Salah satu berita yang paling populer dan dibahas selama beberapa tahun terakhir adalah siapa yang menambahkan kecerdasan buatan ke mana dan apa yang diretas peretas apa dan di mana. Dengan menggabungkan topik-topik ini, studi yang sangat menarik muncul, dan sudah ada beberapa artikel di hub yang mampu menipu model pembelajaran mesin, misalnya: artikel tentang keterbatasan pembelajaran yang mendalam , tentang cara memikat jaringan saraf . Lebih lanjut, saya ingin mempertimbangkan topik ini secara lebih rinci dari sudut pandang keamanan komputer:

Pertimbangkan masalah-masalah berikut:
- Istilah penting.
- Apa itu pembelajaran mesin, jika tiba-tiba Anda masih belum tahu.
- Apa hubungan keamanan komputer dengan itu ?!
- Apakah mungkin untuk memanipulasi model pembelajaran mesin untuk melakukan serangan yang ditargetkan?
- Dapatkah kinerja sistem terdegradasi?
- Bisakah saya memanfaatkan keterbatasan model pembelajaran mesin?
- Kategorisasi serangan.
- Cara perlindungan.
- Konsekuensi yang mungkin.
1. Hal pertama yang ingin saya mulai adalah terminologi.
Pernyataan yang mungkin ini dapat menyebabkan holivar besar di pihak komunitas ilmiah dan profesional karena beberapa artikel yang telah ditulis dalam bahasa Rusia, tetapi saya ingin mencatat bahwa istilah "kecerdasan permusuhan" diterjemahkan sebagai "kecerdasan musuh". Dan kata "permusuhan" itu sendiri harus diterjemahkan bukan dengan istilah hukum "permusuhan", tetapi dengan istilah yang lebih cocok dari keamanan "jahat" (tidak ada keluhan tentang terjemahan nama arsitektur jaringan saraf). Lalu semua istilah terkait dalam bahasa Rusia memiliki makna yang jauh lebih terang, seperti "contoh permusuhan" - contoh data berbahaya, "pengaturan permusuhan" - lingkungan berbahaya. Dan area yang akan kita pertimbangkan "pembelajaran mesin permusuhan" adalah pembelajaran mesin jahat.
Setidaknya dalam kerangka artikel ini, istilah seperti itu dalam bahasa Rusia akan digunakan. Saya berharap bahwa mungkin untuk menunjukkan bahwa topik ini lebih banyak tentang keamanan untuk menggunakan istilah-istilah dari area ini secara adil, daripada contoh pertama dari seorang penerjemah.
Jadi, sekarang kita siap untuk berbicara dalam bahasa yang sama, kita dapat memulai dasarnya :)
2. Apa itu pembelajaran mesin, jika tiba-tiba Anda masih belum tahu
Yah, masih udah di ketahuiDengan metode pembelajaran mesin, kami biasanya berarti metode untuk membangun algoritma yang dapat belajar dan bertindak tanpa secara eksplisit memprogram perilaku mereka pada data yang dipilih sebelumnya. Dengan data kita dapat berarti apa saja, jika kita dapat menggambarkannya dengan beberapa tanda atau mengukurnya. Jika ada beberapa tanda yang tidak diketahui untuk beberapa data, tetapi kami benar-benar membutuhkannya, kami menggunakan metode pembelajaran mesin untuk memulihkan atau memprediksi tanda ini berdasarkan data yang sudah diketahui.
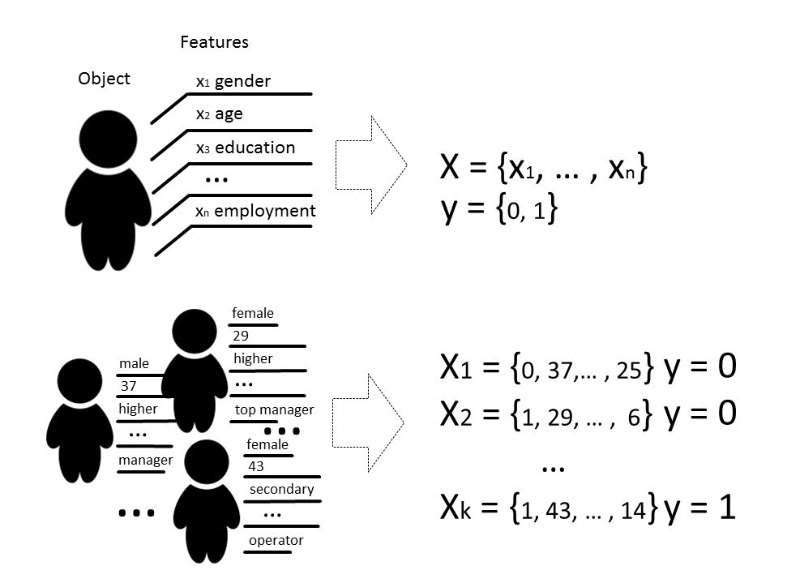
Ada beberapa jenis masalah yang dapat diselesaikan dengan bantuan pembelajaran mesin, tetapi kita terutama akan berbicara tentang masalah klasifikasi.
Secara klasik, tujuan dari tahap pelatihan model classifier adalah untuk memilih hubungan (fungsi) yang akan menunjukkan korespondensi antara fitur dari objek tertentu dan salah satu kelas yang dikenal. Dalam kasus yang lebih kompleks, diperlukan prediksi kemungkinan memiliki kategori tertentu.
Artinya, tugas klasifikasi adalah untuk membangun hyperplane yang akan membagi ruang, di mana, sebagai aturan, dimensinya adalah ukuran vektor fitur, sehingga objek dari kelas yang berbeda terletak pada sisi berlawanan dari hyperplane ini.
Untuk ruang dua dimensi, hyperplane semacam itu adalah garis. Pertimbangkan contoh sederhana:

Dalam gambar Anda dapat melihat dua kelas, kuadrat dan segitiga. Tidak mungkin untuk menemukan ketergantungan dan paling akurat membaginya dengan fungsi linier. Oleh karena itu, dengan bantuan pembelajaran mesin, seseorang dapat memilih fungsi nonlinier yang paling baik membedakan dua set ini.
Tugas klasifikasi adalah tugas mengajar yang cukup khas dengan seorang guru. Untuk melatih model, seperangkat data tersebut diperlukan sehingga memungkinkan untuk membedakan fitur objek dan kelasnya.
3. Apa hubungan keamanan komputer dengan itu ?!
Dalam keamanan komputer, berbagai metode pembelajaran mesin telah lama digunakan dalam penyaringan spam, analisis lalu lintas, dan deteksi penipuan atau malware.
Dan dalam arti tertentu, ini adalah permainan di mana, setelah bergerak, Anda berharap musuh bereaksi. Karena itu, bermain game ini, Anda harus terus-menerus menyesuaikan model, mengajar data baru, atau mengubahnya sepenuhnya, dengan mempertimbangkan pencapaian terbaru ilmu pengetahuan.
Sebagai contoh, sementara antivirus menggunakan analisis tanda tangan, heuristik manual dan aturan yang cukup sulit untuk dipertahankan dan diperluas, industri keamanan masih memperdebatkan tentang manfaat nyata dari antivirus dan banyak yang menganggap antivirus sebagai produk mati. Penyerang menghindari semua aturan ini, misalnya, dengan bantuan kebingungan dan polimorfisme. Akibatnya, preferensi diberikan kepada alat yang menggunakan teknik yang lebih cerdas, misalnya, metode pembelajaran mesin yang secara otomatis memilih fitur (bahkan yang tidak diinterpretasikan oleh manusia), dapat dengan cepat memproses sejumlah besar informasi, menggeneralisasikannya, dan mengambil keputusan dengan cepat.
Artinya, di satu sisi, pembelajaran mesin digunakan sebagai alat untuk perlindungan. Di sisi lain, alat ini juga digunakan untuk serangan yang lebih cerdas.
Mari kita lihat apakah alat ini bisa rentan?
Untuk algoritma apa pun, tidak hanya pemilihan parameter yang sangat penting, tetapi juga data di mana algoritma dilatih. Tentu saja, dalam situasi yang ideal, perlu ada cukup data untuk pelatihan, kelas-kelas harus seimbang, dan waktu untuk pelatihan berlalu tanpa diketahui, yang secara praktis tidak mungkin dalam kehidupan nyata.
Kualitas model yang terlatih biasanya dipahami sebagai keakuratan klasifikasi pada data yang modelnya belum “lihat”, dalam kasus umum, sebagai rasio tertentu dari salinan data yang diklasifikasikan dengan benar terhadap jumlah total data yang kami kirimkan ke model.
Secara umum, semua penilaian kualitas berhubungan langsung dengan asumsi tentang distribusi yang diharapkan dari data input sistem dan tidak memperhitungkan kondisi lingkungan yang berbahaya ( pengaturan permusuhan ), yang seringkali melampaui distribusi yang diharapkan dari data input. Lingkungan jahat dipahami sebagai lingkungan di mana dimungkinkan untuk menghadapi atau berinteraksi dengan sistem. Contoh umum dari lingkungan seperti itu adalah mereka yang menggunakan filter spam, algoritma deteksi penipuan, dan sistem analisis malware.
Dengan demikian, akurasi dapat dianggap sebagai ukuran kinerja sistem rata-rata dalam penggunaan rata-rata, sementara penilaian keamanan tertarik pada implementasi terburuknya.
Yaitu, biasanya model pembelajaran mesin diuji dalam lingkungan yang cukup statis di mana akurasi tergantung pada jumlah data untuk setiap kelas tertentu, tetapi dalam kenyataannya distribusi yang sama tidak dapat dijamin. Dan kami tertarik untuk membuat model yang salah. Dengan demikian, tugas kita adalah menemukan sebanyak mungkin vektor yang memberikan hasil yang salah.
Ketika mereka berbicara tentang keamanan suatu sistem atau layanan, mereka biasanya berarti bahwa tidak mungkin untuk melanggar kebijakan keamanan dalam model ancaman yang diberikan dalam perangkat keras atau perangkat lunak, mencoba memeriksa sistem baik pada tahap pengembangan dan pada tahap pengujian. Tetapi hari ini, sejumlah besar layanan beroperasi berdasarkan algoritma analisis data, sehingga risikonya tidak hanya terletak pada fungsionalitas yang rentan, tetapi juga dalam data itu sendiri, atas dasar di mana sistem dapat membuat keputusan.
Tidak ada yang diam, dan peretas juga menguasai sesuatu yang baru. Dan metode yang membantu mempelajari algoritma pembelajaran mesin untuk kemungkinan kompromi oleh penyerang yang dapat menggunakan pengetahuan tentang bagaimana model bekerja disebut pembelajaran mesin adversarial , atau dalam bahasa Rusia itu masih pembelajaran mesin berbahaya .
Jika kita berbicara tentang keamanan model pembelajaran mesin dari sudut pandang keamanan informasi, maka secara konsep saya ingin mempertimbangkan beberapa masalah.
4. Apakah mungkin untuk memanipulasi model pembelajaran mesin untuk melakukan serangan yang ditargetkan?
Berikut adalah contoh yang bagus dengan optimasi mesin pencari. Orang-orang mempelajari bagaimana algoritma mesin pencari cerdas bekerja dan memanipulasi data di situs mereka untuk menjadi lebih tinggi di peringkat pencarian. Pertanyaan tentang keamanan sistem seperti ini dalam kasus ini tidak begitu akut sampai kompromi beberapa data atau menyebabkan kerusakan serius.
Sebagai contoh dari sistem seperti itu, kita dapat mengutip layanan yang pada dasarnya menggunakan pelatihan model online, yaitu pelatihan di mana model menerima data secara berurutan untuk memperbarui parameter saat ini. Mengetahui bagaimana sistem dilatih, Anda dapat merencanakan serangan dan menyediakan sistem dengan data yang sudah disiapkan.
Misalnya, dengan cara ini sistem biometrik tertipu , yang secara bertahap memperbarui parameternya ketika perubahan kecil dalam penampilan seseorang terjadi , misalnya, dengan perubahan alami dalam usia , yang merupakan fungsi yang benar-benar alami dan diperlukan dari layanan dalam kasus ini. Menggunakan properti sistem ini, Anda dapat menyiapkan data dan mengirimkannya ke sistem biometrik, memperbarui model hingga memperbarui parameter ke orang lain. Dengan demikian, penyerang akan melatih kembali model dan akan dapat mengidentifikasi dirinya sendiri daripada korban.

Masalah ini muncul secara alami dari kenyataan bahwa model pembelajaran mesin sering diuji dalam lingkungan yang agak statis, dan kualitasnya dinilai oleh distribusi data yang menjadi tujuan pelatihan model tersebut. Pada saat yang sama, pertanyaan yang sangat spesifik sering diajukan kepada spesialis analisis data, yang perlu dijawab oleh model:
- Apakah file tersebut berbahaya?
- Apakah transaksi ini milik penipuan?
- Apakah lalu lintas saat ini sah?
Dan diharapkan bahwa algoritme tidak dapat 100% akurat, hanya dapat dengan beberapa probabilitas atribut objek ke beberapa kelas, jadi kita harus mencari kompromi dalam hal kesalahan jenis pertama dan kedua, ketika algoritma kami tidak dapat sepenuhnya yakin dalam pilihannya dan masih salah.
Ambil sistem yang sangat sering menghasilkan kesalahan jenis pertama dan kedua. Misalnya, antivirus memblokir file Anda karena dianggap berbahaya (walaupun tidak demikian), atau antivirus melewatkan file yang berbahaya. Dalam hal ini, pengguna sistem menganggapnya tidak efektif dan paling sering mematikannya, meskipun ada kemungkinan bahwa seperangkat data tersebut baru saja ditangkap.
Dan set data yang menunjukkan model hasil terburuk selalu ada. Dan tugas penyerang adalah mencari data tersebut untuk mematikan sistem. Situasi semacam itu agak tidak menyenangkan, dan tentu saja, model harus menghindarinya. Dan Anda dapat membayangkan skala konsekuensi dari investigasi semua insiden palsu!
Kesalahan jenis pertama dianggap sebagai pemborosan waktu, sedangkan kesalahan jenis kedua dianggap sebagai peluang yang terlewatkan. Meskipun sebenarnya biaya dari jenis kesalahan ini untuk setiap sistem tertentu mungkin berbeda. Jika antivirus bisa lebih murah, itu bisa menjadi kesalahan jenis pertama, karena lebih baik memainkannya dengan aman dan mengatakan bahwa file tersebut berbahaya, dan jika klien mematikan sistem, dan file tersebut benar-benar jahat, maka antivirus “seolah-olah diperingatkan” dan tanggung jawab tetap ada pada pengguna. Jika kita mengambil, misalnya, suatu sistem untuk diagnosa medis, maka kedua kesalahan akan cukup mahal, karena bagaimanapun pasien beresiko perawatan yang salah dan risiko kesehatan.
6. Bisakah seorang penyerang menggunakan properti dari metode pembelajaran mesin untuk mengganggu sistem? Artinya, tanpa ikut campur dalam proses pembelajaran, temukan keterbatasan model yang jelas memberikan prediksi yang salah.
Tampaknya sistem pembelajaran yang dalam secara praktis dilindungi dari intervensi manusia dalam pemilihan tanda-tanda, sehingga ada kemungkinan untuk mengatakan bahwa tidak ada faktor manusia ketika mengambil keputusan apa pun oleh model. Seluruh pesona pembelajaran yang mendalam adalah bahwa itu cukup untuk memberikan input model data yang hampir "mentah", dan model itu sendiri, melalui beberapa transformasi linier, menyoroti fitur-fitur yang “dianggap” paling signifikan dan membuat keputusan. Namun, apakah ini benar-benar baik?
Ada karya yang menggambarkan metode untuk mempersiapkan contoh berbahaya seperti pada model pembelajaran yang mendalam, yang diklasifikasikan secara salah oleh sistem. Salah satu dari sedikit contoh populer adalah artikel tentang serangan fisik yang efektif pada model pembelajaran yang mendalam.
Para penulis melakukan eksperimen dan mengusulkan metode untuk mem-bypass model berdasarkan pembatasan pembelajaran mendalam yang menipu sistem "visi", dengan menggunakan contoh pengakuan tanda-tanda jalan. Untuk hasil yang positif, cukup bagi penyerang untuk menemukan area seperti itu pada objek yang paling kuat menjatuhkan classifier, dan itu salah. Percobaan dilakukan pada tanda "STOP", yang, karena perubahan dalam peneliti, memenuhi syarat model sebagai tanda "BATAL 45 SPEED". Mereka menguji pendekatan mereka pada tanda-tanda lain dan mendapat hasil positif.
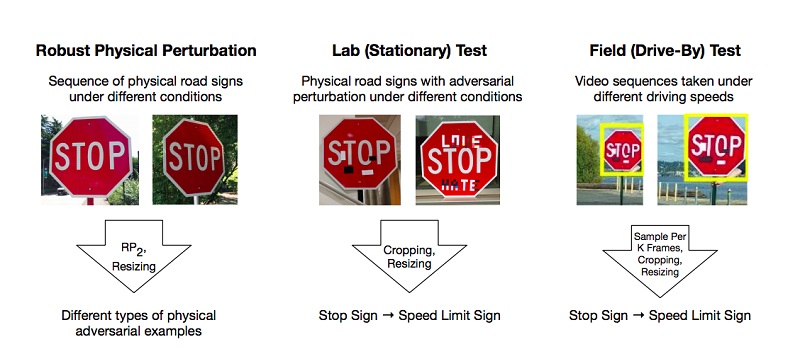
Sebagai hasilnya, penulis mengusulkan dua cara yang dengannya seseorang dapat menipu sistem pembelajaran mesin: Poster-Printing Attack, yang menyiratkan serangkaian perubahan kecil di sekitar seluruh garis tanda, yang disebut kamuflase, dan Serangan Stiker, ketika beberapa stiker dilapiskan pada tanda di area tertentu.
Tetapi ini adalah situasi yang cukup hidup - ketika tanda itu berada di tanah dari debu pinggir jalan atau ketika talenta muda meninggalkan pekerjaan mereka di atasnya. Sangat mungkin bahwa kecerdasan artifisial dan seni tidak memiliki tempat di satu dunia.

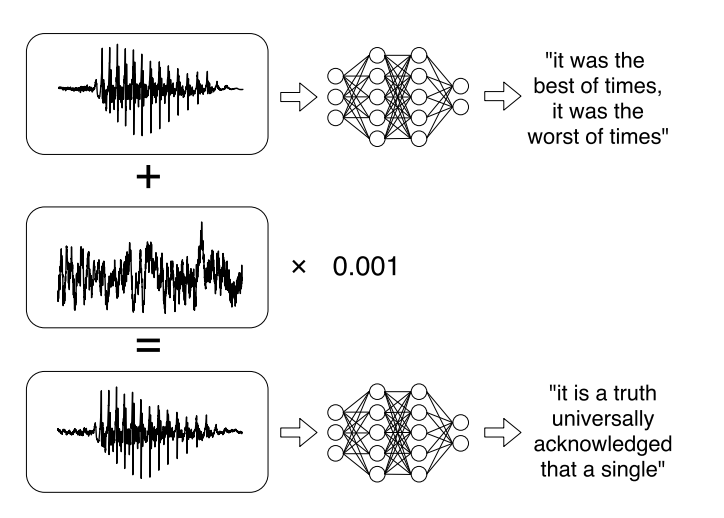
Atau penelitian terbaru tentang serangan yang ditargetkan pada sistem pengenalan suara otomatis . Pesan suara telah menjadi tren yang cukup modis ketika berkomunikasi di jejaring sosial, tetapi mendengarkannya tidak selalu nyaman. Oleh karena itu, ada layanan yang memungkinkan Anda untuk menyiarkan rekaman audio ke dalam teks. Para penulis karya belajar untuk menganalisis audio asli, memperhitungkan sinyal suara, dan kemudian belajar membuat sinyal suara lain, yang 99% mirip dengan aslinya, dengan menambahkan sedikit perubahan padanya. Akibatnya, classifier mendekripsi catatan seperti yang diinginkan penyerang.
7. Dalam hal ini, akan mungkin untuk mengkategorikan serangan yang ada dalam beberapa cara :
Dengan metode paparan (Pengaruh):
- Serangan kausatif memengaruhi pelatihan model melalui gangguan pada set pelatihan.
- Serangan eksplorasi menggunakan kesalahan classifier tanpa mempengaruhi set pelatihan.
Pelanggaran keamanan:
- Serangan integritas merusak sistem melalui kesalahan jenis kedua.
- Serangan ketersediaan menyebabkan shutdown sistem, biasanya berdasarkan bug jenis pertama.
Kekhususan:
- Serangan bertarget (Targeted attack) ditujukan untuk mengubah prediksi classifier menjadi kelas tertentu.
- Serangan massal (serangan tidak pandang bulu) ditujukan untuk mengubah respons classifier ke kelas mana pun kecuali yang benar.
Tujuan keamanan adalah untuk melindungi sumber daya dari penyerang dan kepatuhan terhadap persyaratan, pelanggaran yang mengarah pada kompromi sebagian atau keseluruhan sumber daya.
Berbagai model pembelajaran mesin digunakan untuk keselamatan. Misalnya, sistem deteksi virus bertujuan untuk mengurangi kerentanan terhadap virus dengan mendeteksinya sebelum sistem terinfeksi, atau mendeteksi yang sudah ada untuk dihapus. Contoh lain adalah sistem deteksi intrusi (IDS), yang mendeteksi bahwa sistem telah dikompromikan dengan mendeteksi lalu lintas berbahaya atau perilaku mencurigakan dalam sistem. Tugas lain yang dekat adalah sistem pencegahan intrusi (IPS), yang mendeteksi upaya intrusi dan mencegah intrusi ke dalam sistem.
Dalam konteks masalah keamanan, tujuan model pembelajaran mesin, dalam kasus umum, adalah untuk memisahkan peristiwa berbahaya dan mencegahnya mengganggu sistem.
Secara umum, tujuannya dapat dibagi menjadi dua:
integritas : mencegah penyerang mengakses sumber daya sistem
aksesibilitas : mencegah penyerang mengganggu operasi normal.
Ada koneksi yang jelas antara kesalahan tipe kedua dan pelanggaran integritas: contoh berbahaya yang masuk ke sistem bisa berbahaya. Seperti halnya kesalahan jenis pertama biasanya melanggar aksesibilitas, karena sistem itu sendiri menolak salinan data yang andal.
8. Apa cara untuk melindungi terhadap penjahat cyber yang memanipulasi model pembelajaran mesin?
Saat ini, melindungi model pembelajaran mesin dari serangan jahat lebih sulit daripada menyerang itu. Hanya karena tidak peduli berapa banyak kita melatih model, akan selalu ada dataset yang akan bekerja paling buruk.
Dan hari ini tidak ada cara yang cukup efektif untuk membuat model bekerja dengan akurasi 100%. Tetapi ada beberapa tips yang dapat membuat model lebih tahan terhadap contoh berbahaya.
Inilah yang utama: jika dimungkinkan untuk tidak menggunakan model pembelajaran mesin di lingkungan yang berbahaya, lebih baik tidak menggunakannya. Tidak masuk akal untuk menolak pembelajaran mesin jika Anda dihadapkan dengan tugas mengklasifikasikan gambar atau menghasilkan meme. - , - . , , , , , .
, , , . .
, , . , , , , , , , . , , , , , , .
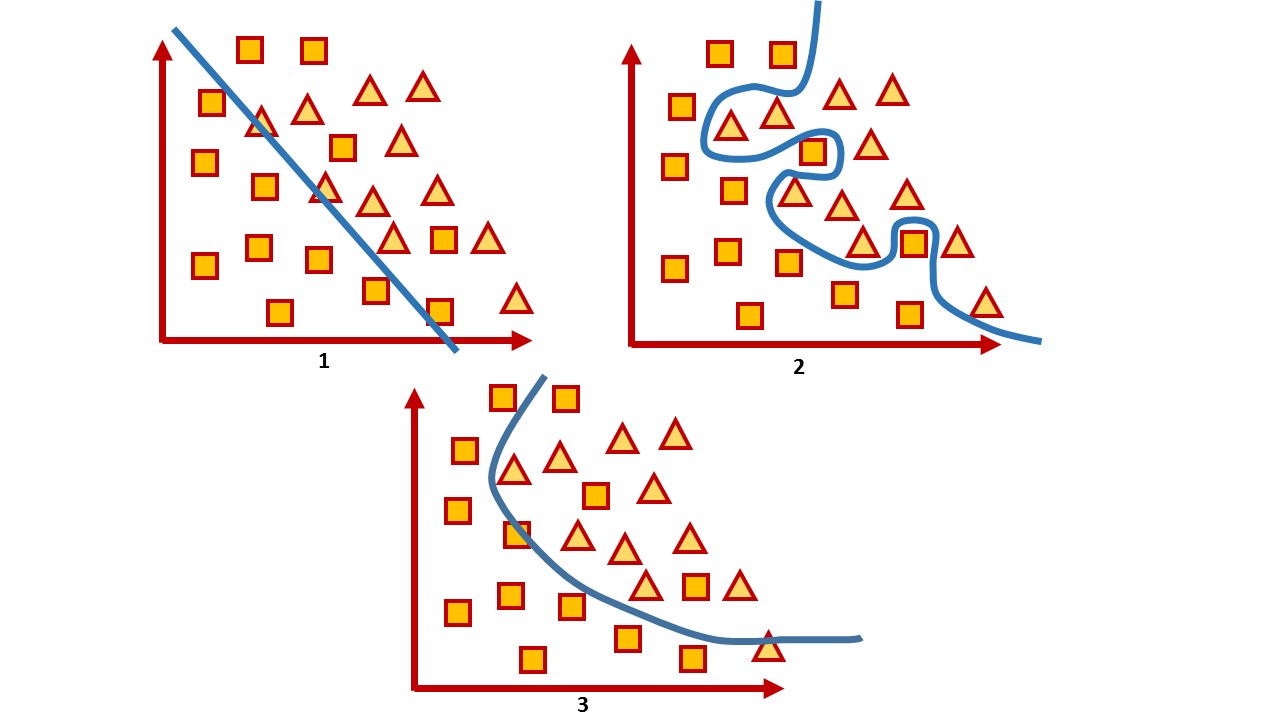
1 — , 2 — , 3 —
, , : . . , .
. , . , . 100%- - , .
- , — . , — , . , .
, , .
9. ?
. : , , , , .
, . . , . , , , «».
, - , . , , . - Twitter, Microsoft, .
? , , — , , . , , , — , , .
, , , « — , »?