Kata Pengantar
Implementasi PHP trie yang dijelaskan di sini membuat kamus terlalu gemuk sejauh ini, yang karenanya membutuhkan waktu cukup lama untuk dimuat ke dalam memori, yang meningkatkan kecepatan kerjanya. Kecepatan pencarian ~ 80 ribu kata per detik. Kamus ini dibuat dari daftar lemmas kamus opencorpora.org dan mencakup 389844 kata. Dalam bentuk yang tidak terkompresi, kamus berbobot ~ 150mb, dan gzip ~ 6mb terkompresi. Namun, hasil kinerja yang cukup bagus membuktikan bahwa dalam PHP murni Anda dapat membuat pohon awalan trie yang berfungsi penuh.
Saya meminta para programmer terlebih dahulu untuk membuat kritikus sastra agar tidak menulis komentar jahat. Artikel ini harus menarik bagi pemula, seperti saya sendiri. Terlalu malas membaca, Anda bisa langsung melihat kode di
github .
Bagaimana semuanya dimulai
Untuk beberapa waktu sekarang saya telah menetas ide untuk menulis analisa morfologis untuk proyek PHP saya, yang akan dapat dengan cepat melakukan analisis morfologis kata-kata yang diberikan, serta mengubah kata-kata menjadi bentuk morfologis yang diinginkan.
PHP sudah memiliki perpustakaan serupa yang disebut phpmorhy. Ini bekerja cukup cepat dan saya akan menggunakannya dan tidak akan menciptakan apa pun, tetapi kompiler kamus di dalamnya dibuat sebagai aplikasi non-PHP yang terpisah, yang membuat saya tidak mungkin menggunakan perpustakaan ini. Perpustakaan itu sendiri dibangun berdasarkan kamus AOT yang telah lama ditunggu-tunggu, yang semakin mengurangi kegunaannya.
Berminggu-minggu dan berbulan-bulan berlalu, saya membaca
sebuah artikel oleh Khabrovchanin, lalu
sebuah artikel oleh I. Segalovich tentang algoritma morfologis yang cepat untuk mesin pencari, kemudian banyak artikel yang berbeda.
Sedikit demi sedikit, saya telah matang untuk menulis
lunapark saya sendiri
dengan blackjack dan tulang-tulang seorang penganalisa morfologis. Saya pikir: "
Ya, kemajuan telah melangkah maju, dalam PHP Anda sudah dapat menguraikan genom manusia! "
Saya mengambil kamus opencorpora.org, memasukkannya ke mysql dan mendapatkan kecepatan pencarian 2 ribu kata per detik. Saya pikir perlu memuat kamus ke dalam memori. Dan di sini ternyata bahwa untuk memiliki struktur data reguler tersedia di PHP seperti array atau objek, Anda perlu menyimpan sekitar 3 GB RAM untuk kamus 3 juta. Semua implementasi php trie yang saya temui hanya cocok sebagai tutorial untuk menunjukkan logika kerja, karena mereka sendiri dibangun di atas struktur penyimpanan data PHP asli.
Perangkat penyimpanan kamus dan prinsip operasi
Di mana pun saya bisa membaca, mendengarkan, atau melihat pohon awalan trie, tidak dijelaskan dengan tepat bagaimana data akan disimpan dalam memori. Di sini kita memiliki simpul, dan inilah pewarisnya, dan inilah bendera akhir kata, yang tidak diperlihatkan di bawah tenda. Karena itu, saya harus menemukan metode penyimpanan sendiri.
Seperti yang Anda tahu, pohon awalan trie terdiri dari node. Node menyimpan awalan, tautan ke simpul berikutnya (keturunan), dan penunjuk ke fakta bahwa awalan ini adalah yang terakhir dalam rantai. Orang India mengatakan dengan cukup cerdas tentang trie di
sini .
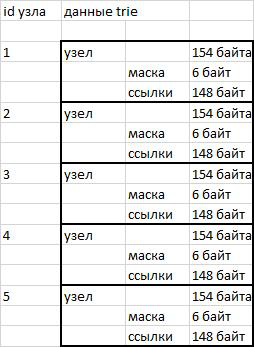
Node dalam implementasi trie saya adalah blok data dengan panjang tetap 154 byte. 6 byte pertama (48 bit) berisi bit mask dari ahli waris. 46 bit pertama adalah alfabet Rusia, angka, tanda kutip, tanda hubung dan apostrof. Apostrof ditambahkan karena dalam kamus opencorpora.org ada kata "cote d'ivoire", yang menggunakan tanda apostrof. Bit ke-47 digunakan untuk menyimpan kata end flag. 148 byte berikut setelah bitmask digunakan untuk menyimpan referensi ke pewaris node. 3 byte per karakter (46 * 3 = 148).
Node disimpan sebagai data biner dalam sebuah string. Akses ke bagian yang diinginkan dilakukan menggunakan fungsi substr () dan membongkar berikutnya () membongkar.
Menggunakan node dengan panjang tetap menyederhanakan proses pengalamatan. Untuk beralih ke node yang diinginkan, cukup mengetahui nomor seri (id) dan panjang node. Kami mengalikan nomor seri dengan panjang dan mencari offset relatif ke awal baris - semuanya sangat sederhana.
gbr. 1 Skema Penyimpanan
Kekurangan
Skema penyimpanan yang digunakan menyederhanakan pengalamatan, tetapi memakan banyak ruang. Penyimpanan 380 ribu kata membutuhkan lebih dari satu juta node. 154 byte * 1.000.000 node = 146,86 megabita. Yaitu sekitar 400 byte per kata. Jika Anda menulis kata-kata dalam file teks sederhana yang disandikan dalam utf8, maka 380 ribu kata yang sama ini dapat dimuat dalam 16 megabita.
Paket
Untuk menggunakan memori lebih rasional, saya ingin beralih ke panjang variabel variabel, maka sebagai tautan saya harus merekam bukan id node, tetapi lokasinya dalam byte. Lokasi tautan ke simpul yang diinginkan akan ditentukan sebagai berikut. Pada contoh kata "abv."
Huruf "a" adalah yang pertama dalam alfabet, oleh karena itu, simpulnya juga yang pertama, masing-masing, offset 0. Baca 6 byte, mulai dari 0.
$str = substr($dic, 0, 6);
Buka kemasan garis:
$mask = (ord($str[5]) << 40) + (ord($str[4]) << 32) + (ord($str[3]) << 24) + (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
Kami melihat topeng bit ke-2 (huruf "b")
bit_get($mask, 2);
Bit diatur, sekarang kita menghitung jumlah bit yang dinaikkan di dalam mask menjadi 2. Katakanlah bit dari huruf "a" juga dinaikkan pada node kita, jadi bit kita dari huruf "b" akan menjadi bit kedua yang diangkat. Hitung offset untuk membaca tautan
$offset = 6 + 3;
6 byte topeng + 3 byte, yang menempati tautan pertama, ternyata 9 byte. Kami membaca seutas tali yang diinginkan.
$str = substr($dic, $offset, 3);
Buka kemasan tautan:
$ref = (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
Pergi ke simpul berikutnya dan ulangi semuanya lagi. Dalam surat terakhir, kami memeriksa keberadaan 47 bit di topeng, jika diatur, ada kata pencarian di trie kami.
Saya berharap bahwa mungkin untuk mempertahankan kecepatan setidaknya 50 ribu kata per detik.
Ucapan Terima Kasih
Saya ingin mengucapkan terima kasih kepada para peserta forum nulled.cc dan php.ru atas bantuan mereka dengan fungsi bitwise.