Halo rekan! Kami mengingatkan Anda bahwa belum lama ini kami menerbitkan
buku tentang Spark , dan saat ini sebuah
buku tentang Kafka sedang menjalani proofreading terbaru.
Kami berharap buku-buku ini akan cukup berhasil untuk melanjutkan topik - misalnya, untuk terjemahan dan publikasi literatur tentang Spark Streaming. Kami ingin menawarkan kepada Anda terjemahan tentang pengintegrasian teknologi ini dengan Kafka hari ini.
1. PembenaranApache Kafka + Spark Streaming adalah salah satu kombinasi terbaik untuk membuat aplikasi waktu nyata. Dalam artikel ini, kita akan membahas secara detail perincian integrasi tersebut. Selain itu, kita akan melihat contoh dengan Spark Streaming-Kafka. Kemudian kami membahas "pendekatan penerima" dan opsi integrasi langsung Kafka dan Spark Streaming. Jadi, mari kita mulai mengintegrasikan Kafka dan Spark Streaming.
 2. Integrasi Kafka dan Spark Streaming
2. Integrasi Kafka dan Spark StreamingSaat mengintegrasikan Apache Kafka dan Spark Streaming, ada dua pendekatan yang memungkinkan untuk mengonfigurasi Spark Streaming untuk menerima data dari Kafka - yaitu.e. dua pendekatan untuk mengintegrasikan Kafka dan Spark Streaming. Pertama, Anda dapat menggunakan Penerima dan API Kafka tingkat tinggi. Pendekatan kedua (yang lebih baru) bekerja tanpa Penerima. Ada model pemrograman yang berbeda untuk kedua pendekatan, berbeda, misalnya, dalam hal kinerja dan jaminan semantik.
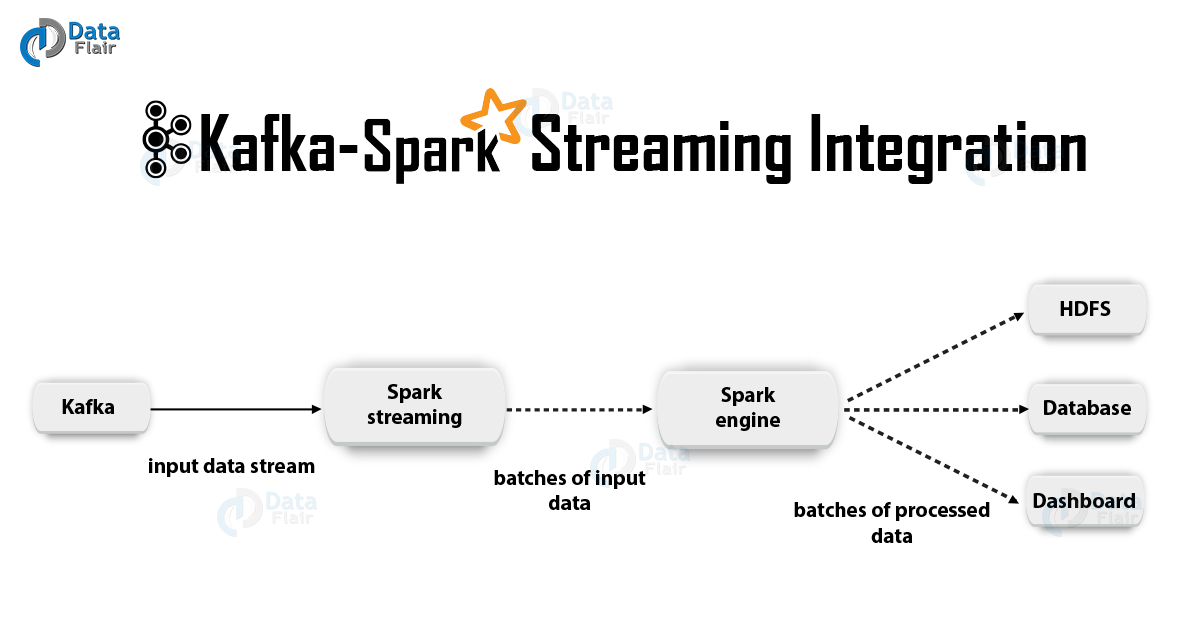
Mari kita pertimbangkan pendekatan ini secara lebih rinci.
a. Pendekatan Berbasis PenerimaDalam hal ini, penerimaan data disediakan oleh Penerima. Jadi, menggunakan API konsumsi tingkat tinggi yang disediakan oleh Kafka, kami menerapkan Penerima. Selanjutnya, data yang diterima disimpan di Spark Artists. Kemudian, pekerjaan diluncurkan di Kafka - Spark Streaming, di mana data diproses.
Namun, ketika menggunakan pendekatan ini, risiko kehilangan data jika terjadi kegagalan (dengan konfigurasi default) tetap ada. Oleh karena itu, perlu untuk memasukkan log write-ahead di Kafka - Spark Streaming untuk mencegah kehilangan data. Dengan demikian, semua data yang diterima dari Kafka disimpan secara sinkron dalam log tulis di sistem file terdistribusi. Itu sebabnya, bahkan setelah kegagalan sistem, semua data dapat dipulihkan.
Selanjutnya, kita akan melihat bagaimana menggunakan pendekatan ini dengan penerima dalam aplikasi dengan Kafka - Spark Streaming.
saya MengikatSekarang kita akan menghubungkan aplikasi streaming kita dengan artefak berikut untuk aplikasi Scala / Java, kita akan menggunakan definisi proyek untuk SBT / Maven.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
Namun, ketika menggunakan aplikasi kita, kita harus menambahkan pustaka yang disebutkan di atas dan dependensinya, ini akan diperlukan untuk aplikasi Python.
ii. PemrogramanSelanjutnya, buat stream input
DStream dengan mengimpor
KafkaUtils ke dalam kode aplikasi stream:
import org.apache.spark.streaming.kafka._ val kafkaStream = KafkaUtils.createStream(streamingContext, [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
Selain itu, dengan menggunakan opsi createStream, Anda dapat menentukan kelas kunci dan kelas nilai, serta kelas yang sesuai untuk penguraiannya.
iii. PenempatanSeperti halnya aplikasi Spark, perintah spark-submit digunakan untuk meluncurkan. Namun, detailnya sedikit berbeda dalam aplikasi Scala / Java dan dalam aplikasi Python.
Selain itu, dengan
–packages Anda dapat menambahkan
spark-streaming-Kafka-0-8_2.11 dan dependensinya secara langsung ke
spark-submit , ini berguna untuk aplikasi Python di mana tidak mungkin untuk mengelola proyek menggunakan SBT / Maven.
./bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 ...
Anda juga dapat mengunduh arsip JAR artifact
spark-streaming-Kafka-0-8-assembly dari repositori Maven. Kemudian tambahkan ke
spark-submit dengan -
jars .
b. Pendekatan langsung (tidak ada penerima)Setelah pendekatan menggunakan penerima, pendekatan yang lebih baru dikembangkan - yang "langsung". Ini memberikan jaminan end-to-end yang andal. Dalam hal ini, kami secara berkala bertanya kepada Kafka tentang offset offset untuk setiap topik / bagian, dan tidak mengatur pengiriman data melalui penerima. Selain itu, ukuran fragmen baca ditentukan, ini diperlukan untuk pemrosesan yang benar dari setiap paket. Akhirnya, API konsumsi sederhana digunakan untuk membaca rentang dengan data dari Kafka dengan offset yang diberikan, terutama ketika pekerjaan pemrosesan data dimulai. Seluruh proses seperti membaca file dari sistem file.
Catatan: Fitur ini muncul di Spark 1.3 untuk Scala dan Java API, serta di Spark 1.4 untuk Python API.
Sekarang mari kita bahas bagaimana menerapkan pendekatan ini dalam aplikasi streaming kami.
API Konsumen dijelaskan secara lebih rinci di tautan berikut:
Konsumen Apache Kafka | Contoh Konsumen Kafkasaya Mengikat
Benar, pendekatan ini hanya didukung di aplikasi Scala / Java. Dengan artefak berikut, bangun proyek SBT / Maven.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
ii. PemrogramanSelanjutnya, impor KafkaUtils dan buat input
DStream dalam kode aplikasi streaming:
import org.apache.spark.streaming.kafka._ val directKafkaStream = KafkaUtils.createDirectStream[ [key class], [value class], [key decoder class], [value decoder class] ]( streamingContext, [map of Kafka parameters], [set of topics to consume])
Dalam parameter Kafka, Anda harus menentukan
metadata.broker.list atau
bootstrap.servers . Karenanya, secara default, kami akan menggunakan data mulai dari offset terakhir di setiap bagian Kafka. Namun, jika Anda ingin pembacaan dimulai dari fragmen terkecil, maka dalam parameter Kafka Anda perlu mengatur opsi konfigurasi
auto.offset.reset .
Selain itu, bekerja dengan opsi
KafkaUtils.createDirectStream , Anda dapat mulai membaca dari offset acak. Kemudian kita akan melakukan hal berikut, yang akan memungkinkan kita untuk mengakses fragmen Kafka yang dikonsumsi dalam setiap paket.
Jika kami ingin mengatur pemantauan Kafka berdasarkan Zookeeper menggunakan alat khusus, kami dapat memperbarui Zookeeper sendiri dengan bantuan mereka.
iii. PenempatanProses penyebaran dalam hal ini menyerupai proses penyebaran dalam varian dengan penerima.
3. Manfaat dari pendekatan langsungPendekatan kedua untuk mengintegrasikan Spark Streaming dengan Kafka mengungguli yang pertama karena alasan berikut:
a. Concurrency SederhanaDalam hal ini, Anda tidak perlu membuat banyak aliran input Kafka dan menggabungkannya. Namun, Kafka - Spark Streaming akan membuat segmen RDD sebanyak mungkin karena akan ada segmen Kafka untuk konsumsi. Semua data Kafka ini akan dibaca secara paralel. Oleh karena itu, kita dapat mengatakan bahwa kita akan memiliki korespondensi satu-ke-satu antara segmen Kafka dan RDD, dan model seperti itu lebih mudah dimengerti dan lebih mudah untuk dikonfigurasi.
b. KeefektifanUntuk benar-benar menghilangkan kehilangan data selama pendekatan pertama, informasi perlu disimpan dalam log catatan terkemuka, dan kemudian direplikasi. Sebenarnya, ini tidak efisien karena data direplikasi dua kali: pertama kali oleh Kafka itu sendiri, dan yang kedua oleh log menulis depan. Dalam pendekatan kedua, masalah ini dihilangkan, karena tidak ada penerima, dan, oleh karena itu, tidak diperlukan jurnal tulis terkemuka. Jika kami memiliki penyimpanan data yang cukup panjang di Kafka, Anda dapat memulihkan pesan langsung dari Kafka.
s Semantik yang Tepat SekaliPada dasarnya, kami menggunakan API Kafka tingkat tinggi dalam pendekatan pertama untuk menyimpan fragmen baca yang dikonsumsi di Zookeeper. Namun, ini adalah kebiasaan untuk mengkonsumsi data dari Kafka. Sementara kehilangan data dapat dihilangkan secara andal, ada kemungkinan kecil bahwa dalam beberapa kegagalan, catatan individual dapat dikonsumsi dua kali. Intinya adalah inkonsistensi antara mekanisme transfer data yang dapat diandalkan di Kafka - Spark Streaming dan pembacaan fragmen yang terjadi di Zookeeper. Oleh karena itu, dalam pendekatan kedua, kami menggunakan API Kafka sederhana, yang tidak mengharuskan beralih ke Zookeeper. Di sini, fragmen baca dilacak dalam Kafka - Spark Streaming, untuk ini, titik kontrol digunakan. Dalam hal ini, ketidakkonsistenan antara Spark Streaming dan Zookeeper / Kafka dihilangkan.
Oleh karena itu, bahkan jika terjadi kegagalan, Spark Streaming menerima setiap catatan secara ketat satu kali. Di sini kita perlu memastikan bahwa operasi keluaran kami, di mana data disimpan dalam penyimpanan eksternal, adalah idempoten atau transaksi atom di mana hasil dan offset disimpan. Ini adalah bagaimana semantik-sekali dicapai dalam derivasi hasil kami.
Meskipun, ada satu kelemahan: offset di Zookeeper tidak diperbarui. Karenanya, alat pemantauan Kafka yang berbasis pada Zookeeper tidak memungkinkan Anda melacak kemajuan.
Namun, kita masih bisa merujuk ke offset, jika pemrosesan diatur dengan cara ini - kita beralih ke setiap paket dan memperbarui Zookeeper sendiri.
Itulah yang ingin kami bicarakan tentang mengintegrasikan Apache Kafka dan Spark Streaming. Kami harap Anda menikmatinya.