Hai Pada artikel ini saya akan berbicara tentang classifier Bayesian sebagai salah satu opsi untuk memfilter email spam. Mari kita telaah teorinya, lalu perbaiki dengan latihan, dan pada akhirnya saya akan memberikan sketsa kode saya dalam bahasa tercinta saya R. Saya akan mencoba untuk menjelaskan dengan selingan mungkin dengan ekspresi dan formulasi. Ayo mulai!

Tidak ada rumus di mana pun, yah, teori singkat
Bayesian classifier termasuk dalam kategori pembelajaran mesin. Intinya adalah ini: sistem yang dihadapkan dengan tugas untuk menentukan apakah surat berikutnya adalah spam telah dilatih terlebih dahulu oleh sejumlah huruf tertentu yang tahu persis di mana "spam" dan di mana "bukan spam." Sudah menjadi jelas bahwa ini mengajar dengan seorang guru, di mana kita memainkan peran seorang guru. Pengklasifikasi Bayesian menyajikan dokumen (dalam kasus kami, surat) dalam bentuk serangkaian kata yang konon tidak saling bergantung (dan kenaifan ini mengikuti dari sini).
Penting untuk menghitung nilai untuk setiap kelas (spam / non-spam) dan pilih kelas yang maksimum. Untuk melakukan ini, gunakan rumus berikut:
- kemunculan kata
ke dalam dokumen kelas
(dengan smoothing) *
- jumlah kata yang disertakan dalam dokumen kelas
M - jumlah kata dari set pelatihan
- jumlah kemunculan kata
ke dalam dokumen kelas
- parameter untuk menghaluskan
Ketika volume teks sangat besar, Anda harus bekerja dengan angka yang sangat kecil. Untuk menghindari ini, Anda dapat mengonversi rumus sesuai dengan properti logaritma **:
Pengganti dan dapatkan:
* Selama perhitungan Anda mungkin menemukan kata yang tidak pada tahap pelatihan sistem. Hal ini dapat menyebabkan penilaian sama dengan nol dan dokumen tidak dapat ditugaskan ke salah satu kategori (spam / non-spam). Apa pun yang Anda inginkan, Anda tidak mengajarkan semua kata yang mungkin pada sistem Anda. Untuk melakukan ini, perlu menerapkan smoothing, atau lebih tepatnya, membuat koreksi kecil untuk semua probabilitas kata-kata yang masuk ke dokumen. Parameter 0 <α≤1 dipilih (jika α = 1, maka ini adalah Laplace smoothing)
** Logaritma adalah fungsi yang meningkat secara monoton. Seperti dapat dilihat dari formula pertama - kami sedang mencari yang maksimal. Logaritma fungsi akan memuncak pada titik yang sama (absis) sebagai fungsi itu sendiri. Ini menyederhanakan perhitungan, karena hanya nilai numerik yang berubah.
Dari teori ke praktik
Biarkan sistem kami belajar dari surat-surat berikut, yang diketahui sebelumnya di mana "spam" dan di mana "bukan spam" (contoh pelatihan):
Spam- “Voucher dengan harga murah”
- "Promosi! Beli cokelat dan dapatkan telepon sebagai hadiah »
Bukan spam:- "Pertemuan akan diadakan besok"
- “Beli satu kilogram apel dan sebatang cokelat”
Penugasan: tentukan kategori mana yang dimiliki surat berikut:
- “Toko itu memiliki segunung apel. Beli tujuh kilogram dan sebatang cokelat ”
Solusi:Kami membuat meja. Kami menghapus semua "kata berhenti", menghitung probabilitas, mengambil parameter untuk memuluskan sebagai satu.
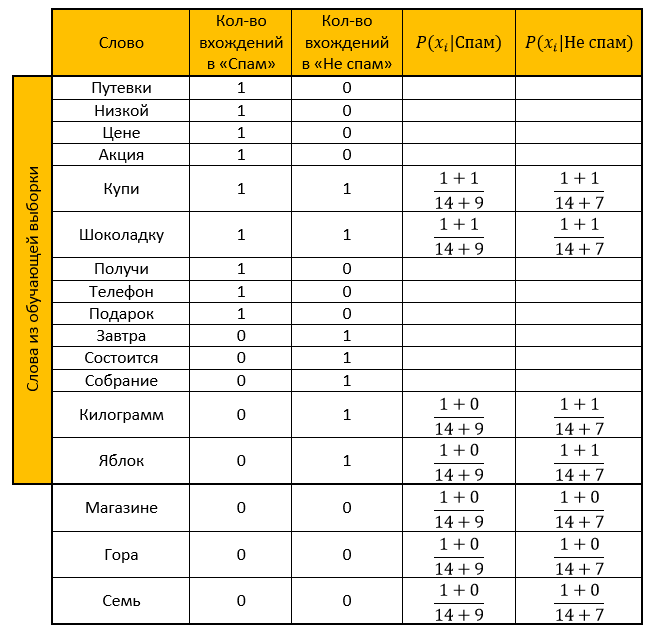
Peringkat untuk kategori Spam:
Peringkat untuk kategori “Bukan spam”:
Jawaban: Peringkat "Bukan spam" lebih dari peringkat "Spam". Jadi surat verifikasi itu bukan spam!
Kami menghitung hal yang sama dengan bantuan fungsi yang diubah oleh properti logaritma:
Peringkat untuk kategori Spam:
Peringkat untuk kategori “Bukan spam”:
Jawab: mirip dengan jawaban sebelumnya. Email verifikasi - tidak ada spam!
Memprogram implementasi bahasa R
Dia mengomentari hampir setiap tindakan, karena saya tahu seberapa sering saya tidak ingin memahami kode orang lain, jadi saya berharap bahwa membaca milik saya tidak akan menyulitkan Anda. (oh betapa aku berharap)
Dan di sini, sebenarnya, kode itu sendirilibrary("tm") # stopwords library("stringr") # # : spam <- c( ' ', '! ' ) # : not_spam <- c( ' ', ' ' ) # test_letter <- " . " #---------------- -------------------- # spam <- str_replace_all(spam, "[[:punct:]]", "") # spam <- tolower(spam) # spam_words <- unlist(strsplit(spam, " ")) # , stopwords spam_words <- spam_words[! spam_words %in% stopwords("ru")] # unique_words <- table(spam_words) # data frame main_table <- data.frame(u_words=unique_words) # names(main_table) <- c("","") #--------------- ------------------ not_spam <- str_replace_all(not_spam, "[[:punct:]]", "") not_spam <- tolower(not_spam) not_spam_words <- unlist(strsplit(not_spam, " ")) not_spam_words <- not_spam_words[! not_spam_words %in% stopwords("ru")] #--------------- ------------------ test_letter <- str_replace_all(test_letter, "[[:punct:]]", "") test_letter <- tolower(test_letter) test_letter <- unlist(strsplit(test_letter, " ")) test_letter <- test_letter[! test_letter %in% stopwords("ru")] #--------------------------------------------- # main_table$_ <- 0 for(i in 1:length(not_spam_words)){ # need_word <- TRUE for(j in 1:(nrow(main_table))){ # " " , +1 if(not_spam_words[i]==main_table[j,1]) { main_table$_[j] <- main_table$_[j]+1 need_word <- FALSE } } # , data frame if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=not_spam_words[i],=0,_=1)) } } #------------- # , - main_table$_ <- NA # , - main_table$__ <- NA #------------- # Xi Qk formula_1 <- function(N_ik,M,N_k) { (1+N_ik)/(M+N_k) } #------------- # quantity <- nrow(main_table) for(i in 1:length(test_letter)) { # , need_word <- TRUE for(j in 1:nrow(main_table)) { # if(test_letter[i]==main_table$[j]) { main_table$_[j] <- formula_1(main_table$[j],quantity,sum(main_table$)) main_table$__[j] <- formula_1(main_table$_[j],quantity,sum(main_table$_)) need_word <- FALSE } } # , data frame, / if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=test_letter[i],=0,_=0,_=NA,__=NA)) main_table$_[nrow(main_table)] <- formula_1(main_table$[nrow(main_table)],quantity,sum(main_table$)) main_table$__[nrow(main_table)] <- formula_1(main_table$_[nrow(main_table)],quantity,sum(main_table$_)) } } # "" probability_spam <- 1 # " " probability_not_spam <- 1 for(i in 1:nrow(main_table)) { if(!is.na(main_table$_[i])) { # 1.1 , - probability_spam <- probability_spam * main_table$_[i] } if(!is.na(main_table$__[i])) { # 1.2 , - probability_not_spam <- probability_not_spam * main_table$__[i] } } # 2.1 , - probability_spam <- (length(spam)/(length(spam)+length(not_spam)))*probability_spam # 2.2 , - probability_not_spam <- (length(not_spam)/(length(spam)+length(not_spam)))*probability_not_spam # - ifelse(probability_spam>probability_not_spam," - !"," - !")
Terima kasih banyak atas waktu Anda membaca artikel saya. Saya harap Anda mempelajari sesuatu yang baru untuk diri Anda sendiri, atau sekadar menjelaskan saat-saat yang tidak jelas bagi Anda. Semoga beruntung
Sumber:- Artikel yang sangat bagus tentang pengelompokan Bayes yang naif
- Pengetahuan yang diperoleh dari Wiki: di sini , di sini , dan di sini
- Kuliah tentang Penambangan Data Chubukova I.A.