 Foto: Alexander Korolkov / WG
Foto: Alexander Korolkov / WGPada 3 Juni, pada hari terakhir Festival Buku Moskow di Lapangan Merah, ahli bahasa
Alexander Pipersky berbicara tentang linguistik komputer. Dia berbicara tentang terjemahan mesin, jaringan saraf, pemetaan vektor kata-kata, dan mengajukan pertanyaan tentang batas-batas kecerdasan buatan.
Orang yang berbeda mendengarkan ceramah. Di sebelah kanan saya, misalnya, seorang turis Cina mematuk hidungnya. Alexander, tentu saja, juga mengerti - beberapa angka tambahan, formula dan kata-kata tentang algoritma, dan orang-orang akan lari ke tenda berikutnya untuk mendengarkan para penulis fiksi ilmiah.
Saya meminta Alexander untuk mempersiapkan Habr versi "penyutradaraan" dari kuliah, di mana tidak ada yang dipotong yang dapat menidurkan wisatawan acak. Bagaimanapun, sebagian besar presentasi tidak memiliki audiensi dengan pertanyaan yang masuk akal dan umumnya diskusi yang baik. Saya pikir kita bisa mengembangkannya di sini.
Di mana AI mulai?
Sejak baru-baru ini, kami terus berkomunikasi dengan komputer dalam suara, dan semua jenis suara Alice, Alexa dan Siri menjawab kami. Jika Anda melihat dari samping, tampaknya komputer memahami kami, memberikan daftar situs yang relevan, melaporkan alamat restoran terdekat, menunjukkan cara menuju ke sana.
Sepertinya kita sedang berhadapan dengan perangkat yang cukup pintar. Anda bahkan bisa mengatakan perangkat ini memiliki apa yang disebut kecerdasan buatan (AI). Meskipun tidak ada yang benar-benar mengerti apa artinya ini dan ke mana perbatasan pergi.
Ketika kita diberi tahu, "AI melakukan fungsi kreatif yang dianggap sebagai hak prerogatif manusia" - apa artinya? Apa itu fitur kreatif? Fungsi mana yang kreatif dan mana yang tidak? Memilih restoran Cina terdekat adalah fitur kreatif? Sekarang sepertinya tidak mungkin.
Kami terus-menerus cenderung menolak kecerdasan buatan ke komputer. Segera setelah kita terbiasa dengan manifestasi intelektual yang dibuat komputer, kita berkata, "ini bukan AI, ini omong kosong, tugas templat, tidak ada yang menarik."
Contoh sederhana - dari sudut pandang kami, tidak ada yang lebih buruk dari kalkulator saku. Itu dijual di kios apa pun untuk 50 rubel. Ambil kalkulator delapan-bit yang biasa, tekan tombol dan dapatkan hasilnya dalam hitungan detik. Nah, Anda pikir, dia memikirkan beberapa hal. Ini bukan kecerdasan.
Dan bayangkan mesin seperti itu di abad XVIII. Itu akan tampak seperti mukjizat, karena perhitungan adalah hak prerogatif manusia.
Hal yang sama terjadi dengan linguistik komputer. Kami cenderung membenci semua prestasinya. Saya memasukkan ke dalam Google kueri "Ayat Pushkin", dia menemukan halaman yang mengatakan "A.S. Pushkin - Puisi. " Tampaknya ini? Perilaku yang benar-benar normal. Tetapi ahli bahasa komputer harus menghabiskan puluhan tahun untuk kata puisi ditemukan dalam kata puisi, untuk kata Pushkin dapat ditemukan dalam kata Pushkin dan tidak ditemukan dalam Pushkin.
Terjemahan Catur dan Mesin Komputer
Linguistik komputer lahir pada saat yang sama dengan catur komputer - dan catur juga pernah menjadi hak prerogatif manusia. Claude Shannon, salah satu pendiri ilmu komputer, menulis
sebuah artikel pada tahun 1950
tentang cara memprogram komputer untuk bermain catur. Menurutnya, kita bisa mengembangkan dua jenis strategi.
A - dengan pencarian sekuel yang lengkap. Penting untuk menguji semua gerakan yang mungkin pada setiap tahap.
B - beralih hanya dari ekstensi yang dinilai menjanjikan.
Orang itu, jelas, menggunakan strategi B. Grandmaster, kemungkinan besar, hanya melalui opsi yang masuk akal menurut pendapatnya, dan dalam waktu yang cukup cepat memberikan langkah yang baik.
Strategi A sulit untuk diimplementasikan. Menurut perhitungan Shannon, untuk menghitung tiga gerakan, Anda perlu memilah 10
9 opsi, dan jika posisinya diperkirakan satu mikrodetik (yang super-optimis di pertengahan abad ke-20), maka akan diperlukan 17 menit untuk melakukan satu gerakan. Dan tiga langkah maju adalah kedalaman prediksi yang tidak signifikan.
Seluruh sejarah catur berikutnya terdiri dari pengembangan teknik yang memungkinkan kita untuk tidak memilah semuanya, tetapi untuk memahami apa yang perlu disortir dan apa yang tidak diperlukan. Dan kemenangan atas manusia telah tercapai, akhirnya dan tidak dapat dibatalkan. Komputer melewati juara catur dunia sekitar 20 tahun yang lalu, dan sejak itu hanya membaik.
Program terbaik dianggap Stockfish. Tahun lalu, AlphaZero memainkan 100 pertandingan dengannya.
| Putih | Hitam | Kemenangan putih | Gambar | Kemenangan Black |
|---|
| AlphaZero | Stockfish | 25 | 25 | 0 |
| Stockfish | AlphaZero | 0 | 47 | 3 |
AlphaZero adalah jaringan saraf tiruan yang baru saja bermain catur selama empat jam. Dan dia belajar bermain lebih baik dari semua program sebelumnya.
Hal serupa terjadi di linguistik komputer sekarang - lonjakan pemodelan jaringan saraf. Mereka mulai mengerjakan catur mesin secara bersamaan dengan terjemahan mesin - di pertengahan abad terakhir. Sejak itu, tiga tahap pembangunan telah dibedakan.
- Terjemahan mesin berbasis aturanIni dirancang sangat sederhana - sesuatu seperti dalam pelajaran tata bahasa, komputer memilih subjek, predikat, tambahan. Dia mengerti dengan kata apa semua ini diterjemahkan ke bahasa lain, belajar bagaimana mengekspresikan subjek, predikat, penambahan, dan semuanya.
Terjemahan seperti itu dikembangkan lebih dari 30 tahun, tidak banyak berhasil.
- Terjemahan statistik (frasa)Komputer bergantung pada database besar teks yang diterjemahkan manusia. Itu memilih kata-kata dan frasa di dalamnya yang sesuai dengan kata-kata dan frasa asli, mengumpulkan mereka ke dalam kalimat dalam bahasa target dan memberikan hasilnya.
Ketika di Internet mereka menulis tentang “20 terjemahan mesin paling bodoh berikutnya” - kemungkinan besar, ini tentang terjemahan frasa. Meskipun ia mencapai beberapa kesuksesan.
- Terjemahan jaringan sarafKami akan berbicara lebih banyak tentang dia. Itu memasuki penggunaan massal tepat di depan mata kita: Google menyalakan terjemahan jaringan saraf pada akhir 2016. Untuk Rusia, ia muncul pada Maret 2017. Yandex meluncurkan pada akhir 2017 sistem hybrid berdasarkan jaringan saraf dan statistik.
Jaringan saraf
Terjemahan jaringan saraf didasarkan pada ide berikut: jika secara matematis mensimulasikan dan mereproduksi karya neuron di kepala seseorang, dapat diasumsikan bahwa komputer akan belajar bagaimana bekerja dengan bahasa seperti halnya seseorang.
Untuk melakukan ini, lihat sel-sel di otak manusia.
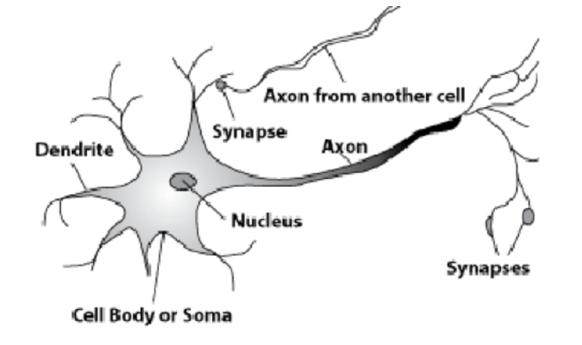
Ini neuron alami. Proses panjang, akson, berangkat dari nukleus. Itu menempel pada proses dari sel lain - sinapsis. Menurut akson, informasi tentang beberapa proses elektrokimia ditransmisikan ke sinapsis sel sel. Hanya satu akson yang muncul dari setiap sel, dan banyak sinapsis dapat masuk. Sinyal menyebar, dan ini adalah bagaimana informasi dikirimkan.
Beberapa sel terhubung ke dunia luar. Mereka menerima sinyal yang diproses lebih lanjut oleh jaringan saraf.
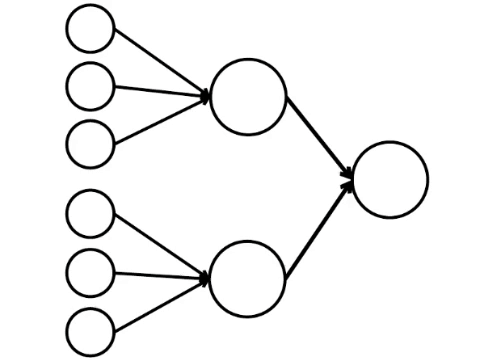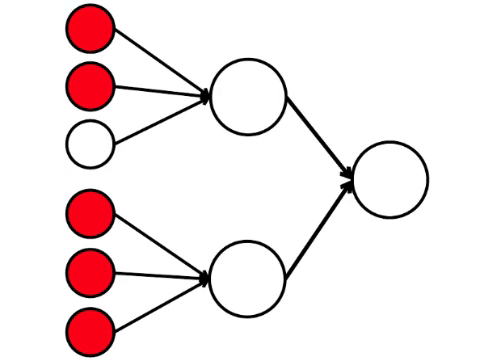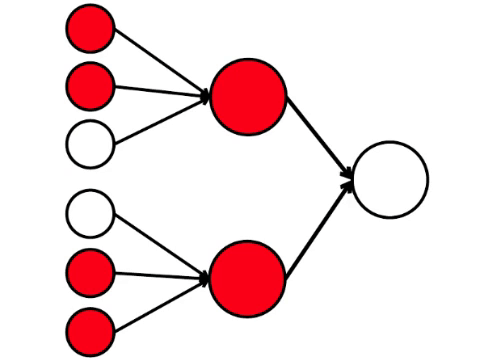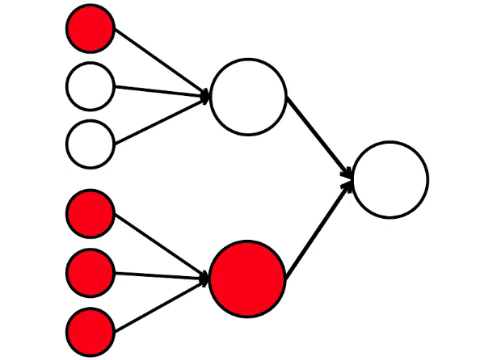
Dan ini adalah model matematika paling sederhana dari apa yang bisa kita lakukan di sini. Saya menggambar sembilan lingkaran yang terhubung. Ini adalah neuron.

Enam neuron di sebelah kiri adalah lapisan input, yang menerima sinyal dari lingkungan eksternal. Neuron pada lapisan kedua dan ketiga tidak menyentuh lingkungan, tetapi hanya dengan neuron lain. Kami memperkenalkan aturan - jika setidaknya dua panah dari neuron yang diaktifkan memasuki neuron, maka neuron ini juga diaktifkan.
Jaringan saraf memproses sinyal yang diterima pada input, dan akhirnya, output-kanan - neuron menyala atau tidak menyala. Dengan arsitektur ini, untuk mengaktifkan neuron kanan, Anda memerlukan setidaknya empat neuron aktif di baris kiri. Jika 6 atau 5 menyala, pasti akan menyala, jika dari 0 hingga 3, itu pasti tidak akan menyala. Tetapi jika empat terbakar, maka hanya akan menyala jika dibagikan secara merata: 2 di bagian atas dan 2 di bagian bawah.
Ternyata skema sembilan lingkaran yang paling sederhana mengarah pada argumen yang agak bercabang.
Jaringan saraf tiruan bekerja dengan cara yang hampir sama, tetapi biasanya tidak dengan hal-hal sederhana seperti "menyala / tidak menyala" (yaitu, 1 atau 0), tetapi dengan bilangan real.
Ambil contoh jaringan 5 neuron - dua di lapisan input, dua di tengah (tersembunyi) dan satu di output. Di antara semua neuron lapisan tetangga ada koneksi ke mana nomor ditugaskan - bobot. Untuk mengetahui apa yang terjadi pada neuron yang belum kosong, mari kita lakukan hal yang sangat sederhana: mari kita lihat apa yang menyebabkan koneksi, kalikan bobot setiap koneksi dengan jumlah yang ditulis dalam neuron dari lapisan sebelumnya dari mana koneksi ini datang, dan kami akan merangkum semuanya. Dalam neuron hijau atas dalam diagram, 50 × 1 + 3 × 10 = 80 diperoleh, dan di bagian bawah - 50 × 0,5 - 3 × 10 = −5.
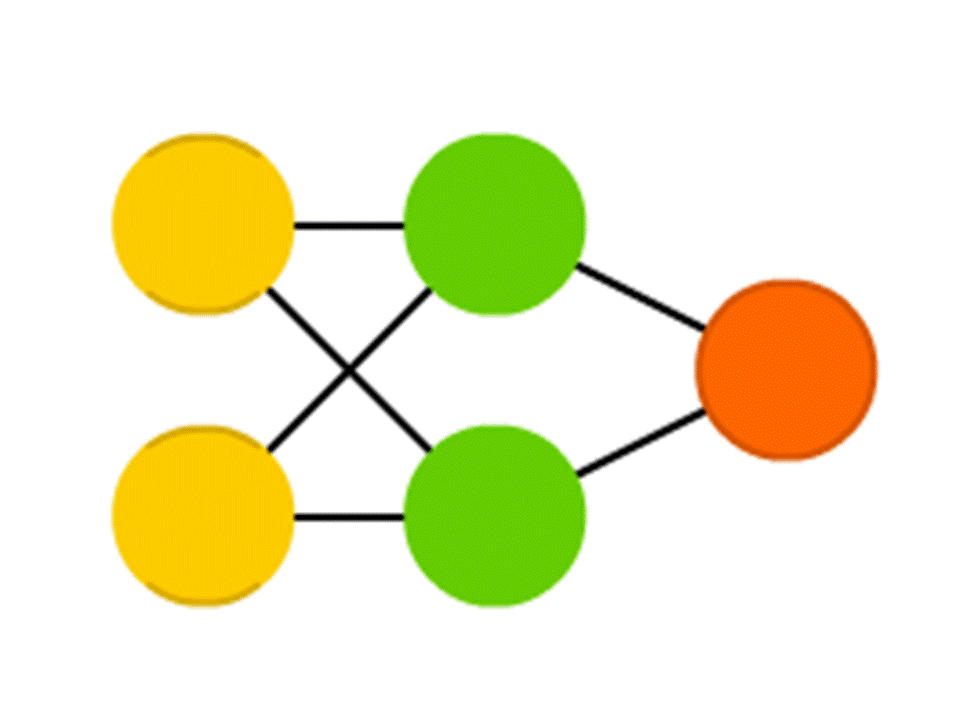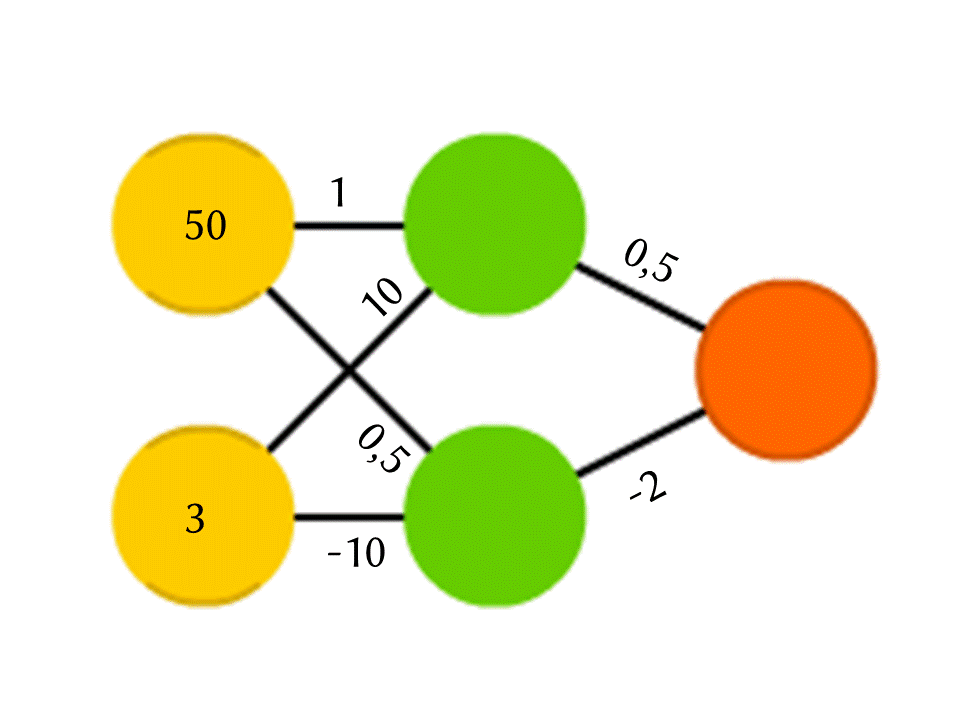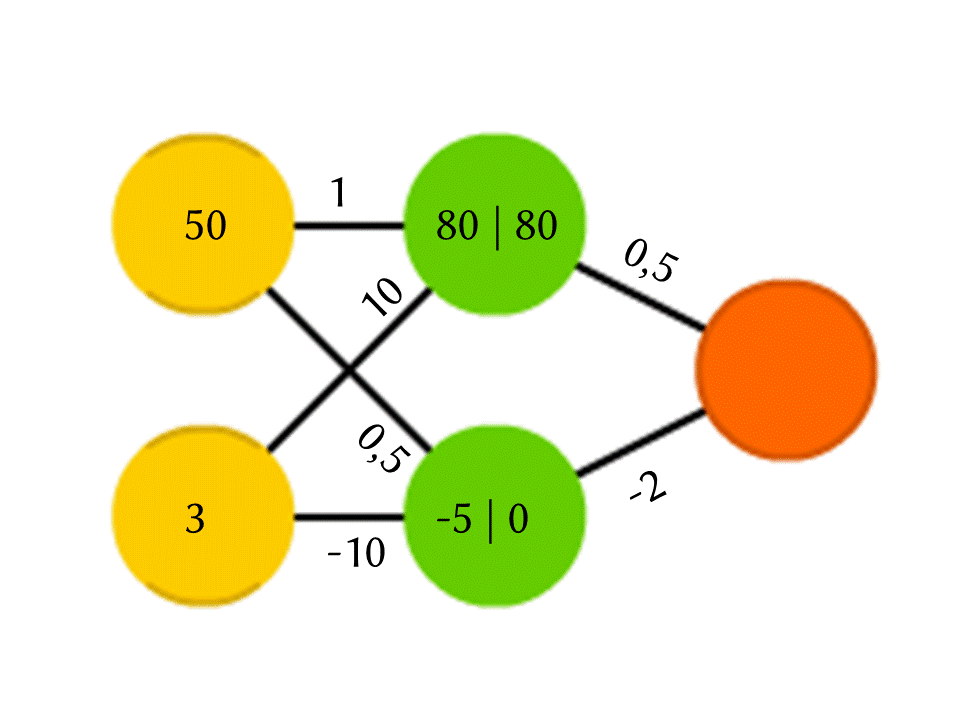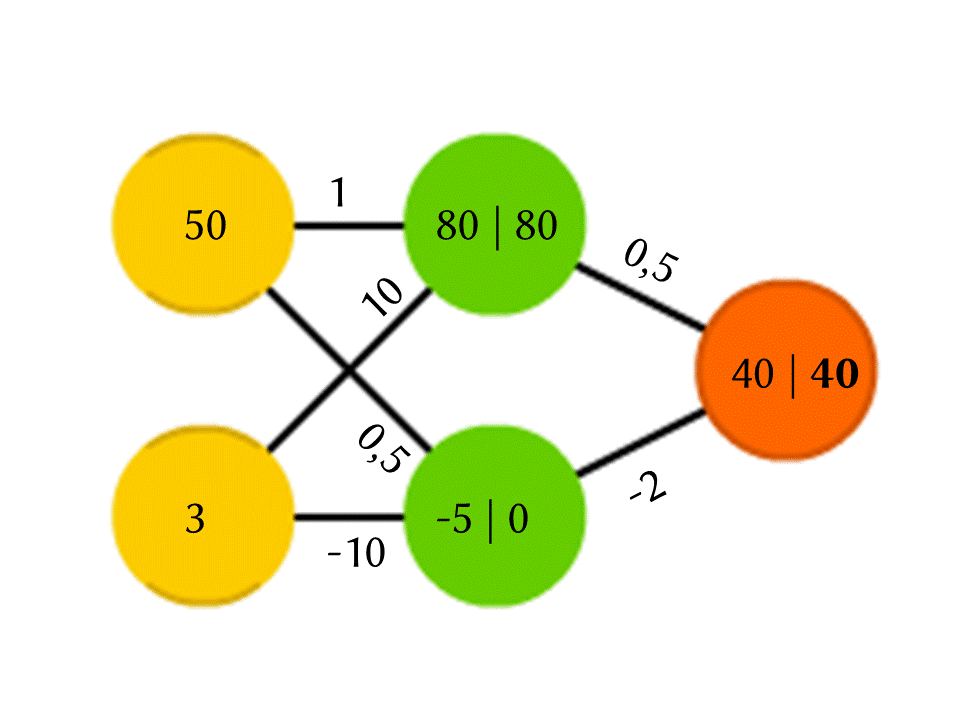
Benar, jika Anda melakukan hal itu, output hanya akan menjadi hasil dari penghitungan fungsi linier dari nilai input (dalam contoh kami, 25 Y - 0,5 X akan keluar, di mana X adalah angka di neuron kuning atas dan Y adalah di bawah), jadi kami akan setuju sesuatu yang lain sedang terjadi di dalam neuron. Fungsi yang paling sederhana dan sekaligus memberikan hasil yang baik adalah ReLU (Rectified Linear Unit): jika angka negatif diperoleh dalam neuron, output 0, dan jika tidak negatif, maka outputnya tidak berubah.
Jadi, dalam skema kami, −5 di pintu keluar dari neuron hijau bawah berubah menjadi 0, dan nomor inilah yang digunakan dalam perhitungan lebih lanjut. Tentu saja, arsitektur jaringan saraf nyata yang digunakan dalam praktik jauh lebih rumit daripada contoh mainan kami, dan bobot tidak diambil dari langit-langit, tetapi dipilih melalui pelatihan, tetapi prinsip itu sendiri penting.
Apa hubungannya ini dengan bahasa?
Yang paling langsung, asalkan kami mewakili bahasa dalam bentuk angka. Kami menyandikan setiap kata dan mengalami jaringan saraf seperti itu.
Di sini pencapaian yang sangat penting dari linguistik komputer datang untuk menyelamatkan, yang muncul dalam hal ide 50 tahun yang lalu, dan dalam hal implementasi, 10 tahun terakhir telah aktif berkembang: representasi vektor kata-kata.
 ini dan dua gambar berikutnya dari presentasi oleh Stefan Evert
ini dan dua gambar berikutnya dari presentasi oleh Stefan EvertIni adalah representasi kata-kata sebagai susunan angka berdasarkan pertimbangan yang sangat sederhana. Untuk mencari tahu arti kata, kita tidak melihat kamus, tetapi pada array teks yang besar dan mempertimbangkan di sebelah mana kata kita lebih umum.
Misalnya, apakah Anda tahu kata muffler? Jika tidak, coba tebak dengan melihat teks di mana kata itu teredam.
- Jas hitam dan topi putih. Yah, dan masih ada knalpot yang sangat diperlukan ...
Di sebelahnya ada barang-barang pakaian, mantel dan topi, dan mungkin syal dari antara mereka. Ini bukan makanan, bukan elemen arsitektur.
- Untuk beberapa alasan, di lehernya di malam yang pengap, knalpot bergaris tua ditaburi.
Di leher - ini berarti mereka bukan kaus kaki. Anda dapat menangkapnya - tampaknya, fleksibel, terbuat dari kain, dan bukan, katakanlah, dari kayu atau batu.
- Handuk wafel kutsey basah Nerzhin tergantung di lehernya seperti syal.
Kami mengisi dan mengisi kembali bank contoh, dan melihat contoh itu, kami akan secara bertahap memahami apa yang diredam - sesuatu seperti syal. Komputer melakukan hal yang persis sama, yang melihat teks dan melakukan hal yang sederhana - menangkap kata-kata yang berdiri di dekatnya.
Berikut adalah hieroglif Mesir.
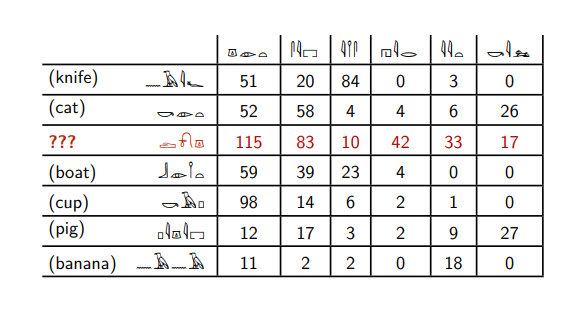
Misalkan Anda tahu arti enam dari mereka, dan ingin memahami apa jenis kata yang disorot dalam warna merah. Tabel ini mengatakan berapa kali kata-kata ini ditemukan di sebelah hieroglif Mesir lainnya.
Kata merah muncul dengan kata keenam - seperti kata
kucing dan
babi . Dan kata-kata lain tidak terjadi sama sekali dengannya.
Kata merah ditemukan dengan kata kedua jauh lebih sering daripada dengan yang ketiga, berbeda dengan kata
pisau dan
pisang . Kata-kata
kucing, perahu, babi, dan
cangkir berperilaku sama.
Berdasarkan alasan tersebut, kita dapat mengatakan bahwa kata merah paling mirip dengan kata
kucing dan
babi - hanya saja mereka bertemu dengan kata keenam, mereka memiliki rasio yang sama dari yang kedua dan ketiga.
Dan kita tidak akan salah, karena kata merah adalah kata
anjing .

Sebenarnya, ini bukan hieroglif Mesir, tetapi kata benda dan kata kerja dalam bahasa Inggris, yang di dalamnya ditunjukkan berapa kali mereka muncul bersama dalam koleksi teks-teks bahasa Inggris yang besar. Kata keenam itu adalah kata kerja
kill .
Kata-kata
kucing, anjing dan
babi sering ditemukan di sebelah kanan kata
kill . Pisau, perahu dan pisang jarang sekali terbunuh. Meskipun dalam bahasa Rusia, jika Anda mau, Anda bisa mengatakan, "Saya membunuh perahuku", tetapi ini adalah hal yang langka.
Persis apa yang dilakukan komputer saat memproses teks. Dia hanya percaya bahwa dia bertemu dengan sesuatu, dan tidak ada lagi mahakarya pemahaman.
Lebih lanjut, komputer menyajikan kata-kata dalam bentuk sekumpulan angka: pada contoh di atas, kata
anjing berhubungan dengan angka (115; 83; 10; 42; 33; 17). Faktanya, kita harus menghitung berapa kali itu terjadi bukan dengan enam kata, tetapi dengan semua kata yang ada dalam teks kita: jika kita semua memiliki 100.000 kata yang berbeda, maka kita mengasosiasikan kata
anjing dengan deretan angka 100.000. Ini tidak terlalu praktis dalam prakteknya, oleh karena itu, metode pengurangan dimensi biasanya digunakan untuk mengubah hasil untuk setiap kata menjadi array yang terdiri dari beberapa ratus elemen panjangnya (lebih lanjut tentang ini dapat ditemukan di
sini ).
Ada pustaka siap pakai untuk bahasa pemrograman yang memungkinkan Anda melakukan ini: misalnya,
gensim untuk Python. Dengan mengirimkannya
corpus bahasa Inggris Brown dengan volume sekitar 1 juta kata, dalam beberapa detik saya dapat membangun model di mana kata
kucing akan terlihat seperti ini:

Kami mewakili seekor binatang, dengan rambut, ekor, mengeong. Komputer saya, yang saya ajarkan Bahasa Inggris, mewakili kata
cat dalam bentuk seratus angka yang berasal dari kata-kata di sebelahnya.
Berikut ini adalah contoh dalam materi Rusia dari situs web
RusVectōres . Saya mengambil kata
gagak dan meminta komputer untuk memberi tahu saya kata-kata mana yang paling mirip dengannya - atau, dengan kata lain, kumpulan angka yang kata-katanya paling mirip dengan kumpulan angka untuk kata
gagak .

8 dari 10 kata ternyata adalah nama burung. Tidak tahu apa-apa, komputer menghasilkan hasil yang luar biasa - saya menyadari bahwa burung terlihat seperti burung gagak. Tapi dari mana kata-kata merah panas dan ruchenka berasal?
Anda bisa menebakDengan ketiganya, kata putih sering digunakan: untuk panas putih, di bawah gagang putih, gagak putih.
Menerima array angka dan melewati mereka sendiri, jaringan saraf memberikan hasil yang luar biasa baik. Berikut ini adalah teks filosofis yang agak rumit dari pidato oleh akademisi Andrei Zaliznyak tentang status sains di dunia modern. Itu diterjemahkan ke dalam bahasa Inggris oleh seorang penerjemah sebulan yang lalu, dan memerlukan intervensi editorial minimal.

Ini menimbulkan pertanyaan filosofis global
Ini adalah masalah yang disebut kamar Cina - percobaan pikiran tentang batas kecerdasan buatan. Itu dirumuskan oleh filsuf John Searle pada 1980.
Di kamar duduk seorang pria yang tidak tahu bahasa Cina. Dia diberi instruksi, dia punya buku, kamus, dan dua jendela. Di satu jendela ia diberikan catatan dalam bahasa Cina, dan di jendela lain ia memberikan jawaban - juga dalam bahasa Cina, bertindak secara eksklusif sesuai instruksi.
Misalnya, instruksi dapat mengatakan, “di sini Anda memiliki catatan, cari karakter di kamus. Jika hieroglif No. 518, berikan hieroglif No. 409 ke jendela kanan; jika hieroglif No. 711 telah tiba, berikan hieroglif No. 35 ke jendela kanan dan seterusnya. " Jika orang di ruangan mengikuti instruksi dengan baik dan jika instruksi ini ditulis dengan baik, maka orang di jalan yang memberi dan menerima catatan dapat berasumsi bahwa ruangan atau orang di dalamnya tahu bahasa Cina. Lagi pula, tidak terlihat dari luar apa yang terjadi di dalam.
Kita semua tahu bahwa ini adalah pria yang hanya diberi instruksi bodoh. Dia melakukan beberapa operasi pada mereka, tetapi tidak tahu bahasa Mandarin sama sekali. Meskipun dari sudut pandang pengamat itu adalah pengetahuan bahasa.
Pertanyaan filosofis - bagaimana kita berhubungan dengan ini? Apakah ruangan itu berbahasa Cina? Mungkin pengarang instruksi ini tahu bahasa Mandarin? Dan mungkin tidak, karena Anda dapat mengeluarkan instruksi berdasarkan serangkaian pertanyaan dan jawaban yang sudah jadi.
Di sisi lain, apa yang diketahui orang Cina? Di sini Anda tahu bahasa Rusia. Apa yang bisa kamu lakukan Apa yang terjadi di kepala Anda? Semacam reaksi biokimia. Telinga atau mata menerima sinyal tertentu, itu menyebabkan semacam reaksi, Anda mengerti sesuatu. Tapi apa artinya "mengerti"? Apa yang kamu lakukan saat kamu mengerti?
Dan pertanyaan yang lebih rumit - apakah Anda melakukan ini secara optimal? Benarkah Anda bekerja dengan bahasa lebih baik daripada mesin mana pun bisa bekerja dengan bahasa itu? Dapatkah Anda bayangkan bahwa Anda akan berbicara bahasa Rusia lebih buruk daripada komputer mana pun? Kami selalu membandingkan Siri, Alice dengan cara kami berbicara sendiri, dan tertawa jika mereka berbicara salah dari sudut pandang kami. Di sisi lain, Anda dan saya memberi komputer banyak hal yang sebelumnya dianggap hak prerogatif manusia. Sekarang mobil jauh lebih baik dalam menghitung dan bermain catur, tetapi sebelumnya mereka tidak bisa. Mungkin hal serupa akan terjadi dengan komputer yang berbicara: dalam 100, 10, atau bahkan 5 tahun, kami menyadari bahwa mesin telah menguasai bahasa jauh lebih baik, mengerti lebih banyak, dan secara umum adalah penutur asli yang jauh lebih baik daripada kita.
Lalu apa yang harus dilakukan dengan fakta bahwa seseorang terbiasa mendefinisikan dirinya sendiri melalui bahasa? Lagipula, mereka mengatakan bahwa hanya seseorang yang berbicara bahasa tersebut. Apa yang akan terjadi jika kita mengenali kemenangan di depan komputer di area ini?
Tinggalkan pertanyaan Anda di komentar. Mungkin nanti kita bisa melakukan wawancara dengan Alexander. Atau mungkin dia sendiri akan datang mengomentari undangan kami dan berbicara dengan semua orang yang tertarik.