Artikel ini tidak akan membahas dasar-dasar hibernate (cara mendefinisikan entitas atau menulis kueri kriteria). Di sini saya akan mencoba untuk berbicara tentang hal-hal menarik yang sangat berguna dalam pekerjaan. Informasi tentang yang belum saya temui di satu tempat.

Saya akan melakukan reservasi segera. Semua hal berikut ini berlaku untuk Hibernate 5.2. Kesalahan juga dimungkinkan karena fakta bahwa saya salah memahami sesuatu. Jika Anda menemukan - tulis.
Masalah memetakan model objek menjadi relasional
Tapi mari kita mulai dengan dasar-dasar ORM. ORM - pemetaan objek-relasional - sehingga kami memiliki model relasional dan objek. Dan ketika menampilkan satu sama lain, ada masalah yang harus kita selesaikan sendiri. Mari kita pisahkan mereka.
Sebagai ilustrasi, mari kita ambil contoh berikut: kita memiliki entitas "Pengguna", yang bisa berupa Jedi atau pesawat serang. Jedi harus memiliki kekuatan, dan spesialisasi serangan pesawat. Di bawah ini adalah diagram kelas.
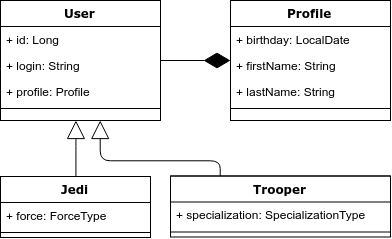
Masalah 1. Warisan dan pertanyaan polimorfik.
Ada pewarisan dalam model objek, tetapi tidak dalam model relasional. Karenanya, ini adalah masalah pertama - bagaimana memetakan warisan dengan benar ke model relasional.
Hibernate menawarkan 3 opsi untuk menampilkan model objek seperti itu:
- Semua ahli waris berada di tabel yang sama:
@Inheritance (strategi = InheritanceType.SINGLE_TABLE)

Dalam hal ini, bidang umum dan bidang ahli waris terletak di satu meja. Menggunakan strategi ini, kami menghindari bergabung ketika memilih entitas. Dari minus, perlu dicatat bahwa, pertama, kita tidak dapat mengatur batasan “NOT NULL” untuk kolom “force” dalam model relasional, dan kedua, kita kehilangan bentuk normal ketiga. (ketergantungan transitif dari atribut non-kunci muncul: force and disc).
Omong-omong, termasuk untuk alasan ini ada 2 cara untuk menentukan batasan bidang bukan nol - NotNull bertanggung jawab untuk validasi; @ Kolom (nullable = true) - bertanggung jawab atas kendala bukan nol dalam database.
Menurut pendapat saya, ini adalah cara terbaik untuk memetakan model objek ke model relasional.
- Bidang khusus entitas berada di tabel terpisah.
@Inheritance (strategi = InheritanceType.JOINED)
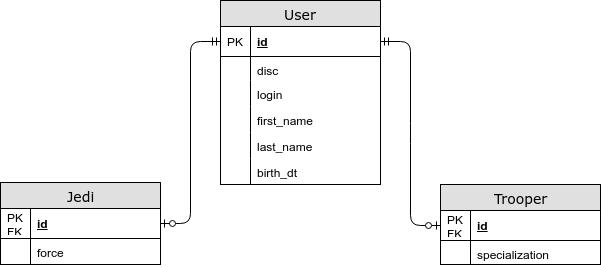
Dalam kasus ini, bidang umum disimpan dalam tabel bersama, dan khusus untuk entitas anak disimpan dalam yang terpisah. Dengan menggunakan strategi ini, kami mendapatkan GABUNGAN saat memilih entitas, tetapi sekarang kami menyimpan bentuk normal ketiga, dan kami juga dapat menentukan batasan NOT NULL dalam database. - Setiap entitas memiliki tabel sendiri.
@ InheritanceType.TABLE_PER_CLASS
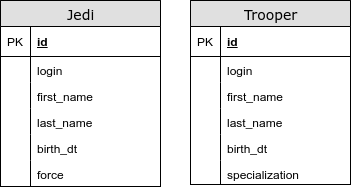
Dalam hal ini, kami tidak memiliki tabel bersama. Menggunakan strategi ini, kami menggunakan UNION untuk kueri polimorfik. Kami mengalami masalah dengan generator kunci utama dan kendala integritas lainnya. Jenis pemetaan warisan sangat tidak dianjurkan.
Untuk jaga-jaga, saya akan menyebutkan anotasi - @MappedSuperclass. Ini digunakan ketika Anda ingin "menyembunyikan" bidang umum untuk beberapa entitas model objek. Selain itu, kelas yang dijelaskan itu sendiri tidak dianggap sebagai entitas yang terpisah.
Masalah 2. Rasio komposisi dalam OOP
Kembali ke contoh kita, kita perhatikan bahwa dalam model objek kita mengambil profil pengguna ke entitas yang terpisah - Profil. Tetapi dalam model relasional, kami tidak memilih tabel terpisah untuk itu.
Sikap OneToOne sering merupakan praktik buruk karena di pilih, kami memiliki GABUNGAN yang tidak dibenarkan (bahkan menentukan fetchType = LAZY dalam kebanyakan kasus kami akan GABUNG - kami akan membahas masalah ini nanti).
Ada penjelasan @Embedable dan @Embeded untuk menampilkan komposisi dalam tabel bersama. Yang pertama ditempatkan di atas bidang, dan yang kedua di atas kelas. Mereka dipertukarkan.
Manajer Entitas
Setiap instance dari EntityManager (EM) mendefinisikan sesi interaksi dengan database. Dalam instance EM, ada cache level pertama. Di sini saya akan menyoroti poin-poin penting berikut:
- Menangkap koneksi basis data
Ini hanya poin yang menarik. Hibernate tidak menangkap Connection pada saat menerima EM, tetapi pada akses pertama ke database atau membuka transaksi (meskipun masalah ini dapat diselesaikan ). Ini dilakukan untuk mengurangi waktu koneksi yang sibuk. Selama menerima EM-a, keberadaan transaksi JTA diperiksa. - Entitas gigih selalu memiliki id
- Entitas yang menjelaskan satu baris dalam database setara dengan referensi
Seperti disebutkan di atas, EM memiliki cache tingkat pertama, objek di dalamnya dibandingkan dengan referensi. Oleh karena itu, muncul pertanyaan - bidang mana yang harus digunakan untuk mengganti persamaan dan kode hash? Pertimbangkan opsi berikut:
- Cara kerja flush
Flush - mengeksekusi akumulasi insert, update, dan delete pada database. Secara default, flush dijalankan dalam kasus:
- Sebelum menjalankan kueri (dengan pengecualian em.get), ini perlu untuk mematuhi prinsip ACID. Misalnya: kami mengubah tanggal lahir pesawat serang, dan kemudian kami ingin mendapatkan jumlah pesawat serang orang dewasa.
Jika kita berbicara tentang CriteriaQuery atau JPQL, maka flush akan dieksekusi jika kueri memengaruhi tabel yang entitasnya ada dalam cache dari level pertama. - Saat melakukan transaksi;
- Kadang-kadang ketika mempertahankan entitas baru - dalam kasus ketika kita bisa mendapatkan id hanya melalui sisipan.
Dan sekarang tes kecil. Berapa banyak operasi UPDATE yang akan dilakukan dalam kasus ini?
val spaceCraft = em.find(SpaceCraft.class, 1L); spaceCraft.setCoords(...); spaceCraft.setCompanion( findNearestSpaceCraft(spacecraft) );
Fitur hibernasi yang menarik disembunyikan di bawah operasi flush - ia berusaha mengurangi waktu yang diperlukan untuk mengunci baris dalam database.
Perhatikan juga bahwa ada beberapa strategi berbeda untuk operasi flush. Misalnya, Anda dapat melarang "penggabungan" perubahan ke database - ini disebut MANUAL (ini juga menonaktifkan mekanisme pemeriksaan kotor).
- Pemeriksaan kotor
Pengecekan Kotor adalah mekanisme yang dilakukan selama operasi flush. Tujuannya adalah untuk menemukan entitas yang telah berubah dan memperbaruinya. Untuk menerapkan mekanisme seperti itu, hibernate harus menyimpan salinan asli objek (dengan objek apa yang sebenarnya akan dibandingkan). Untuk lebih tepatnya, hibernate menyimpan salinan bidang objek, bukan objek itu sendiri.
Perlu dicatat bahwa jika grafik entitas besar, maka operasi pemeriksaan kotor bisa mahal. Jangan lupa bahwa hibernate menyimpan 2 salinan entitas (secara kasar).
Untuk "mengurangi biaya" dari proses ini, gunakan fitur berikut:
- em.detach / em.clear - lepaskan entitas dari EntityManager
- FlushMode = MANUAL - berguna dalam operasi baca
- Abadi - juga menghindari operasi pengecekan kotor
- Transaksi
Seperti yang Anda ketahui, hibernasi memungkinkan Anda memperbarui entitas hanya dalam transaksi. Operasi baca menawarkan lebih banyak kebebasan - kita dapat menjalankannya tanpa secara eksplisit membuka transaksi. Tetapi justru ini pertanyaannya: apakah layak untuk membuka transaksi secara eksplisit untuk operasi baca?
Saya akan mengutip beberapa fakta:
- Pernyataan apa pun dijalankan di basis data di dalam transaksi. Bahkan jika kita jelas tidak membukanya. (mode komit otomatis).
- Sebagai aturan, kami tidak terbatas pada satu permintaan ke database. Misalnya: untuk mendapatkan 10 catatan pertama, Anda mungkin ingin mengembalikan jumlah total catatan. Dan ini hampir selalu 2 permintaan.
- Jika kita berbicara tentang data pegas, maka metode repositori adalah transaksional secara default , sedangkan metode baca hanya baca.
- Anotasi pegas @Transaksional (readOnly = true) juga memengaruhi FlushMode, lebih tepatnya, Pegas meletakkannya dalam status MANUAL, sehingga hibernate tidak akan melakukan pemeriksaan kotor.
- Pengujian sintetis dengan satu atau dua permintaan basis data akan menunjukkan bahwa komit otomatis lebih cepat. Tetapi dalam mode tempur, ini mungkin tidak begitu. ( artikel bagus tentang hal ini , + lihat komentar)
Singkatnya: adalah praktik yang baik untuk melakukan komunikasi apa pun dengan database dalam suatu transaksi.
Generator
Generator diperlukan untuk menggambarkan bagaimana kunci utama entitas kita akan menerima nilai. Mari kita cepat membahas opsi:
- GenerationType.AUTO - pemilihan generator didasarkan pada dialek. Bukan pilihan terbaik, karena aturan "eksplisit lebih baik daripada implisit" hanya berlaku di sini.
- GenerationType.IDENTITY adalah cara termudah untuk mengonfigurasi generator. Itu bergantung pada kolom kenaikan otomatis di tabel. Karena itu, untuk mendapatkan id dengan persisten kita perlu melakukan insert. Itulah sebabnya mengapa menghilangkan kemungkinan ditangguhkan bertahan dan karena itu batching.
- GenerationType.SEQUENCE adalah kasus paling nyaman ketika kita mendapatkan id dari urutan.
- GenerationType.TABLE - dalam hal ini hibernate mengemulasi urutan melalui tabel tambahan. Bukan pilihan terbaik, karena dalam solusi semacam itu, hibernate harus menggunakan transaksi terpisah dan mengunci per baris.
Mari kita bicara sedikit lebih banyak tentang urutan. Untuk meningkatkan kecepatan operasi, hibernate menggunakan algoritma optimasi yang berbeda. Semuanya ditujukan untuk mengurangi jumlah percakapan dengan database (jumlah perjalanan pulang pergi). Mari kita lihat lebih detail:
- tidak ada - tidak ada optimasi. untuk setiap id kita tarik urutan.
- pooled dan pooled-lo - dalam hal ini, sekuens kami harus meningkat dengan interval tertentu - N dalam database (SequenceGenerator.allocationSize). Dan dalam aplikasi, kami memiliki kumpulan tertentu, nilai-nilai dari mana kami dapat menetapkan untuk entitas baru tanpa mengakses database ..
- hilo - untuk menghasilkan ID, algoritma hilo menggunakan 2 angka: hi (disimpan dalam database - nilai yang diperoleh dari panggilan urutan) dan lo (disimpan hanya dalam aplikasi - SequenceGenerator.allocationSize). Berdasarkan angka-angka ini, interval untuk menghasilkan id dihitung sebagai berikut: [(hi - 1) * lo + 1, hi * lo + 1). Untuk alasan yang jelas, algoritma ini dianggap ketinggalan jaman dan tidak disarankan untuk menggunakannya.
Sekarang mari kita lihat bagaimana pengoptimal dipilih. Hibernate memiliki beberapa generator urutan. Kami akan tertarik pada 2 dari mereka:
- SequenceHiLoGenerator adalah generator lama yang menggunakan pengoptimal hilo. Dipilih secara default jika kita memiliki hibernate.id.new_generator_mappings == properti palsu.
- SequenceStyleGenerator - digunakan secara default (jika hibernate.id.new_generator_mappings == true property). Generator ini mendukung beberapa pengoptimal, tetapi standarnya dikumpulkan.
Anda juga dapat mengkonfigurasi anotasi generator @GenericGenerator.
Jalan buntu
Mari kita lihat contoh situasi kode semu yang dapat menyebabkan kebuntuan:
Thread #1: update entity(id = 3) update entity(id = 2) update entity(id = 1) Thread #2: update entity(id = 1) update entity(id = 2) update entity(id = 3)
Untuk mencegah masalah seperti itu, hibernate memiliki mekanisme yang menghindari kebuntuan jenis ini - parameter hibernate.order_updates. Dalam hal ini, semua pembaruan akan dipesan oleh id dan dieksekusi. Saya juga akan menyebutkan sekali lagi bahwa hibernate sedang mencoba untuk "menunda" penangkapan koneksi dan eksekusi insert dan pembaruan.
Set, Tas, Daftar
Hibernate memiliki 3 cara utama untuk menyajikan koleksi komunikasi OneToMany.
- Set - set entitas yang tidak terurut tanpa pengulangan;
- Bag - seperangkat entitas yang tidak teratur;
- Daftar adalah seperangkat entitas yang dipesan.
Tidak ada kelas untuk Bag di inti java yang akan menggambarkan struktur seperti itu. Karena itu, semua Daftar dan Koleksi adalah tas kecuali Anda menentukan kolom di mana koleksi kami akan diurutkan (anotasi OrderColumn. Jangan bingung dengan SortBy). Saya sangat merekomendasikan untuk tidak menggunakan anotasi OrderColumn karena implementasi fitur yang buruk (menurut saya) - tidak kueri sql yang optimal, kemungkinan NULL dalam lembar.
Muncul pertanyaan, tetapi apa yang lebih baik menggunakan tas atau set? Untuk mulai dengan, saat menggunakan tas, masalah berikut mungkin terjadi:
- Jika versi hibernate Anda lebih rendah dari 5.0.8, maka ada bug yang agak serius - HHH-5855 - saat memasukkan entitas anak, duplikasinya dimungkinkan (dalam kasus cascadType = MERGE dan PERSIST);
- Jika Anda menggunakan tas untuk hubungan ManyToMany, maka hibernate menghasilkan kueri yang sangat tidak pantas saat menghapus entitas dari koleksi - pertama-tama menghapus semua baris dari tabel bergabung, dan kemudian melakukan memasukkan;
- Hibernate tidak dapat mengambil beberapa tas untuk entitas yang sama secara bersamaan.
Jika Anda ingin menambahkan entitas lain ke koneksi @OneToMany, akan lebih menguntungkan jika menggunakan Bag, karena tidak memerlukan pemuatan semua entitas terkait untuk operasi ini. Mari kita lihat sebuah contoh:
Referensi Kekuatan
Referensi adalah referensi ke objek, yang kami putuskan untuk menunda pemuatan. Dalam kasus hubungan ManyToOne dengan fetchType = LAZY, kami mendapatkan referensi seperti itu. Inisialisasi objek terjadi pada saat mengakses bidang entitas, dengan pengecualian id (karena kita tahu nilai bidang ini).
Perlu dicatat bahwa dalam kasus Lazy Loading, referensi selalu merujuk ke baris yang ada dalam database. Untuk alasan ini, sebagian besar kasus Pemuatan Malas tidak berfungsi dalam hubungan OneToOne - hibernate perlu dibuat BERGABUNG untuk memeriksa apakah koneksi sudah ada dan sudah GABUNG, lalu hibernasi memuatnya ke dalam model objek. Jika kami mengindikasikan nullable = true di OneToOne, maka LazyLoad harus berfungsi.
Kita dapat membuat referensi kita sendiri menggunakan metode em.getReference. Benar, dalam hal ini tidak ada jaminan bahwa referensi merujuk ke baris yang ada dalam database.
Mari kita beri contoh menggunakan tautan seperti itu:
Untuk berjaga-jaga, saya mengingatkan Anda bahwa kami akan mendapatkan LazyInitializationException jika terjadi EM atau tautan terpisah.
Tanggal dan waktu
Terlepas dari kenyataan bahwa java 8 memiliki API yang sangat baik untuk bekerja dengan tanggal dan waktu, JDBC API masih memungkinkan Anda untuk bekerja hanya dengan API tanggal yang lama. Karena itu, kami akan menganalisis beberapa poin menarik.
Pertama, Anda perlu memahami dengan jelas perbedaan antara LocalDateTime dan Instan dan ZonedDateTime. (Saya tidak akan melakukan peregangan, tapi saya akan memberikan artikel bagus tentang topik ini: yang
pertama dan
kedua )
Jika singkatLocalDateTime dan LocalDate mewakili tuple angka reguler. Mereka tidak terikat pada waktu tertentu. Yaitu waktu pendaratan pesawat tidak dapat disimpan di LocalDateTime. Dan tanggal lahir melalui LocalDate cukup normal. Instan mewakili suatu titik waktu, relatif yang dengannya kita dapat memperoleh waktu setempat di titik mana pun di planet ini.
Poin yang lebih menarik dan penting adalah bagaimana tanggal disimpan dalam database. Jika kita memiliki TIMESTAMP DENGAN tipe TIMEZONE ditempelkan, maka seharusnya tidak ada masalah, tetapi jika TIMESTAMP (TANPA TIMEZONE) berdiri, maka ada kemungkinan bahwa tanggal akan ditulis / dibaca salah. (tidak termasuk LocalDate dan LocalDateTime)
Mari kita lihat mengapa:
Saat kami menyimpan tanggal, metode dengan tanda tangan berikut digunakan:
setTimestamp(int i, Timestamp t, java.util.Calendar cal)
Seperti yang Anda lihat, API lama digunakan di sini. Argumen Kalender opsional diperlukan untuk mengonversi cap waktu ke representasi string. Yaitu menyimpan zona waktu dengan sendirinya. Jika Kalender tidak dikirim, maka Kalender digunakan secara default dengan zona waktu JVM.
Ada 3 cara untuk mengatasi masalah ini:
- Tetapkan JVM zona waktu yang diinginkan
- Gunakan parameter hibernate - hibernate.jdbc.time_zone (ditambahkan pada 5.2) - hanya akan memperbaiki ZonedDateTime dan OffsetDateTime
- Gunakan jenis TIMESTAMP DENGAN TIMEZONE
Pertanyaan yang menarik, mengapa LocalDate dan LocalDateTime tidak termasuk dalam masalah seperti itu?
JawabannyaUntuk menjawab pertanyaan ini, Anda perlu memahami struktur kelas java.util.Date (java.sql.Date dan java.sql.Timestamp, ahli warisnya dan perbedaannya dalam hal ini tidak mengganggu kami). Date menyimpan tanggal dalam milidetik sejak 1970, secara kasar berbicara dalam UTC, tetapi metode toString mengubah tanggal menurut zona waktu sistem.
Dengan demikian, ketika kita mendapatkan tanggal tanpa zona waktu dari database, itu dipetakan ke objek Timestamp sehingga metode toString menampilkan nilai yang diinginkan. Pada saat yang sama, jumlah milidetik sejak tahun 1970 dapat berbeda (tergantung pada zona waktu). Itu sebabnya hanya waktu lokal yang selalu ditampilkan dengan benar.
Saya juga memberikan contoh kode yang bertanggung jawab untuk mengubah Timesamp ke LocalDateTime dan Instan:
Batching
Secara default, kueri dikirim ke database satu per satu. Ketika batching diaktifkan, hibernate akan dapat mengirim beberapa pernyataan dalam satu permintaan ke database. (mis. batching mengurangi jumlah perjalanan pulang-pergi ke basis data)
Untuk melakukan ini, Anda harus:
- Aktifkan batching dan atur jumlah pernyataan maksimum:
hibernate.jdbc.batch_size (disarankan 5 hingga 30) - Aktifkan penyortiran sisipan dan perbarui:
hibernate.order_inserts
hibernate.order_updates
- Jika kita menggunakan versi, maka kita juga harus mengaktifkannya
hibernate.jdbc.batch_versioned_data - hati-hati di sini, Anda memerlukan driver jdbc untuk dapat memberikan jumlah baris yang terpengaruh selama pembaruan.
Saya juga akan mengingatkan Anda tentang efektivitas operasi em.clear () - ini melepaskan ikatan entitas dari mereka, sehingga membebaskan memori dan mengurangi waktu operasi pengecekan kotor.
Jika kita menggunakan postgres, maka kita juga bisa mengatakan hibernate untuk menggunakan
insert multi-mentah .
Masalah N +1
Ini adalah topik yang cukup umum, jadi cepatlah membahasnya.
Masalah N +1 adalah situasi di mana, alih-alih satu permintaan untuk memilih buku N, setidaknya terjadi permintaan N +1.
Cara termudah untuk menyelesaikan masalah N +1 adalah dengan mengambil tabel terkait. Dalam hal ini, kami mungkin mengalami beberapa masalah lain:
- Pagination. dalam kasus hubungan OneToMany, hibernasi tidak akan dapat menentukan offset dan batas. Oleh karena itu, pagination akan muncul di memori.
- Masalah produk Cartesian adalah situasi ketika database mengembalikan baris N * M * K untuk memilih buku N dengan bab M dan penulis K.
Ada cara lain untuk menyelesaikan masalah N +1.
- FetchMode - memungkinkan Anda untuk mengubah algoritma pemuatan entitas anak. Dalam kasus kami, kami tertarik pada yang berikut:
- FetchType.SUBSELECT - Memuat catatan anak dalam permintaan terpisah. Kelemahannya adalah bahwa semua kompleksitas permintaan utama diulangi dalam subselect.
- BATCH (FetchType.SELECT + anotasi BatchSize) - juga memuat catatan sebagai permintaan terpisah, tetapi bersama dengan subquery membuat kondisi seperti WHERE parent_id IN (?,?,?, ..., N)
Perlu dicatat bahwa saat menggunakan fetch di API Kriteria, FetchType diabaikan - GABUNG selalu digunakan - JPA EntityGraph dan Hibernate FetchProfile - memungkinkan Anda untuk membuat aturan pemuatan entitas menjadi abstraksi terpisah - menurut pendapat saya kedua implementasi tidak nyaman.
Pengujian
Idealnya, lingkungan pengembangan harus memberikan informasi yang berguna sebanyak mungkin tentang operasi hibernate dan tentang interaksi dengan database. Yaitu:
- Penebangan
- org.hibernate.SQL: debug
- org.hibernate.type.descriptor.sql: trace
- Statistik
- hibernate.generate_statistics
Dari utilitas yang bermanfaat, berikut ini dapat dibedakan:
- DBUnit - memungkinkan Anda untuk menggambarkan keadaan basis data dalam format XML. Terkadang itu nyaman. Tetapi lebih baik pikirkan lagi apakah Anda membutuhkannya.
- DataSource-proxy
- p6spy adalah salah satu solusi tertua. menawarkan logging, runtime, dll. permintaan
- com.vladmihalcea: db-util: 0.0.1 adalah utilitas praktis untuk menemukan masalah N +1. Ini juga memungkinkan Anda untuk mencatat kueri. Komposisi tersebut mencakup anotasi Coba Lagi yang menarik, yang mencoba kembali transaksi dalam kasus OptimisticLockException.
- Sniffy - memungkinkan Anda untuk menegaskan jumlah permintaan melalui anotasi. Dalam beberapa hal, lebih elegan daripada keputusan dari Vlad.
Tetapi sekali lagi saya ulangi bahwa ini hanya untuk pengembangan, ini tidak boleh dimasukkan dalam produksi.
Sastra