Institut Teknologi Massachusetts. Kursus Kuliah # 6.858. "Keamanan sistem komputer." Nikolai Zeldovich, James Mickens. Tahun 2014
Keamanan Sistem Komputer adalah kursus tentang pengembangan dan implementasi sistem komputer yang aman. Ceramah mencakup model ancaman, serangan yang membahayakan keamanan, dan teknik keamanan berdasarkan pada karya ilmiah baru-baru ini. Topik meliputi keamanan sistem operasi (OS), fitur, manajemen aliran informasi, keamanan bahasa, protokol jaringan, keamanan perangkat keras, dan keamanan aplikasi web.
Kuliah 1: “Pendahuluan: model ancaman”
Bagian 1 /
Bagian 2 /
Bagian 3Kuliah 2: "Kontrol serangan hacker"
Bagian 1 /
Bagian 2 /
Bagian 3 Bisakah Anda memberi tahu saya apa kurangnya pendekatan keamanan yang menggunakan
halaman penjaga ?
Pemirsa: butuh waktu lebih lama!
Profesor: tepatnya! Jadi, bayangkan tumpukan ini sangat, sangat kecil, tetapi saya memilih seluruh halaman untuk memastikan bahwa benda kecil ini tidak diserang oleh pointer. Ini adalah proses yang sangat intensif secara spasial, dan orang-orang tidak benar-benar menyebarkan sesuatu seperti ini di lingkungan kerja. Ini mungkin berguna untuk menguji "bug", tetapi Anda tidak akan pernah melakukannya untuk program nyata. Saya pikir sekarang Anda mengerti apa debugger memori
pagar listrik .
Hadirin: Mengapa
halaman penjaga harus begitu besar?
Profesor: Alasannya adalah bahwa mereka biasanya mengandalkan perangkat keras, seperti perlindungan tingkat halaman, untuk menentukan ukuran halaman. Untuk sebagian besar komputer, 2 halaman berukuran 4 KB dialokasikan untuk setiap buffer yang dialokasikan, berjumlah 8 KB. Karena heap terdiri dari objek, halaman terpisah dialokasikan untuk setiap fungsi
malloc . Dalam beberapa mode, debugger ini tidak mengembalikan ruang yang disediakan ke program, sehingga
pagar listrik sangat lahap dalam hal memori dan tidak boleh dikompilasi dengan kode kerja.
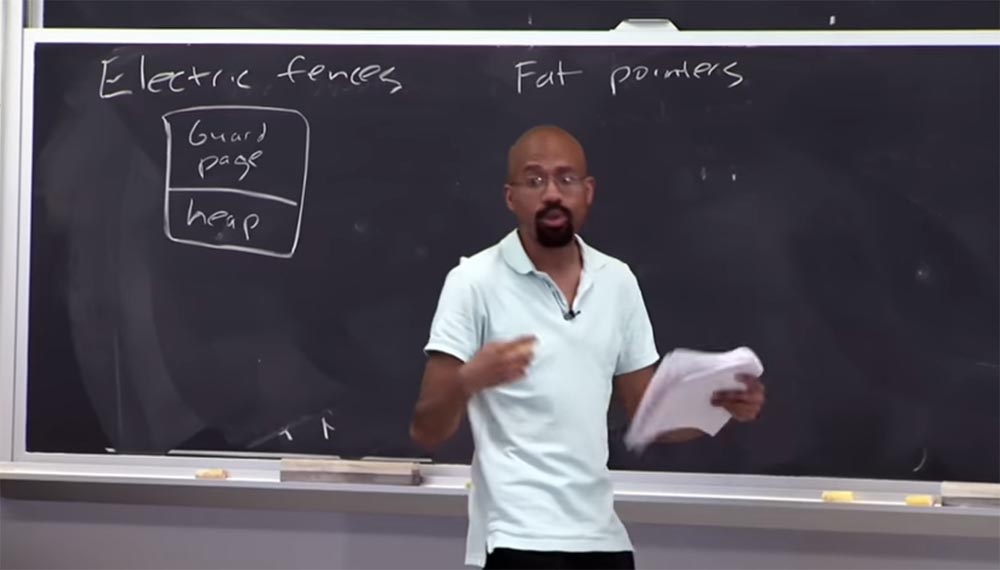
Pendekatan keamanan lain yang layak untuk dilihat adalah
Fat pointer , atau "pointer tebal." Dalam hal ini, istilah "tebal" berarti bahwa sejumlah besar data dilampirkan ke pointer. Dalam hal ini, idenya adalah kita ingin mengubah representasi pointer untuk memasukkan informasi tentang batas-batas dalam komposisinya.
Pointer 32-bit reguler terdiri dari 32 bit, dan alamat berada di dalamnya. Jika kita menganggap "pointer tebal", maka itu terdiri dari 3 bagian. Bagian pertama adalah basis 4-byte, yang berakhiran 4 byte juga dilampirkan. Di bagian pertama, objek dimulai, di bagian kedua berakhir, dan di bagian ketiga, juga 4 byte,
skr alamat tertutup. Dan dalam batas-batas umum ini adalah sebuah pointer.

Jadi, ketika kompiler membuat kode akses untuk "penunjuk tebal" ini, ia memperbarui konten dari bagian terakhir dari
alamat skr dan secara bersamaan memeriksa konten dari dua bagian pertama untuk memastikan bahwa tidak ada yang buruk terjadi dengan pointer selama proses pembaruan.
Bayangkan saya memiliki kode ini:
int * ptr = malloc (8) , ini adalah pointer yang dialokasikan 8 byte. Selanjutnya, saya memiliki beberapa
while yang baru saja akan memberikan beberapa nilai ke pointer dan kemudian kenaikan
ptr ++ pointer berikut. Setiap kali kode ini dieksekusi pada alamat saat ini dari pointer
alamat cur , itu memeriksa apakah pointer berada dalam batas yang ditentukan dalam bagian pertama dan kedua.
Ini adalah kasus dalam kode baru yang dihasilkan oleh kompiler. Grup daring sering menimbulkan pertanyaan tentang apa itu "kode alat". Ini adalah kode yang dihasilkan oleh kompiler. Anda, sebagai programmer, hanya melihat apa yang ditampilkan di sebelah kanan - 4 baris ini. Tetapi sebelum operasi ini, kompiler memasukkan beberapa kode C baru ke dalam
alamat skr , memberikan nilai ke pointer dan memeriksa batas setiap waktu.

Dan jika, ketika menggunakan kode baru, nilainya melampaui batas, fungsi terputus. Ini disebut "kode alat." Ini berarti bahwa Anda mengambil kode sumber menggunakan program C, lalu menambahkan kode sumber C baru, dan kemudian mengkompilasi program baru. Jadi ide dasar di balik
Fat pointer cukup sederhana.
Ada beberapa kelemahan dari pendekatan ini. Kelemahan terbesar adalah ukuran besar pointer. Dan ini berarti bahwa Anda tidak bisa hanya mengambil "penunjuk tebal" dan meneruskannya tidak berubah, di luar perpustakaan shell. Karena mungkin ada harapan bahwa pointer memiliki ukuran standar, dan program akan menyediakannya dengan ukuran ini, yang "tidak akan cocok", karena semuanya akan meledak. Ada juga masalah jika Anda ingin memasukkan pointer dari tipe ini dalam sebuah
struct atau sesuatu seperti itu, karena mereka dapat mengubah ukuran
struct .
Oleh karena itu, hal yang sangat populer dalam kode C adalah mengambil sesuatu seukuran
struct , dan kemudian melakukan sesuatu berdasarkan ukuran ini - simpan ruang disk untuk struktur dengan ukuran ini, dan seterusnya.
Dan satu hal yang lebih rumit adalah bahwa petunjuk ini, sebagai suatu peraturan, tidak dapat diperbarui dengan cara atom. Untuk arsitektur 32-bit, biasanya menulis variabel 32-bit yang bersifat atomik. Tapi "pointer tebal" berisi 3 ukuran
integer , jadi jika Anda memiliki kode yang mengharapkan pointer memiliki nilai atom, Anda mungkin mendapat masalah. Karena untuk melakukan beberapa pemeriksaan ini, Anda harus melihat alamat saat ini dan kemudian melihat ukurannya, dan kemudian Anda mungkin harus menambahnya, dan seterusnya dan seterusnya. Dengan demikian, ini dapat menyebabkan kesalahan yang sangat halus jika Anda menggunakan kode yang mencoba untuk menarik paralel antara pointer biasa dan tebal. Dengan demikian, Anda dapat menggunakan
Fat pointer dalam beberapa kasus, seperti
pagar Electroc , tetapi efek samping dari penggunaannya sangat signifikan sehingga dalam praktik normal pendekatan ini tidak digunakan.
Dan sekarang kita akan berbicara tentang memeriksa batas terkait dengan struktur data bayangan. Gagasan utama dari struktur ini adalah Anda tahu seberapa besar setiap objek yang akan Anda tempatkan, yaitu, Anda tahu ukuran yang Anda butuhkan untuk memesan objek ini. Jadi, misalnya, jika Anda memiliki pointer yang Anda panggil dengan fungsi
malloc , Anda perlu menentukan ukuran objek:
char xp = malloc (size) .

Jika Anda memiliki sesuatu seperti variabel statis seperti
karakter ini
[256] , kompiler dapat secara otomatis mengetahui batas-batas yang seharusnya untuk penempatannya.
Oleh karena itu, untuk masing-masing petunjuk ini, Anda perlu memasukkan dua operasi. Ini terutama aritmatika, seperti
q = p + 7 , atau yang serupa. Penyisipan ini dilakukan dengan mereferensikan tautan tipe
deref * q = 'q' . Anda mungkin bertanya-tanya mengapa Anda tidak bisa mengandalkan tautan saat menempel? Mengapa kita perlu melakukan aritmatika ini? Faktanya adalah bahwa ketika menggunakan C dan c ++, Anda memiliki pointer yang menunjuk ke satu lintasan ke ujung objek yang benar di sebelah kanan, setelah itu Anda menggunakannya sebagai kondisi berhenti. Jadi, Anda pergi ke objek dan segera setelah Anda mencapai trailing pointer ini, Anda benar-benar menghentikan loop atau membatalkan operasi.
Jadi, jika kita mengabaikan aritmatika, kita selalu menyebabkan kesalahan serius, di mana pointer melampaui batas, yang sebenarnya dapat mengganggu pekerjaan banyak aplikasi. Jadi kami tidak bisa hanya menyisipkan tautan, karena bagaimana Anda tahu bahwa ini terjadi di luar batas yang ditetapkan? Aritmatika memungkinkan kita untuk mengatakan apakah itu benar atau tidak, dan di sini semuanya akan sah dan benar. Karena wedging ini menggunakan aritmatika memungkinkan Anda untuk melacak di mana pointer berada relatif terhadap baseline aslinya.
Jadi pertanyaan selanjutnya adalah: bagaimana kita benar-benar menerapkan validasi perbatasan? Karena kita perlu entah bagaimana mencocokkan alamat spesifik dari pointer dengan beberapa jenis informasi batas untuk pointer itu. Dan oleh karena itu, banyak keputusan Anda sebelumnya menggunakan hal-hal seperti, misalnya, tabel hash, atau pohon, yang memungkinkan Anda untuk melakukan pencarian yang benar. Jadi, mengingat alamat penunjuk, saya melakukan beberapa pencarian dalam struktur data ini dan mencari tahu batas-batas yang dimilikinya. Dengan batasan-batasan ini, saya memutuskan apakah saya dapat membiarkan tindakan itu terjadi atau tidak. Masalahnya adalah ini adalah pencarian yang lambat, karena struktur data ini bercabang, dan ketika memeriksa pohon, Anda perlu memeriksa banyak cabang seperti itu sampai Anda menemukan nilai yang tepat. Dan bahkan jika itu adalah tabel hash, Anda harus mengikuti rantai kode dan sebagainya. Jadi, kita perlu mendefinisikan struktur data yang sangat efektif yang melacak batas-batas mereka, yang akan membuat verifikasi ini sangat sederhana dan jelas. Jadi mari kita mulai sekarang.
Tetapi sebelum kita melakukannya, izinkan saya memberi tahu Anda secara singkat tentang cara kerja pendekatan
alokasi memori teman . Karena ini adalah salah satu hal yang sering ditanyakan.
Alokasi memori teman membagi memori menjadi beberapa partisi yang merupakan kelipatan dari kekuatan 2, dan mencoba mengalokasikan permintaan memori di dalamnya. Mari kita lihat cara kerjanya. Pada awalnya,
alokasi teman memperlakukan memori yang tidak terisi sebagai satu blok besar - ini adalah persegi panjang 128-bit atas. Kemudian, ketika Anda meminta blok yang lebih kecil untuk alokasi dinamis, ia mencoba untuk membagi ruang alamat ini menjadi bagian-bagian dengan peningkatan 2 sampai menemukan blok yang cukup untuk kebutuhan Anda.
Misalkan permintaan tipe
a = malloc (28) tiba, yaitu permintaan untuk mengalokasikan 28 byte. Kami memiliki blok 128 byte yang terlalu boros untuk dialokasikan untuk permintaan ini. Oleh karena itu, blok kami dibagi menjadi dua blok 64 byte - dari 0 hingga 64 byte dan dari 64 byte hingga 128 byte. Dan ukuran ini juga besar untuk permintaan kami, jadi
sobat lagi membagi satu blok 64 byte menjadi 2 bagian dan menerima 2 blok 32 byte.

Kurang tidak mungkin, karena 28 byte tidak akan cocok, dan 32 adalah ukuran minimum yang paling cocok. Jadi sekarang blok 32 byte ini akan dialokasikan ke alamat kami a. Misalkan kita memiliki permintaan lain untuk
b = malloc (50) .
Sobat memeriksa blok yang dipilih, dan karena 50 lebih besar dari setengah dari 64, tetapi kurang dari 64, menempatkan nilai b di blok paling kanan.
Akhirnya, kami memiliki permintaan lain untuk 20 byte:
c = malloc (20) , nilai ini ditempatkan di blok tengah.
 Buddy
Buddy memiliki properti yang menarik: ketika Anda membebaskan memori di blok dan di sebelahnya adalah blok dengan ukuran yang sama, setelah membebaskan kedua blok,
buddy menggabungkan dua blok tetangga yang kosong menjadi satu.

Misalnya, ketika kita memberikan perintah
© gratis , kita akan
membebaskan blok tengah, tetapi penyatuan tidak akan terjadi, sehingga blok di sebelahnya masih sibuk. Tetapi setelah membebaskan blok pertama menggunakan perintah
(a) gratis , kedua blok akan bergabung menjadi satu. Kemudian, jika kita membebaskan nilai b, blok tetangga akan digabungkan lagi dan kita akan mendapatkan seluruh blok dengan ukuran 128 byte, seperti pada awalnya. Keuntungan dari pendekatan ini adalah bahwa Anda dapat dengan mudah menemukan di mana sobat adalah dengan aritmatika sederhana dan menentukan batas-batas memori. Inilah cara alokasi memori bekerja dengan pendekatan
alokasi memori Sobat .
Semua kuliah saya sering ditanyakan, bukankah pendekatan seperti itu sia-sia? Bayangkan bahwa pada awalnya saya memiliki permintaan 65 byte, saya harus mengalokasikan seluruh blok 128 byte untuk itu. Ya, ini boros, sebenarnya Anda tidak memiliki memori dinamis dan Anda tidak dapat lagi mengalokasikan sumber daya di blok yang sama. Tapi sekali lagi, ini kompromi, karena sangat mudah untuk membuat perhitungan, cara membuat merger dan sejenisnya. Jadi, jika Anda menginginkan alokasi memori yang lebih akurat, Anda perlu menggunakan pendekatan yang berbeda.
Jadi, apa yang sistem
Buggy bouncing checking (BBC) lakukan?

Dia melakukan beberapa trik, salah satunya adalah pemisahan blok memori menjadi 2 bagian, salah satunya berisi objek, dan yang kedua adalah tambahan untuk itu. Jadi, kita memiliki 2 jenis batas - batas objek dan batas distribusi memori. Keuntungannya adalah tidak perlu menyimpan alamat dasar, dan pencarian cepat menggunakan tabel garis dimungkinkan.
Semua ukuran distribusi kami adalah 2 pangkat dari
n , di mana
n adalah bilangan bulat. Prinsip
2n ini disebut
kekuatan dua . Oleh karena itu, kita tidak perlu banyak bit untuk membayangkan seberapa besar ukuran distribusi tertentu. Sebagai contoh, jika ukuran cluster adalah 16, maka Anda hanya perlu memilih 4 bit - ini adalah konsep logaritma, yaitu, 4 adalah eksponen
n , di mana Anda perlu menaikkan angka 2 untuk mendapatkan 16.
Ini adalah pendekatan yang cukup ekonomis untuk alokasi memori, karena jumlah minimum byte yang digunakan, tetapi harus kelipatan 2, yaitu, Anda dapat memiliki 16 atau 32, tetapi tidak 33 byte. Selain itu,
pemeriksaan bouncing Buggy memungkinkan Anda untuk menyimpan informasi tentang nilai batas dalam array linier (1 byte per catatan) dan memungkinkan Anda untuk mengalokasikan memori dalam 1 slot dengan ukuran 16 byte. mengalokasikan memori dengan granularity slot. Apa artinya ini?

Jika kita memiliki slot 16-byte di mana kita akan meletakkan nilai
p = malloc (16) , maka nilai dalam tabel akan terlihat seperti
tabel [p / slot.size] = 4 .

Misalkan kita sekarang perlu menempatkan nilai 32 byte dalam ukuran
p = malloc (32) . Kami perlu memperbarui tabel perbatasan agar sesuai dengan ukuran baru. Dan ini dilakukan dua kali: pertama sebagai
tabel [p / slot.size] = 5 , dan kemudian sebagai
tabel [(p / slot.size) + 1] = 5 - pertama kali untuk slot pertama, yang dialokasikan untuk memori ini, dan yang kedua kali - untuk slot kedua. Jadi kami mengalokasikan 32 byte memori. Inilah yang tampak seperti log distribusi ukuran. Jadi, untuk dua slot alokasi memori, tabel batas diperbarui dua kali. Apakah itu jelas? Contoh ini ditujukan untuk orang yang meragukan apakah log dan tabel memiliki arti atau tidak. Karena tabel dikalikan setiap kali alokasi memori terjadi.
Mari kita lihat apa yang terjadi dengan tabel perbatasan. Misalkan kita memiliki kode C yang terlihat seperti ini:
p '= p + i , yaitu, pointer
p' diperoleh dari
p dengan menambahkan beberapa variabel
i . Jadi bagaimana kita mendapatkan ukuran memori yang dialokasikan untuk
p ? Untuk melakukan ini, Anda melihat tabel menggunakan kondisi logis berikut:
size = 1 << tabel [p >> log slot_size]
Di sebelah kanan kita memiliki ukuran data yang dialokasikan untuk
p , yang seharusnya 1. Kemudian Anda memindahkannya ke kiri dan melihat tabel, ambil ukuran pointer ini, lalu pindah ke kanan, di mana log dari tabel ukuran slot berada. Jika aritmatika berfungsi, maka kita mengikat pointer dengan benar ke tabel batas. Artinya, ukuran penunjuk harus lebih besar dari 1, tetapi lebih kecil dari ukuran slot. Di sebelah kiri kita memiliki nilai, dan di sebelah kanan - ukuran slot, dan nilai pointer terletak di antara mereka.
Misalkan ukuran pointer adalah 32 byte, maka dalam tabel, di dalam tanda kurung, kita akan memiliki angka 5.
Misalkan kita ingin menemukan kata kunci dasar dari penunjuk ini:
base = p & n (ukuran - 1) . Apa yang akan kita lakukan memberi kita massa tertentu, dan massa ini akan memungkinkan kita untuk mengembalikan
basis yang terletak di sini. Bayangkan ukuran kita 16, dalam biner 16 = ... 0010000. Ellipsis berarti masih ada banyak nol, tetapi kami tertarik pada unit ini dan nol di belakangnya. Jika kita mempertimbangkan (16 -1), maka akan terlihat seperti ini: (16 - 1) = ... 0001111. Dalam kode biner, kebalikan dari ini akan terlihat seperti ini: ~ (16-1) ... 1110000.
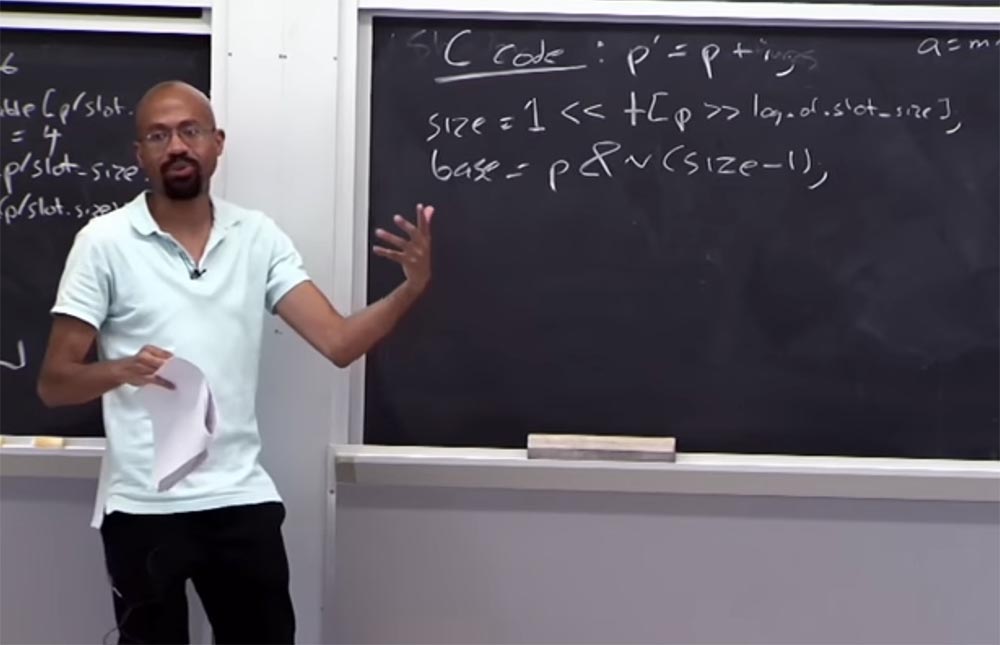

Dengan demikian, hal ini memungkinkan kita untuk pada dasarnya menghapus bit, yang pada dasarnya akan diberikan dari pointer saat ini dan memberi kita
basisnya . Berkat ini, akan sangat mudah bagi kami untuk memeriksa apakah pointer ini berada dalam batas. Jadi kita cukup memeriksa bahwa
(p ')> = basis dan apakah nilai (
p' - basis) lebih kecil dari ukuran yang dipilih.

Ini adalah hal yang cukup sederhana untuk mengetahui apakah pointer berada dalam batas memori. Saya tidak akan masuk ke rincian, cukuplah untuk mengatakan bahwa semua aritmatika biner diselesaikan dengan cara yang sama. Trik semacam itu memungkinkan Anda menghindari perhitungan yang lebih rumit.
Ada satu lagi, properti kelima dari
pemeriksaan bouncing Buggy - ia menggunakan sistem memori virtual untuk mencegah melampaui batas yang ditetapkan untuk pointer. Gagasan utamanya adalah jika kita memiliki aritmatika untuk pointer yang kita tentukan jalan keluarnya, maka kita dapat mengatur bit orde tinggi untuk pointer.

Dengan demikian, kami menjamin bahwa penereferensi pointer tidak akan menyebabkan masalah perangkat keras. Menyetel
urutan tinggi agak tinggi dengan sendirinya tidak menyebabkan masalah, dereferensi penunjuk dapat menyebabkan masalah.
Versi lengkap dari kursus ini tersedia di
sini .
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikannya kepada teman-teman Anda,
diskon 30% untuk pengguna Habr pada analog unik dari server entry-level yang kami temukan untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps dari $ 20 atau bagaimana membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
Dell R730xd 2 kali lebih murah? Hanya kami yang memiliki
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV dari $ 249 di Belanda dan Amerika Serikat! Baca tentang
Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?