Pada akhir musim dingin tahun ini, kompetisi Signal Processing Society - Camera Model IEEE diadakan. Saya berpartisipasi dalam kompetisi tim ini sebagai mentor. Tentang metode alternatif pembentukan tim, keputusan, dan tahap kedua di bawah pemotongan.
 tldr.py
tldr.pyfrom internet import yandex_fotki, flickr, wiki commons from Andres_Torrubia import Ivan_Romanov as pytorch_baseline import kaggle dataset = kaggle.data() for source in [yandex_fotki, flickr, wiki_commons]: dataset[train].append(source.download()) predicts = [] for model in [densenet201, resnext101, se_resnext50, dpn98, densenet161, resnext101 d4, se resnet50, dpn92]: with pytorch_baseline(): model.fit(dataset[train]) predicts.append(model.predict_tta(dataset[test])) kaggle.submit(gmean(predicts))
Pernyataan masalahDari foto itu, perlu untuk menentukan perangkat di mana foto ini diperoleh. Dataset terdiri dari gambar sepuluh kelas: dua iPhone, tujuh smartphone Android dan satu kamera. Sampel pelatihan termasuk 275 gambar ukuran penuh dari setiap kelas. Dalam sampel uji, hanya tanaman pusat berukuran 512x512 yang dipresentasikan. Selain itu, salah satu dari tiga augmentasi diterapkan pada 50 persen dari mereka: kompresi jpg, mengubah ukuran dengan interpolasi kubik, atau koreksi gamma. Itu mungkin untuk menggunakan data eksternal.
 Essence (tm)
Essence (tm)Jika Anda mencoba menjelaskan tugas dalam bahasa yang sederhana, idenya disajikan pada gambar di bawah ini. Sebagai aturan, jaringan saraf modern diajarkan untuk membedakan objek dalam foto. yaitu Anda perlu belajar membedakan kucing dari anjing, pornografi dari pakaian renang atau tank dari jalan. Pada saat yang sama, harus selalu acuh tak acuh pada bagaimana dan di mana perangkat gambar kucing dan tangki diambil.

Dalam kontes yang sama, semuanya justru sebaliknya. Terlepas dari apa yang ditampilkan dalam foto, Anda perlu menentukan jenis perangkat. Yaitu, gunakan hal-hal seperti kebisingan matriks, artefak pemrosesan gambar, cacat optik, dll. Ini adalah tantangan utama - untuk mengembangkan algoritma yang menangkap fitur gambar tingkat rendah.
Fitur Kerja Sama TimMayoritas besar tim kaggle dibentuk sebagai berikut: peserta dengan lead dekat pada leaderboard disatukan ke dalam sebuah tim, sementara masing-masing melihat versi solusinya dari awal hingga akhir. Saya menulis
posting tentang contoh khas pidato seperti itu. Namun, kali ini kami pergi ke arah lain, yaitu: kami membagi bagian keputusan menjadi orang. Selain itu, sesuai dengan aturan kompetisi, 3 tim siswa top menerima tiket ke Kanada untuk tahap kedua. Karena itu, ketika tulang punggung berkumpul, kami kekurangan staf untuk mematuhi aturan.
SolusiUntuk menunjukkan hasil yang baik pada tugas ini, perlu dirakit puzzle berikut sesuai dengan prioritas:
- Temukan dan unduh data eksternal. Kompetisi ini diizinkan untuk menggunakan data eksternal dalam jumlah yang tidak terbatas. Dan dengan cepat menjadi jelas bahwa dataset eksternal besar sedang terseret.
- Saring data eksternal. Orang terkadang memposting gambar yang diproses, yang membunuh semua fitur perangkat.
- Gunakan skema validasi lokal yang andal. Karena bahkan satu model menunjukkan keakuratan di wilayah 0,98+, dan dalam pengujian hanya ada 2 bidikan, memilih pos pemeriksaan model adalah tugas yang terpisah.
- Model kereta. Garis dasar yang sangat kuat diposting di forum. Namun, tanpa sejumput sihir, dia hanya mengizinkan perak.
Pengumpulan dataBagian ini ditempati oleh
Arthur Fattakhov . Untuk tugas ini, cukup mudah untuk mendapatkan data eksternal, ini hanya gambar dari model ponsel tertentu. Arthur menulis skrip python yang menggunakan perpustakaan untuk dengan mudah mengurai halaman html yang disebut
BeautifulSoup . Tetapi, misalnya, pada halaman album flickr, blok foto dimuat secara dinamis, dan untuk menyiasatinya saya harus menggunakan
selenium , yang meniru aksi browser. Sebanyak 500+ GB foto diunduh dari yandex.fotki, flickr, wiki commons.
Pemfilteran dataIni adalah satu-satunya kontribusi saya untuk solusi dalam bentuk kode. Saya hanya melihat bagaimana foto-foto mentah terlihat dan membuat banyak aturan: 1) ukuran khas untuk model tertentu 2) kualitas jpg di atas ambang batas 3) keberadaan meta-tag yang diperlukan dari model 4) perangkat lunak yang benar yang diproses.
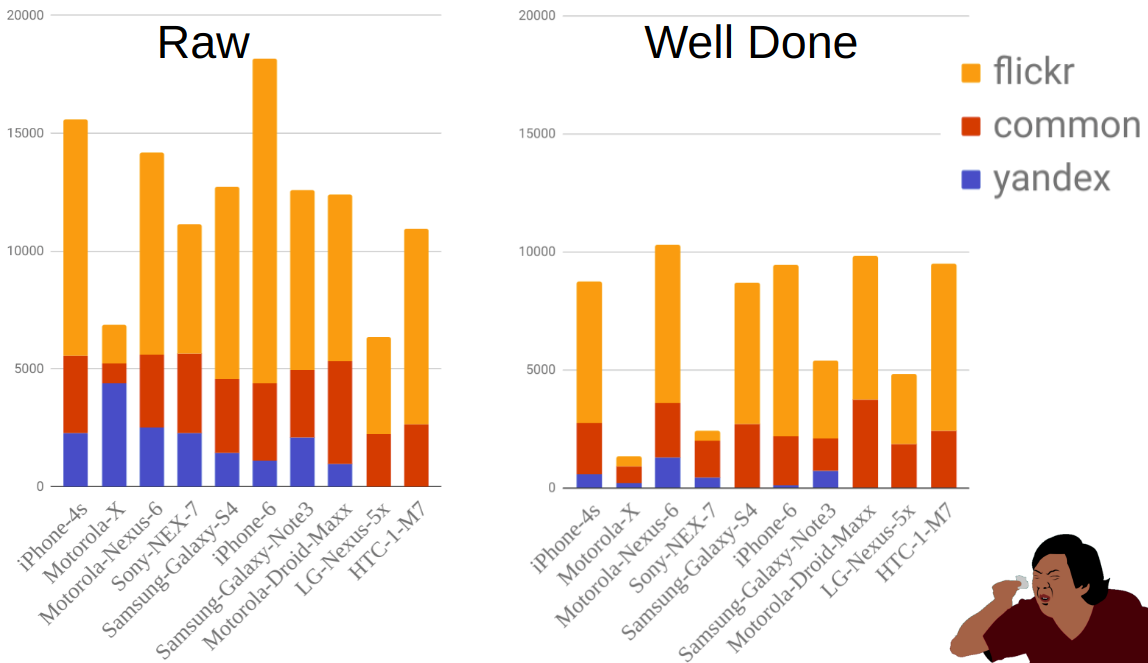
Gambar tersebut menunjukkan distribusi foto berdasarkan sumber dan ponsel sebelum dan sesudah pemfilteran. Seperti yang Anda lihat, misalnya, Moto-X jauh lebih kecil daripada ponsel lain. Pada saat yang sama, ada banyak dari mereka sebelum difilter, tetapi kebanyakan dari mereka dihilangkan karena fakta bahwa ada banyak pilihan untuk ponsel ini dan pemiliknya tidak selalu menunjukkan model dengan benar.
ValidasiImplementasi bagian dengan pelatihan dan validasi dilakukan oleh
Ilya Kibardin . Validasi pada sepotong kereta kaggle tidak bekerja sama sekali - kisi-kisi merobohkan hampir 1.0 akurasi, dan pada leaderboard itu sekitar 0,96.
Karena itu, validasi diambil gambar
Gleb Posobin , yang ia ambil dari semua situs dengan ulasan telepon. Ada kesalahan di dalamnya: alih-alih iPhone 6 ada iPhone 6+. Kami menggantinya dengan iPhone 6 asli dan menjatuhkan 10% gambar dari kereta kagla untuk menyeimbangkan kelas.
Saat mempelajari metrik dianggap sebagai berikut:
- Kami mempertimbangkan cross entropy dan akurasi pada bagian tengah crop dari validasi.
- Kami menganggap entropi silang dan akurasi (manipulasi + pusat pangkasan) untuk masing-masing manipulasi 8. Rata-rata lebih dari delapan manipulasi dengan rata-rata aritmatika.
- Kami menambahkan kecepatan item 1 dan item 2 dengan bobot 0,7 dan 0,3.
Pos pemeriksaan terbaik dipilih sesuai dengan entropi silang tertimbang yang diperoleh di Bagian 3.
Pelatihan modelDi suatu tempat di tengah kompetisi,
Andres Torrubia memposting seluruh
kode untuk keputusannya . Dia sangat bagus dalam hal akurasi model akhir sehingga sekelompok tim terbang bersamanya naik ke papan peringkat. Namun, ia ditulis dengan keras dan level kode yang diinginkan.
Situasi berubah untuk kedua kalinya ketika
Ivan Romanov memposting
versi pytorch dari kode ini. Itu lebih cepat, dan selain itu, paralel dengan mudah ke beberapa kartu video. Level kode, bagaimanapun, masih tidak terlalu baik, tetapi ini tidak begitu penting.
Sedihnya adalah orang-orang ini selesai di tempat ke-30 dan ke-45, tetapi dalam hati kami mereka selalu tetap di atas.
Ilya di tim kami mengambil kode Misha dan membuat perubahan berikut.
Preprocessing:- Dari gambar aslinya dibuat 960x960 tanaman acak.
- Dengan probabilitas 0,5, satu manipulasi acak diterapkan. (Tergantung pada apakah itu digunakan, is_manip = 1 atau 0 diatur)
- Pemotongan acak dilakukan 480x480
- Ada dua opsi pelatihan: rotasi acak 90 derajat dilakukan dalam arah tertentu (mensimulasikan pemotretan horizontal / vertikal untuk ponsel), atau konversi acak grup D4.
 Pelatihan
PelatihanPelatihan ini dilakukan oleh seluruh finetune jaringan, tanpa membekukan lapisan konvolusional classifier (kami memiliki banyak data + secara intuitif, bobot yang objek tingkat tinggi dalam bentuk ekstrak kucing / anjing dapat ditambahkan karena kita membutuhkan fitur tingkat rendah).
 Penjadwalan:
Penjadwalan:Adam dengan lr = 1e-4. Ketika kehilangan validasi berhenti meningkat selama 2-3 zaman, kami mengurangi setengahnya. Jadi untuk konvergensi. Ganti Adam dengan SGD dan pelajari tiga siklus dengan siklus berulang dari 1e-3 hingga 1e-6.
Ansambel akhir:Saya meminta Ilya untuk menerapkan pendekatan saya dari kompetisi sebelumnya. Untuk ansambel anak, kami melatih 9 model, dari masing-masing kami memilih 3 pos pemeriksaan terbaik, setiap pos pemeriksaan diprediksi dengan TTA dan pada akhirnya semua prediksi dirata-rata dengan rata-rata geometris.
 Kata penutup dari tahap pertama
Kata penutup dari tahap pertamaSebagai hasilnya, kami menempati posisi kedua di papan peringkat dan posisi 1 di antara tim siswa. Dan ini berarti bahwa kita mencapai tahap 2 kompetisi ini sebagai bagian dari
Konferensi Internasional IEEE 2018 tentang Akustik, Pidato dan Pemrosesan Sinyal di Kanada. Yang luar biasa, tim yang mengambil tempat ke-3 juga secara resmi adalah siswa. Jika kita menghitung kecepatannya, ternyata kita memutarnya dengan satu gambar yang diprediksi dengan benar.
Piala pemrosesan sinyal IEEE akhir 2018Setelah kami menerima semua konfirmasi, saya, Valery dan Andrey memutuskan untuk tidak pergi ke Kanada untuk tahap kedua. Ilya dan Arthur F. memutuskan untuk pergi, mereka mulai mengatur semuanya dan mereka tidak diberi visa. Untuk menghindari skandal internasional atas penindasan Ilmuwan terkuat dari Rusia, pesta pora diizinkan untuk berpartisipasi dari jarak jauh.
Garis waktunya seperti ini:
03.03 - diberi data kereta
04.09 - mengeluarkan data uji
12,04 - kami diizinkan untuk berpartisipasi dari jarak jauh
13,04 - kami mulai melihat apa yang ada dengan data
04/16 - final
Fitur dari tahap keduaPada tahap kedua tidak ada leaderboard: itu perlu untuk mengirim hanya satu pengiriman di akhir. Artinya, bahkan format prediksi tidak dapat diverifikasi. Juga, model kamera tidak diketahui. Dan ini berarti dua file sekaligus: itu tidak akan berhasil menggunakan data eksternal dan validasi lokal bisa sangat tidak representatif.
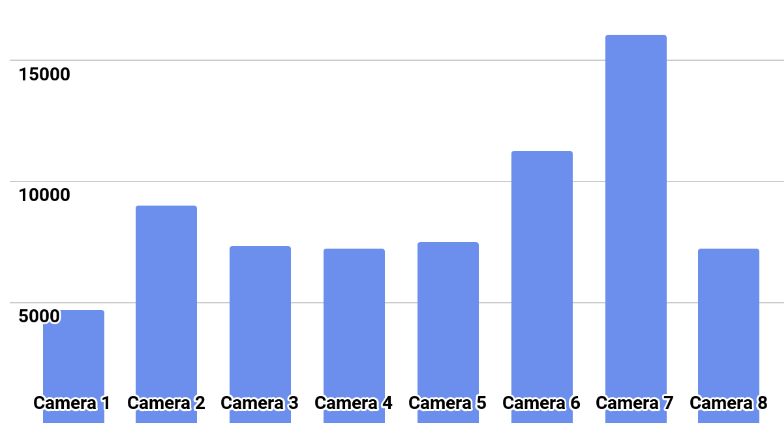
Distribusi kelas ditunjukkan pada gambar.
SolusiKami mencoba melatih model dengan rencana dari tahap pertama dari skala model terbaik. Semua model dengan ceria dilatih untuk akurasi 0,97+ di lipatan mereka, tetapi pada tes mereka memberikan persimpangan prediksi di wilayah 0,87.
Apa yang saya artikan sebagai pakaian keras. Karena itu, ia mengusulkan rencana baru:
- Kami mengambil model terbaik kami dari tahap pertama sebagai ekstraktor fitur.
- Kami mengambil PCA dari fitur yang diekstraksi sehingga semuanya dapat dipelajari dalam semalam.
- Belajar LightGBM.

Logikanya di sini adalah sebagai berikut. Jaringan saraf sudah dilatih untuk mengekstraksi fitur tingkat rendah dari sensor, optik, algoritma demo, dan pada saat yang sama tidak melekat pada konteks. Selain itu, fitur yang diekstraksi sebelum klasifikasi akhir (pada kenyataannya, regresi logistik) adalah hasil dari transformasi yang sangat non-linear. Oleh karena itu, seseorang bisa mengajarkan sesuatu yang sederhana, tidak rentan untuk pelatihan ulang, seperti regresi logistik. Namun, karena data baru bisa sangat berbeda dari data tahap pertama, masih lebih baik untuk melatih sesuatu yang non-linear, misalnya, gradien meningkatkan pada pohon keputusan. Saya menggunakan pendekatan ini di beberapa kompetisi, di mana saya memposting kode.
Karena ada satu pengiriman, saya tidak memiliki cara yang dapat diandalkan untuk menguji pendekatan saya. Namun, DenseNet terbukti menjadi ekstraktor fitur terbaik. Jaringan Resnext dan SE-Resnext menunjukkan kinerja yang lebih rendah pada validasi lokal. Karena itu, keputusan akhir terlihat seperti ini.
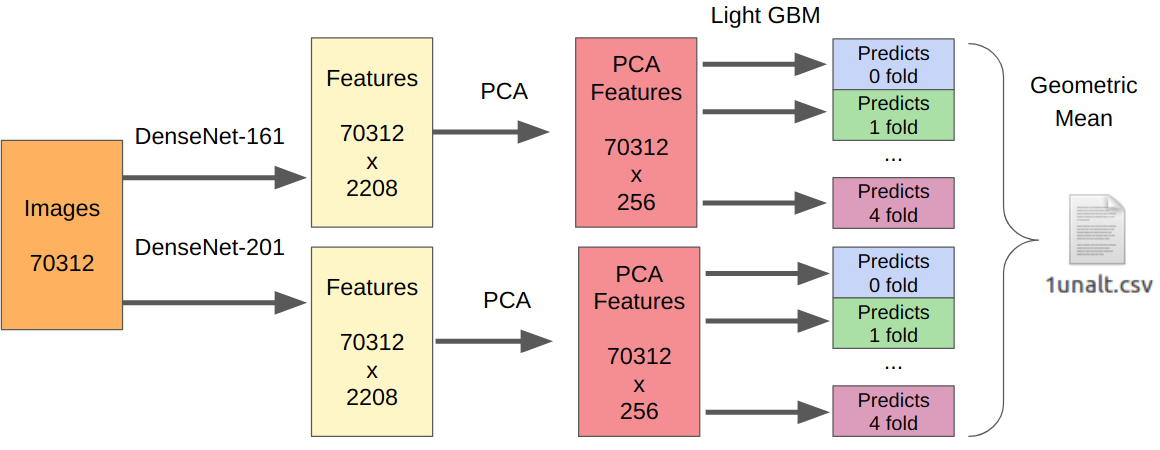
Untuk bagian dengan manipulasi, jumlah semua sampel pelatihan perlu dikalikan dengan 7, karena saya mengekstraksi fitur dari setiap manipulasi secara terpisah.
Kata penutupAkibatnya, pada tahap akhir kami mengambil tempat kedua, tetapi ada banyak pemesanan. Untuk mulai dengan, tempat itu dianugerahi tidak sesuai dengan keakuratan algoritma, tetapi menurut perkiraan presentasi juri. Tim, yang dianugerahi tempat pertama, membuat tidak hanya preza, tetapi juga demo langsung dengan karya algoritma mereka. Yah, kita masih belum tahu kecepatan terakhir dari masing-masing tim, dan para org tidak mengungkapkannya dalam korespondensi bahkan setelah pertanyaan langsung.
Dari hal-hal lucu: pada tahap pertama, semua tim komunitas kami ditunjukkan dalam nama tim [ods.ai] dan cukup kuat menduduki papan peringkat. Setelah itu, legenda kegle seperti
inversi dan
Giba memutuskan untuk bergabung dengan kami untuk melihat apa yang kami lakukan di sini.

Saya sangat menikmati berpartisipasi sebagai mentor. Berdasarkan pengalaman berpartisipasi dalam kompetisi sebelumnya, saya bisa memberikan sejumlah tips berharga untuk meningkatkan baseline, serta membangun validasi lokal. Di masa depan, format seperti itu akan menjadi lebih dari kasus: Kaggle Master / Grandmaster sebagai arsitek solusi + 2-3 Ahli Kaggle untuk menulis kode dan menguji hipotesis. Menurut pendapat saya, ini murni win-win, karena peserta yang berpengalaman sudah terlalu malas untuk menulis kode dan mungkin tidak begitu banyak waktu, dan pemula mendapatkan hasil yang lebih baik, jangan membuat kesalahan dangkal dengan pengalaman kurang dan mendapatkan pengalaman lebih cepat.
→
Kode solusi kami→
Merekam kinerja dengan latihan ML