Ini adalah kuliah kedua dengan J. Subbotnik tentang database - yang
pertama kami terbitkan beberapa minggu yang lalu.
Kepala kelompok DBMS serba guna Dmitry Sarafannikov berbicara tentang evolusi gudang data di Yandex: bagaimana kami memutuskan untuk membuat antarmuka yang kompatibel dengan S3, mengapa kami memilih PostgreSQL, penggaruk seperti apa yang kami injak dan bagaimana menanganinya.
- Halo semuanya! Nama saya Dima, di Yandex saya melakukan database.
Saya akan memberi tahu Anda bagaimana kami melakukan S3, bagaimana kami melakukan persis S3, dan penyimpanan seperti apa sebelumnya. Yang pertama adalah Elliptics, diposting di open source, tersedia di GitHub. Banyak yang mungkin telah menemukannya.

Ini pada dasarnya adalah tabel hash terdistribusi dengan kunci 512-bit, hasil dari SHA-512. Ini membentuk gantungan kunci yang secara acak dibagi antara mesin. Jika Anda ingin menambahkan mesin di sana, tombolnya didistribusikan ulang, terjadi penyeimbangan ulang. Repositori ini memiliki masalah sendiri yang terkait, khususnya, dengan penyeimbangan kembali. Jika Anda memiliki jumlah kunci yang cukup besar, maka dengan volume yang terus tumbuh Anda perlu terus-menerus membuang mobil di sana, dan pada sejumlah besar kunci penyeimbangan mungkin tidak akan bertemu. Ini masalah yang cukup besar.
Tetapi pada saat yang sama, penyimpanan ini bagus untuk data statis yang kurang lebih, ketika Anda mengunggah sejumlah besar satu kali, dan kemudian menggerakkan beban baca-saja di atasnya. Untuk keputusan seperti itu, sangat cocok.
Kita melangkah lebih jauh. Masalah dengan penyeimbangan kembali cukup serius, sehingga penyimpanan berikutnya muncul.

Apa esensinya? Ini bukan penyimpanan nilai-kunci, ini adalah penyimpanan nilai. Saat Anda mengunggah beberapa objek atau file di sana, ia menjawab Anda dengan kunci, yang dengannya Anda dapat mengambil file ini. Apa yang diberikannya? Secara teoritis, akses tulis seratus persen, jika Anda memiliki ruang kosong dalam penyimpanan. Jika Anda memiliki satu mesin tik, Anda cukup menulis ke orang lain yang tidak berbohong di mana ada ruang kosong, Anda mendapatkan kunci lain dan dengan tenang mengambil data Anda.
Penyimpanan ini sangat mudah diukur, Anda dapat membuangnya dengan besi, ini akan berhasil. Ini sangat sederhana, dapat diandalkan. Satu-satunya kelemahan: klien tidak mengelola kunci, dan semua klien harus menyimpan kunci di suatu tempat, menyimpan pemetaan kunci mereka. Ini tidak nyaman untuk semua orang. Faktanya, ini adalah tugas yang sangat mirip untuk semua pelanggan, dan masing-masing memecahkannya dengan caranya sendiri dalam metabasisnya, dll. Ini tidak nyaman. Tetapi pada saat yang sama, saya tidak ingin kehilangan keandalan dan kesederhanaan penyimpanan ini, bahkan berfungsi dengan kecepatan jaringan.
Kemudian kami mulai melihat S3. Ini adalah penyimpanan bernilai-kunci, klien mengelola kunci, seluruh penyimpanan dibagi menjadi apa yang disebut ember. Di setiap bucket, ruang kuncinya adalah dari minus infinity hingga plus infinity. Kuncinya adalah semacam string teks. Dan kami sepakat, pada opsi ini. Mengapa S3?
Semuanya cukup sederhana. Pada saat ini, banyak klien siap pakai untuk berbagai bahasa pemrograman telah ditulis, banyak alat siap pakai untuk menyimpan sesuatu dalam S3, katakanlah, cadangan basis data, telah ditulis. Andrew
berbicara tentang salah satu contoh. Sudah ada API yang dipikirkan dengan matang yang telah berjalan di klien selama bertahun-tahun, dan Anda tidak perlu menemukan apa pun di sana. API memiliki banyak fitur yang mudah digunakan seperti daftar, unggahan banyak bagian, dan sebagainya. Karena itu, kami memutuskan untuk tetap menggunakannya.
Bagaimana cara membuat S3 dari penyimpanan kami? Apa yang terlintas dalam pikiran? Karena klien sendiri menyimpan pemetaan kunci, kami hanya mengambil, meletakkan basis data di sebelahnya, dan kami akan menyimpan pemetaan kunci-kunci ini di dalamnya. Saat membaca, kami hanya akan menemukan kunci dan penyimpanan di basis data kami, dan memberikan apa yang diinginkan klien. Jika Anda membuat sketsa ini secara skematis, bagaimana isinya terjadi?

Ada entitas tertentu, di sini disebut Proxy, yang disebut backend. Dia menerima file, mengunggahnya ke penyimpanan, mengambil kunci dari sana dan menyimpannya ke database. Semuanya cukup sederhana.
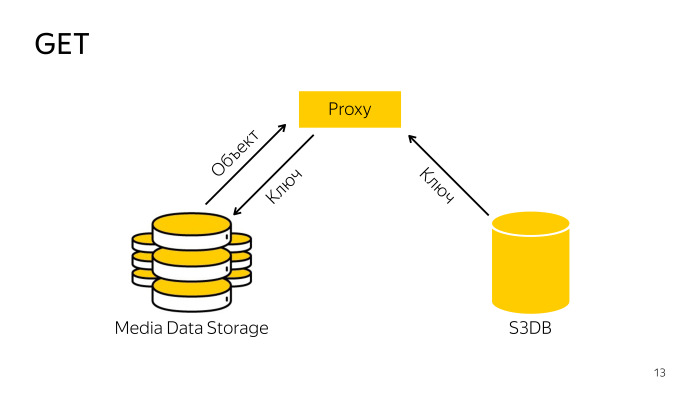
Bagaimana struknya? Proxy menemukan kunci yang diperlukan dalam database, pergi dengan kunci penyimpanan, mengunduh objek dari sana, memberikannya kepada klien. Semuanya juga sederhana.
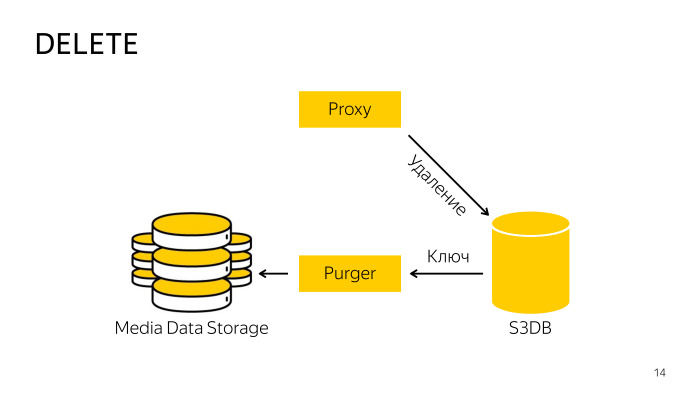
Bagaimana pemindahannya? Ketika menghapus langsung dari penyimpanan, proksi tidak berfungsi, karena sulit untuk mengoordinasikan database dan penyimpanan, sehingga hanya pergi ke database, mengatakan bahwa objek ini dihapus, di sana objek dipindahkan ke antrian penghapusan, dan kemudian di latar belakang seorang profesional terlatih khusus robot mengambil kunci ini, menghapusnya dari penyimpanan dan dari database. Semuanya di sini juga cukup sederhana.
Kami memilih PostgreSQL sebagai basis data untuk metabase ini.
Anda sudah tahu bahwa kami sangat mencintainya. Dengan transfer Yandex.Mail, kami memperoleh keahlian yang memadai dalam PostgreSQL, dan ketika berbagai layanan e-mail pindah, kami mengembangkan beberapa pola yang disebut pola sharding. Salah satunya jatuh pada S3 dengan sedikit modifikasi, tapi itu berjalan dengan baik di sana.
Apa sajakah pilihan sharding? Ini adalah repositori besar. Pada skala Yandex-lebar, Anda harus segera berpikir bahwa akan ada banyak objek, Anda harus segera berpikir tentang cara membuang semuanya. Anda dapat shard dengan hash atas nama objek, ini adalah cara yang paling dapat diandalkan, tetapi itu tidak akan bekerja di sini, karena S3 memiliki, misalnya, daftar yang harus menampilkan daftar kunci dalam urutan, ketika Anda cache, semua penyortiran akan hilang, Anda harus menghapus semua objek sehingga output sesuai dengan spesifikasi API.
Opsi selanjutnya, Anda dapat shard dengan hash atas nama atau id dari ember. Satu ember dapat hidup di dalam satu basis data.
Pilihan lain adalah untuk beling di rentang kunci. Di dalam ember, ada ruang dari minus tak terhingga ke plus tak terhingga, kita dapat membaginya menjadi sejumlah rentang, kami menyebutnya rentang sepotong, ia dapat hidup hanya dalam satu beling.

Kami memilih opsi ketiga, yang dihancurkan dengan potongan-potongan, karena murni secara teoritis akan ada jumlah objek yang tak terbatas dalam satu ember, dan itu bodohnya tidak akan masuk ke dalam sepotong besi. Akan ada masalah besar, jadi kami akan memotong dan mengatur pecahan sesuka kami. Itu saja.

Apa yang terjadi Seluruh database terdiri dari tiga komponen. S3 Proxy - sekelompok host, ada juga database. PL / Proxy berada di bawah balancer, permintaan dari backend fly di sana. Selanjutnya S3Meta, grup bass seperti itu, yang menyimpan informasi tentang bucket dan bongkahan. Dan S3DB, pecahan tempat benda disimpan, antrian penghapusan. Jika digambarkan secara skematis, sepertinya ini.
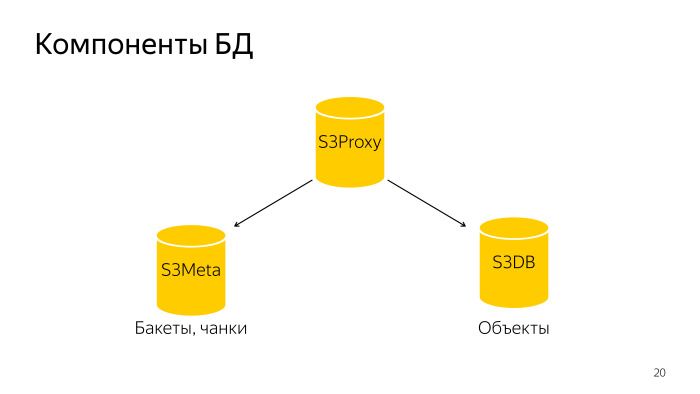
Permintaan datang ke S3Proxy, masuk ke S3Meta dan S3DB dan mengeluarkan informasi ke atas.

Mari kita pertimbangkan lebih detail. S3Proxy, fungsi di dalamnya dibuat dalam bahasa prosedural PLProxy, itu adalah bahasa yang memungkinkan Anda untuk menjalankan prosedur atau permintaan yang tersimpan dari jarak jauh. Ini adalah kode dari fungsi ObjectInfo terlihat, pada dasarnya, permintaan Dapatkan.
Cluster LProxy memiliki operator Cluster, dalam hal ini db_ro. Apa artinya ini?

Jika konfigurasi database khas beling, ada master dan dua replika. Master memasuki db_rw cluster, ketiga host masukkan db-ro, ini adalah di mana Anda dapat mengirim hanya membaca permintaan, dan permintaan menulis dikirim ke db_rw. Cluster db_rw mencakup semua master dari semua pecahan.
Pernyataan RUN ON berikutnya, dibutuhkan nilai semua, yang berarti mengeksekusi pada semua pecahan baik array atau semacam pecahan. Dalam hal ini, ia menerima hasil dari fungsi get_object_shard sebagai input, ini adalah jumlah beling di mana objek yang diberikan terletak.
Dan target - yang berfungsi untuk memanggil remote shard. Dia akan memanggil fungsi ini dan menggantikan argumen yang terbang ke fungsi ini.

Fungsi get_object_shard juga ditulis dalam PLProxy, sudah menjadi cluster meta_ro, permintaan akan terbang ke beling S3Meta, yang akan mengembalikan fungsi ini get_bucket_meta_shard.
S3Meta juga bisa di-shard, kami juga meletakkannya, sementara ini tidak relevan, tetapi ada peluang. Dan itu akan memanggil fungsi get_object_shard di S3Meta.

get_bucket_meta_shard hanyalah hash teks atas nama bucket, kami mengocok S3Meta hanya dengan hash atas nama bucket.

Pertimbangkan S3Meta apa yang terjadi di dalamnya. Informasi paling penting yaitu ada meja dengan potongan. Saya memotong beberapa informasi yang tidak perlu sedikit, yang paling penting kiri adalah bucket_id, tombol mulai, tombol putus dan beling di mana potongan ini terletak.

Seperti apa tampilan kueri pada tabel seperti itu, yang akan mengembalikan kepada kita bongkahan di mana, misalnya, objek uji terletak? Seperti ini Minus infinity dalam bentuk teks, kami menyajikannya sebagai nilai nol, ada titik-titik halus sehingga Anda perlu memeriksa start_key dan end_key adalah Null.

Permintaan tidak terlihat sangat baik, dan rencananya terlihat lebih buruk. Sebagai salah satu opsi untuk paket permintaan seperti itu, BitmapOr. Dan 6.000 tulang layak untuk rencana semacam itu.

Bagaimana bisa berbeda? Ada hal yang luar biasa di PostgreSQL sebagai indeks inti, yang dapat mengindeks tipe rentang, kisaran itu pada dasarnya adalah apa yang kita butuhkan. Kami membuat jenis ini, fungsi s3.to_keyrange kembali kepada kami, pada kenyataannya, kisaran. Kita dapat memeriksa dengan operator berisi, menemukan potongan di mana kunci kita. Dan untuk ini, mengecualikan batasan dibangun di sini, yang memastikan non-persimpangan bongkahan ini. Kita perlu mengizinkan, lebih disukai di tingkat basis data, beberapa kendala untuk memastikan bahwa potongan tidak dapat saling bersilangan, sehingga hanya satu baris yang dikembalikan sebagai tanggapan atas permintaan. Kalau tidak, itu tidak akan seperti yang kita inginkan. Ini adalah bagaimana rencana untuk permintaan seperti itu terlihat, index_scan biasa. Kondisi ini sepenuhnya cocok dengan kondisi indeks, dan rencana seperti itu hanya memiliki 700 tulang, 10 kali lebih sedikit.

Apa itu Pengecualian Pengecualian?

Mari kita buat tabel uji dengan dua kolom, dan tambahkan dua kendala untuk itu, satu unik yang semua orang tahu, dan satu mengecualikan kendala, yang memiliki parameter sama, operator tersebut. Mari kita atur dengan dua operator yang sama, plat seperti itu dibuat.

Kemudian kami mencoba menyisipkan dua baris yang identik, kami mendapatkan kesalahan pelanggaran keunikan kunci pada kendala pertama. Jika kami menjatuhkannya, maka kami telah melanggar batasan pengecualian. Ini adalah kasus umum dari kendala unik.

Faktanya, batasan unik sama dengan mengecualikan kendala dengan operator yang sama, tetapi dalam kasus pengecualian kendala, Anda dapat membuat beberapa kasus yang lebih umum.

Kami memiliki indeks seperti itu. Jika Anda melihat lebih dekat, Anda akan melihat bahwa keduanya adalah indeks inti, dan secara umum keduanya sama. Anda mungkin bertanya mengapa menduplikasi bisnis ini sama sekali. Aku akan memberitahumu.

Indeks adalah hal semacam itu, terutama indeks inti, sehingga tabel dapat hidup sendiri, pembaruan terjadi, dibagi, dan seterusnya, indeks memburuk di sana, tidak lagi optimal. Dan ada praktik seperti itu, khususnya ekstensi pg repack, indeks dibangun kembali secara berkala, sesekali mereka dibangun kembali.
Bagaimana cara membangun kembali indeks di bawah batasan unik? Buat buat indeks saat ini, buat indeks yang sama dengan tenang di sebelahnya tanpa mengunci, dan kemudian ekspresi ubah tabel dari constraint user_index adalah ini dan itu. Dan semuanya, semuanya jelas dan bagus di sini, itu berfungsi.
Dalam kasus pengecualian mengecualikan, Anda dapat membangunnya kembali hanya melalui penguncian ulang indeks, lebih tepatnya, indeks Anda akan diblokir secara eksklusif, dan pada kenyataannya Anda akan memiliki semua pertanyaan yang tersisa. Ini tidak dapat diterima, indeks inti dapat dibangun cukup lama. Oleh karena itu, kita tetap di sebelah indeks kedua, yang lebih kecil volumenya, membutuhkan lebih sedikit ruang, glider menggunakannya, dan kita dapat membangun kembali indeks itu secara kompetitif tanpa memblokir.
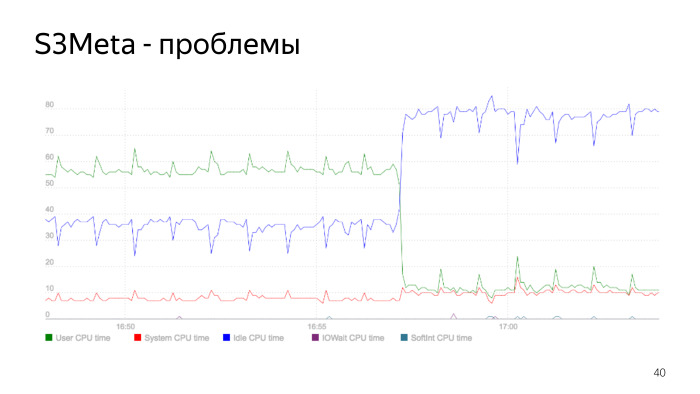
Berikut ini adalah grafik konsumsi prosesor. Garis hijau adalah konsumsi prosesor di user_space, itu melonjak dari 50% menjadi 60%. Pada titik ini, konsumsi turun tajam, ini adalah saat ketika indeks dibangun kembali. Kami membangun kembali indeks, menghapus yang lama, konsumsi prosesor kami turun tajam. Ini adalah masalah indeks inti, memang, dan ini adalah contoh yang baik tentang bagaimana hal ini bisa terjadi.
Ketika kami melakukan semua ini, kami mulai pada versi 9.5 S3DB, sesuai rencana, kami berencana untuk menumpuk 10 miliar objek di setiap pecahan. Seperti yang Anda ketahui, lebih dari 1 miliar dan bahkan masalah awal dimulai ketika sebuah tabel memiliki banyak baris, semuanya menjadi jauh lebih buruk. Ada praktik berpisah. Pada saat itu ada dua opsi, baik standar melalui pewarisan, tetapi ini tidak berfungsi dengan baik, karena ada kecepatan pemilihan partisi linier. Dan menilai dari jumlah objek, kita membutuhkan banyak partisi. Orang-orang dari Postgres Pro kemudian secara aktif menggergaji ekstensi pg_pathman.

Kami memilih pg_pathman, kami tidak punya pilihan lain. Bahkan versi 1.4. Dan seperti yang Anda lihat, kami menggunakan 256 partisi. Kami memecah seluruh tabel objek menjadi 256 partisi.
Apa yang dilakukan pg_pathman? Menggunakan ungkapan ini, Anda dapat membuat 256 partisi yang dipartisi oleh hash dari kolom tawaran.

Bagaimana cara kerja pg_pathman?
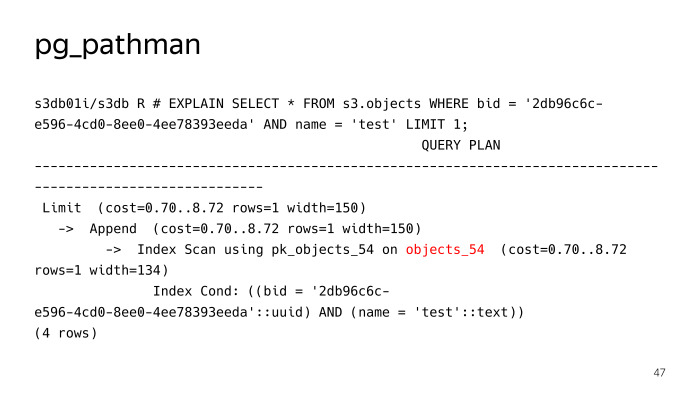
Ini mendaftarkan kaitnya di glider, dan selanjutnya pada permintaan itu menggantikan, pada dasarnya, rencana. Kita melihat bahwa dia tidak mencari 256 partisi untuk permintaan pencarian reguler untuk suatu objek dengan tes nama, tetapi segera menentukan bahwa perlu naik ke tabel objects_54, tetapi semuanya tidak berjalan dengan lancar di sini, pg_pathman memiliki masalah sendiri. Pertama, ada beberapa bug di awal, ketika dia menggergaji, tetapi berkat orang-orang dari Postgres Pro, mereka dengan cepat memperbaiki dan memperbaikinya.
Masalah pertama adalah sulitnya memperbaruinya. Masalah kedua adalah pernyataan yang disiapkan.
Mari kita pertimbangkan lebih detail. Secara khusus, pembaruan. Terdiri dari apa pg_pathman?

Ini pada dasarnya terdiri dari kode C, yang dikemas ke perpustakaan. Dan itu terdiri dari bagian SQL, segala macam fungsi untuk membuat partisi, dan sebagainya. Plus, antarmuka ke fungsi yang ada di perpustakaan. Kedua bagian ini tidak dapat diperbarui secara bersamaan.
Dari sini kesulitan muncul, sesuatu seperti algoritma ini untuk memperbarui versi pg_pathman, pertama-tama kita menggulung paket baru dengan versi baru, tetapi PostgreSQL memiliki versi lama yang dimuat dalam memori, ia menggunakannya. Ini segera dalam hal apapun, pangkalan harus dihidupkan ulang.
Selanjutnya, kita memanggil fungsi set_enable_parent, ini mengaktifkan fungsi di tabel induk, yang dimatikan secara default. Selanjutnya, matikan pathman, restart database, katakan ALTER EXTENSION UPDATE, saat ini semuanya jatuh ke tabel induk.
Selanjutnya, nyalakan pathman, dan jalankan fungsi, yang ada di ekstensi, yang mentransfer objek dari tabel induk yang menyerang mereka dalam periode waktu yang singkat ini, mentransfernya kembali ke tabel di mana mereka seharusnya berada. Dan kemudian matikan penggunaan tabel induk, cari di dalamnya.

Masalah selanjutnya adalah pernyataan yang disiapkan.

Jika kami memblokir permintaan biasa yang sama, cari berdasarkan tawaran dan kunci, coba jalankan. Lakukan lima kali - semuanya baik-baik saja. Kami melakukan yang keenam - kami melihat rencana seperti itu. Dan dalam hal ini kita melihat semua 256 partisi. Jika Anda perhatikan dengan cermat kondisi-kondisi ini, kita melihat dolar 1, dolar 2, inilah yang disebut rencana umum, rencana umum. Lima pertanyaan pertama dibangun secara individual, rencana individual digunakan untuk parameter ini, pg_pathman dapat segera menentukan, karena parameter diketahui sebelumnya, ia dapat langsung menentukan tabel ke mana harus pergi. Dalam hal ini, dia tidak bisa melakukan ini. Dengan demikian, rencana harus memiliki semua 256 partisi, dan ketika pelaksana melakukan ini, ia pergi dan mengambil kunci bersama untuk semua 256 partisi, dan kinerja solusi seperti itu tidak segera. Itu hanya kehilangan semua kelebihannya, dan permintaan apa pun dilakukan sangat lama.

Bagaimana kita bisa keluar dari situasi ini? Saya harus membungkus semuanya di dalam prosedur yang tersimpan dalam menjalankan, dalam SQL dinamis, sehingga pernyataan yang disiapkan tidak digunakan dan rencana itu dibangun setiap waktu. Begitulah cara kerjanya.
Kelemahannya adalah Anda harus menjejalkan semua kode ke dalam struktur yang menyentuh tabel ini. Ini sulit dibaca di sini.

Bagaimana distribusi benda? Di setiap beling S3DB, penghitung potongan disimpan, ada juga informasi tentang potongan mana yang ada di dalam beling ini, dan penghitung disimpan untuknya. Untuk setiap operasi yang bermutasi pada objek - menambah, menghapus, mengubah, menulis ulang - penghitung ini untuk perubahan chunk. Agar tidak memperbarui baris yang sama ketika menuangkan aktif dalam bongkahan ini, kami menggunakan teknik yang cukup standar ketika kami memasukkan penghitung delta ke dalam tabel yang terpisah, dan sekali satu menit robot khusus melewati dan mengumpulkan semua ini, memperbarui penghitung di bongkahan .

Selanjutnya, penghitung ini dikirim ke S3Meta dengan beberapa penundaan, sudah ada gambaran lengkap tentang berapa banyak penghitung di mana bongkahan, maka Anda dapat melihat distribusi dengan pecahan, berapa banyak objek dalam pecahan apa, dan berdasarkan ini, keputusan dibuat di mana bongkahan baru jatuh. Ketika Anda membuat sebuah ember, secara default, satu bongkahan dibuat dari minus tak terhingga ke plus tak terhingga, tergantung pada distribusi objek saat ini yang diketahui oleh S3Meta, itu jatuh ke dalam semacam beling.
Saat Anda menuangkan data ke dalam ember ini, semua data ini dituangkan ke dalam chunk ini, ketika ukuran tertentu tercapai, sebuah robot khusus datang dan berbagi chunk ini.

Kami membuat bongkahan ini kecil. Kami melakukan ini sehingga dalam hal ini bongkahan kecil ini dapat diseret ke pecahan lain. Bagaimana perpecahan potongan terjadi? Ini adalah robot biasa, ia pergi dan membagi potongan ini dalam S3DB dengan komit dua fase dan memperbarui informasi dalam S3Meta.
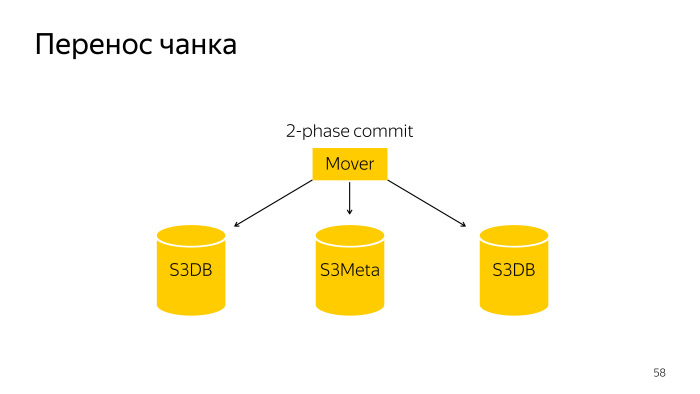
Chunk transfer adalah operasi yang sedikit lebih rumit, ini adalah komit dua fase atas tiga pangkalan, S3Meta dan dua pecahan, S3DB, diseret dari satu, ke yang lain.

S3 memiliki fitur seperti daftar, ini adalah hal yang paling sulit, dan ada masalah dengannya juga. Bahkan, daftar, Anda mengatakan S3 - tunjukkan benda yang saya miliki. Parameter yang disorot dalam warna merah sekarang Null. Parameter ini, delimeter, pemisah, Anda dapat menentukan daftar pemisah mana yang Anda inginkan.
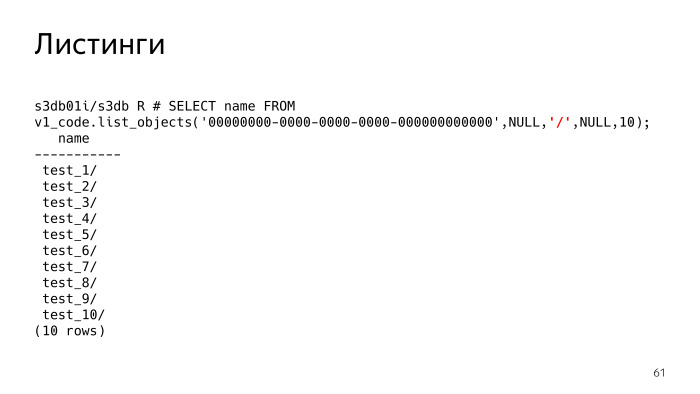
Apa artinya ini? Jika delimeter tidak disetel, kita melihat bahwa kita hanya diberi daftar file. Jika kita mengatur delimeter, pada intinya, S3 harus menunjukkan folder. Saya harus mengerti bahwa ada folder seperti itu, dan pada kenyataannya, itu menunjukkan semua folder dan file di folder saat ini. Folder saat ini diawali, parameter ini kosong. Kami melihat ada 10 folder.
Semua kunci tidak disimpan dalam semacam struktur hierarki pohon, seperti dalam sistem file. Setiap objek disimpan sebagai string, dan mereka memiliki awalan umum yang sederhana. S3 sendiri harus mengerti bahwa ini adalah keledai.

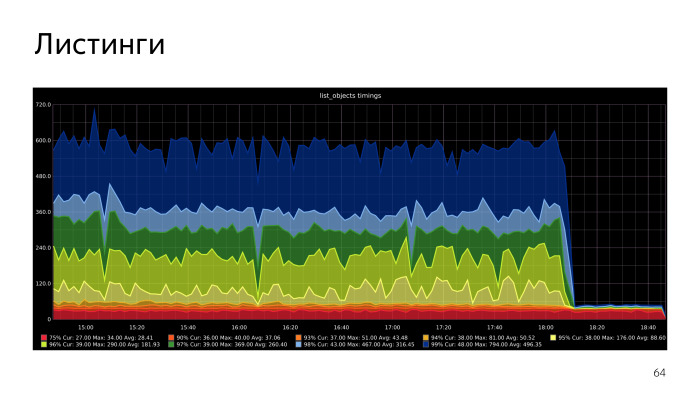
SQL, . , PL/pgSQL. , repeatable read. , . , - - , .
Recursive CTE, , - , execute PL/pgSQL. , . , , , list objects. , .
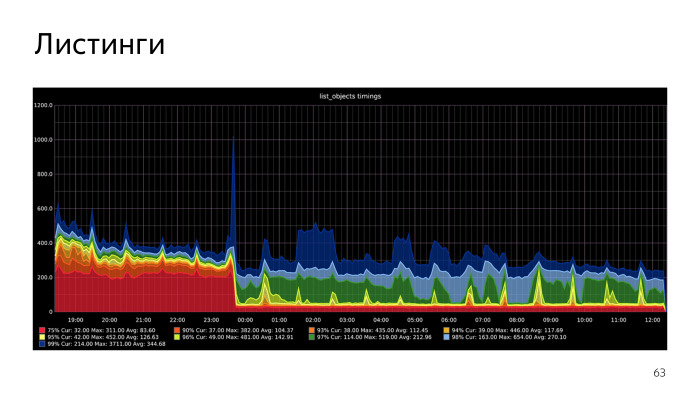
, .
. , .
Docker,
Behave Behave
. , , , .
. , , CPU S3Meta. Gist index CPU, , . CPU S3Meta . , . PLProxy , S3Meta S3DB. , . S3Meta . , .
, , . — , range btree. , btree . , , btree. , . PL/pgSQL-. , .