
Musim semi ini, tim Reydiks menyiapkan dan merilis versi pertama dari perangkat lunak untuk membuat sistem penyimpanan blok terdistribusi yang berjalan pada platform server Elbrus-4.4 berdasarkan mikroprosesor Elbrus-4C.
Kegunaan simbiosis semacam itu dapat dilihat dengan mata telanjang - perakitan sistem penyimpanan berdasarkan besi domestik dan sistem operasi domestik menjadi produk yang menarik dari pasar domestik, khususnya bagi pelanggan dengan fokus pada substitusi impor.
Namun, potensi sistem operasi yang dikembangkan tidak terbatas pada platform server Rusia. Saat ini, kompatibilitas dengan server x86-64 standar, yang didistribusikan secara luas di pasar, sedang diuji dan diuji. Selain itu, produk "selesai" dengan fungsi yang diinginkan, yang akan memungkinkan penerapannya di luar pasar Rusia.
Di bawah ini kami akan menyajikan diskusi kecil tentang bagaimana solusi perangkat lunak (disebut RAIDIX RAIN) diatur, yang memungkinkan menggabungkan media server lokal menjadi satu cluster penyimpanan toleran-kesalahan dengan manajemen terpusat dan kemampuan penskalaan horizontal dan vertikal.
Fitur Penyimpanan Terdistribusi
Sistem penyimpanan tradisional, dibuat dalam bentuk kompleks perangkat keras dan lunak tunggal, memiliki masalah umum terkait penskalaan: kinerja sistem bergantung pada pengontrol, jumlah mereka terbatas, ekspansi kapasitas dengan menambahkan rak ekspansi dengan operator tidak meningkatkan produktivitas.
Dengan pendekatan ini, kinerja keseluruhan sistem penyimpanan akan turun, karena dengan peningkatan kapasitas, jumlah pengontrol sebelumnya perlu memproses lebih banyak operasi akses ke volume data yang meningkat.
RAIDIX RAIN mendukung penskalaan blok horizontal, berbeda dengan solusi tradisional, meningkatkan node (blok server) dari sistem mengarah pada peningkatan linier dalam kapasitas tidak hanya, tetapi juga kinerja sistem. Hal ini dimungkinkan karena setiap simpul RAIDIX RAIN tidak hanya mencakup media, tetapi juga sumber daya komputasi untuk I / O dan pemrosesan data.
Skenario aplikasi
RAIDIX RAIN melibatkan penerapan semua skenario aplikasi utama untuk penyimpanan blok terdistribusi: infrastruktur penyimpanan cloud, basis data yang sangat banyak, dan penyimpanan analisis Big Data. RAIDIX RAIN juga dapat bersaing dengan sistem penyimpanan tradisional dengan volume data yang cukup tinggi dan kemampuan keuangan yang sesuai dari klien.
Awan publik dan pribadi
Solusi ini memberikan skalabilitas fleksibel yang diperlukan untuk menggunakan infrastruktur cloud: peningkatan kinerja, throughput, dan kapasitas penyimpanan dengan setiap node ditambahkan ke sistem.
Basis data
Cluster RAIDIX RAIN dalam konfigurasi all-flash adalah solusi yang efisien untuk melayani basis data yang sangat dimuat. Solusi ini akan menjadi alternatif yang terjangkau untuk produk Oracle Exadata untuk Oracle RAC.
Analisis Data Besar
Bersama dengan perangkat lunak tambahan, dimungkinkan untuk menggunakan solusi untuk melakukan analisis data besar. RAIDIX RAIN memberikan tingkat kinerja dan kemudahan perawatan yang jauh lebih tinggi dibandingkan dengan cluster HDFS.
Arsitektur Solusi
RAIDIX RAIN mendukung 2 opsi penempatan: berdedikasi (eksternal atau konvergen) dan hyper-konvergensi (HCI, infrastruktur hyper-konvergen).
Opsi Penempatan Khusus
Dalam versi yang dipilih, cluster RAIDIX RAIN adalah penyimpanan perangkat lunak klasik. Solusinya dikerahkan pada jumlah node server khusus yang diperlukan (setidaknya 3, jumlahnya praktis tak terbatas dari atas), sumber daya yang sepenuhnya digunakan untuk tugas penyimpanan.
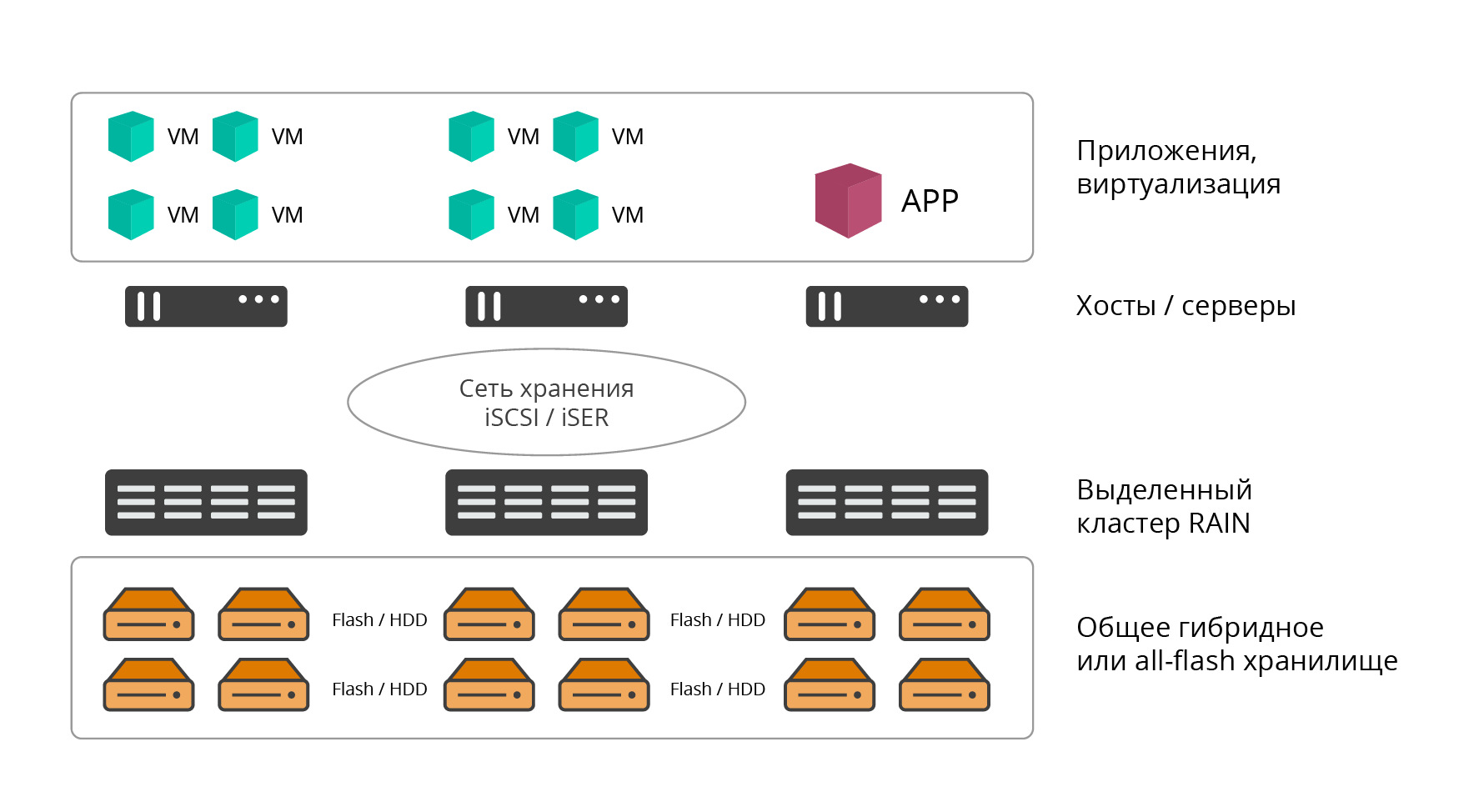 Fig. 1. Opsi penyebaran khusus
Fig. 1. Opsi penyebaran khususPerangkat lunak RAIDIX RAIN diinstal langsung pada bare metal. Aplikasi, layanan, sumber daya komputasi yang menggunakan RAIN untuk menyimpan informasi di-host pada host eksternal dan terhubung dengannya melalui jaringan penyimpanan (arsitektur pusat data klasik).
Opsi penerapan hyperconverged
Opsi hyperconvergent melibatkan penempatan daya komputasi bersama (hypervisor dan VM produksi) dan sumber daya penyimpanan (penyimpanan perangkat lunak) dari pusat data pada satu set node, terutama ini berlaku untuk infrastruktur virtual. Dengan pendekatan ini, perangkat lunak RAIN diinstal pada setiap host (node) infrastruktur (HCI) dalam bentuk mesin virtual.
 Fig. 2. Opsi penyebaran Hyperconverged
Fig. 2. Opsi penyebaran HyperconvergedInteraksi node cluster RAIN satu sama lain dan dengan pengguna akhir sumber daya penyimpanan (server, aplikasi) dilakukan melalui iSCSI (IP, IPoIB), iSER (RoCE, RDMA) atau protokol NVMeOF.
Opsi penerapan hyperconverged menawarkan manfaat berikut:
- Konsolidasi sumber daya komputasi dan penyimpanan (tidak perlu menerapkan dan memelihara penyimpanan eksternal khusus).
- Penskalaan blok horisontal gabungan sumber daya komputasi dan sumber daya penyimpanan.
- Kemudahan implementasi dan pemeliharaan.
- Manajemen terpusat.
- Menghemat kapasitas rack-mount dan konsumsi daya.
Dalam hal media yang digunakan, RAIDIX RAIN mendukung 3 konfigurasi:
- All-flash - node cluster hanya disediakan dengan media flash (NVMe, SSD);
- HDD - node cluster hanya disediakan dengan HDD-carrier;
- Hibrida - dua tingkat penyimpanan independen pada HDD dan SSD.
Ketahanan Produktif
Nilai inti dari RAIDIX RAIN adalah keseimbangan kinerja, toleransi kesalahan, dan penggunaan kapasitas penyimpanan yang efisien.
Sebagai bagian dari infrastruktur TI klien, RAIDIX RAIN juga menarik karena kami memiliki akses blok "jujur" pada output, yang membedakan solusi dari sebagian besar analog pasar.
Saat ini, sebagian besar produk kompetitif menunjukkan kinerja tinggi, hanya ketika menggunakan mirroring. Pada saat yang sama, kapasitas penyimpanan yang berguna berkurang sebanyak 2 kali atau lebih: replikasi data tunggal (mirroring) - redundansi 50%, replikasi data ganda (mirroring ganda) - redundansi 66,6%.
Penggunaan teknologi optimisasi penyimpanan seperti EC (Erasure Coding - noiseless coding), deduplikasi dan kompresi yang diterapkan dalam sistem penyimpanan terdistribusi menyebabkan penurunan kinerja penyimpanan yang signifikan, yang tidak dapat diterima untuk aplikasi yang sensitif terhadap penundaan.
Oleh karena itu, dalam praktiknya, solusi semacam itu biasanya dipaksa untuk beroperasi tanpa menggunakan teknologi ini, atau untuk memasukkannya hanya untuk data "dingin".
Persyaratan kegagalan
Awalnya, RAIDIX RAIN dirancang dengan serangkaian persyaratan awal yang jelas untuk ketahanan dan ketersediaan sistem:
- Cluster harus selamat dari kegagalan setidaknya dua node, dengan jumlah node benar-benar lebih besar dari 4. Untuk tiga dan empat, kegagalan satu node dijamin.
- Sebuah node harus selamat dari kegagalan setidaknya dua disk di setiap node jika setidaknya ada 5 disk dalam sebuah node.
- Tingkat redundansi drive pada kluster tipikal (dari 16 node) tidak boleh lebih dari 30%
- Tingkat ketersediaan data harus minimal 99,999%
Ini telah sangat mempengaruhi arsitektur produk yang ada.
Menghapus Kemampuan Pengkodean dalam Penyimpanan Terdistribusi
Pendekatan toleransi kesalahan utama RAIDIX RAIN adalah penggunaan teknologi Erasure Coding yang unik. Perusahaan EC yang dikenal dengan produk andalannya juga digunakan dalam penyimpanan terdistribusi, yang memungkinkan kinerjanya sebanding dengan konfigurasi cermin. Ini berlaku untuk muatan acak dan berurutan. Pada saat yang sama, tingkat toleransi kesalahan yang telah ditentukan dipastikan dan kapasitas yang berguna meningkat secara signifikan, dan biaya overhead tidak lebih dari 30% dari kapasitas penyimpanan mentah.
Disebutkan terpisah diperlukan EC RAIDIX kinerja tinggi pada operasi berurutan, khususnya ketika menggunakan disk SATA berkapasitas besar.
Secara umum, RAIDIX RAIN menawarkan 3 opsi pengkodean koreksi-kesalahan:
- selama 3 node, penggunaan RAID 1 optimal;
- untuk 4 node, penggunaan optimal RAID 5;
- untuk subkluster penyimpanan 5 hingga 20 node, pendekatan optimal adalah dengan menggunakan RAID jaringan 6.
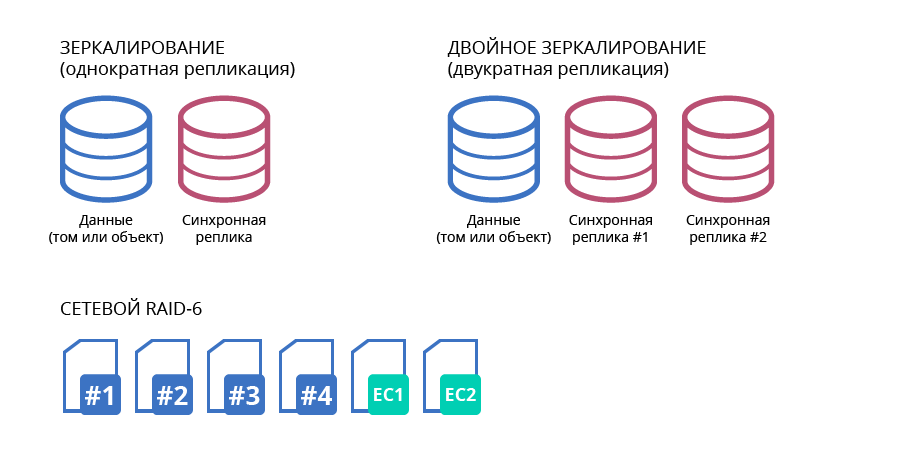 Fig. 3. Opsi untuk pengkodean koreksi kesalahan
Fig. 3. Opsi untuk pengkodean koreksi kesalahanSemua opsi mengasumsikan distribusi data yang seragam di semua node cluster dengan penambahan redundansi dalam bentuk checksum (atau kode koreksi). Ini memungkinkan kita untuk menggambar paralel dengan kode Reed-Solomon yang digunakan dalam array RAID standar (RAID-6) dan memungkinkan failover hingga 2 operator. Jaringan RAID-6 bekerja mirip dengan yang berbasis disk, namun, itu mendistribusikan data di antara node cluster dan memungkinkan failover dari 2 node.
Dalam RAID 6, ketika 1-2 operator gagal dalam satu node, mereka dipulihkan secara lokal tanpa menggunakan checksum terdistribusi, meminimalkan jumlah data yang dipulihkan, beban jaringan dan degradasi sistem secara keseluruhan.
Domain kegagalan
HUJAN mendukung konsep domain kesalahan atau domain ketersediaan. Ini memungkinkan Anda untuk mengetahui kegagalan tidak hanya node individual, tetapi juga seluruh server rak atau keranjang, yang node secara logis dikelompokkan ke dalam domain kegagalan. Kemungkinan ini dicapai dengan mendistribusikan data untuk memastikan toleransi kesalahan mereka tidak pada tingkat node individu, tetapi pada tingkat domain, yang akan memungkinkan untuk bertahan dari kegagalan semua node yang dikelompokkan di dalamnya (misalnya, seluruh rak server). Dalam pendekatan ini, cluster dibagi menjadi subkelompok independen (subclust). Jumlah node dalam satu subkelompok tidak lebih dari 20, yang menyediakan persyaratan untuk toleransi kesalahan dan ketersediaan. Selain itu, jumlah subkelompok tidak terbatas.
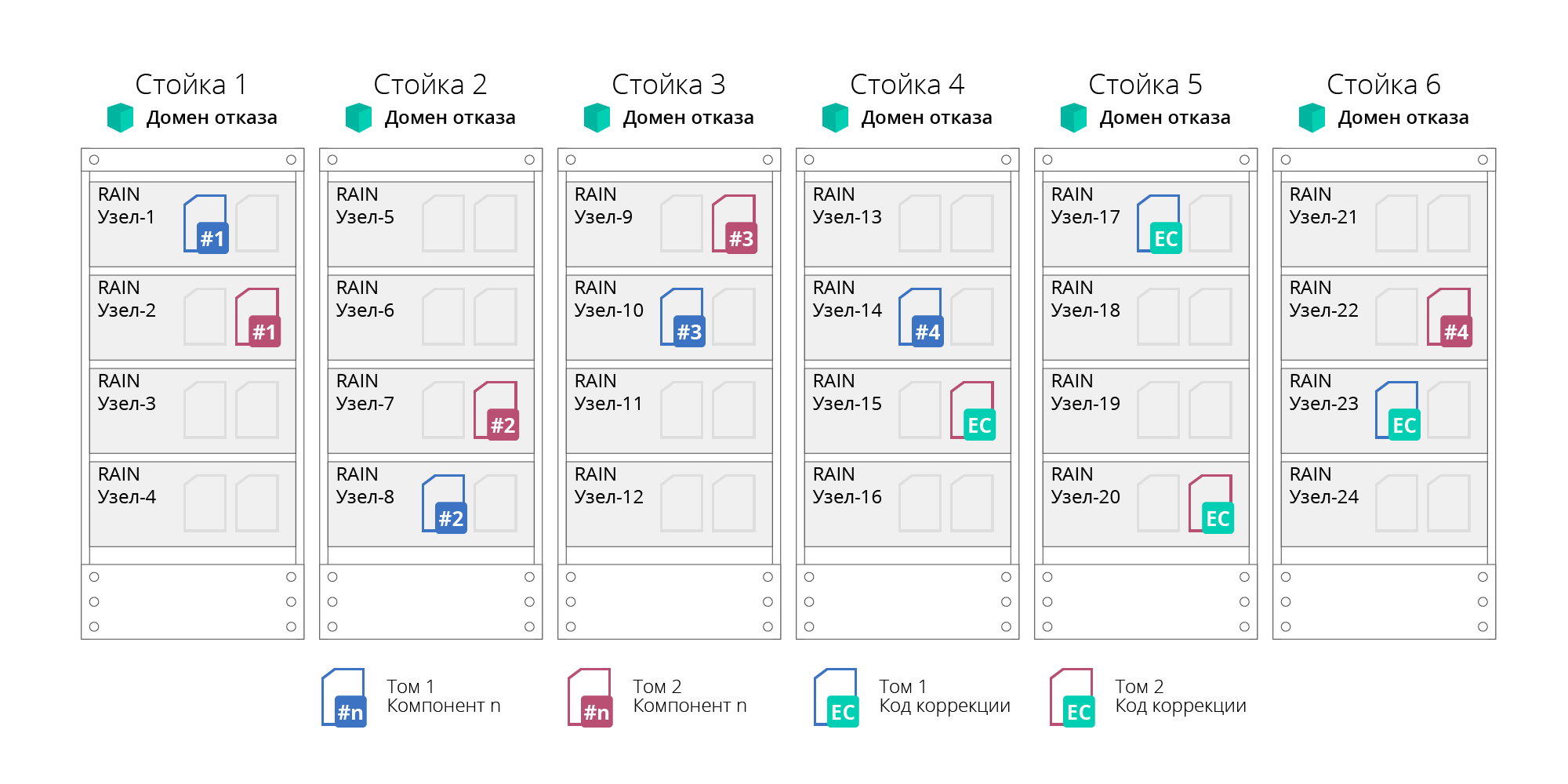 Fig. 4. Kegagalan Domain
Fig. 4. Kegagalan DomainKegagalan setiap kegagalan (disk, node atau jaringan) dilakukan secara otomatis, tanpa menghentikan sistem.
Selain itu, semua perangkat cluster RAIDIX RAIN dilindungi terhadap kegagalan daya dengan menghubungkan ke catu daya tak terputus (UPS). Perangkat yang terhubung ke UPS yang sama disebut kelompok kegagalan daya.
Fitur dan Fungsi
Pertimbangkan fitur fungsional utama RAIDIX RAIN.
Tabel 1. Fitur Basic RAIDIX RAIN| Karakteristik operasional | Nilai |
|---|
| Jenis Node yang Didukung | Platform server domestik berdasarkan pada prosesor Elbrus-4C
Server standar x86-64 (perspektif) |
| Jenis Media yang Didukung | SATA dan SAS HDD, SATA dan SAS SSD, NVMe |
| Kapasitas penyimpanan maksimum | 16 EB |
| Ukuran cluster maksimum | 1.024 knot |
| Fungsionalitas dasar | Ekspansi Volume Panas
Hot menambahkan node ke cluster
Penyeimbangan ulang kluster
Gagal tanpa downtime |
| Teknologi Ketahanan | Kegagalan node, media, jaringan.
Erasure Coding, didistribusikan di seluruh node cluster: network RAID 0/1/5/6.
Kode koreksi di tingkat pembawa host lokal (RAID 6 lokal)
Domain kegagalan |
Sebagai fitur fungsional penting RAIDIX RAIN, perlu dicatat bahwa layanan seperti
inisialisasi, rekonstruksi dan penulisan ulang (penskalaan) masuk di latar belakang dan mereka dapat diatur ke parameter prioritas .
Pengaturan prioritas memungkinkan pengguna untuk secara mandiri menyesuaikan beban dalam sistem, mempercepat atau memperlambat kerja layanan ini. Misalnya, prioritas 0 berarti bahwa layanan hanya berfungsi ketika tidak ada beban dari aplikasi klien.
Opsi penskalaan
Proses memperluas RAIDIX RAIN cluster adalah sesederhana dan seotomatis mungkin, sistem secara independen mendistribusikan kembali data dalam proses latar belakang dengan mempertimbangkan kapasitas node baru, beban menjadi seimbang dan seragam, kinerja keseluruhan dan kapasitas penyimpanan ditingkatkan secara proporsional. Proses penskalaan horisontal melewati "panas" tanpa downtime, tidak memerlukan penghentian aplikasi dan layanan.
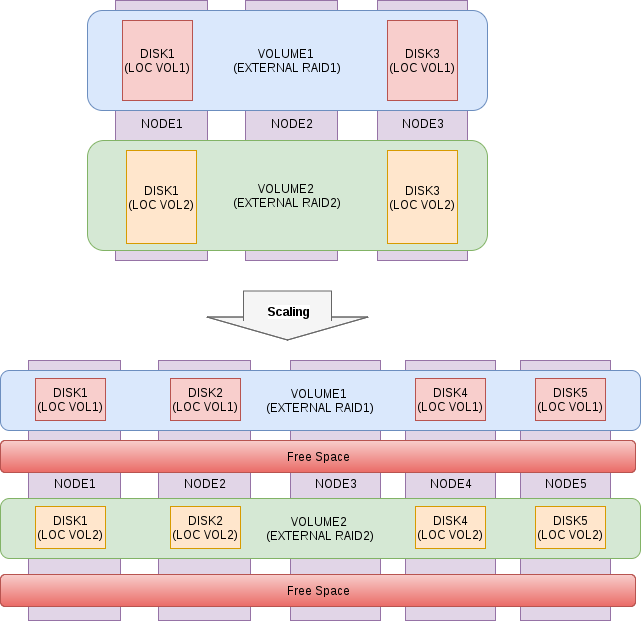 Fig. 5. Skema dari proses penskalaan
Fig. 5. Skema dari proses penskalaanFleksibilitas arsitektur
RAIDIX RAIN adalah produk perangkat lunak dan tidak terbatas pada platform perangkat keras tertentu - konsepnya menunjukkan kemampuan untuk menginstal pada perangkat keras server yang kompatibel.
Berdasarkan spesifik infrastruktur dan aplikasi mereka, setiap pelanggan memilih opsi penyebaran terbaik: berdedikasi atau hyperconverged.
Dukungan untuk berbagai jenis media memungkinkan Anda membangun berdasarkan anggaran dan tugas-tugas yang akan dibangun berdasarkan RAIDIX RAIN:
1. mendistribusikan semua penyimpanan flash dengan kinerja tinggi yang belum pernah terjadi sebelumnya dan dijamin latensi rendah;
2. sistem hybrid ekonomis yang memenuhi sebagian besar tipe beban dasar.
Indikator kinerja
Sebagai kesimpulan, kami akan menunjukkan beberapa angka yang diperoleh sebagai hasil pengujian RAIDIX RAIN pada konfigurasi cluster NVMe 6-node. Sekali lagi, kami mencatat bahwa pada perakitan seperti itu (dengan server x86-64) produk masih dalam penyelesaian, dan angka-angka ini belum final.
Lingkungan uji
- 6 knot pada 2 disk NVMe HGST SN100
- Kartu IB Mellanox MT27700 Family [ConnectX-4]
- Kernel Linux 4.11.6-1.el7.elrepo.x86_64
- MLNX_OFED_LINUX-4.3-1.0.1.0-rhel7.4-x86_64
- Raid lokal - raid 0
- Serangan eksternal - serangan 6
- Benchmark untuk pengujian FIO 3.1
UPD: beban dilakukan dalam blok 4K, berurutan - 1M, kedalaman antrian 32. Beban diluncurkan pada semua node cluster secara bersamaan dan tabel menunjukkan hasil total. Penundaan tidak melebihi 1 ms (99,9 persen).
Tabel 2. Hasil Tes| Jenis beban | Nilai |
|---|
| Baca acak 100% | 4.098.000 IOps |
| Tulis acak 100% | 517.000 IOps |
| Sequential read 100% | 33,8 GB / s |
| Penulisan berurutan 100% | 12 GB / s |
| Baca acak 70% / tulis acak 30% | 1.000.000 IOps / 530.000 IOps |
| Acak baca 50% / tulis acak 50% | 530.000 IOps / 530.000 IOps |
| Acak baca 30% / tulis acak 70% | 187.000 IOps / 438.000 IOps |