran mesin, termasuk jaringan saraf ke dalam pekerjaannya, ada kesenjangan antara apa yang ingin dilakukan oleh ilmuwan data dan apa yang menguntungkan produksi. Termasuk karena bisnis tidak selalu bisa menjelaskan apa manfaatnya dan bagaimana itu bisa membantu.
Kami menangani ini dengan cara berikut: kami mendiskusikan semua ide yang muncul, tetapi hanya menerapkan apa yang akan bermanfaat bagi perusahaan - sekarang atau di masa depan. Kami tidak melakukan penelitian dalam ruang hampa.
Setelah setiap implementasi atau percobaan, kami mempertimbangkan kualitas, sumber daya, dan efek ekonomi serta memperbarui rencana kami.
Menyapu nomor 2: memperbarui perpustakaan
Masalah ini banyak terjadi. Banyak perpustakaan baru dan nyaman muncul yang tidak ada yang pernah mendengar beberapa tahun yang lalu, atau tidak ada sama sekali. Saya ingin menggunakan perpustakaan terbaru, karena lebih nyaman.
Tetapi ada beberapa kendala:
1. Jika prod menggunakan, misalnya, Ubuntu ke-14, maka kemungkinan besar tidak ada perpustakaan baru di dalamnya. Solusinya adalah mentransfer layanan ke buruh pelabuhan dan menginstal pustaka Python menggunakan pip (bukan paket deb).
2. Jika format yang bergantung pada kode digunakan untuk penyimpanan data (seperti acar), ini akan membekukan perpustakaan yang digunakan. Yaitu, ketika model pembelajaran mesin diperoleh dengan menggunakan perpustakaan scikit-learning versi 15 dan disimpan dalam format acar, maka untuk pemulihan model yang benar, perpustakaan scikit-belajar versi lima belas akan diperlukan. Anda tidak dapat memutakhirkan ke versi terbaru, dan ini adalah jebakan yang jauh lebih berbahaya daripada yang dijelaskan dalam ayat 1.
Ada dua jalan keluar:
- Gunakan format bebas kode untuk menyimpan model
- selalu dapat melatih kembali model apa pun. Kemudian, ketika memperbarui perpustakaan, perlu untuk melatih semua model dan menyimpannya dengan versi perpustakaan yang baru.
Kami telah memilih jalur kedua.
Rake nomor 3: bekerja dengan model lama
Melakukan sesuatu yang baru dalam model lama dan terpelajar kurang berguna daripada melakukan sesuatu yang sederhana dalam model baru. Seringkali pada akhirnya ternyata pengenalan model yang lebih sederhana, tetapi lebih segar lebih bermanfaat, dan jumlah usahanya kurang. Penting untuk mengingat ini dan selalu memperhitungkan jumlah upaya bersama dalam mencari pola.
Menyapu nomor 4: hanya eksperimen lokal
Banyak ahli ilmu data suka bereksperimen secara lokal di server pembelajaran mesin mereka. Hanya prod yang tidak memiliki fleksibilitas seperti itu: sebagai akibatnya, banyak alasan terungkap yang tidak memungkinkan untuk menyeret percobaan ini ke dalam produksi.
Penting untuk mengkonfigurasi komunikasi antara spesialis DS dan insinyur penjualan untuk pemahaman bersama - bagaimana model ini atau itu akan bekerja dalam produksi, apakah ada kekuatan yang diperlukan dan kemampuan fisik untuk meluncurkannya. Selain itu, semakin kompleks model dan faktornya, semakin sulit membuatnya andal dan dapat melatihnya lagi kapan saja. Tidak seperti kompetisi Kaggle, dalam produksi seringkali lebih baik mengorbankan seperseribu pada metrik lokal dan bahkan KPI online kecil, tetapi untuk mengimplementasikan versi modelnya jauh lebih sederhana, stabil dalam hasil dan mudah dalam sumber daya komputasi.
Kepemilikan bersama atas kode (pengembang dan ilmuwan data tahu bagaimana kode yang ditulis oleh pengembang lain bekerja), penggunaan kembali tanda-tanda dan meta-atribut dalam berbagai model baik dalam proses pembelajaran dan ketika bekerja di prod (kami dibantu oleh us framework), unit- dan autotests, yang sering kami kendarai, integrasi kode dengan pengujian ulang. Kami menempatkan model akhir dalam repositori git dan menggunakannya dalam produksi juga.
Menyapu nomor 5: uji hanya prod
Setiap pengembang dan ilmuwan data kami memiliki bangku tes sendiri, terkadang tidak satu pun. Komponen utama HH produksi dikerahkan di atasnya. Itu mahal, tetapi membayar untuk kualitas dan kecepatan pengembangan. Itu perlu, tetapi tidak cukup. Kami memuat tidak hanya model yang sudah dalam produksi, tetapi juga yang akan segera hadir. Ini membantu untuk memahami dalam waktu bahwa model yang bekerja sempurna pada mesin lokal, bangku tes atau dalam produksi untuk 5% pengguna, dan ketika dihidupkan 100%, terlalu berat.
Kami menggunakan beberapa tahap pengujian. Kami memeriksa kode dengan sangat cepat (ini adalah titik kunci) - ketika menambahkan atau mengubah komponen dalam repositori, kode dikumpulkan, unit dan autotest dijalankan pada komponen yang sesuai, jika perlu, kami juga menguji ulang secara manual - dan jika ada sesuatu yang salah, berikan jawaban "Putramu rusak, putuskan."
Rake nomor 6: perhitungan panjang dan kehilangan fokus
Jika seorang model membutuhkan, katakanlah, satu minggu untuk berlatih, mudah untuk kehilangan konsentrasi pada tugas karena beralih ke proyek lain. Kami mencoba untuk tidak memberikan pengembang dan ilmuwan data lebih dari dua tugas di satu tangan. Dan tidak lebih dari satu mendesak sehingga Anda dapat beralih ke sana segera setelah perhitungan atau percobaan A / B selesai untuk itu. Aturan ini diperlukan agar tidak kehilangan fokus, dan karena kekhawatiran bahwa beberapa tugas ini umumnya berisiko hilang, dan bagian lain yang berjalan lebih lambat dari yang diperlukan.
Kami menginjak menyapu tetapi tidak menyerah
Kami baru-baru ini menyelesaikan percobaan memperkenalkan jaringan saraf ke dalam sistem pemberi rekomendasi. Itu dimulai dengan fakta bahwa dalam dua hari hackathon internal menulis sebuah model untuk meramalkan tanggapan melalui resume, yang sangat memudahkan pencarian lowongan yang sesuai.
Tetapi kemudian kami belajar: untuk membuatnya menjadi produksi, Anda perlu memperbarui hampir semua hal - misalnya, mentransfer sistem penggunaan ganda, yang mempertimbangkan tanda dan mengajarkan model, ke buruh pelabuhan, serta memperbarui perpustakaan pembelajaran mesin.
Bagaimana itu?
Kami menggunakan model DSSM dengan jaringan saraf single-layer. Dalam artikel Microsoft asli, jaringan saraf tiga lapis digunakan, tetapi kami tidak mengamati peningkatan kualitas dengan peningkatan jumlah lapisan, jadi kami memilih satu lapisan.

Singkatnya:
- Teks kueri dan header lowongan dikonversikan menjadi dua vektor trigram simbol. Kami menggunakan 20.000 trigram karakter.
- Vektor trigram diumpankan ke input jaringan saraf lapis tunggal. Pada input lapisan jaringan saraf, ada 20.000 angka, pada output, 64. Pada dasarnya, jaringan saraf adalah 20.000 x 64 matriks di mana vektor trigram input dimensi 1 x 20 000 dikalikan. Vektor konstan dimensi 1 x 64 ditambahkan ke hasil penggandaan. Vektor oleh output dari jaringan saraf seperti itu sesuai dengan permintaan (atau judul lowongan).
- Produk skalar dari vektor dssm permintaan dan vektor dssm header lowongan dihitung. Fungsi sigmoid diterapkan pada pekerjaan. Hasil akhirnya adalah meta-tanda dssm.
Ketika kami mencoba memasukkan model ini untuk pertama kalinya, metrik lokal menjadi lebih baik, tetapi ketika kami mencoba memasukkannya ke dalam uji A / B, kami melihat bahwa tidak ada peningkatan.
Setelah itu, kami mencoba meningkatkan lapisan kedua neuron menjadi 256 - diluncurkan oleh 5% pengguna: ternyata sistem rekomendasi dan pencarian menjadi lebih baik, tetapi ketika Anda menghidupkan model 100% tiba-tiba ternyata itu terlalu berat.
Kami menganalisis mengapa model ini sangat berat, menghilangkan stemming, dan bereksperimen dengan jaringan saraf ini lagi. Dan hanya setelah itu, setelah berjalan jauh lagi, mereka menemukan bahwa model itu berguna: jumlah respons dalam sistem rekomendasi meningkat sebesar 700 per hari, dan dalam pencarian, setelah semua penghitungan ulang, sebesar 4200.
Pengenalan jaringan saraf yang tidak terlalu rumit memungkinkan pelanggan kami untuk mempekerjakan beberapa lusin karyawan tambahan setiap hari melalui hh.ru, dan selama implementasi kami mengalahkan bagian penting dari masalah besar. Oleh karena itu, kami berencana untuk mengembangkan jaringan saraf kami lebih lanjut. Rencananya adalah mencoba stemming umum, lemmatization tambahan, memproses teks lengkap dari lowongan dan melanjutkan, membuat percobaan dengan topologi (lapisan tersembunyi dan, mungkin, RNN / LSTM).
Hal terpenting yang kami lakukan dengan model ini:
- Jangan jatuhkan eksperimen di tengah.
- Kami menghitung indikator peningkatan respons dan menemukan bahwa pekerjaan pada model ini sepadan. Sangat penting untuk memahami seberapa besar manfaat yang diberikan oleh setiap implementasi tersebut.
Menariknya, model yang kami lakukan dan akhirnya ditambahkan ke prod sangat mirip dengan metode komponen utama (PCA) yang diterapkan pada matriks [teks permintaan, judul dokumen, apakah ada klik]. Yaitu, ke matriks di mana baris terkait dengan kueri unik, kolom ke header lowongan unik; nilai dalam sel adalah 1 jika setelah permintaan ini pengguna mengklik lowongan dengan tajuk ini, dan 0 jika tidak ada klik.
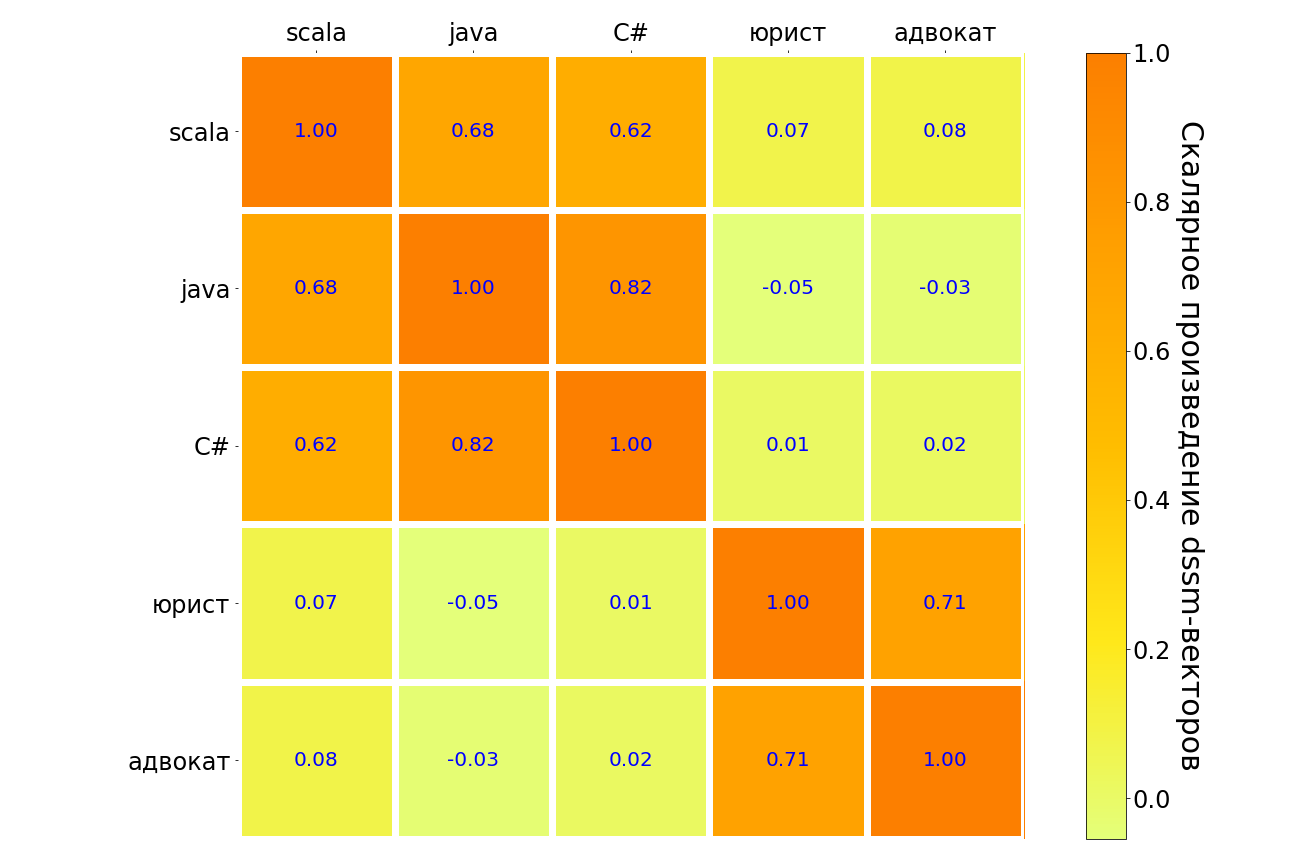
Hasil penerapan model ini untuk permintaan scala, java, C #, "pengacara", "pengacara" ada dalam tabel di bawah ini. Serupa dalam arti, pasangan pertanyaan disorot dalam gelap, tidak seperti - cahaya. Dapat dilihat bahwa model memahami hubungan antara bahasa pemrograman yang berbeda, ada hubungan yang kuat antara permintaan "pengacara" dan "pengacara". Tetapi antara "pengacara" dan bahasa pemrograman apa pun, koneksi sangat lemah.
Pada titik tertentu, saya benar-benar ingin menyerah - percobaan sedang berlangsung, tetapi mereka tidak "memicu". Pada titik ini, seorang ilmuwan data mungkin berguna untuk mendukung tim dan sekali lagi menghitung manfaatnya: mungkin bermanfaat untuk "mengubur pramugari" dan tidak mencoba untuk "menunggang kuda mati", ini bukan kegagalan, tetapi percobaan yang sukses dengan hasil negatif. Atau, setelah mempertimbangkan pro dan kontra, Anda akan melakukan percobaan lain yang akan “menembak”. Jadi itu terjadi pada kita.