
Tahap
kualifikasi DataScienceGame2018, yang terjadi dalam format InClass kaggle, baru-baru ini berakhir.
DataScienceGame adalah kompetisi siswa internasional yang diadakan setiap tahun. Tim kami berhasil berada di posisi ke-3 di antara lebih dari 100 tim dan pada saat yang sama JANGAN pergi ke tahap akhir.
Interaksi tim

Dalam kompetisi kaggle besar, tim biasanya dibentuk di sepanjang jalan dari orang-orang yang nyaris unggul di papan peringkat (
contoh khas tim ), dan karenanya mewakili kota yang berbeda dan, seringkali, negara yang berbeda. Segera, sesuai dengan ketentuan kompetisi, setiap tim harus terdiri dari 4 orang dari satu lembaga pendidikan (kami mewakili MIPT). Dan itu berarti sebagian besar peserta, menurut saya, semua diskusi berlangsung secara offline. Sebagai contoh, kami memiliki seluruh tim tinggal di satu lantai asrama, jadi kami hanya berkumpul di malam hari dengan seseorang di ruangan itu.
Kami tidak memiliki pemisahan tugas, perencanaan atau pembangunan tim. Di awal kompetisi, kami hanya duduk melingkar, mendiskusikan apa yang bisa kami lakukan di masa depan dan tidak. Kode itu ditulis oleh satu orang, dan sisanya pada saat itu hanya melihat dan memberi saran. Saya tidak begitu suka menulis kode, jadi saya suka interaksi ini, walaupun itu jelas bukan yang terbaik. Tetapi karena tahap kualifikasi jatuh tepat pada sesi di universitas, bagian dari tim tidak dapat mencurahkan banyak waktu dan saya masih harus menulis kode sendiri.
Deskripsi tugas
Menurut sejarah yang diberikan oleh BNP, perlu untuk memprediksi apakah pengguna akan tertarik pada beberapa keamanan (Isin) minggu depan atau tidak. Pada saat yang sama, "bunga" ditentukan oleh kolom TradeStatus, yang menggambarkan status transaksi dan memiliki nilai unik berikut:
- Transaksi selesai (yaitu, pengguna membeli / menjual kertas)
- Pengguna melihat kertas, tetapi tidak menyelesaikan transaksi
- Pengguna menyisihkan kertas untuk pembelian / penjualan di masa depan
- Transaksi tidak selesai karena alasan teknis.
- Memegang
Jadi, jika TradeStatus mengambil nilai 1) -4), maka dianggap bahwa pengguna tertarik pada makalah ini dan tidak tertarik pada semua kasus lainnya. Pada saat yang sama, paragraf 4) menunjukkan bahwa garis dengan transaksi ini adalah fiktif, dan dibuat untuk pelaporan yang mudah. Yaitu, pada akhir setiap bulan, status portofolio masing-masing pengguna dibandingkan dengan keadaannya sebulan lalu, dan jika, misalnya, pengguna entah bagaimana dalam portofolio, jumlah keamanan tertentu meningkat sebesar 10k, maka baris ini ditandai dengan “pembelian” “Dan dengan nilai nominal 10k. Baris yang ditandai "holding" memiliki variabel target 0 (pengguna tidak tertarik).
Jika Anda memikirkannya, Anda dapat memahami bahwa set data berjalan sebagai berikut: pengguna aktif di situs web bank - mereka melihat / membeli kertas, dan semua tindakan ini dicatat dalam database. Misalnya, pengguna dengan id = 15 memutuskan untuk menunda kertas dengan id = 7 untuk pembelian di masa mendatang. Segera dalam database muncul garis yang sesuai dengan target 1 (pengguna menjadi tertarik)
| ID pengguna | ID keamanan | Jenis transaksi | Status transaksi | Bidang tambahan | Target |
|---|
| 15 | 7 | Beli | Sisihkan untuk masa depan | ... | 1 |
Selain itu, catatan bulanan dengan status memegang dan target 0 ditambahkan ke ini. Misalnya, pengguna 15 meningkatkan jumlah saham 93 karena beberapa alasan (mungkin ia membelinya di situs lain), sementara ia sendiri tidak menggunakan makalah ini di situs web BNP berinteraksi (tidak tertarik).
| ID pengguna | ID keamanan | Jenis transaksi | Status transaksi | Bidang tambahan | Target |
|---|
| 15 | 93 | Beli | Memegang | ... | 0 |
Tapi, jelas, untuk BNP, tidak ada gunanya memprediksi kepemilikan yang sama ini, karena mereka dapat dipulihkan secara ambigu dari markas. Ini berarti bahwa ada jenis token lain yang tidak ada dalam tabel pelatihan, yaitu, tiga kali lipat "pengguna - kertas - jenis transaksi" yang tidak muncul dalam database. Artinya, pengguna TIDAK tertarik pada tindakan tertentu, itu berarti dia tidak berinteraksi dengannya di sistem BNP, sehingga baris yang sesuai tidak muncul dalam database, yang berarti harus memiliki target 0. Dan ini berarti Anda perlu membuat garis seperti itu untuk melatih diri sendiri ( lihat bagian “Menyusun sampel pelatihan”). Semua ini bisa menimbulkan kebingungan, karena banyak peserta mungkin berpikir - ada dataset, ada nol dan satu - Anda dapat memprediksi. Tapi tidak sesederhana itu.
Jadi, di kereta ada tabel dengan sejarah transaksi (yaitu, interaksi "pengguna - kertas - jenis transaksi" dan beberapa informasi tambahan tentang mereka) dan banyak piring lainnya dengan karakteristik pengguna, stok, kondisi pasar global. Dalam tes ini hanya ada tiga kali lipat "pengguna - kertas - jenis transaksi" dan untuk setiap tiga kali lipat Anda perlu memperkirakan apakah akan muncul minggu depan. Misalnya, Anda perlu memperkirakan apakah id pengguna = 8 akan tertarik pada tindakan id = 46 dengan jenis transaksi "penjualan"?
| ID pengguna | ID keamanan | Jenis transaksi | Target |
|---|
| 8 | 46 | Dijual | ? |
Fitur membangun dataset
Karena, seperti yang sudah saya katakan, dalam database BNP nyata tidak ada garis dengan nol "tidak memegang", panitia entah bagaimana menghasilkan garis seperti itu untuk tes itu sendiri. Dan di mana ada generasi data buatan, sering ada wajah dan informasi tersirat lainnya yang dapat secara signifikan meningkatkan hasilnya tanpa mengubah model / fitur. Bagian ini menjelaskan beberapa fitur membangun dataset yang berhasil kami pahami, tetapi yang, sayangnya, tidak membantu kami dengan cara apa pun.

Jika Anda melihat tiga kali lipat "tipe pengguna - kertas - transaksi" dari tabel tes, mudah untuk melihat bahwa jumlah transaksi dengan jenis "pembelian" dan "penjualan" persis sama, dan tabel tersebut secara ketat diurutkan berdasarkan atribut ini: pertama semua pembelian, lalu semua penjualan. Jelas, ini bukan kecelakaan dan timbul pertanyaan: bagaimana ini bisa terjadi? Sebagai contoh, dengan cara ini: penyelenggara mengambil semua catatan nyata dari database mereka untuk minggu yang kita perlu membuat prediksi (garis tersebut memiliki target 1), entah bagaimana menghasilkan baris baru (target mereka adalah 0), yang tidak sesuai dengan yang dijelaskan di atas. Jadi ternyata tabel di mana jenis transaksi (pembelian / penjualan) diatur dalam urutan acak:
| ID pengguna | ID keamanan | Jenis transaksi | Target |
|---|
| 8 | 46 | Dijual | 1 |
| 2 | 6 | Beli | 1 |
| 158 | 73 | Beli | 1 |
| 3 | Tanggal 29 | Dijual | 0 |
| 67 | 9 | Beli | 0 |
| 17 | 465 | Dijual | 0 |
Sekarang dimungkinkan untuk mengatur jenis pembelian ke semua lini dengan jenis transaksi "penjualan", dan jika targetnya adalah satu, maka itu akan menjadi nol (dalam kebanyakan kasus, pengguna tertarik pada beberapa kertas dengan hanya satu status: pembelian atau penjualan). Ini akan menghasilkan tabel berikut:
| ID pengguna | ID keamanan | Jenis transaksi | Target |
|---|
| 8 | 46 | Beli | 0 |
| 2 | 6 | Beli | 1 |
| 158 | 73 | Beli | 1 |
| 3 | Tanggal 29 | Beli | 0 |
| 67 | 9 | Beli | 0 |
| 17 | 465 | Beli | 0 |
Langkah terakhir tetap: untuk melakukan hal yang sama, tetapi mengganti "pembelian untuk dijual" dan mengatur target yang benar:
| ID pengguna | ID keamanan | Jenis transaksi | Target |
|---|
| 8 | 46 | Dijual | 1 |
| 2 | 6 | Dijual | 0 |
| 158 | 73 | Dijual | 0 |
| 3 | Tanggal 29 | Dijual | 0 |
| 67 | 9 | Dijual | 0 |
| 17 | 465 | Dijual | 0 |
Menggabungkan meja dengan "pembelian" dan meja dengan "penjualan" kita mendapatkan (jika kita adalah penyelenggara) meja seperti yang diberikan kepada kita dalam ujian. Sangat mudah untuk memahami bahwa bagian pertama dan kedua dari tabel yang dibangun dengan cara ini memiliki urutan pasangan pengguna-kertas yang sama, yang sebenarnya ternyata demikian dalam tabel pengujian.
Fitur lain adalah bahwa ada banyak baris dalam dataset pelatihan di mana indeks pengguna diulang beberapa kali berturut-turut, meskipun fakta bahwa dataset tidak diurutkan berdasarkan salah satu dari tanda-tanda:
| ID pengguna | ID keamanan | Jenis transaksi | Target |
|---|
| 8 | 46 | Dijual | ? |
| 8 | 152 | Dijual | ? |
| 8 | 73 | Beli | ? |
Rekan satu tim menganggap ini normal, dan dataset awalnya diurutkan berdasarkan ID pengguna, dan penyelenggara hanya mengacaukannya dengan buruk (misalnya, jika shuffle diatur pada permutasi acak dan tidak ada permutasi yang cukup seperti itu). Mencoba memastikan hal ini, ia pergi melalui empat pengocokan dari perpustakaan yang berbeda, tetapi tidak ada pengulangan yang sering terjadi. Tes juga memiliki fitur ini. Ada ide bahwa panitia tidak menghasilkan angka nol, tetapi hanya mengambil pasangan lama dari kereta. Untuk memeriksa, saya memutuskan untuk melakukan hal berikut: untuk setiap pasangan “pengguna - kertas” dari tes, bandingkan nomor baris dari kereta ketika pasangan ini pertama kali bertemu untuk pertama kalinya dan membuat plot dari ini. Misalnya, kita melihat baris pertama dalam tes, biarkan ia memiliki id pengguna = 8 dan id = kertas = 15. Sekarang kita pergi melalui tabel pelatihan dari atas ke bawah dan mencari ketika pasangan ini pertama kali muncul, biarlah, misalnya, Baris ke-51. Kami mendapat perbandingan: baris pertama dalam tes berada di kereta ke-51, jadi kami merencanakan titik dengan koordinat (1, 51) pada grafik. Kami melakukan ini untuk seluruh tes dan mendapatkan grafik berikut:
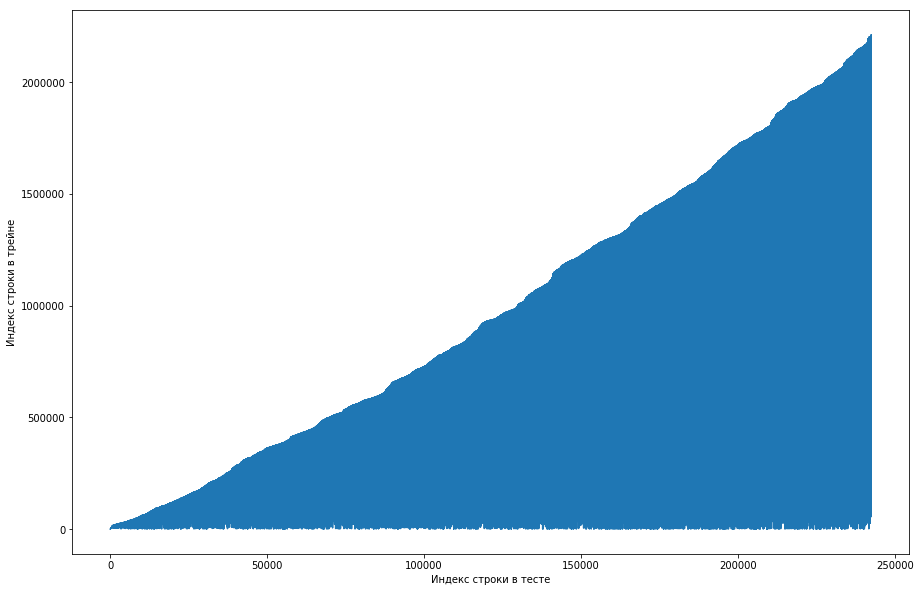
Dapat dilihat dari ini bahwa, pada dasarnya, jika pasangan pernah bertemu sebelumnya di kereta, maka di meja tes posisinya akan lebih tinggi. Tetapi pada saat yang sama, ada beberapa lonjakan pada grafik (sebenarnya tidak begitu banyak, tetapi karena resolusi layar sepertinya ada segitiga yang solid). Selain itu, jumlah emisi kira-kira bertepatan dengan jumlah unit yang diharapkan dalam pengujian. Tentu saja, kami mencoba menandai emisi sebagai unit dan mengirimkannya ke papan peringkat, tetapi, sayangnya, itu tidak berhasil. Tetapi bagi saya sepertinya masih ada semacam wajah (), dan, sebagai kapten tim, saya menyarankan menghabiskan lebih banyak waktu untuk memahami bagaimana hal ini bisa terjadi, dan kami masih punya waktu untuk melatih para model dan membuat tanda-tanda. Penafian: kami menghabiskan banyak waktu untuk hal ini, tetapi seminggu sebelum akhir kompetisi panitia menulis di forum bahwa hanya tiga kali lipat selama 6 bulan terakhir yang dimasukkan ke dalam dataset uji, dan tidak semua. Nah, jika Anda melakukan operasi yang dijelaskan di atas, tetapi selama 6 bulan terakhir, dan bukan hanya dataset, Anda mendapatkan kurva datar yang monoton:
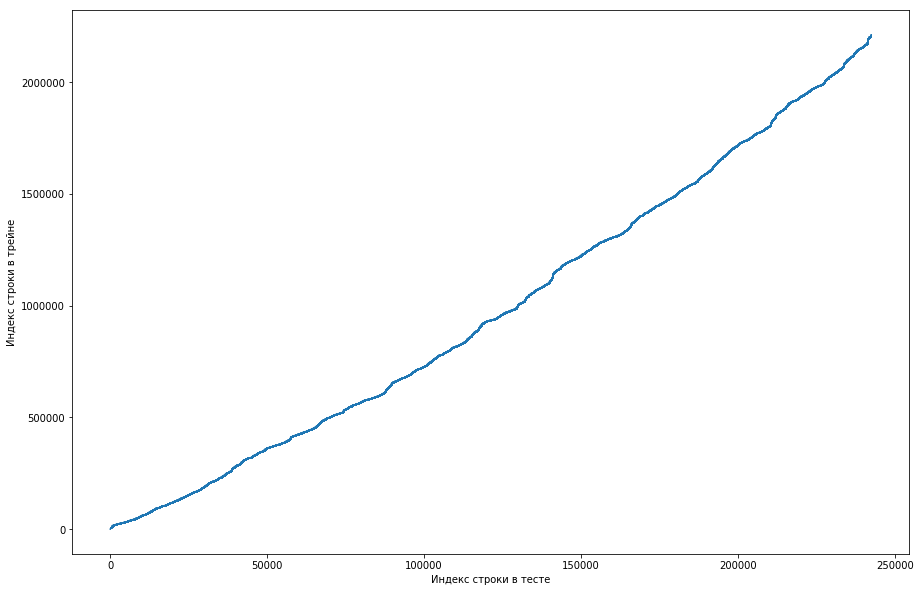
Dan ini berarti tidak ada wajah di sini dan tidak mungkin ada.
Pelatihan diatur
Karena dalam tes ini Anda perlu membuat prediksi untuk tiga kali lipat selama satu minggu, kami akan membagi dataset pelatihan menjadi beberapa minggu (pada saat yang sama, setiap minggu rata-rata ada 20k tiga kali lipat “pengguna - kertas - jenis transaksi”). Sekarang untuk tiga, kita dapat mengatakan apakah dia bertemu di minggu tertentu atau tidak. Pada saat yang sama, kami sudah memiliki tiga kali lipat positif (ini semua entri dari minggu ini di tabel kereta api), dan yang negatif perlu dihasilkan entah bagaimana. Ada banyak opsi untuk melakukan hal ini. Misalnya, Anda dapat memilah-milah semua tiga kali lipat yang tidak ada selama minggu tertentu dalam dataset pelatihan. Jelas bahwa sampel akan sangat tidak seimbang, dan ini buruk. Pertama-tama Anda dapat menghasilkan pengguna secara proporsional dengan frekuensi kemunculan mereka dalam dataset, dan kemudian entah bagaimana menambahkan promosi kepada mereka. Tetapi dengan pendekatan ini, akan ada banyak baris yang statistiknya tidak dapat dihitung, yang juga buruk. Seperti yang kami lakukan: kami mengambil semua jenis tiga kali lipat yang sebelumnya ditemui di kereta, menyalinnya, mengganti beli / jual dengan yang berlawanan, dan menggabungkan dua tabel ini. Jelas bahwa duplikat dapat terjadi dengan cara ini (misalnya, jika pengguna pernah membeli dan menjual saham), tetapi ada beberapa dari mereka, dan setelah penghapusan, sebuah meja berisi 500rb tiga kali lipat yang unik diperoleh. Itu saja, sekarang untuk setiap minggu untuk setiap tiga Anda dapat mengatakan apakah dia bertemu atau tidak (dan berapa kali?).
Karena pada dasarnya kami berurusan dengan deret waktu - pengguna melihat iklan tertentu beberapa kali setiap minggu, kami akan membuat tabel untuk melatih penggolong waktu dengan cara klasik untuk deret waktu. Yaitu, kami akan mengambil minggu terakhir yang tersedia dari kereta, melihat apakah setiap tiga "pelanggan - isin - beli atau jual" bertemu minggu ini. Itu akan menjadi target. Dan kami akan menghitung berbagai statistik sebagai fitur, misalnya, selama 6 minggu terakhir (lebih lanjut tentang statistik di bagian "Tanda"). Sekarang mari kita lupakan tentang keberadaan minggu lalu dan melakukan hal yang sama, tetapi untuk minggu kedua dari belakang dan menyatukan tabel. Ini dapat dilakukan beberapa kali, dengan demikian meningkatkan kereta "tinggi", tetapi pada saat yang sama, interval yang kita anggap statistik menurun secara alami. Kami mengulangi operasi ini 10 kali, karena jika kami berbuat lebih banyak, maka liburan Tahun Baru dan masalah terkait akan ditargetkan, yang akan memperburuk kualitas akhir model. Gambar penjelasan:
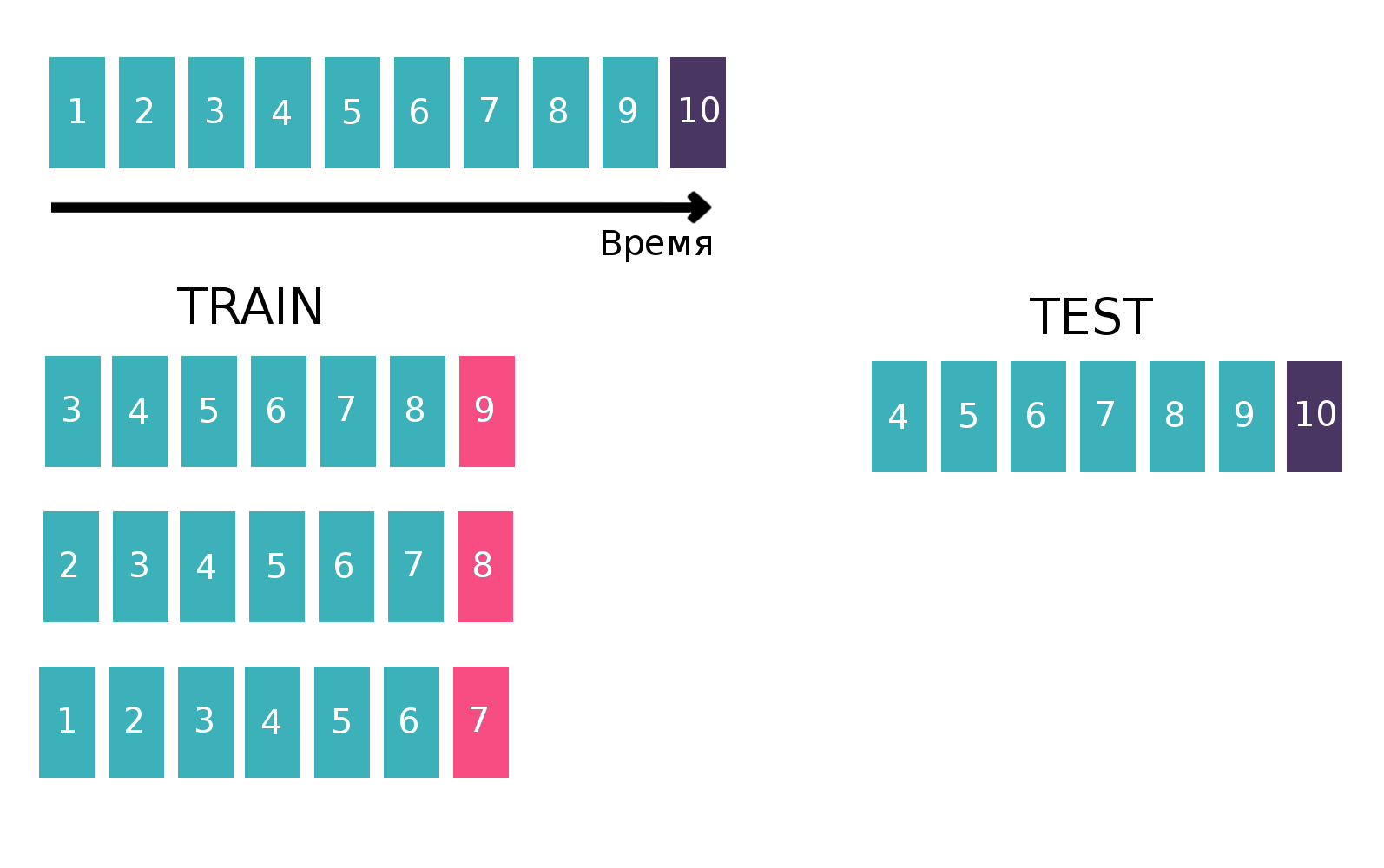
Informasi lebih lanjut tentang deret waktu dan validasi deret waktu dapat ditemukan di
sini .
Tanda
Seperti yang saya katakan, ada banyak tabel yang entah bagaimana mencirikan kondisi pengguna, saham atau pasar global (mata uang utama dan beberapa indikator). Tetapi semuanya hampir tidak meningkatkan kualitas, dan tanda-tanda utamanya adalah statistik yang dihitung untuk pasangan "pelanggan - isin" dan tiga kali lipat "pelanggan - isin - beli atau jual", misalnya, seperti:
- Seberapa sering pasangan / tiga bertemu dalam 1, 2, 5, 20, 100 minggu terakhir?
- Statistik pada interval waktu antara pertemuan pasangan / tiga kali lipat dalam dataset (rata-rata, std, maks, mnt)
- Jarak waktu ke pertama / terakhir kali pasangan / tiga bertemu
- Proporsi setiap nilai TradeStatus untuk pasangan / tiga kali lipat
- Statistik tentang berapa kali seminggu suatu pasangan / rangkap tiga terjadi (rata-rata, std, maks, min)
Selain itu, pada hari terakhir kompetisi saya membaca pada formulir bahwa untuk menjual saham, Anda harus membelinya terlebih dahulu. Pengetahuan ini memungkinkan Anda untuk membuat banyak tanda yang lebih berguna, tetapi, untuk beberapa alasan, bagi saya itu tidak jelas.
Dalam kode, ini semua dinyatakan oleh fungsi dengan panjang 200 baris, yang menghasilkan tanda-tanda yang sama untuk masing-masing dari sepuluh buah kereta (untuk bagian di mana target, misalnya, minggu 7, kita tidak boleh menggunakan informasi untuk tanggal 8 dan 9). Dengan mempertimbangkan tabel tambahan, sekitar 300 tanda direkrut. Seperti yang sudah saya katakan, kami menghasilkan 500k tiga kali lipat yang unik dan mengambil 10 minggu terakhir sebagai target, oleh karena itu tabel pelatihan "tinggi" adalah 500k * 10 = 5kb baris.
Beberapa pengakuan lagi dijelaskan dalam
keputusan tempat kedua . Orang-orang membangun tabel pengguna / kertas, di mana di setiap sel ada unit jika pengguna pernah tertarik pada makalah ini dan nol sebaliknya. Dengan menghitung jarak kosinus antara pengguna dalam tabel ini, Anda bisa mendapatkan konvergensi pengguna di antara mereka sendiri. Jika Anda menerapkan PCA ke tabel kesamaan yang dihasilkan, Anda mendapatkan serangkaian fitur yang mencirikan pengguna dengan beberapa cara.
Model atau bertarung demi seperseribu
Perlu dicatat bahwa selama hampir tiga minggu tidak ada yang bisa mengalahkan garis dasar dari BNP, yang memiliki kecepatan 0,794 (ROC AUC) di leaderboard, dan ini terlepas dari kenyataan bahwa keputusan untuk "cukup menghitung berapa kali pasangan itu bertemu sebelumnya" memberi 0,71 di leaderboard, dan beberapa peserta menerima semua 0,74 tanpa menggunakan pembelajaran mesin.
Tapi kami menggunakan pembelajaran mesin, apalagi, pada hari terakhir kompetisi (yang bertepatan dengan akhir sesi), kami memutuskan untuk berhenti
jika Anda tahu apa yang saya maksud dan membuat campuran besar model yang berbeda dilatih pada subset tanda yang berbeda dengan jumlah minggu yang berbeda dalam Melatih. Seperti yang sudah saya katakan, sampel pelatihan kami terdiri dari 1,5k garis, dengan satu target di antaranya sekitar 150k. Ukuran tes adalah 400rb, sedangkan perkiraan jumlah unit adalah 20rb (rata-rata, sebenarnya, ada begitu banyak tiga kali lipat yang unik). Artinya, proporsi unit dalam tes secara signifikan lebih tinggi daripada di kereta. Oleh karena itu, dalam semua model kami, kami menyesuaikan parameter scale_pos_weight, yang memberikan bobot pada kelas. Informasi lebih lanjut tentang parameter ini dapat ditemukan dalam
analisis solusi terbaik dari salah satu DataScienceGame tahun lalu. Matriks korelasi prediksi model kami ditunjukkan pada gambar:
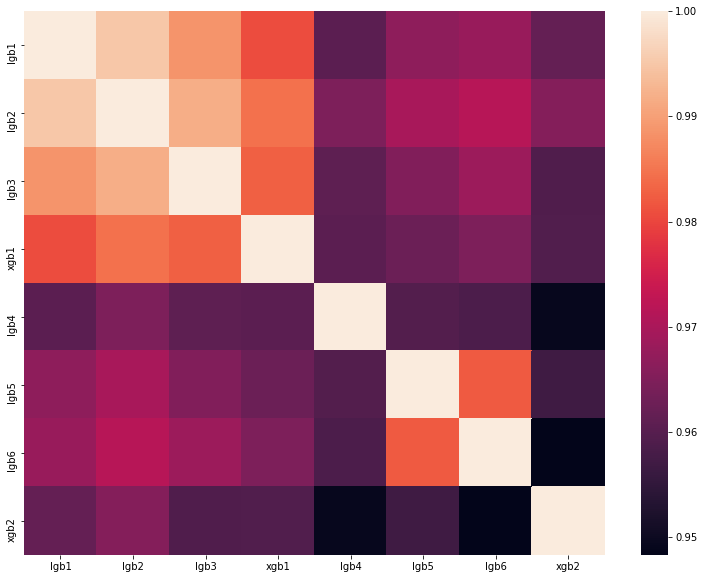
Seperti yang Anda lihat, kami memiliki banyak model yang sangat berbeda, yang memungkinkan kami untuk mendapatkan kecepatan 0,80204 di papan peringkat.
Mengapa kita tidak pergi ke Prancis untuk tahap akhir
Hasilnya, kami menunjukkan hasil yang baik dan menempati posisi ketiga di papan peringkat privet. Tetapi panitia menetapkan aturan berikut untuk pemilihan finalis:
- Tidak lebih dari 20 tim terbaik
- Tidak lebih dari 5 tim terbaik dari negara ini
- Tidak lebih dari 1 tim dari lembaga pendidikan
Dan semuanya akan baik-baik saja jika tim lain dari Institut Fisika dan Teknologi Moskow dengan kecepatan 0,80272 tidak akan berada di posisi kedua. Artinya, kita hanya 0,00068 di belakang. Sayang sekali, tapi tidak ada yang bisa dilakukan. Kemungkinan besar, penyelenggara membuat peraturan sedemikian sehingga orang-orang dari satu universitas tidak saling membantu dengan cara apa pun, tetapi dalam kasus kami, kami tidak tahu apa-apa tentang tim tetangga dan tidak menghubunginya dengan cara apa pun.
Ringkasan
Tahun ini pada bulan September di Paris, 5 tim dari Rusia, satu dari Ukraina dan dua tim dari Jerman dan Finlandia, yang terdiri dari siswa berbahasa Rusia, akan bersaing untuk tempat pertama. Sebanyak 8 tim ru-komunitas, yang sekali lagi membuktikan dominasi ru-segmen basis data. Dan saya
dipindahkan ke Sharaga, saya berlatih dan melatih diri saya sendiri, sehingga tahun depan saya masih bisa mengatasi tahap kualifikasi.