 Hai Nama saya Marco, saya bekerja untuk Badoo di departemen Platform. Kami memiliki banyak hal yang ditulis dalam Go, dan seringkali ini penting untuk kinerja sistem. Itulah sebabnya hari ini saya menawarkan terjemahan sebuah artikel yang sangat saya sukai dan, saya yakin, akan sangat berguna bagi Anda. Penulis menunjukkan langkah demi langkah bagaimana ia mendekati masalah kinerja dan bagaimana mereka memecahkannya. Termasuk Anda akan berkenalan dengan alat kaya yang tersedia di Go untuk pekerjaan seperti itu. Selamat membaca!
Hai Nama saya Marco, saya bekerja untuk Badoo di departemen Platform. Kami memiliki banyak hal yang ditulis dalam Go, dan seringkali ini penting untuk kinerja sistem. Itulah sebabnya hari ini saya menawarkan terjemahan sebuah artikel yang sangat saya sukai dan, saya yakin, akan sangat berguna bagi Anda. Penulis menunjukkan langkah demi langkah bagaimana ia mendekati masalah kinerja dan bagaimana mereka memecahkannya. Termasuk Anda akan berkenalan dengan alat kaya yang tersedia di Go untuk pekerjaan seperti itu. Selamat membaca!Beberapa minggu yang lalu, saya membaca artikel "
Kode yang Baik Melawan Kode Buruk di Go, " di mana penulis, langkah demi langkah, menunjukkan refactoring aplikasi nyata yang memecahkan masalah bisnis nyata. Ini berfokus pada mengubah "kode buruk" menjadi "kode yang baik": lebih idiomatik, lebih dapat dimengerti, sepenuhnya memanfaatkan spesifikasi Go. Namun penulis juga menyatakan pentingnya kinerja aplikasi yang dimaksud. Keingintahuan melompat ke saya: mari kita coba mempercepatnya!
Program, secara kasar, membaca file input, mem-parsingnya baris demi baris dan mengisi objek dalam memori.
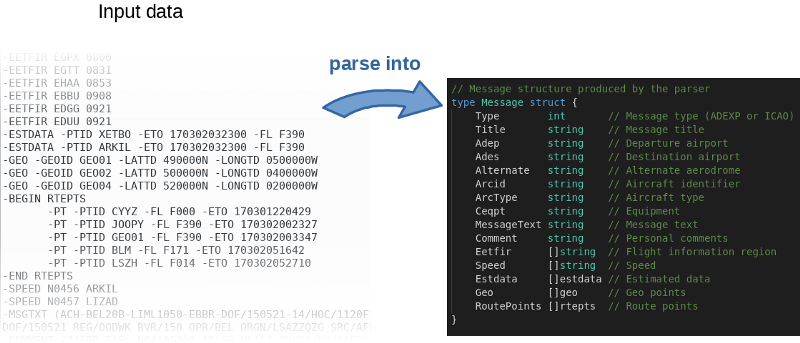
Penulis tidak hanya memposting
kode sumber di GitHub , tetapi juga menulis patokan. Ini ide yang bagus. Bahkan, penulis mengundang semua orang untuk bermain-main dengan kode dan mencoba mempercepatnya. Untuk mereproduksi hasil penulis, gunakan perintah berikut:
$ go test -bench=.
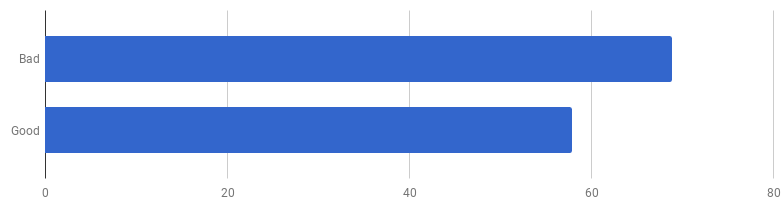 μs per panggilan (kurang - lebih baik)
μs per panggilan (kurang - lebih baik)Ternyata di komputer saya "kode yang baik" adalah 16% lebih cepat. Bisakah kita mempercepatnya?
Dalam pengalaman saya, ada korelasi antara kualitas kode dan kinerja. Jika Anda berhasil refactored kode, membuatnya lebih bersih dan kurang terhubung, Anda kemungkinan besar membuatnya lebih cepat karena menjadi kurang berantakan (dan tidak ada instruksi yang tidak perlu yang sebelumnya dieksekusi dengan sia-sia). Mungkin selama refactoring Anda memperhatikan beberapa peluang pengoptimalan, atau sekarang Anda hanya memiliki kesempatan untuk membuatnya. Tetapi di sisi lain, jika Anda ingin membuat kode lebih produktif, Anda mungkin harus melepaskan diri dari kesederhanaan dan menambahkan berbagai peretasan. Anda benar-benar menghemat milidetik, tetapi kualitas kodenya akan menderita: akan semakin sulit untuk membacanya dan membicarakannya, itu akan menjadi lebih rapuh dan fleksibel.
 Kami mendaki gunung Kesederhanaan, dan kemudian turun dari sana
Kami mendaki gunung Kesederhanaan, dan kemudian turun dari sanaIni adalah kompromi: seberapa jauh Anda bersedia melangkah?
Untuk memprioritaskan pekerjaan akselerasi dengan benar, strategi optimal adalah menemukan kemacetan dan fokus padanya. Untuk melakukan ini, gunakan alat profil.
pprof dan
jejak adalah teman Anda:
$ go test -bench=. -cpuprofile cpu.prof $ go tool pprof -svg cpu.prof > cpu.svg
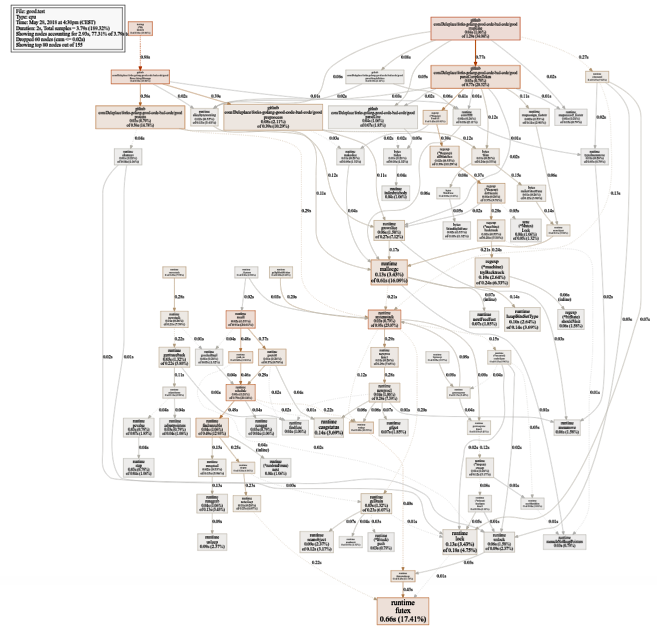 Grafik penggunaan CPU yang cukup besar (klik untuk SVG)
Grafik penggunaan CPU yang cukup besar (klik untuk SVG) $ go test -bench=. -trace trace.out $ go tool trace trace.out
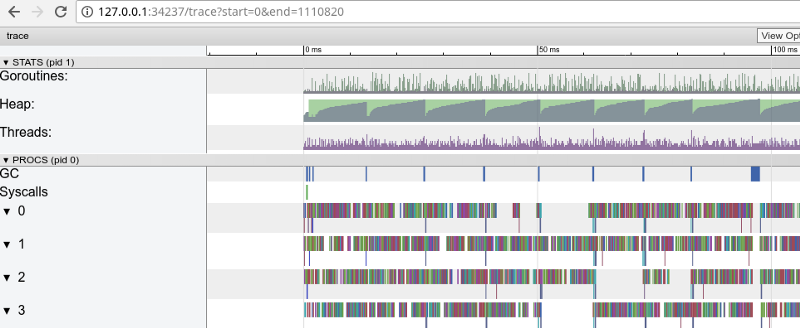 Pelacakan pelangi: banyak tugas kecil (klik untuk membuka, hanya berfungsi di Google Chrome)
Pelacakan pelangi: banyak tugas kecil (klik untuk membuka, hanya berfungsi di Google Chrome)Tracing mengonfirmasi bahwa semua inti prosesor sibuk (garis di bawah 0, 1, dll.), Dan, pada pandangan pertama, ini bagus. Tapi dia juga menunjukkan ribuan "perhitungan" warna kecil dan beberapa area kosong di mana core tidak digunakan. Mari memperbesar:
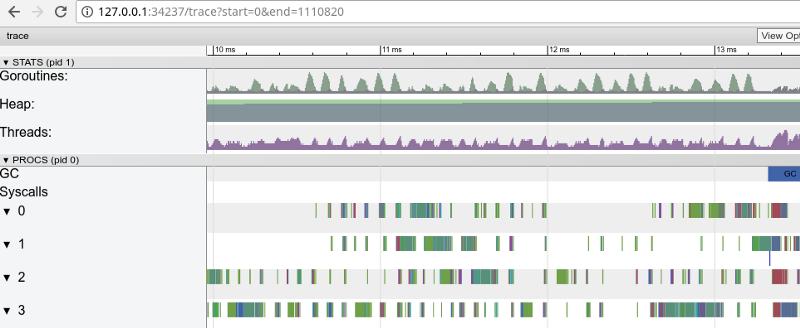 “Jendela” dalam 3 ms (klik untuk membuka, hanya berfungsi di Google Chrome)
“Jendela” dalam 3 ms (klik untuk membuka, hanya berfungsi di Google Chrome)Setiap inti menganggur selama beberapa waktu, dan juga "melompat" di antara tugas mikro setiap saat. Tampaknya rincian tugas-tugas ini tidak terlalu optimal, yang mengarah ke sejumlah besar
saklar konteks dan persaingan karena sinkronisasi.
Mari kita lihat apa yang dikatakan oleh
detektor penerbangan . Apakah ada masalah dalam akses sinkron ke data (jika ada, maka kita memiliki masalah yang jauh lebih besar daripada kinerja)?
$ go test -race PASS
Hebat! Semuanya benar. Tidak ditemukan penerbangan. Fungsi tes dan fungsi benchmark adalah fungsi yang berbeda (
lihat dokumentasi ), tetapi di sini mereka memanggil fungsi
ParseAdexpMessage yang sama, jadi apa yang kami periksa untuk penerbangan data dengan tes tidak apa-apa.
Model kompetitif dalam versi "baik" terdiri dari pemrosesan setiap baris dari file input dalam goroutine terpisah (untuk menggunakan semua core). Intuisi penulis di sini bekerja dengan baik, karena goroutine memiliki reputasi untuk fitur yang mudah dan murah. Tetapi berapa banyak yang kita menangkan melalui eksekusi paralel? Mari kita bandingkan dengan kode yang sama tetapi tidak menggunakan goroutine (hapus saja kata yang datang sebelum pemanggilan fungsi):

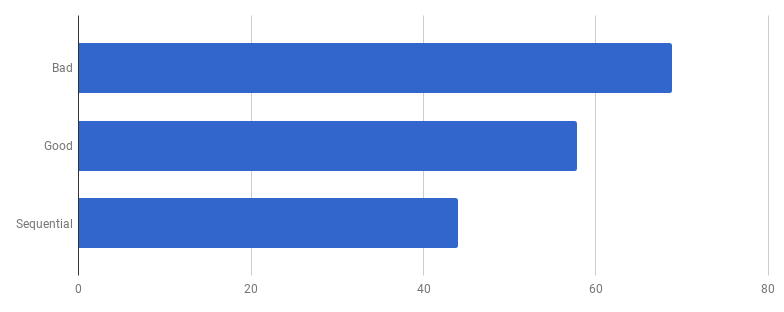
Ups, sepertinya kode menjadi lebih cepat tanpa menggunakan konkurensi. Ini berarti bahwa overhead (non-nol) untuk meluncurkan goroutine melebihi waktu yang kami menangkan dengan menggunakan beberapa core secara bersamaan. Langkah alami selanjutnya adalah menghapus overhead (bukan nol) untuk menggunakan saluran untuk mengirim hasilnya. Mari kita ganti dengan irisan biasa:
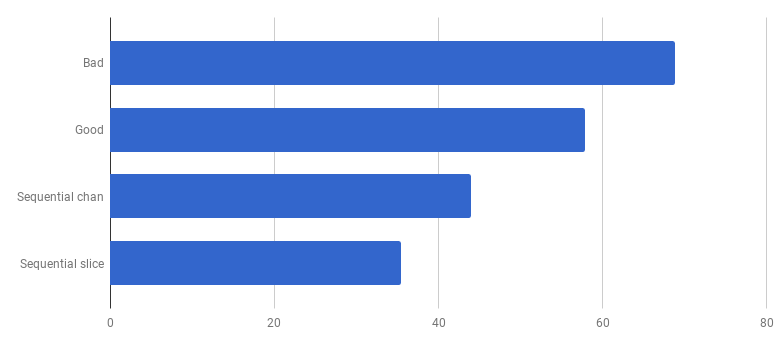 μs per panggilan (lebih sedikit lebih baik)
μs per panggilan (lebih sedikit lebih baik)Kami mendapat akselerasi sekitar 40% dibandingkan dengan versi "baik", menyederhanakan kode dan menghapus kompetisi (berbeda).
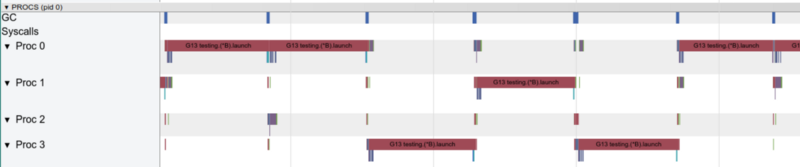 Dengan satu goroutine, hanya satu inti yang bekerja pada satu waktu
Dengan satu goroutine, hanya satu inti yang bekerja pada satu waktuSekarang mari kita lihat fungsi-fungsi panas dalam grafik pprof:
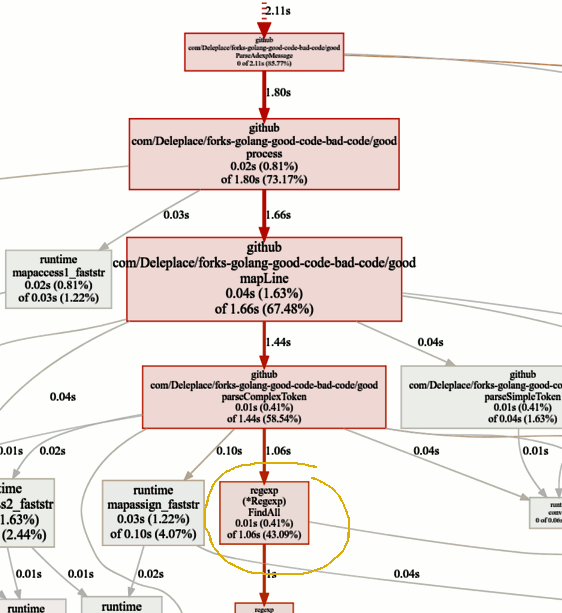 Mencari kemacetan
Mencari kemacetanPatokan versi saat ini (operasi berurutan, irisan) menghabiskan 86% dari waktu penguraian pesan, dan ini normal. Tetapi kami akan segera menyadari bahwa 43% dari waktu dihabiskan untuk menggunakan ekspresi reguler dan fungsi
(* Regexp) .FindAll .
Terlepas dari kenyataan bahwa ekspresi reguler adalah cara yang mudah dan fleksibel untuk mendapatkan data dari teks biasa, mereka memiliki kelemahan, termasuk penggunaan sejumlah besar sumber daya dan prosesor, dan memori. Mereka adalah alat yang ampuh, tetapi seringkali penggunaannya tidak perlu.
Dalam program kami, templat
patternSubfield = "-.[^-]*"
Ini terutama dimaksudkan untuk menyorot perintah yang dimulai dengan tanda hubung (-), dan mungkin ada beberapa baris. Ini, setelah menarik sedikit kode, dapat dilakukan menggunakan
bytes.Split . Mari kita adaptasikan kode (
komit ,
komit ) untuk mengubah ekspresi reguler menjadi Berpisah:
 μs per panggilan (lebih sedikit lebih baik)
μs per panggilan (lebih sedikit lebih baik)Wow! 40% kode lebih produktif! Grafik konsumsi CPU sekarang terlihat seperti ini:
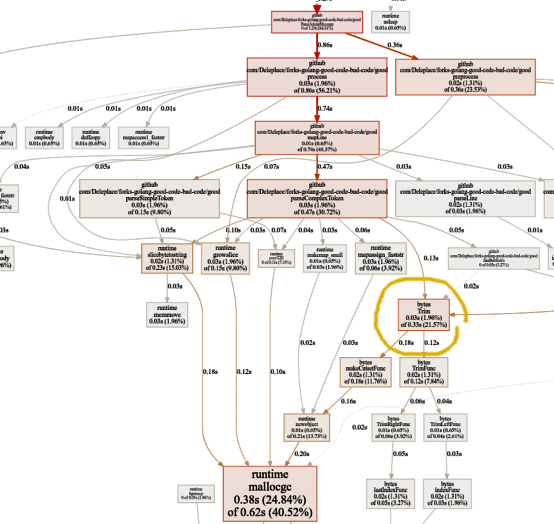
Tidak ada lagi waktu yang terbuang untuk ekspresi reguler. Sebagian besar darinya (40%) digunakan untuk alokasi memori dari lima fungsi yang berbeda. Menariknya, sekarang 21% dari waktu dihabiskan untuk
byte. Fungsi utama:
 Fitur ini menggelitik saya. Apa yang bisa kita lakukan di sini?
Fitur ini menggelitik saya. Apa yang bisa kita lakukan di sini?
bytes.Trim mengharapkan string dengan karakter yang "terpotong" sebagai argumen, tetapi karena string ini kita meneruskan string dengan hanya satu karakter - spasi. Ini hanya sebuah contoh bagaimana Anda bisa mendapatkan akselerasi karena kerumitan: mari kita buat fungsi trim kami alih-alih yang standar. Fungsi
trim khusus kami akan bekerja dengan satu byte, bukan seluruh baris:

 μs per panggilan (lebih sedikit lebih baik)
μs per panggilan (lebih sedikit lebih baik)Hore, potongan 20% lagi! Versi saat ini empat kali lebih cepat dari versi "buruk" asli dan pada saat yang sama hanya menggunakan satu inti. Tidak buruk!
Sebelumnya, kami meninggalkan daya saing di tingkat pemrosesan garis, tetapi saya berpendapat bahwa akselerasi dapat dicapai dengan menggunakan daya saing di tingkat yang lebih tinggi. Misalnya, memproses 6.000 file (6.000 pesan) lebih cepat di komputer saya jika setiap file diproses di goroutine sendiri:
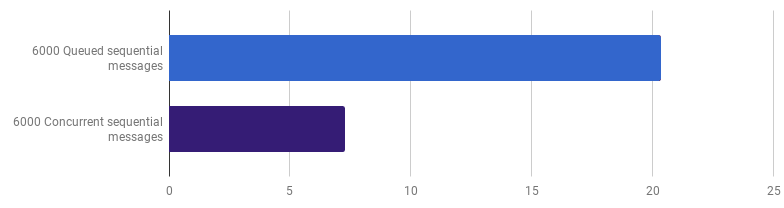 μs per panggilan (lebih sedikit lebih baik; ungu adalah solusi kompetitif)
μs per panggilan (lebih sedikit lebih baik; ungu adalah solusi kompetitif)Keuntungannya adalah 66% (yaitu akselerasi tiga kali). Ini bagus, tetapi tidak terlalu, mengingat bahwa semua 12 core prosesor yang saya miliki digunakan. Ini mungkin berarti bahwa kode baru yang dioptimalkan yang memproses seluruh file masih merupakan "tugas kecil", yang mana biaya overhead untuk membuat goroutine dan biaya sinkronisasi tidak signifikan. Cukup menarik, meningkatkan jumlah pesan dari 6.000 menjadi 120.000 tidak memiliki efek pada versi single-threaded dan mengurangi kinerja pada versi "satu goroutine per pesan". Ini karena, terlepas dari kenyataan bahwa membuat sejumlah besar goroutine adalah mungkin dan kadang-kadang berguna, ia membawa overhead sendiri di area runtime-
sheduler .
Kami dapat mengurangi waktu eksekusi lebih lanjut (bukan 12 kali, tetapi masih) dengan menciptakan hanya beberapa pekerja. Misalnya, 12 goroutine berumur panjang, masing-masing akan memproses bagian dari pesan:
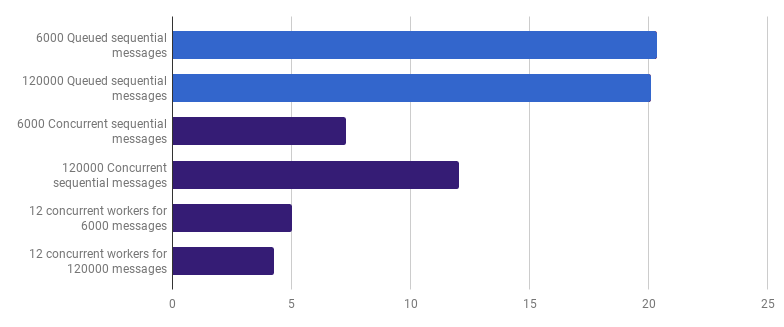 μs per panggilan (lebih sedikit lebih baik; ungu adalah solusi kompetitif)
μs per panggilan (lebih sedikit lebih baik; ungu adalah solusi kompetitif)Opsi ini mengurangi waktu eksekusi hingga 79% dibandingkan dengan versi single-threaded. Perhatikan bahwa strategi ini hanya masuk akal jika Anda memiliki banyak file untuk diproses.
Penggunaan optimal semua inti prosesor adalah dengan menggunakan beberapa goroutine, yang masing-masing memproses sejumlah besar data tanpa interaksi atau sinkronisasi sebelum pekerjaan diselesaikan.
Biasanya mereka mengambil sebanyak proses (goroutine) sebagai inti dari prosesor, tetapi ini tidak selalu merupakan pilihan terbaik: semuanya tergantung pada tugas tertentu. Misalnya, jika Anda membaca sesuatu dari sistem file atau membuat banyak panggilan jaringan, maka untuk mendapatkan lebih banyak kinerja, Anda harus menggunakan lebih banyak goroutine daripada inti Anda.
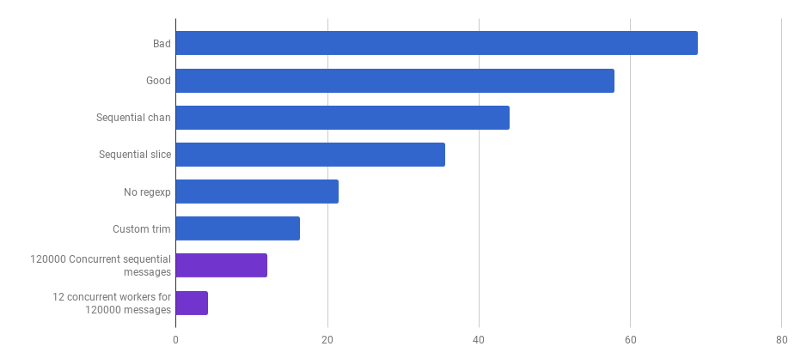 μs per panggilan (lebih sedikit lebih baik; ungu adalah solusi kompetitif)
μs per panggilan (lebih sedikit lebih baik; ungu adalah solusi kompetitif)Kami sampai pada titik di mana kinerja penguraian sulit ditingkatkan dengan beberapa perubahan yang dilokalkan. Runtime didominasi oleh waktu untuk alokasi memori dan pengumpulan sampah. Ini terdengar logis karena fungsi manajemen memori agak lambat. Optimalisasi lebih lanjut dari proses yang terkait dengan alokasi tetap sebagai pekerjaan rumah bagi pembaca.
Menggunakan algoritme lain juga dapat menghasilkan peningkatan kinerja yang besar.
Di sini saya terinspirasi oleh kuliah oleh Lexical Scanning in Go dari Rob Pike,
untuk membuat lexer khusus (
sumber ) dan parser khusus (
sumber ). Kode ini belum siap (saya tidak memproses banyak kasus sudut), kurang jelas dari algoritma asli, dan kadang-kadang sulit untuk menulis penanganan kesalahan yang benar. Tetapi ini kecil dan 30% lebih cepat dari versi yang paling optimal.
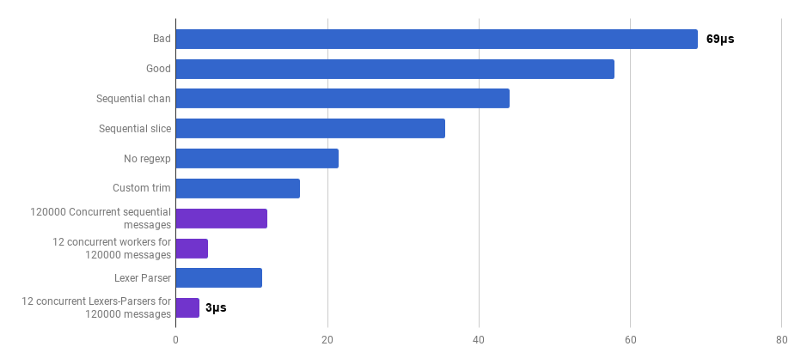 μs per panggilan (lebih sedikit lebih baik; ungu adalah solusi kompetitif)
μs per panggilan (lebih sedikit lebih baik; ungu adalah solusi kompetitif)Ya Akibatnya, kami mendapat akselerasi 23 kali dibandingkan dengan kode sumber.
Itu saja untuk hari ini. Saya harap Anda menikmati petualangan ini. Berikut beberapa catatan dan kesimpulan:
- Produktivitas dapat ditingkatkan pada berbagai tingkat abstraksi, menggunakan teknik yang berbeda, dan keuntungannya sering meningkat.
- Tuning harus dimulai dengan abstraksi tingkat tinggi: struktur data, algoritma, decoupling modul yang benar. Ambil abstraksi tingkat rendah nanti: I / O, batching, daya saing, menggunakan perpustakaan standar, bekerja dengan memori, mengalokasikan memori.
- Analisis Big O sangat penting, tetapi biasanya bukan alat yang paling cocok untuk mempercepat program.
- Menulis tolok ukur adalah kerja keras. Gunakan profiling dan tolok ukur untuk menemukan kemacetan dan mendapatkan pemahaman yang lebih luas tentang apa yang terjadi dalam program. Ingatlah bahwa hasil tolok ukur tidak sama dengan yang akan dialami pengguna Anda dalam pekerjaan nyata.
- Untungnya, satu set alat ( Bench , pprof , trace , Race Detector , Cover ) membuat penelitian tentang kinerja kode terjangkau dan menarik.
- Menulis tes yang baik dan relevan bukanlah tugas yang sepele. Tetapi mereka sangat penting untuk tidak pergi ke alam liar. Anda dapat melakukan refactor, memastikan kode tetap benar.
- Berhentilah dan tanyakan pada diri sendiri seberapa cepat "cukup cepat." Jangan buang waktu Anda mengoptimalkan beberapa naskah satu kali. Jangan lupa bahwa pengoptimalan tidak gratis: waktu insinyur, kompleksitas, bug, dan hutang teknis.
- Berpikir dua kali sebelum menyulitkan kode.
- Algoritma dengan kompleksitas Ω (n²) dan di atas biasanya terlalu mahal.
- Algoritma dengan kompleksitas O (n) atau O (n log n) dan di bawah ini biasanya ok.
- Berbagai faktor tersembunyi tidak dapat diabaikan. Sebagai contoh, semua perbaikan dalam artikel dibuat dengan mengurangi faktor-faktor ini, dan bukan dengan mengubah kelas kompleksitas algoritma.
- I / O sering menjadi hambatan: kueri jaringan, kueri basis data, sistem file.
- Ekspresi reguler seringkali terlalu mahal dan tidak perlu.
- Alokasi memori lebih mahal daripada perhitungan.
- Objek yang dialokasikan pada stack lebih murah daripada objek yang dialokasikan pada heap.
- Irisan bermanfaat sebagai alternatif dari pergerakan memori yang mahal.
- String efektif ketika hanya-baca (termasuk reslicing). Dalam semua kasus lain, [] byte lebih efektif.
- Sangat penting bahwa data yang Anda proses dekat (cache prosesor).
- Daya saing dan paralelisme sangat bermanfaat, tetapi sulit untuk dipersiapkan.
- Saat Anda menggali dalam dan bawah, ingatlah "lantai kaca" yang tidak ingin Anda buka. Jika tangan Anda gatal untuk mencoba instruksi assembler, instruksi SIMD, Anda mungkin perlu menggunakan Go only untuk prototyping, dan kemudian beralih ke bahasa tingkat yang lebih rendah untuk mendapatkan kontrol penuh dari perangkat keras dan setiap nanodetik!