
"Pola" dalam konteks C ++ biasanya merujuk pada konstruksi bahasa yang sangat spesifik. Ada templat sederhana yang menyederhanakan bekerja dengan jenis kode yang sama - ini adalah templat kelas dan fungsi. Jika templat memiliki salah satu parameter dengan sendirinya, maka ini dapat dikatakan sebagai templat orde kedua dan mereka menghasilkan templat lain bergantung pada parameternya. Tetapi bagaimana jika kemampuan mereka tidak cukup dan lebih mudah untuk segera menghasilkan teks sumber? Banyak kode sumber?
Penggemar tata letak Python dan HTML sudah terbiasa dengan alat (mesin, perpustakaan) untuk bekerja dengan templat teks yang disebut
Jinja2 . Pada input, mesin ini menerima file templat di mana teks dapat dicampur dengan struktur kontrol, outputnya adalah teks bersih, di mana semua struktur kontrol diganti dengan teks sesuai dengan parameter yang ditentukan dari luar (atau dari dalam). Secara kasar, ini adalah sesuatu seperti halaman ASP (atau C ++ - preprocessor), hanya bahasa markup yang berbeda.
Hingga saat ini, implementasi mesin ini hanya untuk Python. Sekarang untuk C ++. Tentang bagaimana dan mengapa itu terjadi, dan akan dibahas dalam artikel.
Mengapa saya mengambil ini
Memang kenapa? Lagi pula, ada Python, untuk itu - implementasi yang sangat baik, banyak fitur, spesifikasi lengkap untuk bahasa. Ambil dan gunakan! Saya tidak suka Python - Anda dapat mengambil
Jinja2CppLight atau
inja , sebagian port Jinja2 di C ++. Anda dapat, pada akhirnya, mengambil port C ++ {{
Kumis }}. Iblis, seperti biasa, dalam perinciannya. Jadi, katakanlah, saya membutuhkan fungsionalitas filter dari Jinja2 dan kemampuan konstruk extends, yang memungkinkan Anda membuat templat yang dapat diperluas (dan juga makro dan sertakan, tetapi ini nanti). Dan tidak ada implementasi yang disebutkan mendukung ini. Bisakah saya melakukannya tanpa semua ini? Juga pertanyaan yang bagus. Nilailah sendiri. Saya punya
proyek yang tujuannya adalah untuk membuat generator kode boilerplate C ++ - to-C ++. Autogenerator ini menerima, katakanlah, file header yang ditulis secara manual dengan struktur atau enum, dan menghasilkan berdasarkan fungsi serialisasi / deserialisasi atau, katakanlah, mengonversi elemen enum ke string (dan sebaliknya). Anda dapat mendengarkan detail lebih lanjut tentang utilitas ini dalam laporan saya di
sini (ind) atau di
sini (rus).
Jadi, tugas khas diselesaikan dalam proses mengerjakan utilitas adalah pembuatan file header, yang masing-masing memiliki header (dengan ifdefs dan termasuk), tubuh dengan konten utama dan catatan kaki. Selain itu, konten utama adalah deklarasi yang dihasilkan dijejali oleh namespace. Dalam eksekusi C ++, kode untuk membuat file header seperti itu terlihat seperti ini (dan bukan itu saja):
Banyak kode C ++void Enum2StringGenerator::WriteHeaderContent(CppSourceStream &hdrOs) { std::vector<reflection::EnumInfoPtr> enums; WriteNamespaceContents(hdrOs, m_namespaces.GetRootNamespace(), [this, &enums](CppSourceStream &os, reflection::NamespaceInfoPtr ns) { for (auto& enumInfo : ns->enums) { WriteEnumToStringConversion(os, enumInfo); WriteEnumFromStringConversion(os, enumInfo); enums.push_back(enumInfo); } }); hdrOs << "\n\n"; { out::BracedStreamScope flNs("\nnamespace flex_lib", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline const char* Enum2String($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline $enumFullQualifiedName$ String2Enum<$enumFullQualifiedName$>(const char* itemName)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::StringTo$enumName$(itemName);"; } } } { out::BracedStreamScope flNs("\nnamespace std", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); out::BracedStreamScope body("inline std::string to_string($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } } }
Dari sini Selain itu, kode ini sedikit berubah dari file ke file. Tentu saja, Anda dapat menggunakan format dentang untuk memformat. Tetapi ini tidak membatalkan sisa pekerjaan manual untuk menghasilkan teks sumber.
Dan kemudian pada suatu saat yang baik, saya menyadari bahwa hidup saya harus disederhanakan. Saya tidak mempertimbangkan opsi untuk mengacaukan bahasa scripting lengkap karena kompleksitas mendukung hasil akhir. Tetapi untuk menemukan mesin templat yang cocok - mengapa tidak? Saya merasa berguna untuk mencari, saya menemukannya, kemudian saya menemukan spesifikasi Jinja2 dan menyadari bahwa inilah yang saya butuhkan. Karena sesuai dengan spesifikasi ini, template untuk menghasilkan header akan terlihat seperti ini:
{% extends "header_skeleton.j2tpl" %} {% block generator_headers %} #include <flex_lib/stringized_enum.h> #include <algorithm> #include <utility> {% endblock %} {% block namespaced_decls %}{{super()}}{% endblock %} {% block namespace_content %} {% for enum in ns.enums | sort(attribute="name") %} {% set enumName = enum.name %} {% set scopeSpec = enum.scopeSpecifier %} {% set scopedName = scopeSpec ~ ('::' if scopeSpec) ~ enumName %} {% set prefix = (scopedName + '::') if not enumInfo.isScoped else (scopedName ~ '::' ~ scopeSpec ~ ('::' if scopeSpec)) %} inline const char* {{enumName}}ToString({{scopedName}} e) { switch (e) { {% for itemName in enum.items | map(attribute="itemName") | sort%} case {{prefix}}{{itemName}}: return "{{itemName}}"; {% endfor %} } return "Unknown Item"; } inline {{scopedName}} StringTo{{enumName}}(const char* itemName) { static std::pair<const char*, {{scopedName}}> items[] = { {% for itemName in enum.items | map(attribute="itemName") | sort %} {"{{itemName}}", {{prefix}}{{itemName}} } {{',' if not loop.last }} {% endfor %} }; {{scopedName}} result; if (!flex_lib::detail::String2Enum(itemName, items, result)) flex_lib::bad_enum_name::Throw(itemName, "{{enumName}}"); return result; } {% endfor %}{% endblock %} {% block global_decls %} {% for ns in [rootNamespace] recursive %} {% for enum in ns.enums %} template<> inline const char* flex_lib::Enum2String({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } template<> inline {{enum.fullQualifiedName}} flex_lib::String2Enum<{{enum.fullQualifiedName}}>(const char* itemName) { return {{enum.namespaceQualifier}}::StringTo{{enum.name}}(itemName); } inline std::string to_string({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } {% endfor %} {{loop(ns.namespaces)}} {% endfor %} {% endblock %}
Dari sini
Hanya ada satu masalah: tidak satu pun dari mesin yang saya temukan mendukung seluruh rangkaian fitur yang saya butuhkan. Yah, tentu saja, semua orang memiliki
cacat fatal standar. Saya berpikir sedikit dan memutuskan bahwa dunia lain tidak akan menjadi lebih buruk dari implementasi mesin template lainnya. Selain itu, menurut perkiraan, fungsi dasar tidak begitu sulit untuk diimplementasikan. Lagi pula, sekarang di C ++ ada regexp's!
Dan proyek
Jinja2Cpp muncul . Dengan mengorbankan kompleksitas penerapan fungsionalitas dasar (sangat mendasar), saya hampir menebak. Secara keseluruhan, saya melewatkan tepat koefisien Ko kuadrat: saya butuh waktu kurang dari tiga bulan untuk menulis semua yang saya butuhkan. Tetapi ketika semuanya selesai, selesai dan dimasukkan ke dalam "Programmer Otomatis" - Saya menyadari bahwa saya mencoba tidak sia-sia. Bahkan, utilitas pembuatan kode menerima bahasa scripting yang kuat dikombinasikan dengan template, yang membuka peluang pengembangan yang sama sekali baru untuk itu.
NB: Saya punya ide untuk mengencangkan Python (atau Lua). Tapi tidak ada mesin skrip lengkap yang ada memecahkan masalah "di luar kotak" tentang menghasilkan teks dari template. Artinya, Python masih harus mengacaukan Jinja2 yang sama, tetapi untuk Lua, cari sesuatu yang berbeda. Mengapa saya memerlukan tautan ekstra ini?
Implementasi Parser
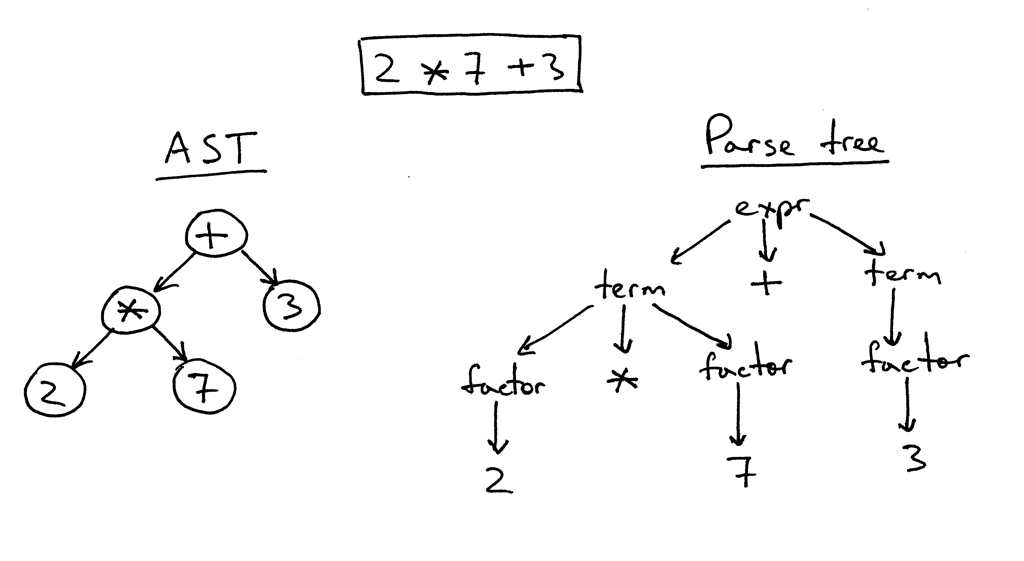
Gagasan di balik struktur template Jinja2 cukup sederhana. Jika ada sesuatu dalam teks yang dilampirkan dalam sepasang "{{" / "}}", maka ini adalah "sesuatu" - ekspresi yang harus dievaluasi, dikonversi ke representasi teks dan dimasukkan ke dalam hasil akhir. Di dalam pasangan "{%" / "%}" adalah operator seperti untuk, jika, set, dll. Nah, di "{#" / "#}" ada komentar. Setelah mempelajari implementasi Jinja2CppLight, saya memutuskan bahwa mencoba mencari semua struktur kontrol ini secara manual dalam teks templat bukanlah ide yang sangat bagus. Karena itu, saya mempersenjatai diri dengan regexp yang cukup sederhana: (((\ {\ {) | (\} \}) | (\ {%) | (% \}) | (\ {#) | (# \}) | (\ n)), dengan bantuannya ia memecah teks menjadi fragmen yang diperlukan. Dan menyebutnya fase parsing kasar. Pada tahap awal pekerjaan, ide tersebut menunjukkan keefektifannya (ya, sebenarnya, itu masih terlihat), tetapi, dengan cara yang baik, itu akan perlu di refactored di masa depan, karena sekarang pembatasan kecil dikenakan pada teks templat: escaping pairs "{{" dan "}}" dalam teks juga diproses "dahi".
Pada fase kedua, hanya apa yang ada di dalam "kurung" diuraikan secara rinci. Dan di sini saya harus mengotak-atik. Dengan inja, dengan Jinja2CppLight, parser ekspresi cukup sederhana. Dalam kasus pertama - pada regexp'ah yang sama, dalam tulisan tangan kedua, tetapi hanya mendukung desain yang sangat sederhana. Dukungan untuk filter, penguji, aritmatika atau pengindeksan kompleks adalah tidak mungkin. Dan justru fitur-fitur Jinja2 inilah yang paling saya inginkan. Oleh karena itu, saya tidak punya pilihan lain selain mengacak parser LL (1) lengkap (di beberapa tempat - peka konteks) yang mengimplementasikan tata bahasa yang diperlukan. Sekitar sepuluh hingga lima belas tahun yang lalu, saya mungkin akan mengambil Bison atau ANTLR untuk ini dan mengimplementasikan parser dengan bantuan mereka. Sekitar tujuh tahun yang lalu saya akan mencoba Boost.Spirit. Sekarang saya baru saja mengimplementasikan parser yang saya butuhkan, bekerja dengan metode turunan rekursif, tanpa menghasilkan dependensi yang tidak perlu dan secara signifikan meningkatkan waktu kompilasi, seperti yang akan terjadi jika utilitas eksternal atau Boost. Spirit digunakan. Pada output parser, saya mendapatkan AST (untuk ekspresi atau untuk operator), yang disimpan sebagai templat, siap untuk rendering berikutnya.
Contoh parsing logic ExpressionEvaluatorPtr<FullExpressionEvaluator> ExpressionParser::ParseFullExpression(LexScanner &lexer, bool includeIfPart) { ExpressionEvaluatorPtr<FullExpressionEvaluator> result; LexScanner::StateSaver saver(lexer); ExpressionEvaluatorPtr<FullExpressionEvaluator> evaluator = std::make_shared<FullExpressionEvaluator>(); auto value = ParseLogicalOr(lexer); if (!value) return result; evaluator->SetExpression(value); ExpressionEvaluatorPtr<ExpressionFilter> filter; if (lexer.PeekNextToken() == '|') { lexer.EatToken(); filter = ParseFilterExpression(lexer); if (!filter) return result; evaluator->SetFilter(filter); } ExpressionEvaluatorPtr<IfExpression> ifExpr; if (lexer.PeekNextToken() == Token::If) { if (includeIfPart) { lexer.EatToken(); ifExpr = ParseIfExpression(lexer); if (!ifExpr) return result; evaluator->SetTester(ifExpr); } } saver.Commit(); return evaluator; } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalOr(LexScanner& lexer) { auto left = ParseLogicalAnd(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalOr) { lexer.ReturnToken(); return left; } auto right = ParseLogicalOr(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalOr, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalAnd(LexScanner& lexer) { auto left = ParseLogicalCompare(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalAnd) { lexer.ReturnToken(); return left; } auto right = ParseLogicalAnd(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalAnd, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalCompare(LexScanner& lexer) { auto left = ParseStringConcat(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); auto tok = lexer.NextToken(); BinaryExpression::Operation operation; switch (tok.type) { case Token::Equal: operation = BinaryExpression::LogicalEq; break; case Token::NotEqual: operation = BinaryExpression::LogicalNe; break; case '<': operation = BinaryExpression::LogicalLt; break; case '>': operation = BinaryExpression::LogicalGt; break; case Token::GreaterEqual: operation = BinaryExpression::LogicalGe; break; case Token::LessEqual: operation = BinaryExpression::LogicalLe; break; case Token::In: operation = BinaryExpression::In; break; case Token::Is: { Token nextTok = lexer.NextToken(); if (nextTok != Token::Identifier) return ExpressionEvaluatorPtr<Expression>(); std::string name = AsString(nextTok.value); bool valid = true; CallParams params; if (lexer.NextToken() == '(') params = ParseCallParams(lexer, valid); else lexer.ReturnToken(); if (!valid) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<IsExpression>(left, std::move(name), std::move(params)); } default: lexer.ReturnToken(); return left; } auto right = ParseStringConcat(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(operation, left, right); }
Dari sini Fragmen kelas pohon ekspresi AST class ExpressionFilter; class IfExpression; class FullExpressionEvaluator : public ExpressionEvaluatorBase { public: void SetExpression(ExpressionEvaluatorPtr<Expression> expr) { m_expression = expr; } void SetFilter(ExpressionEvaluatorPtr<ExpressionFilter> expr) { m_filter = expr; } void SetTester(ExpressionEvaluatorPtr<IfExpression> expr) { m_tester = expr; } InternalValue Evaluate(RenderContext& values) override; void Render(OutStream &stream, RenderContext &values) override; private: ExpressionEvaluatorPtr<Expression> m_expression; ExpressionEvaluatorPtr<ExpressionFilter> m_filter; ExpressionEvaluatorPtr<IfExpression> m_tester; }; class ValueRefExpression : public Expression { public: ValueRefExpression(std::string valueName) : m_valueName(valueName) { } InternalValue Evaluate(RenderContext& values) override; private: std::string m_valueName; }; class SubscriptExpression : public Expression { public: SubscriptExpression(ExpressionEvaluatorPtr<Expression> value, ExpressionEvaluatorPtr<Expression> subscriptExpr) : m_value(value) , m_subscriptExpr(subscriptExpr) { } InternalValue Evaluate(RenderContext& values) override; private: ExpressionEvaluatorPtr<Expression> m_value; ExpressionEvaluatorPtr<Expression> m_subscriptExpr; }; class ConstantExpression : public Expression { public: ConstantExpression(InternalValue constant) : m_constant(constant) {} InternalValue Evaluate(RenderContext&) override { return m_constant; } private: InternalValue m_constant; }; class TupleCreator : public Expression { public: TupleCreator(std::vector<ExpressionEvaluatorPtr<>> exprs) : m_exprs(std::move(exprs)) { } InternalValue Evaluate(RenderContext&) override; private: std::vector<ExpressionEvaluatorPtr<>> m_exprs; };
Dari sini Kelas contoh operator pohon AST struct Statement : public RendererBase { }; template<typename T = Statement> using StatementPtr = std::shared_ptr<T>; template<typename CharT> class TemplateImpl; class ForStatement : public Statement { public: ForStatement(std::vector<std::string> vars, ExpressionEvaluatorPtr<> expr, ExpressionEvaluatorPtr<> ifExpr, bool isRecursive) : m_vars(std::move(vars)) , m_value(expr) , m_ifExpr(ifExpr) , m_isRecursive(isRecursive) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void SetElseBody(RendererPtr renderer) { m_elseBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: void RenderLoop(const InternalValue& val, OutStream& os, RenderContext& values); private: std::vector<std::string> m_vars; ExpressionEvaluatorPtr<> m_value; ExpressionEvaluatorPtr<> m_ifExpr; bool m_isRecursive; RendererPtr m_mainBody; RendererPtr m_elseBody; }; class ElseBranchStatement; class IfStatement : public Statement { public: IfStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void AddElseBranch(StatementPtr<ElseBranchStatement> branch) { m_elseBranches.push_back(branch); } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; std::vector<StatementPtr<ElseBranchStatement>> m_elseBranches; }; class ElseBranchStatement : public Statement { public: ElseBranchStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } bool ShouldRender(RenderContext& values) const; void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; };
Dari sini Node AST hanya dikaitkan dengan teks templat dan dikonversi ke nilai total pada saat rendering, dengan mempertimbangkan konteks rendering saat ini dan parameternya. Ini memungkinkan kami untuk membuat pola yang aman. Tetapi lebih lanjut tentang ini dalam hal rendering yang sebenarnya.
Sebagai tokenizer utama, saya memilih perpustakaan
lexertk . Ini memiliki lisensi yang saya butuhkan dan hanya sundulan. Benar, saya harus memotong semua lonceng dan peluit menghitung keseimbangan kurung dan seterusnya dan hanya meninggalkan tokenizer itu sendiri, yang (setelah sedikit meluruskan dengan file) belajar untuk bekerja tidak hanya dengan char, tetapi juga dengan karakter wchar_t. Di atas tokenizer ini, saya membungkus kelas lain yang melakukan tiga fungsi utama: a) mengabstraksi kode parser dari jenis karakter yang kami kerjakan, b) ia mengenali kata kunci khusus untuk Jinja2, dan c) menyediakan antarmuka yang nyaman untuk bekerja dengan aliran token:
LexScanner class LexScanner { public: struct State { Lexer::TokensList::const_iterator m_begin; Lexer::TokensList::const_iterator m_end; Lexer::TokensList::const_iterator m_cur; }; struct StateSaver { StateSaver(LexScanner& scanner) : m_state(scanner.m_state) , m_scanner(scanner) { } ~StateSaver() { if (!m_commited) m_scanner.m_state = m_state; } void Commit() { m_commited = true; } State m_state; LexScanner& m_scanner; bool m_commited = false; }; LexScanner(const Lexer& lexer) { m_state.m_begin = lexer.GetTokens().begin(); m_state.m_end = lexer.GetTokens().end(); Reset(); } void Reset() { m_state.m_cur = m_state.m_begin; } auto GetState() const { return m_state; } void RestoreState(const State& state) { m_state = state; } const Token& NextToken() { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur ++; } void EatToken() { if (m_state.m_cur != m_state.m_end) ++ m_state.m_cur; } void ReturnToken() { if (m_state.m_cur != m_state.m_begin) -- m_state.m_cur; } const Token& PeekNextToken() const { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur; } bool EatIfEqual(char type, Token* tok = nullptr) { return EatIfEqual(static_cast<Token::Type>(type), tok); } bool EatIfEqual(Token::Type type, Token* tok = nullptr) { if (m_state.m_cur == m_state.m_end) { if(type == Token::Type::Eof && tok) *tok = EofToken(); return type == Token::Type::Eof; } if (m_state.m_cur->type == type) { if (tok) *tok = *m_state.m_cur; ++ m_state.m_cur; return true; } return false; } private: State m_state; static const Token& EofToken() { static Token eof; eof.type = Token::Eof; return eof; } };
Dari sini Jadi, terlepas dari kenyataan bahwa mesin dapat bekerja dengan baik char dan wchar_t-templates, kode parsing utama tidak tergantung pada tipe karakter. Tetapi lebih lanjut tentang ini di bagian petualangan dengan tipe karakter.
Secara terpisah, saya harus mengotak-atik struktur kontrol. Di Jinja2, banyak dari mereka berpasangan. Misalnya, untuk / endfor, if / endif, block / endblock, dll. Setiap elemen dari pasangan berjalan di "kurung" sendiri, dan di antara elemen-elemen dapat ada banyak segalanya: hanya teks biasa dan blok kontrol lainnya. Oleh karena itu, algoritma untuk mem-parsing templat harus dilakukan berdasarkan stack, ke elemen atas saat ini yang mana semua konstruksi dan instruksi baru ditemukan, serta fragmen teks sederhana di antara mereka, “cling”. Menggunakan tumpukan yang sama, tidak adanya ketidakseimbangan dari tipe if-for-endif-endfor diperiksa. Sebagai hasil dari semua ini, kode tersebut ternyata tidak "kompak" seperti, katakanlah, Jinja2CppLight (atau inja), di mana seluruh implementasi dalam satu sumber (atau header). Tetapi logika parsing dan, pada kenyataannya, tata bahasa dalam kode lebih terlihat jelas, yang menyederhanakan dukungan dan ekstensi. Setidaknya itulah yang saya tuju. Masih tidak mungkin untuk meminimalkan jumlah dependensi atau jumlah kode, jadi Anda harus membuatnya lebih jelas.
Pada bagian
selanjutnya, kita akan berbicara tentang proses rendering template, tetapi untuk sekarang - tautan:
Spesifikasi Jinja2:
http://jinja.pocoo.org/docs/2.10/templates/Implementasi Jinja2Cpp:
https://github.com/flexferrum/Jinja2CppImplementasi Jinja2CppLight:
https://github.com/hughperkins/Jinja2CppLightImplementasi yang terluka:
https://github.com/pantor/injaUtilitas untuk menghasilkan kode berdasarkan templat Jinja2:
https://github.com/flexferrum/autoprogrammer/tree/jinja2cpp_refactor