 Ini adalah kisah nyata. Peristiwa yang dijelaskan dalam pos terjadi di satu negara hangat di abad ke-21. Untuk jaga-jaga, nama-nama karakter telah diubah. Karena menghormati profesi, semuanya diceritakan sebagaimana adanya.
Ini adalah kisah nyata. Peristiwa yang dijelaskan dalam pos terjadi di satu negara hangat di abad ke-21. Untuk jaga-jaga, nama-nama karakter telah diubah. Karena menghormati profesi, semuanya diceritakan sebagaimana adanya.
Hai, Habr. Dalam posting ini kita akan berbicara tentang pengujian A / B yang terkenal, sayangnya, bahkan di abad ke-21, itu tidak dapat dihindari. Opsi pengujian alternatif telah ada dan berkembang online untuk waktu yang lama, sementara yang offline harus beradaptasi sesuai dengan situasi. Kami akan berbicara tentang satu adaptasi semacam itu dalam ritel massal offline, membumbui pengalaman bekerja dengan satu kantor konsultan terkemuka, secara umum, di bawah kucing.
Tantangan
 Di masa lalu, saya bekerja pada satu proyek di sebuah perusahaan besar yang memiliki jaringan toko kelontong, lebih dari 500 toko. Saya takut bahwa saya tidak boleh menyebut nama perusahaan, kami akan menyebut organisasi ini Perusahaan. Intinya adalah bahwa toko memiliki ukuran yang berbeda, dapat bervariasi dalam ukuran puluhan kali; toko dapat berada di berbagai kota, desa dan desa; toko-toko dapat berada di berbagai wilayah kota dengan demografi mereka sendiri. Di sini, secara umum, saya cenderung pada fakta bahwa jika Anda perlu menguji hipotesis apa pun, maka dalam paradigma pengujian A / B hampir tidak mungkin untuk melakukan ini tanpa menyebabkan kerusakan signifikan pada bisnis. Mari kita perhatikan semua ini dengan contoh bir. Begitu Kantor Konsultasi mendatangi Perusahaan, Anda tahu, ini dari atas dan berkata: "Tapi Anda tahu, sayang, Anda punya bir di sini yang bukan merek yang tepat di jendela, dan umumnya tidak sesuai urutan yang Anda butuhkan, kirimkan kepada kami beberapa emas Kamaz dan kami akan memberi tahu Anda merek mana yang Anda butuhkan dan cara melipatnya, menurut perkiraan kami, ini akan memberi Anda satu miliar dolar Kanada pada tahun pertama setelah pilot. " Kantor dihormati, jadi tidak ada keraguan tentang satu miliar. Juga, metode Kantor tidak dapat dipertanyakan, karena mereka tidak bisa berbohong. Bukan kita saja. Secara umum, penulis baris ini turun dengan tugas dari bentuk "well, lihat di sana bagaimana mereka melakukan uji coba, bantu jika mereka membutuhkan sesuatu."
Di masa lalu, saya bekerja pada satu proyek di sebuah perusahaan besar yang memiliki jaringan toko kelontong, lebih dari 500 toko. Saya takut bahwa saya tidak boleh menyebut nama perusahaan, kami akan menyebut organisasi ini Perusahaan. Intinya adalah bahwa toko memiliki ukuran yang berbeda, dapat bervariasi dalam ukuran puluhan kali; toko dapat berada di berbagai kota, desa dan desa; toko-toko dapat berada di berbagai wilayah kota dengan demografi mereka sendiri. Di sini, secara umum, saya cenderung pada fakta bahwa jika Anda perlu menguji hipotesis apa pun, maka dalam paradigma pengujian A / B hampir tidak mungkin untuk melakukan ini tanpa menyebabkan kerusakan signifikan pada bisnis. Mari kita perhatikan semua ini dengan contoh bir. Begitu Kantor Konsultasi mendatangi Perusahaan, Anda tahu, ini dari atas dan berkata: "Tapi Anda tahu, sayang, Anda punya bir di sini yang bukan merek yang tepat di jendela, dan umumnya tidak sesuai urutan yang Anda butuhkan, kirimkan kepada kami beberapa emas Kamaz dan kami akan memberi tahu Anda merek mana yang Anda butuhkan dan cara melipatnya, menurut perkiraan kami, ini akan memberi Anda satu miliar dolar Kanada pada tahun pertama setelah pilot. " Kantor dihormati, jadi tidak ada keraguan tentang satu miliar. Juga, metode Kantor tidak dapat dipertanyakan, karena mereka tidak bisa berbohong. Bukan kita saja. Secara umum, penulis baris ini turun dengan tugas dari bentuk "well, lihat di sana bagaimana mereka melakukan uji coba, bantu jika mereka membutuhkan sesuatu."
Setelah mendengarkan ceramah singkat tentang bagaimana metodologi mereka untuk menghasilkan tampilan barang pada jendela tampilan bekerja, keinginan untuk masuk ke rincian algoritma sepenuhnya hilang. Saya memutuskan untuk berkonsentrasi pada pengukuran kualitas, yang jauh lebih menarik dari sudut pandang teori. Hal ini juga memungkinkan Perusahaan untuk tidak berinvestasi dalam proyek yang sengaja tidak menguntungkan. Memiliki akses ke alam semesta paralel, akan mungkin untuk melakukan tes A / B, di mana di alam semesta A semuanya berjalan seperti sebelumnya, dan di alam semesta B tata letak barang telah berubah. Pengujian A / B adalah jenis percobaan terkontrol di mana pengguna dibagi secara acak ke dalam kelompok kontrol dan kelompok uji. Intervensi dilakukan pada kelompok uji, ia menunggu selama waktu tertentu, efek dari intervensi tersebut terhadap indikator target diukur, dan akhirnya indikator kedua kelompok tersebut dibandingkan. Akan diinginkan untuk meminimalkan bias antara kelompok kontrol dan kelompok uji relatif satu sama lain. Misalnya, sehingga tidak ada yang namanya di kelompok A hanya ada kota, dan di kelompok B hanya desa. Dengan situs, sepertinya masalah offset mudah dipecahkan: tunjukkan pengguna dengan ID genap satu versi, dan ID aneh versi lain situs. Dalam situasi dengan rantai toko, semuanya tidak begitu sederhana, tidak peduli bagaimana Anda memecah pengguna atau toko, selalu ternyata bahwa grup A dan B tidak sama. Kelompok A itu datang ke toko di siang hari, dan B di malam hari. Menyelaraskan waktu, ternyata A datang pada akhir pekan lebih sering daripada B. Menyelaraskan semua rincian seperti itu, ternyata untuk hasil yang signifikan secara statistik, Anda harus menunggu setengah tahun dan membatalkan semua perusahaan pemasaran. Jika Anda pergi ke kota, ternyata Moskow hadir dalam satu kelompok dan tidak ada di kelompok lain. Secara umum, selalu ada pergeseran dalam satu kelompok relatif terhadap yang lain. Berbagai kampanye pemasaran global dan lokal, liburan dan keadaan tak terduga dalam bentuk perbaikan parkir ditumpangkan pada ini.
Anda ingat bahwa Office berasal dari kantor-kantor top dunia, dan tentu saja ia memiliki solusi untuk masalah pengujian. Pertimbangkan metodologi mereka, dengan nama pemasaran yang keras - metodologi triple difference.
Metodologi Perbedaan Tiga
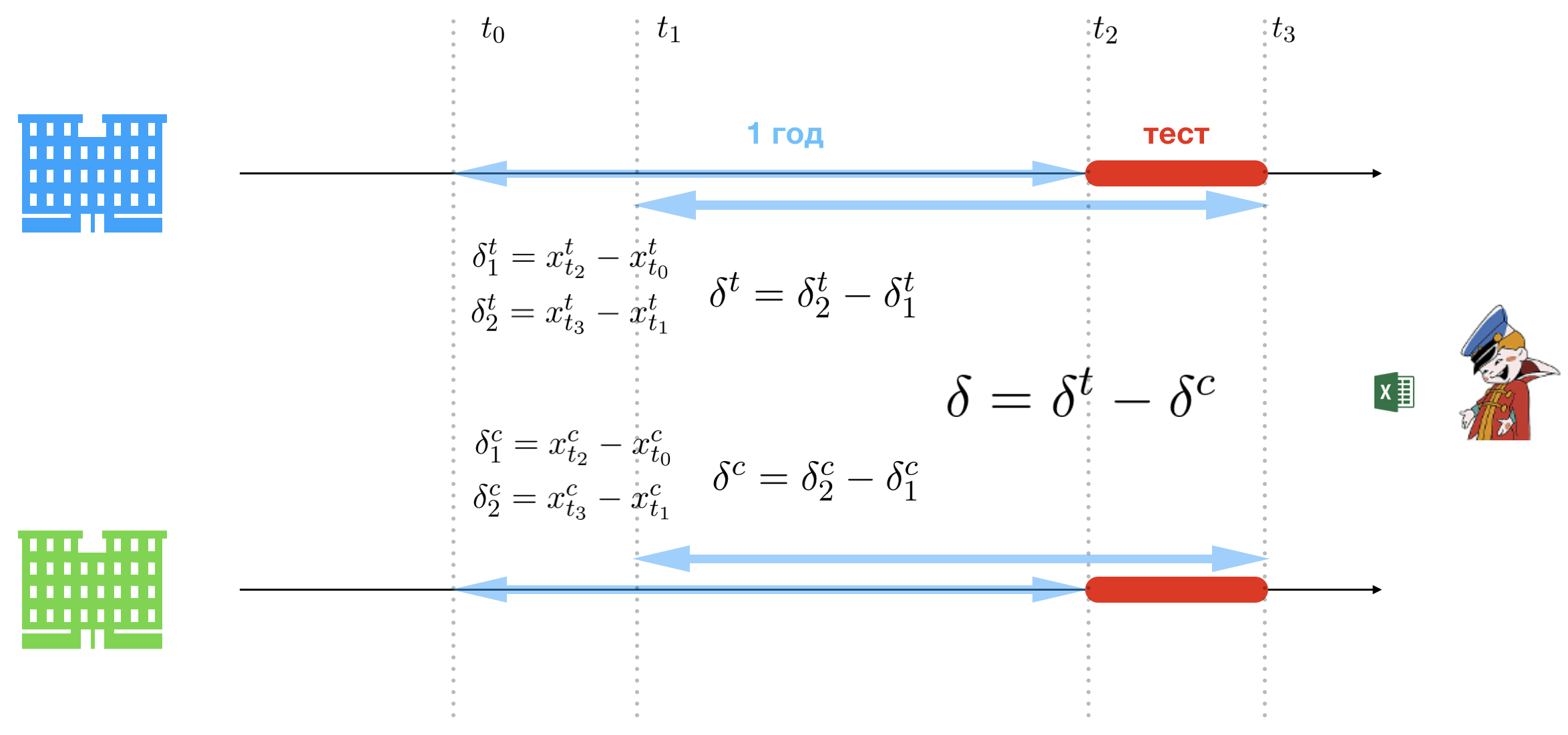
Inti dari metodologi perbedaan tiga adalah kesederhanaan. Dan agar puncak Perusahaan tidak tegang ketika mendengarkan presentasi, presentasi ini akan dilakukan oleh seorang wanita yang penampilannya tidak buruk. Kesederhanaan dicapai dengan mengendurkan keterbatasan tes A / B. Satu-satunya kesulitan yang tetap ada di jalur Office adalah pilihan kelompok kontrol dan uji, tetapi kami akan menghilangkan bagian dari proses ini, karena tidak ada yang menarik kecuali sejumlah besar asumsi yang meragukan. Jadi, sebagai hasil dari analisis menyeluruh dari rantai toko yang ada, Kantor memilih dua: satu untuk kelompok kontrol (hijau) dan satu untuk kelompok uji (biru).
Kami memperkenalkan notasi berikut:
- : tanggal mulai pilot;
- : tanggal akhir pilot;
- : tanggal yang sesuai dengan tanggal pilot dimulai tahun lalu;
- : tanggal yang sesuai dengan tahun terakhir pilot.
Jadi, kita memiliki dua periode waktu:
- : periode pilot (periode percobaan);
- : periode yang sesuai dengan periode pilot tahun lalu.
Diusulkan untuk membandingkan pendapatan dari toko tes dan periode kontrol untuk periode pilot dan setahun yang lalu. Untuk melakukan ini, Anda perlu menghitung tiga kelompok perbedaan. Nyatakan penjualan per hari di toko tes untuk , dan - di kontrol. Kelompok pertama menetapkan dasar dari mana pertumbuhan penjualan atau penurunan dalam periode percontohan akan diukur:
- : perbedaan penjualan antara awal pilot dan tanggal yang sama setahun yang lalu di test store;
- : perbedaan penjualan antara akhir pilot dan tanggal yang sama setahun yang lalu di test store;
- : perbedaan penjualan antara awal pilot dan tanggal yang sama setahun yang lalu di control store;
- : perbedaan penjualan antara akhir pilot dan tanggal yang sama setahun yang lalu di control store.
Kelompok perbedaan kedua menentukan pertumbuhan atau penurunan penjualan dalam periode percontohan:
- : perbedaan penjualan antara akhir pilot dan awal pilot di test store (disesuaikan dengan tanggal setahun yang lalu);
- : perbedaan penjualan antara akhir pilot dan awal pilot di control store (disesuaikan dengan tanggal setahun yang lalu).
Dan akhirnya, perbedaan yang menentukan menentukan toko mana yang bekerja lebih baik pada periode uji coba:
Nah, keputusan untuk mengimplementasikan proyek dengan biaya emas KAMAZ sangat sederhana jika - itu berarti toko tes menjual lebih banyak bir, oleh karena itu metodologi Office berfungsi dan memberikan efek positif, oleh karena itu perlu diperkenalkan. Itu saja.
Tes A / B dengan garis dasar ML
Setelah mempelajari metodologi perbedaan tiga dan mengetahui bahwa pihak berwenang telah menyetujui metode pengukuran ini dan pilot mulai merencanakan, tangan saya dengan sakit memukul wajah saya. Ternyata kantor itu menawarkan kita untuk menginvestasikan emas KAMAZ dalam proyek itu, walaupun metodologinya tidak berhasil, dan perbedaan dalam penjualan adalah 1 rubel, secara kebetulan. Sangat mendesak untuk mengembangkan sesuatu yang setidaknya akan memberi sedikit kepercayaan pada efektivitas cara baru meletakkan bir di rak. Seperti yang Anda ingat, salah satu cara untuk melakukan uji A / B yang jujur secara offline adalah keberadaan alam semesta paralel, maka dalam satu kita dapat memperkenalkan metodologi perhitungan bir, di kedua kita meninggalkan semuanya apa adanya, tunggu sebentar dan bandingkan hasilnya. Tetapi bagaimana jika kita mensimulasikan alam semesta paralel dengan pembelajaran mesin?

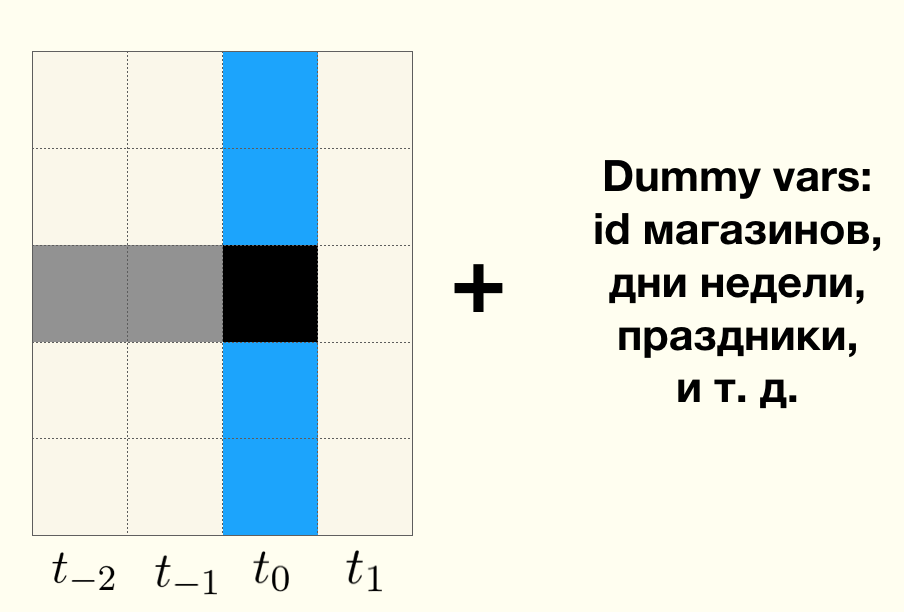
Misalkan kita memiliki serangkaian waktu penjualan harian untuk setiap toko. Garis abu-abu membagi periode
sebelum pilot dan
setelah pilot . Area antara garis abu-abu solid dan garis abu-abu putus-putus adalah periode pembeli beradaptasi dengan bauran produk baru dan merek baru, selama periode ini, data penjualan tidak mempengaruhi hasil pengujian dan diabaikan begitu saja. Merah solid adalah penjualan nyata toko mana pun di periode sebelum pilot. Di sisi kanan adalah kombinasi dari toko tes dan kontrol. Garis putus-putus hijau adalah perkiraan untuk penjualan toko mana pun, hanya menggunakan data yang tersedia pada periode sebelum pilot dimulai.
- Garis merah adalah penjualan nyata dari toko kontrol pada periode setelah peluncuran pilot. Untuk toko dari kelompok kontrol, pada periode setelah uji coba dimulai, kami hanya mengamati perkiraan penjualan (intermiten hijau) dan penjualan riil (intermiten merah).
- Biru pekat adalah penjualan nyata toko dari kelompok uji pada periode setelah peluncuran pilot. Di toko tes, kami hanya mengamati perkiraan penjualan (hijau terputus-putus) dan penjualan nyata (biru pekat).
Garis putus-putus hijau adalah garis dasar pada pembelajaran mesin.
Jika pilot berhasil, mis. Karena intervensi pengujian dalam bentuk bermacam-macam yang diperbarui dan tata letak baru memiliki efek positif pada penjualan harian, penjualan riil di toko-toko tes (biru solid) akan lebih tinggi rata - rata daripada penjualan nyata di toko-toko kontrol (intermiten merah).
Mari kita lihat apa artinya secara rata-rata. Untuk ini kita harus membuat satu asumsi, kita mengasumsikan bahwa kesalahan perkiraan model memiliki distribusi normal:
 Mari kita tambahkan satu asumsi lagi, katakanlah penjualan dalam kategori yang kita minati hari ini secara linear bergantung pada penjualan dalam kategori terkait hari ini dan penjualan dalam kategori yang kita minati kemarin dan di masa lalu, dan Anda juga dapat mengaitkan berbagai metadata toko dengan ini untuk memperhitungkan bias akun dalam demografi dan atribut lainnya.
Mari kita tambahkan satu asumsi lagi, katakanlah penjualan dalam kategori yang kita minati hari ini secara linear bergantung pada penjualan dalam kategori terkait hari ini dan penjualan dalam kategori yang kita minati kemarin dan di masa lalu, dan Anda juga dapat mengaitkan berbagai metadata toko dengan ini untuk memperhitungkan bias akun dalam demografi dan atribut lainnya.
Ternyata menjadi model yang sangat akrab . Perlu dicatat bahwa pilihan model tidak terlalu signifikan di sini, penting bahwa kesalahan memiliki distribusi normal, atau yang diketahui lainnya, untuk melakukan tes statistik untuk kesetaraan nilai rata-rata. Dengan pernyataan masalah seperti itu, seseorang selalu dapat melakukan uji normalitas pada tahap pembangunan model, dan pada hampir semua model distribusi akan normal, menurut versi tes norma , itu diperiksa.
Jadi, sebagai model prediktif, saya menggunakan regresi linier, meskipun ini bukan persyaratan wajib, dan saya dibimbing oleh kesederhanaan model dan interpretabilitas. Perlu dicatat bahwa model ini prediktif, tetapi saya akan menyebutnya penjelasan. Karena kami tidak memprediksi masa depan, tetapi gunakan penjualan dari kategori terkait pada hari yang sama, yang pada dasarnya adalah datalik. Sebaliknya, kami mencoba menjelaskan penjualan bir hari ini dengan penjualan di toko secara keseluruhan. Ini menciptakan masalah baru bagi kita - perlu memilih dengan cermat fitur yang digunakan dalam model. Fitur yang terkait dengan kategori produk terkait dapat dibagi menjadi tiga kelompok:
- sekelompok barang yang menarik bagi kami (bir ringan, bir hitam, nol bir, kvass, bahkan mungkin paus kuning), beberapa dari tanda-tanda ini membentuk variabel target, dan beberapa di antaranya sama sekali dikeluarkan dari model;
- kelompok barang yang agaknya berkorelasi dengan kelompok sasaran, misalnya, kisah akordeon bahwa penjualan popok dan bir memiliki koefisien korelasi positif yang tinggi;
- kelompok produk, yang tentu saja tidak memiliki korelasi yang signifikan dengan kelompok sasaran, ini merupakan metode regularisasi bahkan sebelum model dibangun, dan akan ada godaan besar untuk menambahkan semuanya ke kelompok kedua, untuk berjaga-jaga.
Sebagai variabel penjelas, kami menambahkan karakteristik dari kelompok kedua ke model. Idenya adalah bahwa kita mengasumsikan bahwa perubahan penjualan pada kelompok kedua secara keseluruhan memiliki efek signifikan pada yang pertama, dan perubahan dalam penjualan pada kelompok pertama tidak memiliki efek khusus pada yang kedua secara keseluruhan (yang kedua jauh lebih besar dan lebih bervariasi).
Pertanyaan yang populer selama presentasi metode ini adalah: bagaimana jika di toko tes / kontrol ada perbaikan parkir, tes akan rusak? Jawabannya adalah tidak. Parkir akan memengaruhi penjualan toko secara keseluruhan, dan tidak khusus bir, dan penjualan bir di negara kita bergantung pada penjualan dalam kategori lain dan, karenanya, akan dihabiskan bersama dengan semua orang. Anda dapat dengan meyakinkan melakukan beberapa simulasi pada retrodat.
Perlu juga dicatat bahwa kami tidak menguji perhitungan dengan Metode A terhadap perhitungan dengan Metode B, tetapi kami menguji perilaku baru terhadap yang lama . Ini berarti bahwa toko dan grup secara keseluruhan tidak boleh membatalkan kampanye pemasaran terencana yang sebelumnya digunakan. Misalnya, jika Anda telah mengurangi harga bir kuat sebanyak 2 kali dalam 6 bulan terakhir, bahkan dalam minggu-minggu, terus lakukan ini, jika Anda berhenti melakukan ini, perilaku akan berbeda. Jangan hanya melakukan eksperimen baru di toko tertentu.
Tahap membangun model juga tidak bisa dilakukan tanpa jebakan. Kelompok uji dan kontrol dapat mencakup toko yang sama sekali berbeda, dan tugas model kami adalah menyelaraskan semua toko, sehingga untuk toko mana pun, kesalahan perkiraan acak dipusatkan pada nol (atau sama-sama mengimbangi dari nol). Pada awalnya, saya berharap bahwa saya harus memilah semua jenis hiperparameter pada validasi sampai hasil yang diinginkan diperoleh. Tetapi ternyata dengan serangkaian fitur yang cukup, ini dicapai pertama kali, yang menarik, dan varians kesalahan acak juga tidak berbeda jauh dari toko ke toko. Ini mungkin salah satu kelemahan dari metode ini, karena tidak ada jaminan bahwa kondisi seperti itu akan dipenuhi.  Sebuah tinjauan literatur juga tidak memberikan hasil, sepertinya banyak orang menggunakan garis dasar pada pembelajaran mesin, tetapi tidak ada apa pun tentang jaminan teoritis. Secara umum, setelah semua penipuan tersebut, kami mendapatkan model yang dilatih tentang semua data secara keseluruhan , dan kami dapat membuat perkiraan penjualan harian untuk toko mana pun yang dipilih . Dan kami tidak terlalu khawatir tentang keakuratan, tetapi hanya jika distribusi kesalahan untuk semua toko sama-sama bias (tentu saja lebih menyenangkan, jika tidak bias relatif terhadap nol). Dan fakta bahwa varians bisa besar, ini hanya akan mempengaruhi ukuran dataset yang diperlukan untuk signifikansi statistik dari hasil tes (artinya bahwa untuk diberi signifikansi statistik apriori dan kekuatan statistik tes, jumlah pengamatan. Diperlukan untuk mendapatkan hasil seperti itu tergantung pada varians )
Sebuah tinjauan literatur juga tidak memberikan hasil, sepertinya banyak orang menggunakan garis dasar pada pembelajaran mesin, tetapi tidak ada apa pun tentang jaminan teoritis. Secara umum, setelah semua penipuan tersebut, kami mendapatkan model yang dilatih tentang semua data secara keseluruhan , dan kami dapat membuat perkiraan penjualan harian untuk toko mana pun yang dipilih . Dan kami tidak terlalu khawatir tentang keakuratan, tetapi hanya jika distribusi kesalahan untuk semua toko sama-sama bias (tentu saja lebih menyenangkan, jika tidak bias relatif terhadap nol). Dan fakta bahwa varians bisa besar, ini hanya akan mempengaruhi ukuran dataset yang diperlukan untuk signifikansi statistik dari hasil tes (artinya bahwa untuk diberi signifikansi statistik apriori dan kekuatan statistik tes, jumlah pengamatan. Diperlukan untuk mendapatkan hasil seperti itu tergantung pada varians )
Mari kita kembali ke bagan di atas dengan garis merah, hijau dan biru, dan akhirnya memperkenalkan konsep rata-rata lebih tinggi atau lebih rendah. Untuk toko kontrol, kita dapat mengurangi dari penjualan harian aktual (garis putus-putus merah) penjualan harian yang diprediksi oleh model (garis putus-putus hijau). Akibatnya, kami mendapatkan distribusi kesalahan normal yang berpusat pada nol, sehingga tidak ada yang berubah di dalamnya dan model rata-rata akan bertepatan dengan kenyataan. Untuk toko dari kelompok uji, kami juga mengurangi dari penjualan harian nyata (garis solid biru), penjualan model penjualan harian (berselang hijau), dan kami juga mendapatkan distribusi normal. Maka jika tidak ada yang berubah, maka pusat akan berada di suatu tempat di sekitar nol; jika penjualan meningkat, maka akan bergeser ke kanan, jika memburuk, lalu ke kiri. Ini adalah tampilannya pada data yang disimulasikan.

Dan di sini kita menemukan diri kita dalam kondisi uji statistik biasa untuk persamaan rata-rata dua distribusi, dan tidak ada yang menghalangi kita untuk melakukan tes ini. Untuk tes stat kita perlu mengetahui hal berikut:
- dan : pilih sendiri, atau jika Anda beruntung dan orang-orang terpelajar duduk dalam pemasaran, maka kami memilih bersama mereka;
- dispersi: diambil dari retrodat;
- lift: diperlukan untuk menguji tidak hanya kesetaraan, tetapi bahwa pertumbuhan penjualan dalam kelompok uji tidak kurang dari sejumlah dolar Kanada bersyarat; kami tidak ingin mengimplementasikan proyek yang bernilai emas kamaz, tetapi agar hemat biaya dan tidak membayar sendiri dalam seratus tahun, kami tidak membangun jembatan ke Krimea.
Data ini akan cukup untuk menghitung jumlah hari yang diperlukan untuk pilot. Bonus lain untuk pendekatan ini adalah skalabilitas. Dalam kasus kami, tes memberi 60 hari, mis. kami membutuhkan 60 hari pengamatan untuk tes dan 60 hari pengamatan untuk kelompok kontrol untuk mendapatkan hasil tes yang signifikan secara statistik. Kita dapat memilih satu toko di masing-masing kelompok dan menunggu 2 bulan, atau dua di setiap kelompok dan menunggu 1 bulan, dan seterusnya. Secara alami, anggaran percobaan tergantung pada penambahan toko baru ke grup uji, tetapi ini adalah tugas Anda bagaimana memilih keseimbangan seperti itu. Saya sarankan Anda mempelajari materi ini untuk memahami metodologi untuk menghitung jumlah pengamatan yang diperlukan.
Data nyata
Pertimbangkan dua gambar dengan penjualan nyata, model ini dilatih pada beberapa tahun penjualan retro. Toko nomor satu:
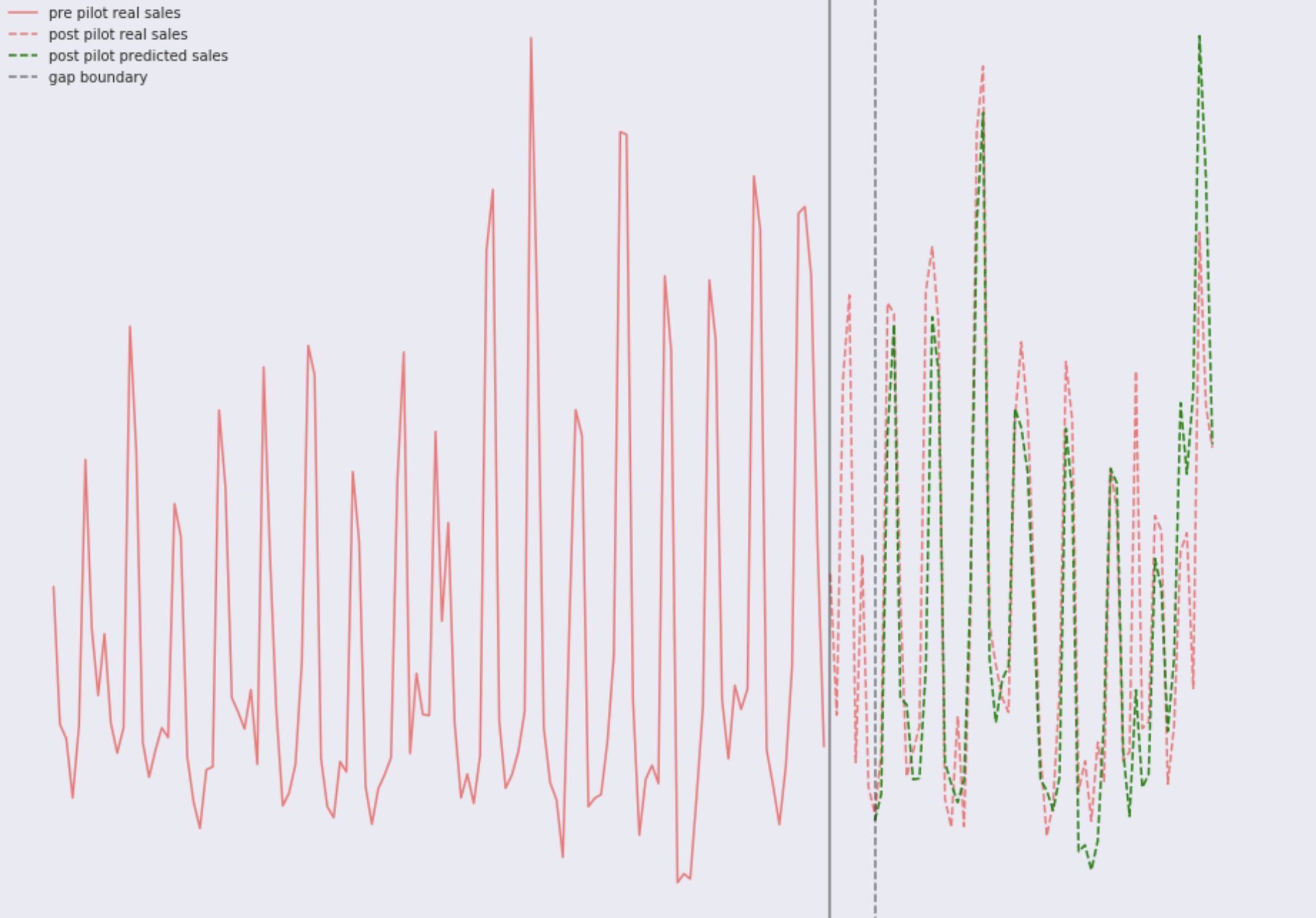
Dan toko nomor dua:

Seperti yang Anda lihat
, semuanya sangat baik
di mata . Anda akan dengan mudah melihat pola mingguan, serta sesuatu yang jelas terjadi baru-baru ini di salah satu toko, dinamika telah berubah. Jika Anda melihat lebih dekat, Anda dapat melihat bahwa model di kedua toko beberapa kali membuat kesalahan yang signifikan. Dalam hal ini, ada dua opsi:
:
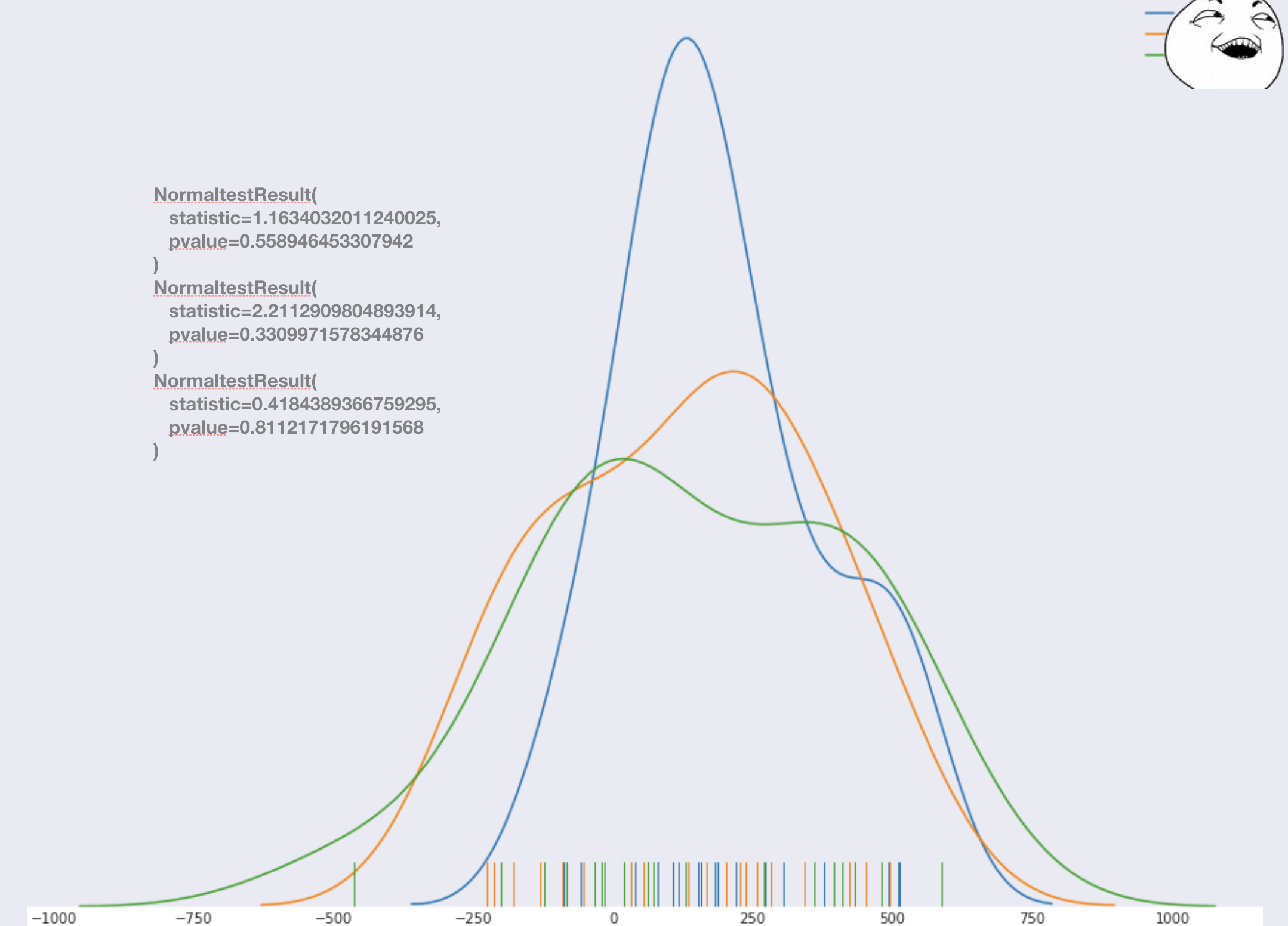 Itu terlihat baik . Untuk persuasif, Anda dapat melakukan tes untuk normalitas, dan memastikan semuanya baik - baik saja . Jika beberapa tes menghasilkan hasil yang tidak normal, maka skorkan atau putar kembali ke titik pemilihan fitur. Dalam hal ini, kami tidak perlu memulai ulang pilot, tetapi hanya membangun kembali model dan menghitung kembali jumlahnya (jadi sebelumnya Anda mungkin berpikir untuk memasukkan lebih banyak hari pilot dalam periode pengujian daripada versi pertama dari model yang diberikan). Dalam kasus kami, semuanya seperti yang seharusnya.
Itu terlihat baik . Untuk persuasif, Anda dapat melakukan tes untuk normalitas, dan memastikan semuanya baik - baik saja . Jika beberapa tes menghasilkan hasil yang tidak normal, maka skorkan atau putar kembali ke titik pemilihan fitur. Dalam hal ini, kami tidak perlu memulai ulang pilot, tetapi hanya membangun kembali model dan menghitung kembali jumlahnya (jadi sebelumnya Anda mungkin berpikir untuk memasukkan lebih banyak hari pilot dalam periode pengujian daripada versi pertama dari model yang diberikan). Dalam kasus kami, semuanya seperti yang seharusnya.Selanjutnya, kami menggabungkan semua toko dari kelompok uji dalam satu kelompok dan semua toko kontrol dalam satu kelompok, sehingga kami dapat melakukannya, jadi kami berasumsi di atas bahwa kesalahan model sama-sama bias untuk setiap toko. Kami mendapatkan dua distribusi dan melakukan uji stat.
 Seperti yang mungkin sudah Anda duga, menurut skeptisisme saya di awal, metodologi unik baru untuk tampilan produk dan pemilihan merek tidak memiliki pengaruh signifikan secara statistik terhadap penjualan. Itu, pada prinsipnya, sudah diharapkan, karena saya melihat metodologi untuk memilih merek baru dan cara mereka ditampilkan. Saya khawatir bahwa saya tidak dapat berbicara tentang teknik-teknik unik ini, tetapi salah satu fotografer yang pergi ke pesaing untuk mengambil gambar etalase toko dengan bir yang diterima ... dikeluarkan dari tempat itu dengan kasar.
Seperti yang mungkin sudah Anda duga, menurut skeptisisme saya di awal, metodologi unik baru untuk tampilan produk dan pemilihan merek tidak memiliki pengaruh signifikan secara statistik terhadap penjualan. Itu, pada prinsipnya, sudah diharapkan, karena saya melihat metodologi untuk memilih merek baru dan cara mereka ditampilkan. Saya khawatir bahwa saya tidak dapat berbicara tentang teknik-teknik unik ini, tetapi salah satu fotografer yang pergi ke pesaing untuk mengambil gambar etalase toko dengan bir yang diterima ... dikeluarkan dari tempat itu dengan kasar.Kesimpulan
Sebuah pertanyaan yang masuk akal mungkin muncul - mengapa, secara umum, kelompok kontrol? Kami hanya membutuhkannya untuk memperhitungkan beberapa perubahan global, karena pilot dapat bertahan 1-2 bulan. Metode ini dapat dimodifikasi untuk menguji promosi yang berlangsung seminggu, misalnya, menjual sosis. Jika kami percaya bahwa kemungkinan tidak ada perubahan global dalam seminggu, maka kelompok uji diuji terhadap model, yang bertindak sebagai kontrol, dan uji statistik dilakukan untuk menyamai nilai distribusi rata-rata menjadi nol. Kami menggambarkan ini sebagai berikut:
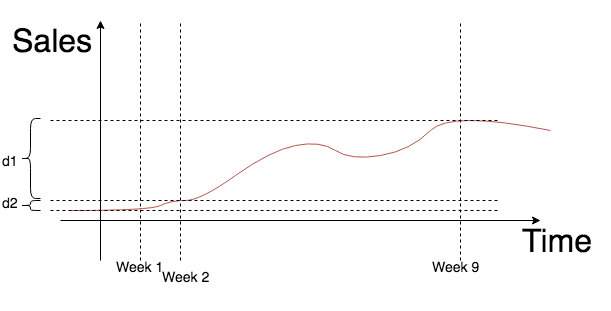
- waktu pada sumbu absis dan penjualan pada sumbu ordinat;
- , ;
- .
, - , . , , , , . , , , , .
Tetapi apa yang terjadi pada pilot? Dan semuanya baik-baik saja, itu datang dan berkembang, mereka menunggu satu miliar dengan imbalan emas yang diberikan kepada Kamaz. Salah satu tugas terakhir pada proyek itu hanyalah penerapan metodologi untuk menguji promosi, tetapi ketika saya meninggalkan proyek, Kantor yang dihormati dengan cepat mengembalikan tes untuk kemiripan tiga perbedaan. Mungkin nasib yang sama menimpa tes ini, tapi aku tidak tahu.
Ngomong-ngomong, sekarang sedang berhasil diimplementasikan di ritel lain, bermacam-macam optimasi sedang diuji, diusulkan oleh kantor konsultan lain, tetapi bukan Kantor ini. Hasilnya memenuhi harapan klien dan kantor, dan klien berencana untuk memperkenalkan optimasi bermacam-macam baru berdasarkan hasil tes tersebut.