
Kami di departemen analitik sinema daring Okko senang mengotomatiskan perhitungan biaya film Alexander Nevsky sebanyak mungkin, dan di waktu luang untuk mempelajari hal-hal baru dan menerapkan hal-hal keren yang karena alasan tertentu biasanya diterjemahkan menjadi bot untuk Telegram. Misalnya, sebelum dimulainya Piala Dunia FIFA 2018, kami meluncurkan bot untuk obrolan yang berfungsi, yang mengumpulkan taruhan pada distribusi tempat terakhir, dan setelah final, kami menghitung hasil berdasarkan metrik yang telah ditemukan sebelumnya dan menentukan pemenang. Kroasia belum menempatkan empat di empat besar.
Waktu luang terakhir dari menyusun komedi TOP-10 Rusia yang kami persembahkan untuk membuat bot yang menemukan selebriti yang paling mirip dengan pengguna. Dalam obrolan yang berhasil, semua orang sangat menghargai gagasan itu sehingga kami memutuskan untuk membuat bot tersedia untuk umum. Pada artikel ini, kami mengingat teori secara singkat, berbicara tentang pembuatan bot kami dan bagaimana melakukannya sendiri.
Sedikit teori (kebanyakan dalam gambar)
Secara rinci tentang bagaimana sistem pengenalan wajah diatur, saya bicarakan di salah satu artikel saya sebelumnya . Pembaca yang tertarik dapat mengikuti tautan, dan saya akan menguraikan di bawah ini hanya poin utama.
Jadi, Anda memiliki foto di mana, mungkin, bahkan wajah ditampilkan dan Anda ingin memahami siapa itu. Untuk melakukan ini, Anda harus mengikuti 4 langkah sederhana:
- Pilih persegi panjang yang membatasi wajah.
- Sorot titik-titik kunci wajah.
- Sejajarkan dan potong wajah Anda.
- Ubah gambar wajah menjadi representasi yang diinterpretasikan dengan mesin.
- Bandingkan tampilan ini dengan yang lain yang Anda miliki.
Seleksi wajah
Meskipun jaringan saraf convolutional baru-baru ini belajar bagaimana menemukan wajah dalam gambar tidak lebih buruk dari metode klasik, mereka masih kalah dengan HOG klasik dalam kecepatan dan kemudahan penggunaan.
HOG - Histogram Gradien Berorientasi. Orang ini mengaitkan setiap piksel dari gambar sumber dengan gradiennya - vektor ke arah yang paling banyak mengubah kecerahan piksel. Keuntungan dari pendekatan ini adalah bahwa ia tidak peduli dengan nilai absolut dari kecerahan piksel, hanya rasio mereka cukup. Oleh karena itu, wajah normal, dan gelap, dan kurang terang, dan berisik akan ditampilkan dalam kira-kira histogram gradien yang sama.
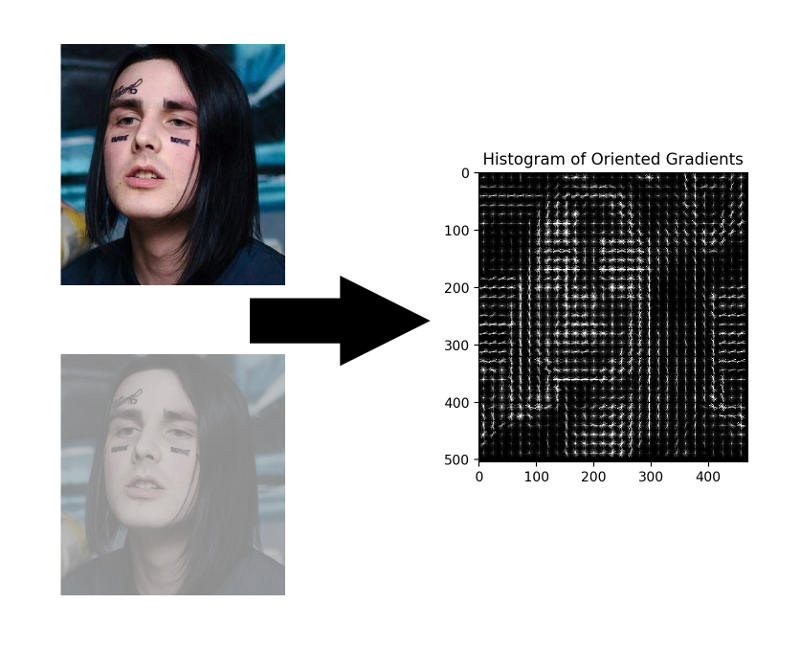
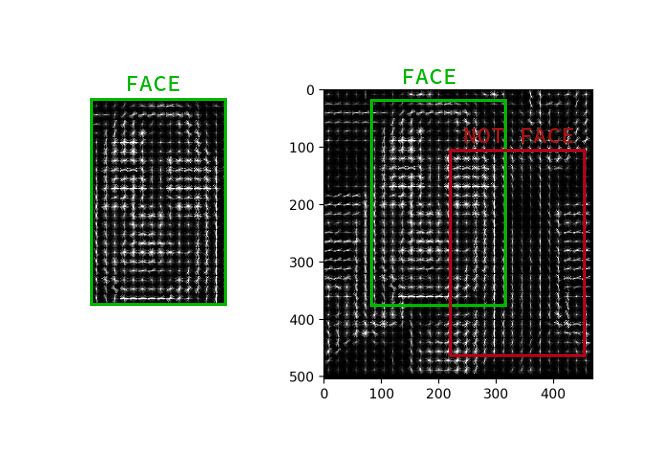
Tidak perlu menghitung gradien untuk setiap piksel, cukup untuk menghitung gradien rata-rata untuk setiap kotak kecil n oleh n . Menggunakan bidang vektor yang diterima, Anda kemudian dapat pergi melalui beberapa detektor dengan jendela dan menentukan untuk setiap jendela seberapa besar kemungkinan wajah di dalamnya. Detektor dapat berupa SVM, hutan acak, atau apa pun.
Sorot Poin-Poin Utama

Poin kunci adalah poin yang membantu mengidentifikasi seseorang di luar angkasa. Lemah dan tidak aman Para ilmuwan biasanya membutuhkan 68 poin utama, dan terutama dalam kasus yang diabaikan, bahkan lebih. Anak laki-laki normal dan percaya diri, berpenghasilan 300rb per detik, selalu punya cukup lima: sudut dalam dan luar mata dan hidung.
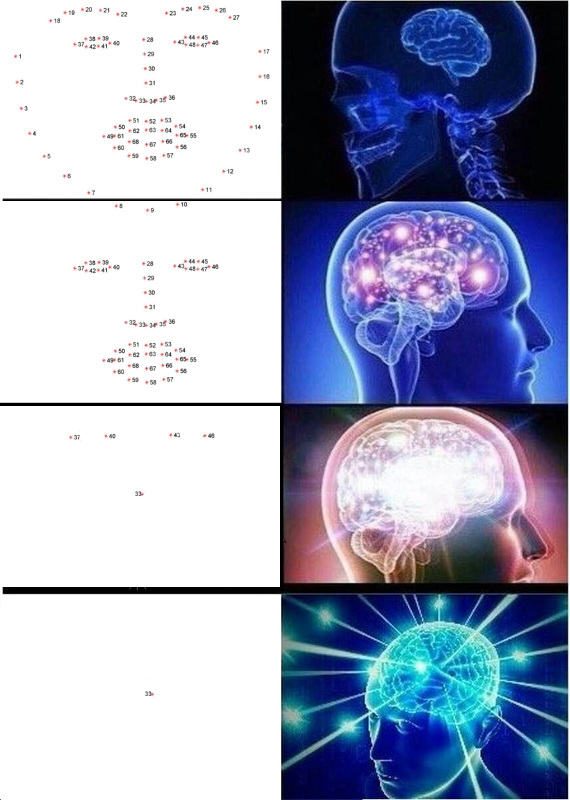
Poin-poin seperti itu dapat diekstraksi, misalnya, dengan kaskade regressor .
Perataan wajah
Aplikasi terpaku di masa kecil? Di sini semuanya persis sama: Anda membangun transformasi affine yang menerjemahkan tiga titik arbitrer ke posisi standar mereka. Hidung bisa dibiarkan apa adanya, tetapi agar mata menghitung pusatnya - ini adalah tiga poin yang siap.

Ubah gambar wajah menjadi vektor

Tiga tahun telah berlalu sejak penerbitan artikel tentang FaceNet , selama ini banyak skema pelatihan yang menarik dan fungsi kerugian muncul, tetapi dialah yang mendominasi di antara solusi OpenSource yang tersedia. Tampaknya, semuanya adalah kombinasi dari kemudahan pemahaman, implementasi dan hasil yang layak. Terima kasih setidaknya untuk fakta bahwa selama tiga tahun terakhir arsitektur telah diubah menjadi ResNet.
FaceNet belajar dari tiga kali lipat contoh: (jangkar, positif, negatif). Anchor dan contoh positif adalah milik satu orang, sedangkan negatif dipilih sebagai wajah orang lain, yang karena beberapa alasan jaringan terlalu dekat dengan yang pertama. Fungsi kerugian dirancang sedemikian rupa untuk memperbaiki kesalahpahaman ini, menyatukan contoh-contoh yang diperlukan dan memindahkan yang tidak perlu dari mereka.

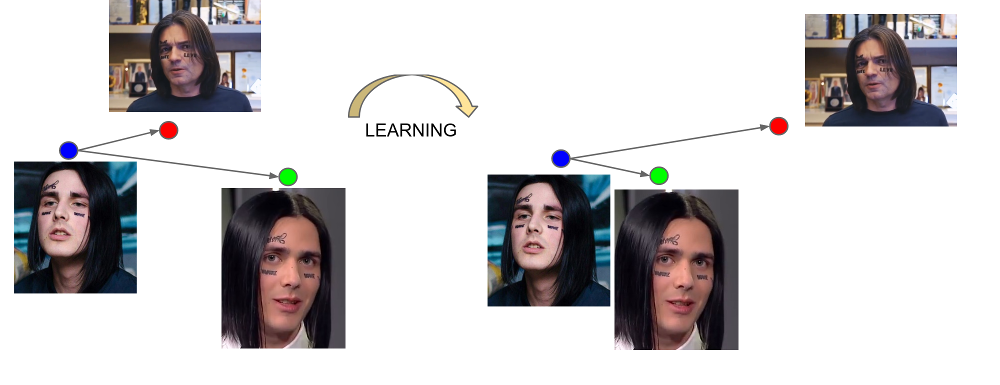
Output dari lapisan terakhir dari jaringan disebut embedding - representasi representatif dari seseorang dalam ruang tertentu dari dimensi kecil (biasanya 128 dimensi).
Perbandingan wajah
Keindahan embeddings terlatih adalah bahwa wajah satu orang ditampilkan di beberapa lingkungan kecil ruang, jauh dari embed wajah orang lain. Jadi, untuk ruang ini Anda dapat memasukkan ukuran kesamaan, kebalikan dari jarak: Euclidean atau cosinus, tergantung pada jarak yang dilatih jaringan.
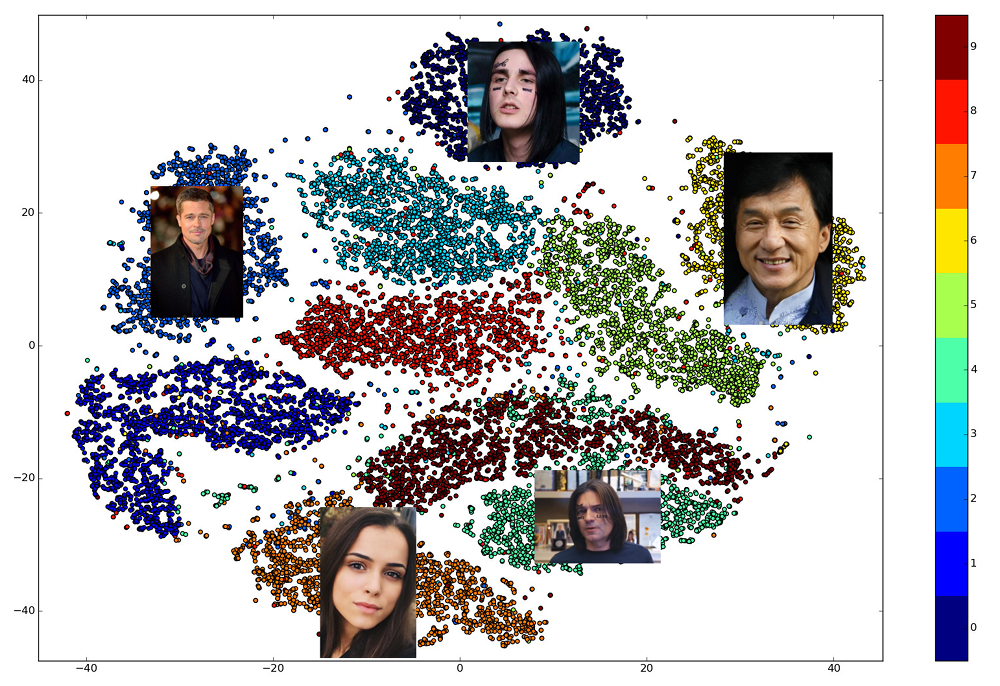
Jadi, sebelumnya kita perlu membuat embed untuk semua orang di antaranya pencarian akan dilakukan, dan kemudian, untuk setiap permintaan, temukan vektor terdekat di antara mereka. Atau, dengan cara lain, selesaikan masalah menemukan k tetangga terdekat, di mana k mungkin sama dengan satu, atau mungkin tidak, jika kita ingin menggunakan beberapa logika bisnis yang lebih maju. Orang yang memiliki vektor hasil akan paling mirip dengan orang yang meminta.

Perpustakaan mana yang digunakan?
Pilihan perpustakaan terbuka yang menerapkan berbagai bagian pipa sangat bagus. dlib dan OpenCV dapat menemukan wajah dan titik kunci, dan versi jaringan yang sudah dilatih sebelumnya dapat ditemukan untuk kerangka kerja jaringan saraf besar. Ada proyek OpenFace di mana Anda dapat memilih arsitektur untuk kebutuhan kecepatan dan kualitas Anda. Tetapi hanya satu perpustakaan yang memungkinkan Anda untuk menerapkan semua 5 poin pengenalan wajah dalam panggilan ke tiga fungsi tingkat tinggi: dlib . Pada saat yang sama, ini ditulis dalam C ++ modern, menggunakan BLAS, memiliki pembungkus untuk Python, tidak memerlukan GPU, dan bekerja cukup cepat pada CPU. Pilihan kita jatuh padanya.
Membuat bot Anda sendiri
Bagian ini telah dijelaskan dalam setiap panduan untuk membuat bot, tetapi setelah kami menulisnya, kami harus mengulanginya. Kami menulis @BotFather dan meminta tanda untuk bot baru kami.
643075690:AAFC8ola8WRdhGbJtzjmkOhne1FGfu1BFg terlihat seperti ini: 643075690:AAFC8ola8WRdhGbJtzjmkOhne1FGfu1BFg . Diperlukan otorisasi pada setiap permintaan ke API bot Telegram.
Saya harap tidak ada seorang pun di tahap ini yang memiliki keraguan ketika memilih bahasa pemrograman. Tentu saja, Anda harus menulis di Haskell. Mari kita mulai dengan modul utama.
import System.Process main :: IO () main = do (_, _, _, handle) <- createProcess (shell "python bot.py") _ <- waitForProcess handle putStrLn "Done!"
Seperti yang dapat Anda lihat dari kode, di masa depan kita akan menggunakan DSL khusus untuk menulis bot telegram. Kode pada DSL ini ditulis dalam file terpisah. Instal bahasa domain dan semua yang diperlukan.
python -m venv .env source .env/bin/activate pip install python-telegram-bot
python-telegram-bot saat ini merupakan kerangka kerja yang paling nyaman untuk membuat bot. Mudah dipelajari, fleksibel, dapat diskalakan, mendukung multithreading. Sayangnya, saat ini tidak ada kerangka asinkron normal tunggal dan utas kuno harus digunakan sebagai pengganti coroutine ilahi.

Memulai bot dengan python-telegram-bot mudah. Tambahkan kode berikut ke bot.py
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
Jalankan bot. Untuk keperluan debugging, ini bisa dilakukan dengan perintah python bot.py tanpa menjalankan kode Haskell.
Bot sederhana semacam itu mampu mempertahankan percakapan minimum, dan karenanya, dapat dengan mudah diatur untuk berfungsi sebagai pengembang front-end.
Tetapi ujung depan pengembang sudah terlalu banyak, jadi kami akan membunuhnya sesegera mungkin dan melanjutkan untuk mengimplementasikan fungsi utama. Demi kesederhanaan, bot kami hanya akan membalas pesan yang berisi foto dan mengabaikan yang lainnya. Ubah kode menjadi yang berikut.
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
Ketika gambar memasuki server Telegram, gambar itu secara otomatis disesuaikan ke beberapa ukuran yang telah ditentukan. Bot, pada gilirannya, dapat mengunduh gambar dalam berbagai ukuran dari yang ada di daftar message.photo diurutkan dalam urutan menaik. Opsi termudah: ambil gambar terbesar. Tentu saja, di lingkungan toko bahan makanan, Anda perlu memikirkan tentang beban jaringan dan waktu muat serta memilih gambar dengan ukuran minimum yang sesuai. Tambahkan kode unduhan gambar ke bagian atas fungsi handle_photo .
import io
message = update.message photo = message.photo[~0] with io.BytesIO() as fd: file_id = bot.get_file(photo.file_id) file_id.download(out=fd) fd.seek(0)
Gambar telah diunduh dan ada di memori. Untuk menafsirkannya dan menyajikannya dalam bentuk matriks intensitas piksel, kami menggunakan perpustakaan Pillow dan numpy .
from PIL import Image import numpy as np
Kode berikut perlu ditambahkan ke blok with .
image = Image.open(fd) image.load() image = np.asarray(image)
Waktunya telah tiba dlib. Di luar fungsinya, buat pendeteksi wajah.
import dlib
face_detector = dlib.get_frontal_face_detector()
Dan di dalam fungsi kita menggunakannya.
face_detects = face_detector(image, 1)
Parameter kedua dari fungsi berarti perbesaran yang harus diterapkan sebelum mencoba untuk mendeteksi wajah. Semakin besar, semakin kecil dan kompleks wajah detektor akan dapat dideteksi, tetapi semakin lama akan berfungsi. face_detects - daftar wajah yang diurutkan dalam urutan menurun dari kepercayaan detektor bahwa wajah ada di depannya. Dalam aplikasi nyata, Anda kemungkinan besar akan ingin menerapkan beberapa logika memilih orang utama, dan dalam studi kasus kami akan membatasi diri untuk memilih yang pertama.
if not face_detects: bot.send_message(chat_id=update.message.chat_id, text='no faces') face = face_detects[0]
Kami melanjutkan ke tahap berikutnya - mencari poin-poin penting. Unduh model yang terlatih dan pindahkan muatannya ke luar fungsi.
shape_predictor = dlib.shape_predictor('path/to/shape_predictor_5_face_landmarks.dat')
Temukan poin kunci.
landmarks = shape_predictor(image, face)
Satu-satunya yang tersisa adalah kecil: untuk meluruskan wajah, mengendarainya melalui ResNet dan mendapatkan embedding 128 dimensi. Untungnya, dlib memungkinkan Anda melakukan semua ini dengan satu panggilan. Anda hanya perlu mengunduh model pra-terlatih .
face_recognition_model = dlib.face_recognition_model_v1('path/to/dlib_face_recognition_resnet_model_v1.dat')
embedding = face_recognition_model.compute_face_descriptor(image, landmarks) embedding = np.asarray(embedding)
Lihat saja betapa indahnya waktu kita hidup. Seluruh kerumitan jaringan saraf convolutional, metode vektor dukungan, dan transformasi affine yang diterapkan untuk pengenalan wajah dirangkum dalam tiga panggilan perpustakaan.
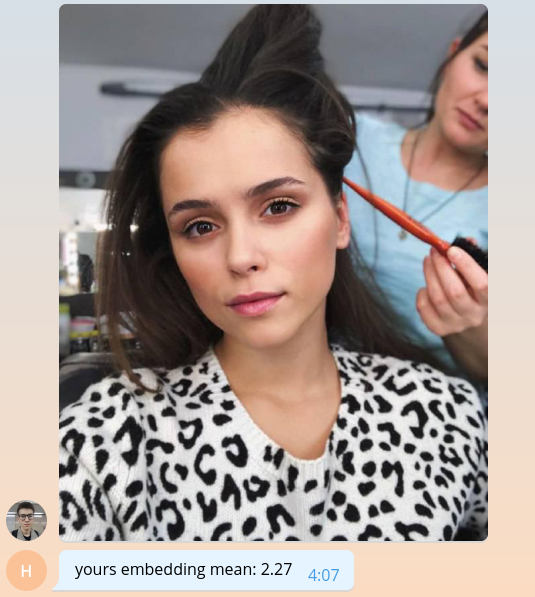
Karena kita belum tahu bagaimana melakukan sesuatu yang berarti, mari kembali kepada pengguna nilai rata-rata penanamannya, dikalikan dengan seribu.
bot.send_message( chat_id=update.message.chat_id, text=f'yours embedding mean: {embedding.mean() * 1e3:.2f}' )
Agar bot kami dapat menentukan selebriti mana yang disukai pengguna, kami sekarang perlu menemukan setidaknya satu foto dari setiap selebriti, membuat embedding di atasnya dan menyimpannya di suatu tempat. Kami hanya akan menambahkan 10 selebritas ke bot pelatihan kami, menemukan foto-foto mereka dengan tangan dan meletakkannya di direktori photos . Seperti inilah seharusnya tampilannya:
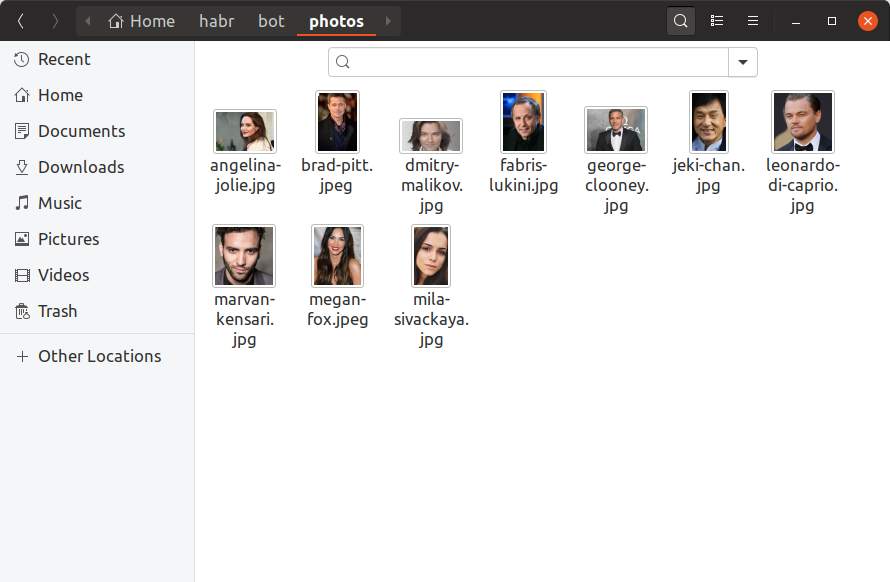
Jika Anda ingin memiliki satu juta selebritas dalam basis data, semuanya akan terlihat sama persis, hanya ada lebih banyak file dan tidak mungkin Anda bisa mencarinya dengan tangan Anda. Sekarang mari kita buat utilitas build_embeddings.py menggunakan panggilan dlib sudah kita ketahui dan menyimpan embeddings selebriti beserta nama mereka dalam format biner.
import os import dlib import numpy as np import pickle from PIL import Image face_detector = dlib.get_frontal_face_detector() shape_predictor = dlib.shape_predictor('assets/shape_predictor_5_face_landmarks.dat') face_recognition_model = dlib.face_recognition_model_v1('assets/dlib_face_recognition_resnet_model_v1.dat') fs = os.listdir('photos') es = [] for f in fs: print(f) image = np.asarray(Image.open(os.path.join('photos', f))) face_detects = face_detector(image, 1) face = face_detects[0] landmarks = shape_predictor(image, face) embedding = face_recognition_model.compute_face_descriptor(image, landmarks, num_jitters=10) embedding = np.asarray(embedding) name, _ = os.path.splitext(f) es.append((name, embedding)) with open('assets/embeddings.pickle', 'wb') as f: pickle.dump(es, f)
Tambahkan pemuatan sematan ke kode bot kami.
import pickle
with open('assets/embeddings.pickle', 'rb') as f: star_embeddings = pickle.load(f)
Dan dengan pencarian lengkap kami akan menemukan siapa pengguna kami yang sama.
ds = [] for name, emb in star_embeddings: distance = np.linalg.norm(embedding - emb) ds.append((name, distance)) best_match, best_distance = min(ds, key=itemgetter(1)) bot.send_message( chat_id=update.message.chat_id, text=f'your look exactly like *{best_match}*', parse_mode='Markdown' )
Harap dicatat bahwa kami menggunakan jarak Euclidean sebagai jarak, karena jaringan di dlib dilatih dengan tepat dengan bantuannya.

Itu saja, selamat! Kami telah membuat bot sederhana yang dapat menentukan selebriti yang disukai pengguna. Tetap menemukan lebih banyak foto, menambahkan branding, skalabilitas, sedikit logging dan semuanya dapat dirilis dalam produksi. Semua topik ini terlalu tebal untuk dibicarakan secara rinci dengan daftar kode besar, jadi saya hanya akan menguraikan poin utama dalam format tanya jawab di bagian berikutnya.
Kode bot pelatihan lengkap tersedia di GitHub .
Kami berbicara tentang bot kami
Berapa banyak selebriti yang Anda miliki di basis data Anda? Di mana Anda menemukannya?
Keputusan paling logis saat membuat bot sepertinya mengambil data selebritas dari basis konten internal kami. Dia dalam format grafik menyimpan film dan semua entitas yang terkait dengan film, termasuk aktor dan sutradara. Untuk setiap orang, kami tahu namanya, login dan kata sandi dari iCloud, film terkait dan alias, yang dapat digunakan untuk menghasilkan tautan ke situs. Setelah membersihkan dan mengekstraksi hanya informasi yang diperlukan, file json tetap sebagai berikut:
[ { "name": " ", "alias": "tilda-swinton", "role": "actor", "n_movies": 14 }, { "name": " ", "alias": "michael-shannon", "role": "actor", "n_movies": 22 }, ... ]
Ada 22.000 entri seperti itu di katalog. Ngomong-ngomong, bukan katalog, tapi katalog.
Di mana menemukan foto untuk semua orang ini?

Ya, Anda tahu, di sana-sini . Misalnya, ada perpustakaan yang luar biasa yang memungkinkan Anda untuk mengunggah hasil permintaan gambar dari Google. 22 ribu orang - tidak banyak, menggunakan 56 aliran kami berhasil mengunduh foto untuk mereka dalam waktu kurang dari satu jam.
Di antara foto yang diunduh, Anda harus membuang foto yang rusak, berisik, dalam format yang salah. Kemudian tinggalkan hanya yang ada wajah dan yang memenuhi kondisi tertentu: jarak minimum antara mata, kemiringan kepala. Semua ini memberi kita 12.000 foto.
Dari 12 ribu selebritas, pengguna hanya menemukan 2 saat ini, yaitu ada sekitar 8 ribu selebritas yang masih belum seperti orang lain. Jangan biarkan begitu saja! Buka telegram dan temukan semuanya.
Bagaimana cara menentukan persentase kesamaan untuk jarak Euclidean?
Pertanyaan bagus! Memang, jarak Euclidean, berbeda dengan cosinus, tidak dibatasi di atas. Oleh karena itu, muncul pertanyaan yang masuk akal, bagaimana menunjukkan kepada pengguna sesuatu yang lebih bermakna daripada "Selamat, jarak antara penyematan Anda dan penyematan Angelina Jolie adalah 0,27635462738"? Salah satu anggota tim kami mengusulkan solusi sederhana dan cerdik berikut ini. Jika Anda membangun distribusi jarak antara embed, itu akan menjadi normal. Jadi, baginya, Anda dapat menghitung rata-rata dan standar deviasi, dan kemudian untuk setiap pengguna, menurut parameter ini, pertimbangkan berapa persen orang yang kurang seperti selebritas mereka daripada dirinya . Ini sama dengan mengintegrasikan fungsi kerapatan probabilitas dari d hingga plus tak terhingga, di mana d adalah jarak antara pengguna dan demonstrasi selebriti.
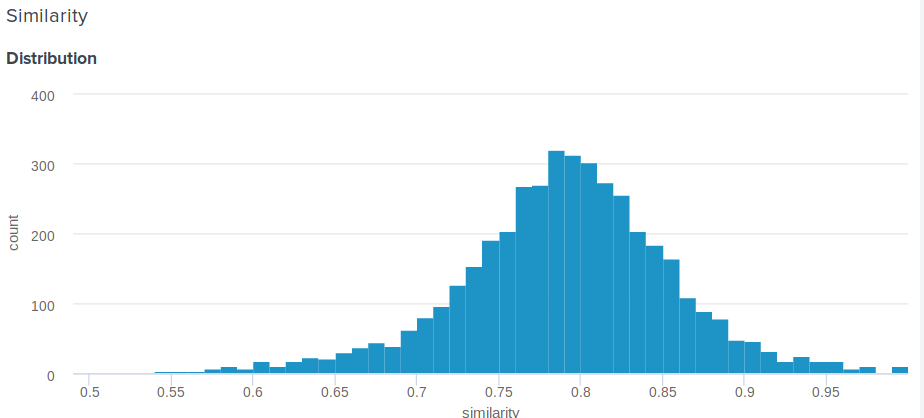
Berikut adalah fungsi persis yang kami gunakan:
def _transform_dist_to_sim(self, dist): p = 0.5 * (1 + erf((dist - self._dist_mean) / (self._dist_std * 1.4142135623730951))) return max(min(1 - p, 1.0), self._min_similarity)
Apakah benar-benar perlu untuk mengulangi daftar semua serikat pekerja untuk menemukan kecocokan?
Tentu saja tidak, ini tidak optimal dan membutuhkan banyak waktu. Cara termudah untuk mengoptimalkan perhitungan adalah dengan menggunakan operasi matriks. Alih-alih mengurangi vektor dari satu sama lain, Anda dapat menyusun matriks dari mereka dan mengurangi vektor dari matriks, dan kemudian menghitung norma L2 dalam baris.
scores = np.linalg.norm(emb - embeddings, axis=1) best_idx = scores.argmax()
Ini sudah memberi peningkatan besar dalam produktivitas, tetapi, ternyata, Anda bahkan bisa lebih cepat. Pencarian dapat dipercepat secara signifikan dengan kehilangan sedikit dalam akurasinya menggunakan pustaka nmslib . Ia menggunakan metode HNSW untuk memperkirakan pencarian k tetangga terdekat. Untuk semua vektor yang tersedia, indeks yang disebut harus dibangun, di mana kemudian pencarian akan dilakukan. Anda dapat membuat dan menyimpan indeks untuk jarak Euclidean sebagai berikut:
import nmslib index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) for idx, emb in enumerate(embeddings): index.addDataPoint(idx, emb) index_time_params = { 'indexThreadQty': 4, 'skip_optimized_index': 0, 'post': 2, 'delaunay_type': 1, 'M': 100, 'efConstruction': 2000 } index.createIndex(index_time_params, print_progress=True) index.saveIndex('./assets/embeddings.bin')
Parameter M dan efConstruction dijelaskan secara rinci dalam dokumentasi dan dipilih secara eksperimental berdasarkan akurasi yang diperlukan, waktu konstruksi indeks dan kecepatan pencarian. Sebelum menggunakan indeks, Anda harus mengunduh:
index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) index.loadIndex('./assets/embeddings.bin') query_time_params = {'efSearch': 400} index.setQueryTimeParams(query_time_params)
Parameter efSearch memengaruhi keakuratan dan kecepatan kueri dan mungkin tidak cocok dengan efConstruction . Sekarang Anda dapat membuat permintaan.
ids, dists = index.knnQuery(embedding, k=1) best_dx = ids[0] best_dist = dists[0]
Dalam kasus kami, nmslib adalah 20 kali lebih cepat dari versi linier vektor, dan satu permintaan diproses rata-rata 0.005 detik.
Bagaimana cara membuat bot saya siap untuk produksi?
1. Asynchrony
Pertama, Anda perlu membuat fungsi handle_photo asinkron. Seperti yang sudah saya katakan, python-telegram-bot menawarkan multithreading untuk ini dan mengimplementasikan dekorator yang nyaman.
from telegram.ext.dispatcher import run_async @run_async def handle_photo(bot, update): ...
Sekarang framework itu sendiri akan meluncurkan handler Anda di utas terpisah di kumpulannya. Ukuran kumpulan diatur saat membuat Updater . "Tapi dengan python tidak ada multithreading!" yang paling tidak sabar dari Anda sudah berseru. Dan ini tidak sepenuhnya benar. Karena GIL, kode Python biasa benar-benar tidak dapat dieksekusi secara paralel, tetapi GIL dirilis untuk menunggu semua operasi IO, dan itu juga dapat dirilis oleh perpustakaan yang menggunakan ekstensi C.
Sekarang menganalisis fungsi handle_photo kami: itu hanya terdiri dari menunggu operasi IO (mengunggah foto, mengirim respons, membaca foto dari disk, dll.) Dan memanggil fungsi dari perpustakaan numpy , nmslib dan Pillow .
Saya tidak menyebutkan dlib karena suatu alasan. Perpustakaan yang memanggil kode asli tidak diperlukan untuk merilis GIL dan dlib hak ini. Dia tidak membutuhkan kunci ini, dia hanya tidak membiarkannya pergi. Penulis mengatakan bahwa ia akan dengan senang hati menerima Permintaan Tarik yang sesuai, tetapi saya terlalu malas.
2. Multiprocessing
Cara termudah untuk berurusan dengan dlib adalah merangkum model dalam entitas terpisah dan menjalankannya dalam proses terpisah. Dan lebih baik di pool proses.
def _worker_initialize(config): global model model = Model(config) model.load_state() def _worker_do(image): return model.process_image(image) pool = multiprocessing.Pool(8, initializer=_worker_initialize, initargs=(config,))
result = pool.apply(_worker_do, (image,))
3. Besi
Jika bot Anda perlu terus-menerus membaca foto dari disk, pastikan disk tersebut adalah SSD. Atau bahkan memasangnya ke RAM. Ping ke server telegram dan kualitas saluran juga penting.
4. Kontrol banjir
Telegram tidak mengizinkan bot mengirim lebih dari 30 pesan per detik. Jika bot Anda populer dan banyak orang menggunakannya pada saat yang bersamaan, maka sangat mudah untuk mendapatkan larangan selama beberapa detik, yang akan berubah menjadi kekecewaan dari harapan banyak pengguna. Untuk mengatasi masalah ini, python-telegram-bot menawarkan kepada kami antrian yang tidak dapat mengirim lebih dari batas pesan yang ditentukan per detik, mempertahankan interval yang sama antara pengiriman.
from telegram.ext.messagequeue import MessageQueue
Untuk menggunakannya, Anda perlu mendefinisikan bot Anda sendiri dan menggantinya saat membuat Updater .
from telegram.utils.promise import Promise class MQBot(Bot): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self._message_queue = MessageQueue( all_burst_limit=30, all_time_limit_ms=1000 ) def __del__(self): try: self._message_queue.stop() finally: super().__del__() def send_message(self, *args, **kwargs): is_group = kwargs.get('chat_id', 0) >= 0 return self._message_queue(Promise(super().send_message, args, kwargs), is_group)
bot = MQBot(token=TOKEN) updater = Updater(bot=bot)
5. Kait web
Dalam lingkungan produk, Web Hooks harus selalu digunakan daripada Long Polling sebagai cara untuk menerima pembaruan dari server Telegram. Tentang apa semua ini dan bagaimana menggunakannya dapat dibaca di sini .
6. Trivia
json . , ultrajson .
IO-: , , . , .
6.
, . , , , . , .
, , BI-tool Splunk .
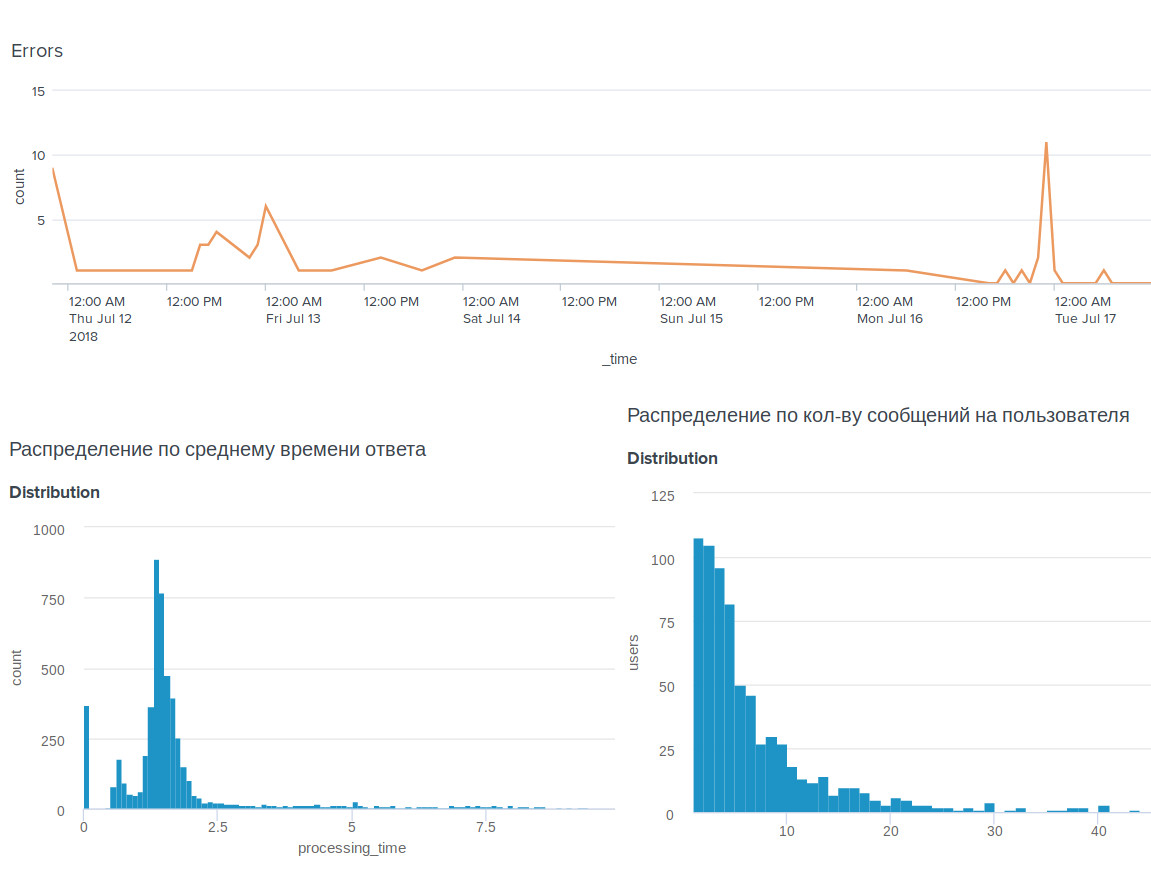
, . , .
, . , : @OkkoFaceBot .