Visi mesin adalah topik yang sangat panas akhir-akhir ini. Untuk mengatasi masalah mengenali tag toko menggunakan jaringan saraf, kami memilih kerangka kerja TensorFlow.
Artikel ini akan membahas cara menggunakannya untuk melokalisasi dan mengidentifikasi beberapa objek pada label harga toko yang sama, serta mengenali isinya.
Sebuah tag harga yang sama IKEA pengakuan tugas telah diselesaikan Habré dengan penggunaan alat-alat pengolahan gambar klasik yang tersedia di perpustakaan OpenCV.
Secara terpisah, saya ingin mencatat bahwa solusinya dapat bekerja baik pada platform SAP HANA bersama dengan Tensorflow Serving, dan pada SAP Cloud Platform.
Tugas mengenali harga barang relevan untuk pembeli yang ingin "meraba-raba" harga satu sama lain dan memilih toko untuk pembelian, dan untuk pengecer - mereka ingin belajar tentang harga pesaing secara real time.
Lirik cukup - pergi ke teknik!
ToolkitUntuk deteksi dan klasifikasi gambar, kami menggunakan jaringan saraf convolutional yang diimplementasikan di perpustakaan TensorFlow dan tersedia untuk kontrol melalui Object Detection API.
TensorFlow Object Detection API adalah metaframe open-source berdasarkan TensorFlow yang menyederhanakan pembuatan, pelatihan, dan penyebaran model untuk deteksi objek.
Setelah mendeteksi objek yang diinginkan, pengenalan teks di atasnya dilakukan menggunakan Tesseract, perpustakaan untuk pengenalan karakter. Sejak 2006, Tesseract dianggap sebagai salah satu perpustakaan OCR paling akurat yang tersedia di open source.
Mungkin saja Anda mengajukan pertanyaan - mengapa tidak semua pemrosesan dilakukan pada TF? Jawabannya sangat sederhana - ini akan membutuhkan waktu yang lebih lama untuk implementasi, tetapi tidak banyak. Lebih mudah mengorbankan kecepatan pemrosesan dan merakit prototipe yang sudah selesai daripada repot dengan OCR buatan sendiri.
Pembuatan dan persiapan datasetUntuk memulainya, perlu mengumpulkan bahan untuk bekerja. Kami mengunjungi 3 toko dan mengambil sekitar 400 foto dari label harga yang berbeda pada kamera ponsel dalam mode otomatis
Contoh foto: Fig. 1. Contoh gambar label harga
Fig. 1. Contoh gambar label harga Fig. 2. Contoh gambar label harga
Fig. 2. Contoh gambar label hargaSetelah itu, Anda perlu memproses dan menandai semua foto dari label harga. Dalam proses mengumpulkan gambar, kami mencoba mengumpulkan gambar berkualitas tinggi (tanpa artefak): label harga dengan format yang kira-kira sama, tanpa blur, rotasi signifikan, dll. Ini dilakukan untuk memudahkan perbandingan lebih lanjut dari konten pada label harga riil dan gambar digitalnya. Namun, jika kita melatih jaringan saraf hanya pada gambar berkualitas tinggi yang tersedia, ini akan secara alami mengarah pada fakta bahwa kepercayaan diri model dalam mengidentifikasi contoh yang terdistorsi akan turun secara signifikan. Untuk melatih jaringan saraf agar tahan terhadap situasi seperti itu, kami menggunakan prosedur terkenal untuk memperluas set pelatihan dengan versi gambar yang terdistorsi (augmentasi). Untuk menambah sampel pelatihan, kami menerapkan algoritma dari perpustakaan Imgaug: shift, belokan kecil, Gaussian blur, noise. Gambar terdistorsi ditambahkan ke sampel, yang meningkat sekitar 5 kali (dari 300 menjadi 1.500 gambar).
Untuk menandai gambar dan memilih objek, program LabelImg digunakan, yang tersedia di domain publik. Ini memungkinkan Anda untuk memilih objek yang diperlukan dalam gambar dengan persegi panjang dan menetapkan setiap kelas ke kotak pembatas. Semua koordinat dan label dari bingkai yang dibuat untuk setiap foto disimpan dalam file XML yang terpisah.
Objek berikut menonjol pada setiap foto: label harga produk, harga produk, nama produk, dan barcode produk pada label harga. Dalam beberapa contoh gambar, di mana itu dibenarkan secara logis, area ditandai dengan tumpang tindih.
 Fig. 3. Contoh foto sepasang label harga yang ditandai di LabelImg. Area dengan deskripsi produk, harga, dan barcode disorot.
Fig. 3. Contoh foto sepasang label harga yang ditandai di LabelImg. Area dengan deskripsi produk, harga, dan barcode disorot. Fig. 4. Contoh foto label harga yang ditandai di LabelImg. Area dengan deskripsi produk, harga, dan barcode disorot.
Fig. 4. Contoh foto label harga yang ditandai di LabelImg. Area dengan deskripsi produk, harga, dan barcode disorot.Setelah semua foto diproses dan ditandai, kami menyiapkan dataset dengan pemisahan semua foto dan menandai file menjadi pelatihan dan sampel uji. Biasanya mengambil 80% dari sampel pelatihan hingga 20% dari sampel uji dan mencampur secara acak.
Selanjutnya, pada mesin di mana model akan dilatih, perlu untuk menginstal semua perpustakaan yang diperlukan. Pertama-tama, kami menginstal perpustakaan pembelajaran mesin TensorFlow. Tergantung pada jenis sistem Anda dan Anda perlu menginstal perpustakaan tambahan untuk komputasi pada GPU. Selanjutnya, instal perpustakaan API Deteksi Objek Tensorflow dan perpustakaan tambahan untuk bekerja dengan gambar dan grafik. Di bawah ini adalah daftar perpustakaan yang kami gunakan dalam pekerjaan kami:
TensorFlow-GPU v1.5, CUDA v9.0, cuDNN v7.0
Protobuf 3+, Python-tk, Bantal 1.0, lxml, tf Slim, notebook Jupyter, Matplotlib
Tensorflow, Cython, Cocoapi; Opencv-python; PandaKetika semua langkah instalasi selesai, Anda dapat melanjutkan untuk mempersiapkan data dan mengatur parameter pembelajaran.
Pelatihan modelUntuk mengatasi masalah kami, kami menggunakan dua versi jaringan saraf pra-pelatihan MobileNet V2 dan Faster-RCNN V2 pada set data coco sebagai ekstraktor properti gambar. Model dilatih ulang menjadi 4 kelas baru: label harga, deskripsi produk, harga, barcode. Sebagai yang utama, kami memilih MobileNet V2, yang merupakan model yang relatif sederhana yang memungkinkan kami untuk memberikan kualitas yang dapat diterima dengan kecepatan yang menyenangkan. MobileNet V2 memungkinkan Anda untuk menerapkan pengenalan gambar bahkan di perangkat seluler.
Pertama, Anda perlu memberi tahu perpustakaan Tensorflow Object Detection API jumlah label, serta nama-nama label ini.
Hal terakhir yang harus dilakukan sebelum pelatihan adalah membuat peta cara pintas dan mengedit file konfigurasi. Peta label menginformasikan model dan memetakan nama kelas ke nomor pengenal kelas untuk setiap objek.

Terakhir, Anda perlu mengonfigurasi sumber belajar untuk Deteksi Objek untuk menentukan model dan parameter mana yang akan digunakan untuk pelatihan. Ini adalah langkah terakhir sebelum memulai pelatihan.

Prosedur pelatihan dimulai dengan perintah:
python train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/mobilenet.config
Jika semuanya dikonfigurasi dengan benar, TensorFlow menginisialisasi pelatihan ulang dari jaringan saraf. Inisialisasi dapat memakan waktu hingga 30 detik sebelum pelatihan yang sebenarnya dimulai. Ketika jaringan saraf dilatih ulang pada setiap langkah, nilai fungsi kesalahan algoritma (kerugian) akan ditampilkan. Untuk MobileNet V2, nilai awal dari fungsi kerugian adalah sekitar 20. Model ini harus dilatih sampai fungsi kehilangan turun ke nilai sekitar 2. Untuk memvisualisasikan proses pembelajaran jaringan saraf, Anda dapat menggunakan utilitas TensorBoard yang nyaman.
: tensorboard
Perintah menginisialisasi antarmuka web pada mesin lokal, yang akan tersedia di localhost: 6006. Setelah berhenti, prosedur pelatihan dapat dilanjutkan lagi menggunakan pos pemeriksaan yang disimpan setiap 5 menit.
Pengakuan label harga dan unsur-unsurnyaKetika pelatihan selesai, langkah terakhir adalah membuat grafik jaringan saraf. Ini dilakukan oleh perintah konsol, di mana di bawah tanda bintang Anda harus menentukan jumlah file cpkt terbesar yang ada di direktori pelatihan.
python export_inference_graph.py --input_type image_tensor --pipeline_config_path training/faster_rcnn_inception_v2.config --trained_checkpoint_prefix training/model.ckpt-**** --output_directory inference_graph
Setelah prosedur ini, classifier deteksi objek siap untuk operasi. Untuk memeriksa pengenalan gambar, cukup menjalankan skrip yang datang dengan pustaka Deteksi Objek Tensorflow yang menunjukkan model yang sebelumnya dilatih dan foto untuk pengakuan. Contoh skrip Python standar disediakan di
sini .
Dalam contoh kami, dibutuhkan sekitar 1,5 detik untuk mengenali satu foto menggunakan model mobilenet SSD pada laptop sederhana.
 Fig. 5. Hasil pengenalan gambar dengan label harga dalam sampel uji
Fig. 5. Hasil pengenalan gambar dengan label harga dalam sampel uji Fig. 6. Hasil pengenalan gambar dengan label harga dalam sampel uji
Fig. 6. Hasil pengenalan gambar dengan label harga dalam sampel ujiKetika kami yakin bahwa label harga terdeteksi secara normal, maka perlu untuk mengajarkan model untuk membaca informasi dari elemen individu: harga barang, nama barang, dan kode batang. Untuk ini, ada perpustakaan yang tersedia di Python untuk mengenali karakter dan barcode dalam foto - Pyzbar dan Tesseract.
Sebelum Anda mulai mengenali karakter dan barcode di foto, Anda perlu memotong foto ini menjadi elemen yang kita butuhkan - untuk meningkatkan kecepatan dan tidak mengenali informasi yang tidak perlu yang tidak termasuk dalam label harga. Juga penting untuk "menarik" koordinat objek yang dikenali oleh model beserta kelasnya.

Kemudian kami menggunakan koordinat ini untuk memotong foto kami menjadi beberapa bagian untuk mengenali hanya area yang diperlukan.


 Fig. 7. Contoh bagian yang disorot dari label harga
Fig. 7. Contoh bagian yang disorot dari label hargaSelanjutnya, kami mentransfer semua area cut-out ke perpustakaan: nama produk dan harga produk ditransfer ke tesseract, dan barcode ke pyzbar, dan kami mendapatkan hasil pengakuan.

 Fig. 8. Contoh konten yang dikenali adalah area label harga.
Fig. 8. Contoh konten yang dikenali adalah area label harga.Pada titik ini, pengenalan teks dan kode batang dapat menyebabkan masalah jika gambar aslinya dalam resolusi rendah atau buram. Jika harga dapat dikenali secara normal karena banyaknya angka pada label harga, maka nama produk dan kode batang akan kurang didefinisikan atau tidak didefinisikan sama sekali. Untuk melakukan ini, disarankan untuk tidak menggunakan foto kecil untuk pengakuan, dan juga untuk mengunggah gambar tanpa noise dan distorsi yang kuat - misalnya, tanpa kurangnya fokus yang tepat.
Contoh Pengenalan Gambar Buruk:



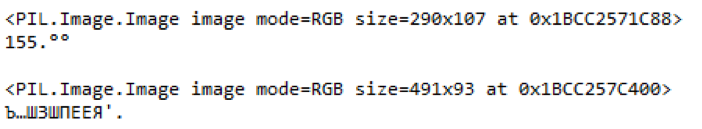 Fig. 9. Contoh bagian yang disorot dari label harga kabur dan konten yang dikenali
Fig. 9. Contoh bagian yang disorot dari label harga kabur dan konten yang dikenaliDalam contoh ini, Anda dapat melihat bahwa jika harga barang dikenali kurang lebih benar dalam citra berkualitas buruk, maka perpustakaan tidak dapat mengatasi nama barang tersebut. Dan barcode tidak dikenali sama sekali.
Teks yang sama dalam kualitas yang baik.

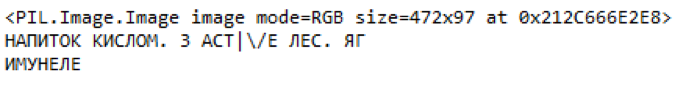 Fig. 10. Contoh bagian label harga yang disorot dan konten yang dikenaliKesimpulan
Fig. 10. Contoh bagian label harga yang disorot dan konten yang dikenaliKesimpulanPada akhirnya, kami berhasil mendapatkan model kualitas yang dapat diterima dengan persentase kesalahan yang rendah dan persentase tinggi deteksi objek yang relevan. Lebih cepat-RCNN Inception V2 memiliki kualitas pengenalan yang lebih baik daripada MobileNet SSD V2, tetapi tentang urutan besarnya lebih rendah dalam kecepatan, yang merupakan batasan yang signifikan.
Keakuratan yang diperoleh dari pengenalan label harga pada sampel 50 sampel yang tertunda adalah 100%, yaitu, semua label harga berhasil diidentifikasi di semua foto. Akurasi pengenalan area dengan barcode dan harga adalah 90%. Akurasi pengenalan area teks adalah 85%. Keakuratan pembacaan harga sekitar 95%, dan teks - 80-85%. Selain itu, sebagai percobaan, kami menyajikan hasil pengenalan label harga, yang sama sekali berbeda dari label harga dalam sampel pelatihan.
 Fig. 11. Contoh pengakuan dari label harga atipikal yang tidak ada dalam set pelatihan.
Fig. 11. Contoh pengakuan dari label harga atipikal yang tidak ada dalam set pelatihan.Seperti yang Anda lihat, bahkan dengan label harga yang sangat berbeda dari label harga pelatihan, modelnya bukan tanpa kesalahan, tetapi objek yang signifikan dapat dikenali pada label harga.
Apa lagi yang bisa dilakukan?1) Artikel keren tentang augmentasi otomatis baru-baru ini telah dirilis, pendekatan yang dapat digunakan
2) Model yang sudah jadi dapat dan harus dikompres secara substansial
3) Contoh penerbitan layanan jadi di SCP dan TFS
Dalam mempersiapkan prototipe dan artikel ini, bahan-bahan berikut digunakan:1.
Membawa Pembelajaran Mesin (TensorFlow) ke perusahaan dengan SAP HANA2.
SAP Leonardo ML Foundation - Bawa Model Anda Sendiri (BYOM)3.
Deteksi Objek TensorFlow Repositori GitHub4.
Periksa Artikel Pengakuan IKEA5.
Artikel tentang manfaat MobileNet6.
Artikel Deteksi Objek TensorFlowArtikel ini disiapkan oleh:
Sergey Abdurakipov, Dmitry Buslov, Alexey Khristenko