
Desain akademis dari gudang data merekomendasikan menjaga segala sesuatu dalam bentuk yang dinormalisasi, dengan koneksi di antaranya. Kemudian rollback perubahan dalam matematika relasional akan menyediakan repositori yang dapat diandalkan dengan dukungan transaksi. Atomicity, Consistency, Isolasi, Durability - itu saja. Dengan kata lain, repositori dibuat khusus untuk memperbarui data dengan aman. Tetapi sama sekali tidak optimal untuk pencarian, terutama dengan gerakan lebar di seluruh tabel dan bidang. Butuh indeks, banyak indeks. Volume bertambah, rekaman melambat. SQL LIKE tidak diindeks, dan BERGABUNG DENGAN GROUP BY mengirimkannya ke perencana permintaan untuk bermeditasi.
Meningkatnya beban pada satu alat berat membuatnya melebar, baik secara vertikal ke langit-langit atau secara horizontal, membeli beberapa simpul lagi. Persyaratan kegagalan membuat data tersebar di beberapa node. Dan persyaratan pemulihan segera setelah kegagalan, tanpa penolakan layanan, memaksa Anda untuk mengkonfigurasi gugus mesin sehingga setiap saat dari mereka dapat melakukan penulisan dan membaca. Artinya, sudah menjadi master, atau menjadi dia secara otomatis dan segera.
Masalah pencarian cepat diselesaikan dengan menginstal repositori kedua yang dioptimalkan untuk pengindeksan terdekat. Pencarian teks lengkap, faceted, dengan stemming dan blackjack . Penyimpanan kedua menerima entri dari tabel pertama sebagai input, menganalisis dan membuat indeks. Dengan demikian, cluster penyimpanan data dilengkapi oleh cluster lain untuk pencarian mereka. Dengan konfigurasi master serupa untuk mencocokkan SLA keseluruhan. Semuanya baik-baik saja, bisnis senang, admin tidur di malam hari ... sampai ada lebih dari tiga mesin di klaster master-master.
Elastis
Gerakan NoSQL telah sangat memperluas cakrawala skala untuk data kecil dan besar. Node NoSQL dari cluster dapat mendistribusikan data di antara mereka sendiri sehingga kegagalan satu atau lebih dari mereka tidak mengarah pada penolakan layanan untuk seluruh cluster. Pembayaran untuk ketersediaan tinggi data terdistribusi adalah ketidakmampuan untuk memastikan konsistensi lengkap mereka untuk direkam pada waktu tertentu. Sebaliknya, NoSQL berbicara tentang konsistensi akhirnya . Artinya, diyakini bahwa suatu hari semua data akan menyebar ke node cluster, dan mereka akan menjadi konsisten dalam jangka panjang.
Jadi model relasional dilengkapi dengan yang non-relasional dan menelurkan banyak mesin basis data yang memecahkan masalah segitiga CAP dengan beberapa keberhasilan. Para pengembang mendapatkan alat-alat modis untuk membangun lapisan kegigihan ideal mereka sendiri - untuk setiap selera, anggaran, dan memuat profil.
ElasticSearch adalah perwakilan dari NoSQL yang dikelompokkan dengan API JSON RESTful di mesin Lucene, open source di Jawa, tidak hanya dapat membangun indeks pencarian, tetapi juga menyimpan dokumen asli. Tipuan seperti itu membantu untuk memikirkan kembali peran DBMS yang terpisah untuk menyimpan dokumen asli, atau bahkan mengabaikannya. Akhir dari pengantar.
Pemetaan
Pemetaan di ElasticSearch adalah sesuatu seperti skema (struktur tabel, dalam hal SQL) yang memberi tahu Anda bagaimana cara mengindeks dokumen yang masuk (catatan, dalam hal SQL). Pemetaan mungkin statis, dinamis, atau tidak ada. Pemetaan statis tidak memungkinkan dirinya untuk diubah. Dinamis memungkinkan Anda menambahkan bidang baru. Jika pemetaan tidak ditentukan, ElasticSearch akan melakukannya sendiri, setelah menerima dokumen pertama untuk ditulis. Ini akan menganalisis struktur bidang, membuat beberapa asumsi tentang jenis data di dalamnya, melewati pengaturan default dan menuliskannya. Sekilas tentang perilaku tanpa sirkuit seperti itu tampaknya sangat nyaman. Tetapi pada kenyataannya, itu lebih cocok untuk eksperimen daripada untuk kejutan dalam produksi.
Jadi, data diindeks, dan ini adalah proses satu arah. Setelah dibuat, pemetaan tidak dapat diubah secara dinamis seperti ALTER TABLE di SQL. Karena tabel SQL menyimpan dokumen asli yang Anda dapat mempercepat indeks pencarian. Tetapi di ElasticSearch sebaliknya. Dia sendiri adalah indeks pencarian di mana Anda dapat mempercepat dokumen asli. Itulah sebabnya skema indeks bersifat statis. Secara teoritis, seseorang dapat membuat bidang dalam pemetaan atau menghapusnya. Dalam praktiknya, ElasticSearch hanya memungkinkan Anda untuk menambahkan bidang. Upaya untuk menghapus bidang tidak mengarah ke apa pun.
Alias
Alias - Ini adalah nama tambahan untuk indeks ElasticSearch. Mungkin ada beberapa alias untuk satu indeks. Atau satu alias untuk banyak indeks. Kemudian indeks digabungkan secara logis seolah-olah dari luar dan terlihat seperti satu. Alias sangat nyaman untuk layanan yang berkomunikasi dengan indeks sepanjang hidupnya. Misalnya, produk alias dapat menyembunyikan products_v2 dan products_v25 , tanpa harus mengubah nama dalam layanan. Alias sangat diperlukan untuk migrasi data, ketika sudah ditransfer dari skema lama ke skema yang baru, dan Anda perlu mengganti aplikasi untuk bekerja dengan indeks baru. Mengganti alias dari indeks ke indeks adalah operasi atom. Artinya, itu dilakukan dalam satu langkah tanpa kerugian.
Reindex API
Tata letak data, pemetaan, cenderung berubah dari waktu ke waktu. Bidang baru ditambahkan, yang tidak perlu dihapus. Jika ElasticSearch berperan sebagai satu-satunya repositori, maka Anda memerlukan semacam alat untuk mengubah pemetaan dengan cepat. Untuk melakukan ini, ada perintah khusus untuk mentransfer data dari satu indeks ke indeks lain, yang disebut _reindex API . Ini bekerja dengan pemetaan indeks penerima yang sudah jadi atau kosong, di sisi server, dengan cepat mengindeks dalam batch 1000 dokumen sekaligus.
Pengindeksan ulang dapat melakukan konversi tipe bidang sederhana. Misalnya panjang dalam teks dan kembali panjang , atau boolean dalam teks dan kembali dalam boolean . Tapi -9,99 dalam boolean tidak tahu lagi bagaimana, itu bukan PHP untukmu . Di sisi lain, konversi tipe tidak aman. Layanan yang ditulis dalam bahasa dengan pengetikan dinamis dapat dimaafkan atas dosa semacam itu. Tetapi jika reindex tidak dapat mengkonversi tipe, maka dokumen tidak akan ditulis. Secara umum, migrasi data harus dilakukan dalam 3 tahap: tambahkan bidang baru, lepaskan layanan dengannya, bersihkan yang lama.
Bidang ditambahkan seperti ini. Skema indeks sumber diambil, properti baru dimasukkan, indeks kosong dibuat. Kemudian pengindeksan ulang dimulai:
{ "source": { "index": "test" }, "dest": { "index": "test_clone" } }
Bidang dihapus dengan cara yang sama. Skema indeks sumber diambil, bidang dihapus, indeks kosong dibuat. Kemudian pengindeksan ulang dimulai dengan daftar bidang yang akan disalin:
{ "source": { "index": "test", "_source": ["field1", "field3"] }, "dest": { "index": "test_clone" } }
Untuk kenyamanan, kedua kasing digabungkan menjadi fungsi kloning di Kaizen, klien desktop untuk ElasticSearch. Kloning dapat beradaptasi dengan pemetaan indeks tujuan. Contoh di bawah ini menunjukkan cara membuat klon parsial dari indeks dengan tiga koleksi (tipe, dalam istilah ElasticSearch), garis , adegan . Hanya baris dengan dua bidang yang tersisa di dalamnya, pemetaan statis diaktifkan, dan bidang speech_number dari teks menjadi panjang .
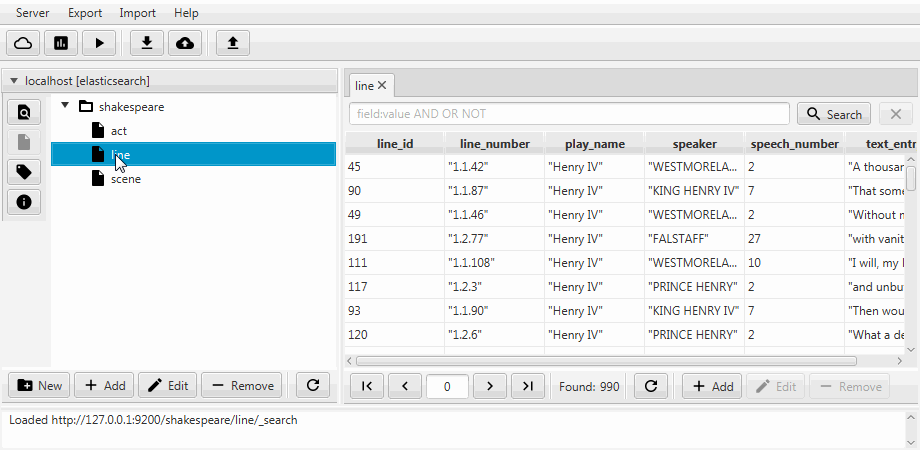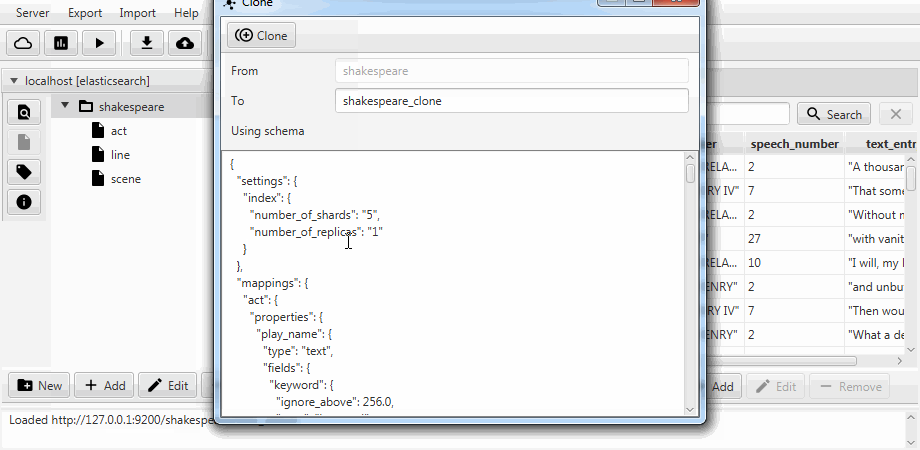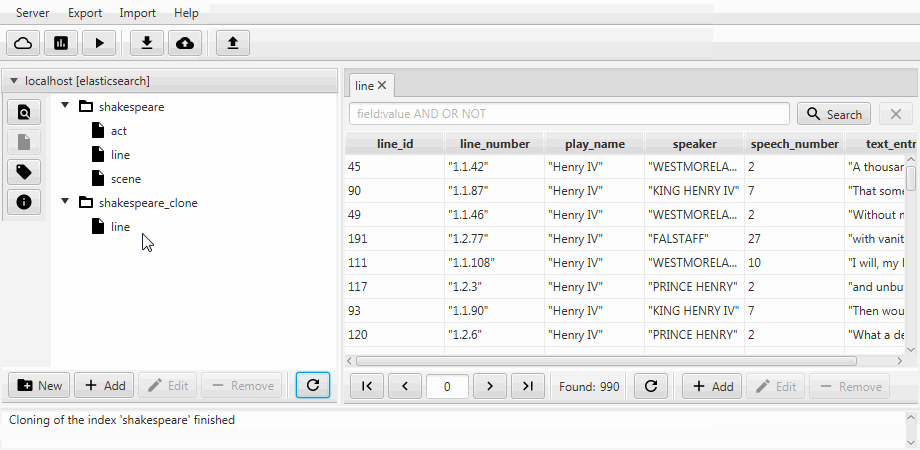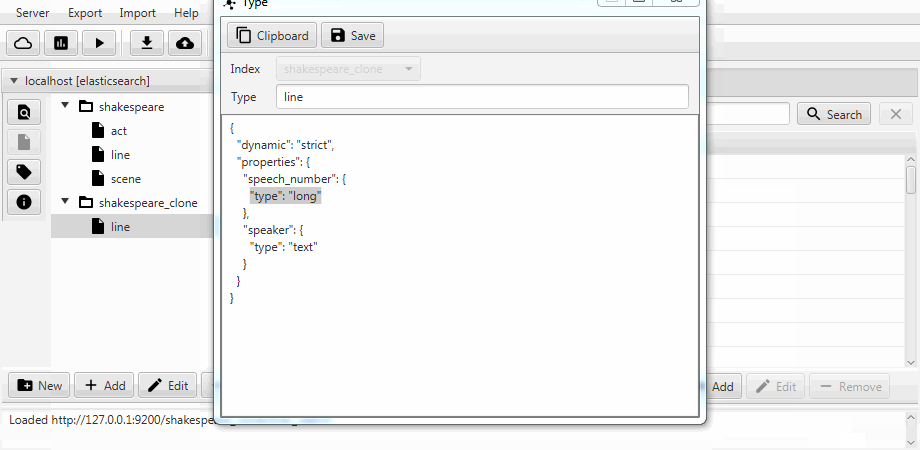
Migrasi
API indeks ulang memiliki satu fitur yang tidak menyenangkan - API tidak tahu bagaimana memonitor perubahan dalam indeks sumber. Jika sesuatu berubah di sana setelah pengindeksan ulang dimulai, maka perubahan tersebut tidak tercermin dalam indeks penerima. Untuk mengatasi masalah ini, Plugin ElasticSearch FollowUp dikembangkan, yang menambahkan perintah logging. Plugin dapat memonitor indeks, mengembalikan dalam format JSON tindakan yang dilakukan pada dokumen dalam urutan kronologis. Indeks, jenis, pengidentifikasi dokumen, dan operasi di atasnya - INDEX atau DELETE diingat. Plugin FollowUp diterbitkan di GitHub dan dikompilasi untuk hampir semua versi ElasticSearch.
Jadi, untuk migrasi data lossless, Anda perlu menginstal FollowUp pada node tempat pengindeksan ulang akan dimulai. Diasumsikan bahwa indeks sudah memiliki alias, dan semua aplikasi bekerja melaluinya. Tepat sebelum pengindeksan ulang, plugin dihidupkan. Ketika pengindeksan ulang selesai, plugin dimatikan dan alias dibalik ke indeks baru. Kemudian, tindakan yang direkam direproduksi pada indeks penerima, mengejar statusnya. Meskipun kecepatan tinggi pengindeksan kembali, dua jenis tabrakan dapat terjadi selama pemutaran:
- tidak ada lagi dokumen dengan _id tersebut di indeks baru. Mereka berhasil menghapus dokumen setelah beralih alias ke indeks baru.
- di indeks baru ada dokumen dengan _id tersebut , tetapi dengan nomor versi lebih tinggi daripada di indeks sumber. Mereka berhasil memperbarui dokumen setelah beralih alias ke indeks baru.
Dalam kasus ini, tindakan tidak boleh direproduksi dalam indeks tujuan. Perubahan lainnya direproduksi.
Selamat coding!