
Di bidang pengenalan emosi, suara adalah sumber data emosi terpenting kedua setelah wajah. Suara dapat ditandai oleh beberapa parameter. Nada suara adalah salah satu karakteristik utama tersebut, namun, di bidang teknologi akustik, lebih tepat menyebut parameter ini sebagai frekuensi fundamental.
Frekuensi nada dasar berhubungan langsung dengan apa yang kita sebut intonasi. Dan intonasi, misalnya, dikaitkan dengan karakteristik suara yang ekspresif secara emosional.
Namun demikian, menentukan frekuensi nada dasar bukanlah tugas sepele dengan nuansa yang menarik. Pada artikel ini, kita akan membahas fitur-fitur algoritma untuk penentuannya dan membandingkan solusi yang ada dengan contoh-contoh rekaman audio tertentu.
PendahuluanUntuk memulainya, mari kita ingat apa, pada intinya, frekuensi nada dasar dan dalam tugas apa yang mungkin diperlukan.
Frekuensi fundamental , yang juga disebut sebagai CHOT, Fundamental Frequency atau F0, adalah frekuensi pita suara ketika mereka mengucapkan suara bersuara. Ketika mengucapkan suara non-nada (tidak disuarakan), misalnya, berbicara dalam bisikan atau mengucapkan suara mendesis dan bersiul, ligamen tidak ragu, yang berarti karakteristik ini tidak relevan bagi mereka.
* Harap diperhatikan bahwa pembagian ke dalam bunyi nada dan non-nada tidak setara dengan pembagian ke dalam vokal dan konsonan.
Variabilitas frekuensi nada dasar cukup besar, dan dapat sangat bervariasi tidak hanya di antara orang-orang (untuk suara laki-laki rata-rata lebih rendah frekuensinya adalah 70-200 Hz, dan untuk suara wanita dapat mencapai 400 Hz), tetapi juga untuk satu orang, terutama dalam pidato emosional .
Penentuan frekuensi nada dasar digunakan untuk menyelesaikan berbagai masalah:
- Pengakuan emosi, seperti yang kami katakan di atas;
- Penentuan jenis kelamin;
- Saat memecahkan masalah segmentasi audio dengan banyak suara atau membagi pidato menjadi frasa;
- Dalam kedokteran, menentukan karakteristik patologis suara (misalnya, menggunakan parameter akustik Jitter dan Shimmer). Misalnya, identifikasi tanda-tanda penyakit Parkinson [ 1 ]. Jitter dan Shimmer juga dapat digunakan untuk mengenali emosi [ 2 ].
Namun, ada sejumlah kesulitan dalam menentukan F0. Sebagai contoh, seringkali mungkin untuk mengacaukan F0 dengan harmonik, yang dapat mengarah pada apa yang disebut efek penggandaan pitch / separasi pitch [
3 ]. Dan dalam rekaman audio berkualitas buruk, F0 cukup sulit untuk dihitung, karena puncak yang diinginkan pada frekuensi rendah hampir menghilang.
Omong-omong, ingat cerita
Laurel dan Yanny ? Perbedaan kata-kata yang didengar orang saat mendengarkan rekaman audio yang sama, muncul justru karena perbedaan persepsi F0, yang dipengaruhi oleh banyak faktor: usia pendengar, tingkat kelelahan, dan perangkat pemutaran. Jadi, ketika mendengarkan rekaman di speaker dengan reproduksi berkualitas tinggi frekuensi rendah, Anda akan mendengar Laurel, dan dalam sistem audio di mana frekuensi rendah direproduksi dengan buruk, Yanny. Efek transisi dapat dilihat pada satu perangkat, misalnya di
sini . Dan dalam
artikel ini, jaringan saraf berperan sebagai pendengar. Di
artikel lain
, Anda bisa membaca bagaimana fenomena Yanny / Laurel dijelaskan dalam istilah pembentukan ucapan.
Karena analisis terperinci dari semua metode untuk menentukan F0 akan terlalu banyak, artikel tersebut bersifat ikhtisar dan dapat membantu menavigasi topik.
Metode untuk menentukan F0Metode untuk menentukan F0 dapat dibagi menjadi tiga kategori: berdasarkan dinamika waktu sinyal, atau domain waktu; berdasarkan pada struktur frekuensi, atau domain frekuensi, serta metode gabungan. Kami menyarankan Anda membiasakan diri dengan
artikel ulasan tentang topik tersebut, di mana metode yang ditunjukkan untuk mengekstraksi F0 dianalisis secara rinci.
Perhatikan bahwa salah satu algoritma yang dibahas terdiri dari 3 langkah utama:
Pra-pemrosesan (memfilter sinyal, membaginya menjadi bingkai)
Cari kemungkinan nilai F0 (kandidat)
Pelacakan adalah pilihan jalur lintasan F0 yang paling memungkinkan (karena untuk setiap saat kami memiliki beberapa kandidat yang bersaing, kami perlu menemukan jalur yang paling memungkinkan di antara mereka)
Domain waktuKami menguraikan beberapa poin umum. Sebelum menerapkan metode waktu-domain, sinyal disaring terlebih dahulu, hanya menyisakan frekuensi rendah. Ambang batas ditetapkan - frekuensi minimum dan maksimum, misalnya dari 75 hingga 500 Hz. Penentuan F0 dibuat hanya untuk daerah dengan ucapan harmonis, karena untuk jeda atau suara bising ini tidak hanya tidak berarti, tetapi juga dapat menyebabkan kesalahan dalam bingkai yang berdekatan ketika interpolasi dan / atau pemulusan diterapkan. Panjang bingkai dipilih sehingga mengandung setidaknya tiga periode.
Metode utama, atas dasar di mana seluruh keluarga algoritma kemudian muncul, adalah autokorelasi. Pendekatannya cukup sederhana - perlu untuk menghitung fungsi autokorelasi dan mengambil maksimum pertama. Ini akan menampilkan komponen frekuensi paling jelas dalam sinyal. Apa yang bisa menjadi kesulitan dalam hal menggunakan autokorelasi dan mengapa jauh dari selalu bahwa maksimum pertama akan sesuai dengan frekuensi yang diinginkan? Bahkan di dekat dengan kondisi ideal pada rekaman berkualitas tinggi, metode ini mungkin keliru karena struktur sinyal yang kompleks. Dalam kondisi yang mendekati real, di mana, antara lain, kita mungkin menemukan hilangnya puncak yang diinginkan dalam rekaman bising atau rekaman kualitas awalnya rendah, jumlah kesalahan meningkat tajam.
Terlepas dari kesalahan, metode autokorelasi cukup mudah dan menarik karena kesederhanaan dan logika dasarnya, yang mengapa itu diambil sebagai dasar dalam banyak algoritma, termasuk YIN. Bahkan nama algoritme merujuk kita pada keseimbangan antara kenyamanan dan ketidaktepatan metode autokorelasi: "Nama YIN dari '' yin '' dan '' yang" dari filosofi oriental menyinggung interaksi antara autokorelasi dan pembatalan yang melibatkannya. " [
4 ]
Para pencipta YIN mencoba untuk memperbaiki kelemahan dari pendekatan autokorelasi. Perubahan pertama adalah penggunaan fungsi Diferensiasi Rata-Rata Kumulatif Rata-rata, yang seharusnya mengurangi sensitivitas terhadap modulasi amplitudo, membuat puncak lebih jelas:
\ mulai {persamaan}
d'_t (\ tau) =
\ begin {cases}
1, & \ tau = 0 \\
d_t (\ tau) \ bigg / \ bigg [\ frac {1} {\ tau} \ jumlah \ limit_ {j = 1} ^ {\ tau} d_t (j) \ bigg], & \ text {jika tidak}
\ end {cases}
\ end {persamaan}
YIN juga mencoba menghindari kesalahan yang terjadi dalam kasus di mana panjang fungsi jendela tidak sepenuhnya dibagi dengan periode osilasi. Untuk ini, interpolasi minimum parabola digunakan. Pada langkah terakhir pemrosesan sinyal audio, fungsi Estimasi Lokal Terbaik dijalankan untuk mencegah lonjakan tajam dalam nilai (apakah itu baik atau buruk - ini adalah titik diperdebatkan).
Frekuensi-domainJika kita berbicara tentang domain frekuensi, maka struktur harmonik dari sinyal muncul kedepan, yaitu, kehadiran puncak spektral pada frekuensi yang merupakan kelipatan F0. Anda dapat "menutup" pola periodik ini menjadi puncak yang jelas menggunakan analisis cepstral. Cepstrum - Transformasi Fourier dari logaritma spektrum daya; puncak cepstral berhubungan dengan komponen spektrum paling periodik (orang dapat membacanya di
sini dan di
sini ).
Metode Hibrida untuk Menentukan F0Algoritme berikutnya, yang perlu ditelusuri lebih detail, memiliki nama yang dapat berbicara YAAPT - Algoritma Pitch Tracking Lainnya - dan pada kenyataannya adalah hybrid, karena menggunakan informasi frekuensi dan waktu. Deskripsi lengkap ada di
artikel , di sini kami hanya menjelaskan tahap utama.
 Gambar 1. Diagram algoritma YAAPTalgo ( tautan )
Gambar 1. Diagram algoritma YAAPTalgo ( tautan ) .
YAAPT terdiri dari beberapa langkah utama, yang pertama adalah preprocessing. Pada tahap ini, nilai-nilai sinyal asli dikuadratkan, dan versi kedua dari sinyal diperoleh. Langkah ini mengejar tujuan yang sama dengan Fungsi Perbedaan Normalisasi Rata-Rata Kumulatif di YIN - penguatan dan pemulihan puncak otokorelasi yang “macet”. Kedua versi sinyal disaring - biasanya mereka mengambil kisaran 50-1500 Hz, kadang-kadang 50-900 Hz.
Kemudian, lintasan dasar F0 dihitung dari spektrum sinyal yang dikonversi. Kandidat untuk F0 ditentukan menggunakan fitur Spectral Harmonics Correlation (SHC).
\ mulai {persamaan}
SHC (t, f) = \ jumlah \ limit_ {f '= - WL / 2} ^ {WL / 2} \ prod \ limit_ {r = 1} ^ {NH + 1} S (t, rf + f')
\ end {persamaan}
di mana S (t, f) adalah spektrum magnitudo untuk frame t dan frekuensi f, WL adalah panjang jendela dalam Hz, NH adalah jumlah harmonik (penulis merekomendasikan menggunakan tiga harmonik pertama). Kekuatan spektral juga digunakan untuk menentukan frame bersuara-tidak bersuara, setelah lintasan yang paling optimal dicari, dan kemungkinan penggandaan pitch / separuh pitch diperhitungkan [
3 , Bagian II, C].
Lebih lanjut, kandidat untuk F0 ditentukan untuk sinyal awal dan yang dikonversi, dan alih-alih fungsi autokorelasi, Normalized Cross Correlation (NCCF) digunakan di sini.
\ mulai {persamaan}
NCCF (m) = \ frac {\ sum \ limit_ {n = 0} ^ {Nm-1} x (n) * x (n + m)} {\ sqrt {\ sum \ limit_ {n = 0} ^ { Nm-1} x ^ 2 (n) * \ jumlah \ limit_ {n = 0} ^ {Nm-1} x ^ 2 (n + m)}} \ text {,} \ hspace {0.3cm} 0 <m <M_ {0}
\ end {persamaan}
Langkah selanjutnya adalah mengevaluasi semua kandidat yang mungkin dan menghitung signifikansi, atau bobot (prestasi) mereka. Bobot kandidat yang diperoleh dari sinyal audio tidak hanya bergantung pada amplitudo puncak NCCF, tetapi juga pada kedekatannya dengan lintasan F0 yang ditentukan dari spektrum. Artinya, domain frekuensi dianggap kasar dalam hal akurasi, tetapi stabil [
3 , Bagian II, D].
Kemudian, untuk semua pasangan kandidat yang tersisa, matriks Biaya Transisi dihitung - harga transisi, di mana mereka akhirnya menemukan lintasan optimal [
3 , Bagian II, E].
ContohnyaSekarang kami menerapkan semua algoritma di atas untuk rekaman audio tertentu. Sebagai titik awal, kita akan menggunakan
Praat , alat yang sangat mendasar bagi banyak sarjana pidato. Dan kemudian dengan Python kita akan melihat implementasi YIN dan YAAPT dan kita akan membandingkan hasil yang diterima.
Sebagai materi audio, Anda dapat menggunakan audio yang tersedia. Kami mengambil beberapa kutipan dari basis data
RAMAS kami -
set data multimoda yang dibuat dengan partisipasi aktor VGIK. Anda juga dapat menggunakan materi dari database terbuka lainnya, seperti
LibriSpeech atau
RAVDESS .
Sebagai contoh ilustratif, kami mengambil kutipan dari beberapa rekaman dengan suara pria dan wanita, keduanya berwarna netral dan emosional, dan untuk kejelasan, kami menggabungkannya menjadi satu
rekaman . Mari kita lihat sinyal kita, spektogramnya, intensitasnya (warna oranye), dan F0 (warna biru). Di Praat, ini dapat dilakukan dengan menggunakan Ctrl + O (Buka - Baca dari file) dan kemudian tombol Lihat & Edit.
 Gambar 2. Spectrogram, intensitas (warna oranye), F0 (warna biru) dalam Praat.
Gambar 2. Spectrogram, intensitas (warna oranye), F0 (warna biru) dalam Praat.Audio menunjukkan dengan sangat jelas bahwa dalam pidato emosional, nada meningkat pada pria dan wanita. Pada saat yang sama, F0 untuk ucapan pria yang emosional dapat dibandingkan dengan F0 dari suara wanita.
PelacakanPilih jangka waktu Analisis - ke Pitch (ac) di menu Praat, yaitu definisi F0 menggunakan autokorelasi. Sebuah jendela untuk pengaturan parameter akan muncul di mana dimungkinkan untuk menetapkan 3 parameter untuk menentukan kandidat untuk F0 dan 6 parameter lainnya untuk algoritma path-finder, yang membangun jalur F0 paling mungkin di antara semua kandidat.
Banyak parameter (dalam Praat, uraiannya juga ada di tombol Bantuan)- Ambang batas - ambang amplitudo relatif dari sinyal untuk menentukan diam, nilai standarnya adalah 0,03.
- Ambang pengisi suara - bobot kandidat yang tidak disuarakan, nilai maksimumnya adalah 1. Semakin tinggi parameter ini, semakin banyak frame akan didefinisikan sebagai tidak disuarakan, artinya, tidak mengandung suara nada. Dalam bingkai ini, F0 tidak akan ditentukan. Nilai parameter ini adalah ambang untuk puncak fungsi autokorelasi. Nilai standarnya adalah 0,45.
- Biaya oktaf - menentukan berapa banyak bobot yang dimiliki kandidat frekuensi tinggi dalam kaitannya dengan frekuensi rendah. Semakin tinggi nilainya, semakin banyak preferensi diberikan kepada kandidat frekuensi tinggi. Nilai standarnya adalah 0,01 per oktaf.
- Biaya lompat oktaf - dengan peningkatan koefisien ini, jumlah transisi lompatan tajam antara nilai F0 berturut-turut menurun. Nilai standarnya adalah 0,35.
- Biaya yang disuarakan / tidak disuarakan - meningkatkan koefisien ini mengurangi jumlah transisi yang disuarakan / tidak disuarakan. Nilai standarnya adalah 0,14.
- Plafon lapangan (Hz) - kandidat di atas frekuensi ini tidak dipertimbangkan. Nilai standarnya adalah 600 Hz.
Penjelasan terperinci dari algoritma dapat ditemukan di
artikel 1993.
Seperti apa hasil pelacak (path-finder) dapat dilihat dengan mengklik OK dan kemudian melihat (Lihat & Edit) file Pitch yang dihasilkan. Dapat dilihat bahwa selain lintasan yang dipilih, masih ada kandidat yang cukup signifikan dengan frekuensi yang lebih rendah.
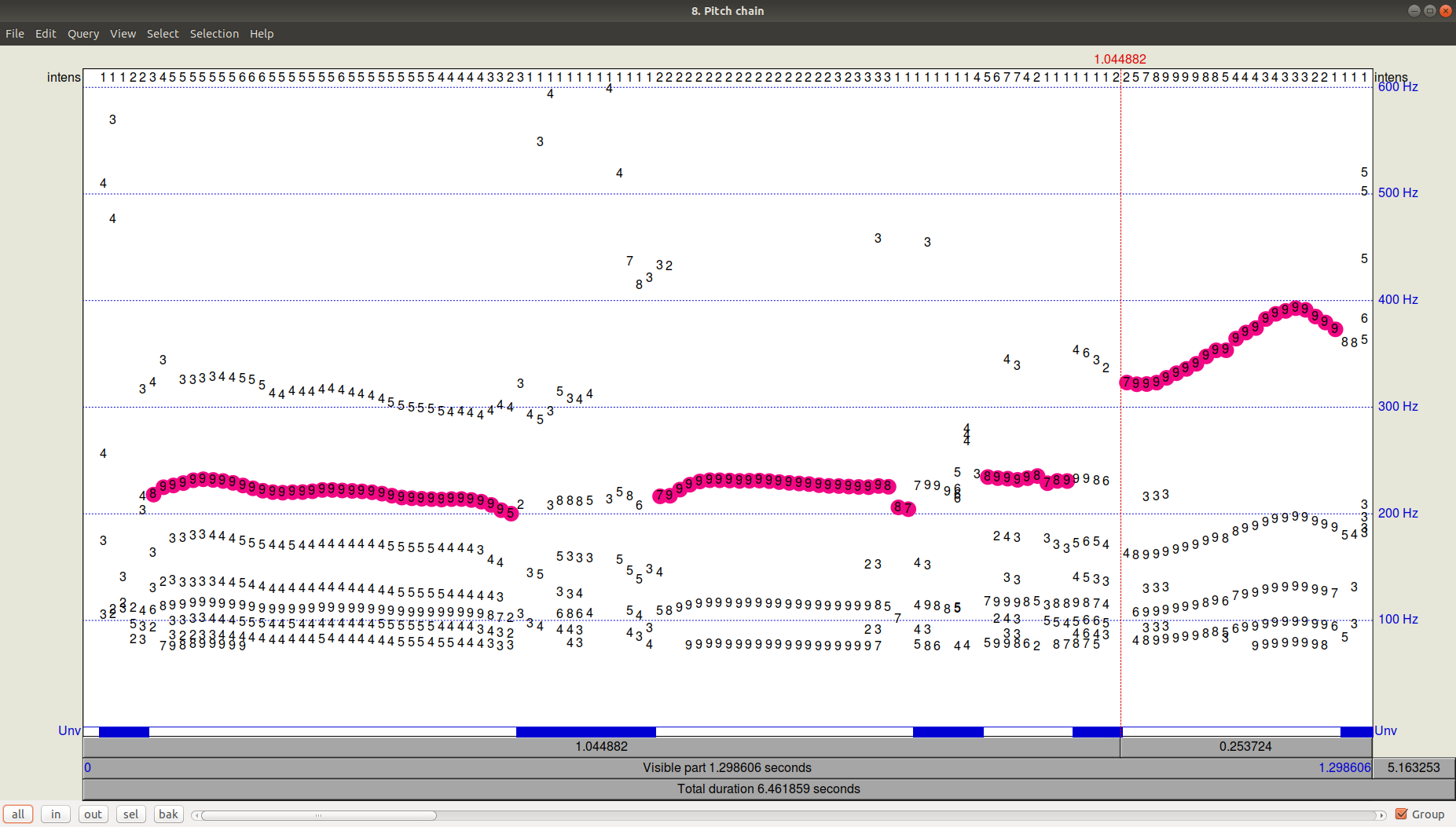 Gambar 3. PitchPath untuk 1,3 detik pertama perekaman audio.Tapi bagaimana dengan Python?
Gambar 3. PitchPath untuk 1,3 detik pertama perekaman audio.Tapi bagaimana dengan Python?Mari kita ambil dua perpustakaan yang menawarkan pelacakan pitch -
aubio , di mana algoritma default adalah YIN, dan perpustakaan
AMFM_decompsition , yang memiliki implementasi algoritma YAAPT. Dalam file terpisah (file
PraatPitch.txt ),
masukkan nilai F0 dari Praat (ini dapat dilakukan secara manual: pilih file suara, klik Lihat & Edit, pilih seluruh file dan pilih daftar Pitch-Pitch di menu atas).
Sekarang bandingkan hasil untuk ketiga algoritma (YIN, YAAPT, Praat).
Banyak kodeimport amfm_decompy.basic_tools as basic import amfm_decompy.pYAAPT as pYAAPT import matplotlib.pyplot as plt import numpy as np import sys from aubio import source, pitch
 Gambar 4. Perbandingan pengoperasian algoritma YIN, YAAPT dan Praat.
Gambar 4. Perbandingan pengoperasian algoritma YIN, YAAPT dan Praat.Kita melihat bahwa dengan parameter default, YIN cukup tersingkir, mendapatkan lintasan yang sangat datar dengan nilai lebih rendah dari Praat dan benar-benar kehilangan transisi antara suara pria dan wanita, serta antara pidato emosional dan non-emosional.
YAAPT memangkas nada bicara perempuan yang sangat tinggi, tetapi secara keseluruhan berhasil dengan lebih baik. Karena fitur-fiturnya yang spesifik, YAAPT bekerja lebih baik - tentu saja, tidak mungkin untuk langsung menjawab, tetapi dapat diasumsikan bahwa peran tersebut dimainkan dengan mendapatkan kandidat dari tiga sumber dan perhitungan bobot mereka yang lebih ketat daripada di YIN.
KesimpulanKarena pertanyaan menentukan frekuensi nada dasar (F0) dalam satu bentuk atau lainnya muncul sebelum hampir semua orang yang bekerja dengan suara, ada banyak cara untuk menyelesaikannya. Pertanyaan tentang keakuratan dan fitur yang diperlukan dari bahan audio dalam setiap kasus menentukan seberapa hati-hati diperlukan untuk memilih parameter, atau dalam kasus lain, Anda dapat membatasi diri Anda pada solusi dasar seperti YAAPT. Mengambil Praat sebagai standar algoritme untuk pemrosesan wicara (namun demikian, sejumlah besar peneliti menggunakannya), kita dapat menyimpulkan bahwa YAAPT, menurut perkiraan pertama, lebih andal dan akurat daripada YIN, meskipun contoh kami ternyata rumit untuknya.
Diposting oleh
Eva Kazimirova, Peneliti Laboratorium Neurodata, Spesialis Pemrosesan Bicara.
Offtop : Apakah Anda suka artikel ini? Faktanya, kami memiliki banyak tugas menarik dalam ML, matematika dan pemrograman, dan kami membutuhkan otak. Apakah kamu penasaran? Datanglah ke kami! Email: hr@neurodatalab.com
Referensi- Rusz, J., Cmejla, R., Ruzickova, H., Ruzicka, E. Pengukuran akustik kuantitatif untuk karakterisasi gangguan bicara dan suara pada penyakit Parkinson awal yang tidak diobati. Jurnal Masyarakat Akustik Amerika, vol. 129, edisi 1 (2011), hlm. 350-367. Akses
- Farrús, M., Hernando, J., Ejarque, P. Jitter dan Pengukuran Shimmer untuk Pengenalan Pembicara. Prosiding Konferensi Tahunan Asosiasi Komunikasi Pidato Internasional, INTERSPEECH, vol. 2 (2007), hlm. 1153-1156. Akses
- Zahorian, S., Hu, HA. Metode spektral / temporal untuk pelacakan frekuensi fundamental yang kuat. Jurnal Masyarakat Akustik Amerika, vol. 123, edisi 6 (2008), hlm. 4559-4571. Akses
- De Cheveigné, A., Kawahara, H. YIN, penaksir frekuensi dasar untuk bicara dan musik. Jurnal Masyarakat Akustik Amerika, vol. 111, edisi 4 (2002), hlm. 1917-1930. Akses