Dalam artikel ini kita akan berbicara tentang penggunaan jaringan saraf convolutional untuk menyelesaikan tugas bisnis praktis mengembalikan realogram dari foto-foto rak dengan barang. Menggunakan Tensorflow Object Detection API, kami akan melatih model pencarian / pelokalan. Kami akan meningkatkan kualitas pencarian produk kecil dalam foto resolusi tinggi menggunakan jendela mengambang dan algoritma penindasan yang tidak maksimal. Di Keras, kami menerapkan klasifikasi barang berdasarkan merek. Secara paralel, kami akan membandingkan pendekatan dan hasil dengan keputusan 4 tahun yang lalu. Semua data yang digunakan dalam artikel tersedia untuk diunduh, dan kode yang berfungsi penuh ada di
GitHub dan dirancang sebagai tutorial.

Pendahuluan
Apa itu planogram? Diagram tata letak tampilan barang pada peralatan perdagangan beton toko.
Apa itu realogram? Tata letak barang pada peralatan perdagangan tertentu yang ada di toko di sini dan sekarang.
Planogram - sebagaimana mestinya, realogram - apa yang kita miliki.

Sampai sekarang, di banyak toko, mengelola sisa barang di rak, rak, konter, rak adalah pekerjaan manual. Ribuan karyawan memeriksa ketersediaan produk secara manual, menghitung saldo, memeriksa lokasi dengan persyaratan. Itu mahal, dan kesalahan sangat mungkin terjadi. Tampilan yang salah atau kurangnya barang menyebabkan penjualan lebih rendah.
Juga, banyak produsen mengadakan perjanjian dengan pengecer untuk memajang barang-barang mereka. Dan karena ada banyak produsen, di antara mereka perjuangan untuk tempat terbaik di rak dimulai. Semua orang ingin produknya terletak di tengah di seberang mata pembeli dan menempati area seluas mungkin. Ada kebutuhan untuk audit berkelanjutan.
Ribuan pedagang bergerak dari satu toko ke toko untuk memastikan bahwa produk perusahaan mereka ada di rak dan disajikan sesuai dengan kontrak. Terkadang mereka malas: jauh lebih menyenangkan untuk menyusun laporan tanpa meninggalkan rumah Anda daripada pergi ke outlet ritel. Ada kebutuhan untuk audit permanen terhadap auditor.
Secara alami, tugas otomatisasi dan penyederhanaan proses ini telah dipecahkan sejak lama. Salah satu bagian tersulit adalah pemrosesan gambar: menemukan dan mengenali produk. Dan hanya relatif baru-baru ini tugas ini telah disederhanakan sehingga untuk kasus tertentu dalam bentuk yang disederhanakan, solusi lengkapnya dapat dijelaskan dalam satu artikel. Ini yang akan kita lakukan.
Artikel berisi kode minimal (hanya untuk kasus-kasus ketika kode lebih jelas daripada teks). Solusi lengkap tersedia sebagai tutorial bergambar di
notebook jupyter . Artikel ini tidak mengandung deskripsi arsitektur jaringan saraf, prinsip-prinsip neuron, rumus matematika. Dalam artikel tersebut, kami menggunakannya sebagai alat teknik, tanpa terlalu banyak membahas detail perangkatnya.
Data dan Pendekatan
Seperti halnya pendekatan berbasis data, solusi jaringan saraf membutuhkan data. Anda juga dapat merakitnya secara manual: untuk menangkap beberapa ratus penghitung dan menandainya menggunakan, misalnya,
LabelImg . Anda dapat memesan markup, misalnya, di Yandex.Tolok.
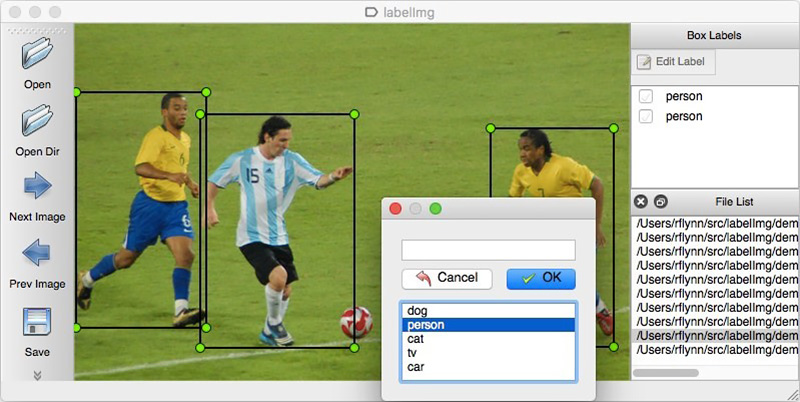
Kami tidak dapat mengungkapkan rincian proyek nyata, oleh karena itu kami akan menjelaskan teknologi pada data terbuka. Berbelanja dan mengambil foto terlalu malas (dan kita tidak akan dipahami di sana), dan keinginan untuk melakukan markup foto yang ditemukan di Internet pada kita sendiri berakhir setelah objek rahasia yang keseratus. Untungnya, kebetulan saya menemukan arsip
Grocery Dataset .
Pada 2014, karyawan Idea Teknoloji, Istanbul, Turki mengunggah 354 foto dari 40 toko yang dibuat di 4 kamera. Pada masing-masing foto ini, mereka menyorot dengan persegi panjang total beberapa ribu objek, beberapa di antaranya diklasifikasikan ke dalam 10 kategori.
Ini adalah gambar bungkus rokok. Kami tidak mempromosikan atau mempromosikan merokok. Tidak ada yang lebih netral. Kami berjanji bahwa di mana saja dalam artikel ini, di mana situasinya memungkinkan, kami akan menggunakan foto-foto kucing.

Selain foto rak yang ditandai, mereka menulis artikel
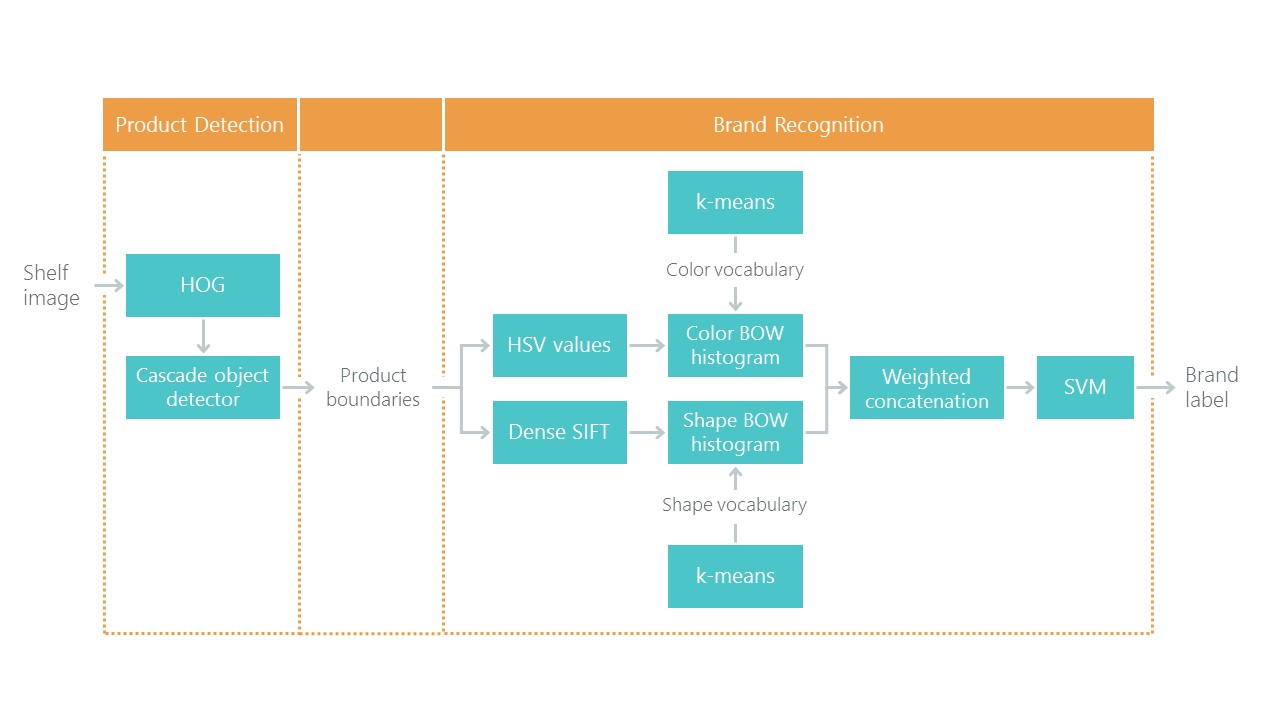
Menuju Pengakuan Produk Eceran di Rak Kelontong dengan solusi untuk masalah lokalisasi dan klasifikasi. Ini menetapkan semacam titik referensi: solusi kami menggunakan pendekatan baru seharusnya menjadi lebih sederhana dan lebih akurat, jika tidak itu tidak menarik. Pendekatan mereka terdiri dari kombinasi algoritma:
Baru-baru ini, jaringan saraf convolutional (CNN) telah merevolusi bidang visi komputer dan benar-benar mengubah pendekatan untuk memecahkan masalah tersebut. Selama beberapa tahun terakhir, teknologi ini telah tersedia untuk berbagai pengembang, dan API tingkat tinggi seperti Keras telah secara signifikan menurunkan ambang entri mereka. Sekarang, hampir semua pengembang dapat menggunakan kekuatan penuh dari jaringan saraf convolutional setelah hanya beberapa hari berkencan. Artikel ini menjelaskan penggunaan teknologi ini menggunakan contoh, menunjukkan bagaimana seluruh kaskade algoritma dapat dengan mudah diganti dengan hanya dua jaringan saraf tanpa kehilangan keakuratan.
Kami akan memecahkan masalah dalam langkah-langkah:
- Persiapan data. Kami memompa arsip dan mengubahnya menjadi tampilan yang nyaman untuk bekerja.
- Klasifikasi merek. Kami memecahkan masalah klasifikasi menggunakan jaringan saraf.
- Cari produk di foto. Kami melatih jaringan saraf untuk mencari barang.
- Implementasi pencarian. Kami akan meningkatkan kualitas deteksi menggunakan jendela mengambang dan algoritma untuk menekan non-maksimum.
- Kesimpulan Jelaskan secara singkat mengapa kehidupan nyata jauh lebih rumit daripada contoh ini.
Teknologi
Teknologi utama yang akan kami gunakan: Tensorflow, Keras, Tensorflow Object Detection API, OpenCV. Meskipun Windows dan Mac OS cocok untuk bekerja dengan Tensorflow, kami tetap merekomendasikan menggunakan Ubuntu. Bahkan jika Anda belum pernah bekerja dengan sistem operasi ini sebelumnya, menggunakannya akan menghemat banyak waktu. Menginstal Tensorflow untuk bekerja dengan GPU adalah topik yang pantas mendapatkan artikel terpisah. Untungnya, artikel seperti itu sudah ada. Misalnya,
Menginstal TensorFlow di Ubuntu 16.04 dengan GPU Nvidia . Beberapa instruksi darinya mungkin sudah ketinggalan zaman.
Langkah 1. Mempersiapkan data ( tautan github )Langkah ini, sebagai suatu peraturan, membutuhkan waktu lebih lama dari simulasi itu sendiri. Untungnya, kami menggunakan data yang sudah jadi, yang kami konversi ke formulir yang kami butuhkan.
Anda dapat mengunduh dan menghapus zip dengan cara ini:
wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part1.tar.gz wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part2.tar.gz tar -xvzf GroceryDataset_part1.tar.gz tar -xvzf GroceryDataset_part2.tar.gz
Kami mendapatkan struktur folder berikut:
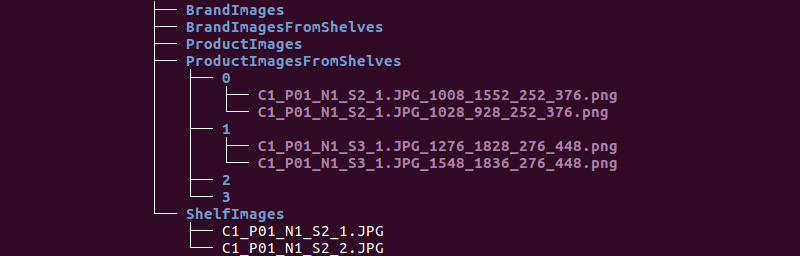
Kami akan menggunakan informasi dari direktori ShelfImages dan ProductImagesFromShelves.
ShelfImages berisi gambar-gambar rak itu sendiri. Dalam namanya, pengidentifikasi rak dengan pengidentifikasi gambar dikodekan. Mungkin ada beberapa gambar satu rak. Misalnya, satu foto secara keseluruhan dan 5 foto di bagian dengan persimpangan.
File C1_P01_N1_S2_2.JPG (rack C1_P01, snapshot N1_S2_2):

Kami menelusuri semua file dan mengumpulkan informasi dalam bingkai data panda photos_df:
ProductImagesFromShelves berisi foto cut-out barang dari rak di 11 subdirektori: 0 - tidak diklasifikasikan, 1 - Marlboro, 2 - Kent, dll. Agar tidak mengiklankannya, kami hanya akan menggunakan nomor kategori tanpa menyebutkan nama. File dalam nama berisi informasi tentang rak, posisi dan ukuran paket di atasnya.
File C1_P01_N1_S3_1.JPG_1276_1828_276_448.png dari direktori 1 (kategori 1, rak C1_P01, gambar N1_S3_1, koordinat sudut kiri atas (1276, 1828), lebar 276, tinggi 448):
Kami tidak membutuhkan foto-foto paket individu sendiri (kami akan memotongnya dari gambar-gambar rak), dan kami mengumpulkan informasi tentang kategori dan posisi mereka dalam bingkai data panda products_df:
Pada langkah yang sama, kami membagi semua informasi kami menjadi dua bagian: melatih untuk pelatihan dan validasi untuk pelatihan pemantauan. Tentu saja, ini tidak layak dilakukan dalam proyek nyata. Dan juga jangan percaya pada mereka yang melakukan ini. Anda setidaknya harus mengalokasikan tes lain untuk ujian akhir. Tetapi bahkan dengan pendekatan yang tidak terlalu jujur ini, penting bagi kita untuk tidak menipu diri sendiri.
Seperti yang telah kita catat, mungkin ada beberapa foto dari satu rak. Dengan demikian, paket yang sama dapat jatuh ke beberapa gambar. Oleh karena itu, kami menyarankan Anda untuk memecah bukan oleh gambar, dan bahkan lebih lagi bukan dengan paket, tetapi oleh rak. Ini diperlukan agar tidak terjadi bahwa objek yang sama, yang diambil dari sudut yang berbeda, berakhir di kereta dan validasi.
Kami membuat pemisahan 70/30 (30% dari rak digunakan untuk validasi, sisanya untuk pelatihan):
Kami akan memastikan bahwa ketika kami berpisah, ada cukup perwakilan dari setiap kelas untuk pelatihan dan validasi:

Warna biru menunjukkan jumlah produk dalam kategori untuk validasi, dan oranye untuk pelatihan. Situasinya tidak terlalu baik dengan kategori 3 untuk validasi, tetapi pada prinsipnya ada beberapa perwakilannya.
Pada tahap persiapan data, penting untuk tidak membuat kesalahan, karena semua pekerjaan lebih lanjut didasarkan pada hasilnya. Kami masih membuat satu kesalahan dan menghabiskan banyak waktu senang mencoba memahami mengapa kualitas model sangat biasa-biasa saja. Sudah merasa seperti pecundang terhadap teknologi "sekolah tua", sampai Anda secara tidak sengaja memperhatikan bahwa beberapa foto asli diputar 90 derajat, dan beberapa dilakukan terbalik.
Pada saat yang sama, markup dibuat seolah-olah foto berorientasi dengan benar. Setelah perbaikan cepat, segalanya menjadi lebih menyenangkan.
Kami akan menyimpan data kami dalam file pkl untuk digunakan dalam langkah-langkah berikut. Total, kami memiliki:
- Direktori foto-foto rak dan bagian-bagiannya dengan bundel,
- Bingkai data dengan deskripsi setiap rak dengan catatan apakah itu dimaksudkan untuk pelatihan,
- Kerangka data dengan informasi tentang semua produk di rak, yang menunjukkan posisi, ukuran, kategori, dan penandaan mereka untuk pelatihan.
Untuk verifikasi, kami menampilkan satu rak sesuai dengan data kami:
 Langkah 2. Klasifikasi berdasarkan merek ( tautan di github )
Langkah 2. Klasifikasi berdasarkan merek ( tautan di github )Klasifikasi gambar adalah tugas utama di bidang visi komputer. Masalahnya adalah “celah semantik”: fotografi hanyalah matriks besar angka [0, 255]. Misalnya, 800x600x3 (3 saluran RGB).

Mengapa tugas ini sulit:

Seperti yang telah kami katakan, penulis data yang kami gunakan mengidentifikasi 10 merek. Ini adalah tugas yang sangat disederhanakan, karena ada lebih banyak merek rokok di rak. Tetapi semua yang tidak termasuk dalam 10 kategori ini dikirim ke 0 - tidak diklasifikasikan:

"
Artikel mereka menawarkan algoritma klasifikasi seperti itu dengan akurasi total 92%:

Apa yang akan kita lakukan:
- Kami akan menyiapkan data untuk pelatihan,
- Kami melatih jaringan saraf convolutional dengan arsitektur ResNet v1,
- Periksa foto untuk validasi.
Kedengarannya “bervolume”, tetapi kami hanya menggunakan contoh Keras '“
Melatih ResNet pada dataset CIFAR10 ” dengan mengambil darinya fungsi membuat ResNet v1.
Untuk memulai proses pelatihan, Anda perlu menyiapkan dua larik: x - foto paket dengan dimensi (jumlah paket, tinggi, lebar, 3) dan y - kategorinya dengan dimensi (jumlah paket, 10). Array y berisi apa yang disebut vektor 1-panas. Jika kategori paket untuk pelatihan memiliki nomor 2 (dari 0 hingga 9), maka ini sesuai dengan vektor [0, 0, 1, 0, 0, 0, 0, 0, 0, 0].
Pertanyaan penting adalah apa yang harus dilakukan dengan lebar dan tinggi, karena semua foto diambil dengan resolusi berbeda dari jarak yang berbeda. Kita perlu memilih beberapa ukuran tetap, yang dapat kita bawa semua gambar paket. Ukuran tetap ini adalah meta-parameter yang menentukan bagaimana jaringan saraf kita akan melatih dan bekerja.
Di satu sisi, saya ingin membuat ukuran ini sebesar mungkin sehingga tidak ada satu detail gambar yang diperhatikan. Di sisi lain, dengan jumlah data pelatihan kami yang sedikit, ini dapat mengarah pada pelatihan ulang cepat: model ini akan bekerja dengan sempurna pada data pelatihan, tetapi buruk pada data validasi. Kami memilih ukuran 120x80, mungkin pada ukuran yang berbeda kami akan mendapatkan hasil yang lebih baik. Fungsi zoom:
Skala dan tampilkan satu paket untuk verifikasi. Nama merek sulit dibaca oleh seseorang, mari kita lihat bagaimana jaringan saraf akan mengatasi tugas klasifikasi:

Setelah menyiapkan sesuai dengan flag yang diperoleh pada langkah sebelumnya, kita memecah array x dan y menjadi x_train / x_validation dan y_train / y_validation, kita mendapatkan:
x_train shape: (1969, 120, 80, 3) y_train shape: (1969, 10) 1969 train samples 775 validation samples
Data disiapkan, kami menyalin fungsi konstruktor jaringan saraf arsitektur ResNet v1 dari contoh Keras:
def resnet_v1(input_shape, depth, num_classes=10): …
Kami membangun model:
model = resnet_v1(input_shape=x_train.shape[1:], depth=depth, num_classes=num_classes) model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=lr_schedule(0)), metrics=['accuracy'])
Kami memiliki kumpulan data yang cukup terbatas. Oleh karena itu, untuk mencegah model melihat foto yang sama setiap kali selama pelatihan, kami menggunakan augmentasi: menggeser gambar secara acak dan memutarnya sedikit. Keras menyediakan serangkaian opsi untuk ini:
Kami memulai proses pelatihan.
Setelah pelatihan dan evaluasi, kami mendapatkan akurasi di wilayah 92%. Anda mungkin mendapatkan akurasi yang berbeda: hanya ada sedikit data, jadi akurasi sangat tergantung pada keberhasilan partisi. Pada partisi ini, kami tidak mendapatkan akurasi secara signifikan lebih tinggi daripada yang ditunjukkan dalam artikel, tetapi kami praktis tidak melakukan apa pun dan menulis sedikit kode. Selain itu, kami dapat dengan mudah menambahkan kategori baru, dan keakuratan seharusnya (secara teori) meningkat secara signifikan jika kami menyiapkan lebih banyak data.
Untuk menarik, bandingkan matriks kebingungan:
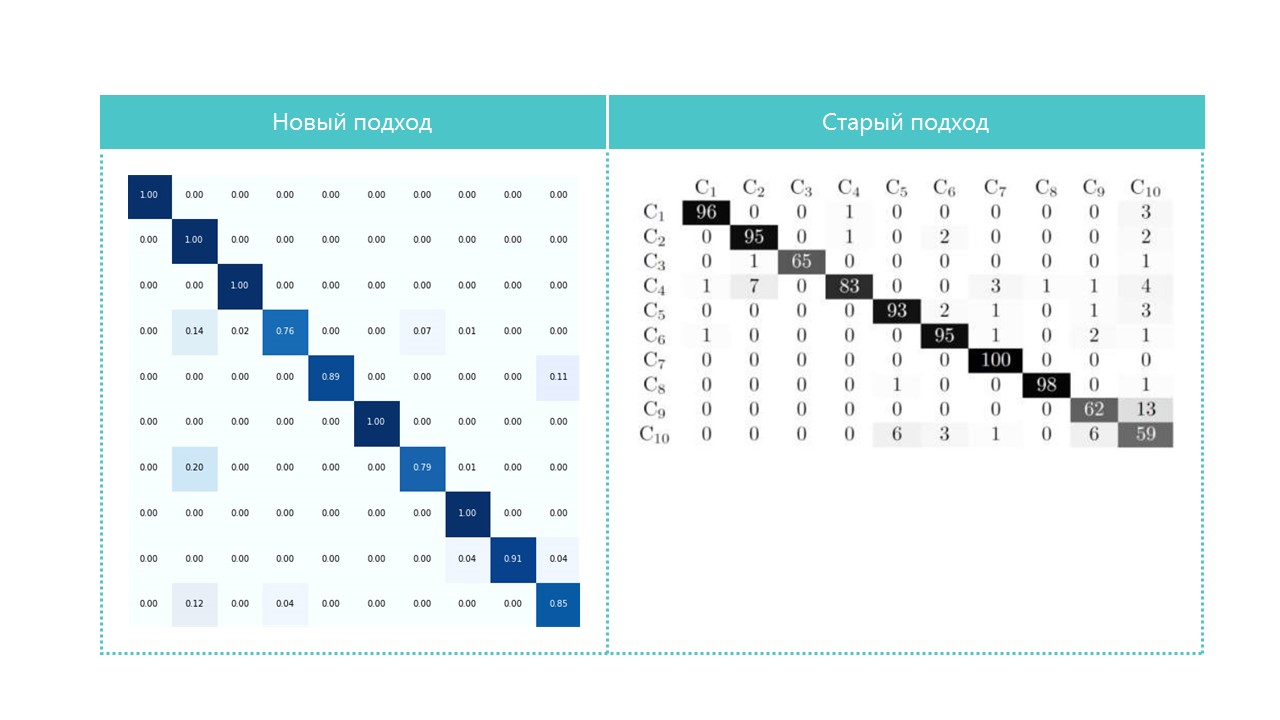
Hampir semua kategori jaringan saraf kita mendefinisikan lebih baik, kecuali untuk kategori 4 dan 7. Juga berguna untuk melihat perwakilan paling terang dari setiap sel matriks kebingungan:
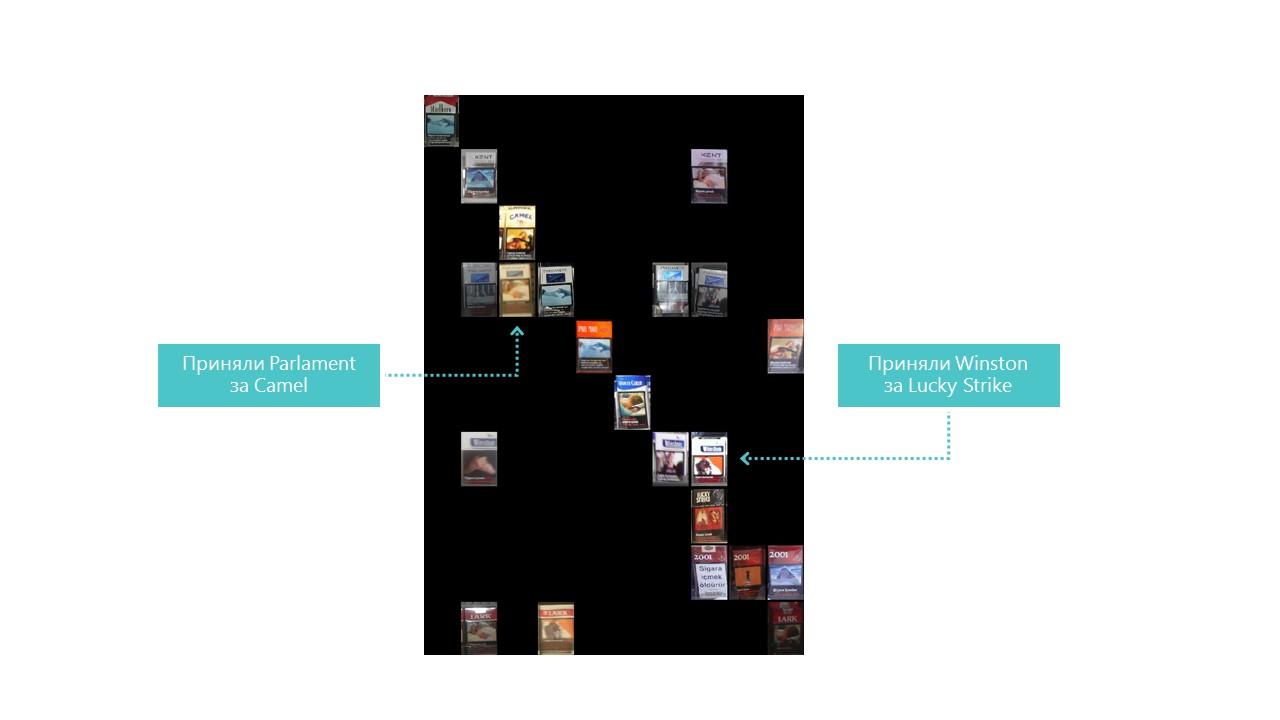
Anda juga dapat memahami mengapa Parlemen salah mengira Camel, tetapi mengapa Winston salah dengan Lucky Strike benar-benar tidak dapat dipahami, tetapi mereka tidak memiliki kesamaan. Ini adalah masalah utama dari jaringan saraf - ketidakjelasan lengkap dari apa yang terjadi di dalam. Anda dapat, tentu saja, memvisualisasikan beberapa lapisan, tetapi bagi kami visualisasi ini terlihat seperti ini:

Peluang nyata untuk meningkatkan kualitas pengakuan dalam kondisi kami adalah menambahkan lebih banyak foto.
Jadi, classifiernya sudah siap. Pergi ke detektor.
Langkah 3. Cari produk di foto ( tautan di github )Tugas-tugas penting berikut dalam bidang visi komputer adalah segmentasi semantik, lokalisasi, pencarian objek, dan segmentasi instance.
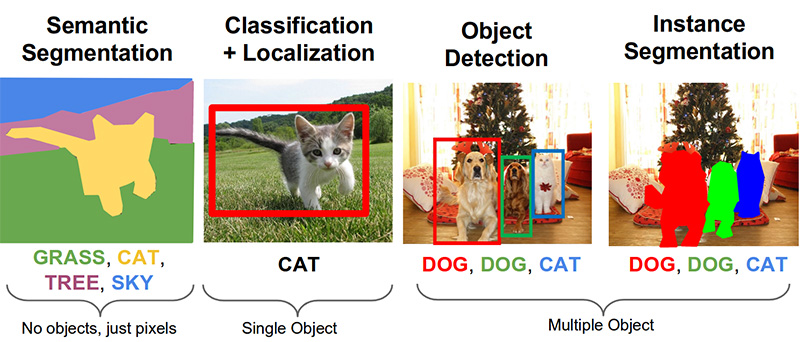
Tugas kita membutuhkan deteksi objek. Artikel 2014 menawarkan pendekatan berdasarkan metode Viola-Jones dan HOG dengan akurasi visual:

Berkat penggunaan pembatasan statistik tambahan, akurasinya sangat baik:

Sekarang tugas pengenalan objek berhasil diselesaikan dengan bantuan jaringan saraf. Kami akan menggunakan sistem Tensorflow Object Detection API dan melatih jaringan saraf dengan arsitektur Mobilenet V1 SSD. Pelatihan model seperti itu dari awal membutuhkan banyak data dan bisa memakan waktu berhari-hari, jadi kami menggunakan model yang dilatih tentang data COCO sesuai dengan prinsip pembelajaran transfer.
Konsep kunci dari pendekatan ini adalah ini. Mengapa seorang anak tidak perlu menunjukkan jutaan objek sehingga ia belajar menemukan dan membedakan bola dari kubus? Karena anak memiliki 500 juta tahun perkembangan korteks visual. Evolusi telah menjadikan visi sistem sensorik terbesar. Hampir 50% (tetapi ini tidak akurat) dari neuron otak manusia bertanggung jawab untuk pemrosesan gambar. Orang tua hanya dapat menunjukkan bola dan kubus, dan kemudian mengoreksi anak itu beberapa kali sehingga ia dengan sempurna menemukan dan membedakan satu dari yang lainnya.
Dari sudut pandang filosofis (dengan perbedaan teknis lebih dari umum), transfer pembelajaran dalam jaringan saraf bekerja dengan cara yang sama. Jaringan saraf convolutional terdiri dari level-level, yang masing-masingnya mendefinisikan bentuk-bentuk yang semakin kompleks: ia mengidentifikasi titik-titik kunci, menggabungkannya ke dalam garis-garis, yang pada gilirannya menggabungkan menjadi angka-angka. Dan hanya pada tingkat terakhir dari keseluruhan tanda yang ditemukan menentukan objek.
Objek dunia nyata memiliki banyak kesamaan. Saat mentransfer pembelajaran, kami menggunakan level definisi fitur dasar yang sudah terlatih dan hanya melatih layer yang bertanggung jawab untuk mengidentifikasi objek. Untuk melakukan ini, beberapa ratus foto dan beberapa jam pengoperasian GPU biasa sudah cukup bagi kami. Jaringan ini awalnya dilatih pada dataset COCO (Microsoft Common Objects in Context), yang terdiri dari 91 kategori dan 2.500.000 gambar! Banyak, meski bukan 500 juta tahun evolusi.
Melihat sedikit ke depan, animasi-gif ini (agak lambat, jangan gulir segera) dari tensorboard memvisualisasikan proses pembelajaran. Seperti yang Anda lihat, model mulai menghasilkan hasil yang benar-benar berkualitas tinggi segera, dan kemudian muncul penggilingan:

"Pelatih" sistem Tensorflow Object Detection API dapat secara independen melakukan augmentasi, memotong bagian gambar acak untuk pelatihan, dan memilih contoh "negatif" (bagian foto yang tidak mengandung benda apa pun). Secara teori, tidak perlu preprocessing foto. Namun, pada komputer di rumah dengan HDD dan RAM dalam jumlah kecil, ia menolak untuk bekerja dengan gambar beresolusi tinggi: pada awalnya ia menggantung lama, berkarat dengan disk, kemudian terbang keluar.
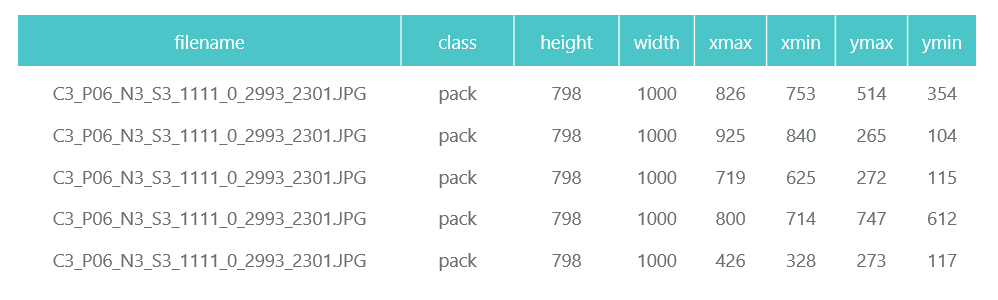
Hasilnya, kami mengkompres foto ke ukuran 1000x1000 piksel sambil mempertahankan rasio aspek. Tetapi karena ketika mengompresi foto besar, banyak tanda hilang, beberapa kotak pertama ukuran acak dipotong dari setiap foto rak dan diperas menjadi 1000x1000. Akibatnya, paket dalam resolusi tinggi (tetapi tidak cukup) dan dalam jumlah kecil (tetapi banyak) masuk ke dalam data pelatihan. Kami ulangi: langkah ini terpaksa dan, kemungkinan besar, sama sekali tidak perlu, dan mungkin berbahaya.
Foto yang disiapkan dan dikompresi disimpan dalam direktori yang terpisah (eval dan kereta), dan deskripsi mereka (dengan bundel yang terkandung di dalamnya) dibentuk dalam bentuk dua bingkai data panda (train_df dan eval_df):
Sistem API Deteksi Objek Tensorflow membutuhkan input untuk disajikan sebagai file tfrecord. Anda dapat membentuknya menggunakan utilitas, tetapi kami akan membuatnya menjadi kode:
def class_text_to_int(row_label): if row_label == 'pack': return 1 else: None def split(df, group): data = namedtuple('data', ['filename', 'object']) gb = df.groupby(group) return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)] def create_tf_example(group, path): with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid: encoded_jpg = fid.read() encoded_jpg_io = io.BytesIO(encoded_jpg) image = Image.open(encoded_jpg_io) width, height = image.size filename = group.filename.encode('utf8') image_format = b'jpg' xmins = [] xmaxs = [] ymins = [] ymaxs = [] classes_text = [] classes = [] for index, row in group.object.iterrows(): xmins.append(row['xmin'] / width) xmaxs.append(row['xmax'] / width) ymins.append(row['ymin'] / height) ymaxs.append(row['ymax'] / height) classes_text.append(row['class'].encode('utf8')) classes.append(class_text_to_int(row['class'])) tf_example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': dataset_util.int64_feature(height), 'image/width': dataset_util.int64_feature(width), 'image/filename': dataset_util.bytes_feature(filename), 'image/source_id': dataset_util.bytes_feature(filename), 'image/encoded': dataset_util.bytes_feature(encoded_jpg), 'image/format': dataset_util.bytes_feature(image_format), 'image/object/bbox/xmin': dataset_util.float_list_feature(xmins), 'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs), 'image/object/bbox/ymin': dataset_util.float_list_feature(ymins), 'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs), 'image/object/class/text': dataset_util.bytes_list_feature(classes_text), 'image/object/class/label': dataset_util.int64_list_feature(classes), })) return tf_example def convert_to_tf_records(images_path, examples, dst_file): writer = tf.python_io.TFRecordWriter(dst_file) grouped = split(examples, 'filename') for group in grouped: tf_example = create_tf_example(group, images_path) writer.write(tf_example.SerializeToString()) writer.close() convert_to_tf_records(f'{cropped_path}train/', train_df, f'{detector_data_path}train.record') convert_to_tf_records(f'{cropped_path}eval/', eval_df, f'{detector_data_path}eval.record')
Tetap bagi kami untuk menyiapkan direktori khusus dan memulai proses:
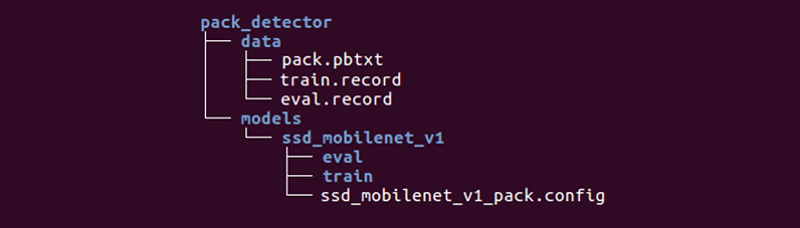
Strukturnya mungkin berbeda, tetapi kami merasa sangat nyaman.
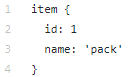
Direktori data berisi file yang telah kita buat dengan tfrecords (train.record dan eval.record), serta pack.pbtxt dengan jenis objek yang akan kita latih jaringan saraf. Kami hanya memiliki satu jenis objek untuk didefinisikan, sehingga file ini sangat pendek:
Direktori models (mungkin ada banyak model untuk menyelesaikan satu masalah) di direktori anak ssd_mobilenet_v1 berisi pengaturan untuk pelatihan dalam file .config, serta dua direktori kosong: train and eval. Dalam kereta, "pelatih" akan menyimpan titik kontrol model, "evaluator" akan mengambilnya, menjalankannya pada data untuk evaluasi dan memasukkannya ke direktori eval. Tensorboard akan melacak dua direktori ini dan menampilkan informasi proses.
Penjelasan terperinci tentang struktur file konfigurasi, dll. dapat ditemukan di
sini dan di
sini . Instruksi pemasangan Tensorflow Object Detection API dapat ditemukan di
sini .
Kami masuk ke direktori models / research / object_detection dan mengempiskan model pra-terlatih:
wget http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2017_11_17.tar.gz tar -xvzf ssd_mobilenet_v1_coco_2017_11_17.tar.gz
Kami menyalin direktori pack_detector yang disiapkan oleh kami di sana.
Pertama, mulailah proses pelatihan:
python3 train.py --logtostderr \ --train_dir=pack_detector/models/ssd_mobilenet_v1/train/ \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config
Kami memulai proses evaluasi. Kami tidak memiliki kartu video kedua, jadi kami meluncurkannya pada prosesor (menggunakan instruksi CUDA_VISIBLE_DEVICES = ""). Karena itu, ia akan sangat terlambat mengenai proses pelatihan, tetapi ini tidak terlalu buruk:
CUDA_VISIBLE_DEVICES="" python3 eval.py \ --logtostderr \ --checkpoint_dir=pack_detector/models/ssd_mobilenet_v1/train \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --eval_dir=pack_detector/models/ssd_mobilenet_v1/eval
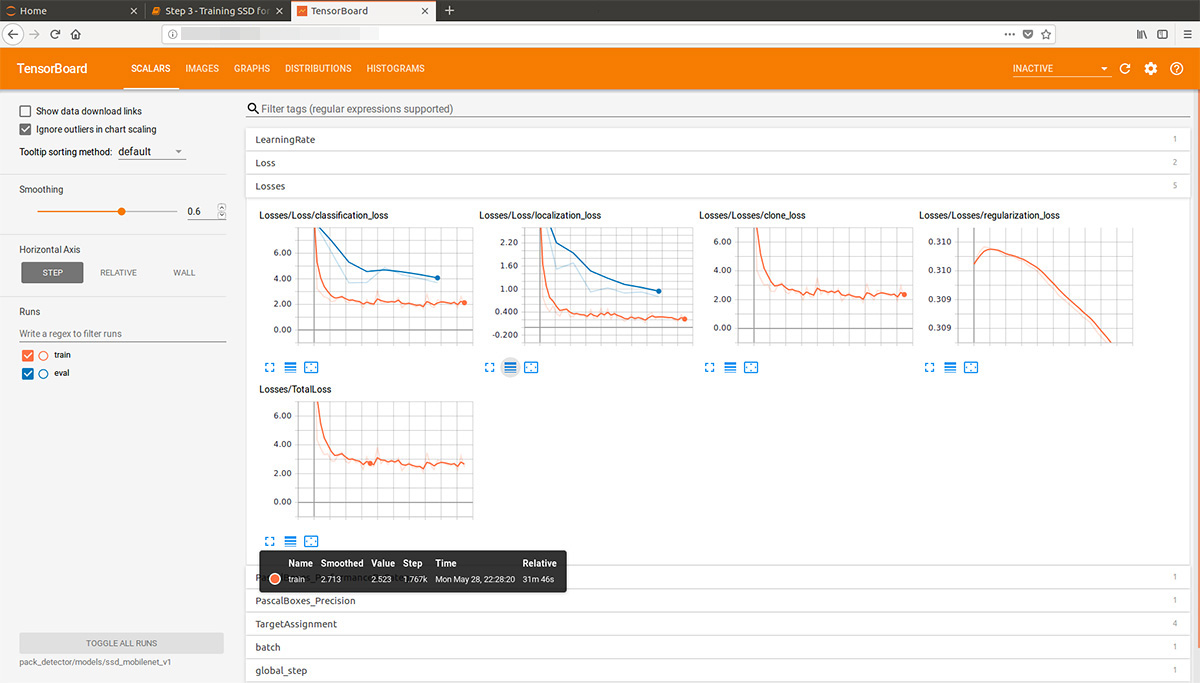
Kami memulai proses papan tensor:
tensorboard --logdir=pack_detector/models/ssd_mobilenet_v1
Setelah itu kita bisa melihat grafik yang indah, serta karya nyata model pada estimasi data (gif di awal):
Proses pelatihan dapat dihentikan dan dilanjutkan kapan saja. Ketika kami yakin bahwa modelnya cukup baik, kami menyimpan pos pemeriksaan dalam bentuk grafik inferensi:
python3 export_inference_graph.py \ --input_type image_tensor \ --pipeline_config_path pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --trained_checkpoint_prefix pack_detector/models/ssd_mobilenet_v1/train/model.ckpt-13756 \ --output_directory pack_detector/models/ssd_mobilenet_v1/pack_detector_2018_06_03
Jadi, pada langkah ini kami mendapat grafik inferensi, yang dapat kita gunakan untuk mencari objek bundel. Kami lolos penggunaannya.
Langkah 4. Menerapkan pencarian ( tautan github )Kode inisialisasi pemuatan dan inferensi grafik ada di tautan di atas. Fitur pencarian utama:
Fungsi ini menemukan kotak terikat untuk paket tidak di seluruh foto, tetapi di bagiannya. Fungsi ini juga menyaring persegi panjang yang ditemukan dengan skor deteksi rendah yang ditentukan dalam parameter cutoff.
Ternyata menjadi dilema. Di satu sisi, dengan cutoff tinggi, kami kehilangan banyak objek, di sisi lain, dengan cutoff rendah, kami mulai menemukan banyak objek yang bukan bundel. Pada saat yang sama, kami masih menemukan tidak semuanya dan tidak secara ideal:

Namun, perhatikan bahwa jika kita menjalankan fungsi untuk sepotong kecil foto, pengakuannya hampir sempurna dengan cutoff = 0,9:

Ini disebabkan oleh fakta bahwa model MobileNet V1 SSD menerima 300x300 foto sebagai input. Secara alami, dengan kompresi seperti itu banyak tanda hilang.
Tetapi tanda-tanda ini tetap ada jika kita memotong sebuah kotak kecil berisi beberapa paket. Ini menyarankan ide untuk menggunakan jendela mengambang: kita berlari melalui kotak kecil di foto dan mengingat semua yang kami temukan.

: , . . : (detection score), , , overlapTresh ( ):
:

:

, , .
Kesimpulan
«»: , . , , .. .
, , :
- 150 , , ,
- 3-7 ,
- 100 ,
- ,
- (),
- (, ),
- , «»,
- , , (SSD ),
- , ,
- .
, , .