Berita (+
riset ) ini tentang penemuan generator meme oleh para ilmuwan dari Universitas Stanford mendorong saya untuk menulis sebuah artikel. Dalam artikel saya, saya akan mencoba menunjukkan bahwa Anda tidak perlu menjadi ilmuwan Stanford untuk melakukan hal-hal menarik dengan jaringan saraf. Dalam artikel tersebut, saya menjelaskan bagaimana pada tahun 2017 kami melatih jaringan saraf pada sekitar 30.000 teks dan memaksanya untuk menghasilkan meme dan meme internet baru (tanda komunikasi) dalam arti kata sosiologis. Kami menggambarkan algoritma pembelajaran mesin yang kami gunakan, kesulitan teknis dan administrasi yang kami temui.
Sedikit latar belakang tentang bagaimana kita sampai pada gagasan tentang penulis neuro dan apa sebenarnya itu. Pada tahun 2017, kami membuat proyek untuk satu situs web publik Vkontakte, nama dan tangkapan layar yang dilarang oleh moderator Habrahabr untuk dipublikasikan, mengingat penyebutannya sebagai PR "mandiri". Publik ada sejak 2013 dan menyatukan posting dengan ide umum untuk menguraikan humor melalui garis dan memisahkan garis dengan simbol "@":
@
@
Jumlah garis dapat bervariasi, plot dapat berupa apa saja. Paling sering, ini adalah humor atau catatan sosial yang tajam tentang fakta realitas yang merajalela. Secara umum, desain ini disebut "buhurt."
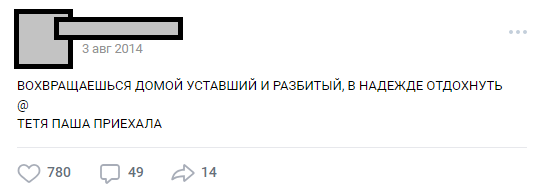 Salah satu buhur yang khas
Salah satu buhur yang khasSelama bertahun-tahun, publik telah tumbuh menjadi pengetahuan internal (karakter, plot, lokasi), dan jumlah posting telah melebihi 30.000. Pada saat penguraian mereka untuk kebutuhan proyek, jumlah baris sumber teks melebihi setengah juta.
Bagian 0. Munculnya ide dan tim
Setelah popularitas massa jaringan syaraf, gagasan untuk melatih JST pada teks-teks kami sudah mengudara selama sekitar enam bulan, tetapi akhirnya diformulasikan menggunakan E7su pada bulan Desember 2016. Pada saat yang sama, nama itu diciptakan ("Neurobugurt"). Saat itu, tim yang tertarik dengan proyek ini hanya terdiri dari tiga orang. Kami semua adalah siswa tanpa pengalaman praktis dalam algoritma dan jaringan saraf. Lebih buruk lagi, kami bahkan tidak memiliki satu GPU yang cocok untuk pelatihan. Yang kami miliki adalah antusiasme dan keyakinan bahwa cerita ini bisa menarik.
Bagian 1. Perumusan hipotesis dan tugas
Hipotesis kami ternyata adalah asumsi bahwa jika Anda mencampur semua teks yang diterbitkan selama tiga setengah tahun dan melatih jaringan saraf pada bangunan ini, Anda bisa mendapatkan:
a) lebih kreatif daripada orang
b) lucu
Bahkan jika kata-kata atau huruf-huruf dalam buhurt berubah menjadi mesin bingung dan diatur secara acak - kami percaya bahwa ini bisa berfungsi sebagai layanan penggemar dan masih akan menyenangkan para pembaca.
Tugas ini sangat disederhanakan oleh fakta bahwa format buhur pada dasarnya bersifat tekstual. Jadi, kami tidak perlu terjun ke visi mesin dan hal-hal rumit lainnya. Berita baik lainnya adalah seluruh isi teks sangat mirip. Ini memungkinkan untuk tidak menggunakan pembelajaran yang diperkuat - setidaknya pada tahap awal. Pada saat yang sama, kami memahami dengan jelas bahwa membuat penulis jaringan saraf dengan output yang dapat dibaca lebih dari sekali tidak mudah. Risiko melahirkan monster yang secara acak akan mengirim surat sangat besar.
Bagian 2. Persiapan tubuh teks
Dipercayai bahwa fase persiapan dapat memakan waktu yang sangat lama, karena hal ini terkait dengan pengumpulan dan pembersihan data. Dalam kasus kami, ternyata agak pendek:
parser kecil ditulis yang memompa sekitar 30k posting dari dinding komunitas dan memasukkannya ke dalam
file txt .
Kami tidak menghapus data sebelum pelatihan pertama. Di masa depan, ini memainkan lelucon kejam dengan kami, karena karena kesalahan yang merayap di tahap ini, kami tidak bisa membawa hasilnya ke bentuk yang dapat dibaca untuk waktu yang lama. Tetapi lebih lanjut tentang itu nanti.
 File layar dengan burger
File layar dengan burgerBagian 3. Pengumuman, penyempurnaan hipotesis, pilihan algoritma
Kami menggunakan sumber daya yang dapat diakses - sejumlah besar pelanggan publik. Asumsinya adalah bahwa di antara 300.000 pembaca ada beberapa penggemar yang memiliki jaringan saraf pada tingkat yang cukup untuk mengisi kesenjangan dalam pengetahuan tim kami. Kami mulai dari ide mengumumkan kompetisi secara luas dan menarik penggemar pembelajaran mesin hingga diskusi tentang masalah yang dirumuskan. Setelah menulis teks, kami memberi tahu orang-orang tentang ide kami dan mengharapkan tanggapan.
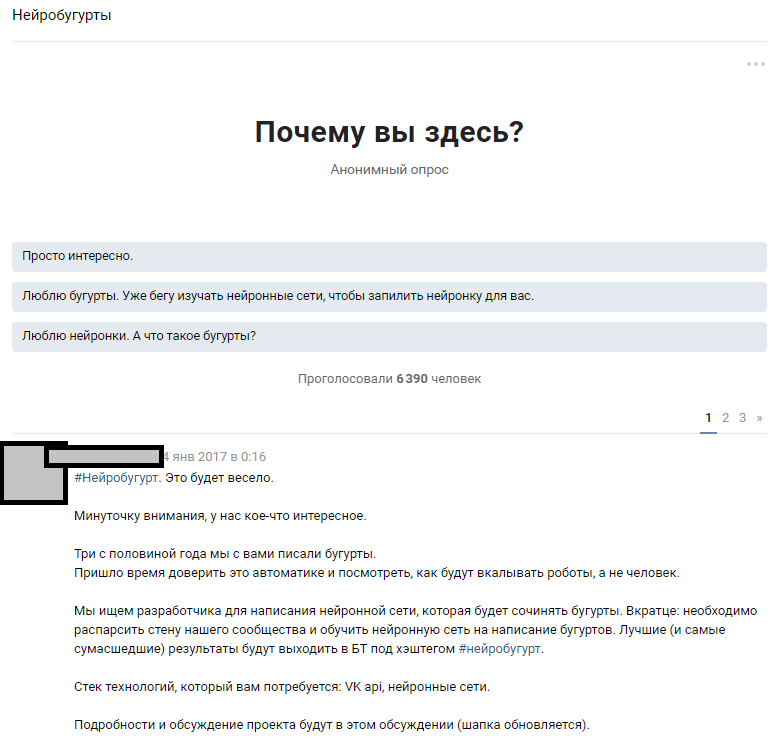 Pengumuman diskusi tematik
Pengumuman diskusi tematikReaksi orang-orang melebihi harapan kami yang paling liar. Diskusi tentang fakta bahwa kita akan melatih jaringan saraf menyebarkan holivar dengan hampir 1.000 komentar. Sebagian besar pembaca memudar dan mencoba membayangkan seperti apa hasilnya nanti. Sekitar 6.000 orang mengintip diskusi tematik, dan lebih dari 50 amatir yang tertarik meninggalkan komentar untuk siapa kami memberikan serangkaian uji
814 jalur buhurt untuk melakukan tes awal dan pelatihan. Setiap orang yang tertarik dapat mengambil dataset dan mempelajari algoritma yang paling menarik baginya, dan kemudian berdiskusi dengan kami dan penggemar lainnya. Kami mengumumkan sebelumnya bahwa kami akan terus bekerja dengan para peserta yang hasilnya paling mudah dibaca.
Pekerjaan dimulai: seseorang diam-diam mengumpulkan generator di rantai Markov, seseorang mencoba berbagai implementasi dengan github, dan kebanyakan hanya menjadi gila dalam diskusi dan meyakinkan kami dengan busa di mulut bahwa tidak ada yang akan datang darinya. Ini memulai bagian teknis dari proyek.
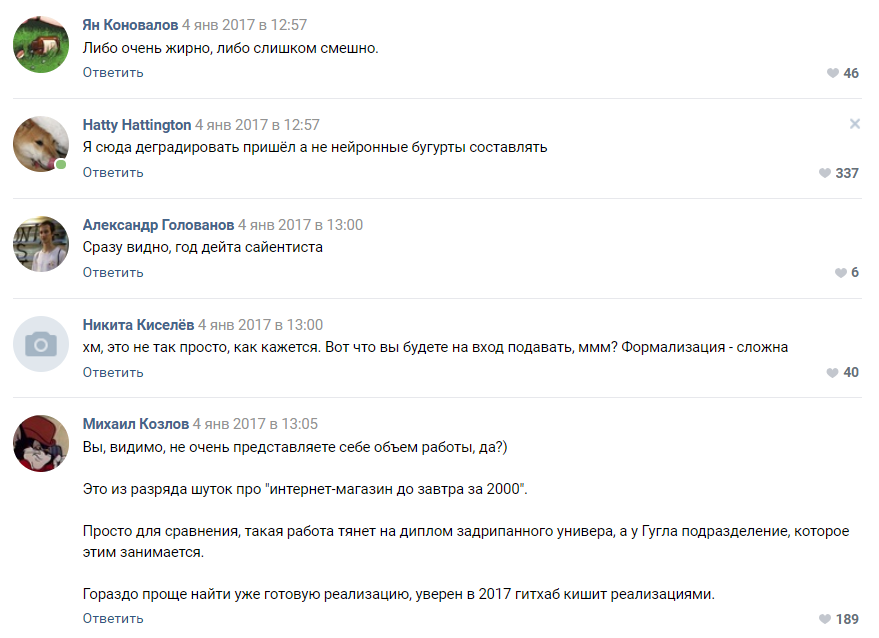
Beberapa saran dari para penggemar
Orang menawarkan puluhan opsi untuk implementasi:
- Rantai Markov.
- Temukan implementasi yang sudah jadi dari sesuatu yang mirip dengan GitHub dan latihlah.
- Generator frasa acak yang ditulis dalam Pascal.
- Dapatkan Negro sastra yang akan menulis omong kosong acak, dan kami akan menyampaikan ini sebagai output jaringan saraf.
 Evaluasi kompleksitas proyek dari salah satu pelanggan
Evaluasi kompleksitas proyek dari salah satu pelangganSebagian besar komentator setuju bahwa proyek kami akan gagal dan kami bahkan tidak akan mencapai tahap prototipe. Seperti yang kita pahami kemudian, orang masih cenderung menganggap jaringan saraf sebagai semacam sihir hitam yang terjadi di "kepala Zuckerberg" dan divisi rahasia Google.
Bagian 4. Pemilihan algoritma, pelatihan dan perluasan tim
Setelah beberapa waktu, kampanye yang kami luncurkan untuk ide crowdsourcing untuk algoritme mulai membuahkan hasil pertama. Kami mendapat sekitar 30 prototipe yang berfungsi, yang sebagian besar memberikan omong kosong yang sama sekali tidak dapat dibaca.
Pada tahap ini, kami pertama kali mengalami penurunan motivasi tim. Semua hasilnya sangat mirip dengan buhurts dan paling sering mewakili abracadabra huruf dan simbol. Pekerjaan puluhan penggemar menjadi debu dan ini mendemotivasi kami dan kami.
Algoritma berbasis pyTorch menunjukkan dirinya lebih baik daripada yang lain. Diputuskan untuk mengambil implementasi ini dan algoritma LSTM sebagai dasar. Kami mengenali pelanggan yang mengusulkannya sebagai pemenang dan mulai bekerja meningkatkan algoritme bersama dengannya. Tim kami yang terdistribusi telah berkembang menjadi empat orang. Fakta lucu di sini adalah bahwa
pemenang kontes , ternyata, baru berusia 16 tahun. Kemenangan itu adalah hadiah nyata pertamanya di bidang Ilmu Data.
Untuk pelatihan pertama, sekelompok 8 kartu grafis GXT1080 disewa.
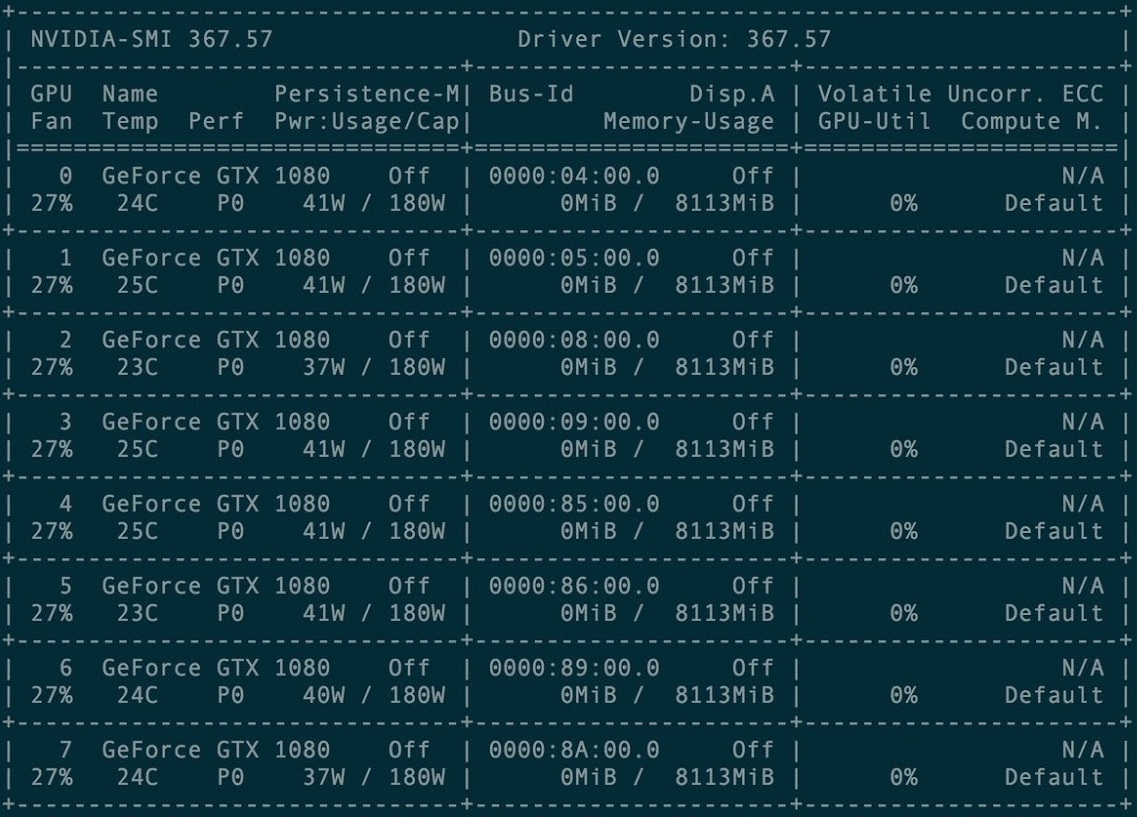 Konsol Manajemen Kartu Cluster
Konsol Manajemen Kartu ClusterRepositori asli dan semua manual proyek Torch-rnn ada di sini:
github.com/jcjohnson/torch-rnn . Kemudian, atas dasar itu, kami menerbitkan
repositori kami , di mana ada sumber kami, ReadMe untuk instalasi, serta neurobugur yang sudah selesai sendiri.
Beberapa kali pertama kami dilatih menggunakan konfigurasi pra-konfigurasi pada cluster GPU berbayar. Menyiapkannya ternyata tidak terlalu sulit - cukup instruksi dari pengembang Torch dan bantuan dari administrasi hosting, yang termasuk dalam pembayaran, sudah cukup.
Namun, sangat cepat kami mengalami kesulitan: setiap pelatihan memakan waktu sewa GPU - yang berarti tidak ada uang dalam proyek. Karena itu, pada Januari-Februari 2017, kami melakukan pelatihan di fasilitas yang dibeli, dan kami mencoba meluncurkan generasi pada mesin lokal kami.
Teks apa pun cocok untuk pelatihan model. Sebelum pelatihan, Anda harus terlebih dahulu memprosesnya, untuk itu Torch memiliki algoritma preprocess.py khusus yang mengubah my_data.txt Anda menjadi dua file: HDF5 dan JSON:
Script preprocessing berjalan seperti ini:
python scripts/preprocess.py \ --input_txt my_data.txt \ --output_h5 my_data.h5 \ --output_json my_data.json
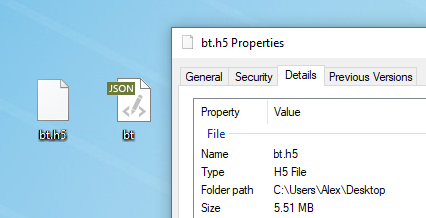 Setelah preprocessing, dua file muncul di mana jaringan saraf akan dilatih di masa depan
Setelah preprocessing, dua file muncul di mana jaringan saraf akan dilatih di masa depanBerbagai flag yang dapat diubah pada tahap preprocessing dijelaskan di
sini . Dimungkinkan juga untuk menjalankan
Torch dari Docker , tetapi penulis artikel tidak memeriksanya.
Pelatihan jaringan saraf
Setelah preprocessing, Anda dapat melanjutkan ke pelatihan model. Dalam folder dengan HDF5 dan JSON, Anda perlu menjalankan utilitas th, yang muncul bersama Anda jika Anda menginstal Torch dengan benar:
th train.lua -input_h5 my_data.h5 -input_json my_data.json
Pelatihan membutuhkan banyak waktu dan menghasilkan file dari formulir cv / checkpoint_1000.t7, yang merupakan "bobot" dari jaringan saraf kita. File-file ini memiliki berat megabita yang luar biasa dan mengandung kekuatan tautan antara huruf-huruf tertentu dalam dataset asli Anda.
 Jaringan saraf sering dibandingkan dengan otak manusia, tetapi menurut saya analogi yang lebih jelas dengan fungsi matematika yang mengambil parameter pada input (dataset Anda) dan memberikan hasilnya (data baru) pada output.
Jaringan saraf sering dibandingkan dengan otak manusia, tetapi menurut saya analogi yang lebih jelas dengan fungsi matematika yang mengambil parameter pada input (dataset Anda) dan memberikan hasilnya (data baru) pada output.Dalam kasus kami, setiap pelatihan pada kluster 8 GTX 1080 dalam kumpulan data 500.000 baris membutuhkan waktu sekitar satu atau dua jam, dan pelatihan serupa pada jenis CPU i3-2120 memakan waktu sekitar 80-100 jam. Dalam hal pelatihan yang lebih lama, jaringan saraf mulai berlatih kembali dengan kaku - simbol-simbol itu terlalu sering diulang satu sama lain, jatuh ke dalam siklus panjang preposisi, konjungsi dan kata-kata pengantar.
Sangat nyaman bahwa Anda dapat memilih frekuensi pos pemeriksaan dan selama satu pelatihan Anda akan segera mendapatkan banyak model: dari yang paling tidak terlatih (checkpoint_1000) hingga dilatih ulang (checkpoint_1000000). Hanya ruang yang cukup akan cukup.
Pembuatan teks baru
Setelah menerima setidaknya satu file yang sudah jadi dengan bobot (pos pemeriksaan _ *******), Anda dapat melanjutkan ke tahap berikutnya dan yang paling menarik: mulai menghasilkan teks. Bagi kami, itu adalah momen kebenaran yang sesungguhnya, karena untuk pertama kalinya kami mendapat hasil nyata - bugurt yang ditulis oleh mesin.
Pada titik ini, kami akhirnya berhenti menggunakan cluster dan semua generasi dilakukan pada mesin berdaya rendah kami. Namun, ketika mencoba memulai secara lokal, kami tidak berhasil mengikuti instruksi dan menginstal Torch. Penghalang pertama adalah penggunaan mesin virtual. Pada Ubuntu 16 virtual, tongkat tidak lepas landas - lupakan saja. StackOverflow sering datang untuk menyelamatkan, tetapi beberapa kesalahan sangat tidak penting sehingga jawabannya hanya dapat ditemukan dengan kesulitan besar.
Memasang Torch pada mesin lokal menghentikan proyek selama beberapa minggu: kami menemui semua jenis kesalahan dalam menginstal banyak paket yang diperlukan, kami juga berjuang dengan virtualisasi (virtualenv .env) dan akhirnya tidak menggunakannya. Beberapa kali dudukan dihancurkan ke tingkat sudo rm -rf dan hanya dipasang lagi.
Dengan menggunakan file yang dihasilkan dengan bobot, kami dapat mulai membuat teks pada mesin lokal kami:
 Salah satu kesimpulan pertama
Salah satu kesimpulan pertamaBagian 5. Menghapus teks
Kesulitan lain yang jelas adalah bahwa topik posting sangat berbeda, dan algoritma kami tidak melibatkan divisi apa pun dan menganggap semua 500.000 baris sebagai teks tunggal. Kami mempertimbangkan berbagai opsi untuk pengelompokan dataset dan bahkan siap untuk secara manual memecah tubuh teks berdasarkan topik atau tag tempat di beberapa ribu buhur (ada sumber daya manusia yang diperlukan untuk ini), tetapi terus-menerus menghadapi kesulitan teknis dalam mengirimkan kluster ketika mempelajari LSTM. Mengubah algoritma dan melakukan kompetisi lagi tampaknya bukan ide yang paling masuk akal dalam hal waktu proyek dan motivasi para peserta.
Tampaknya kami menemui jalan buntu - kami tidak dapat mengelompokkan buhur, dan pelatihan tentang satu set data besar menghasilkan hasil yang meragukan. Saya tidak ingin mengambil langkah mundur dan mengubah algoritma dan implementasi yang hampir melonjak - proyek hanya bisa koma. Tim mati-matian tidak memiliki pengetahuan yang cukup untuk menyelesaikan situasi secara normal, tetapi SME-KAL-OCHK-A tua yang baik datang untuk menyelamatkan. Solusi terakhir untuk
kruk ternyata jenius sederhana: dalam dataset asli, pisahkan buhur yang ada satu sama lain dengan garis kosong dan latih LSTM lagi.
Kami mengatur ketukan dalam 10 ruang vertikal setelah masing-masing buhurt, mengulangi pelatihan, dan selama generasi kami menetapkan batas pada volume output 500 karakter (panjang rata-rata satu "plot" buhurt dalam dataset asli).
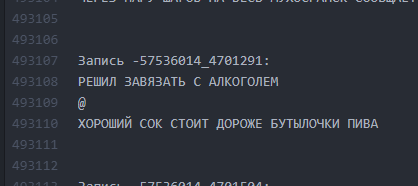 Seperti itu. Interval antar teks minimal.
Seperti itu. Interval antar teks minimal.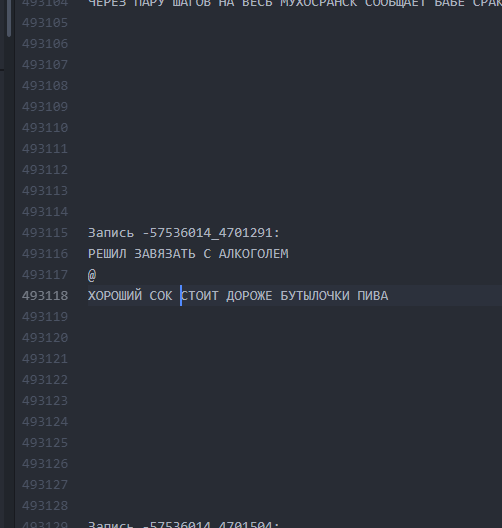 Bagaimana jadinya. Interval 10 baris membuat LSTM “memahami” bahwa satu bogurt telah berakhir dan yang lain telah dimulai.
Bagaimana jadinya. Interval 10 baris membuat LSTM “memahami” bahwa satu bogurt telah berakhir dan yang lain telah dimulai.Dengan demikian, adalah mungkin untuk mencapai bahwa sekitar 60% dari semua buhur yang dihasilkan mulai memiliki plot yang dapat dibaca (meskipun seringkali sangat delusi) sepanjang seluruh buhurt dari awal hingga akhir. Panjang satu plot, rata-rata, dari 9 hingga 13 baris.
Bagian 6. Pelatihan ulang
Setelah memperkirakan ekonomi proyek, kami memutuskan untuk tidak menghabiskan uang untuk menyewa sebuah cluster lagi, tetapi untuk berinvestasi dalam membeli kartu kami sendiri. Waktu belajar akan meningkat, tetapi setelah membeli kartu sekali, kita dapat menghasilkan buhur baru terus-menerus. Pada saat yang sama, sering melakukan pelatihan terus-menerus tidak lagi diperlukan.
 Memerangi pengaturan pada mesin lokal
Memerangi pengaturan pada mesin lokalBagian 7. Menyeimbangkan Hasil
Pada pergantian Maret-April 2017, kami melatih kembali jaringan saraf, menentukan parameter suhu dan jumlah era pelatihan. Hasilnya, kualitas output sedikit meningkat.
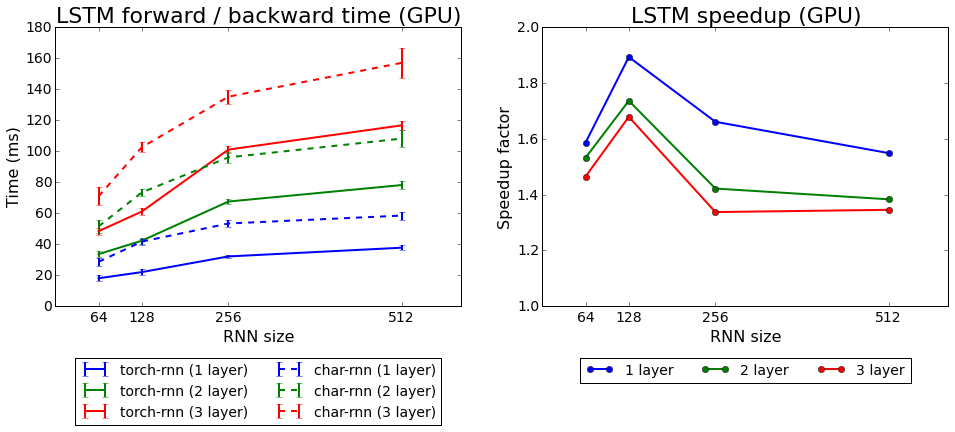 Kecepatan belajar obor-rnn dibandingkan dengan char-rnn
Kecepatan belajar obor-rnn dibandingkan dengan char-rnnKami menguji kedua algoritma yang datang dengan Torch: rnn dan LSTM. Yang kedua terbukti lebih baik.
Bagian 8. Apa yang telah kita capai?
Neurobugurt pertama diterbitkan pada 17 Januari 2017 - segera setelah pelatihan tentang cluster - dan pada hari pertama lebih dari 1000 komentar dikumpulkan.
 Salah satu neurobugurts pertama
Salah satu neurobugurts pertamaNeurobugur mencapai audiens dengan sangat baik sehingga mereka menjadi bagian yang terpisah, yang sepanjang tahun keluar di bawah tagar # neurobugurt dan pelanggan geli. Secara total, pada 2017 dan awal 2018, kami menghasilkan lebih dari
18.000 neurobugurts , dengan rata-rata masing-masing 500 karakter. Selain itu, seluruh gerakan parodi publik muncul, para peserta yang menggambarkan neurobugur, secara acak menata ulang frase di beberapa tempat.

Bagian 9. Alih-alih kesimpulan
Dengan artikel ini saya ingin menunjukkan bahwa meskipun Anda tidak memiliki pengalaman dalam jaringan saraf, kesedihan ini bukan masalah. Anda tidak perlu bekerja di Stanford untuk melakukan hal-hal sederhana namun menarik dengan jaringan saraf. Semua peserta dalam proyek kami adalah siswa biasa dengan tugas, ijazah, pekerjaan mereka saat ini, tetapi tujuan umum memungkinkan kami untuk membawa proyek ke final. Berkat gagasan, perencanaan, dan energi para peserta, kami dapat memperoleh hasil yang waras pertama dalam waktu kurang dari sebulan setelah perumusan akhir gagasan (sebagian besar pekerjaan teknis dan organisasi jatuh pada liburan musim dingin 2017).
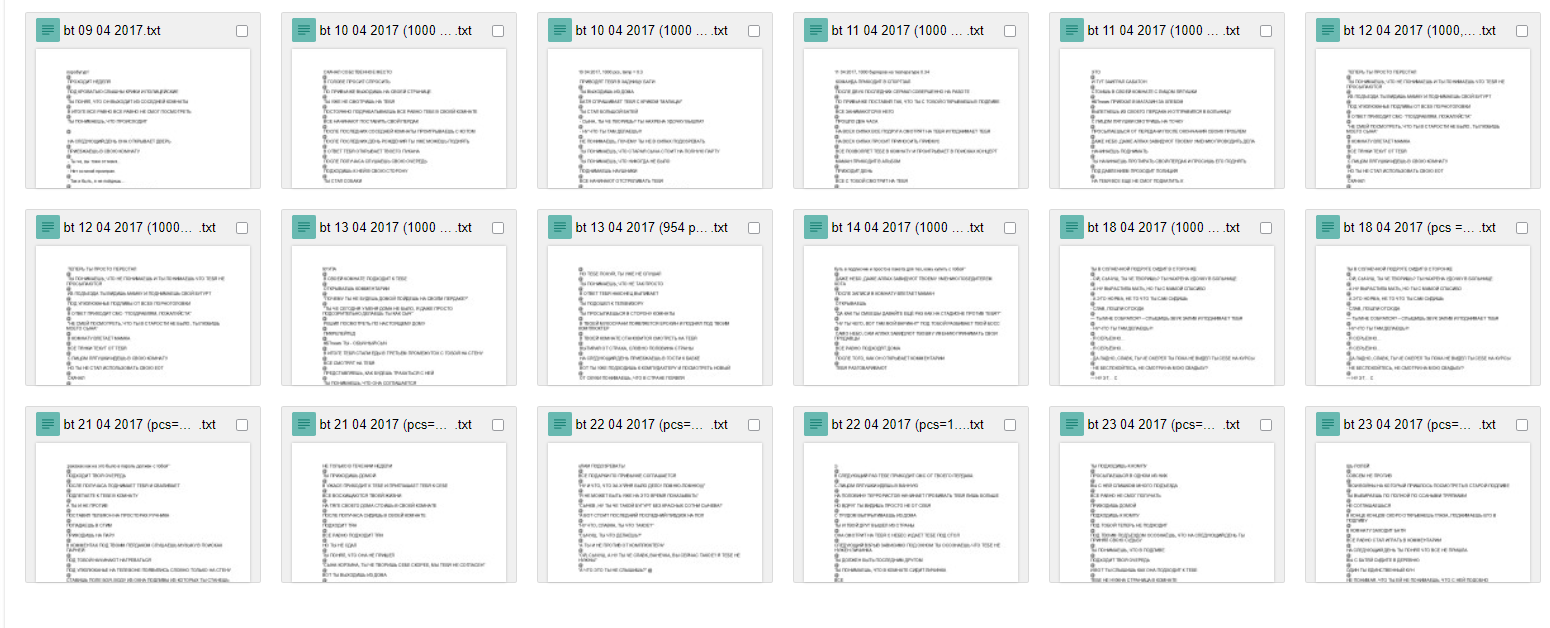 Lebih dari 18.000 buhur yang dihasilkan mesin
Lebih dari 18.000 buhur yang dihasilkan mesinSaya harap artikel ini membantu seseorang merencanakan proyek ambisius mereka sendiri dengan jaringan saraf. Saya meminta untuk tidak menghakimi dengan ketat, karena ini adalah artikel pertama saya tentang Habré. Jika Anda, seperti saya, penggemar ML, mari
berteman .