Beberapa waktu yang lalu, salah satu kolega saya mengatakan bahwa tempat di DC hampir habis, tidak ada tempat untuk meletakkan server, dan beban bertambah dan tidak jelas apa yang harus dilakukan, dan Anda mungkin harus mengubah semua server yang tersedia menjadi yang lebih kuat.
Pada waktu itu saya terlibat dalam tugas menyusun jadwal optimal, dan saya pikir - tetapi bagaimana jika kita menerapkan algoritma optimasi untuk meningkatkan pemanfaatan server di DC? Dari sinilah lahir proyek yang ingin saya tulis.
Untuk pengguna tingkat lanjut, saya akan segera mengatakan bahwa dalam artikel ini kita akan berbicara tentang pengemasan bin, dan untuk sisanya yang ingin mempelajari cara menghemat hingga 30% sumber daya server menggunakan perhitungan yang relatif sederhana, selamat datang di cat.
Jadi, kami memiliki DC dengan sekitar 100 server, yang menampung sekitar 7.000 mesin virtual. Apa yang ada di dalam mesin virtual - kita tidak tahu dan seharusnya tidak tahu. Kita perlu menempatkan mesin virtual di server untuk melakukan SLA dan pada saat yang sama menggunakan jumlah server minimum.
Kami tahu:
- daftar server
- jumlah sumber daya pada setiap server (waktu CPU, core CPU, RAM, disk, disk io, io jaringan).
- daftar mesin virtual (VM)
- jumlah sumber daya yang dikonsumsi oleh setiap mesin virtual (waktu CPU, inti CPU, RAM, disk, disk io, jaringan io).
- konsumsi sumber daya oleh sistem host di server.
Kita perlu mendistribusikan mesin virtual di antara server sehingga untuk setiap sumber daya di setiap server tidak melebihi jumlah sumber daya yang tersedia, dan pada saat yang sama menggunakan jumlah server minimum.
Tugas ini dalam literatur ilmiah disebut masalah pengemasan bin (bagaimana nantinya dalam bahasa Rusia?). Secara sederhana, ini adalah tugas tentang cara memasukkan kotak kecil dengan ukuran acak ke dalam kotak besar, dan pada saat yang sama menggunakan jumlah minimum kotak besar. Masalah yang terkenal dalam matematika, NP-complete, tepatnya diselesaikan hanya dengan pencarian lengkap, yang biayanya meningkat secara kombinasi.
Gambar di bawah menggambarkan esensi dari algoritma pengemasan bin untuk kasus satu dimensi:
 Fig. 1. Ilustrasi masalah pengemasan bin, penempatan tidak optimal
Fig. 1. Ilustrasi masalah pengemasan bin, penempatan tidak optimalPada gambar pertama, item entah bagaimana didistribusikan di antara keranjang dan 3 keranjang digunakan untuk menempatkannya.
 Fig. 2. Ilustrasi masalah pengemasan bin, penempatan optimal
Fig. 2. Ilustrasi masalah pengemasan bin, penempatan optimalGambar kedua menunjukkan distribusi optimal, yang hanya membutuhkan 2 keranjang.
Formulasi standar dari algoritma pengemasan bin juga mengasumsikan bahwa semua keranjang adalah sama. Server kami tidak sama, karena dibeli pada waktu yang berbeda dan konfigurasinya berbeda - jumlah core prosesor, memori, disk, daya prosesor yang berbeda.
Solusi suboptimal dapat diperoleh dengan menggunakan heuristik, algoritma genetika, pencarian pohon monte-carlo dan jaringan saraf yang dalam. Kami memutuskan pada algoritma heuristik BestFit, yang menyatu ke solusi yang tidak lebih dari 1,7 kali lebih buruk daripada yang optimal, serta pada beberapa variasi dari algoritma genetika. Di bawah ini saya akan memberikan hasil aplikasi mereka.
Tetapi pertama-tama, mari kita bahas apa yang harus dilakukan dengan metrik yang bervariasi waktu, seperti penggunaan CPU, disk io, io jaringan. Cara termudah adalah mengganti variabel metrik dengan konstanta. Tetapi bagaimana cara memilih nilai konstanta ini? Kami mengambil nilai maksimum metrik untuk beberapa periode karakteristik (sebelumnya menghaluskan outlier nilai-nilai). Minggu ternyata menjadi periode karakteristik dalam kasus kami, karena musiman utama dalam beban dikaitkan dengan hari kerja dan hari libur.
Dalam model ini, setiap mesin virtual dialokasikan strip sumber daya ukuran nilai sumber daya maksimum yang dikonsumsi, dan masing-masing VM dijelaskan oleh konstanta maks penggunaan CPU, RAM, disk, io diska maks, io jaringan maks.
Selanjutnya, kami menggunakan algoritma untuk menghitung pengepakan yang optimal dan mendapatkan peta lokasi server fisik VM.
Praktek menunjukkan bahwa jika Anda tidak meninggalkan margin tertentu untuk masing-masing sumber daya di server, maka ketika VM dialokasikan secara padat, server menjadi kelebihan beban. Karenanya, untuk penggunaan CPU, kami menyisakan margin 30%, untuk RAM 20%, untuk disk io - 20%, untuk jaringan io - 20%, batas ini dipilih secara empiris.
Kami juga memiliki beberapa jenis disk (SSD cepat dan HDD murah lambat), untuk setiap jenis disk kami mengambil metrik disk dan disk io secara terpisah, sehingga model akhir menjadi agak lebih rumit dan memiliki lebih banyak dimensi.
Hasil optimalisasi penempatan VM ditunjukkan pada diagram:
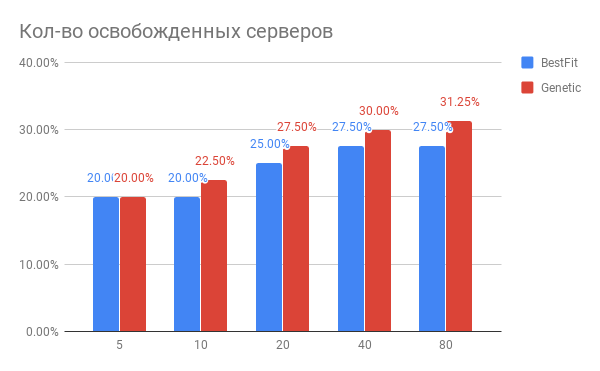 Fig. 3. Hasil mengoptimalkan penempatan VM di server
Fig. 3. Hasil mengoptimalkan penempatan VM di serverHorizontal - jumlah server yang telah dioptimalkan, vertikal - jumlah server yang dibebaskan untuk heuristik BestFit dan untuk algoritma genetika.
Kesimpulan apa yang bisa ditarik dari diagram?
- Untuk tugas saat ini, Anda dapat menggunakan server yang lebih sedikit 20-30%.
- Semakin banyak server yang Anda optimalkan pada suatu waktu, semakin banyak Anda menang dalam%, dengan jumlah server 40 dan di atasnya, terjadi kejenuhan.
- Algoritma genetik sedikit lebih unggul dari BestFit heuristik. Jika kami ingin lebih meningkatkan hasil kami, kami akan menggali ke arah ini.
Apa masalah lain yang muncul dalam praktik?
- Jika Anda ingin mengguncang sekitar 100 server dengan 7.000 mesin virtual, maka volume migrasi akan sangat signifikan, sehingga seluruh ide tidak akan terealisasi. Tetapi jika Anda bekerja dengan kelompok 20-40 server secara berurutan, maka efek yang akan Anda dapatkan hampir sama, tetapi jumlah migrasi akan jauh lebih sedikit. Dan Anda dapat mengoptimalkan bagian DC Anda.
- Jika Anda harus melakukan migrasi langsung, maka Anda mungkin menghadapi situasi di mana migrasi tidak dapat berakhir. Ini berarti bahwa di dalam VM terdapat penulisan intensif ke disk dan / atau keadaan memori berubah, dan status VM antara replika lama dan baru tidak punya waktu untuk menyinkronkan sampai keadaan replika lama berubah. Dalam hal ini, Anda perlu menentukan sebelumnya mesin VM tersebut dan menandainya sebagai tidak bergerak. Pada gilirannya, ini membutuhkan modifikasi algoritma pengoptimalan. Apa yang menyenangkan adalah bahwa keuntungan total praktis tidak tergantung pada jumlah mesin seperti itu, jika tidak ada lebih dari 10-15% dari jumlah total VM.
Bagaimana server memuat perubahan setelah mengoptimalkan penempatan VM?
Oke, kami telah mengoptimalkan penempatan VM. Mungkin status baru yang dihasilkan sangat rapuh dalam kaitannya dengan peningkatan beban? Mungkin server berjalan ke batas dan peningkatan beban apa pun akan membunuh mereka?
Kami membandingkan pemanfaatan sumber daya server sebelum pengoptimalan dan setelah untuk periode 1 minggu. Apa yang terjadi ditunjukkan pada Gambar 2:
 Fig. 4. Ubah beban CPU setelah mengoptimalkan alokasi VM
Fig. 4. Ubah beban CPU setelah mengoptimalkan alokasi VMMenurut penggunaan CPU: rata-rata penggunaan CPU telah meningkat dari 10% menjadi hanya 18%. Yaitu kami memiliki margin tiga kali kinerja CPU, sementara server akan tetap berada di zona yang disebut "hijau".
Bagaimana ini dilakukan dalam perangkat lunak?
Kami mengumpulkan metrik yang kami butuhkan di Yandex.ClickHouse (kami mencoba InfluxDB, tetapi pada volume data kami kueri dengan agregasi di dalamnya dilakukan terlalu lambat) dengan frekuensi 30 detik. Dari sana, tugas menghitung keadaan optimal membaca metrik, menghitung konsumsi maksimum dari mereka, dan menghasilkan tugas perhitungan yang dimasukkan ke dalam antrian. Segera setelah tugas perhitungan selesai, tes dijalankan untuk memverifikasi bahwa hasilnya tidak melampaui batas yang ditentukan.
Adakah yang sudah melakukan ini?
Dari yang diketahui oleh kami, algoritma yang sama ada di dalam VMware vSphere dan Nutanix dan muncul di dalam OpenStack (proyek OpenStack Watcher).
Apakah mungkin melakukan lebih baik?
Ya kamu bisa. Pada artikel selanjutnya saya akan memberi tahu Anda cara mengemas mesin virtual lebih padat tanpa melanggar SLA, dan mengapa neuron diperlukan untuk ini.