Hai Di bawah ini adalah transkrip dari video pidato di reli komunitas Apache Ignite di St. Petersburg pada 20 Juni. Anda dapat mengunduh slide di sini .
Ada seluruh kelas masalah yang dihadapi pengguna pemula. Mereka baru saja mengunduh Apache Ignite, menjalankan dua, tiga, sepuluh kali pertama, dan mendatangi kami dengan pertanyaan yang diselesaikan dengan cara yang sama. Oleh karena itu, saya mengusulkan untuk membuat daftar periksa yang akan menghemat banyak waktu dan saraf ketika Anda membuat aplikasi Apache Ignite pertama Anda. Kami akan berbicara tentang persiapan peluncuran; cara membuat cluster berkumpul; cara memulai beberapa perhitungan di Compute Grid; Cara menyiapkan model dan kode data sehingga Anda dapat menulis data Anda ke Ignite dan kemudian membacanya dengan sukses. Dan yang paling penting: bagaimana tidak merusak apa pun dari awal.
Persiapan untuk peluncuran - konfigurasi logging
Kami membutuhkan log. Jika Anda pernah mengajukan pertanyaan di mailing list Apache Ignite atau di StackOverflow, seperti "mengapa semuanya ditutup", kemungkinan besar hal pertama yang diminta untuk Anda kirim adalah semua log dari semua node.
Secara alami, Apache Ignite logging diaktifkan secara default. Namun ada nuansa. Pertama, Apache Ignite menulis sedikit di stdout . Secara default, ini dimulai dalam apa yang disebut mode senyap. Di stdout Anda hanya akan melihat kesalahan paling mengerikan, dan semua yang lain akan disimpan dalam file, jalur yang ditampilkan Apache Ignite di awal (secara default - ${IGNITE_HOME}/work/log ). Anda tidak menghapusnya dan menyimpan log lebih lama, ini bisa sangat berguna.
stdout dinyalakan saat startup standar
Untuk membuatnya lebih mudah untuk mencari tahu tentang masalah tanpa masuk ke file yang terpisah dan mengatur pemantauan terpisah untuk Apache Ignite, Anda dapat menjalankannya dalam mode-verbose dengan perintah
ignite.sh -v
dan kemudian sistem akan mulai menulis tentang semua peristiwa di stdout bersama dengan sisa dari pendataan aplikasi.
Periksa log! Sangat sering di dalamnya Anda dapat menemukan solusi untuk masalah Anda. Jika cluster telah runtuh, sangat sering di log Anda dapat melihat pesan seperti "Tambah batas waktu ini dan itu dalam konfigurasi ini dan itu. Kami jatuh karena dia. Dia terlalu kecil. Jaringannya tidak cukup baik. "
Perakitan klaster
Tamu tak diundang
Masalah pertama yang dihadapi banyak orang adalah tamu tak diundang di kluster Anda. Atau Anda sendiri berubah menjadi tamu yang tidak diundang: mulailah sebuah cluster baru dan tiba-tiba Anda melihat bahwa dalam snapshot topologi pertama alih-alih satu node Anda memiliki dua server dari awal. Bagaimana bisa begitu? Anda hanya meluncurkan satu.
Pesan yang menunjukkan bahwa cluster memiliki dua node

Faktanya adalah bahwa secara default Apache Ignite menggunakan Multicast, dan saat startup itu akan mencari semua Apache Ignite lain yang berada di subnet yang sama, di grup Multicast yang sama. Dan jika ya, itu akan mencoba untuk terhubung. Dan jika koneksi gagal, itu tidak akan memulai sama sekali. Oleh karena itu, di cluster di laptop pekerjaan saya, node tambahan dari cluster di laptop rekan secara teratur muncul secara teratur, yang tentu saja tidak terlalu nyaman.
Bagaimana cara melindungi diri dari ini? Cara termudah untuk mengkonfigurasi IP statis. Alih-alih TcpDiscoveryMulticastIpFinder , yang digunakan secara default, ada TcpDiscoveryVmIpFinder . Di sana, tuliskan semua IP dan port yang Anda hubungkan. Ini jauh lebih nyaman dan akan melindungi Anda dari sejumlah besar masalah, terutama di lingkungan pengembangan dan pengujian.
Alamat terlalu banyak
Masalah selanjutnya. Anda menonaktifkan Multicast, memulai cluster, dalam satu konfigurasi, Anda mengatur jumlah IP yang layak dari lingkungan yang berbeda. Dan itu terjadi bahwa Anda meluncurkan simpul pertama dalam gugus baru selama 5-10 menit, meskipun semua yang berikutnya terhubung dengannya dalam 5-10 detik.
Ambil daftar tiga alamat IP. Untuk masing-masing, kami meresepkan kisaran 10 port. Secara total, 30 alamat TCP diperoleh. Karena Apache Ignite harus berusaha menyambung ke cluster yang ada sebelum membuat cluster baru, itu akan memeriksa setiap IP pada gilirannya. Mungkin tidak ada salahnya pada laptop Anda, tetapi perlindungan pemindaian port sering kali termasuk dalam beberapa lingkungan berawan. Artinya, ketika mengakses port pribadi pada beberapa alamat IP, Anda tidak akan menerima respons apa pun sampai batas waktu berlalu. Secara default, ini adalah 10 detik. Dan jika Anda memiliki 3 alamat dari 10 port, maka Anda mendapatkan 3 * 10 * 10 = 300 detik menunggu - 5 menit yang sama untuk terhubung.
Solusinya jelas: jangan mendaftar port yang tidak perlu. Jika Anda memiliki tiga IP, maka Anda benar-benar membutuhkan kisaran 10 port default. Ini nyaman ketika Anda menguji sesuatu pada mesin lokal dan menjalankan 10 node. Tetapi dalam sistem nyata, satu port biasanya cukup. Atau nonaktifkan perlindungan terhadap pemindaian port pada jaringan internal, jika Anda memiliki kesempatan seperti itu.
Masalah umum ketiga adalah IPv6. Anda dapat melihat pesan kesalahan jaringan yang aneh: tidak bisa terhubung, tidak bisa mengirim pesan, simpul tersegmentasi. Ini berarti bahwa Anda telah jatuh dari kluster. Sangat sering, masalah seperti itu disebabkan oleh lingkungan campuran dari IPv4 dan IPv6. Ini bukan untuk mengatakan bahwa Apache Ignite tidak mendukung IPv6, tetapi saat ini ada masalah tertentu.
Solusi termudah adalah dengan memberikan opsi ke mesin Java
-Djava.net.preferIPv4Stack=true
Kemudian Java dan Apache Ignite tidak akan menggunakan IPv6. Ini memecahkan bagian penting dari masalah dengan runtuh cluster.
Persiapan basis kode - kami membuat cerita bersambung dengan benar
Cluster telah berkumpul, perlu untuk memulai sesuatu di dalamnya. Salah satu elemen terpenting dalam interaksi kode Anda dengan kode Apache Ignite adalah Marshaller, atau serialisasi. Untuk menulis sesuatu ke memori, untuk kegigihan, untuk mengirim melalui jaringan, Apache Ignite terlebih dahulu membuat serial objek Anda. Anda dapat melihat pesan yang dimulai dengan kata-kata: "tidak dapat ditulis dalam format biner" atau "tidak dapat diserialisasi menggunakan BinaryMarshaller". Hanya akan ada satu peringatan seperti itu di log, tetapi terlihat. Ini berarti Anda perlu sedikit mengubah kode Anda untuk berteman dengan Apache Ignite.
Apache Ignite menggunakan tiga mekanisme untuk serialisasi:
JdkMarshaller - serialisasi Java biasa;OptimizedMarshaller - serialisasi Java sedikit dioptimalkan, tetapi mekanismenya sama;BinaryMarshaller adalah serialisasi yang ditulis khusus untuk Apache Ignite, digunakan di mana-mana di bawah kapnya. Dia memiliki sejumlah keunggulan. Di suatu tempat kita dapat menghindari serialisasi dan deserialisasi tambahan, dan di suatu tempat kita bahkan bisa mendapatkan objek non-deserialisasi di API, bekerja dengannya secara langsung dalam format biner, seperti dengan sesuatu seperti JSON.
BinaryMarshaller akan dapat membuat cerita bersambung dan BinaryMarshaller serialisasi POJO Anda yang tidak memiliki apa-apa selain bidang dan metode sederhana. Tetapi jika Anda memiliki serialisasi khusus melalui readObject() dan writeObject() , jika Anda menggunakan Externalizable , maka BinaryMarshaller tidak akan mengatasinya. Dia akan melihat bahwa objek Anda tidak dapat diserialisasi dengan rekaman bidang non-transient yang biasa dan akan menyerah - itu akan bergulir kembali ke OptimizedMarshaller .
Untuk berteman dengan objek-objek tersebut dengan Apache Ignite, Anda perlu mengimplementasikan antarmuka Binarylizable . Dia sangat sederhana.
Misalnya, ada TreeMap standar dari Jawa. Ini memiliki serialisasi khusus dan deserialisasi melalui objek membaca dan menulis. Pertama menjelaskan beberapa bidang, dan kemudian menulis panjang dan data itu sendiri ke OutputStream .
Implementasi TreeMap.writeObject()
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException {
writeBinary() dan readBinary() dari karya Binarylizable dengan cara yang persis sama: BinaryTreeMap membungkus dirinya dalam TreeMap biasa dan menulisnya ke OutputStream . Metode ini mudah ditulis, dan akan sangat meningkatkan produktivitas.
BinaryTreeMap.writeBinary()
public void writeBinary(BinaryWriter writer) throws BinaryObjectException { BinaryRawWriter rewriter = writer. rewrite (); rawWriter.writeObject(map.comparator()); int size = map.size(); rawWriter.writeInt(size); for (Map.Entry<Object, Object> entry : ((TreeMap<Object, Object>)map).entrySet()) { rawWriter.writeObject(entry.getKey()); rawWriter.writeObject(entry.getValue()); } }
Luncurkan di Compute Grid
Menyalakan tidak hanya memungkinkan Anda untuk menyimpan data, tetapi juga menjalankan komputasi terdistribusi. Bagaimana kita menjalankan semacam lambda sehingga mencerai-beraikan semua server dan berjalan?
Sebagai permulaan, apa masalahnya dengan contoh kode ini?
Apa masalahnya?
Foo foo = …; Bar bar = ...; ignite.compute().broadcast( () -> doStuffWithFooAndBar(foo, bar) );
Dan jika demikian?
Foo foo = …; Bar bar = ...; ignite.compute().broadcast(new IgniteRunnable() { @Override public void run() { doStuffWithFooAndBar(foo, bar); } });
Seperti yang Anda duga, banyak yang akrab dengan perangkap lambdas dan kelas anonim, masalahnya adalah dalam menangkap variabel dari luar. Misalnya, kami mengirim lambda. Ini menggunakan beberapa variabel yang dideklarasikan di luar lambda. Ini berarti bahwa variabel-variabel ini akan bepergian dengannya dan terbang melintasi jaringan ke semua server. Dan kemudian semua pertanyaan yang sama muncul: apakah benda-benda ini bersahabat dengan BinaryMarshaller ? Apa ukurannya? Apakah kita umumnya ingin mereka dipindahkan ke suatu tempat, atau apakah benda-benda ini begitu besar sehingga lebih baik untuk melewati semacam ID dan menciptakan kembali benda-benda di dalam lambda sudah di sisi lain?
Kelas anonim bahkan lebih buruk. Jika lambda tidak dapat membawa ini, membuangnya, jika tidak digunakan, maka kelas anonim pasti akan membawanya, dan ini biasanya tidak mengarah pada sesuatu yang baik.
Contoh berikut. Lambda lagi, tetapi yang menggunakan API Apache Ignite sedikit.
Menggunakan ignite dalam penutupan komputasi salah
ignite.compute().broadcast(() -> { IgniteCache foo = ignite.cache("foo"); String sql = "where id = 42"; SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true); return foo.query(qry); });
Dalam versi asli, dibutuhkan cache dan secara lokal membuat semacam query SQL di dalamnya. Ini adalah pola seperti itu ketika Anda perlu mengirim tugas yang hanya berfungsi dengan data lokal pada node jarak jauh.
Apa masalahnya di sini? Lambda lagi menangkap tautan, tetapi sekarang bukan ke objek, tetapi ke Ignite lokal pada node yang kami kirimkan. Dan itu bahkan berfungsi, karena objek Ignite memiliki metode readResolve() , yang memungkinkan deserialisasi untuk menggantikan Ignite yang datang melalui jaringan dengan yang lokal pada node tempat kami mengirimkannya. Tetapi ini juga terkadang membawa konsekuensi yang tidak diinginkan.
Pada dasarnya, Anda hanya mentransfer lebih banyak data melalui jaringan daripada yang Anda inginkan. Jika Anda perlu mendapatkan dari beberapa kode yang Anda tidak mengontrol peluncuran ke Apache Ignite atau beberapa antarmuka, maka yang paling sederhana adalah menggunakan metode Ignintion.localIgnite() . Anda dapat memanggilnya dari utas apa pun yang dibuat oleh Apache Ignite dan mendapatkan tautan ke objek lokal. Jika Anda memiliki lambda, layanan, apa pun, dan Anda mengerti bahwa Anda perlu Ignite di sini, maka saya merekomendasikan metode ini.
Kami menggunakan Ignite inside compute closure dengan benar - melalui localIgnite()
ignite.compute().broadcast(() -> { IgniteCache foo = Ignition.localIgnite().cache("foo"); String sql = "where id = 42"; SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true); return foo.query(qry); });
Dan contoh terakhir di bagian ini. Apache Ignite memiliki Grid Layanan yang dapat digunakan untuk menggunakan layanan microser secara langsung dalam sebuah cluster, dan Apache Ignite akan membantu menjaga jumlah instance yang tepat secara online. Katakanlah dalam layanan ini kita juga memerlukan tautan ke Apache Ignite. Bagaimana cara mendapatkannya? Kita bisa menggunakan localIgnite() , tetapi kemudian tautan ini harus disimpan secara manual di bidang tersebut.
Layanan menyimpan Ignite di bidang yang salah - menganggapnya sebagai argumen untuk konstruktor
MyService s = new MyService(ignite) ignite.services().deployClusterSingleton("svc", s); ... public class MyService implements Service { private Ignite ignite; public MyService(Ignite ignite) { this.ignite = ignite; } ... }
Ada cara yang lebih sederhana. Kami masih memiliki kelas penuh, dan bukan lambda, sehingga kami dapat membuat anotasi bidang sebagai @IgniteInstanceResource . Ketika layanan dibuat, Apache Ignite akan menempatkan dirinya di sana, dan Anda dapat menggunakannya dengan aman. Saya sangat menyarankan Anda untuk melakukan hal itu, dan jangan mencoba untuk memberikan Apache Ignite dan anak-anaknya ke konstruktor.
Layanan menggunakan @IgniteInstanceResource
public class MyService implements Service { @IgniteInstanceResource private Ignite ignite; public MyService() { } ... }
Menulis dan membaca data
Memperhatikan garis dasar
Sekarang kami memiliki gugus Apache Ignite dan kode yang disiapkan.
Mari kita bayangkan skenario ini:
- Satu cache
REPLICATED - salinan data tersedia di semua node; - Kegigihan asli sedang dalam proses penulisan ke disk.
Kami memulai satu simpul. Karena kegigihan asli diaktifkan, kita perlu mengaktifkan cluster sebelum bekerja dengannya. Aktifkan. Lalu kami meluncurkan beberapa node lagi.
Segalanya tampak bekerja: menulis dan membaca baik-baik saja. Semua node memiliki salinan data, Anda dapat dengan aman menghentikan satu node. Tetapi jika Anda menghentikan simpul pertama dari mana Anda memulai peluncuran, maka semuanya rusak: data hilang, dan operasi berhenti lewat.
Alasannya adalah topologi dasar - banyak node yang menyimpan data kegigihan pada mereka. Semua node lain tidak akan memiliki data persisten.
Set node ini untuk pertama kali ditentukan pada saat aktivasi. Dan simpul-simpul yang Anda tambahkan kemudian tidak lagi termasuk dalam jumlah simpul dasar. Artinya, banyak topologi dasar hanya terdiri dari satu, simpul pertama, ketika berhenti, semuanya rusak. Untuk mencegah hal ini terjadi, mulailah semua node terlebih dahulu, lalu aktifkan cluster. Jika Anda perlu menambah atau menghapus simpul menggunakan perintah
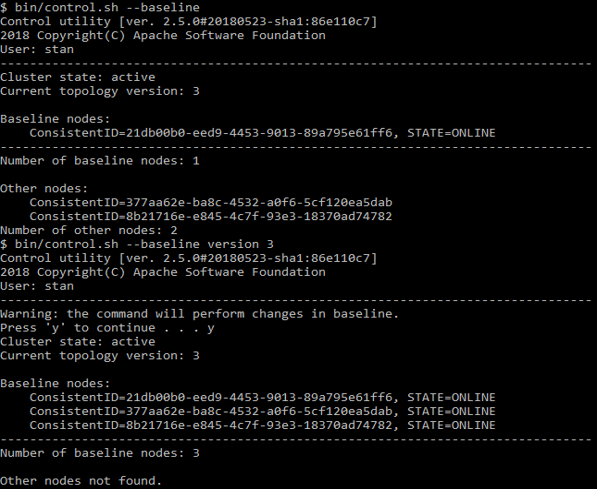
control.sh --baseline
Anda dapat melihat node mana yang terdaftar di sana. Script yang sama dapat memperbarui baseline ke keadaan saat ini.
Contoh control.sh
Colokasi data
Sekarang kita tahu bahwa data tersebut disimpan, cobalah untuk membacanya. Kami memiliki dukungan SQL, Anda dapat melakukan SELECT - hampir seperti di Oracle. Tetapi pada saat yang sama, kita dapat skala dan berjalan pada sejumlah node, data disimpan secara terdistribusi. Mari kita lihat model seperti itu:
public class Person { @QuerySqlField public Long id; @QuerySqlField public Long orgId; } public class Organization { @QuerySqlField private Long id; }
Minta
SELECT * FROM Person as p JOIN Organization as o ON p.orgId = o.id
tidak akan mengembalikan semua data. Apa yang salah
Orang ( Person ) mengacu pada organisasi ( Organization ) dengan ID. Ini adalah kunci asing klasik. Tetapi jika kita mencoba untuk menggabungkan dua tabel dan mengirimkan query SQL, maka dengan beberapa node dalam cluster kita tidak akan menerima semua data.
Faktanya adalah, secara default, SQL JOIN hanya berfungsi dalam satu node. Jika SQL terus-menerus pergi ke seluruh cluster untuk mengumpulkan data dan mengembalikan hasil lengkap, itu akan sangat lambat. Kami akan kehilangan semua manfaat dari sistem terdistribusi. Jadi alih-alih, Apache Ignite hanya melihat data lokal.
Untuk mendapatkan hasil yang benar, kita perlu menempatkan data bersama (colocation). Yaitu, untuk kombinasi Person dan Organisasi yang benar, data dari kedua tabel harus disimpan pada node yang sama.
Bagaimana cara melakukannya? Solusi termudah adalah mendeklarasikan kunci afinitas. Ini adalah nilai yang menentukan pada simpul mana, di mana partisi, di mana kelompok catatan ini atau nilai itu akan ditemukan. Jika kami mendeklarasikan ID organisasi di Person sebagai kunci afinitas, ini berarti bahwa orang-orang dengan ID organisasi ini harus berada di simpul yang sama dengan organisasi dengan ID yang sama.
Jika karena alasan tertentu Anda tidak dapat melakukan ini, ada solusi lain yang kurang efektif - aktifkan sambungan terdistribusi. Ini dilakukan melalui API, dan prosedurnya tergantung pada apa yang Anda gunakan - Java, JDBC atau yang lainnya. Kemudian JOIN akan dieksekusi lebih lambat, tetapi kemudian mereka akan mengembalikan hasil yang benar.
Mari kita pertimbangkan cara bekerja dengan kunci afinitas. Bagaimana kita memahami bahwa ID ini dan itu, bidang ini dan itu cocok untuk menentukan afinitas? Jika kita mengatakan bahwa semua orang dengan orgId sama akan disimpan bersama, maka orgId adalah satu grup yang tidak dapat dibagi. Kami tidak dapat mendistribusikannya di beberapa node. Jika database berisi 10 organisasi, maka akan ada 10 grup yang tidak dapat dibagi yang dapat diletakkan di 10 node. Jika ada lebih banyak node di cluster, maka semua node "ekstra" akan tetap tanpa grup. Ini sangat sulit untuk didefinisikan dalam runtime, jadi pikirkan sebelumnya.
Jika Anda memiliki satu organisasi besar dan 9 organisasi kecil, maka ukuran grup akan berbeda. Tetapi Apache Ignite tidak melihat jumlah catatan dalam grup afinitas ketika mendistribusikannya di seluruh node. Oleh karena itu, ia tidak akan menempatkan satu grup pada satu node, tetapi 9 grup lainnya pada yang lain untuk menaikkan level distribusi. Sebaliknya, ia akan menempatkan mereka 5 dan 5, (atau 6 dan 4, atau bahkan 7 dan 3).
Bagaimana cara membuat data terdistribusi secara merata? Semoga kita punya
- Kunci K;
- Berbagai kunci afinitas;
- Partisi P, yaitu kelompok besar data yang akan didistribusikan oleh Apache Ignite di antara node;
- N node.
Maka perlu bahwa kondisi
K >> A >> P >> N
di mana >> adalah "lebih banyak" dan data akan didistribusikan secara relatif merata.
Omong-omong, standarnya adalah P = 1024.
Kemungkinan besar Anda tidak akan berhasil dalam distribusi yang seragam. Ini adalah kasus di Apache Ignite 1.x hingga 1.9. Ini disebut FairAffinityFunction dan tidak berfungsi dengan baik - ini menyebabkan terlalu banyak lalu lintas antar node. Sekarang algoritma ini disebut RendezvousAffinityFunction . Itu tidak memberikan distribusi yang benar-benar jujur, kesalahan antara node akan menjadi plus atau minus 5-10%.
Daftar periksa untuk pengguna baru Apache Ignite
- Siapkan, baca, simpan log
- Matikan multicast, catat hanya alamat dan port yang Anda gunakan
- Nonaktifkan IPv6
- Persiapkan Kelas Anda untuk
BinaryMarshaller - Melacak garis dasar Anda
- Atur kolokasi afinitas