Semakin banyak solusi yang bergerak menjauh dari pendekatan penyimpanan terpadu tradisional. Ini adalah penyimpanan khusus yang dirancang untuk tugas-tugas area bisnis tertentu. Sebelumnya, saya berbicara tentang sistem Infinidat InfiniBox F2230. Hari ini di pusat ulasan SolidFire saya.
"Siapa yang menyimpan penyimpanan kebencian" @ Dave Heats, pendiri NetAppPada akhir 2015, NetApp mengumumkan pembelian startup SolidFire, yang didirikan pada 2010. Ketertarikan pada sistem ini adalah karena pendekatan mereka yang berbeda dalam mengelola gudang data dan kinerja yang dapat diprediksi.
Solusi SolidFire melengkapi jajaran produk NetApp, yang mencakup All Flash FAS (AFF), EF, dan E Series. Ini juga memungkinkan satu setengah tahun kemudian untuk meluncurkan produk baru di pasar - NetApp HCI (Hyper Converged Infrastructure), yang menggunakan SolidFire sebagai subsistem penyimpanan.
“Kami sedang mengembangkan sistem penyimpanan baru yang dirancang untuk pusat data komputasi awan yang sangat besar. Pada dasarnya, idenya adalah bahwa banyak perusahaan mentransfer komputasi dari kantor mereka atau pusat data mereka sendiri ke pusat data komputasi awan besar ini, di mana mereka memiliki puluhan ribu pelanggan dengan semua informasi mereka di satu tempat. Oleh karena itu, kami menciptakan sistem penyimpanan baru yang dirancang untuk melayani pusat data besar ini. "
Dave Wright, CEO SolidFire, 2012
Baru-baru ini, ada semakin banyak solusi yang bergerak menjauh dari pendekatan tradisional penyimpanan terpadu yang dapat memecahkan masalah, ke penyimpanan khusus yang dirancang untuk memecahkan masalah area bisnis tertentu.
Belum lama ini,
saya sudah berbicara tentang sistem Infinidat InfiniBox F2230 , yang sangat cocok untuk tugas penyedia layanan. Peserta hari ini dalam ulasan SolidFire kami juga dapat dikaitkan dengan kelas perangkat ini. Pendiri SolidFire, Dave Wright dan timnya berasal dari RackSpace, di mana mereka mengembangkan sistem penyimpanan yang efisien yang akan memberikan kinerja linier dalam lingkungan dengan banyak pengguna, sementara itu sederhana, mudah scalable dan memiliki kemampuan otomatisasi yang fleksibel. Dalam upaya untuk menyelesaikan masalah ini, SolidFire lahir.
Hingga saat ini, jajaran SolidFire terdiri dari empat model dengan rasio IOPS / TB yang berbeda.
10 (MLC) SSD digunakan untuk penyimpanan data, dan Radian RMS-200 sebagai NVRAM. Benar, sudah ada rencana untuk pindah ke modul
NVDIMM .
Yang menarik di sini adalah bagaimana SolidFire mengambil dan menyimpan data. Kita semua tahu tentang sumber daya yang terbatas dari drive SSD, oleh karena itu logis bahwa untuk pelestarian terbaik mereka, kompresi dan deduplikasi harus dilakukan dengan cepat, sebelum merekam ke SSD. Ketika SolidFire menerima data dari host, ia memecahnya menjadi blok 4K, setelah itu blok ini dikompresi dan disimpan dalam NVRAM. Kemudian replikasi sinkron blok ini di NVRAM ke node "tetangga" dari cluster terjadi. Setelah itu, SolidFire menerima hash dari blok terkompresi ini dan mencari nilai hash ini dalam indeks data yang disimpan dalam seluruh cluster. Jika blok dengan hash seperti itu sudah ada, SolidFire hanya memperbarui metadata-nya dengan tautan ke blok ini, jika blok tersebut berisi data unik, itu ditulis ke SSD, dan metadata juga ditulis untuk itu. Mekanisme ini untuk menyimpan data dan metadata sangat mirip dengan mekanisme operasi penyimpanan objek.
Cluster uji kami terdiri dari empat nodeRumor sudah muncul bahwa baris ini akan segera diperbarui. Perlu diperhatikan satu hal yang sangat penting - cluster SolidFire dapat bekerja dengan node dengan “kepadatan TIO / TB” yang berbeda, dan menggabungkan node dari berbagai generasi dalam satu cluster. Pertama, itu membuat penggunaan sistem ini lebih dapat diprediksi dalam hal dukungan perangkat keras, dan juga memfasilitasi transisi dari node lama ke yang baru, ketika Anda cukup menambahkan yang baru dan menghapus yang lama dari cluster secara real time (hanya menunggu cluster untuk membangun kembali) tanpa downtime, karena Ada dukungan untuk Scale Out dan Scale Back.
SolidFire dapat disampaikan sebagai tiga solusi:
- SolidFire sebagai produk mandiri berbasis pada server Dell / EMC,
- sebagai bagian dari FlexPod SF pada server Cisco,
- sebagai bagian dari NetApp HCI pada platformnya.
Seperti yang dapat Anda lihat dari tabel karakteristik, node hanya mendukung koneksi iSCSI, dan untuk koneksi FC ada jenis node yang terpisah - Fabric Interconnect, yang pada gilirannya berisi empat port untuk data FC dan empat port iSCSI untuk menghubungkan ke node, serta 64GB memori sistem asli / cache baca.
Tabel karakteristik juga menunjukkan kinerja masing-masing node. Ini adalah salah satu kasus ketika Anda mengetahui kinerja sistem penyimpanan Anda pada tahap pembelian. Kinerja ini dijamin (dengan profil beban 4Kb, 80/20) untuk setiap node.
Dengan demikian, membeli sekelompok node X atau memperluas solusi yang ada, Anda memahami berapa banyak volume dan kinerja seperti apa yang akan Anda dapatkan pada akhirnya. Tentu saja, Anda dapat memeras lebih banyak kinerja dari setiap node dalam kondisi tertentu, tetapi ini bukanlah tujuan dari solusi ini. Jika Anda ingin mendapatkan jutaan IOPS dalam 2U dalam satu volume, lebih baik Anda mengalihkan perhatian ke produk lain, seperti AFF. Kinerja terbesar di SolidFire dapat diperoleh dengan sejumlah besar volume dan sesi.
Beranda AntarmukaManajemen penyimpanan cukup sederhana. Faktanya, kami memiliki dua kumpulan sumber daya: volume dan IOPS. Dengan mengidentifikasi salah satu jenis sumber daya dan mengetahui jumlah akhirnya, kami dengan jelas memahami kemampuan lain dari sistem kami. Ini lagi membuat memperluas sistem tugas yang sangat mudah. Perlu lebih banyak kinerja? Pertimbangkan SF4805 atau SF19210 dengan rasio IOPS / TB “kurang padat”. Perlu volume? Kami melihat ke SF9605 dan SF38410, yang menyediakan lebih sedikit IOPS di Gb.
Dari sudut pandang administrator penyimpanan, sistem terlihat sangat membosankan. Hal-hal seperti deduplikasi dan kompresi berfungsi secara default.
Replikasi dan snapshot juga tersedia, dan replikasi dapat diatur untuk seluruh jajaran produk NetApp (kecuali untuk E-series). Kesederhanaan inilah, menurut pendapat saya, yang diungkapkan di balik kutipan dari Dave Heats dari judul artikel. Mengingat bahwa sistem ini melibatkan integrasi dengan berbagai sistem alokasi sumber daya yang dinamis, tanpa partisipasi administrator dan tanpa biaya tenaga kerja tambahan, Anda akan segera lupa bagaimana tampilan antarmuka SolidFire. Tetapi kita akan berbicara lebih banyak tentang integrasi.
Kami di
Onlanta melakukan stress testing untuk memastikan IOPS 200k yang dijanjikan. Bukannya kita tidak percaya dengan vendor, tetapi sudah terbiasa mencoba semuanya sendiri. Kami tidak menetapkan diri kami tujuan memeras sistem lebih dari yang dinyatakan. Kami juga dapat memverifikasi dari pengalaman kami sendiri bahwa sistem memberikan hasil yang baik justru dengan sejumlah besar arus. Untuk melakukan ini, kami mengatur 10 volume 1TB di SolidFire, di mana kami menempatkan satu mesin virtual pengujian. Sudah pada tahap mempersiapkan lingkungan pengujian, kami sangat terkejut dengan pekerjaan deduplikasi. Terlepas dari kenyataan bahwa skema kerjanya cukup standar, kualitas kerja di dalam cluster ternyata sangat efektif. Disk sebelum tes diisi dengan data acak.
Untuk membuatnya lebih cepat, kami membuat blok 10 mb, lalu mereka mengisinya. Selain itu, pada setiap mesin virtual, blok ini dibuat secara terpisah, yaitu di semua mobil polanya berbeda. Dari 10TB diisi dengan data - ruang yang ditempati sebenarnya pada array adalah 4TB. Efisiensi deduplikasi adalah 1: 2.5, pada FAS dengan pendekatan ini, efisiensi deduplikasi inline cenderung ke 0. Kami mampu mendapatkan 190k IOPS dengan respons ~ 1 ms di bangku uji kami.
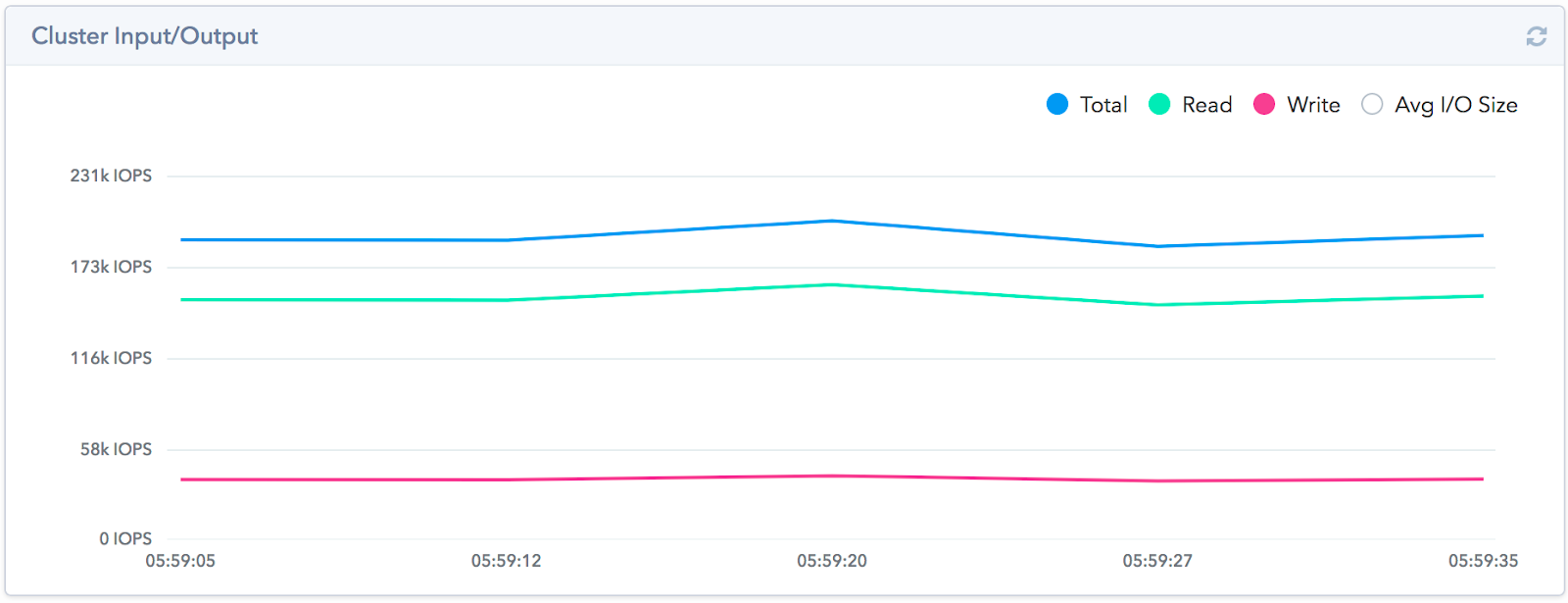
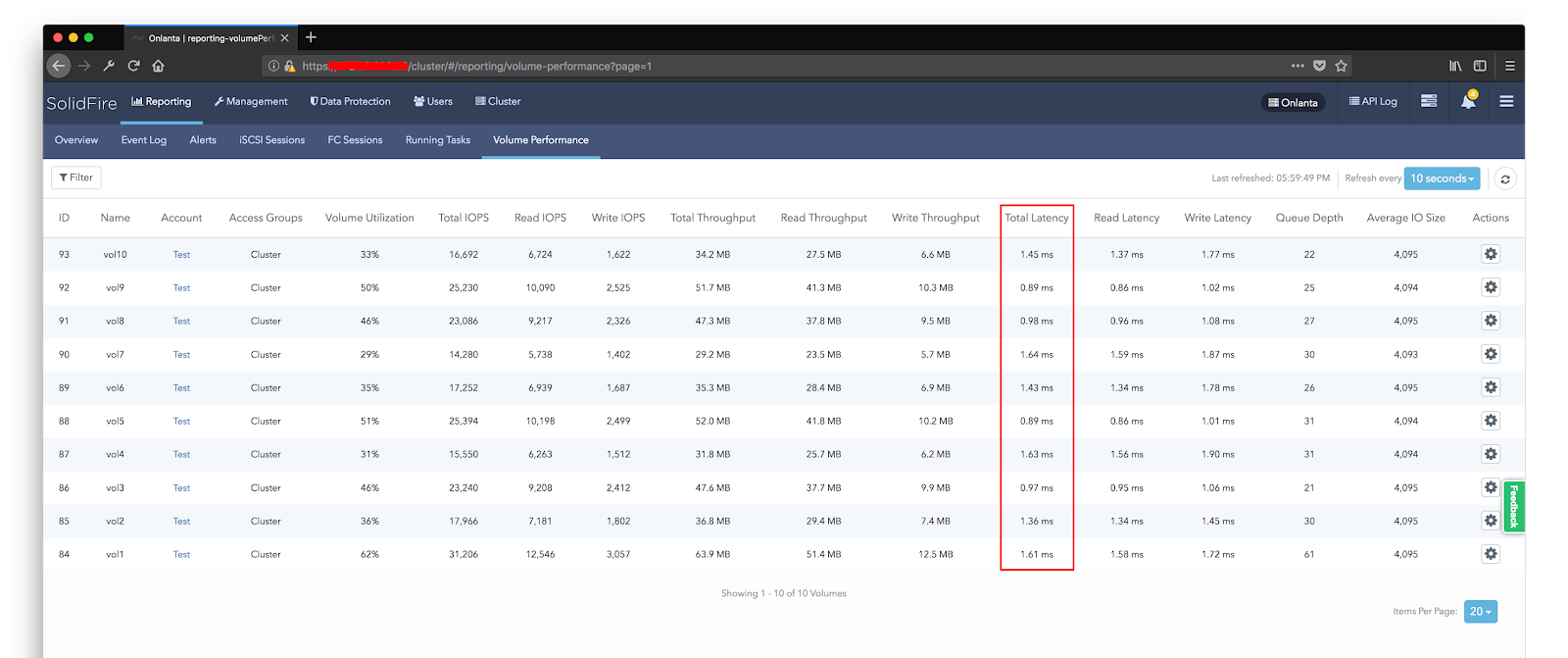
Saya ingin mencatat bahwa fitur arsitektural dari solusi ini tidak memungkinkan untuk mendapatkan kinerja tingkat tinggi pada sejumlah kecil thread. Satu bulan kecil atau hanya satu mesin virtual uji tidak akan dapat menunjukkan hasil yang tinggi. Kami bisa mendapatkan jumlah IOPS ini dengan menggunakan seluruh kapasitas sistem dan dengan peningkatan bertahap dalam jumlah mesin virtual yang membuat beban menggunakan fio. Kami meningkatkan jumlah mereka sampai penundaan tidak melebihi 1,5 ms, setelah itu kami berhenti dan melepas indikator kinerja.
Kepenuhan subsistem disk juga memengaruhi kinerja. Seperti yang saya katakan sebelumnya, sebelum menjalankan tes, kami mengisi disk dengan data acak. Jika Anda menjalankan tes tanpa terlebih dahulu mengisi disk, kinerjanya akan jauh lebih tinggi dengan tingkat penundaan yang sama.
Kami juga melakukan tes toleransi kesalahan favorit kami dengan mematikan salah satu node. Untuk mendapatkan efek terbaik, node Master dipilih untuk menonaktifkan. Karena kenyataan bahwa setiap server klien membuat sesi sendiri dengan node cluster, dan tidak melalui beberapa titik, ketika melepaskan salah satu dari node, tidak semua mesin virtual mengalami degradasi, tetapi hanya mereka yang bekerja dengan node ini. Dengan demikian, dari sisi penyimpanan, kami hanya melihat penurunan sebagian kinerja.
Tentu saja, pada bagian host virtualisasi, pada beberapa penyimpanan data, penurunan kinerja mencapai 0. Tetapi dalam waktu 30 detik, kinerja dipulihkan tanpa kehilangan kinerja (harus diingat bahwa beban pada saat penurunan berada pada 120k iops, yang tiga berpotensi menghasilkan dari empat node, masing-masing, kita seharusnya tidak melihat kerugian dalam kinerja).
Di sisi SolidFire, pembangunan kembali array dimulai. Pengatur waktu berbohong sedikit, dan prosesnya memakan waktu sekitar 55 menit, yang cocok dengan jam yang dijanjikan oleh vendor. Pada saat yang sama, tidak ada yang menghapus beban dari sistem penyimpanan, dan tetap pada level yang sama dengan 120k IOPS.Toleransi kesalahan disediakan tidak hanya pada level disk, tetapi juga pada level node. Cluster mendukung kegagalan simultan dari satu node, setelah itu proses membangun kembali cluster dimulai. Mempertimbangkan penggunaan SSD dan bahwa semua node terlibat dalam pembangunan kembali, pemulihan cluster membutuhkan waktu sekitar satu jam (pembangunan kembali jika terjadi kegagalan disk membutuhkan waktu sekitar 10 menit). Harus diingat bahwa ketika sebuah simpul gagal, Anda kehilangan baik dalam kinerja dan dalam jumlah ruang yang dapat digunakan. Dengan demikian, Anda selalu perlu memiliki ruang kosong dalam jumlah satu node. Ukuran cluster minimum adalah empat node. Konfigurasi ini akan memungkinkan Anda untuk menghindari masalah jika salah satu node gagal sebelum Anda menunggu penggantian tiba.
Seperti kebanyakan sistem penyimpanan, pemantauan kinerja hanya ditampilkan di sini secara waktu nyata. Untuk memiliki akses ke data historis, Anda perlu menggunakan apa yang disebut Management Node, yang berkomitmen untuk mengambil data API dari SolidFire dan mengunggahnya ke Active IQ. Jika Anda sudah bekerja dengan sistem NetApp, maka Anda mungkin sudah menemukan portal ini. Anda memiliki peluang untuk bekerja dengan data produktivitas, efisiensi, termasuk perkiraan pertumbuhan. Pada apa Anda dapat mengakses data ini bahkan dari perangkat seluler Anda, berada di mana saja di dunia.
Karena saya menyebutkan pekerjaan deduplikasi inline, saya juga akan mengatakan tentang efisiensi penyimpanan secara umum. Seperti halnya seri AFF, NetApp memberikan rasio efisiensi penyimpanan yang dijamin berdasarkan jenis data yang disimpan.
Seperti yang Anda lihat, tipe data dan koefisien yang dijamin sedikit berbeda. Sebagai contoh, SolidFire memiliki kasus kami - Infrastruktur Virtual dengan koefisien 4: 1. Dan ini tidak memperhitungkan penggunaan foto.
Arsitektur solusi didasarkan pada Kualitas Layanan (QoS), yang sebenarnya menjamin kinerja yang terjamin untuk setiap volume.
QoS adalah salah satu fungsi penting untuk penyedia layanan dan perusahaan lain yang perlu memberikan tingkat kinerja penyimpanan yang terjamin. Seseorang akan mengatakan bahwa QoS bukanlah sesuatu yang baru dan diterapkan oleh banyak vendor lain. Pertanyaan lain adalah bagaimana cara kerjanya. Jika dalam penyimpanan tradisional lebih cenderung memprioritaskan dan membatasi kecepatan, maka SolidFire, pada gilirannya, menggunakan pendekatan terintegrasi untuk mencapai kinerja yang dijamin.
- Menggunakan All-SSD memungkinkan Anda untuk mencapai latensi rendah untuk I / O.
- Scale-out dengan mudah memprediksi metrik kinerja.
- Kurangnya RAID klasik - kinerja yang dapat diprediksi dengan
- kegagalan perangkat keras
- Distribusi muatan seimbang menghilangkan hambatan dalam sistem.
- QoS membantu menghindari "tetangga yang berisik."
Selain kemampuan untuk mengatur kinerja maksimum dan minimum, dimungkinkan untuk memberikan kinerja di luar batas maksimum (Burst). Setiap volume memiliki sistem pinjaman bersyarat tertentu. Ketika produktivitasnya di bawah batas maksimum, ia dikreditkan dengan pinjaman ini, berkat itu, untuk jangka waktu tertentu, ia dapat mengatasi tanda maksimum produktivitas. Pendekatan ini memungkinkan Anda untuk menempatkan sejumlah besar aplikasi yang membutuhkan kinerja tinggi dalam penyimpanan, dan pada saat yang sama melindunginya dari efek negatif satu sama lain. Yang paling menarik adalah bahwa QoS didukung tidak hanya pada level volume array, tetapi juga pada level VMware VVs, yang memungkinkan alokasi sumber daya granular untuk setiap mesin virtual. Dukungan penuh untuk VAAI dan VASA API menyediakan integrasi array yang ketat dengan virtualizer.
Berbicara tentang integrasi, solusi dari VMware masih jauh dari selesai.
Mungkin SolidFire dapat disebut sistem penyimpanan paling otomatis yang dapat berintegrasi dengan sistem modern, sistem virtualisasi / wadahisasi, mendukung sistem manajemen konfigurasi, SDK tersedia untuk berbagai bahasa.
Saya, seperti biasa, melihat hal pertama yang SDK untuk Python adalah dengan mana saya mengotomatisasi alur kerja saya sendiri. Jadi kita perlu membuat 15 volume 1 TB dan mendapatkan iqn di output, yang akan kita sampaikan ke administrator VMware untuk menambahkan datastore. Kami sudah memiliki grup akses yang dibuat sebelumnya di mana VMware kami host dan kebijakan QoS yang telah dibuat sebelumnya terdaftar.
Atau inilah video Demo Python SDK yang lebih rinci dari SolidFire sendiri:
Pendekatan otomatisasi ini membuat SolidFire nyaman tidak hanya untuk penyedia cloud dan tugas serupa, tetapi sesuai dengan konsep integrasi dan pengiriman berkelanjutan (CI / CD) memungkinkan Anda untuk mengoptimalkan proses pengembangan.
Seperti yang saya sebutkan - WebUI bekerja melalui API, dan Anda dapat melihat semua permintaan dan tanggapan melalui API Log.Jika Anda tertarik untuk mempelajari lebih lanjut tentang SolidFire, tentang perbandingannya dengan pesaing, tentang bekerja dengan sistem, dll., Saya ingin merekomendasikan
saluran YouTube mereka, yang memiliki sejumlah besar video yang bermanfaat, dari berguna. Misalnya, siklus “Membandingkan Arsitektur All-Flash Modern”.
Di antara fitur-fitur bagus dari sistem ini adalah mekanisme bawaan untuk mencadangkan foto ke penyimpanan S3 eksternal yang kompatibel. Ini memungkinkan Anda untuk menggunakan snapshot sebagai cadangan dan menyimpannya di repositori eksternal baik di situs Anda maupun pada sumber daya eksternal, misalnya, di Amazon. Tentu saja, pendekatan ini hampir tidak bisa disebut fleksibel, dari sudut pandang pemulihan data, tetapi untuk beberapa kasus solusi ini dapat bermanfaat dan cukup dapat diterapkan. Ada hal menarik lainnya - Anda dapat mengunggah data ke penyimpanan S3 dengan dua cara:
- Asli - dalam hal ini, data yang sudah diduplikasi akan dituangkan, tetapi pada saat yang sama, volume ini hanya dapat dipulihkan ke sistem yang sama dengan yang dituangkan.
- Terkompresi - satu set blok lengkap sudah dituangkan di sini, yang memungkinkan Anda untuk mengembalikan bulan ini pada cluster SolidFire lainnya.
Secara umum, kami lebih dari puas dengan komunikasi kami dengan SolidFire. Kami mendapat kinerja yang dijanjikan, pekerjaan deduplikasi inline melampaui pujian, integrasi dan kemampuan otomatisasi juga meninggalkan kesan yang sangat positif. Pengaruh kegagalan node, atau lebih tepatnya efek minimalnya terhadap kinerja sistem secara keseluruhan, distribusi beban dan tidak adanya titik kegagalan tunggal yang dapat sangat mempengaruhi kinerja membuat sistem ini sangat menarik. Terlepas dari kenyataan bahwa cluster hanya dapat bekerja pada iSCSI, keberadaan node transport FC membuat sistem ini lebih universal.
Saya ingin mengucapkan terima kasih khusus dalam pengujian untuk Yevgeny Krasikov dari NetApp dan Arthur Alikulov dari Merlion. Omong-omong, Arthur, memiliki
saluran Telegram yang luar biasa untuk semua orang yang ingin mengikuti berita dari arah penyimpanan dan NetApp pada khususnya. Anda dapat menemukan sejumlah besar bahan yang berguna di dalamnya, dan siapa pun yang hanya perlu membaca, tetapi juga ingin berbicara, ada juga diskusi
penyimpanan obrolan .
Jika Anda masih memiliki pertanyaan atau jika yang baru tiba-tiba muncul, saya mengundang Anda untuk mengunjungi NetApp Directions 2018, yang akan diadakan 17 Juli 2018 di Hyatt Regency Petrovsky Park, di mana Arthur dan saya akan berbicara tentang SolidFire di salah satu sesi.
Registrasi untuk acara dan semua detailnya.
Dan di perusahaan kami ada lowongan.