Komentar dalam publikasi terbaru "Seberapa baik ekosistem open-source R untuk memecahkan masalah bisnis?" Adapun unduhan di Excel, mereka mengarah pada gagasan bahwa masuk akal untuk menghabiskan waktu dan menggambarkan salah satu pendekatan yang terbukti mungkin yang dapat diterapkan tanpa meninggalkan R.
Situasinya cukup khas. Perusahaan selalu memiliki metode N yang digunakan manajer secara manual untuk membuat laporan di Excel. Bahkan jika mereka terotomatisasi, selalu ada situasi di mana sangat mendesak untuk melakukan pemotongan sewenang-wenang baru atau membuat presentasi untuk manajer tertentu dalam bentuk tertentu.
Dan ada sejumlah kamus excel yang didukung secara manual untuk mengubah penyajian data dalam laporan dan sampel dalam terminologi yang benar.
Karena kenyataan bahwa tidak ada alat yang cocok (massa nuansa tambahan akan lebih rendah) tidak dapat ditemukan, saya harus menumpuk "konstruktor universal" pada Shiny + R. Karena universalitas dan kemampuan parameter pengaturan, konstruktor seperti itu dapat dengan mudah ditanam di hampir semua sistem di area subjek mana pun.
Ini adalah kelanjutan dari publikasi sebelumnya .
Pernyataan singkat tentang masalahnya
- Sebagai sumber data teknis, ada penyimpanan tipe OLAP utama (kami fokus pada Clickhouse), beberapa tambahan (Postgre, MS SQL, REST API) dan referensi xml, json, xlsx manual. Karena fakta bahwa analitik ad-hoc diperlukan, termasuk perhitungan nilai-nilai unik, hanya diperlukan untuk bekerja dengan sumber data, dan bukan dengan agregat.
- Catatan dalam database - ratusan miliar baris per beberapa ratus kolom (peristiwa waktu), disarankan untuk melakukan analisis dalam mode yang diukur tidak lebih dari beberapa puluh detik, kueri dapat sepenuhnya tidak dapat diprediksi, data disimpan dalam bentuk teknis (singkatan bahasa Inggris, jumlah entri kamus, dll. ) Di negara target, ~ 200Tb data mentah diharapkan.
- Peristiwa terakumulasi memiliki versi spesifik, mis. karena Sistem berfungsi, informasi dari berbagai versi dan rilis sumber yang melaporkan diri mereka sendiri dengan berbagai cara terakumulasi di dalamnya.
- Manajer bekerja dengan baik di excel, tetapi seharusnya tidak tahu (dan secara fisik tidak bisa) komponen teknis Sistem.
Bagaimana mengatasi masalah tersebut
Skenario umum pekerjaan ini cukup sederhana. Manajer menerima tugas mendesak untuk bagian analitis - manajer membuka aplikasi, membentuk sampel sewenang-wenang dalam hal area subjek - melihat dan memutar hasil tabular - membongkar hasil yang diatur dalam excel - menggambar untuk manajemen. Kenyamanan dan kesederhanaan antarmuka pengguna dipilih sebagai titik nol.
- Semuanya dirancang sebagai aplikasi Shiny satu layar dengan menu navigasi dan bookmark.
- Semua kontrol dibagi menjadi 3 bagian:
- filter (global dan pribadi). Batasi area pilihan, ada 4 jenis: daftar-drop-down kamus, tanggal, fragmen teks, rentang digital.
- 3 tingkat bersarang dari grup permintaan
- daftar jumlah agregat (yaitu jumlah).
- Karena kenyataan bahwa ada banyak bidang dalam sumber asli (sekitar 2,5 ratus), tetapi Anda perlu menampilkan semuanya, elemen kontrol dikelompokkan ke dalam blok tematik.
Contoh antarmuka
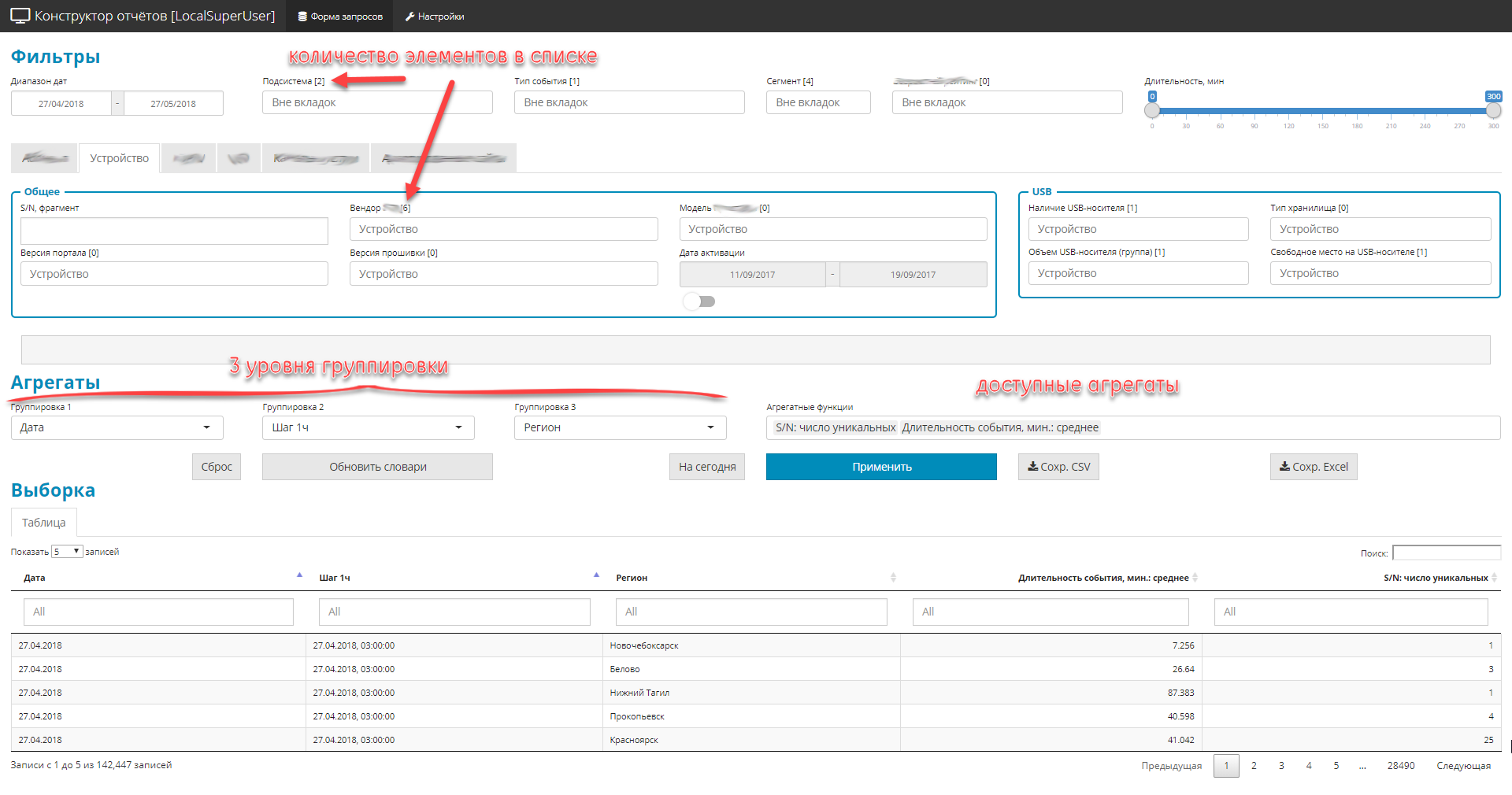
Contoh file dengan informasi meta
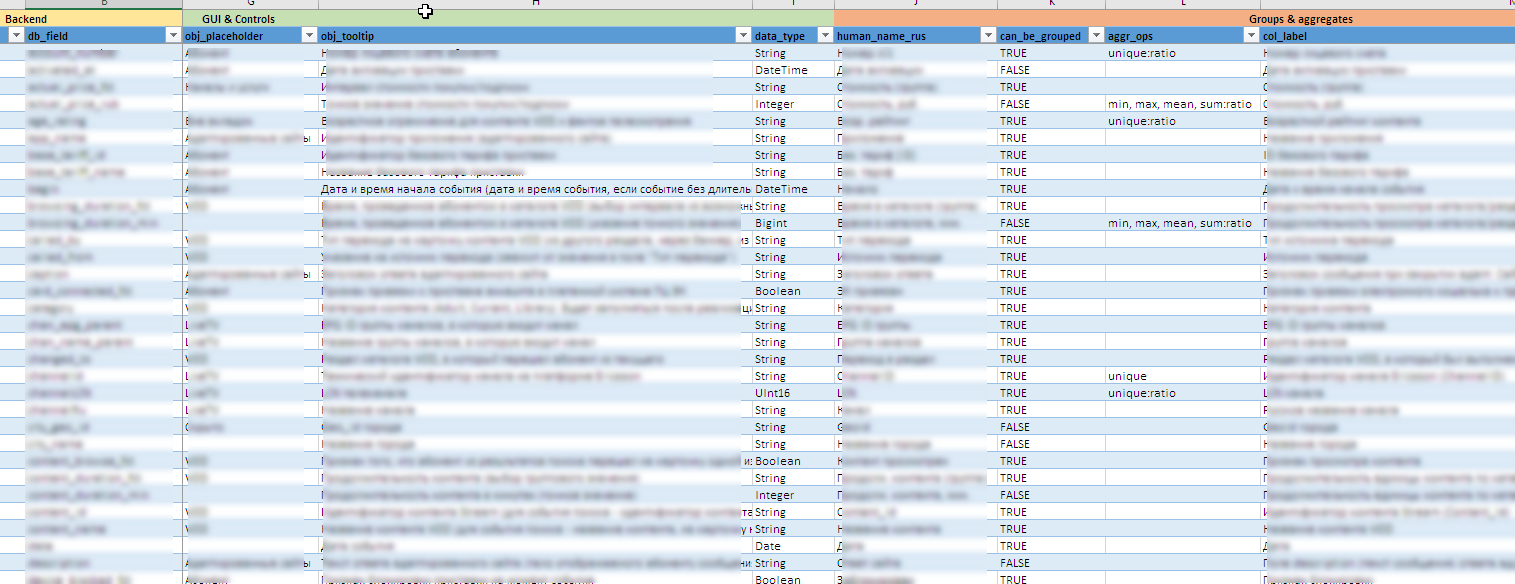
"Keripik" yang berguna di belakang layar:
- Saat sumber data berkembang, seluruh konfigurasi antarmuka, termasuk pembuatan kontrol, tooltips, konten pengelompokan dan agregat yang tersedia, aturan ekspor di excel, dll. didekorasi sebagai metamodel dalam bentuk file excel. Ini memungkinkan Anda untuk memodifikasi "perancang" dengan cepat untuk bidang baru atau unit perhitungan tanpa perubahan signifikan (atau tidak ada perubahan sama sekali) ke kode sumber.
- Sulit untuk mengatakan terlebih dahulu nilai-nilai apa yang dapat terjadi di bidang tertentu, dan untuk menemukannya, saya tidak tahu apa, bahkan lebih sulit. Mempertahankan 90 kontrol dinamis secara manual hampir mustahil. Dalam beberapa daftar, kosakata mencakup beberapa ratus makna. Oleh karena itu, entri kamus untuk kontrol diperbarui di latar belakang berdasarkan data yang terkumpul di backend.
- Manajer perlu melihat semua bidang dan konten dalam bahasa Rusia. Dan di sumbernya, data ini dapat disimpan dalam bentuk resmi. Oleh karena itu, kombinasi teknologi kamus Clickhouse dan pasca-pemrosesan dua arah nilai-nilai bidang di tingkat Shiny digunakan. Segera memberikan pemrosesan semua jenis pengecualian untuk aturan dan nuansa versi isi dari bidang.
- Untuk melindungi dari pilihan yang salah, koneksi silang dibuat antara daftar untuk pengelompokan. Level 2 hanya dapat dipilih jika Level 1 diatur, dan Level 3, hanya jika Level 2 ditetapkan. Dan daftar nilai yang tersedia dikurangi secara dinamis dengan mempertimbangkan yang sudah dipilih.
- Elemen penting adalah kontrol atas tampilan pilihan baik di layar maupun selama mengunggah berikutnya untuk unggul. Di sini, juga, ada sejumlah fitur dalam postprocessing yang ditujukan untuk kenyamanan alat bagi manajer:
- dukungan terorganisir untuk "matriks visibilitas" dalam bentuk file excel. Matriks ini menentukan tampilan atau menyembunyikan bidang tertentu dalam pemilihan, tergantung pada filter yang dipasang.
- modifikasi dinamis baris demi baris konten sampel. Bergantung pada konten berbagai bidang, isi bidang lain dapat diubah (misalnya, jika 0 ditentukan dalam bidang "jumlah pesanan", maka baris kosong ditampilkan di bidang "jenis pesanan".
- pengelolaan tampilan data pribadi. tergantung pada hak akses peran yang dikonfigurasikan. data dapat ditampilkan serta sebagian ditutup dengan
* . - manajemen presisi. hanya untuk menyebutkan. menunjukkan 10 tempat desimal - Moveton, tetapi ada beberapa situasi ketika akurasi 2 tempat desimal tidak cukup. 80% objek, misalnya, memiliki persentase
0.00% - Anda perlu meningkatkan karakter signifikan ketika membulatkan, sehingga perbedaan antara garis terlihat. Dan jumlah di bongkar di excel harus konvergen (jumlah di semua garis di kolom fraksional cukup diharapkan di wilayah 100%). - menyediakan akses peran di tingkat kontrol konten yang tersedia. Hak akses dikendalikan oleh file konfigurasi json.
- Kontrol dinamis kedalaman permintaan. Dalam kasus ketika tidak ada pengelompokan dan agregat yang ditentukan (studi sedang berlangsung dan Anda hanya perlu mengembalikan data mentah yang jatuh di bawah filter yang diinstal), perlindungan terhadap kelebihan backend diaktifkan. Pengguna dapat mengatur rentang waktu untuk pencarian dalam 1 tahun, tetapi benar-benar membutuhkan 1000 catatan terakhir dari pilihan. Mengetahui bahwa jutaan catatan tiba setiap hari, permintaan uji coba untuk kedalaman yang dikurangi pertama kali dilakukan (3-7 hari yang lalu). Jika jumlah baris yang diterima tidak cukup (kondisi penyaringan ketat), kueri lengkap diluncurkan untuk seluruh periode waktu.
- Membongkar sampel yang diterima dalam format excel. Semuanya diformat, semuanya dalam bahasa Rusia, disertai dengan lembar terpisah dengan memperbaiki semua parameter sampel, sehingga Anda dapat dengan mudah memahami bagaimana hasil ini atau itu diperoleh.
- Log terperinci dipelihara dalam aplikasi, sehingga Anda bisa mendapatkan gagasan tentang tindakan pengguna dan pengoperasian mekanisme kompartemen mesin.
Mengantisipasi kemungkinan komentar tentang "sepeda", jika akan ada 100%, saya segera menyarankan untuk menuliskannya dengan indikasi produk open source yang Anda tahu. Saya akan senang dengan penemuan baru.
Tentu saja, tautan ke produk harus diberikan dengan mempertimbangkan seluruh jajaran persyaratan lanjutan. Nah, lebih disukai segera dengan penilaian infrastruktur yang dibutuhkan. Untuk opsi ini, dua atau tiga server berkapasitas sedang (64-128Gb; inti CPU 12-20, berbasis disk pada jumlah data) sudah cukup untuk seluruh kompleks. ELK tidak cocok, karena tugas utamanya adalah analitik numerik, dan tidak berfungsi dengan teks.
Persyaratan terperinci ditetapkan
Di bawah ini, sebagai informasi, daftar persyaratan terperinci untuk unit analitis diberikan di bagian antarmuka mesin-mesin dan antarmuka manusia-mesin ("perancang laporan" hanya sebagian).
Impor \ Ekspor \ Lingkungan
- File log distandarisasi dan terstruktur hanya dalam hal cap waktu, modul, dan subsistem. Sistem harus memproses file log dengan konten sewenang-wenang dari isi pesan (badan log rekaman), mendukung baik badan log rekaman terstruktur dan tidak terstruktur.
- Untuk memperkaya data, Sistem harus memiliki adaptor impor untuk setidaknya jenis sumber data berikut:
- file rata (csv, txt)
- file terstruktur xml, json, xlsx
- sumber yang kompatibel dengan odbc, khususnya MS SQL, MySQL, PostgreSQL
- data disediakan melalui REST API.
- Sistem harus mendukung impor dan impor otomatis atas permintaan pengguna. Saat mengimpor data pengguna, Sistem harus menyediakan:
- kemungkinan validasi teknis dari data yang diimpor (kebenaran jumlah bidang, jenisnya, kelengkapan, keberadaan nilai-nilai
- kemungkinan validasi logis (konten bidang, validasi, validasi silang, ...)
- kemampuan untuk mengkonfigurasi parameter validasi (dalam bentuk apa pun) sesuai dengan logika prosedur impor;
- Laporan terperinci tentang kesalahan teknis dan logis yang terdeteksi, memungkinkan operator untuk dengan cepat melokalisasi dan menghilangkan kesalahan fungsi pada data yang diimpor.
- Sistem harus mendukung ekspor hasil, setidaknya, dalam format berikut:
- ekspor data ke file flat csv, txt
- ekspor data ke file xml, json, xlsx terstruktur
- ekspor data ke sumber yang kompatibel dengan ODBC, khususnya, MS SQL, MySQL, PostgreSQL
- menyediakan akses ke data melalui protokol REST API
- Sistem harus memiliki fungsi untuk menghasilkan laporan tercetak:
- kombinasi kohesif dari teks, representasi tabel dan representasi grafik ke dalam satu dokumen sesuai dengan templat yang telah dibentuk sebelumnya (story telling);
- pembentukan semua elemen yang dihitung (tabel, grafik) pada saat pembuatan formulir pencetakan;
- penggunaan sumber dan direktori eksternal yang diperlukan dalam penyusunan laporan dalam mode on-the-fly sesuai dengan protokol yang disebutkan di atas, tanpa integrasi dan duplikasi data
- ekspor laporan yang dihasilkan dalam format html, docx, pdf
- pembentukan representasi cetak harus didukung baik sesuai permintaan maupun di latar belakang, sesuai dengan jadwal.
- Sistem harus menyimpan catatan terperinci dari perhitungan, tindakan pengguna aktif atau interaksi dengan sistem eksternal.
- Sistem harus diinstal di tempat.
- Instalasi dan operasi selanjutnya harus dilakukan dengan isolasi lengkap sistem dari Internet.
Perhitungan
- Sistem harus mendukung perhitungan metrik agregat (minimum, maksimum, rata-rata, median, kuartil) untuk interval waktu acak dalam mode dalam mode yang mendekati waktu nyata.
- Sistem harus mendukung perhitungan metrik dasar (jumlah nilai, jumlah nilai unik) untuk interval waktu arbitrer dalam mode yang dekat dengan waktu nyata.
- Saat menghitung data agregat, periode agregasi harus ditentukan oleh pengguna dari rentang yang telah ditentukan: 5 menit, 10 menit, 15 menit, 20 menit, 30 menit, 1 jam, 2 jam, 24 jam, 1 minggu, 1 bulan
- Sistem harus menyertakan konstruktor untuk membentuk sampel yang sewenang-wenang. Komposisi operasi yang mungkin harus ditentukan oleh metamodel data yang telah ditentukan. Konstruktor harus mendukung pengaturan minimum berikut:
- Saring dukungan untuk tanggal: [awal periode pelaporan - akhir periode pelaporan]
- Saring dukungan (daftar drop-down) dengan banyak pilihan untuk bidang yang disebutkan (misalnya, kota: Moskow, St. Petersburg, ...)
- Pembentukan otomatis daftar drop-down untuk filter bidang enumerable berdasarkan direktori eksternal yang dinamis atau akumulasi data.
- mendukung setidaknya tiga tingkat pengelompokan data secara berurutan dalam sampel yang diminta; parameter untuk pengelompokan sendiri ditetapkan oleh pengguna dari daftar data yang tersedia yang ditetapkan pada tingkat metamodel.
- pembatasan bidang yang tersedia untuk pengelompokan di satu atau tingkat lain, dengan mempertimbangkan bidang yang dipilih di tingkat yang lebih tinggi dari pengelompokan (misalnya, jika "kota" dipilih di tingkat 1, parameter ini tidak boleh tersedia di ke-2 atau ke-3 tingkat pengelompokan m)
- kemungkinan pengelompokan berdasarkan parameter waktu tambahan: hari dalam seminggu, kelompok jam (11-12; 12-13), minggu
- dukungan untuk agregat terhitung dasar: (minimum, maksimum, rata-rata, median, jumlah, jumlah yang unik);
- dukungan untuk filter pengujian untuk menyediakan pencarian teks lengkap dalam pemilihan;
- dukungan pada tahap menampilkan pengayaan dan transformasi data yang diperoleh berdasarkan permintaan berdasarkan data dari direktori atau sumber eksternal.
- Sistem harus memiliki mekanisme untuk menghitung metrik dalam koordinat spasial (sp = titik spasial) untuk mendukung geoanalitik.
- Untuk metrik waktu (transaksi, operasi, kueri, ...), sistem harus menghitung dan menampilkan kepadatan distribusi waktu eksekusi kueri.
- Semua indikator yang dihitung harus dilakukan untuk semua objek secara keseluruhan, serta untuk sampel yang ditetapkan oleh pengguna menggunakan filter
- Sistem harus melakukan semua perhitungan dalam memori.
- Semua acara memiliki cap waktu, sehingga sistem harus mendukung pekerjaan dengan deret waktu yang sama dan sewenang-wenang.
- Sistem harus mendukung kemampuan untuk mengkonfigurasi dan mengaktifkan mekanisme untuk mengembalikan data yang terlewat dalam deret waktu (berbagai algoritma), menentukan anomali, memprediksi deret waktu, klasifikasi / pengelompokan.
Bagian antarmuka
- Seluruh antarmuka pengguna, termasuk konten elemen grafis dan tabel, harus dilokalkan.
- Untuk kontrol dan kolom representasi tabular, kemungkinan membentuk tooltips dengan deskripsi terperinci (hover tip), dibentuk baik secara statis dan dinamis (misalnya, dalam tooltip mungkin parameter yang digunakan untuk menghitung), harus didukung.
- Antarmuka tempat kerja harus dibangun hanya dengan penggunaan HTML, CSS, teknologi JS, tanpa menggunakan teknologi yang ketinggalan zaman, bergantung pada platform atau tidak dapat diakses, seperti Adobe Flash, MS Silverlight, dll.
- Waktu pada grafik harus ditampilkan dalam format 24 jam.
- Parameter untuk menampilkan data pada sumbu harus mendukung penskalaan otomatis (frekuensi label dan format tampilan) tergantung pada kisaran nilai. Contoh khas adalah tampilan jam dengan rentang pengukuran dalam satu hari, tampilan hari dengan rentang pengukuran dalam seminggu.
- Sistem minimal harus mendukung format tampilan grafik atom berikut:
- Histogram (bilah)
- Spot
- Linier
- Peta panas
- Kontur (kontur)
- Pie chart
- Sistem harus mendukung kemampuan untuk secara otomatis menempatkan marker (misalnya, nilai) dari subset titik tertentu dengan tumpang tindih minimum marker ini.
- Sistem harus mendukung kemungkinan penggabungan pada satu representasi grafis dari data yang diperoleh dari sumber data yang berbeda. Kemampuan untuk menentukan format tampilan grafik atom yang berbeda untuk setiap sumber data harus didukung, asalkan sumbu koordinat dan jenis sistem koordinat cocok.
- Sistem harus mendukung distribusi facet (partisi grafik pada grid M x N) grafik atom untuk variabel parameterisasi yang diberikan. Dalam tampilan segi, untuk setiap grafik, penskalaan independen dari sumbu X dan sumbu Y harus dimungkinkan.
- Grafik harus mendukung parameterisasi karakteristik berikut:
- Warna
- Jenis garis atau titik
- Ketebalan garis atau garis besar titik
- Ukuran titik
- Transparansi
- Untuk tugas-tugas geoanalisis data, sistem harus mendukung kerja dengan shapefile, termasuk impor, tampilan, pewarnaan parameter area dan memastikan bahwa berbagai elemen grafik dan indikator yang dihitung ditumpangkan pada geopod yang dihasilkan.
- Kontrol antarmuka pengguna (daftar, bidang, panel, dll.) Harus mendukung perubahan dinamis konten mereka tergantung pada keadaan elemen lainnya. Misalnya, ketika memilih wilayah tertentu, konten elemen pemilihan kota harus dibatasi pada daftar kota yang termasuk dalam wilayah tersebut.
- Model peran akses ke aplikasi pelaporan harus didukung:
- dukungan untuk metamodel data untuk menyediakan akses peran di tingkat url (mungkin / tidak mungkin)
- dukungan untuk metamodel data untuk menyediakan akses berbasis peran pada tingkat konten elemen kontrol (misalnya, daftar objek yang tersedia dalam daftar drop-down ditentukan oleh tanggung jawab regional manajer)
- mendukung metamodel data untuk memastikan akses berbasis peran pada tingkat visualisasi data pribadi (misalnya, menutupi "*" bagian tertentu dari nomor email atau bidang lainnya)
Kesimpulan
Tujuan utama dari publikasi ini adalah untuk menunjukkan bahwa kemungkinan R meluas sangat kuat di luar batas statistik klasik. Secara praktis diperiksa, tidak perlu mengorbankan kualitas atau fungsionalitas.
Posting sebelumnya - "Seberapa baik ekosistem open-source R untuk memecahkan masalah bisnis?" .