 Bagaimana terjemahan AI dapat belajar menghasilkan gambar kucing
Bagaimana terjemahan AI dapat belajar menghasilkan gambar kucing .
Penelitian
Generative Adversarial Nets (GAN) yang diterbitkan pada tahun 2014 adalah terobosan di bidang model generatif. Peneliti utama Yann Lekun menyebut jaring permusuhan "ide terbaik dalam pembelajaran mesin selama dua puluh tahun terakhir." Hari ini, berkat arsitektur ini, kita dapat membuat AI yang menghasilkan gambar realistis kucing. Keren!
 DCGAN selama pelatihan
DCGAN selama pelatihanSemua kode yang berfungsi ada di
repositori Github . Ini akan berguna bagi Anda jika Anda memiliki pengalaman dalam pemrograman Python, pembelajaran mendalam, bekerja dengan Tensorflow dan jaringan saraf convolutional.
Dan jika Anda baru belajar mendalam, saya sarankan Anda membiasakan diri dengan serangkaian artikel yang sangat baik
Machine Learning is Fun!Apa itu DCGAN?
Deep Convolutional Generative Adverserial Networks (DCGAN) adalah arsitektur pembelajaran mendalam yang menghasilkan data yang mirip dengan data dari set pelatihan.
Model ini menggantikan dengan lapisan konvolusional lapisan yang sepenuhnya terhubung dari jaringan permusuhan generatif. Untuk memahami cara kerja DCGAN, kami menggunakan metafora konfrontasi antara seorang kritikus ahli seni dan pemalsu.
Pemalsu ("generator") sedang mencoba membuat gambar Van Gogh palsu dan mengirimkannya sebagai gambar asli.
Seorang kritikus seni ("diskriminator") sedang mencoba untuk menghukum pemalsuan, menggunakan pengetahuannya tentang kanvas nyata Van Gogh.
Seiring waktu, kritikus seni semakin mendefinisikan kepalsuan, dan pemalsuan membuat semuanya lebih sempurna.
 Seperti yang Anda lihat, DCGAN terdiri dari dua jaringan saraf pembelajaran dalam yang terpisah yang saling bersaing.
Seperti yang Anda lihat, DCGAN terdiri dari dua jaringan saraf pembelajaran dalam yang terpisah yang saling bersaing.- Generator sedang mencoba untuk membuat data yang dapat dipercaya. Dia tidak tahu apa data sebenarnya, tetapi dia belajar dari respons jaringan saraf musuh, mengubah hasil karyanya dengan setiap iterasi.
- Diskriminator mencoba untuk menentukan data palsu (membandingkan dengan yang asli), menghindari sejauh mungkin yang salah dalam kaitannya dengan data nyata. Hasil dari model ini adalah umpan balik untuk generator.
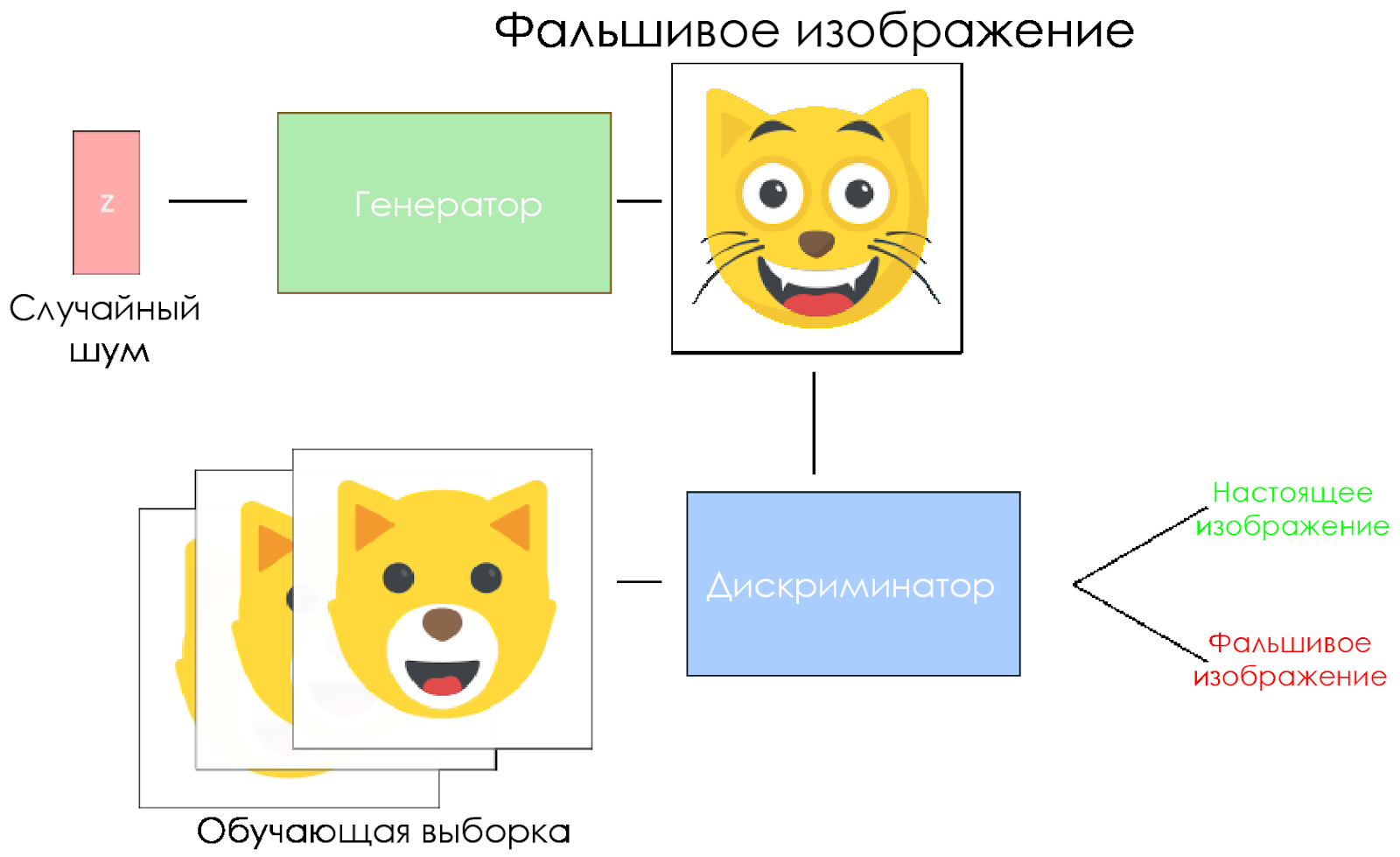 Skema DCGAN.
Skema DCGAN.- Generator mengambil vektor noise acak dan menghasilkan gambar.
- Gambar diberikan kepada diskriminator, ia membandingkannya dengan sampel pelatihan.
- Diskriminator mengembalikan angka - 0 (palsu) atau 1 (gambar asli).
Mari kita buat DCGAN!
Sekarang kita siap untuk membuat AI kita sendiri.
Pada bagian ini, kita akan fokus pada komponen utama model kita. Jika Anda ingin melihat seluruh kode, buka di
sini .
Masukkan data
Buat bertopik untuk input:
inputs_real untuk pembeda dan
inputs_z untuk generator. Harap dicatat bahwa kami akan memiliki dua tingkat pembelajaran, secara terpisah untuk generator dan pembeda.
DCGAN sangat sensitif terhadap hiperparameter, sehingga sangat penting untuk menyempurnakannya.
def model_inputs(real_dim, z_dim): """ Create the model inputs :param real_dim: tuple containing width, height and channels :param z_dim: The dimension of Z :return: Tuple of (tensor of real input images, tensor of z data, learning rate G, learning rate D) """
Diskriminator dan generator
Kami menggunakan
tf.variable_scope karena dua alasan.
Pertama, untuk memastikan semua nama variabel dimulai dengan generator / diskriminator. Nantinya ini akan membantu kita dalam melatih dua jaringan saraf.
Kedua, kami akan menggunakan kembali jaringan ini dengan data input yang berbeda:
- Kami akan melatih generator, dan kemudian mengambil sampel gambar yang dihasilkannya.
- Dalam diskriminator, kami akan membagikan variabel untuk gambar input palsu dan nyata.

Mari kita buat diskriminator. Ingat bahwa sebagai input, dibutuhkan gambar nyata atau palsu dan mengembalikan 0 atau 1 sebagai respons.
Beberapa catatan:
- Kita perlu menggandakan ukuran filter di setiap lapisan konvolusional.
- Menggunakan downsampling tidak disarankan. Sebaliknya, hanya lapisan convolutional yang dilucuti yang berlaku.
- Di setiap lapisan, kami menggunakan normalisasi batch (dengan pengecualian lapisan input), karena ini mengurangi pergeseran kovarians. Baca lebih lanjut di artikel luar biasa ini .
- Kami akan menggunakan Leaky ReLU sebagai fungsi aktivasi, ini akan membantu untuk menghindari efek dari gradien "menghilang".
def discriminator(x, is_reuse=False, alpha = 0.2): ''' Build the discriminator network. Arguments --------- x : Input tensor for the discriminator n_units: Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out, logits: ''' with tf.variable_scope("discriminator", reuse = is_reuse):
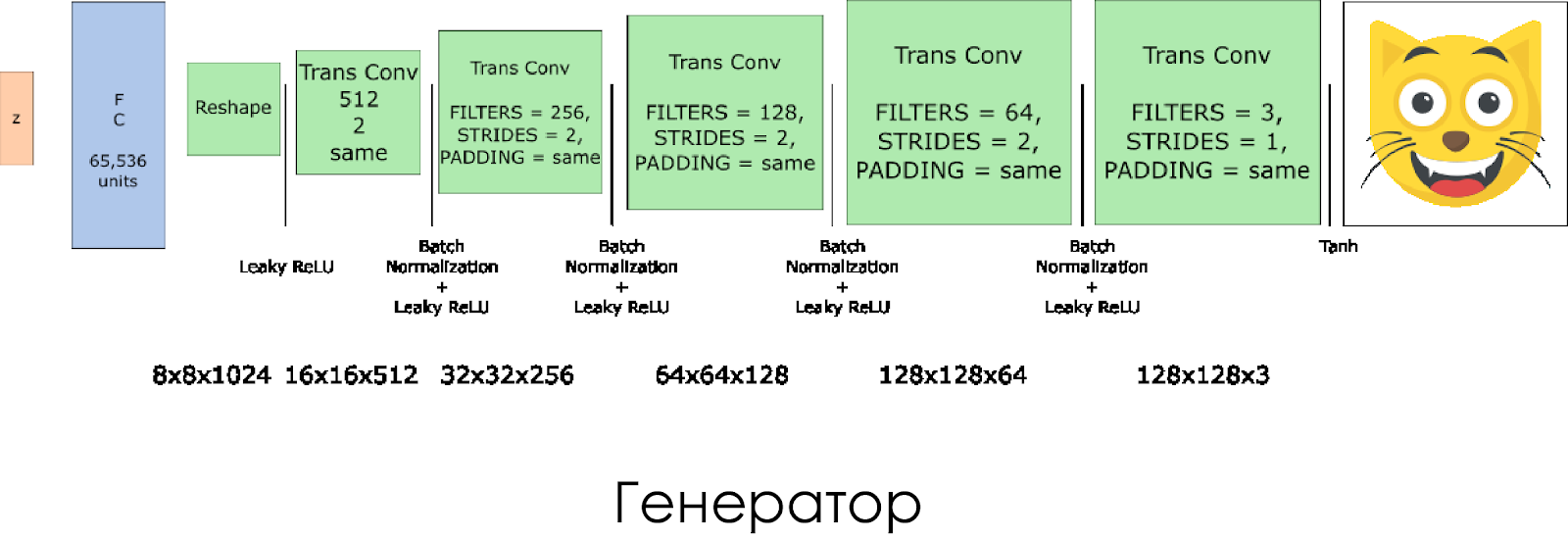
Kami telah membuat generator. Ingatlah bahwa dibutuhkan vektor noise (z) sebagai input dan, berkat lapisan konvolusi yang ditransformasikan, menciptakan gambar palsu.
Pada setiap lapisan, kami membagi dua ukuran filter, dan juga menggandakan ukuran gambar.
Generator bekerja paling baik saat menggunakan
tanh sebagai fungsi aktivasi output.
def generator(z, output_channel_dim, is_train=True): ''' Build the generator network. Arguments --------- z : Input tensor for the generator output_channel_dim : Shape of the generator output n_units : Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out: ''' with tf.variable_scope("generator", reuse= not is_train):
Kerugian dalam diskriminator dan generator
Karena kita melatih generator dan diskriminator, kita perlu menghitung kerugian untuk kedua jaringan saraf. Diskriminator harus memberi 1 ketika "menganggap" gambar itu nyata, dan 0 jika gambar itu palsu. Sesuai dengan ini dan Anda perlu mengkonfigurasi kerugian. Kerugian diskriminator dihitung sebagai jumlah kerugian untuk citra asli dan palsu:
d_loss = d_loss_real + d_loss_fakedi mana
d_loss_real adalah kerugian ketika diskriminator menganggap gambar itu salah, tetapi sebenarnya itu nyata. Itu dihitung sebagai berikut:
- Kami menggunakan
d_logits_real , semua label sama dengan 1 (karena semua data adalah nyata). labels = tf.ones_like(tensor) * (1 - smooth) . Mari kita gunakan label smoothing: turunkan nilai label dari 1,0 ke 0,9 untuk membantu pembeda menggeneralisasi lebih baik.
d_loss_fake adalah kerugian ketika diskriminator menganggap gambar itu nyata, tetapi sebenarnya itu palsu.
- Kami menggunakan
d_logits_fake , semua label adalah 0.
Untuk kehilangan generator,
d_logits_fake dari diskriminator digunakan. Kali ini, semua label adalah 1, karena generator ingin mengelabui pembeda.
def model_loss(input_real, input_z, output_channel_dim, alpha): """ Get the loss for the discriminator and generator :param input_real: Images from the real dataset :param input_z: Z input :param out_channel_dim: The number of channels in the output image :return: A tuple of (discriminator loss, generator loss) """
Pengoptimal
Setelah menghitung kerugian, generator dan pembeda harus diperbarui secara individual. Untuk melakukan ini, gunakan
tf.trainable_variables() membuat daftar semua variabel yang didefinisikan dalam grafik kami.
def model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1): """ Get optimization operations :param d_loss: Discriminator loss Tensor :param g_loss: Generator loss Tensor :param learning_rate: Learning Rate Placeholder :param beta1: The exponential decay rate for the 1st moment in the optimizer :return: A tuple of (discriminator training operation, generator training operation) """
Pelatihan
Sekarang kami menerapkan fungsi pelatihan. Idenya cukup sederhana:
- Kami menyimpan model kami setiap lima periode (zaman).
- Kami menyimpan gambar dalam folder dengan gambar setiap 10 batch terlatih.
- Setiap 15 periode kami menampilkan
g_loss , d_loss dan gambar yang dihasilkan. Ini karena notebook Jupyter mungkin macet ketika menampilkan terlalu banyak gambar. - Atau kita dapat langsung menghasilkan gambar nyata dengan memuat model yang disimpan (ini akan menghemat 20 jam pelatihan).
def train(epoch_count, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, get_batches, data_shape, data_image_mode, alpha): """ Train the GAN :param epoch_count: Number of epochs :param batch_size: Batch Size :param z_dim: Z dimension :param learning_rate: Learning Rate :param beta1: The exponential decay rate for the 1st moment in the optimizer :param get_batches: Function to get batches :param data_shape: Shape of the data :param data_image_mode: The image mode to use for images ("RGB" or "L") """
Bagaimana cara menjalankannya
Semua ini dapat berjalan langsung di komputer Anda jika Anda siap menunggu 10 tahun, jadi lebih baik menggunakan layanan GPU berbasis cloud seperti AWS atau FloydHub. Secara pribadi, saya melatih DCGAN ini selama 20 jam di Microsoft Azure dan
Deep Virtual Machine mereka . Saya tidak memiliki hubungan bisnis dengan Azure, saya hanya menyukai layanan pelanggan mereka.
Jika Anda mengalami kesulitan menjalankan di mesin virtual, lihat
artikel yang bagus
ini .
Jika Anda meningkatkan model, jangan ragu untuk melakukan permintaan penarikan.
