Ketika Dropbox baru saja dimulai, satu pengguna di Hacker News berkomentar bahwa itu dapat diimplementasikan dengan beberapa skrip bash menggunakan FTP dan Git. Sekarang ini tidak dapat dikatakan dengan cara apa pun, ini adalah penyimpanan file cloud besar dengan miliaran file baru setiap hari, yang tidak hanya disimpan entah bagaimana dalam database, tetapi sedemikian rupa sehingga setiap database dapat dipulihkan ke titik mana pun dalam enam hari terakhir.
Di bawah potongan, transkrip laporan
Glory Bakhmutov (
m0sth8 ) di Highload ++ 2017, tentang bagaimana basis data di Dropbox dikembangkan dan bagaimana mereka diatur sekarang.
Tentang pembicara: Glory to Bakhmutov - insinyur keandalan situs di tim Dropbox, sangat menyukai Go dan terkadang muncul di podcast golangshow.com.
Isi
Arsitektur Dropbox dalam bahasa sederhana
Dropbox muncul pada 2008. Ini pada dasarnya adalah penyimpanan file cloud. Ketika Dropbox baru saja dimulai, pengguna di Hacker News berkomentar bahwa itu dapat diimplementasikan dengan beberapa skrip bash menggunakan FTP dan Git. Namun, bagaimanapun, Dropbox sedang berkembang, dan sekarang ini adalah layanan yang cukup besar dengan lebih dari 1,5 miliar pengguna, 200 ribu bisnis, dan sejumlah besar (beberapa miliar!) File baru setiap hari.
Seperti apa bentuk Dropbox?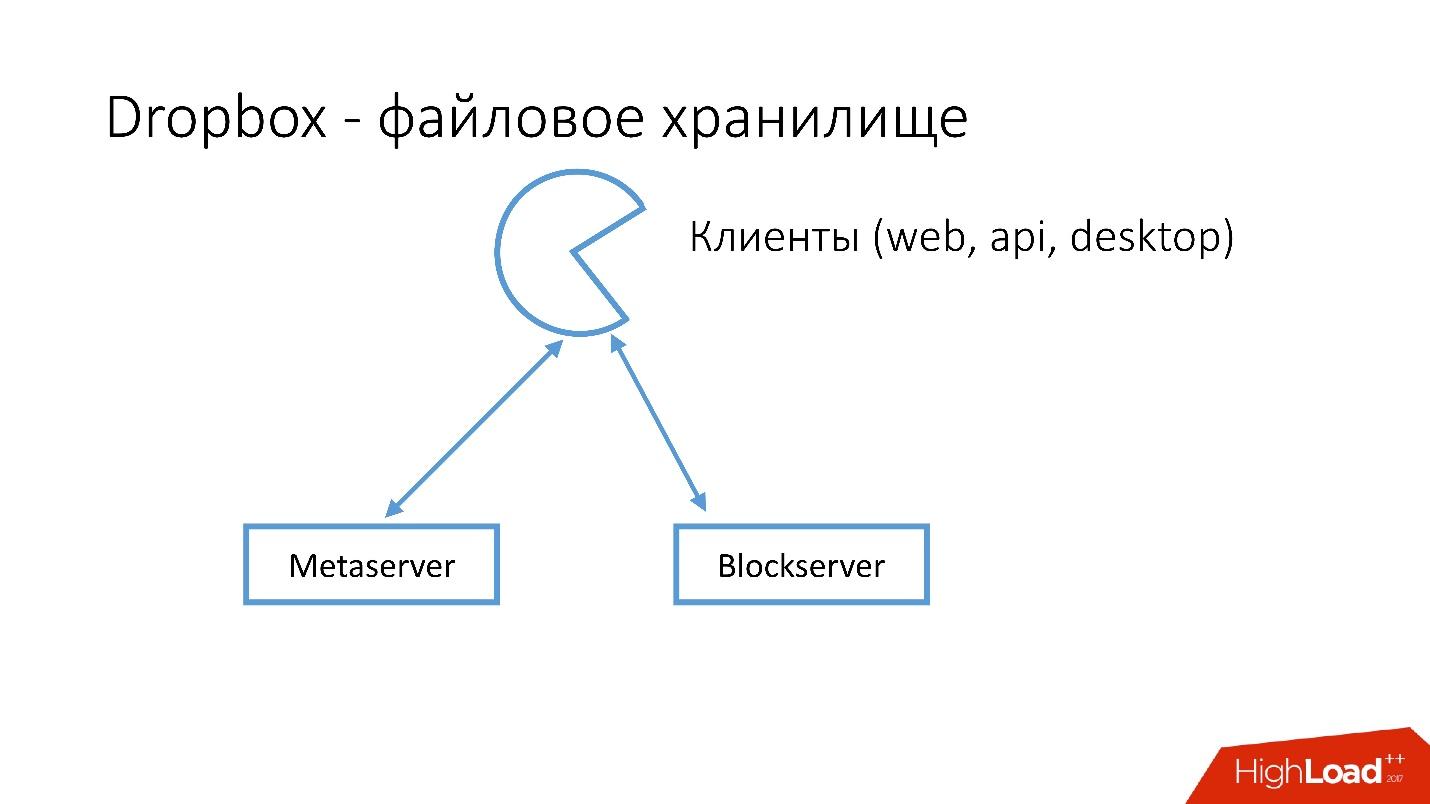
Kami memiliki beberapa klien (antarmuka web, API untuk aplikasi yang menggunakan Dropbox, aplikasi desktop). Semua klien ini menggunakan API dan berkomunikasi dengan dua layanan besar yang secara logis dapat dibagi menjadi:
- Metaserver
- Blockserver
Metaserver menyimpan meta-informasi tentang file: ukuran, komentar di atasnya, tautan ke file ini di Dropbox, dll. Blockserver hanya menyimpan informasi tentang file: folder, jalur, dll.
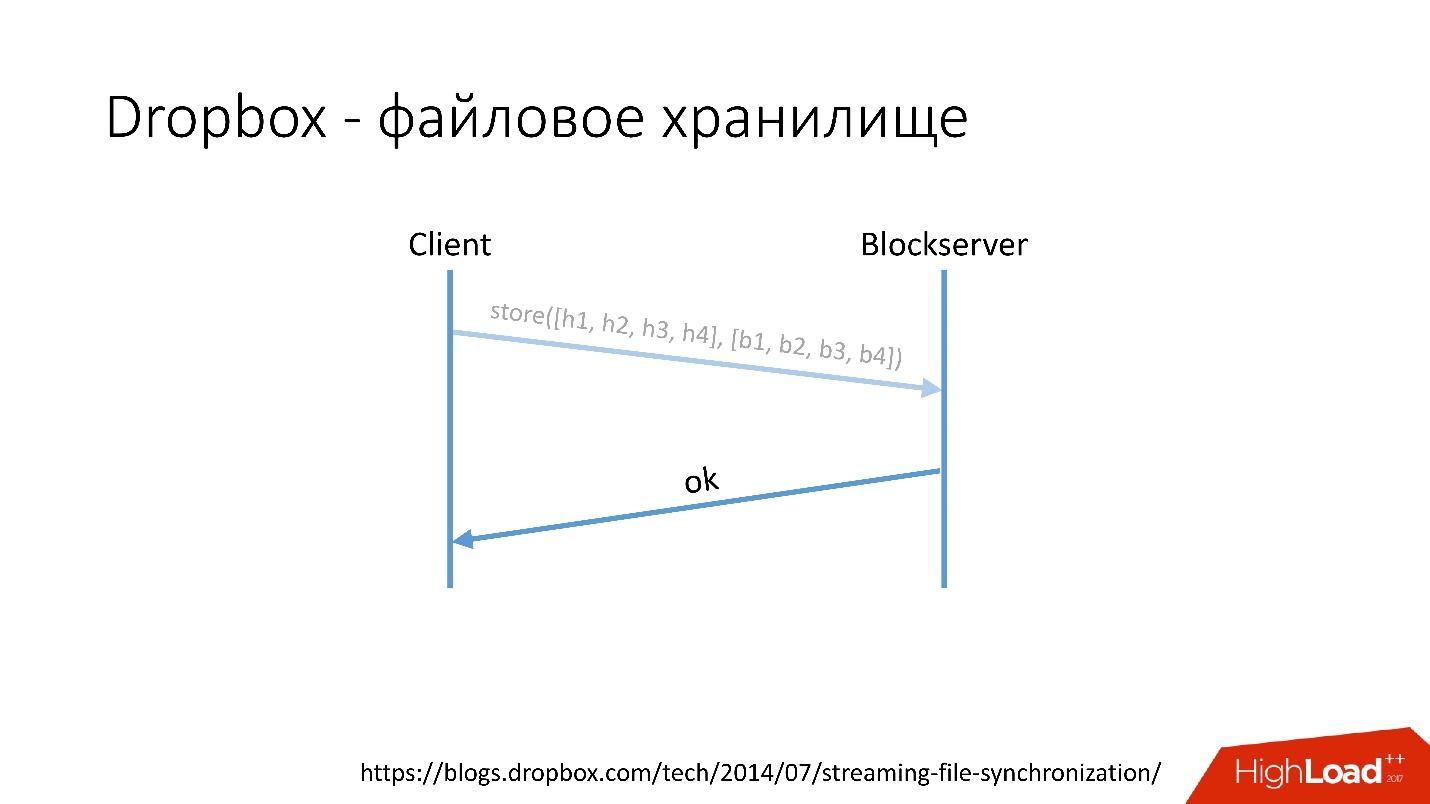
Bagaimana cara kerjanya?Misalnya, Anda memiliki file video.avi dengan beberapa jenis video.
 Tautan dari slide
Tautan dari slide- Klien membagi file ini menjadi beberapa potongan (dalam hal ini, masing-masing 4 MB), menghitung checksum dan mengirimkan permintaan ke Metaserver: "Saya punya file * .avi, saya ingin mengunggahnya, jumlah hash adalah ini dan itu."
- Metaserver mengembalikan jawabannya: "Saya tidak punya blok ini, ayo unduh!" Atau dia dapat menjawab bahwa dia memiliki semua atau beberapa blok, dan hanya yang tersisa yang perlu dimuat.
 Tautan dari slide
Tautan dari slide- Setelah itu, klien pergi ke Blockserver, mengirimkan jumlah hash dan blok data itu sendiri, yang disimpan di Blockserver.
- Blockserver mengkonfirmasi operasi.
 Tautan dari slide
Tautan dari slideTentu saja, ini adalah skema yang sangat disederhanakan, protokolnya jauh lebih rumit: ada sinkronisasi antara klien dalam jaringan yang sama, ada driver kernel, kemampuan untuk menyelesaikan tabrakan, dll. Ini adalah protokol yang cukup rumit, tetapi berfungsi seperti ini secara skematis.

Ketika klien menyimpan sesuatu di Metaserver, semua informasi masuk ke MySQL. Blockserver juga menyimpan informasi tentang file, bagaimana mereka disusun, apa blok mereka terdiri, di MySQL. Blockserver juga menyimpan blok itu sendiri di Block Storage, yang, pada gilirannya, menyimpan informasi tentang di mana blok berada, di server mana dan bagaimana diproses, juga di MYSQL.
Untuk menyimpan exabytes file pengguna, kami secara bersamaan menyimpan informasi tambahan dalam database beberapa lusin petabyte yang tersebar di 6 ribu server.
Sejarah Pengembangan Database
Bagaimana basis data berkembang di Dropbox?

Pada 2008, semuanya dimulai dengan satu Metaserver dan satu basis data global. Semua informasi yang diperlukan Dropbox untuk disimpan di suatu tempat, ia menyimpannya di satu-satunya MySQL global. Ini tidak berlangsung lama, karena jumlah pengguna bertambah, dan masing-masing database dan tablet di dalam basis data membengkak lebih cepat daripada yang lain.

Oleh karena itu, pada tahun 2011 beberapa tabel dikirimkan ke server terpisah:
- Pengguna , dengan informasi tentang pengguna, misalnya, masuk dan token oAuth;
- Host , dengan informasi file dari Blockserver;
- Lain-lain , yang tidak terlibat dalam memproses permintaan dari produksi, tetapi digunakan untuk fungsi utilitas, seperti pekerjaan batch.
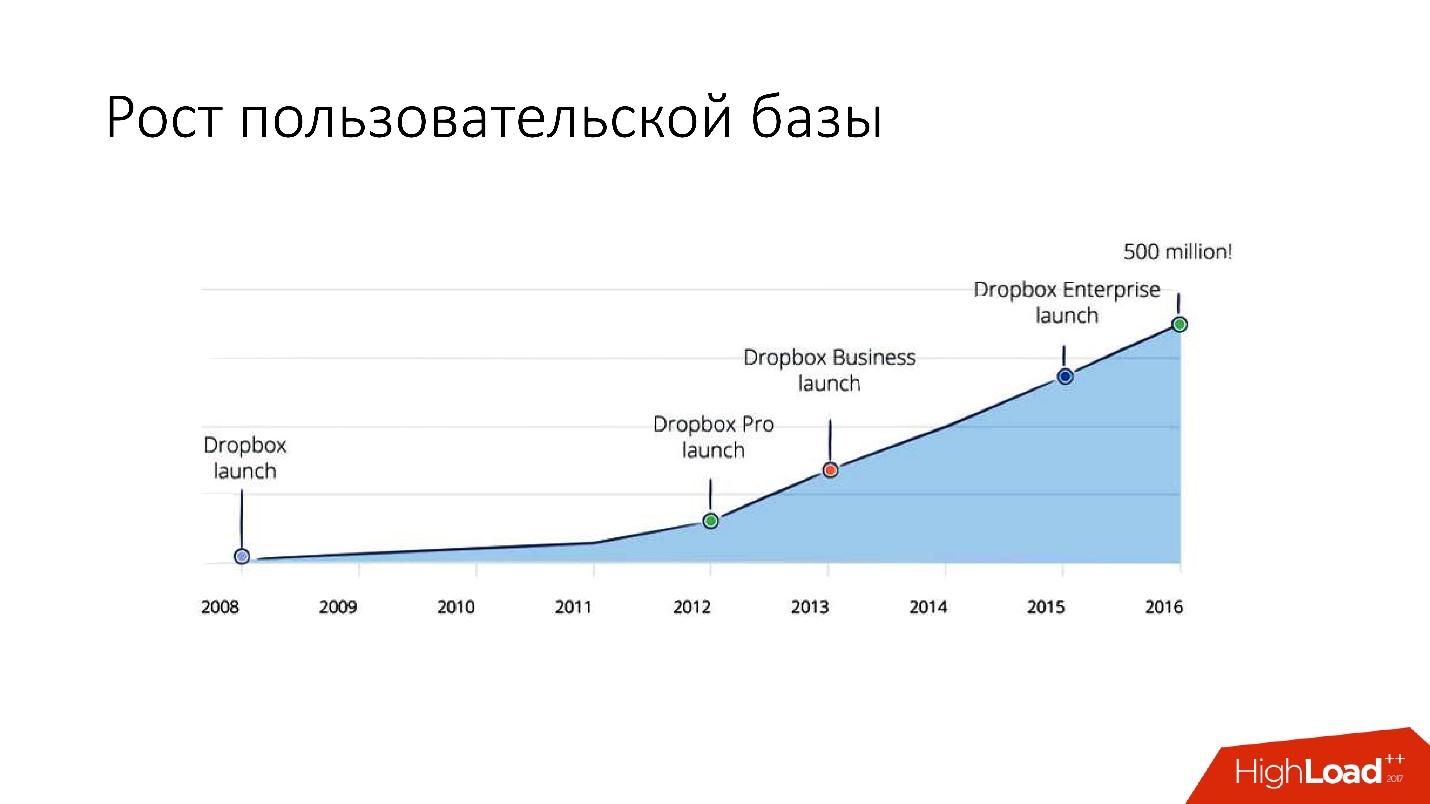
Tetapi setelah 2012, Dropbox mulai tumbuh sangat banyak, sejak itu
kami telah tumbuh
sekitar 100 juta pengguna per tahun .
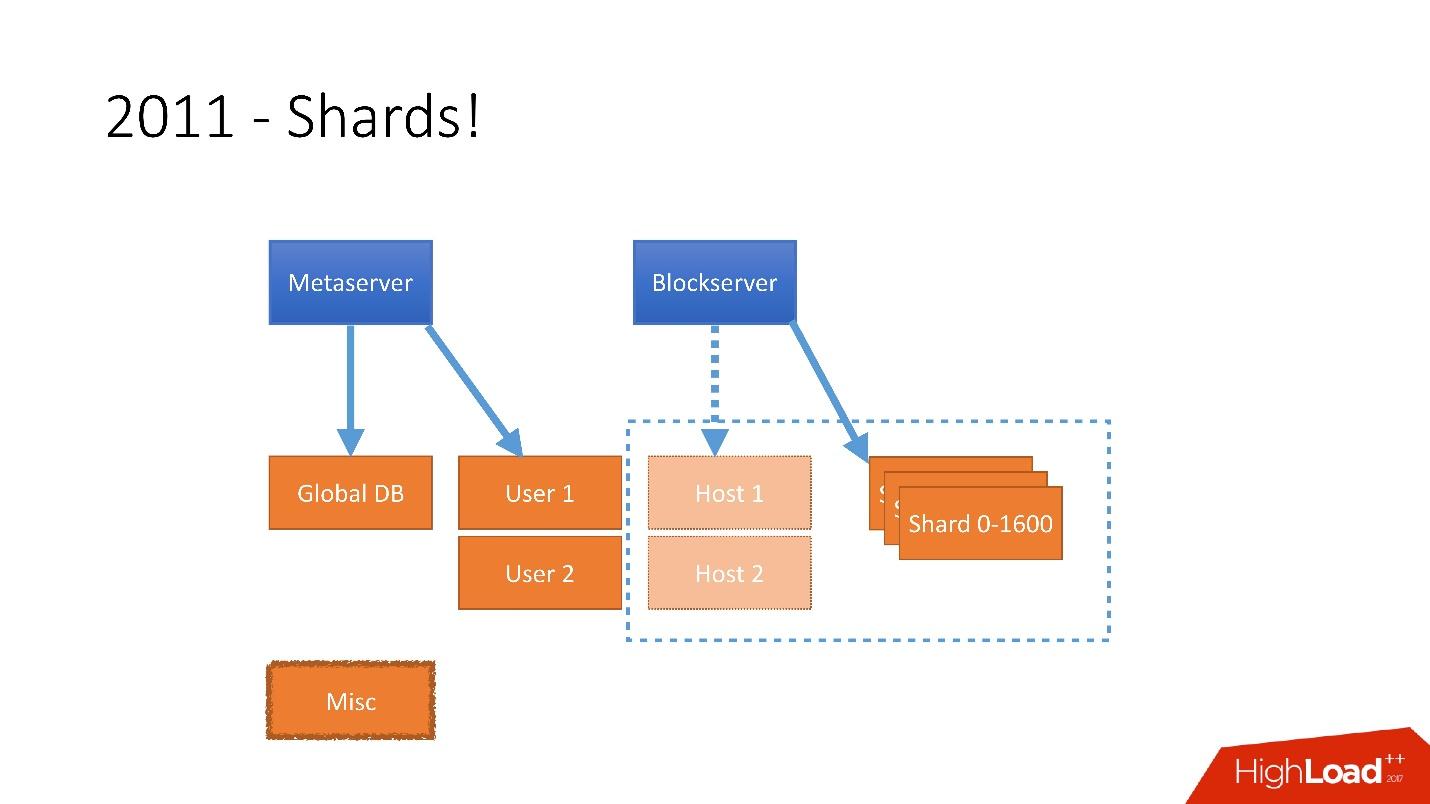
Itu perlu untuk memperhitungkan pertumbuhan sebesar itu, dan karena itu pada akhir 2011 kami memiliki pecahan - basis yang terdiri dari 1.600 pecahan. Awalnya, hanya 8 server dengan masing-masing 200 pecahan. Sekarang ini adalah 400 server master dengan masing-masing 4 pecahan.
 Tautan dari slide
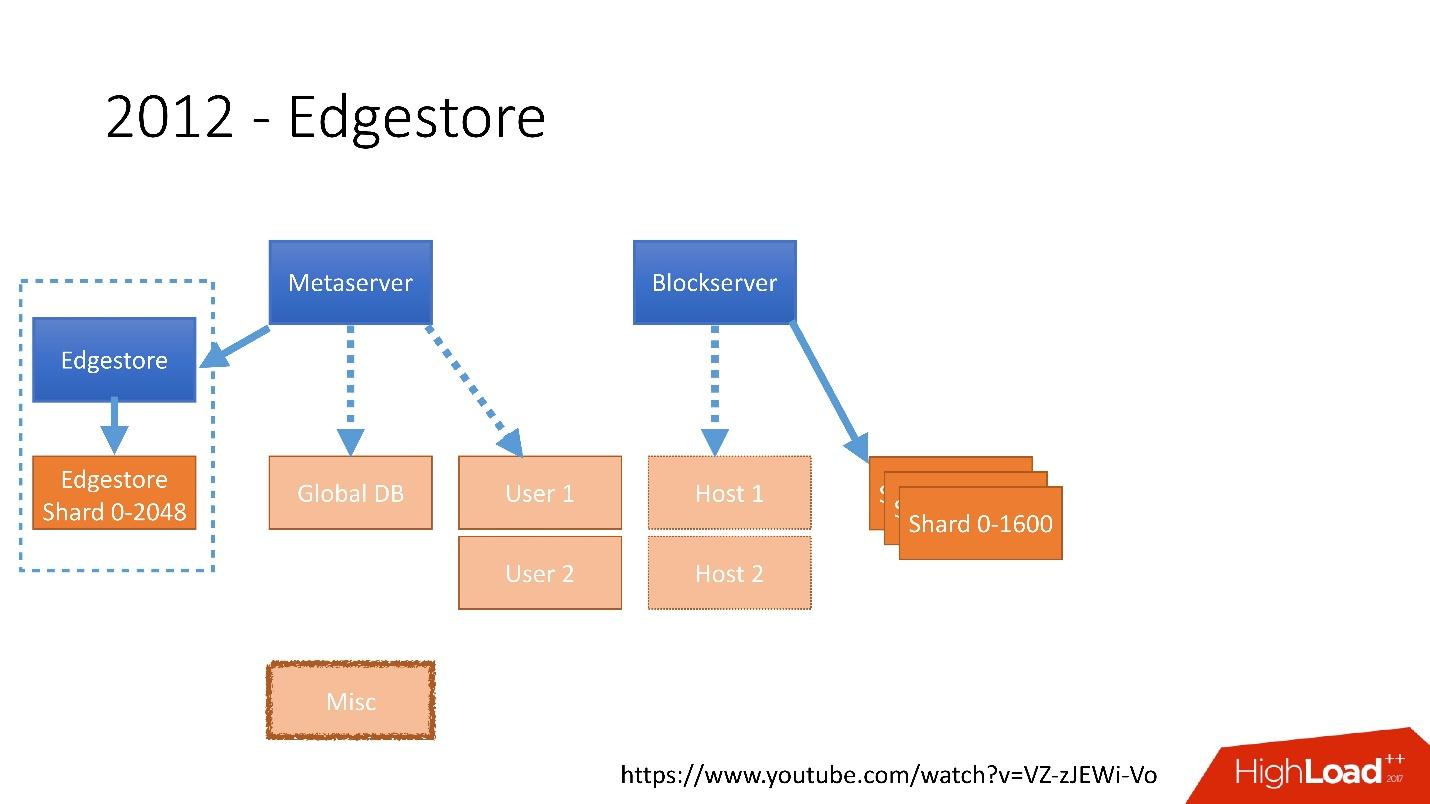
Tautan dari slidePada 2012, kami menyadari bahwa membuat tabel dan memperbaruinya dalam database untuk setiap logika bisnis tambahan sangat sulit, suram, dan bermasalah. Oleh karena itu, pada tahun 2012, kami menemukan penyimpanan grafik kami sendiri, yang kami sebut
Edgestore , dan sejak itu semua logika bisnis dan meta-informasi yang dihasilkan aplikasi disimpan di Edgestore.
Edgestore pada dasarnya abstrak MySQL dari klien. Klien memiliki entitas tertentu yang saling terhubung oleh tautan dari API gRPC ke Edgestore Core, yang mengubah data ini menjadi MySQL dan entah bagaimana menyimpannya di sana (pada dasarnya, ia memberikan semua ini dari cache).
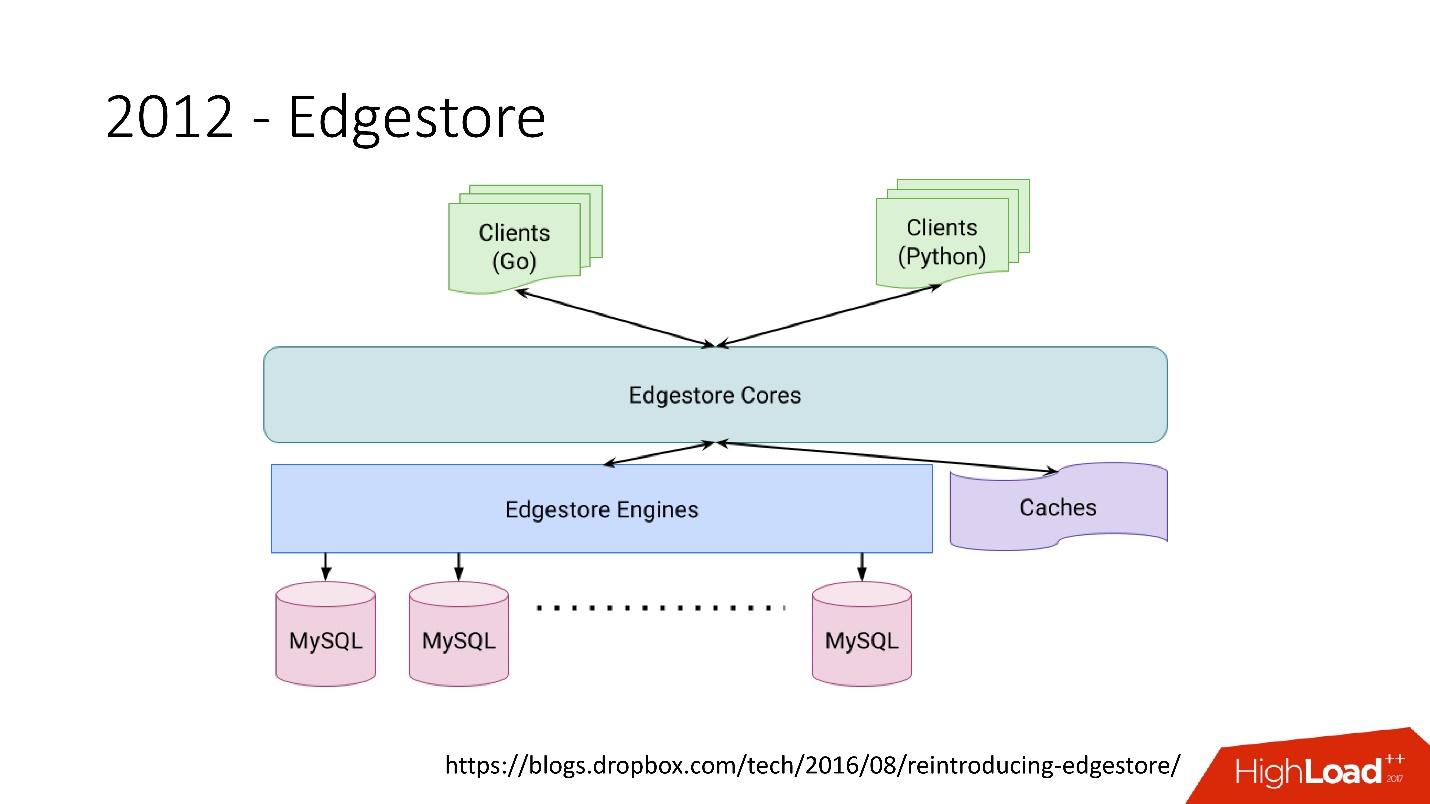 Tautan dari slidePada 2015, kami meninggalkan Amazon S3
Tautan dari slidePada 2015, kami meninggalkan Amazon S3 , mengembangkan penyimpanan cloud kami sendiri yang disebut Magic Pocket. Ini berisi informasi tentang di mana file blok berada, di server mana, tentang pergerakan blok-blok ini antara server, disimpan di MySQL.
 Tautan dari slide
Tautan dari slideTetapi MySQL digunakan dengan cara yang sangat rumit - pada intinya, sebagai tabel hash terdistribusi besar. Ini adalah beban yang sangat berbeda, terutama pada pembacaan catatan acak. 90% pemanfaatannya adalah I / O.
Arsitektur basis data
Pertama, kami segera mengidentifikasi beberapa prinsip yang digunakan untuk membangun arsitektur basis data kami:
- Keandalan dan daya tahan . Ini adalah prinsip paling penting dan apa yang pelanggan harapkan dari kami - data tidak boleh hilang.
- Optimalitas solusi adalah prinsip yang sama pentingnya. Misalnya, pencadangan harus dilakukan dengan cepat dan dikembalikan dengan cepat juga.
- Kesederhanaan solusi - baik secara arsitektur maupun dalam hal layanan dan dukungan pengembangan lebih lanjut.
- Biaya kepemilikan . Jika sesuatu mengoptimalkan solusi, tetapi sangat mahal, ini tidak cocok untuk kita. Sebagai contoh, seorang budak yang satu hari di belakang master sangat nyaman untuk cadangan, tetapi kemudian Anda perlu menambahkan 1.000 lebih ke 6.000 server - biaya kepemilikan budak seperti itu sangat tinggi.
Semua prinsip harus dapat
diverifikasi dan diukur , yaitu, mereka harus memiliki metrik. Jika kita berbicara tentang biaya kepemilikan, maka kita harus menghitung berapa banyak server yang kita miliki, misalnya, masuk ke basis data, berapa banyak server masuk ke cadangan, dan berapa biaya untuk Dropbox pada akhirnya. Ketika kami memilih solusi baru, kami menghitung semua metrik dan fokus pada mereka. Ketika memilih solusi apa pun, kami sepenuhnya dipandu oleh prinsip-prinsip ini.
Topologi dasar
Basis data disusun sebagai berikut:
- Di pusat data utama, kami memiliki master, di mana semua catatan terjadi.
- Server master memiliki dua server slave tempat replikasi semisync terjadi. Server sering mati (sekitar 10 per minggu), jadi kita perlu dua server budak.
- Server budak berada dalam kelompok yang terpisah. Cluster adalah ruangan yang sepenuhnya terpisah di pusat data yang tidak terhubung satu sama lain. Jika satu ruangan terbakar, yang kedua tetap berfungsi sepenuhnya.
- Juga di pusat data lain kita memiliki master semu (master perantara), yang sebenarnya hanya seorang budak, yang memiliki budak lain.
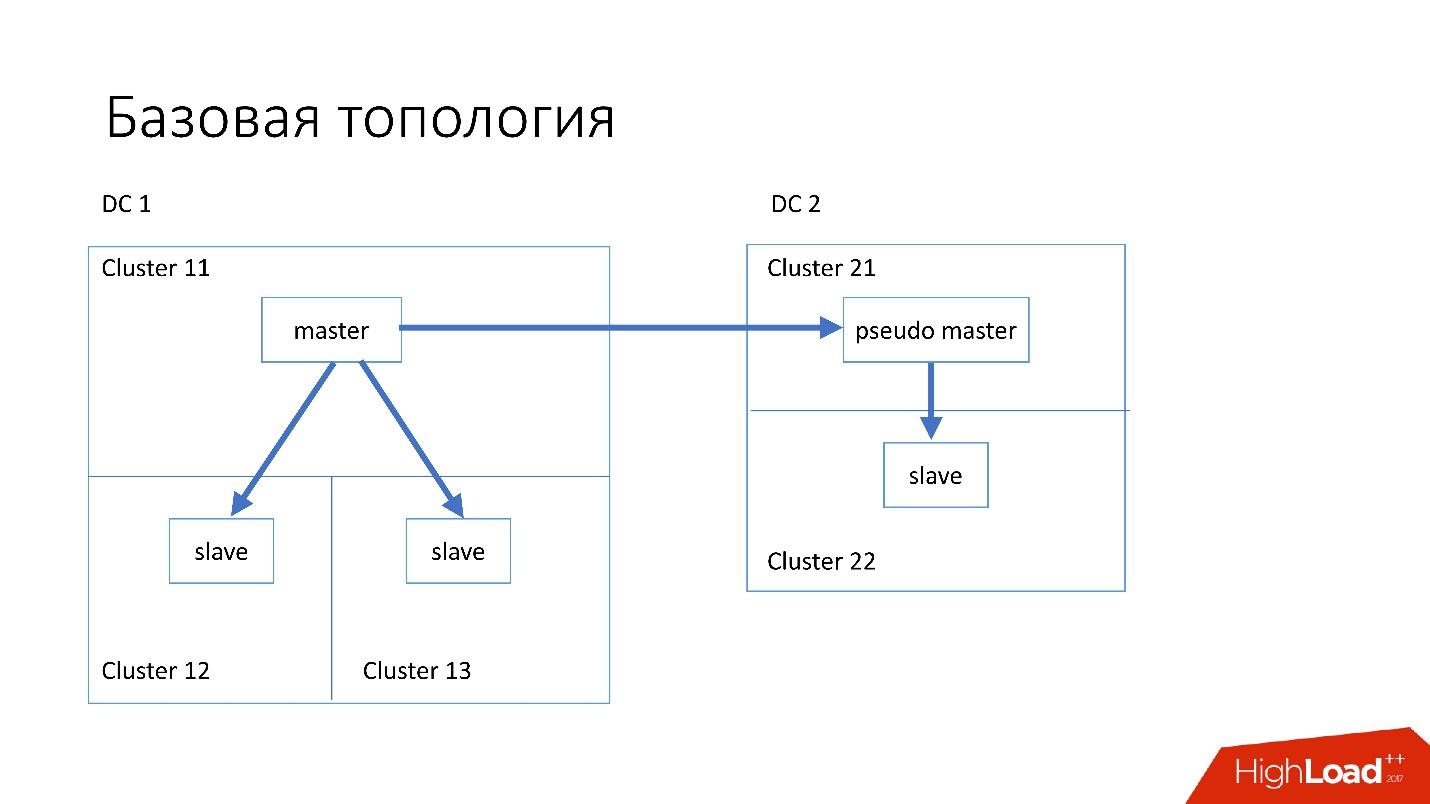
Topologi seperti itu dipilih karena jika pusat data pertama tiba-tiba mati di dalam kita, maka di pusat data kedua kita memiliki
topologi yang hampir lengkap . Kami cukup mengubah semua alamat di Discovery, dan klien dapat bekerja.
Topologi khusus
Kami juga memiliki topologi khusus.
Topologi
Magic Pocket terdiri dari satu server master dan dua server slave. Ini dilakukan karena Magic Pocket sendiri menggandakan data antar zona. Jika kehilangan satu cluster, itu dapat mengembalikan semua data dari zona lain melalui kode penghapusan.

Topologi
aktif-aktif adalah topologi khusus yang digunakan oleh Edgestore. Ia memiliki satu master dan dua budak di masing-masing dari dua pusat data, dan mereka adalah budak untuk satu sama lain. Ini adalah
skema yang sangat
berbahaya , tetapi Edgestore pada levelnya tahu persis data apa yang menguasai kisaran apa yang bisa ditulisnya. Karena itu, topologi ini tidak pecah.
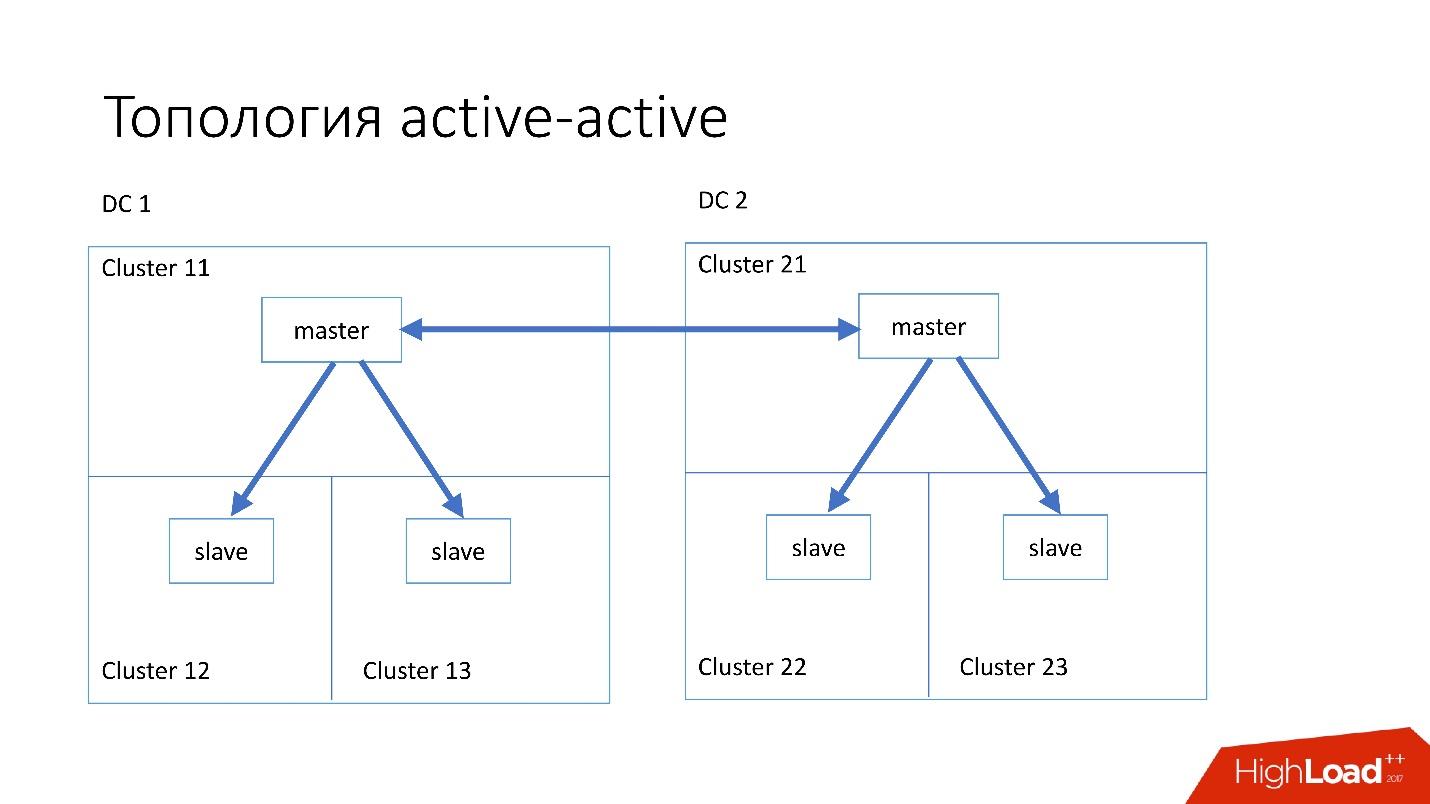
Contoh
Kami telah menginstal server yang cukup sederhana dengan konfigurasi 4-5 tahun yang lalu:
- 2x Xeon 10 core;
- 5TB (8 SSD Raid 0 *);
- Memori 384 GB.
* Raid 0 - karena lebih mudah dan lebih cepat untuk mengganti seluruh server daripada drive.
Contoh tunggal
Di server ini, kami memiliki satu instance MySQL besar tempat beberapa pecahan berada. Contoh MySQL ini segera mengalokasikan sendiri hampir semua memori. Proses lain juga berjalan di server: proksi, pengumpulan statistik, log, dll.
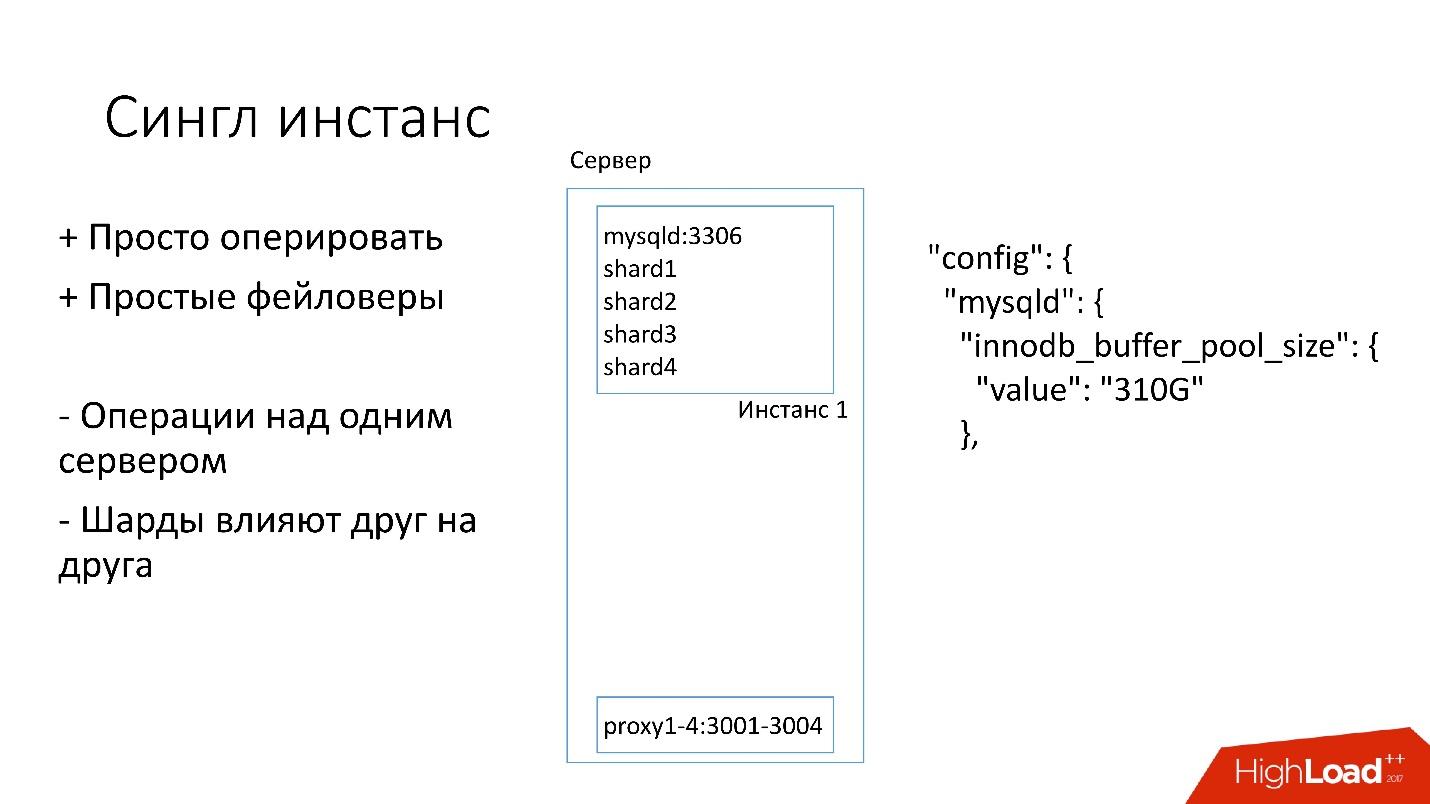
Solusi ini bagus karena:
+
Mudah dikelola . Jika Anda perlu mengganti instance MySQL, cukup ganti server.
+
Lakukan faylovers .
Di sisi lain:
- Bermasalah bahwa setiap operasi terjadi pada seluruh instance MySQL dan langsung pada semua pecahan. Misalnya, jika Anda perlu mencadangkan, kami mencadangkan semua pecahan sekaligus. Jika Anda perlu membuat faylover, kami membuat faylover keempat pecahan sekaligus. Dengan demikian, aksesibilitas menderita 4 kali lebih banyak.
- Masalah dengan mereplikasi satu pecahan mempengaruhi pecahan lainnya. Replikasi MySQL tidak paralel, dan semua pecahan bekerja pada satu utas. Jika sesuatu terjadi pada satu beling, maka sisanya juga menjadi korban.
Jadi sekarang kita pindah ke topologi yang berbeda.
Multi instance

Dalam versi baru, beberapa contoh MySQL diluncurkan pada server sekaligus, masing-masing dengan satu beling. Apa yang lebih baik
+ Kami dapat
melakukan operasi hanya pada satu beling tertentu . Artinya, jika Anda membutuhkan faylover, alihkan hanya satu beling, jika Anda membutuhkan cadangan, kami hanya mencadangkan satu beling. Ini berarti bahwa operasi sangat dipercepat - 4 kali untuk server empat-beling.
+
Pecahan hampir tidak saling mempengaruhi .
+
Peningkatan replikasi. Kami dapat mencampur berbagai kategori dan kelas basis data. Edgestore membutuhkan banyak ruang, misalnya, semua 4 TB, dan Magic Pocket hanya memakan 1 TB, tetapi memiliki pemanfaatan 90%. Artinya, kita dapat menggabungkan berbagai kategori yang menggunakan I / O dan sumber daya mesin dengan cara yang berbeda, dan memulai 4 aliran replikasi.
Tentu saja, solusi ini memiliki kekurangan:
- Kekurangan terbesar adalah bahwa
jauh lebih sulit untuk mengelola semua ini . Kami membutuhkan penjadwal cerdas yang akan memahami di mana ia dapat mengambil contoh ini, di mana akan ada beban optimal.
-
Lebih sulit dari kegagalan .
Karena itu, kami baru saja beralih ke keputusan ini.
Penemuan
Klien entah bagaimana harus tahu cara terhubung ke database yang diinginkan, jadi kami memiliki Discovery, yang seharusnya:
- Beri tahu klien dengan sangat cepat tentang perubahan topologi. Jika kita mengganti master dan slave, klien harus segera mempelajarinya.
- Topologi tidak boleh bergantung pada topologi replikasi MySQL, karena dengan beberapa operasi kita mengubah topologi MySQL. Sebagai contoh, ketika kita melakukan split, pada langkah persiapan pada master target, di mana kita akan mentransfer bagian dari pecahan, beberapa server slave dikonfigurasi ulang untuk master target ini. Pelanggan tidak perlu tahu tentang ini.
- Penting bahwa ada atomicity operasi dan verifikasi negara. Tidak mungkin dua server berbeda dari database yang sama untuk menjadi master pada saat yang sama.
Bagaimana Discovery Dikembangkan
Awalnya semuanya sederhana: alamat basis data dalam kode sumber di konfigurasi. Ketika kami perlu memperbarui alamat, maka semuanya baru saja dikerahkan dengan sangat cepat.

Sayangnya, ini tidak berfungsi jika ada banyak server.
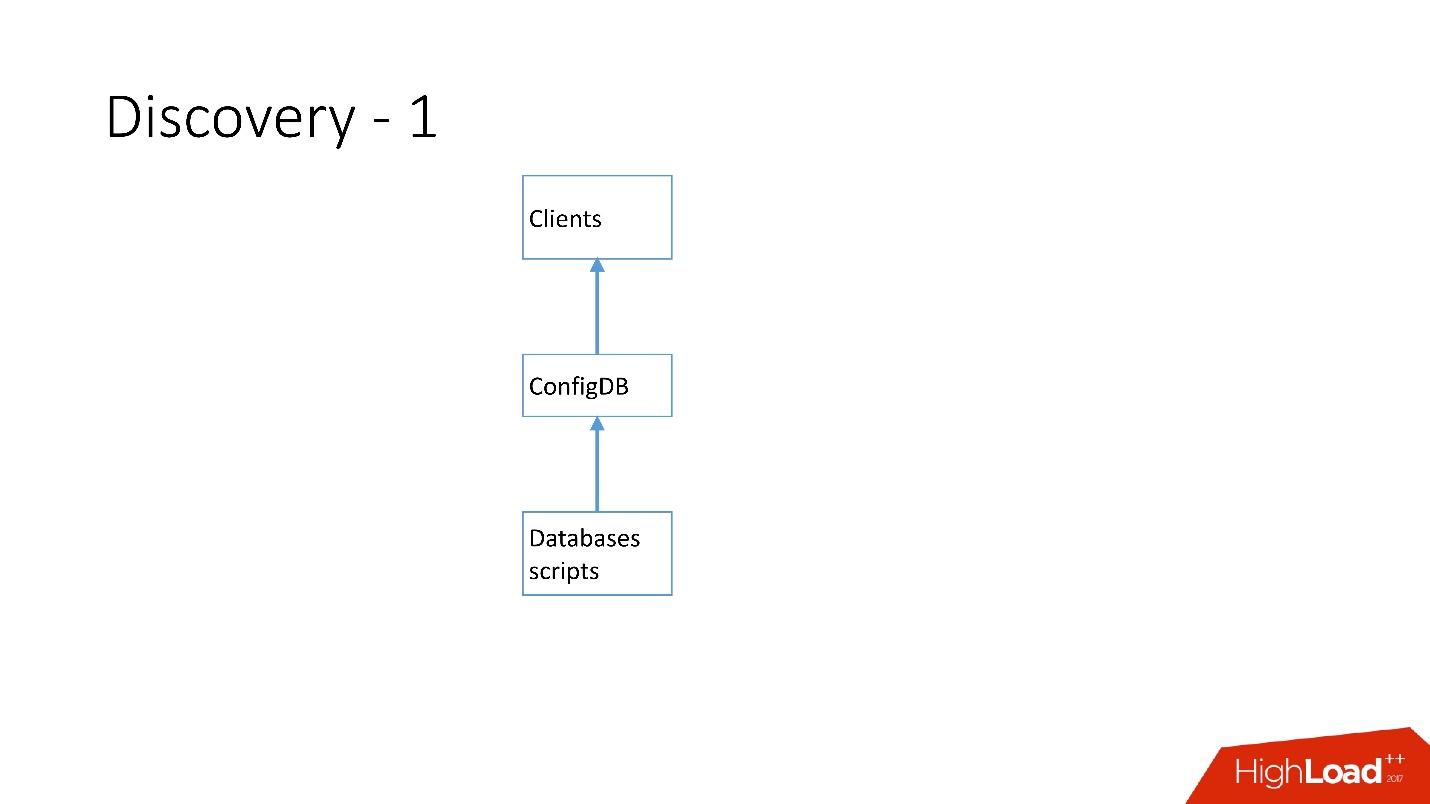
Di atas adalah Penemuan pertama yang kita miliki. Ada skrip database yang mengubah papan nama di ConfigDB - itu adalah papan nama MySQL yang terpisah, dan klien sudah mendengarkan database ini dan secara berkala mengambil data dari sana.

Tabelnya sangat sederhana, ada kategori database, kunci shard, kelas master database / slave, proxy, dan alamat database. Bahkan, klien meminta kategori, kelas DB, kunci shard, dan alamat MySQL dikembalikan ke mana ia sudah bisa membuat koneksi.
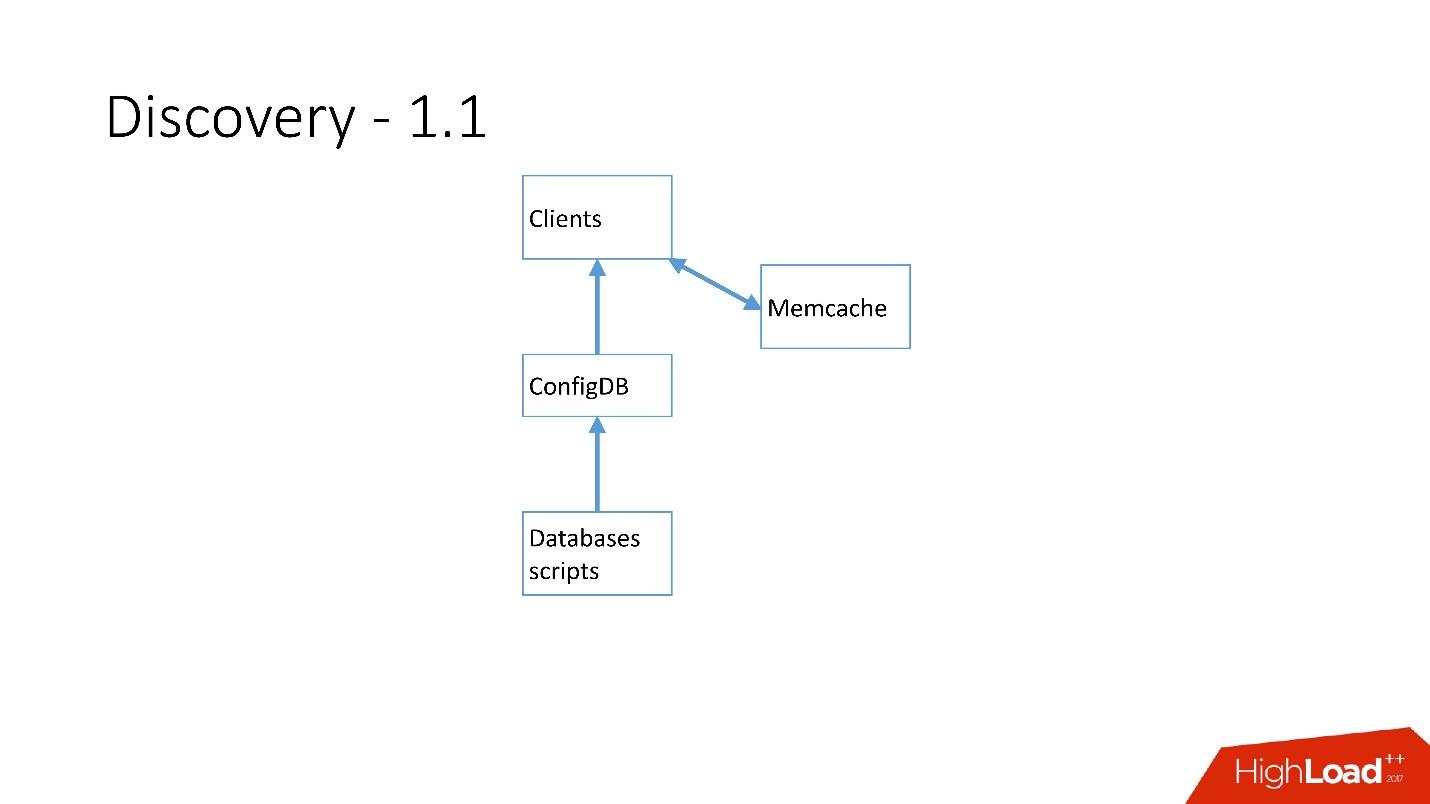
Segera setelah ada banyak server, Memcache ditambahkan dan klien mulai berkomunikasi dengannya.
Tapi kemudian kami ulang. Script MySQL mulai berkomunikasi melalui gRPC, melalui thin client dengan layanan yang kami sebut RegisterService. Ketika beberapa perubahan terjadi, RegisterService memiliki antrian, dan dia mengerti bagaimana menerapkan perubahan ini. RegisterService menyimpan data dalam AFS. AFS adalah sistem internal kami yang didasarkan pada ZooKeeper.

Solusi kedua, yang tidak ditampilkan di sini, menggunakan ZooKeeper secara langsung, dan ini menciptakan masalah karena masing-masing beling adalah simpul di ZooKeeper. Misalnya, 100 ribu klien terhubung ke ZooKeeper, jika mereka tiba-tiba mati karena beberapa jenis bug bersama-sama, maka 100 ribu permintaan ke ZooKeeper akan segera datang, yang hanya akan menjatuhkannya dan tidak akan bisa naik.
Karenanya,
sistem AFS dikembangkan
, yang digunakan oleh seluruh Dropbox . Bahkan, itu abstrak pekerjaan dengan ZooKeeper untuk semua pelanggan. Daemon AFS secara lokal berjalan di setiap server dan menyediakan file API yang sangat sederhana dari formulir: membuat file, menghapus file, meminta file, menerima pemberitahuan tentang perubahan file dan membandingkan serta menukar operasi. Artinya, Anda dapat mencoba mengganti file dengan beberapa versi, dan jika versi ini telah berubah selama perubahan, operasi dibatalkan.
Pada dasarnya, seperti abstraksi atas ZooKeeper, di mana ada algoritma backoff dan jitter lokal. ZooKeeper tidak lagi mogok saat dimuat. Dengan AFS, kami mengambil cadangan dalam S3 dan GIT, lalu AFS lokal sendiri memberi tahu klien bahwa data telah berubah.

Dalam AFS, data disimpan sebagai file, yaitu API sistem file. Misalnya, di atas adalah file shard.slave_proxy - terbesar, dibutuhkan sekitar 28 Kb, dan ketika kami mengubah kategori kelas shard dan slave_proxy, maka semua klien yang berlangganan file ini menerima pemberitahuan. Mereka membaca kembali file ini, yang berisi semua informasi yang diperlukan. Menggunakan kunci beling, mereka mendapatkan kategori dan mengkonfigurasi ulang kumpulan koneksi ke database.
Operasi
Kami menggunakan operasi yang sangat sederhana: promosi, klon, backup / pemulihan.
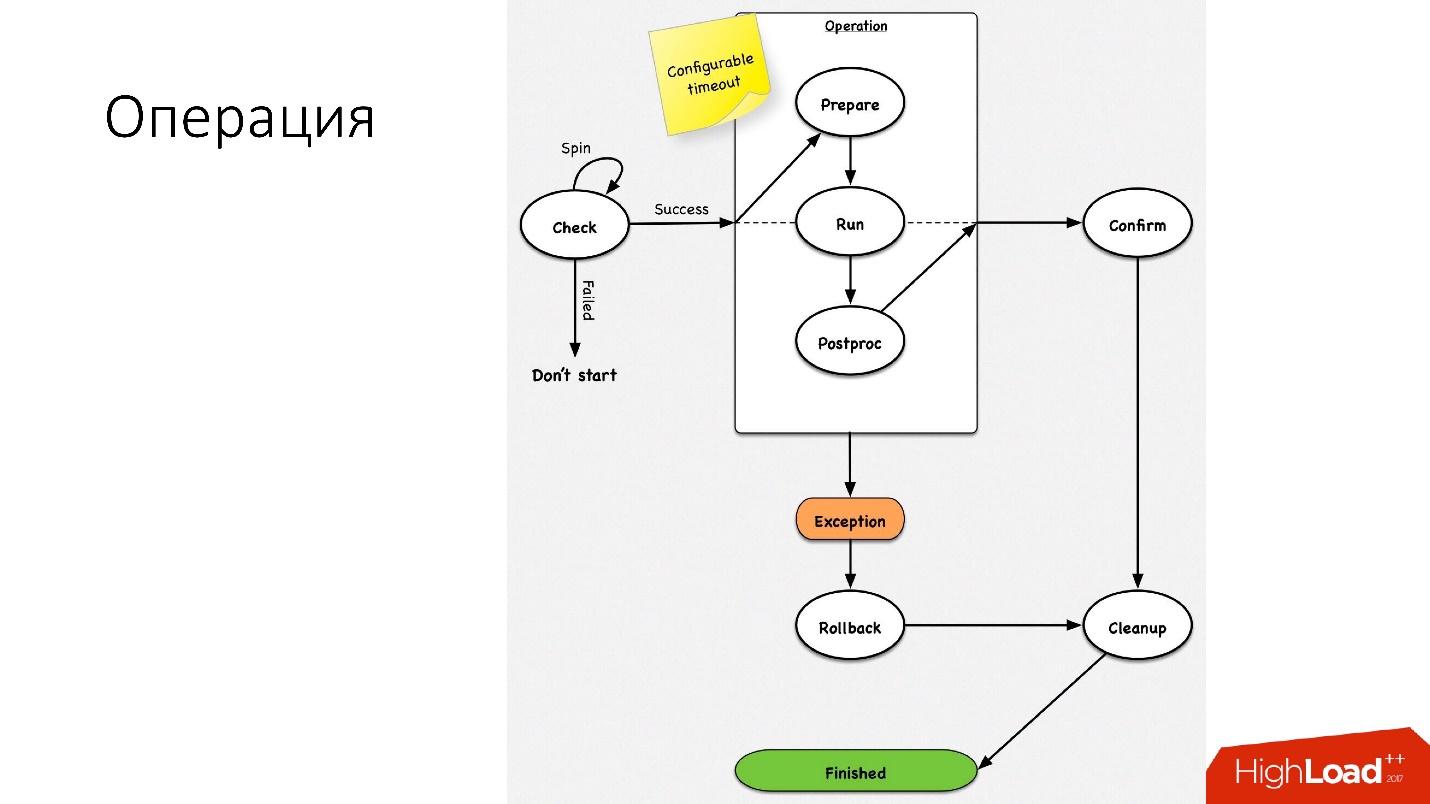 Operasi adalah mesin keadaan sederhana
Operasi adalah mesin keadaan sederhana . Ketika kita masuk ke operasi, kita melakukan beberapa pemeriksaan, misalnya, spin-check, yang beberapa kali oleh waktu habis memeriksa apakah kita dapat melakukan operasi ini. Setelah itu, kami melakukan beberapa tindakan persiapan yang tidak mempengaruhi sistem eksternal. Selanjutnya, operasi itu sendiri.
Semua langkah dalam operasi memiliki
langkah mundur (undo). Jika ada masalah dengan operasi, operasi mencoba mengembalikan sistem ke posisi semula. Jika semuanya baik-baik saja, maka pembersihan terjadi dan operasi selesai.
Kami memiliki mesin keadaan sederhana untuk operasi apa pun.
Promosi (pergantian master)
Ini adalah operasi yang sangat umum dalam database. Ada pertanyaan tentang bagaimana melakukan perubahan pada server master panas yang berfungsi - itu akan dipertaruhkan. Hanya saja semua operasi ini dilakukan pada server slave, dan kemudian slave perubahan dengan tempat utama. Karena itu,
operasi promosi sangat sering dilakukan .

Kita perlu memperbarui kernel - kita melakukan swap, kita perlu memperbarui versi MySQL - kita memperbarui pada slave, beralih ke master, perbarui di sana.

Kami telah mencapai promosi yang sangat cepat. Misalnya,
untuk empat pecahan, kami sekarang memiliki promosi sekitar 10-15 detik. Grafik di atas menunjukkan bahwa dengan ketersediaan promosi menderita 0,0003%.
Tetapi promosi normal tidak begitu menarik, karena ini adalah operasi biasa yang dilakukan setiap hari. Kegagalan itu menarik.
Failover (pengganti master rusak)
Kegagalan berarti database sudah mati.
- Jika server benar-benar mati, ini hanya kasus yang ideal.
- Bahkan, ternyata server sebagian hidup.
- Terkadang server mati sangat lambat. Pengendali serangan, sistem disk gagal, beberapa permintaan mengembalikan jawaban, tetapi beberapa aliran diblokir dan tidak mengembalikan jawaban.
- Kebetulan master hanya kelebihan beban dan tidak menanggapi pemeriksaan kesehatan kami. Tetapi jika kita melakukan promosi, master baru juga akan kelebihan beban, dan itu hanya akan bertambah buruk.
Penggantian server master yang meninggal terjadi sekitar
2-3 kali sehari , ini adalah proses yang sepenuhnya otomatis, tidak diperlukan campur tangan manusia. Bagian kritis memakan waktu sekitar 30 detik, dan memiliki banyak pemeriksaan tambahan untuk melihat apakah server benar-benar hidup, atau mungkin sudah mati.
Di bawah ini adalah contoh diagram tentang bagaimana faylover bekerja.

Di bagian yang dipilih, kita
me-reboot server master . Ini diperlukan karena kami memiliki MySQL 5.6, dan replikasi semisync di dalamnya tidak lossless. Oleh karena itu, pembacaan hantu dimungkinkan, dan kami membutuhkan master ini, meskipun belum mati, bunuh secepat mungkin sehingga klien memutuskan sambungan darinya. Karena itu, kami melakukan hard reset melalui Ipmi - ini adalah operasi terpenting pertama yang harus kami lakukan. Dalam versi MySQL 5.7, ini tidak begitu kritis.
Sinkronisasi cluster. Mengapa kita perlu sinkronisasi klaster?
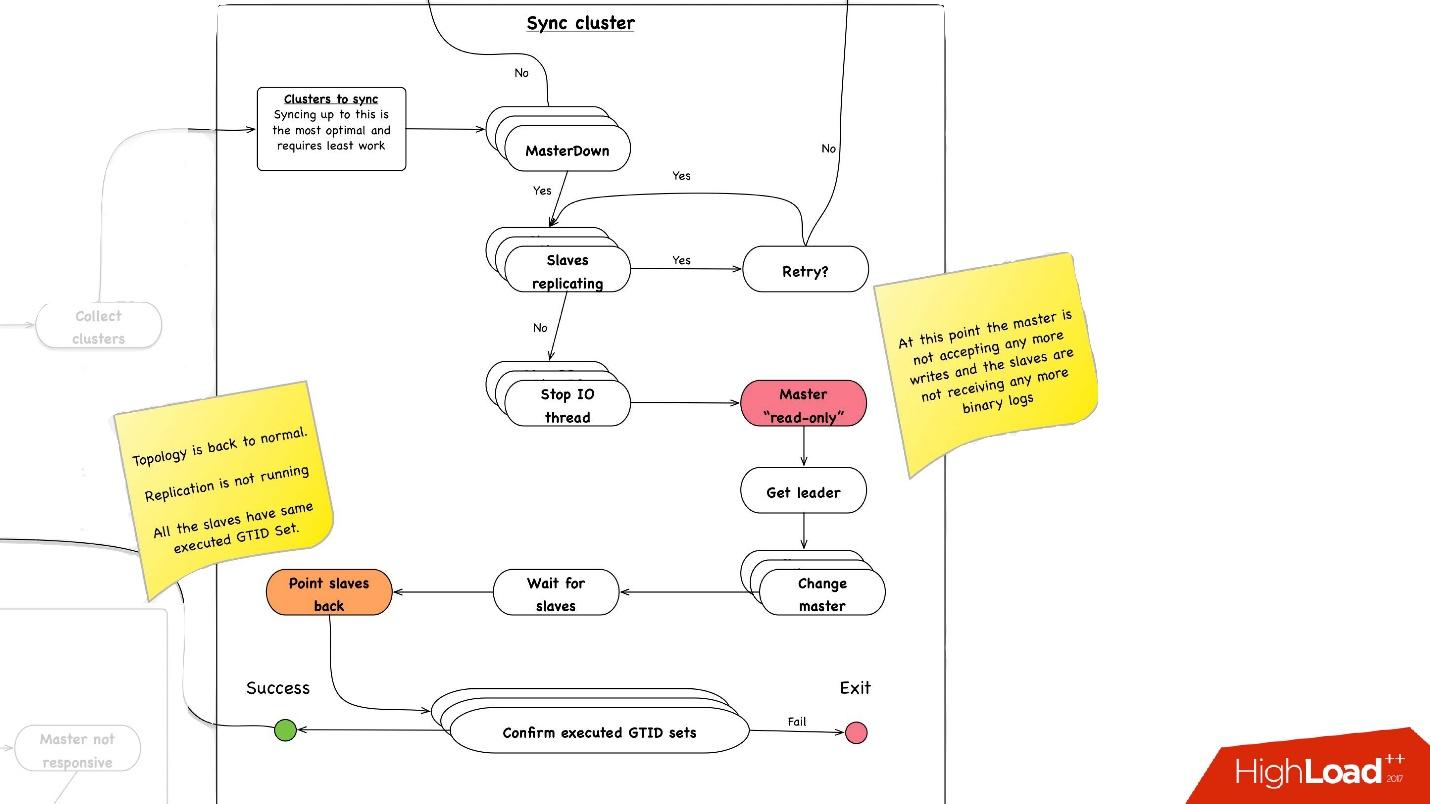
Jika kita mengingat gambar sebelumnya dengan topologi kita, satu server master memiliki tiga server slave: dua dalam satu pusat data, satu di yang lain. Dengan promosi, kita perlu master untuk berada di pusat data utama yang sama. Tetapi kadang-kadang, ketika budak dimuat, dengan semisync terjadi bahwa budak-semisync menjadi budak di pusat data lain, karena tidak dimuat. Oleh karena itu, pertama-tama kita perlu menyinkronkan seluruh cluster, dan kemudian sudah melakukan promosi pada slave di pusat data yang kita butuhkan. Ini dilakukan dengan sangat sederhana:
- Kami menghentikan semua utas I / O pada semua server slave.
- Setelah itu, kita sudah tahu pasti bahwa master "read-only", karena semisync telah terputus dan tidak ada orang lain yang dapat menulis apa pun di sana.
- Selanjutnya, kami memilih budak dengan Set GTID yang diambil / dieksekusi terbesar, yaitu, dengan transaksi terbesar yang diunduh atau sudah diterapkan.
- Kami mengkonfigurasi ulang semua server slave ke slave yang dipilih ini, memulai utas I / O, dan mereka disinkronkan.
- Kami menunggu sampai mereka disinkronkan, setelah itu kami memiliki seluruh cluster menjadi disinkronkan. , executed GTID set .
—
.
promotion , :
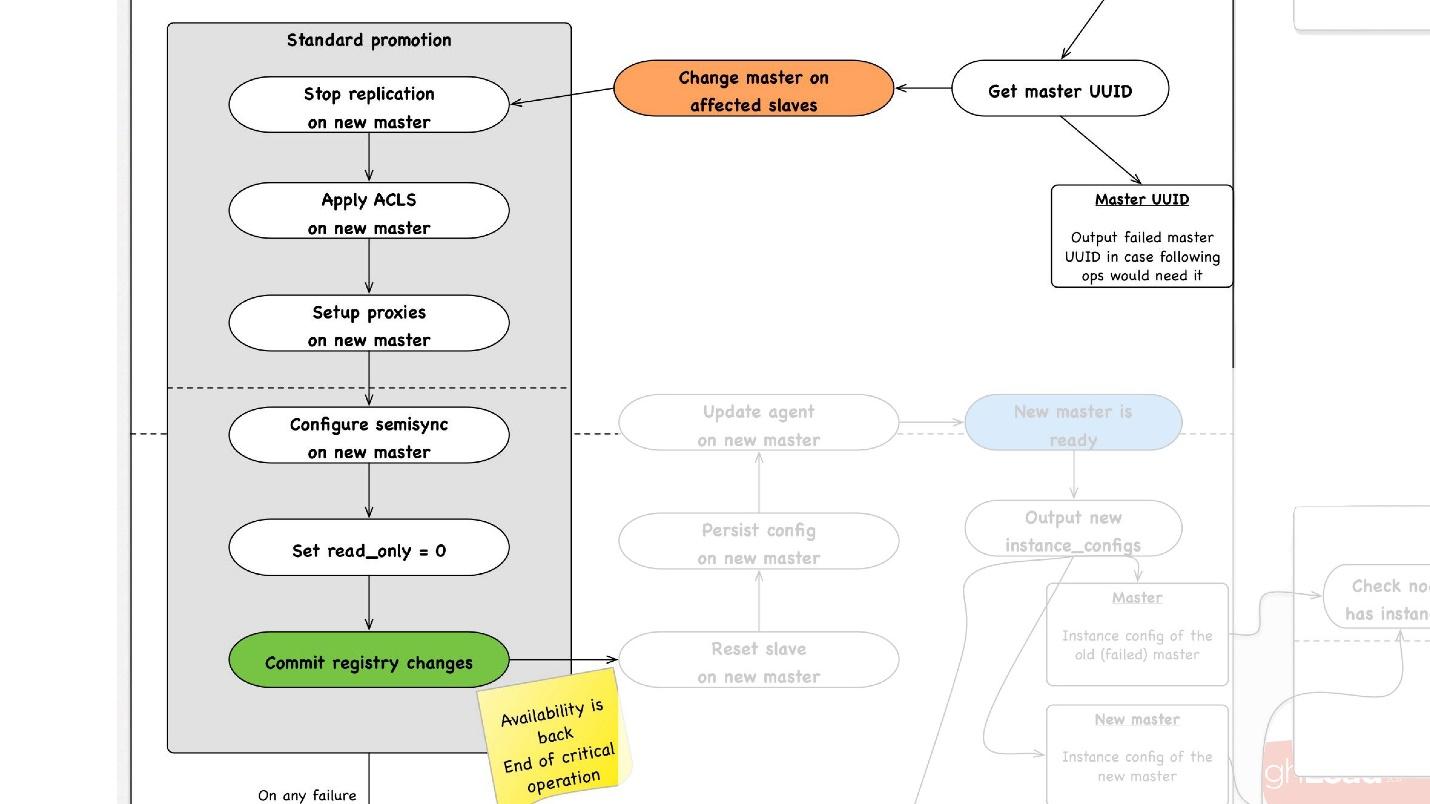
- slave -, , master, promotion.
- slave- master, , ACLs, , - proxy, , - .
- read_only = 0, , master , . master .
- - . - , , , , , proxy .
- .
, rollback , . rollback reboot. , , , — change master — master .
— . , , , , .
● slave
, slave-, . .
●
, , . .
●
, , . . 3 .
, , , :
- . 1 40 .
- .
, . 1 40 , , , .
, . . 4 .
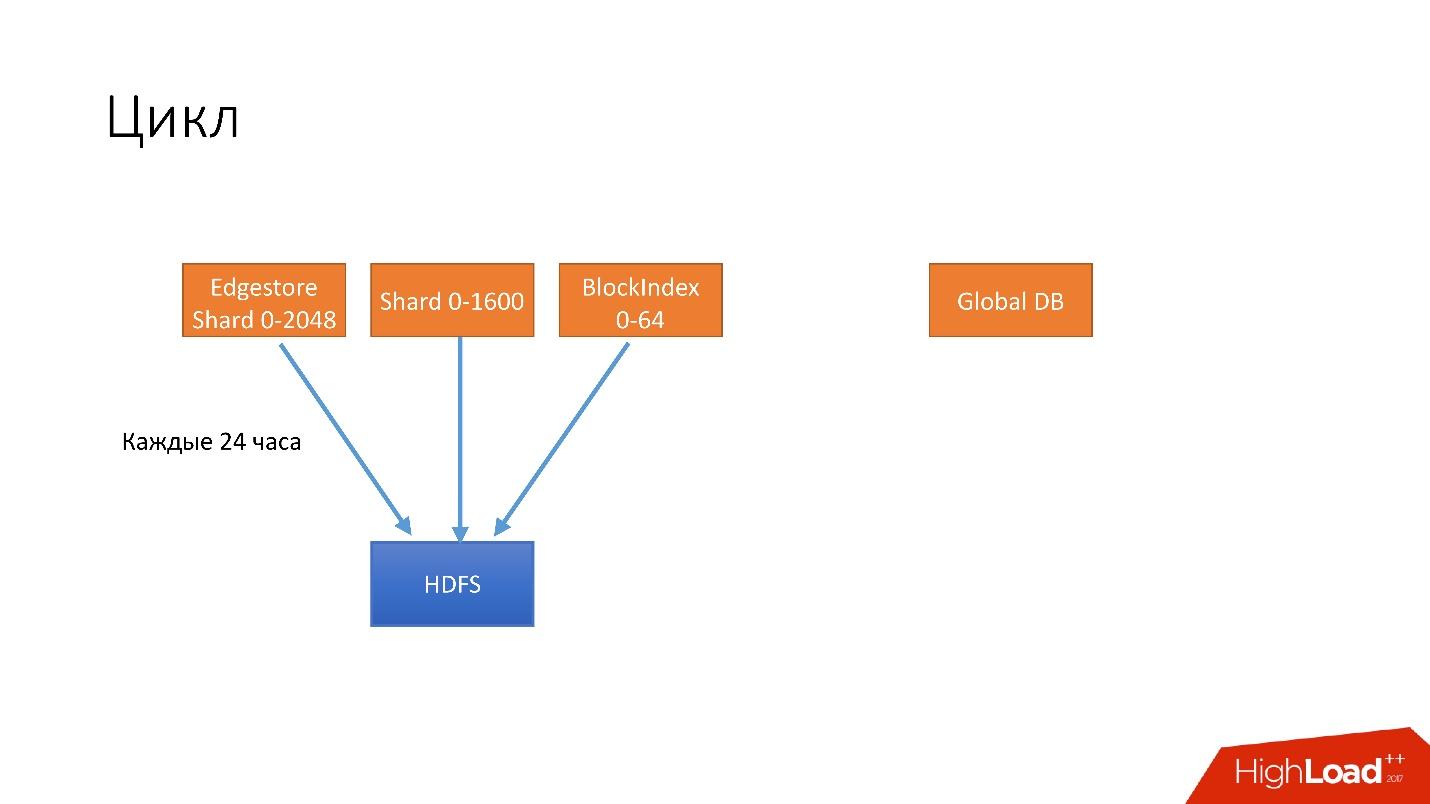
- 24 . HDFS, .
- 6 unsharded databases, Global DB. , , , .
- 3 S3.
- 3 S3 .

. , 3 , HDFS 3 , 6 S3. .
, .

, , . , , recovery - . , , - . 100 , .
, , , , , , , . .

hot-, Percona xtrabackup. —stream=xbstream, , . script-splitter, , .
MySQL 2x. 3 , , , 1 500 . , , HDFS S3.
.

, , HDFS S3, , splitter xtrabackup, . crash-recovery.
hot , crash-recovery . , . binlog, master.
binlogs?binlog'. master , 4 , 100 , HDFS.
: Binlog Backuper, . , , binlog HDFS.
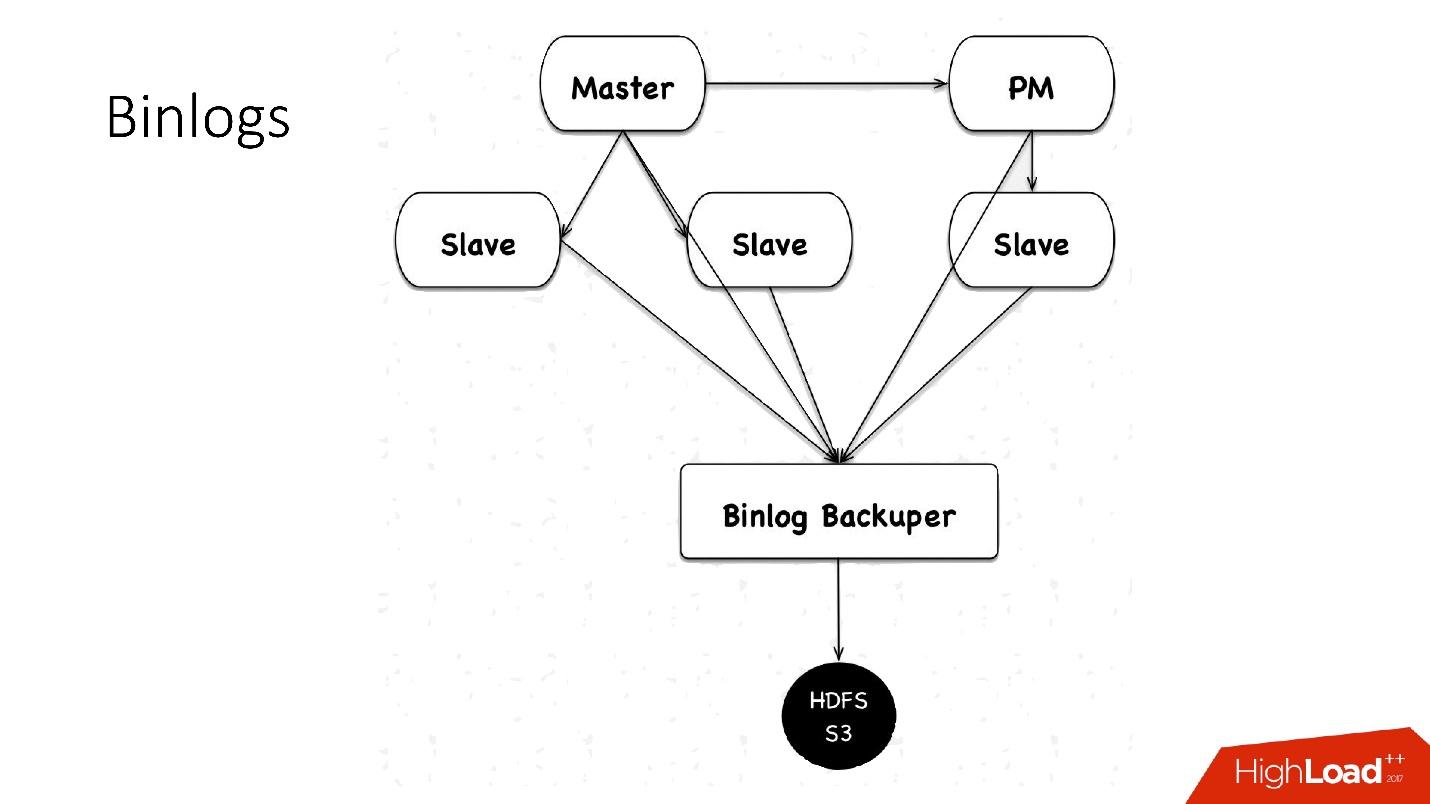
, 4 , 5 , , , . HDFS S3 .
.
:
- — 10 , 45 — .
- , scheduler multi instance slave master .
- — , . , , , , , , . pt-table-checksum , .
, :
- 1 10 , . crash-recovery, .
- .

slave -, . , . .
++
. Hardware , (HDD) 10 , + crash recovery xtrabackup, . , , . , , , , HDD , HDFS .
, — :
- ;
- .
, HDFS, , , .
Otomasi
, 6 000 . , , — :
- Auto-replace;
- DBManager;
- Naoru, Wheelhouse
Auto-replace
, , , , — , -. , .
Availability () — , . — recovery , .

MySQL , heartbeat. Heartbeat — timestamp.
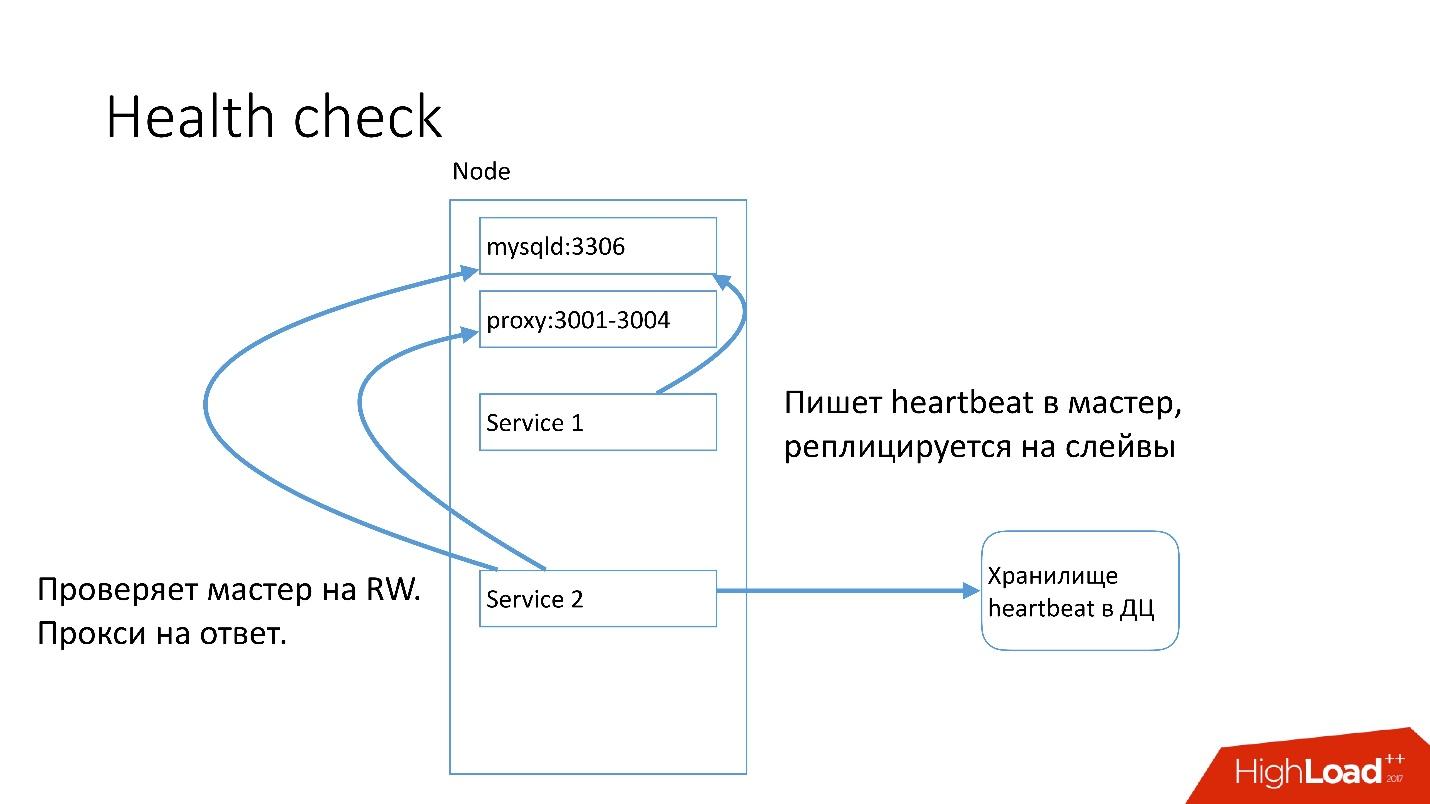
, , , master read-write. heartbeat.
auto-replace , .
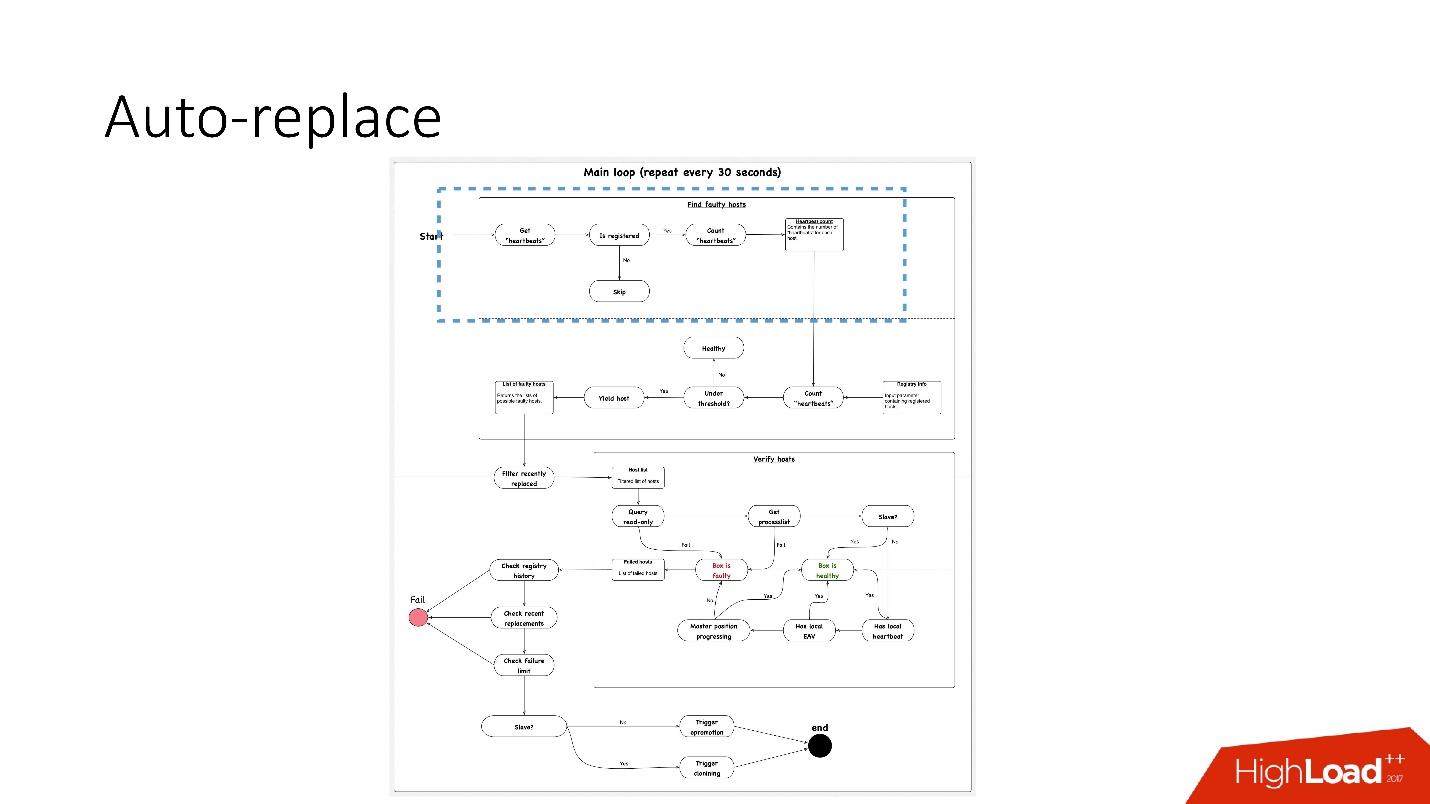 , 91 .?
, 91 .?- , heartbeat . , . heartbeat', , heartbeat' 30 .
- Selanjutnya, lihat apakah nomor mereka memenuhi nilai ambang batas. Jika tidak, maka ada sesuatu yang salah dengan server - karena tidak mengirim detak jantung.
- Setelah itu, kami melakukan pemeriksaan terbalik untuk berjaga-jaga - tiba-tiba kedua layanan ini mati, ada sesuatu dengan jaringan, atau database global tidak dapat menulis detak jantung karena suatu alasan. Dalam pemeriksaan terbalik, kami terhubung ke database yang rusak dan memeriksa statusnya.
- Jika semuanya gagal, kita melihat apakah posisi master sedang berkembang atau tidak, apakah ada catatan di sana. Jika tidak ada yang terjadi, maka server ini pasti tidak berfungsi.
- Langkah terakhir sebenarnya adalah penggantian otomatis.
Penggantian otomatis sangat konservatif, ia tidak pernah ingin melakukan banyak operasi otomatis.
- Pertama, kami memeriksa apakah ada operasi topologi baru-baru ini? Mungkin server ini baru saja ditambahkan dan sesuatu di dalamnya belum berjalan.
- Kami memeriksa untuk melihat apakah ada penggantian di cluster yang sama setiap saat.
- Periksa batas kegagalan apa yang kami miliki. Jika kita memiliki banyak masalah sekaligus - 10, 20 - maka kita tidak akan secara otomatis menyelesaikannya semua, karena kita dapat secara tidak sengaja mengganggu operasi semua basis data.
Karena itu, kami
hanya memecahkan satu masalah pada satu waktu .
Karenanya, untuk server slave, kami mulai mengkloning dan menghapusnya dari topologi, dan jika master, maka kami meluncurkan feylover, yang disebut promosi darurat.
DBManager
DBManager adalah layanan untuk mengelola basis data kami. Itu memiliki:
- penjadwal tugas pintar yang tahu persis kapan pekerjaan dimulai;
- log dan semua informasi: siapa, kapan dan apa yang diluncurkan - ini adalah sumber kebenaran;
- titik sinkronisasi.
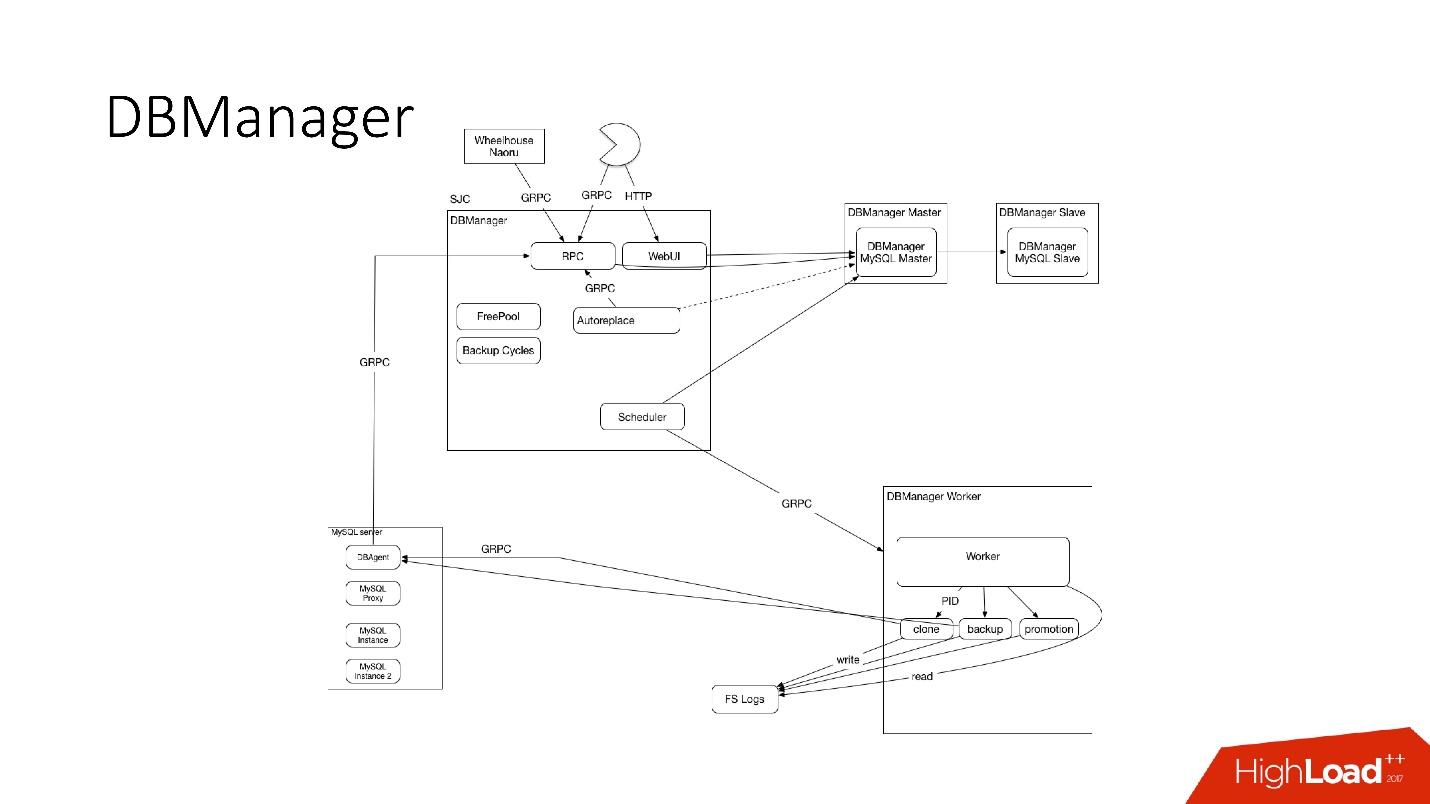
DBManager cukup sederhana secara arsitektur.
- Ada klien, baik DBA yang melakukan sesuatu melalui antarmuka web, atau skrip / layanan yang menulis DBA yang mengakses melalui gRPC.
- Ada sistem eksternal seperti Wheelhouse dan Naoru, yang masuk ke DBManager via gRPC.
- Ada penjadwal yang mengerti operasi apa, kapan dan di mana dia bisa memulai.
- Ada pekerja yang sangat bodoh yang, ketika operasi datang kepadanya, memulainya, memeriksa oleh PID. Pekerja dapat memulai kembali, proses tidak terganggu. Semua pekerja ditempatkan sedekat mungkin ke server tempat operasi berlangsung, sehingga, misalnya, saat memperbarui ACLS, kami tidak perlu melakukan banyak perjalanan bolak-balik.
- Pada setiap host SQL kami memiliki DBAgent - ini adalah server RPC. Ketika Anda perlu melakukan beberapa operasi di server, kami mengirim permintaan RPC.
Kami memiliki antarmuka web untuk DBManager, di mana Anda dapat melihat tugas yang sedang berjalan, log untuk tugas-tugas ini, siapa yang memulai dan kapan, operasi apa yang dilakukan untuk server dari database tertentu, dll.
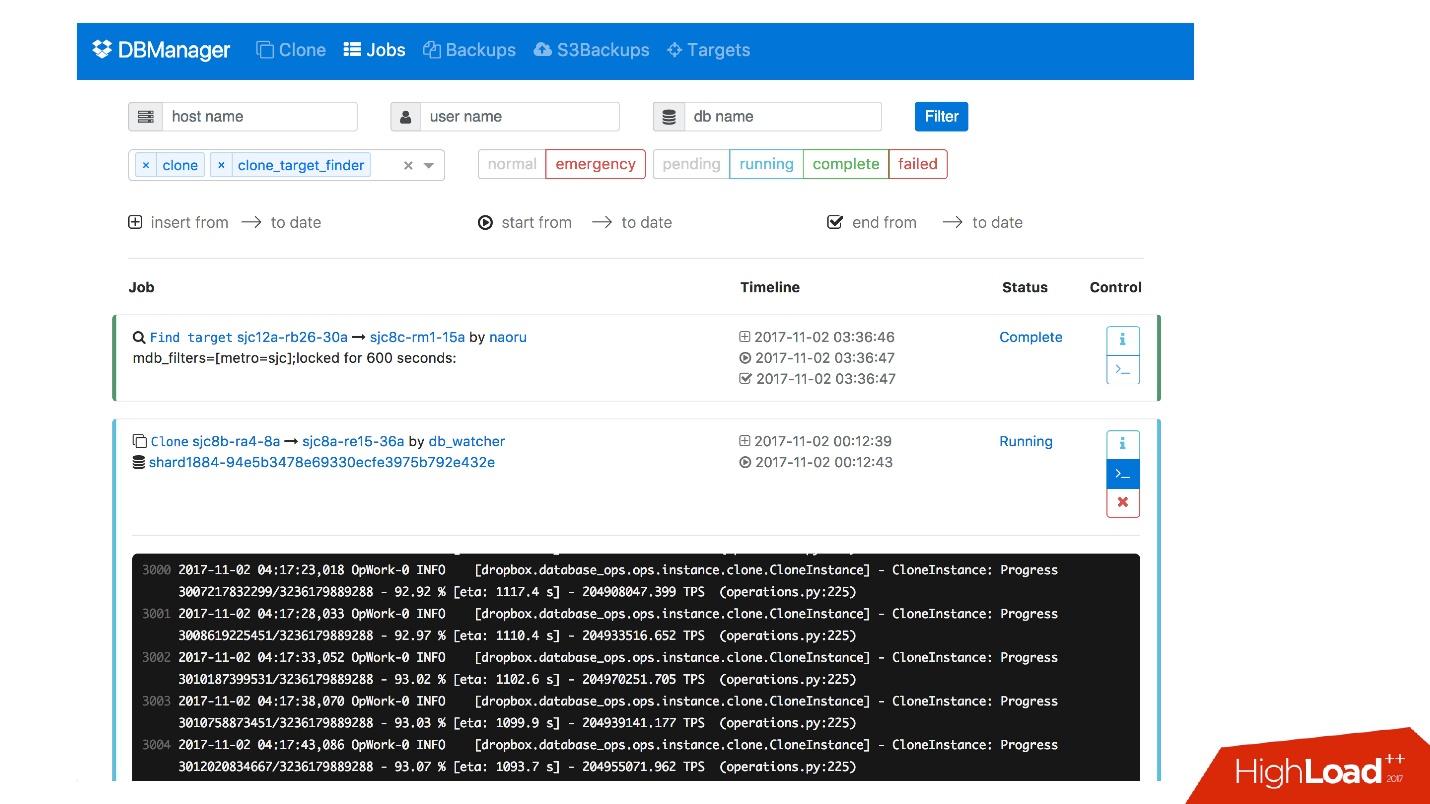
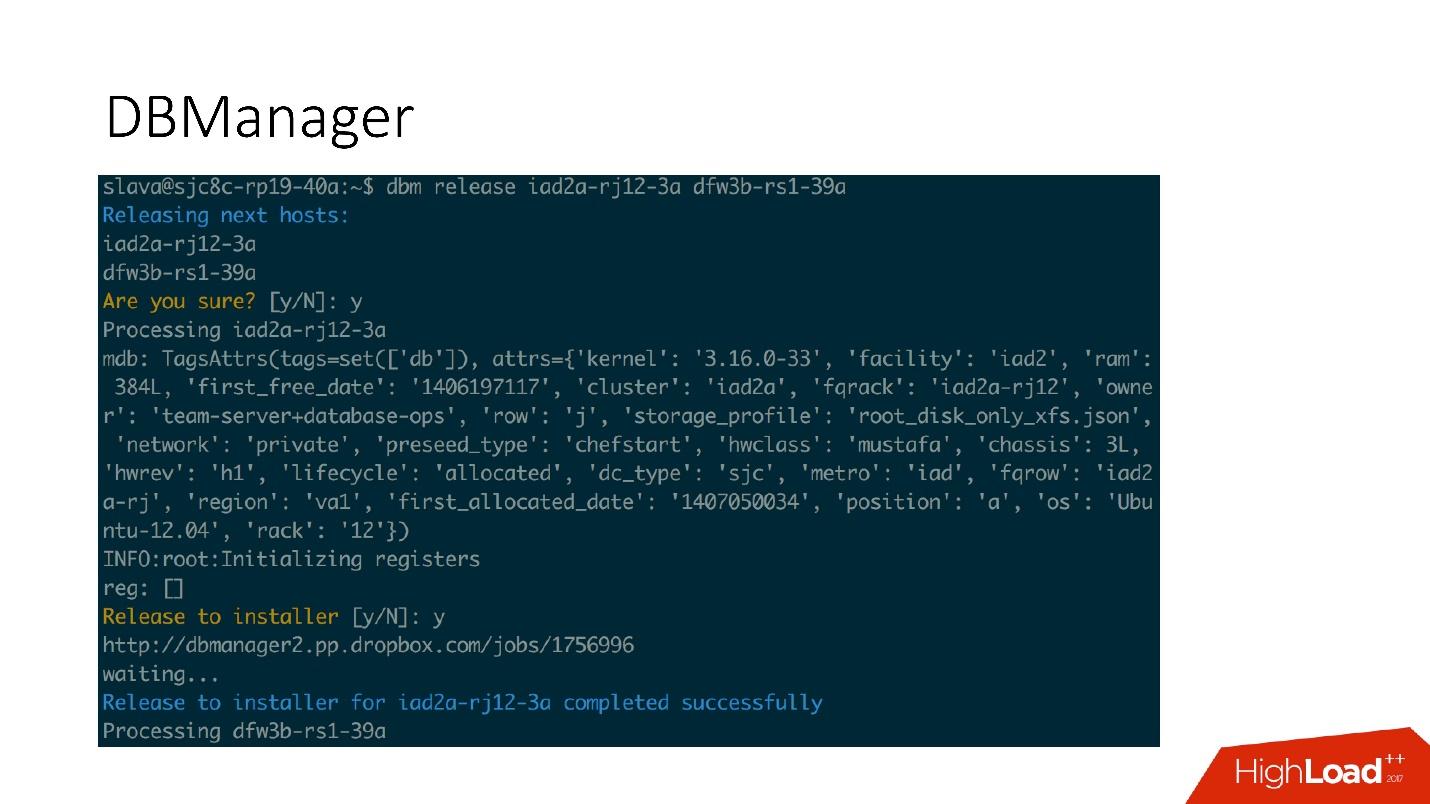
Ada antarmuka CLI yang cukup sederhana di mana Anda dapat menjalankan tugas dan juga melihatnya dalam tampilan yang nyaman.
Remediasi
Kami juga memiliki sistem untuk menanggapi masalah. Ketika ada sesuatu yang rusak, misalnya, drive macet, atau beberapa layanan tidak berfungsi,
Naoru berfungsi
. Ini adalah sistem yang bekerja di seluruh Dropbox, semua orang menggunakannya, dan ini dibuat khusus untuk tugas-tugas kecil seperti itu. Saya berbicara tentang Naoru dalam
laporan saya pada tahun 2016.
Wheelhouse didasarkan pada mesin
negara dan dirancang untuk proses panjang. Sebagai contoh, kita perlu memperbarui kernel pada semua MySQL di seluruh cluster kami dari 6.000 mesin. Wheelhouse melakukan ini dengan jelas - pembaruan di server slave, meluncurkan promosi, slave menjadi master, pembaruan di server master. Operasi ini dapat memakan waktu satu atau dua bulan.
Pemantauan

Ini sangat penting.
Jika Anda tidak memonitor sistem, maka kemungkinan besar itu tidak berfungsi.
Kami memantau semua yang ada di MySQL - semua informasi yang kami dapat dari MySQL disimpan di suatu tempat, kami dapat mengaksesnya tepat waktu. Kami menyimpan informasi tentang InnoDb, statistik permintaan, transaksi, panjang transaksi, persentasi panjang transaksi, replikasi, di jaringan - semuanya - semua metrik.
Peringatan
Kami memiliki 992 peringatan yang dikonfigurasi. Bahkan, tidak ada yang melihat metrik, bagi saya tampaknya tidak ada orang yang datang untuk bekerja dan mulai melihat grafik metrik, ada tugas yang lebih menarik.

Oleh karena itu, ada peringatan yang berfungsi saat nilai ambang tertentu tercapai.
Kami memiliki 992 peringatan, apa pun yang terjadi, kami akan mengetahuinya .
Insiden

Kami memiliki PagerDuty - layanan di mana peringatan dikirimkan kepada orang-orang yang bertanggung jawab yang mulai mengambil tindakan.

Dalam hal ini, terjadi kesalahan dalam promosi darurat, dan segera setelah itu peringatan dicatat bahwa master jatuh. Setelah itu, petugas jaga memeriksa apa yang mencegah promosi darurat, dan melakukan operasi manual yang diperlukan.
Kami pasti akan menganalisis setiap insiden yang telah terjadi, untuk setiap insiden kami memiliki tugas di pelacak tugas. Sekalipun insiden ini merupakan masalah di lansiran kami, kami juga membuat tugas, karena jika masalahnya ada dalam logika dan ambang lansiran, maka semua itu perlu diubah. Peringatan seharusnya tidak hanya merusak kehidupan orang. Peringatan selalu menyakitkan, terutama pada jam 4 pagi.
Pengujian
Seperti pemantauan, saya yakin semua orang menguji. Selain tes unit yang kami gunakan untuk menutupi kode kami, kami memiliki tes integrasi yang kami uji:
- semua topologi yang kita miliki;
- semua operasi pada topologi ini.
Jika kami memiliki operasi promosi, kami menguji operasi promosi dalam tes integrasi. Jika kita memiliki kloning, kita melakukan kloning untuk semua topologi yang kita miliki.
Contoh topologi
Kami memiliki topologi untuk semua kesempatan: 2 pusat data dengan multi instance, dengan pecahan, tanpa pecahan, dengan cluster, satu pusat data - umumnya hampir semua topologi - bahkan yang tidak kami gunakan, hanya untuk melihat.

Dalam file ini, kita hanya memiliki pengaturan, server mana dan dengan apa yang perlu kita tingkatkan. Sebagai contoh, kita perlu meningkatkan master, dan kita mengatakan bahwa kita perlu melakukan ini dengan data instance ini dan itu, dengan database ini dan itu pada port ini dan itu. Hampir semuanya berjalan bersama dengan Bazel, yang menciptakan topologi berdasarkan file-file ini, memulai server MySQL, dan kemudian pengujian dimulai.

Tes ini terlihat sangat sederhana: kami mengindikasikan topologi mana yang sedang digunakan. Dalam tes ini, kami menguji auto_replace.
- Kami membuat layanan auto_replace, kami memulainya.
- Kami membunuh master dalam topologi kami, menunggu sebentar dan melihat bahwa target-budak telah menjadi master. Jika tidak, maka tes gagal.
Tahapan
Lingkungan panggung adalah basis data yang sama dengan dalam produksi, tetapi tidak ada lalu lintas pengguna, tetapi ada beberapa lalu lintas sintetis yang mirip dengan produksi melalui Percona Playback, sysbench dan sistem serupa.
Di Percona Playback, kami merekam lalu lintas, lalu kehilangannya di lingkungan panggung dengan intensitas berbeda, kami bisa kehilangan 2-3 kali lebih cepat. Artinya, itu buatan, tetapi sangat dekat dengan beban nyata.
Ini diperlukan karena dalam pengujian integrasi kami tidak dapat menguji produksi kami. Kami tidak dapat menguji lansiran atau fakta bahwa metrik berfungsi. Pada tahap pengujian, kami menguji peringatan, metrik, operasi, secara berkala membunuh server dan melihat bahwa mereka dikumpulkan secara normal.
Plus, kami menguji semua otomatisasi bersama, karena dalam tes integrasi, kemungkinan besar, satu bagian dari sistem diuji, dan dalam pementasan, semua sistem otomatis bekerja secara bersamaan. Terkadang Anda berpikir bahwa sistem akan berperilaku seperti ini dan bukan sebaliknya, tetapi mungkin berperilaku dengan cara yang sama sekali berbeda.
DRT (Pengujian pemulihan bencana)
Kami juga melakukan pengujian dalam produksi - langsung dari basis nyata. Ini disebut pengujian pemulihan Bencana. Mengapa kita membutuhkan ini?
● Kami ingin menguji jaminan kami.
Ini dilakukan oleh banyak perusahaan besar. Misalnya, Google memiliki satu layanan yang bekerja sangat stabil - 100% dari waktu - bahwa semua layanan yang menggunakannya memutuskan bahwa layanan ini benar-benar 100% stabil dan tidak pernah macet. Karena itu, Google harus menjatuhkan layanan ini dengan sengaja, sehingga pengguna memperhitungkan kemungkinan ini.
Jadi kami - kami memiliki jaminan bahwa MySQL berfungsi - dan terkadang tidak berfungsi! Dan kami memiliki jaminan bahwa itu mungkin tidak berfungsi untuk jangka waktu tertentu, pelanggan harus mempertimbangkan ini. Dari waktu ke waktu, kami membunuh master produksi, atau jika kami ingin membuat faylover, kami membunuh semua budak untuk melihat bagaimana replikasi semisync berperilaku.
● Pelanggan siap untuk kesalahan ini (penggantian dan kematian master)
Kenapa itu bagus? Kami memiliki kasus ketika selama promosi 4 pecahan dari 1600, ketersediaan turun menjadi 20%. Tampaknya ada sesuatu yang salah, untuk 4 pecahan dari 1600 harus ada beberapa nomor lainnya. Kegagalan untuk sistem ini jarang terjadi, sekitar sebulan sekali, dan semua orang memutuskan: "Ya, itu failover, itu terjadi."
Pada titik tertentu, ketika kami beralih ke sistem baru, satu orang memutuskan untuk mengoptimalkan dua layanan perekaman detak jantung dan menggabungkannya menjadi satu. Layanan ini melakukan sesuatu yang lain dan, pada akhirnya, mati dan detak jantung berhenti merekam. Kebetulan untuk klien ini kami memiliki 8 faylovers sehari. Semuanya awam - ketersediaan 20%.
Ternyata dalam klien ini tetap hidup adalah 6 jam. Oleh karena itu, begitu master meninggal, kami memiliki semua koneksi ditahan selama 6 jam. Kolam tidak dapat terus bekerja - koneksinya tetap, terbatas dan tidak berfungsi. Itu diperbaiki.
Kami melakukan feylover lagi - tidak lagi 20%, tetapi masih banyak. Masih ada yang salah. Ternyata ada bug dalam implementasi pool. Ketika diminta, kolam berubah menjadi banyak pecahan, dan kemudian menghubungkan semua ini. Jika beberapa pecahan demam, beberapa kondisi lomba terjadi dalam kode Go, dan seluruh kolam tersumbat. Semua pecahan ini tidak bisa lagi berfungsi.
Pengujian pemulihan bencana sangat berguna, karena klien harus siap untuk kesalahan ini, mereka harus memeriksa kode mereka.
● Plus Pengujian pemulihan bencana bagus karena berlangsung selama jam kerja dan semuanya sudah ada, lebih sedikit stres, orang tahu apa yang akan terjadi sekarang. Ini tidak terjadi di malam hari, dan itu hebat.
Kesimpulan
1. Semuanya perlu diotomatisasi, jangan pernah mengalaminya.
Setiap kali seseorang naik ke sistem dengan tangan kita, semuanya mati dan rusak di sistem kita - setiap saat! - bahkan pada operasi sederhana. Misalnya, seorang budak meninggal, seseorang harus menambahkan yang kedua, tetapi memutuskan untuk menghapus budak yang mati dengan tangannya dari topologi. Namun, bukannya almarhum, ia menyalin ke perintah live - master dibiarkan tanpa budak sama sekali. Operasi semacam itu tidak boleh dilakukan secara manual.
2. Tes harus kontinu dan otomatis (dan dalam produksi).
Sistem Anda berubah, infrastruktur Anda berubah. Jika Anda memeriksanya sekali, dan sepertinya berhasil, ini tidak berarti itu akan berfungsi besok. Karena itu, Anda perlu terus melakukan pengujian otomatis setiap hari, termasuk dalam produksi.
3. Pastikan untuk memiliki klien (perpustakaan).
Pengguna mungkin tidak tahu cara kerja basis data. Mereka mungkin tidak mengerti mengapa waktu habis diperlukan, tetap hidup. Karena itu, lebih baik memiliki pelanggan ini - Anda akan lebih tenang.
4. Penting untuk menentukan prinsip Anda untuk membangun sistem dan jaminan Anda, dan selalu mematuhinya.
Dengan demikian, Anda dapat mendukung 6 ribu server database.
Dalam pertanyaan setelah laporan, dan terutama jawaban mereka, ada juga banyak informasi berguna.Tanya Jawab
- Apa yang akan terjadi jika ada ketidakseimbangan beban pecahan - beberapa informasi meta tentang beberapa file ternyata lebih populer? Apakah mungkin untuk meredakan pecahan ini, atau beban pada pecahan tidak berbeda di mana pun berdasarkan pesanan besarnya?
Dia tidak berbeda dengan urutan besarnya. Hampir terdistribusi secara normal. Kami memiliki pelambatan, yaitu, kami tidak dapat membebani pecahan sebenarnya, kami melambat di tingkat klien. Secara umum, beberapa bintang mengunggah foto, dan beling itu praktis meledak. Lalu kami melarang tautan ini
- Anda mengatakan Anda memiliki 992 peringatan. Bisakah Anda menguraikan apa itu - apakah di luar kotak atau itu dibuat? Jika dibuat, apakah itu kerja manual atau sesuatu seperti pembelajaran mesin?
Ini semua dibuat secara manual. Kami memiliki sistem internal kami sendiri yang disebut Vortex, tempat metrik disimpan, peringatan didukung di dalamnya. Ada file yaml yang mengatakan bahwa ada kondisi, misalnya, bahwa cadangan harus dijalankan setiap hari, dan jika kondisi ini terpenuhi, peringatan tidak berfungsi. Jika tidak dieksekusi, maka peringatan datang.
Ini adalah pengembangan internal kami, karena hanya sedikit orang yang dapat menyimpan metrik sebanyak yang kami butuhkan.
- Seberapa kuat saraf untuk melakukan DRT? Anda jatuh, TERKENAL, tidak naik, dengan setiap menit lebih banyak panik.
Secara umum, bekerja di basis data benar-benar menyebalkan. Jika database macet, layanan tidak berfungsi, seluruh Dropbox tidak berfungsi. Ini adalah rasa sakit yang nyata. DRT berguna karena merupakan jam tangan bisnis. Yaitu, saya siap, saya duduk di meja saya, saya minum kopi, saya segar, saya siap untuk melakukan apa saja.
Lebih buruk ketika itu terjadi pukul 4 pagi, dan itu bukan DRT. Misalnya, kegagalan besar terakhir yang kami alami baru-baru ini. Saat menyuntikkan sistem baru, kami lupa mengatur Skor OOM untuk MySQL kami. Ada layanan lain yang membaca binlog. Pada titik tertentu, operator kami adalah manual - lagi secara manual! - menjalankan perintah untuk menghapus beberapa informasi dalam tabel checksum Percona. Hanya penghapusan sederhana, operasi sederhana, tetapi operasi ini menghasilkan binlog yang sangat besar. Layanan membaca binlog ini ke dalam memori, OOM Killer datang dan berpikir siapa yang harus dibunuh? Dan kami lupa mengatur Skor OOM, dan itu membunuh MySQL!
Kami memiliki 40 master sekarat pukul 4 pagi. Ketika 40 master mati, itu benar-benar sangat menakutkan dan berbahaya. DRT tidak menakutkan dan tidak berbahaya. Kami berbaring sekitar satu jam.
Ngomong-ngomong, DRT adalah cara yang baik untuk melatih saat-saat seperti itu sehingga kita tahu persis urutan tindakan yang diperlukan jika sesuatu rusak secara massal.
- Saya ingin belajar lebih banyak tentang beralih master-master. Pertama, mengapa sebuah cluster tidak digunakan, misalnya? Cluster database, yaitu, bukan master-slave dengan switching, tetapi aplikasi master-master, sehingga jika ada yang jatuh, maka itu tidak menakutkan.
Apakah maksud Anda seperti replikasi grup, galera cluster, dll? Sepertinya saya bahwa aplikasi grup belum siap seumur hidup. Sayangnya, kami belum mencoba Galera. Ini bagus ketika faylover ada di dalam protokol Anda, tetapi, sayangnya, mereka memiliki banyak masalah lain, dan tidak mudah untuk beralih ke solusi ini.
- Tampaknya di MySQL 8 ada sesuatu seperti InnoDb cluster. Tidak mencoba?
Kami masih memiliki nilai 5,6. Saya tidak tahu kapan kami akan beralih ke 8. Mungkin kami akan mencoba.
- Dalam hal ini, jika Anda memiliki satu master besar, ketika berpindah dari satu master ke master lainnya, ternyata antriannya terakumulasi di server slave dengan beban tinggi. Jika master dipadamkan, apakah perlu untuk mencapai antrian, sehingga budak beralih ke mode master - atau apakah dilakukan dengan cara yang berbeda?
Beban pada master diatur oleh semisync. Semisync membatasi rekaman master ke kinerja server slave. Tentu saja, mungkin transaksi itu datang, semisync berhasil, tetapi para budak kehilangan transaksi ini untuk waktu yang sangat lama. Anda kemudian harus menunggu sampai budak kehilangan transaksi ini sampai akhir.
- Tapi kemudian data baru akan datang untuk dikuasai, dan itu akan diperlukan ...
Ketika kami memulai proses promosi, kami menonaktifkan I / O. Setelah itu, master tidak dapat menulis apa pun karena semisync direplikasi. Pembacaan hantu mungkin datang, sayangnya, tetapi ini sudah merupakan masalah lain.
- Ini semua mesin negara yang indah - skrip apa yang ditulis dan seberapa sulit untuk menambahkan langkah baru? Apa yang perlu dilakukan untuk orang yang menulis sistem ini?
Semua skrip ditulis dengan Python, semua layanan ditulis dalam Go. Ini adalah kebijakan kami. Mengubah logika itu mudah - cukup dengan kode Python yang menghasilkan diagram keadaan.
- Dan Anda dapat membaca lebih lanjut tentang pengujian. Bagaimana tes ditulis, bagaimana mereka menggunakan node dalam mesin virtual - apakah ini wadah?
Ya Kami akan menguji dengan bantuan Bazel. Ada beberapa file konfigurasi (json) dan Bazel mengambil skrip yang menciptakan topologi untuk pengujian kami menggunakan file konfigurasi ini. Topologi yang berbeda dijelaskan di sana.
Itu semua bekerja untuk kita dalam wadah buruh pelabuhan: baik itu bekerja di CI atau di Devbox. Kami memiliki sistem Devbox. Kita semua berkembang di beberapa server jarak jauh, dan ini dapat bekerja di dalamnya, misalnya. Di sana juga berjalan di dalam Bazel, di dalam wadah buruh pelabuhan atau di Bazel Sandbox. Bazel sangat rumit tapi menyenangkan.
- Ketika Anda membuat 4 instance pada satu server, apakah Anda kehilangan efisiensi memori?
Setiap instance menjadi lebih kecil. Dengan demikian, semakin sedikit memori yang beroperasi dengan MySQL, semakin mudah untuk hidup. Sistem apa pun lebih mudah dioperasikan dengan sedikit memori. Di tempat ini, kami tidak kehilangan apapun. Kami memiliki grup C paling sederhana yang membatasi instance ini dari memori.
- Jika Anda memiliki 6.000 server yang menyimpan basis data, dapatkah Anda menyebutkan berapa miliar petabyte yang disimpan dalam file Anda?
Ini adalah puluhan exabytes, kami menuangkan data dari Amazon selama setahun.
- Ternyata pada awalnya Anda memiliki 8 server, 200 pecahan pada mereka, kemudian 400 server dengan 4 pecahan masing-masing. Anda memiliki 1600 pecahan - apakah ini semacam nilai hard-coded? Bisakah kamu tidak melakukannya lagi? Apakah akan sakit jika Anda membutuhkan, misalnya, 3.200 pecahan?
Ya, ini awalnya 1600. Ini dilakukan kurang dari 10 tahun yang lalu, dan kami masih hidup. Tapi kami masih memiliki 4 pecahan - 4 kali kami masih bisa menambah ruang.
- Bagaimana server mati, terutama karena alasan apa? Apa yang terjadi lebih sering, lebih jarang, dan yang sangat menarik, apakah blok spontan terjadi?
Yang paling penting adalah bahwa disk terbang keluar. Kami memiliki RAID 0 - disk macet, master meninggal. Ini adalah masalah utama, tetapi lebih mudah bagi kami untuk mengganti server ini. Google lebih mudah untuk mengganti pusat data, kami masih memiliki server. Kami hampir tidak pernah memiliki checksum Korupsi. Sejujurnya, saya tidak ingat kapan terakhir kali. Kami hanya sering memperbarui wizard. Waktu hidup kami untuk satu master terbatas hingga 60 hari. Itu tidak bisa hidup lebih lama, setelah itu kami menggantinya dengan server baru, karena untuk beberapa alasan sesuatu terus-menerus terakumulasi di MySQL, dan setelah 60 hari kami melihat bahwa masalah mulai terjadi. Mungkin tidak di MySQL, mungkin di Linux.
, . 60 , . .
— , 6 . , JPEG , JPEG, , ? , , - ? — , ?
, . — Dropbox .
— ? ? , , - , , ? , 10 . , 7 , 6 , . ?
Dropbox - , . . , , , - .
, . , , , . - , 6 , , , , .
, facebook youtube- — Highload++ 2018 . , 1 .