Di Internet modern, lebih dari 630 juta situs, tetapi hanya 6% di antaranya berisi konten berbahasa Rusia. Hambatan bahasa adalah masalah utama penyebaran pengetahuan di antara pengguna jaringan, dan kami percaya bahwa itu harus diselesaikan tidak hanya dengan mengajarkan bahasa asing, tetapi juga menggunakan terjemahan mesin otomatis di browser.
Hari ini kami akan memberi tahu pembaca Habr tentang dua perubahan teknologi penting dalam penerjemah Yandex.Browser. Pertama, terjemahan kata dan frasa yang dipilih sekarang menggunakan model hibrida, dan kami ingat bagaimana pendekatan ini berbeda dari penggunaan jaringan saraf eksklusif. Kedua, jaringan saraf penerjemah sekarang memperhitungkan struktur halaman web, fitur yang juga akan kita bahas di bawah potongan.
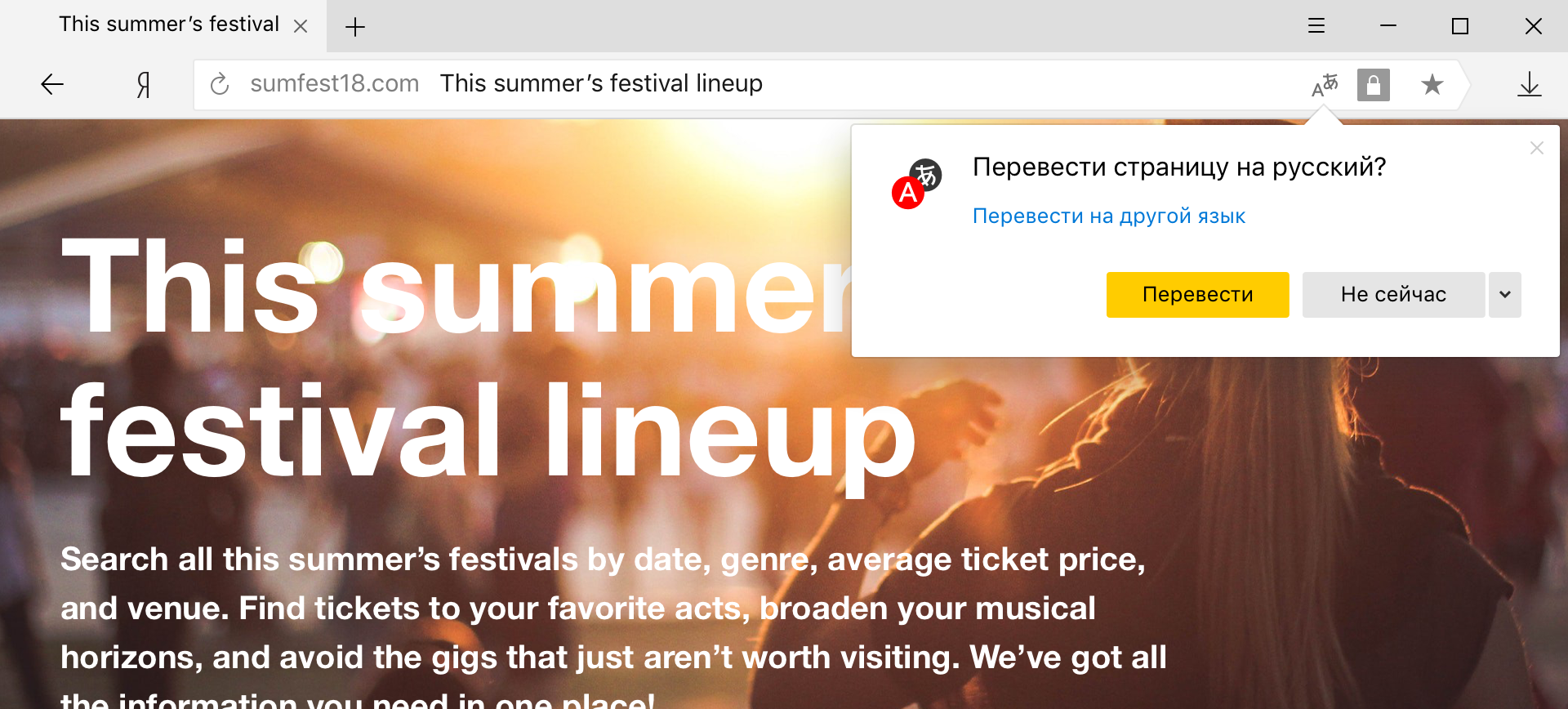
Penerjemah kata dan frasa hibrid
Sistem terjemahan mesin pertama didasarkan pada
kamus dan aturan (pada kenyataannya, pelanggan tetap yang ditulis tangan), yang menentukan kualitas terjemahan. Ahli bahasa profesional telah bekerja selama bertahun-tahun untuk menghasilkan aturan manual yang lebih rinci. Pekerjaan ini sangat memakan waktu sehingga perhatian serius diberikan hanya pada pasangan bahasa yang paling populer, tetapi bahkan dalam kerangka mereka mesin-mesin itu bekerja dengan buruk. Bahasa hidup adalah sistem yang sangat kompleks yang tidak mematuhi aturan. Bahkan lebih sulit untuk menggambarkan aturan korespondensi dari dua bahasa.
Satu-satunya cara mesin dapat secara konstan beradaptasi dengan kondisi yang berubah adalah belajar secara mandiri pada sejumlah besar teks paralel (artinya identik, tetapi ditulis dalam berbagai bahasa). Ini adalah pendekatan statistik untuk terjemahan mesin. Komputer membandingkan teks paralel dan secara bebas mengungkapkan pola.
Seorang
penerjemah statistik memiliki kelebihan dan kekurangan. Di satu sisi, ia dengan baik mengingat kata-kata dan frase yang langka dan kompleks. Jika ditemukan dalam teks paralel, penerjemah akan mengingatnya dan akan terus menerjemahkan dengan benar. Di sisi lain, hasil terjemahannya bisa serupa dengan teka-teki yang dirangkai: gambaran keseluruhan tampaknya bisa dimengerti, tetapi jika Anda perhatikan dengan seksama, Anda dapat melihat bahwa itu terdiri dari bagian-bagian yang terpisah. Alasannya adalah bahwa penerjemah menyajikan kata-kata individual dalam bentuk pengidentifikasi, yang sama sekali tidak mencerminkan hubungan di antara mereka. Ini tidak sesuai dengan bagaimana orang memahami bahasa ketika kata-kata ditentukan oleh bagaimana mereka digunakan, bagaimana mereka berhubungan dengan kata-kata lain, dan bagaimana mereka berbeda dari mereka.
Jaringan saraf membantu mengatasi masalah ini. Representasi vektor kata-kata (embedding kata) yang digunakan dalam terjemahan mesin saraf, sebagai suatu peraturan, mencocokkan setiap kata dengan vektor beberapa ratus angka. Vektor, berbeda dengan pengidentifikasi sederhana dari pendekatan statistik, dibentuk selama pelatihan jaringan saraf dan memperhitungkan hubungan antara kata-kata. Misalnya, seorang model dapat mengenali bahwa karena "teh" dan "kopi" sering muncul dalam konteks yang sama, kedua kata ini harus dimungkinkan dalam konteks kata "tumpahan" yang baru, yang, katakanlah, hanya satu di antaranya yang ditemukan dalam data pelatihan.
Namun, proses pengajaran representasi vektor jelas lebih banyak menuntut statistik daripada contoh menghafal secara mekanis. Selain itu, tidak jelas apa yang harus dilakukan dengan kata-kata masukan langka yang tidak sering cukup untuk jaringan untuk membangun representasi vektor yang dapat diterima untuk mereka. Dalam situasi ini, logis untuk menggabungkan kedua metode.
Sejak tahun lalu, Yandex.Translator telah menggunakan
model hybrid . Ketika Penerjemah menerima teks dari pengguna, ia memberikannya ke kedua sistem - baik jaringan saraf dan penerjemah statistik. Kemudian suatu algoritma yang didasarkan pada metode pelatihan
CatBoost mengevaluasi terjemahan mana yang lebih baik. Saat mencetak, puluhan faktor diperhitungkan - dari panjang kalimat (frasa pendek lebih baik diterjemahkan oleh model statistik) ke sintaksis. Terjemahan yang diakui sebagai yang terbaik ditampilkan kepada pengguna.
Ini adalah model hybrid yang sekarang digunakan di Yandex.Browser, ketika pengguna memilih kata dan frasa tertentu pada halaman untuk terjemahan.
Mode ini sangat nyaman bagi mereka yang umumnya berbicara bahasa asing dan ingin menerjemahkan hanya kata-kata yang tidak dikenal. Tetapi jika, misalnya, alih-alih bahasa Inggris yang biasa, Anda menemukan bahasa Mandarin, maka di sini akan sulit dilakukan tanpa penerjemah halaman. Tampaknya perbedaannya hanya pada volume teks yang diterjemahkan, tetapi tidak begitu sederhana.
Penerjemah Jaringan Neural Web
Dari waktu
percobaan Georgetown hingga hampir hari ini, semua sistem terjemahan mesin telah dilatih untuk menerjemahkan setiap kalimat dari teks sumber secara terpisah. Sedangkan halaman web bukan hanya seperangkat kalimat, tetapi teks terstruktur di mana ada elemen yang berbeda secara fundamental. Pertimbangkan elemen dasar dari sebagian besar halaman.
Tajuk . Biasanya teks cerah dan besar yang kita lihat segera ketika Anda pergi ke halaman. Judul sering berisi inti berita, jadi penting untuk menerjemahkannya dengan benar. Tetapi ini sulit dilakukan, karena teks dalam judul kecil dan tanpa memahami konteksnya, Anda dapat membuat kesalahan. Dalam kasus bahasa Inggris, ini masih lebih rumit, karena judul berbahasa Inggris sering mengandung frasa dengan tata bahasa non-tradisional, infinitif atau bahkan miss verba. Misalnya,
prekuel Game of Thrones diumumkan .
Navigasi Kata dan frasa yang membantu kami menavigasi situs. Misalnya,
Beranda ,
Kembali, dan
Akun saya hampir tidak layak diterjemahkan sebagai "Rumah," "Kembali," dan "Akun Saya," jika mereka berada di menu situs dan tidak dalam teks publikasi.
Teks utama . Semuanya lebih sederhana dengan dia, dia sedikit berbeda dari teks dan kalimat biasa yang dapat kita temukan dalam buku. Tetapi bahkan di sini penting untuk memastikan konsistensi terjemahan, yaitu untuk memastikan bahwa dalam halaman web yang sama istilah dan konsep yang sama diterjemahkan dengan cara yang sama.
Untuk terjemahan halaman web berkualitas tinggi, tidak cukup menggunakan jaringan saraf atau model hybrid - Anda juga harus memperhitungkan struktur halaman. Dan untuk ini kami harus menghadapi banyak kesulitan teknologi.
Klasifikasi segmen teks . Untuk melakukan ini, kami kembali menggunakan CatBoost dan faktor-faktor berdasarkan pada teks itu sendiri dan pada markup dokumen HTML (tag, ukuran teks, jumlah tautan per unit teks, ...). Faktor-faktornya cukup heterogen, oleh karena itu CatBoost (berdasarkan peningkatan gradien) yang menunjukkan hasil terbaik (akurasi klasifikasi di atas 95%). Tetapi klasifikasi segmen saja tidak cukup.
Ketidakseimbangan dalam data . Secara tradisional, algoritma Yandex.Translator belajar tentang teks dari Internet. Tampaknya ini adalah solusi ideal untuk melatih penerjemah halaman web (dengan kata lain, jaringan belajar dari teks-teks yang sifatnya sama dengan teks-teks yang akan kita gunakan). Tetapi segera setelah kami belajar memisahkan segmen yang berbeda satu sama lain, kami menemukan fitur yang menarik. Rata-rata, konten menempati sekitar 85% dari semua teks di situs web, sedangkan judul dan akun navigasi masing-masing hanya 7,5%. Ingat juga bahwa judul dan elemen navigasi dalam gaya dan tata bahasa mereka sendiri sangat berbeda dari teks lainnya. Kedua faktor ini bersama-sama menyebabkan masalah kemiringan data. Lebih menguntungkan bagi jaringan saraf untuk mengabaikan fitur segmen yang sangat kurang terwakili ini dalam rangkaian pelatihan. Jaringan belajar menerjemahkan dengan baik hanya teks utama, karena itu kualitas terjemahan dari header dan navigasi menderita. Untuk menetralkan efek yang tidak menyenangkan ini, kami melakukan dua hal: untuk setiap pasangan kalimat paralel, kami mengaitkan salah satu dari tiga jenis segmen (konten, judul atau navigasi) sebagai informasi meta dan secara artifisial meningkatkan konsentrasi dua yang terakhir di gedung pelatihan menjadi 33% karena fakta bahwa mulai menunjukkan contoh serupa dengan belajar jaringan saraf lebih sering.
Pembelajaran multi-tugas . Karena kami sekarang dapat memisahkan teks pada halaman web menjadi tiga kelas segmen, mungkin tampak seperti ide alami untuk melatih tiga model terpisah, yang masing-masing akan mengatasi terjemahan dari jenis teksnya sendiri - heading, navigasi atau konten. Ini benar-benar bekerja dengan baik, tetapi skema ini bekerja lebih baik ketika kita melatih satu jaringan saraf untuk menerjemahkan semua jenis teks sekaligus. Kunci untuk memahami terletak pada ide
mutli-task learning (MTL): jika ada hubungan internal antara beberapa tugas pembelajaran mesin, maka model yang belajar untuk menyelesaikan masalah ini pada saat yang sama dapat belajar untuk menyelesaikan setiap masalah dengan lebih baik daripada model khusus profil sempit!
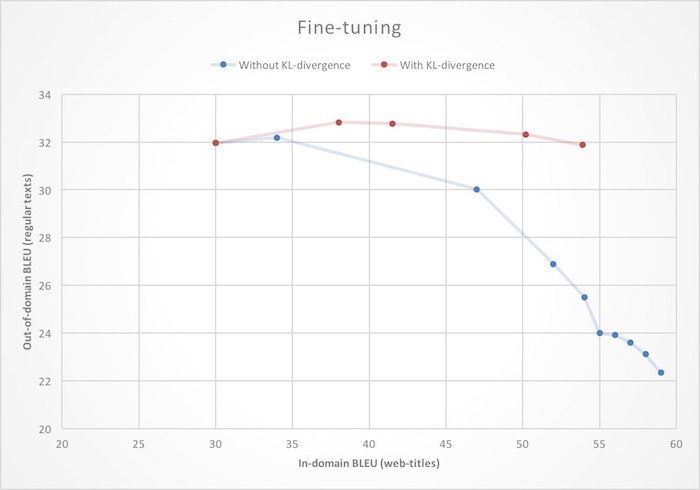
Penyetelan halus . Kami sudah memiliki terjemahan mesin yang sangat baik, sehingga tidak masuk akal untuk melatih penerjemah baru untuk Yandex.Browser dari awal. Lebih logis untuk menggunakan sistem dasar untuk menerjemahkan teks biasa dan melatihnya untuk bekerja dengan halaman web. Dalam konteks jaringan saraf, ini sering disebut sebagai fine-tuning. Tetapi jika Anda mendekati tugas ini secara langsung, mis. hanya untuk menginisialisasi bobot jaringan saraf dengan nilai-nilai dari model yang sudah selesai dan mulai belajar pada data baru, Anda mungkin menghadapi efek pergeseran domain: saat Anda belajar, kualitas terjemahan halaman web (dalam-domain) akan meningkat, tetapi kualitas terjemahan biasa (di luar domain) ) teks akan jatuh. Untuk menghilangkan fitur yang tidak menyenangkan ini, selama pelatihan ulang, kami memberlakukan batasan tambahan pada jaringan saraf, melarangnya untuk mengubah bobot terlalu banyak dibandingkan dengan keadaan awal.
Secara matematis, ini dinyatakan dengan menambahkan istilah ke fungsi kehilangan, yang
merupakan jarak Kullback - Leibler (KL-divergence) antara distribusi probabilitas kata berikutnya yang dihasilkan oleh jaringan asli dan yang dilatih ulang. Seperti yang dapat Anda lihat dalam ilustrasi, ini mengarah pada fakta bahwa peningkatan kualitas terjemahan halaman web tidak lagi mengarah pada degradasi terjemahan teks biasa.
 Memoles frasa frekuensi dari navigasi
Memoles frasa frekuensi dari navigasi . Dalam proses pengerjaan penerjemah baru, kami mengumpulkan statistik pada teks-teks dari berbagai segmen halaman web dan melihat yang menarik. Teks yang berhubungan dengan elemen navigasi cukup terstandarisasi, sehingga sering kali mereka adalah frase templat yang sama. Ini adalah efek yang sangat kuat sehingga lebih dari setengah dari semua frasa navigasi ditemukan di akun Internet hanya untuk 2 ribu yang paling sering.
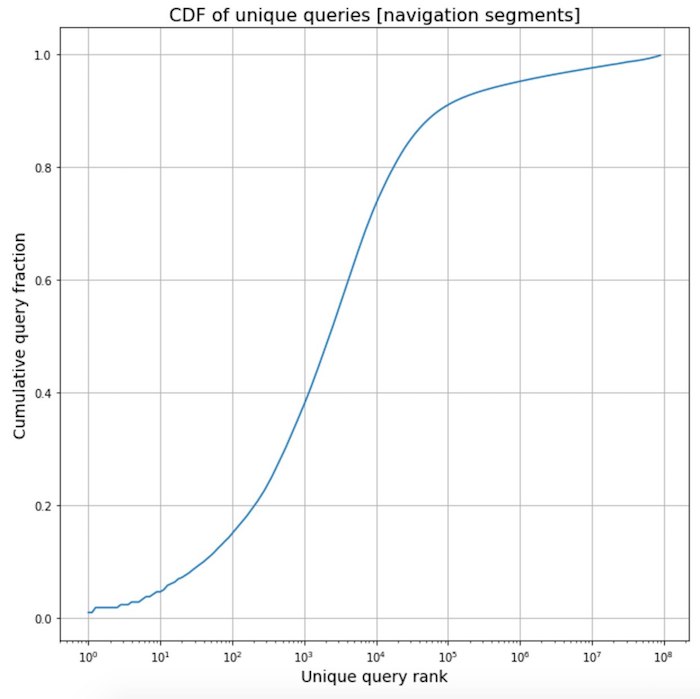
Tentu saja, kami memanfaatkan ini dan memberikan beberapa ribu frasa paling sering dan terjemahannya kepada penerjemah kami untuk verifikasi agar benar-benar yakin dengan kualitasnya.
Penjajaran eksternal. Ada persyaratan penting lain untuk penerjemah halaman web di Browser - itu tidak boleh merusak markup. Ketika tag HTML terletak di luar kalimat atau di perbatasannya, tidak ada masalah yang muncul. Tetapi jika ada, misalnya,
dua kata yang digarisbawahi di dalam kalimat, maka dalam terjemahan kita ingin melihat "dua kata yang
digarisbawahi ". Yaitu sebagai akibat dari transfer, dua kondisi harus dipenuhi:
- Fragmen yang digarisbawahi dalam terjemahan harus sesuai dengan fragmen yang digarisbawahi dalam teks sumber.
- Konsistensi terjemahan di perbatasan fragmen yang digarisbawahi tidak boleh dilanggar.
Untuk memastikan perilaku ini, pertama-tama kami menerjemahkan teks seperti biasa, dan kemudian menggunakan model statistik
penyelarasan kata- demi-
kata, kami menentukan korespondensi antara fragmen teks asli dan terjemahan. Ini membantu untuk memahami apa yang perlu ditekankan (sorot dalam huruf miring, format sebagai hyperlink, ...).
Pengamat titik-temu . Model terjemahan jaringan saraf yang kuat yang kami latih membutuhkan sumber daya komputasi yang jauh lebih banyak di server kami (baik CPU dan GPU) daripada model statistik generasi sebelumnya. Pada saat yang sama, pengguna tidak selalu membaca halaman sampai akhir, jadi mengirim semua teks halaman web ke cloud tampaknya tidak perlu. Untuk menghemat sumber daya server dan lalu lintas pengguna, kami mengajarkan Penerjemah untuk menggunakan
API Pengamat Persimpangan untuk hanya mengirim teks yang ditampilkan di layar untuk diterjemahkan. Karena hal ini, kami dapat mengurangi konsumsi lalu lintas untuk terjemahan lebih dari 3 kali.
Beberapa kata tentang hasil pengenalan penerjemah jaringan saraf dengan mempertimbangkan struktur halaman web di Yandex.Browser. Untuk menilai kualitas terjemahan, kami menggunakan metrik BLEU *, yang membandingkan terjemahan yang dibuat oleh mesin dan penerjemah profesional, dan mengevaluasi kualitas terjemahan mesin pada skala dari 0 hingga 100%. Semakin dekat terjemahan mesin ke terjemahan manusia, semakin tinggi persentasenya. Biasanya, pengguna melihat perubahan kualitas saat metrik BLEU tumbuh setidaknya 3%. Penerjemah Yandex.Browser baru menunjukkan peningkatan hampir 18%.

Terjemahan mesin adalah salah satu tugas yang paling kompleks, panas dan diteliti dalam bidang teknologi kecerdasan buatan. Ini karena murni daya tarik matematis dan relevansinya di dunia modern, di mana setiap detik sejumlah besar konten dibuat di Internet dalam berbagai bahasa. Terjemahan mesin, yang hingga baru-baru ini terutama menyebabkan tawa (ingat
pembuat mouse ), saat ini membantu pengguna mengatasi hambatan bahasa.
Kualitas yang ideal masih jauh, sehingga kami akan terus bergerak di garis depan teknologi ke arah ini sehingga pengguna Yandex.Browser dapat melampaui, misalnya, Runet dan menemukan konten yang berguna untuk diri mereka sendiri di mana saja di Internet.