Satu perusahaan pertambangan besar datang dengan tugas yang menarik: ada banyak situs dengan sistem IT. Mereka berada di kota dan di deposito. Ini adalah beberapa lusinan kantor regional ditambah perusahaan pertambangan. 500 kilometer di taiga tanpa jalan - mudah! Di setiap fasilitas ada peralatan yang perlu "dilipat" menjadi infrastruktur bersama dan untuk menentukan apa dan dalam kondisi apa ia berfungsi.
Apa yang dibutuhkan di sini bukan hanya inventaris teknis semua perangkat di jaringan (nomor seri, versi perangkat lunak, dll.), Tetapi sistem pemantauan yang lengkap. Mengapa Untuk mengidentifikasi akar penyebab kecelakaan dan segera memperingatkan tentang hal itu, membangun peta jaringan, menggambar koneksi antara peralatan, memantau keadaan besi dan saluran komunikasi, membuat peringatan tentang cara keluar dari dukungan atau menghidupkan peralatan baru yang tidak terhitung, dll. Selain itu, diperlukan integrasi. dengan CMDB (dengan mempertimbangkan unit konfigurasi akun), sehingga semua besi yang ditemukan oleh sistem pemantauan "dibandingkan dengan apa yang terdaftar di cabang tertentu, yaitu, sebenarnya dalam jaringan.
Sistem pemantauan lain yang diperlukan untuk menjadi "teman" dengan telepon Asterisk, sehingga yang terakhir
jika terjadi situasi darurat serius seperti pemadaman listrik di lokasi di Krasnoyarsk, maka secara otomatis dapat dengan cepat memanggil orang-orang yang bertanggung jawab. Ada juga tugas untuk membedakan antara visibilitas objek pemantauan dan kekuatan kelompok pengguna. Operator merawat peralatan, Moskow - Moskow, insinyur di lapangan - hanya bidang mereka.
Pelanggan memilih antara beberapa sistem pemantauan: 1) produk shareware; 2) salah satu solusi komersial; 3) Sistem Infosim StableNet. Sebagai hasil pengujian, kerugian dari produk shareware menjadi jelas bagi pelanggan: produk ini panjang dan sulit dikonfigurasi, ditambah lagi tidak memiliki jumlah fungsionalitas yang diperlukan (di bagian yang sama, misalnya, memberikan koneksi antar perangkat di jaringan). Di luar kotak, dia tidak tahu bagaimana melakukan ini, tetapi dengan plugin itu ternyata begitu-begitu. Produk komersial tidak memiliki agen pemantauan yang didistribusikan - ini dipasang di situs tertentu dan hanya mengendalikan "semak" mereka. Karena itu, kami berhenti di Infosima - ia menutup semua Wishlist. Dan itu sebabnya.
Inilah tampilan layar utama admin InfoSim StableNet (ini bukan proyek mineral, tetapi infrastruktur uji).
Layar utama tempat status jaringan saat ini ditampilkan:

Panel kontrol terlihat di sebelah kiri, di mana kita dapat mengkonfigurasi sistem dan menampilkan statistik yang kita butuhkan. Misalnya, tombol Analyzer memungkinkan Anda untuk menampilkan statistik untuk setiap parameter yang kami kumpulkan, khususnya, waktu pulang-pergi selama satu jam untuk sepotong besi tertentu.

Tombol Inventaris menampilkan data inventaris dari objek pemantauan, tetangga, tabel MAC untuk setiap perangkat yang ada di sistem. Sangat nyaman: proses menemukan parameter peralatan dalam jaringan dengan nomor seri, jenis peralatan, versi sistem operasi, dll., Difasilitasi.

Ketika, di suatu tempat yang jauh di taiga, karyawan lokal, misalnya, memasang saklar baru dan tidak memberi tahu siapa pun tentang itu, itu langsung menjadi terlihat dalam sistem. Peralatan ini jatuh ke cabang khusus di pohon perangkat "Perangkat baru" dan secara otomatis ke CMDB.

Objek pemantauan disurvei tidak hanya untuk model dan model serial, tetapi juga untuk memuat memori, antarmuka, dll. Ada dukungan untuk banyak vendor - khususnya, server, penyimpanan, peralatan telekomunikasi, mesin pengguna akhir. Jika ada sesuatu yang hilang, pelanggan menulis kepada kami atau vendor secara langsung dan potongan besi baru ditambahkan. Semuanya sederhana.

Sistem terintegrasi dengan MS Active Directory dan server RADIUS untuk otorisasi umum dan penerapan kebijakan grup. Seperti inilah arsitektur sistem:
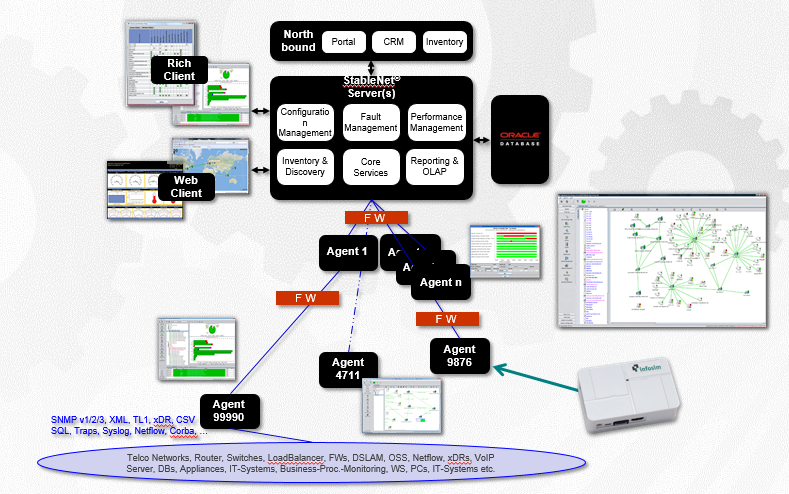
Server pusat bertanggung jawab untuk memproses dan menampilkan statistik yang dikumpulkan dari perangkat keras.
Komponen penting kedua adalah agen yang bertanggung jawab untuk menginterogasi peralatan dan memeriksa ketersediaan besi. Mungkin ada beberapa agen (perangkat lunak jarak jauh), kami memiliki topik yang didistribusikan secara geografis, dengan agen untuk setiap situs. Hal ini diperlukan agar tidak mengarahkan lalu lintas telemetri mentah ke organisasi induk - pelanggan memiliki sejumlah besar situs yang terhubung melalui saluran satelit yang mahal, sehingga hanya hasil pengukuran yang dikirim. Dan database untuk menyimpan semua yang dikumpulkan.
Jika situs jarak jauh tidak tersedia, karyawan di tempat dapat terhubung langsung ke agen dan melihat status "semak" jaringan mereka bahkan tanpa akses ke server pusat.
Agen dapat berupa server x64 / x86 yang menjalankan RedHat, CentOS, Ubuntu, Windows Server (untuk platform besar), atau agen mikro yang didasarkan pada komputer ARM kecil seperti Raspberry PI (untuk platform kecil). Kami tidak memuat saluran dengan ping besi, agen melakukannya, dan sudah mengumpulkan paket dengan statistik.

Kami juga dapat menghapus delay, jitter, variasi jitter untuk peralatan Cisco (IP SLA) dan Huawei (NQA). Oleh karena itu, jika di masa depan pelanggan menambahkan beberapa zat besi lainnya, perusahaan tidak akan memiliki masalah - kami juga dapat membantu mengukur indikator kualitas saluran, melakukan pengujian sintetis, dan memuat saluran komunikasi pengujian antara agen.
Sistem pemantauan dapat menerima pesan syslog, perangkap SNMP dari besi, memfilternya dan menghasilkan pesan alarm. Secara otomatis membangun topologi di tingkat L2 dan L3, dan berdasarkan ini, dependensi situasi darurat (analisis akar masalah) secara otomatis dikonfigurasi. Ini sangat keren, karena memungkinkan administrator untuk mengetahui akar penyebab kecelakaan, sehingga mengurangi waktu yang diperlukan untuk menyelesaikannya. Misalnya, jika dalam rantai lima sakelar, satu sakelar di tengah jatuh, kita akan mendapatkan pesan bahwa sakelar ketiga (akar penyebab) telah jatuh, dan sakelar keempat dan kelima tidak dapat diakses karena hal ini.

Solusinya bekerja di luar kotak, tetapi prosesnya dapat disesuaikan. Jadi, misalnya, untuk memudahkan pekerjaan dukungan teknis kami, kami “menambahkan” status catu daya dan status daya yang tidak pernah terputus: jika daya di situs dimatikan, maka alih-alih 30 alarm, kami mendapatkan satu untuk daya. Korelasi terjadi menurut topologi, pengguna, dan aturan.
Ada konfigurasi grup peralatan, Anda tidak bisa hanya secara pasif menyurvei perangkat keras, tetapi meluncurkan konfigurasi seperti pengaturan pada sakelar. Daftarkan vlan atau ntp pada 40 switch? Mudah!
Sangat keren juga bahwa sistem memungkinkan pelanggan untuk membuat cadangan konfigurasi peralatan sesuai jadwal: kumpulkan konfigurasi sekali sehari atau selama acara (misalnya, pesan tentang perubahan konfigurasi masuk - Anda dapat mengatur tugas yang akan berfungsi saat peristiwa terjadi dan mengumpulkan konfigurasi yang diubah). Hal yang sama adalah untuk landai, untuk acara darurat. Ini akan sangat membantu dengan "pembekalan" dan pencarian penyebab utama perubahan konfigurasi. Ditambah lagi, pada kenyataannya, database terbaru dari semua konfigurasi perangkat di jaringan dibuat.
Ada API untuk integrasi. Dalam proyek kami, pemantauan integrasi dengan CMDB 1C dibuat: Manajemen teknologi informasi ITIL Enterprise untuk menyimpan semua informasi tentang peralatan (aset berwujud). Informasi survei dibandingkan dengan apa yang ada di aset, ketika mendeteksi peralatan yang tidak terhitung, sistem mengatakan: "Ini adalah saklar yang tidak dapat dipahami." Cari tahu apa itu, mereka menyumbat semua bidang yang diperlukan - lokasi instalasi, nama, dll. Nomor seri, nama, nomor bagian, dan versi firmware diperoleh dari perangkat keras. Selanjutnya, tugas dikirim untuk pemantauan - nama potongan besi dalam sistem diubah, diatur ke posisi yang benar di pohon lokasi, pengaturan pemantauan diterapkan tergantung pada jenis potongan besi (misalnya, peralatan batas harus diinterogasi lebih sering daripada yang lain), nama host pada perangkat itu sendiri berubah, dan sebagainya. d.
Proses lapangan
Pertama-tama, kami menyiapkan integrasi dengan AD. Ini membuat hidup kami lebih mudah selama implementasi, serta dalam operasi selanjutnya. Tidak perlu membuat dan menghapus akun untuk pengguna setiap saat. Sistem akan secara otomatis menerima semua akun aktif dari AD. Jika tiba-tiba seseorang keluar, maka sistem itu sendiri menonaktifkan akun ini di rumah dan tidak ada orang lain yang bisa memasukkannya.
Untuk administrator dan manajemen menengah, tugas yang sangat mendesak adalah untuk mendapatkan banyak laporan. Selama peluncuran, laporan tentang pemanfaatan dan aksesibilitas saluran, tentang ketersediaan kelenjar di situs, situasi darurat utama, laporan tentang jenis kecelakaan tertentu, versi OS, laporan tentang perubahan dalam konfigurasi peralatan, dan lainnya dikonfigurasikan.
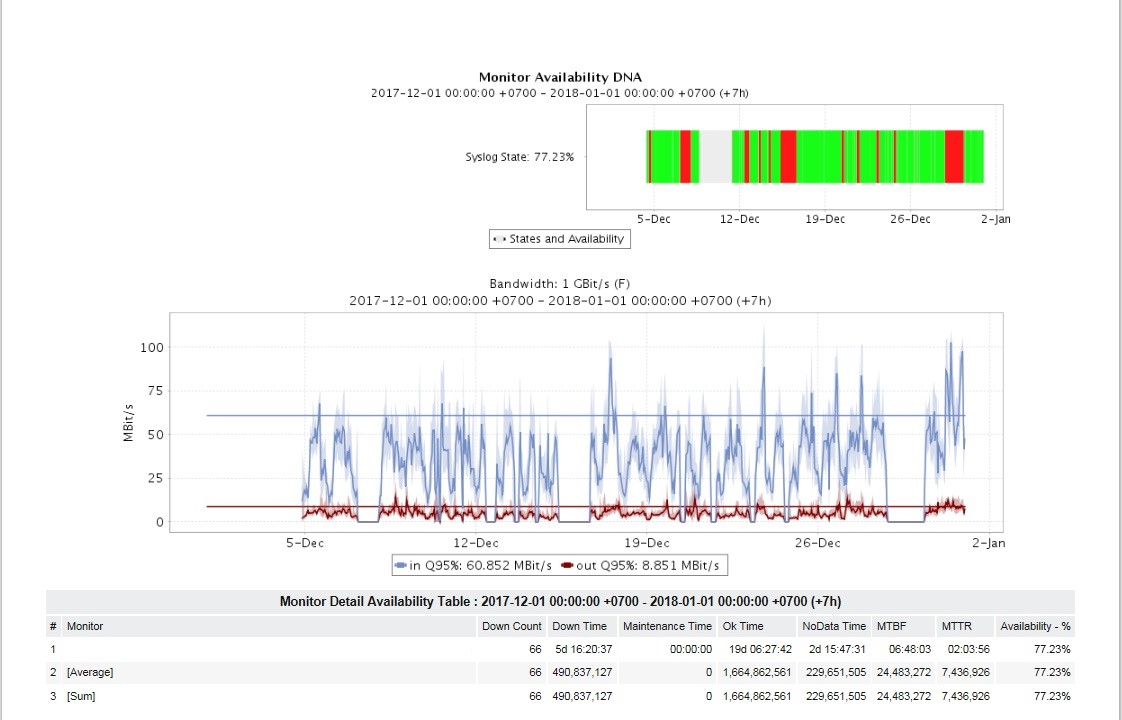
Laporan dapat dilihat dalam format HTML, diterima melalui pos dalam format PDF dan XLSX dengan frekuensi yang diinginkan (sekali sehari, seminggu, sebulan, dll.). Untuk laporan yang berbeda, frekuensi dan penargetan pribadinya dari konsumen laporan dibentuk.
Sistem ini juga memiliki fleksibilitas untuk memberi tahu dan melakukan tindakan kustom jika terjadi keadaan darurat, dapat mengirim pesan email, pesan SMS (menggunakan gateway SMS eksternal), plus menulis skrip Anda sendiri yang akan diluncurkan. Misalnya, kami telah membuat bot Telegram di layanan pemantauan cloud kami, yang memberi tahu karyawan yang bertanggung jawab dalam layanan operasi kami tentang situasi darurat. Itu juga dapat diinterogasi untuk berbagai parameter: "CPU, 10.1.1.100" mengembalikan "95%," tetapi mengingat dukungan aplikasi mobile, ini mungkin tampak sedikit berlebihan, meskipun nyaman.
Selanjutnya, kami menulis naskah untuk integrasi dengan pertukaran telepon. Sekarang, ketika situasi megakritik muncul (listrik padam di lokasi penting atau pusat data), sistem memanggil orang yang bertanggung jawab di ponsel dan dengan suara seperti Siri mengatakan: "Tegangan pada objek seperti itu di bawah level kritis." Ini dilakukan cukup sederhana: kecelakaan itu digandakan dalam folder tertentu pada pertukaran telepon, di mana ia diproses oleh layanan telepon - Anda hanya perlu menentukan terlebih dahulu nomor yang akan dihubungi secara otomatis. Faktanya, kami mengotomatiskan proses memberi tahu administrator atau manajemen yang bertanggung jawab jika terjadi kecelakaan. Dengan kata lain, mereka mengganti orang yang harus menelepon dan melaporkan kecelakaan itu.
Fungsi pencarian yang sangat nyaman bagi pengguna dan kelenjar. Pengguna memanggil, mengatakan: "Jaringan saya tidak berfungsi." Dengan alamat IP-nya, Anda dapat langsung melihat di mana ia terhubung (yang beralih, port mana, yang poppy) dan di mana ia terhubung sebelumnya:

Anda dapat membangun berbagai jenis topologi grafis yang membuat hidup lebih mudah bagi para insinyur. Anda perlu, misalnya, untuk melihat di mana kami memiliki semacam saklar. Sederhana: mereka menemukannya di cabang kanan (atau menggunakan pencarian) dan membuka tetangganya. Beberapa tingkat lingkungan didukung (yang pertama adalah tetangga dekat, yang kedua adalah tetangga tetangga, dll.). Dan Anda dapat melihat langsung di mana saklar kami berada di topologi, port mana dan di mana terhubung, alamat poppy apa yang ada di port. Atau lihat peta protokol OSPF, BGP, EIGRP, STP, PIM, MPLS - sistem akan memproses dan menggambar semua ini dengan sendirinya.

Atau lihat secara visual bagaimana jaringan "terasa" di salah satu situs. Untuk kenyamanan, kami membagi bagian-bagian situs WAN dan LAN dan menggambarnya dengan kartu terpisah. Semua indikator dan tautan bersifat interaktif. Ketika Anda mengarahkan kursor ke mereka, Anda dapat melihat status saat ini dan jatuh ke perangkat tertentu. Saya juga ingin menarik perhatian pada fakta bahwa skema dari Microsoft Visio, yang dibuat oleh insinyur sendiri, digunakan sebagai substrat untuk laporan semacam itu. Dia melihat skema ini berkali-kali sebagai gambar statis di atas kertas atau di layar. Sekarang "hidup kembali" dan memberikan umpan balik real-time. Sangat nyaman

Sesuai dengan persyaratan pelanggan, hak akses pengguna dibatasi. Ada banyak peran, tetapi mereka dikonfigurasi secara fleksibel. Mengingat perbedaan zona waktu antara objek, fitur jam kerja dalam peran sangat berguna: pada jam berapa, untuk kecelakaan apa, kepada siapa SMS dan sebagainya.
InfoSim StableNet mengumpulkan statistik kejadian. Menurut pengalaman kami, dalam kasus seperti itu ada masalah dengan pekerjaan yang direncanakan - mereka merusak laporan dan menyebabkan kekhawatiran yang tidak perlu. Dapat dicatat di sini bahwa di sana-sini akan berfungsi: maka alarm akan masuk dalam mode senyap, dan laporan akan menunjukkan dalam warna yang berbeda bahwa waktu henti ini adalah suatu rencana. Ya, kegiatan yang direncanakan tidak diumumkan secara surut.

Jika tidak ada cukup peluang di luar kotak, Anda dapat membuat templat yang ditulis sendiri. Misalnya, ada titik akses Motorola di proyek. Tidak ada templat yang sudah jadi untuk mereka. Dengan menggunakan "wizard" bawaan, kami membuat templat dan memonitor parameter yang ingin dilihat pelanggan (level sinyal, rasio signal-to-noise).
Ada kasus lain ketika sistem "tidak mengerti" satu pabrikan Rusia dan menunjukkan kode pabrikan sebagai ganti nama. Untuk kasus ini, sistem memiliki fungsionalitas yang memungkinkan Anda untuk menambah vendor dan model perangkat keras baru dalam hitungan detik.
Berikut adalah daftar fitur yang saat ini memungkinkan sistem pemantauan pelanggan melakukan:
- Pantau ketersediaan menggunakan ping ICMP.
- Kumpulkan info menggunakan SNMP.
- Pindai subnet untuk perangkat keras baru.
- Kirimkan laporan berdasarkan periode.
- Terapkan konfigurasi cadangan.
- Menganalisis ketersediaan.
- "Bunyikan alarm" tentang tidak tersedianya peralatan atau output indikator di luar kisaran normal.
- Script SNMP menjebak sebagai pemicu, data syslog, dan input apa pun.
- Integrasikan dengan AD.
- Secara otomatis mendeteksi konektivitas perangkat (lingkungan CDP, LLDP, L3) dan berdasarkan ini, secara otomatis menggambar peta jaringan.
- Buat "peta cuaca" untuk memvisualisasikan status jaringan dengan kemampuan untuk menggunakan media grafis.
- Buat layar kerja (dasbor) untuk menampilkan informasi operasional tentang status jaringan dan perangkat.
- Melakukan inventarisasi peralatan (jenis peralatan, pabrikan, model, versi perangkat lunak, ketika tanggal EoS / EoL datang, dll.)
- Ada REST API untuk integrasi mendalam dengan CMDB 1C dan sistem eksternal lainnya.
- Lakukan konfigurasi grup peralatan dari sistem pemantauan.
- Periksa konfigurasi perangkat untuk kebijakan perusahaan
Referensi
-
Sepeda pendukung lini pertama.-
Saluran komunikasi untuk deposit mineral.- Surat saya: DDrozhzhin@croc.ru