Sebelum kode yang ditulis oleh kami dieksekusi, ia berjalan agak jauh.
Andrey Melikhov dalam laporannya tentang RIT ++ 2018 memeriksa setiap langkah di jalur ini menggunakan contoh mesin V8. Datanglah ke bawah kucing untuk mencari tahu apa yang memberi kita pemahaman mendalam tentang prinsip-prinsip kompiler dan bagaimana membuat kode JavaScript lebih produktif.

Kami akan mencari tahu apakah WASM adalah peluru perak untuk meningkatkan kinerja kode, dan apakah optimasi selalu dibenarkan.
Spoiler: "Optimalisasi prematur adalah akar dari semua penyakit," Donald Knuth.
 Tentang pembicara:
Tentang pembicara: Andrei Melikhov bekerja di Yandex.Money, menulis secara aktif di Node.js, dan lebih sedikit di browser, jadi server JavaScript lebih dekat dengannya. Andrew mendukung dan mengembangkan komunitas devShacht, jadi lihatlah
GitHub atau
Medium .
Motivasi dan Daftar Istilah
Hari ini kita akan berbicara tentang kompilasi JIT. Saya pikir ini menarik bagi Anda, karena Anda membaca ini. Namun, mari kita perjelas mengapa Anda perlu tahu apa itu JIT dan bagaimana V8 bekerja, dan mengapa menulis Bereaksi di browser tidak cukup.
- Memungkinkan Anda menulis kode yang lebih efisien , karena bahasa kami spesifik.
- Ini mengungkapkan teka - teki mengapa di perpustakaan orang lain kode ini ditulis dengan cara ini, dan bukan sebaliknya. Kadang-kadang kita menjumpai perpustakaan lama dan melihat apa yang tertulis di sana entah bagaimana aneh, tetapi jika ini perlu, itu tidak perlu - itu tidak jelas. Ketika Anda tahu cara kerjanya, Anda mengerti mengapa ini dilakukan.
- Ini sangat menarik . Selain itu, ini memungkinkan kita untuk memahami apa yang disampaikan oleh Axel Rauschmeier, Benedict Moyrer dan Dan Abramov di Twitter.
Wikipedia mengatakan bahwa JavaScript adalah bahasa pemrograman tingkat tinggi yang ditafsirkan dengan pengetikan dinamis. Kami akan berurusan dengan persyaratan ini.
Kompilasi dan interpretasiKompilasi - ketika program dikirim dalam kode biner, dan pada awalnya dioptimalkan untuk lingkungan di mana ia akan bekerja.
Interpretasi - ketika kami mengirimkan kode apa adanya.
JavaScript dikirimkan apa adanya - ini adalah bahasa yang ditafsirkan, seperti yang ditulis di Wikipedia.
Pengetikan dinamis dan statisPengetikan statis dan dinamis sering dikacaukan dengan pengetikan lemah dan kuat. Misalnya, C adalah bahasa dengan pengetikan lemah statis. JavaScript memiliki ketikan dinamis yang lemah.
Mana yang lebih baik? Jika program dikompilasi, itu diarahkan pada lingkungan di mana ia akan dieksekusi, yang berarti akan bekerja lebih baik. Pengetikan statis membuat kode ini lebih efisien. Dalam JavaScript, yang terjadi adalah sebaliknya.
Tetapi pada saat yang sama, aplikasi kita menjadi lebih kompleks: baik di klien dan di server, kelompok besar muncul di Node.js, yang berfungsi dengan baik dan menggantikan aplikasi Java.
Tetapi bagaimana semuanya bekerja jika pada awalnya tampaknya menjadi pecundang.
JIT akan merekonsiliasi semua orang! Atau setidaknya coba.
Kami memiliki JIT (kompilasi Just In Time) yang terjadi saat runtime. Kami akan membicarakannya.
Mesin Js
- Chakra Unloved, yang terletak di Internet Explorer. Ini bahkan tidak berfungsi dengan JavaScript, tetapi dengan Jscript - ada subset seperti itu.
- Chakra dan Chakra modern yang berfungsi di Edge;
- SpiderMonkey di FireFox;
- JavaScriptCore di WebKit. Ini juga digunakan dalam Bereaksi Asli. Jika Anda memiliki aplikasi RN untuk Android, maka itu juga berjalan di JavaScriptCore - mesin dibundel dengan aplikasi tersebut.
- V8 adalah favorit saya. Ini bukan yang terbaik, saya hanya bekerja dengan Node.js, di mana itu adalah mesin utama, seperti di semua browser Berbasis Chrome.
- Badak dan Nashorn adalah mesin yang digunakan di Jawa. Dengan bantuan mereka, Anda juga dapat menjalankan JavaScript di sana.
- JerryScript - untuk perangkat yang disematkan;
- dan lainnya ...
Anda dapat menulis mesin sendiri, tetapi jika Anda bergerak menuju eksekusi yang efektif, Anda akan sampai pada skema yang kira-kira sama, yang akan saya tunjukkan nanti.
Hari ini kita akan berbicara tentang V8, dan ya, dinamai mesin 8-silinder.
Kami memanjat di bawah tenda
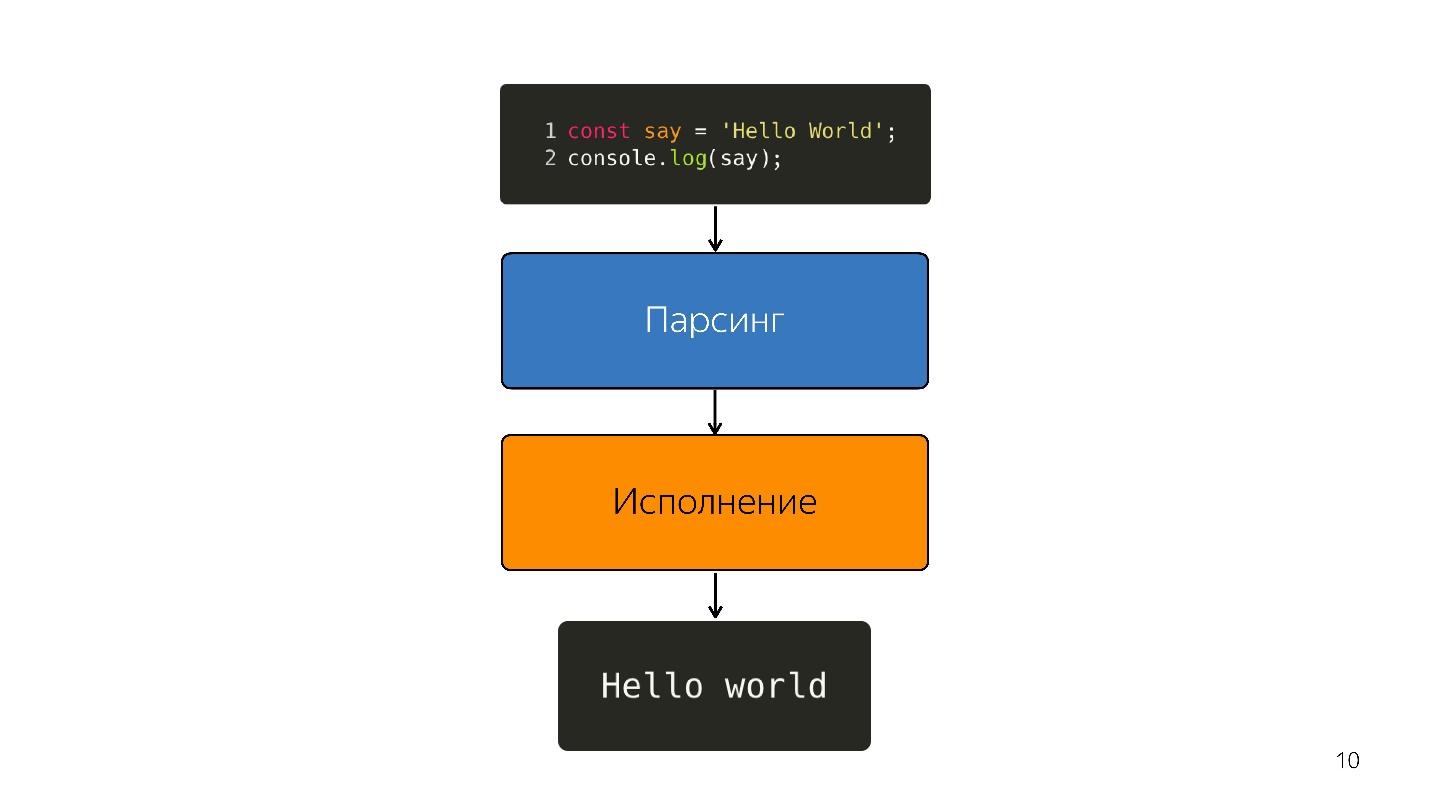
Bagaimana javascript dijalankan?
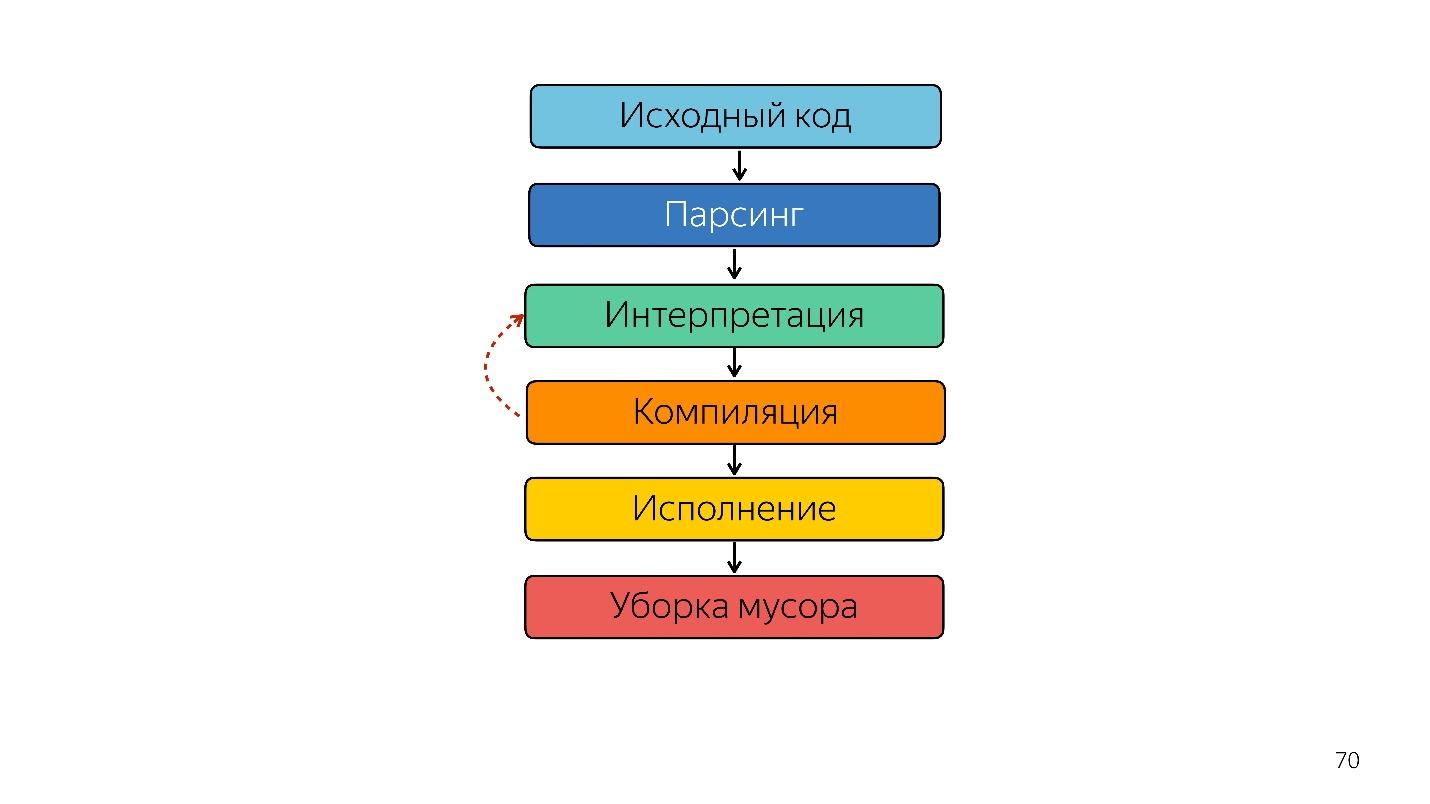
- Ada kode yang ditulis dalam JavaScript, yang disediakan.
- dia mengurai;
- sedang dieksekusi;
- hasilnya didapat.
Parsing mengubah kode menjadi
pohon sintaksis abstrak . AST adalah tampilan struktur sintaksis kode dalam bentuk pohon. Ini sebenarnya nyaman untuk program ini, meskipun sulit dibaca.
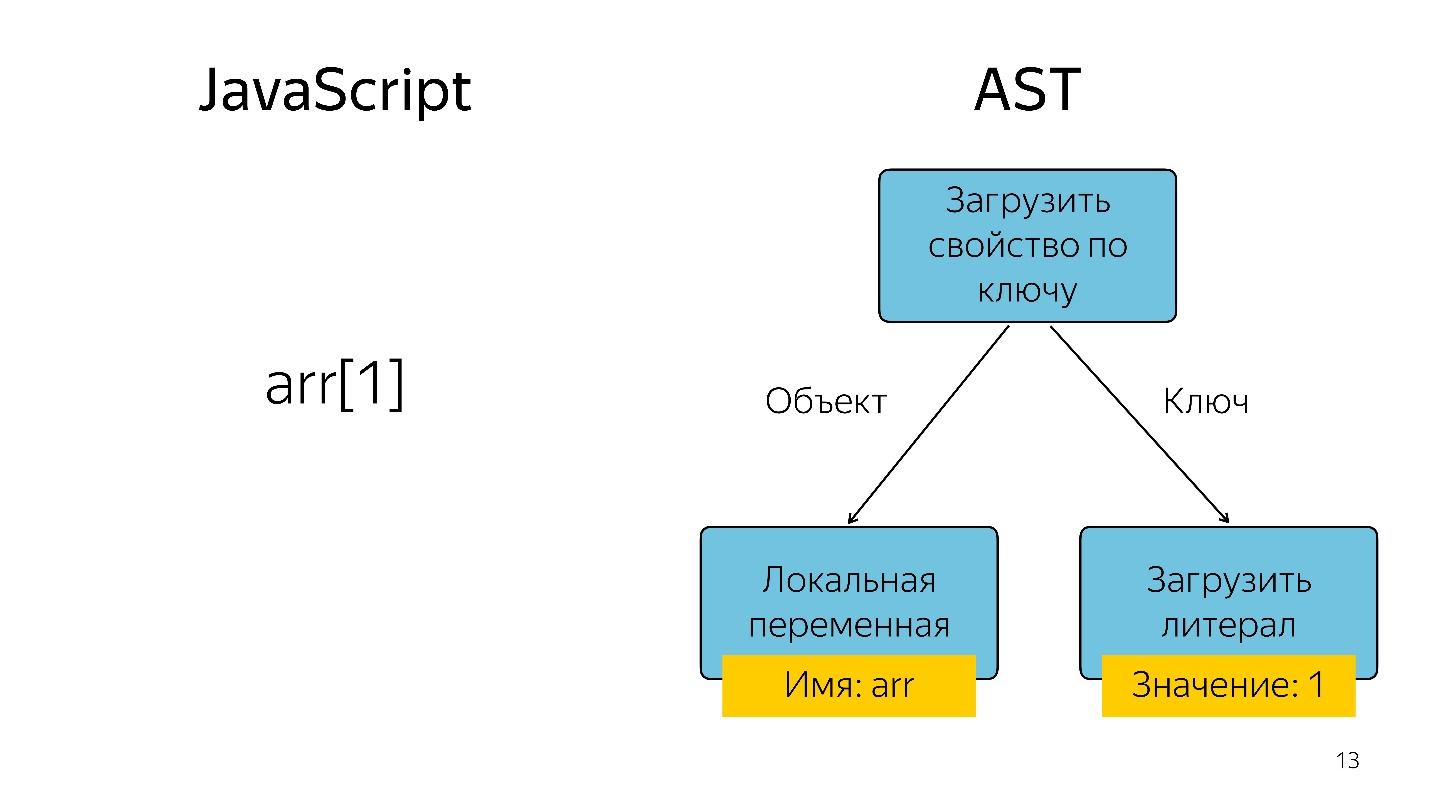
Mendapatkan elemen array dengan indeks 1 dalam bentuk pohon direpresentasikan sebagai operator dan dua operan: muat properti dengan kunci dan kunci-kunci ini.
Di mana AST digunakan?
AST tidak hanya di mesin. Menggunakan AST, banyak utilitas menulis ekstensi, termasuk:
- ESLint;
- Babel;
- Lebih cantik
- Jscodeshift.
Misalnya, hal keren Jscodeshift, yang belum diketahui semua orang, memungkinkan Anda menulis transformasi. Jika Anda mengubah API suatu fungsi, Anda dapat mengatur transformasi ini di atasnya dan membuat perubahan di seluruh proyek.

Kami melanjutkan. Prosesor tidak mengerti pohon sintaksis abstrak, itu membutuhkan
kode mesin . Oleh karena itu, transformasi lebih lanjut terjadi melalui penerjemah, karena bahasa ditafsirkan.
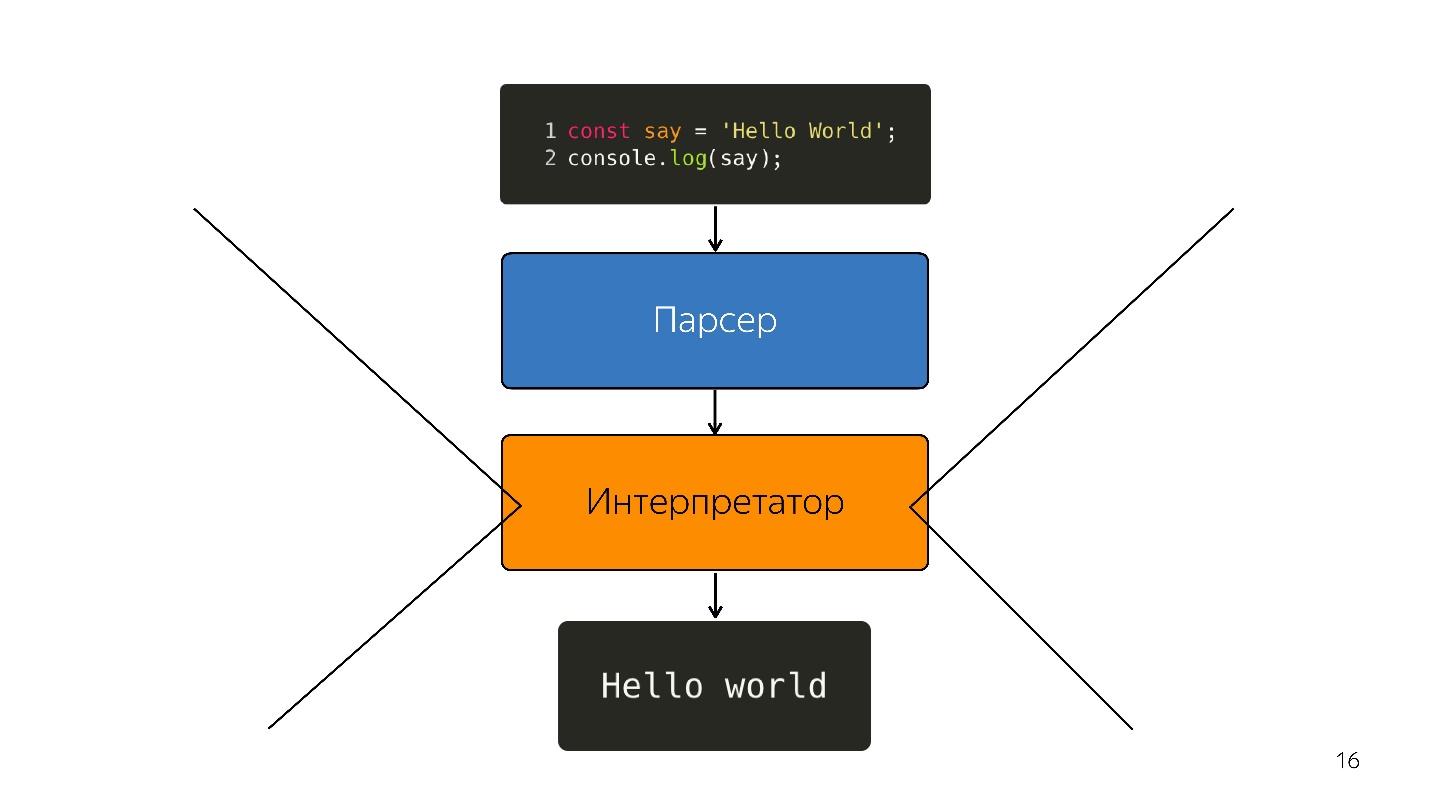
Begitulah, sementara browser memiliki sedikit JavaScript - sorot baris, buka sesuatu, tutup. Tapi sekarang kami memiliki aplikasi - SPA, Node.js, dan
juru bahasa menjadi hambatan .
Mengoptimalkan JIT Compiler
Alih-alih penerjemah, kompiler JIT yang optimal muncul, yaitu kompiler Just-in-time. Kompiler sebelumnya bekerja sebelum eksekusi aplikasi, dan JIT - selama. Pada masalah optimisasi, kompiler JIT mencoba menebak bagaimana kode akan dieksekusi, tipe apa yang akan digunakan, dan mengoptimalkan kode sehingga ia bekerja lebih baik.
Optimalisasi semacam itu disebut
spekulatif , karena berspekulasi pada pengetahuan tentang apa yang terjadi pada kode sebelumnya. Artinya, jika sesuatu dengan tipe angka dipanggil 10 kali, kompiler berpikir bahwa ini akan terjadi setiap saat dan dioptimalkan untuk tipe ini.
Secara alami, jika Boolean memasukkan input, terjadi deoptimisasi. Pertimbangkan fungsi yang menambahkan angka.
const foo=(a, b) => a + b;
foo (1, 2);
foo (2, 3);Lipat sekali, yang kedua kalinya. Kompiler membuat prediksi: "Ini adalah angka, saya punya solusi keren untuk menambahkan angka!" Dan Anda menulis
foo('WTF', 'JS') , dan meneruskan garis ke fungsi - kami memiliki JavaScript, kami dapat menambahkan baris dengan angka.
Pada titik ini, terjadi deoptimisasi.
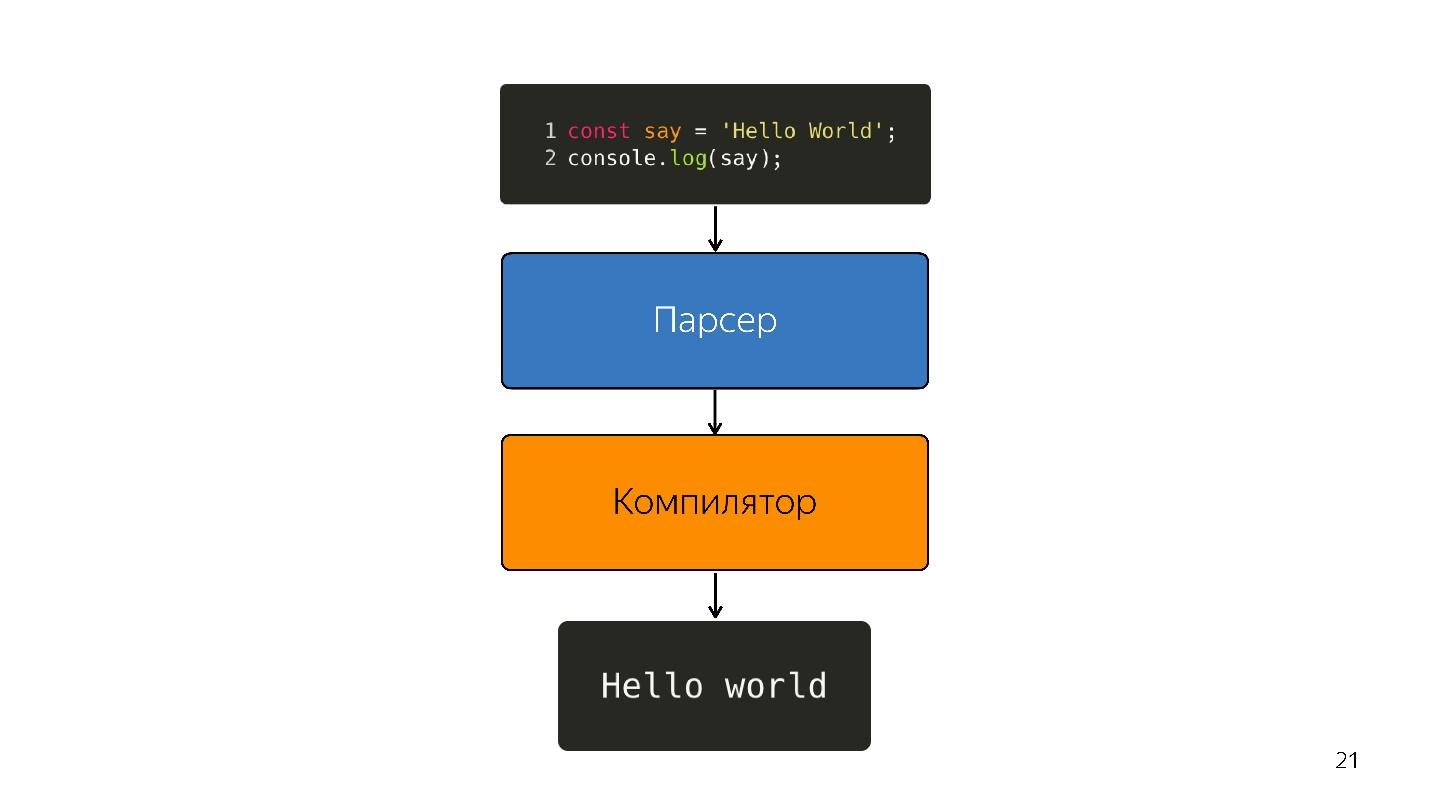
Jadi, penerjemah digantikan oleh kompiler. Diagram di atas tampaknya memiliki pipa yang sangat sederhana. Pada kenyataannya, semuanya sedikit berbeda.
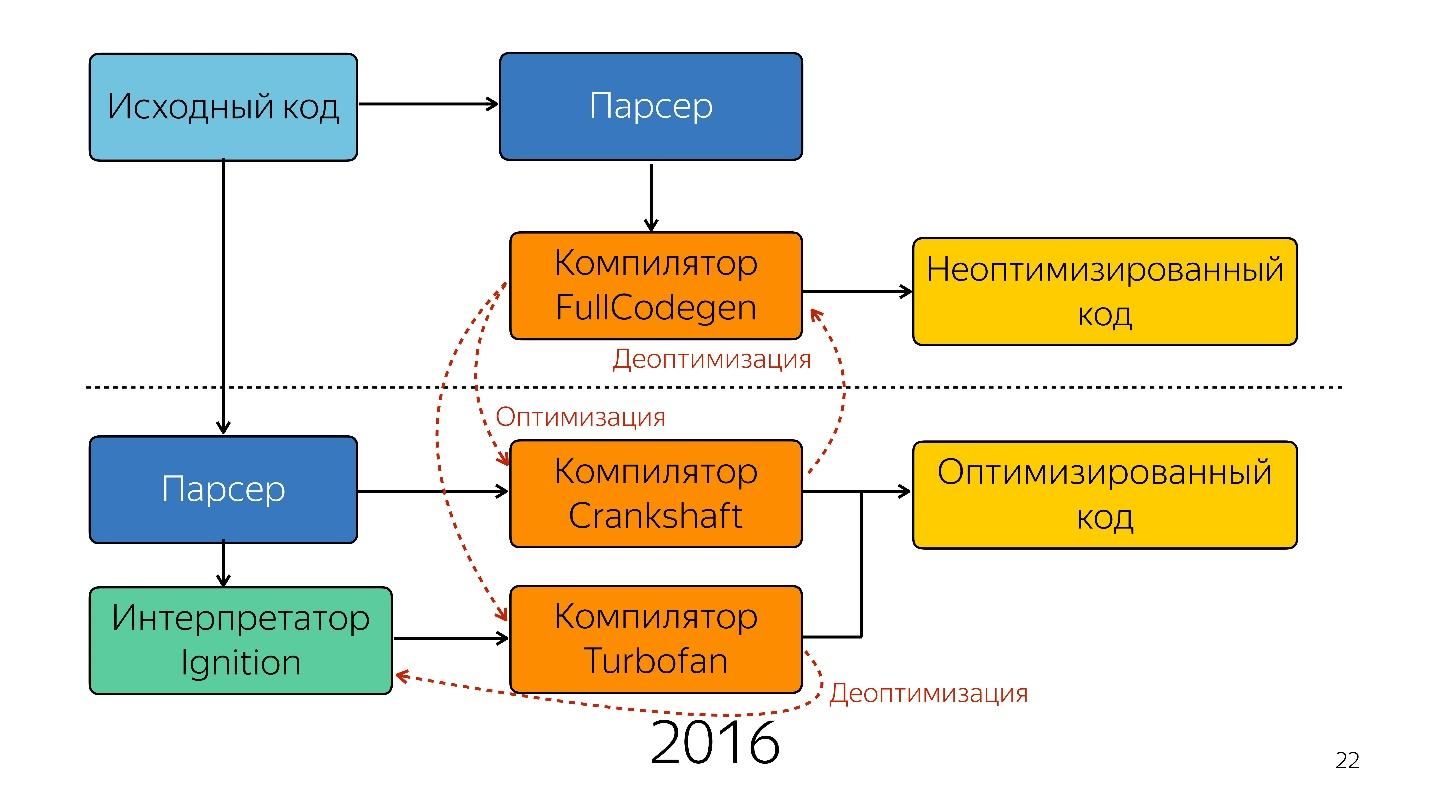
Itu sampai tahun lalu. Tahun lalu, Anda dapat mendengar banyak laporan dari Google bahwa mereka meluncurkan saluran pipa baru dengan TurboFan dan sekarang skemanya terlihat lebih sederhana.
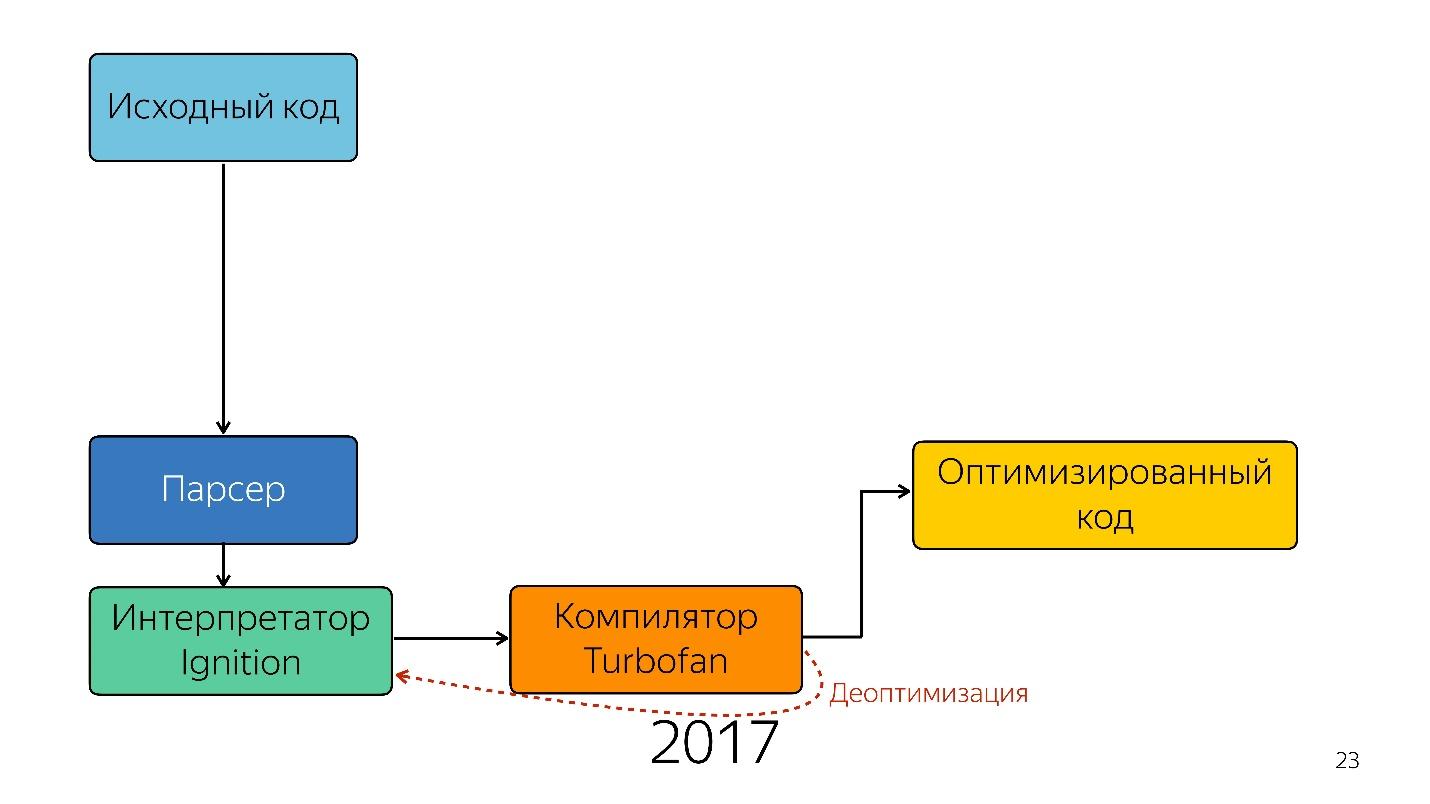
Menariknya, seorang penerjemah muncul di sini.
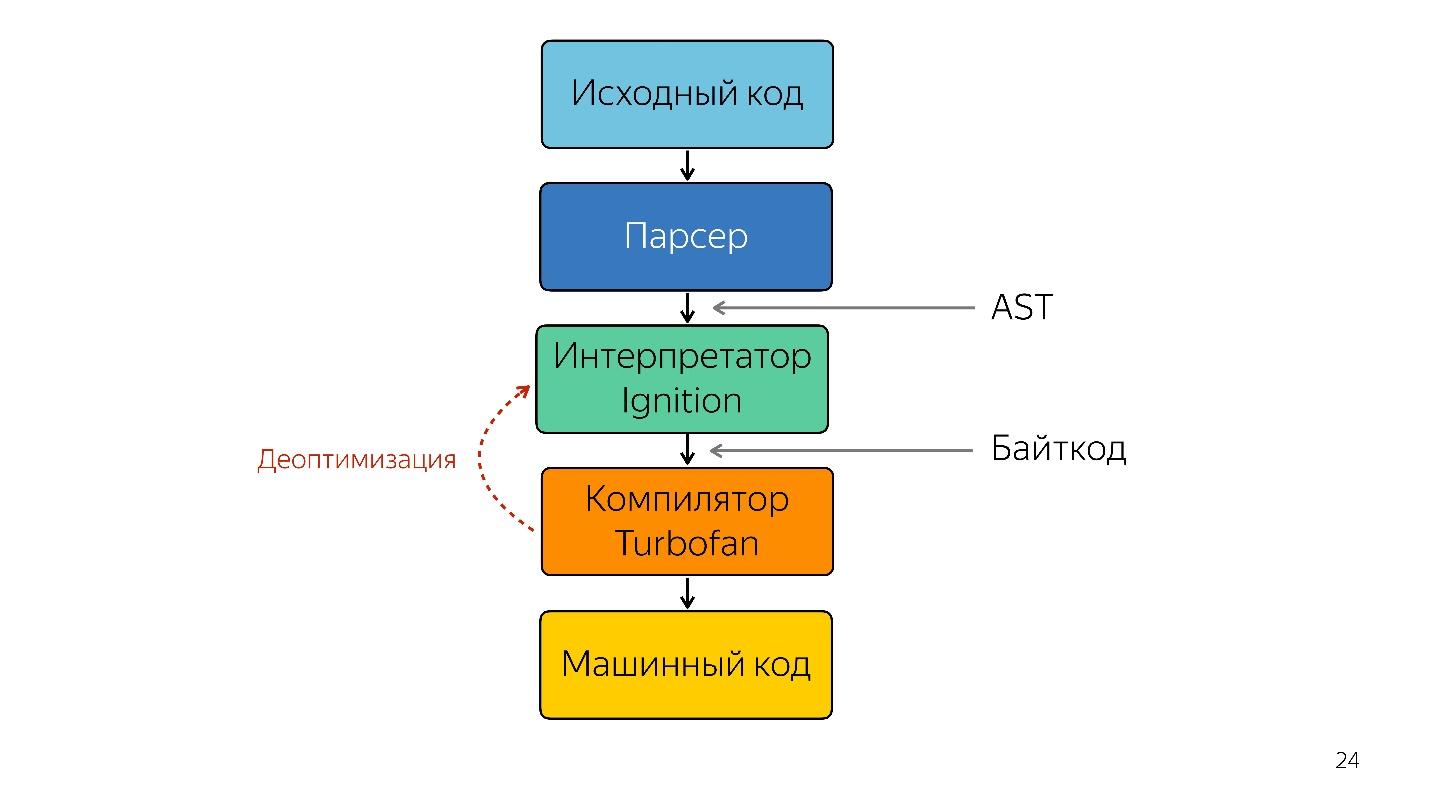
Seorang juru bahasa diperlukan untuk mengubah pohon sintaksis abstrak menjadi bytecode, dan meneruskan bytecode ke kompiler. Dalam kasus deoptimisasi, ia kembali pergi ke penerjemah.
Ignition Interpreter
Sebelumnya, tidak ada skema interpreter pengapian. Google awalnya mengatakan bahwa juru bahasa tidak diperlukan - JavaScript sudah kompak dan cukup dapat ditafsirkan - kami tidak akan memenangkan apa pun.
Tetapi tim yang bekerja dengan aplikasi seluler mengalami masalah berikut ini.

Pada 2013-2014, orang mulai menggunakan perangkat seluler untuk mengakses Internet lebih sering daripada desktop. Pada dasarnya, ini bukan iPhone, tetapi dari perangkat yang lebih sederhana - mereka memiliki sedikit memori dan prosesor yang lemah.
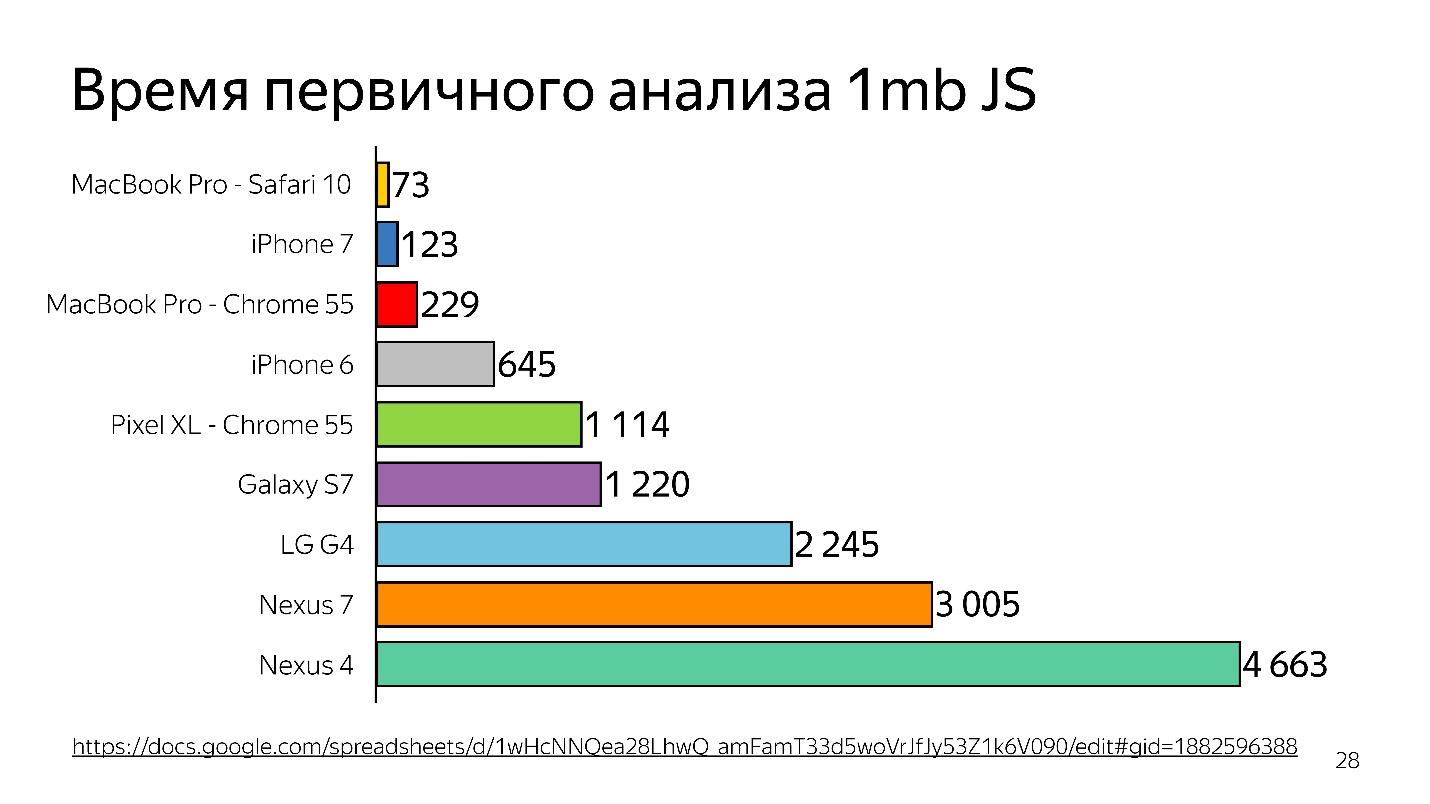
Di atas adalah grafik analisis awal 1 MB kode sebelum memulai juru bahasa. Dapat dilihat bahwa desktop menang sangat banyak. IPhone juga tidak buruk, tetapi memiliki mesin yang berbeda, dan kita berbicara tentang V8, yang berfungsi di Chrome.
Tahukah Anda bahwa jika Anda memasang Chrome di iPhone, itu akan tetap berfungsi di JavaScriptCore?
Dengan demikian, waktu terbuang - dan ini hanya analisis, bukan eksekusi - file Anda telah dimuat, dan ia mencoba memahami apa yang tertulis di dalamnya.
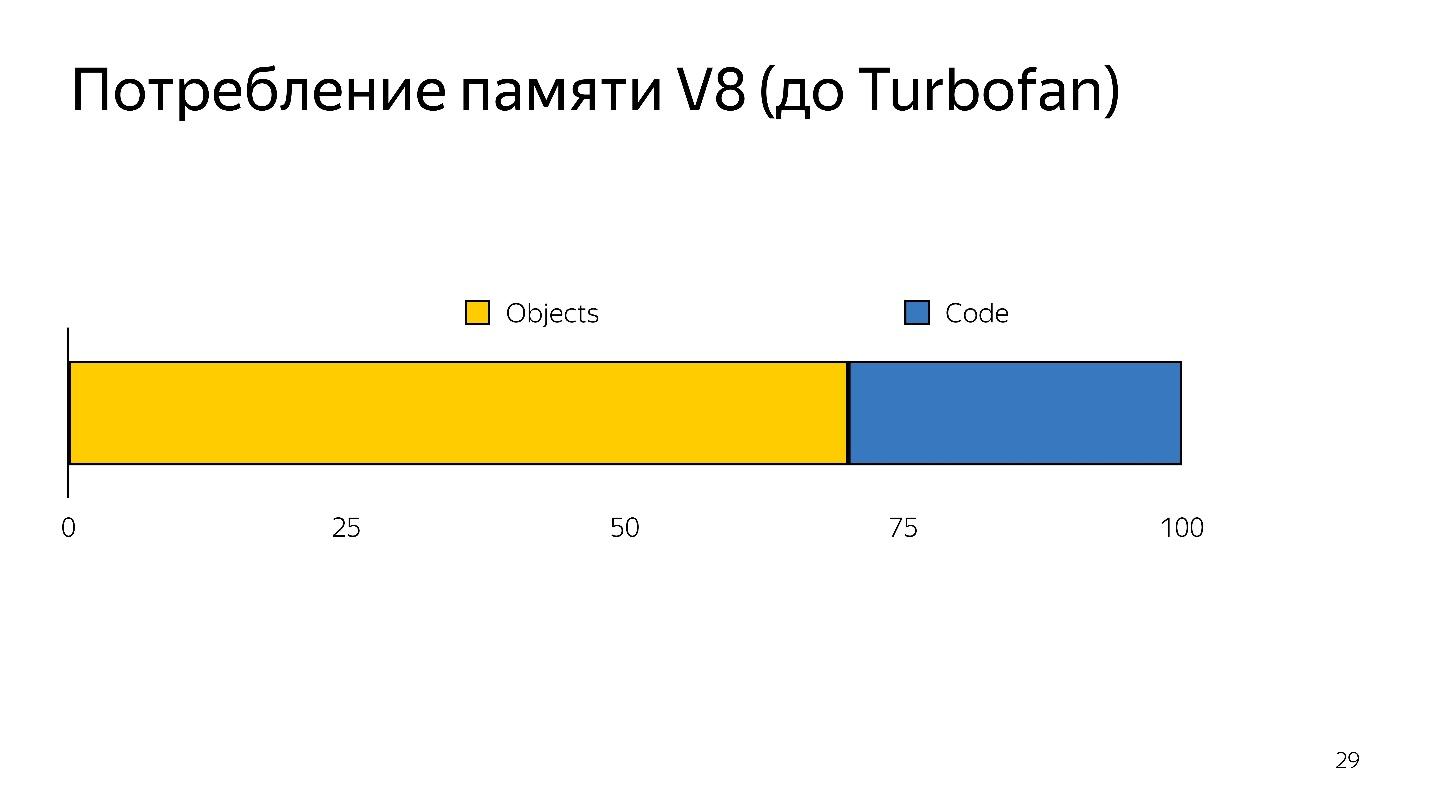
Ketika deoptimisasi terjadi, Anda perlu mengambil kode sumber lagi, yaitu itu perlu disimpan di suatu tempat. Butuh banyak memori.
Dengan demikian, penerjemah memiliki dua tugas:
- mengurangi parsing overhead;
- mengurangi konsumsi memori.
Tugas diselesaikan dengan beralih ke penerjemah bytecode.
 Bytecode di Chrome adalah mesin register dengan baterai
Bytecode di Chrome adalah mesin register dengan baterai . SpiderMonkey memiliki mesin bertumpuk, semua data ada di tumpukan, tetapi tidak ada register. Inilah mereka.
Kami tidak akan sepenuhnya menganalisis cara kerjanya, lihat saja fragmen kode.

Dikatakan di sini: ambil nilai yang ada di baterai dan tambahkan ke nilai yang ada di register
a0 , yaitu, dalam variabel
a . Belum ada yang diketahui tentang jenis di sini. Jika itu adalah kode assembler nyata, maka itu akan ditulis dengan pemahaman tentang jenis shift apa yang ada dalam memori, apa yang ada di dalamnya. Ini hanya sebuah instruksi - ambil apa yang ada di register
a0 dan tambahkan ke nilai yang ada di baterai.
Tentu saja, interpreter tidak hanya mengambil pohon sintaksis abstrak dan menerjemahkannya menjadi bytecode.
Ada juga optimasi, misalnya, penghapusan kode mati.
Jika suatu bagian dari kode tidak dipanggil, itu dibuang dan tidak disimpan lebih lanjut. Jika Ignition melihat penambahan dua angka, ia menambahkannya dan membiarkannya sedemikian rupa agar tidak menyimpan informasi yang tidak perlu. Hanya setelah ini diperoleh bytecode.
Optimasi dan deoptimisasi
Fitur dingin dan panas
Ini adalah topik yang paling mudah.
Fungsi dingin adalah fungsi yang dipanggil sekali atau tidak dipanggil sama sekali, fungsi panas adalah fungsi yang dipanggil beberapa kali. Tidak mungkin untuk mengatakan dengan tepat berapa kali - setiap saat ini dapat diulang. Tetapi pada titik tertentu, fungsinya menjadi panas, dan mesin mengerti bahwa itu perlu dioptimalkan.

Skema kerja.
- Ignition (interpreter) mengumpulkan informasi. Dia tidak hanya mengubah JavaScript menjadi bytecode, tetapi juga memahami tipe apa yang masuk, fungsi apa yang menjadi panas, dan dia memberi tahu kompilator tentang semua ini.
- Ada optimasi.
- Kompiler mengeksekusi kode. Semuanya berfungsi dengan baik, tetapi di sini suatu tipe tiba bahwa dia tidak berharap, dia tidak memiliki kode untuk bekerja dengan tipe ini.
- Terjadi deoptimisasi. Kompiler mengakses interpreter Pengapian untuk kode ini.
Ini adalah siklus normal yang terjadi setiap saat, tetapi ini tidak terbatas. Pada titik tertentu, mesin mengatakan, "Tidak, itu tidak mungkin untuk dioptimalkan," dan mulai dijalankan tanpa optimasi. Penting untuk dipahami bahwa monomorfisme harus diperhatikan.
Monomorfisme adalah ketika tipe yang sama selalu masuk ke input fungsi Anda. Artinya, jika Anda mendapatkan string sepanjang waktu, maka Anda tidak perlu melewati boolean di sana.
Tapi apa yang harus dilakukan dengan benda? Objek adalah semua objek. Kami memiliki kelas, tetapi mereka tidak nyata - itu hanya gula dari model prototipe. Tapi di dalam mesin ada yang disebut kelas tersembunyi.
Kelas tersembunyi
Ada kelas tersembunyi di semua mesin, tidak hanya di V8. Di mana-mana mereka dipanggil secara berbeda, dalam hal V8 itu adalah Peta.
Semua objek yang Anda buat memiliki kelas tersembunyi. Jika anda
lihat profil memori, Anda akan melihat bahwa ada elemen tempat daftar elemen disimpan, properti tempat properti disimpan, dan peta (biasanya parameter pertama), di mana tautan ke sana ditunjukkan pada kelas tersembunyi.
Peta menggambarkan struktur objek, karena pada prinsipnya, dalam JavaScript, pengetikan hanya mungkin struktural, bukan nominal. Kita bisa menggambarkan seperti apa objek kita, untuk apa itu.
Saat menghapus / menambahkan properti objek kelas Tersembunyi, objek berubah, yang baru ditugaskan. Mari kita lihat kodenya.
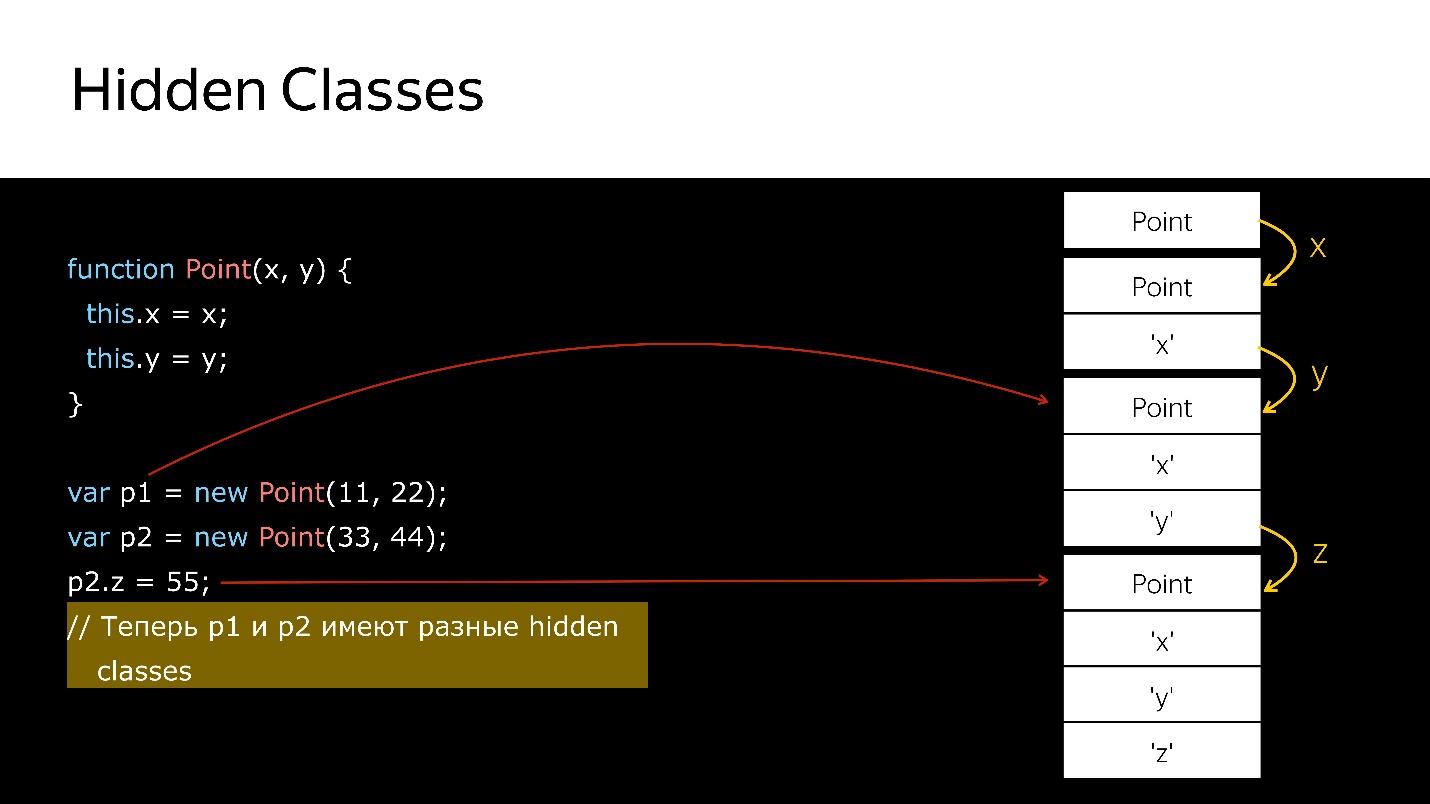
Kami memiliki konstruktor yang membuat objek baru bertipe Point.
- Buat objek.
- Bind kelas tersembunyi untuk itu, yang mengatakan bahwa itu adalah objek bertipe Point.
- Kami menambahkan bidang x - kelas tersembunyi baru yang mengatakan itu adalah objek bertipe Point, di mana nilai x lebih dulu.
- Menambahkan y - kelas Tersembunyi baru, di mana x, dan kemudian y.
- Dibuat objek lain - hal yang sama terjadi. Artinya, ia juga mengikat apa yang sudah dibuat. Pada saat ini, kedua objek ini memiliki tipe yang sama (melalui kelas Tersembunyi).
- Ketika bidang baru ditambahkan ke objek kedua, kelas tersembunyi baru muncul di objek. Sekarang untuk mesin p1 dan p2, ini adalah objek dari kelas yang berbeda, karena mereka memiliki struktur yang berbeda
- Jika Anda mentransfer objek pertama di suatu tempat, maka ketika Anda mentransfer objek kedua di sana, deoptimisasi akan terjadi. Yang pertama mengacu pada satu kelas tersembunyi, yang kedua ke yang lain.
Bagaimana saya bisa memeriksa kelas tersembunyi?Di Node.js, Anda bisa menjalankan simpul —allow-asli-sintaks. Maka Anda akan mendapatkan kesempatan untuk menulis perintah dalam sintaks khusus, yang, tentu saja, tidak dapat digunakan dalam produksi. Ini terlihat seperti ini:
%HaveSameMap({'a':1}, {'b':1})
Tidak ada yang menjamin bahwa besok perintah ini akan berfungsi, mereka tidak ada dalam spesifikasi ECMAScript, itu saja untuk debugging.
Menurut Anda apa hasil dari memanggil fungsi% HaveSameMap untuk dua objek. Jawaban yang benar salah, karena yang satu memiliki bidang, dan yang lainnya
b . Ini adalah objek yang berbeda. Pengetahuan ini dapat digunakan untuk teknik Cache Inline.
Cache sebaris
Kami memanggil fungsi yang sangat sederhana yang mengembalikan bidang dari suatu objek. Mengembalikan unit tampaknya sangat sederhana. Tetapi jika Anda melihat spesifikasi ECMAScript, Anda akan melihat bahwa ada daftar besar apa yang perlu Anda lakukan untuk mendapatkan bidang dari objek. Karena, jika bidang tidak ada di objek, ada kemungkinan bahwa itu dalam prototipe. Mungkin itu setter, pengambil dan sebagainya. Semua ini perlu diperiksa.

Dalam hal ini, objek memiliki tautan ke peta, yang mengatakan: untuk mendapatkan bidang
x , Anda perlu melakukan offset dengan satu, dan kami mendapatkan
x . Anda tidak perlu naik ke mana pun, dalam prototipe apa pun, semuanya ada di dekatnya. Cache Inline menggunakan ini.
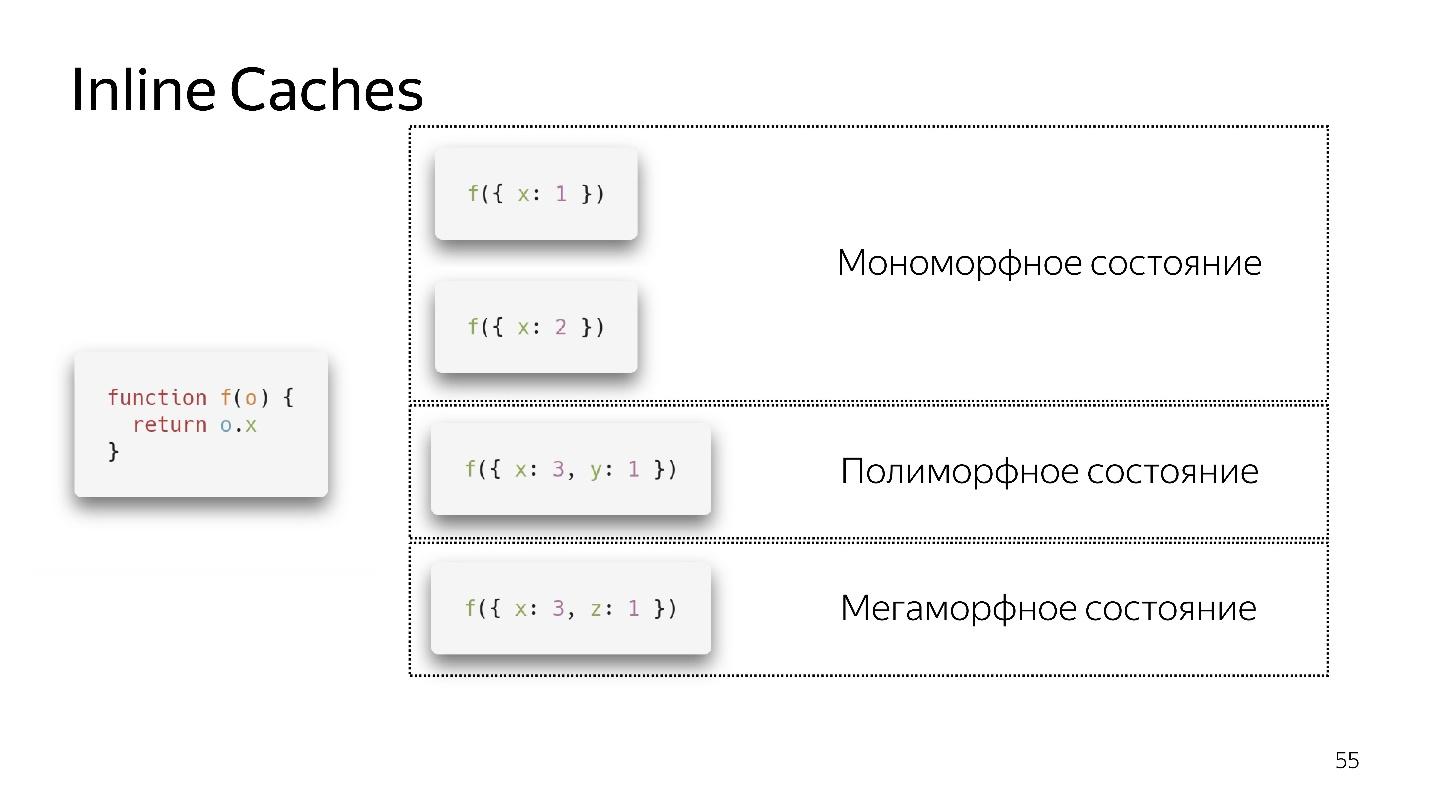
- Jika kita memanggil fungsi untuk pertama kalinya, semuanya baik-baik saja, penerjemah telah melakukan optimasi
- Untuk panggilan kedua, keadaan monomorfik disimpan.
- Saya memanggil fungsi untuk ketiga kalinya, melewatkan objek yang sedikit berbeda {x: 3, y: 1}. Deoptimisasi terjadi, jika muncul, kita masuk ke keadaan polimorfik. Sekarang kode yang menjalankan fungsi ini tahu bahwa dua jenis objek dapat terbang ke dalamnya.
- Jika kita melewati objek yang berbeda beberapa kali, ia tetap dalam keadaan polimorfik, menambahkan ifs baru. Tetapi pada titik tertentu menyerah dan pergi ke keadaan megamorphic, yaitu ketika: "Terlalu banyak jenis berbeda tiba di pintu masuk - saya tidak tahu cara mengoptimalkannya!"
Tampaknya sekarang 4 negara polimorfik diizinkan, tetapi besok mungkin ada 8. Ini diputuskan oleh para pengembang mesin. Lebih baik kita tetap dalam keadaan monomorfik, dalam kasus ekstrim, polimorfik. Transisi antara keadaan monomorfik dan polimorfik mahal, karena Anda harus pergi ke juru bahasa, mendapatkan kode lagi dan mengoptimalkannya lagi.
Array
Dalam JavaScript, selain dari Typed Arays tertentu, ada satu jenis
array Ada 6 dari mereka di mesin V8:
1. [1, 2, 3, 4] // PACKED_SMI_ELEMENTS - hanya array bilangan bulat kecil yang dikemas. Ada optimasi untuknya.
2. [1.2, 2.3, 3.4, 4.6] // PACKED_DOUBLE_ELEMENTS - array elemen ganda yang dikemas, ada juga optimasi untuknya, tetapi yang lebih lambat.
3. [1, 2, 3, 4, 'X'] // PACKED_ELEMENTS - larik yang dikemas di mana terdapat objek, string, dan yang lainnya. Baginya, juga, ada optimasi.
Tiga tipe berikut adalah array dengan tipe yang sama dengan tiga yang pertama, tetapi berlubang:
4. [1, / * hole * /, 2, / * hole * /, 3, 4] // HOLEY_SMI_ELEMENTS
5. [1.2, / * hole * /, 2, / * hole * /, 3,4] // HOLEY_DOUBLE_ELEMENTS
6. [1, / * lubang * /, 'X'] // HOLEY_ELEMENTS
Ketika lubang muncul di array Anda, optimasi menjadi kurang efisien. Mereka mulai bekerja dengan buruk, karena tidak mungkin untuk melewati array ini secara berurutan, memilah-milah iterasi. Setiap jenis selanjutnya kurang dioptimalkan
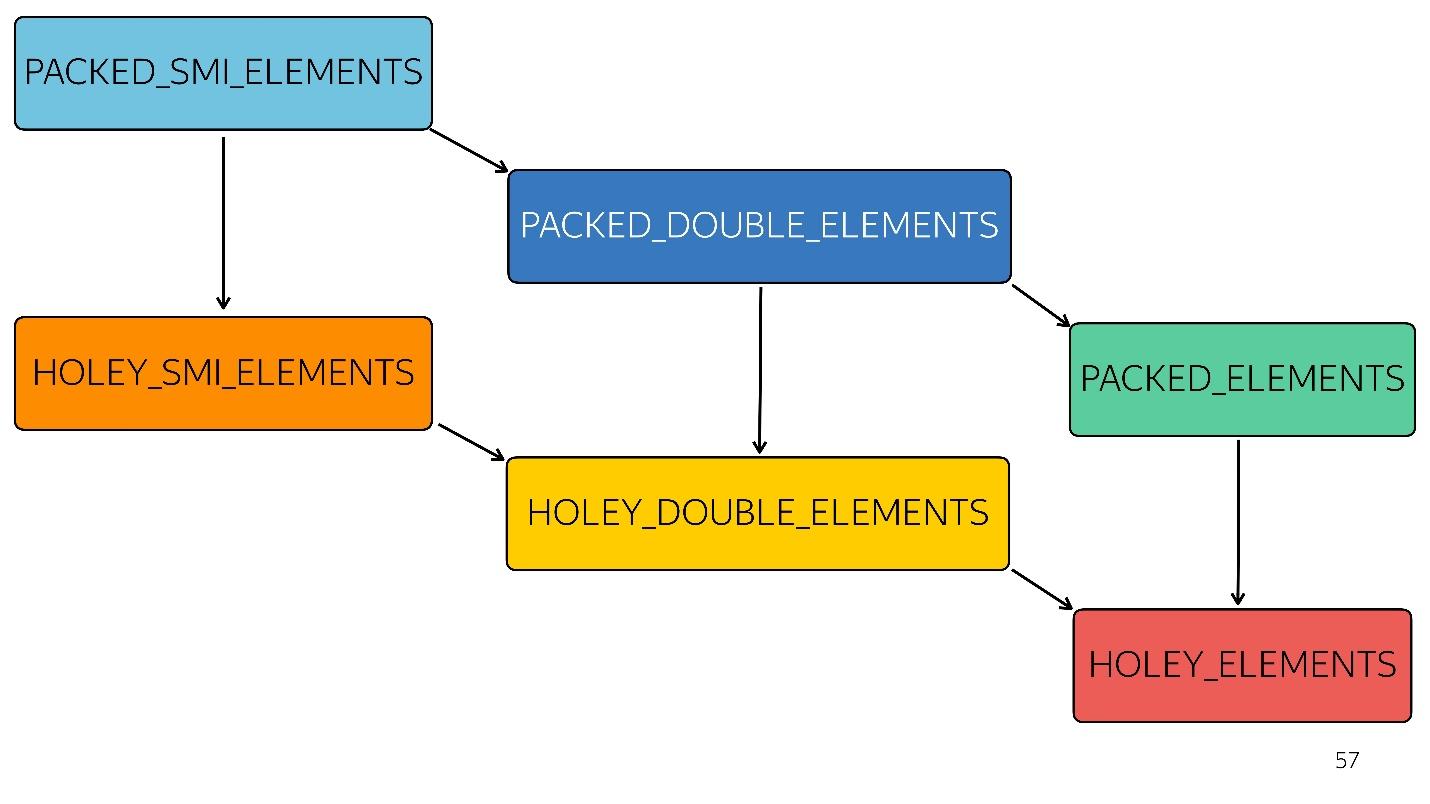
Dalam diagram, semuanya di atas dioptimalkan lebih cepat. Artinya, semua metode asli Anda - peta, kurangi, sortir - di dalam dioptimalkan dengan baik. Tetapi dengan masing-masing jenis, optimasi semakin buruk.
Sebagai contoh, sebuah array sederhana [
1 ,
2 ,
3 ] datang ke input (integer kecil tipe-dikemas). Kami sedikit mengubah array ini dengan menambahkan double ke dalamnya - masuk ke status PACKED_DOUBLE_ELEMENTS. Tambahkan objek ke sana - buka status berikutnya, persegi panjang hijau PACKED_ELEMENTS. Tambahkan lubang ke dalamnya - buka status HOLEY_ELEMENTS. Kami ingin mengembalikannya ke keadaan sebelumnya sehingga menjadi "baik" lagi - kami menghapus semua yang kami tulis dan tetap dalam kondisi yang sama ... dengan lubang! Yaitu, HOLEY_ELEMENTS di kanan bawah diagram. Kembali ini tidak berfungsi. Array Anda hanya dapat menjadi lebih buruk, tetapi tidak sebaliknya.
Objek seperti array
Kita sering menemukan Array-Like Objects - ini adalah objek yang terlihat seperti array karena memiliki tanda panjang. Faktanya, mereka seperti kucing bajak laut, artinya mereka mirip, tetapi dalam efisiensi konsumsi rum, kucing akan lebih buruk daripada bajak laut. Demikian pula, Obyek Array-Like seperti array, tetapi tidak efisien.

Dua Objek Seperti Array favorit kami adalah argumen dan document.querySelectorAII. Ada hal-hal fungsional yang begitu indah.
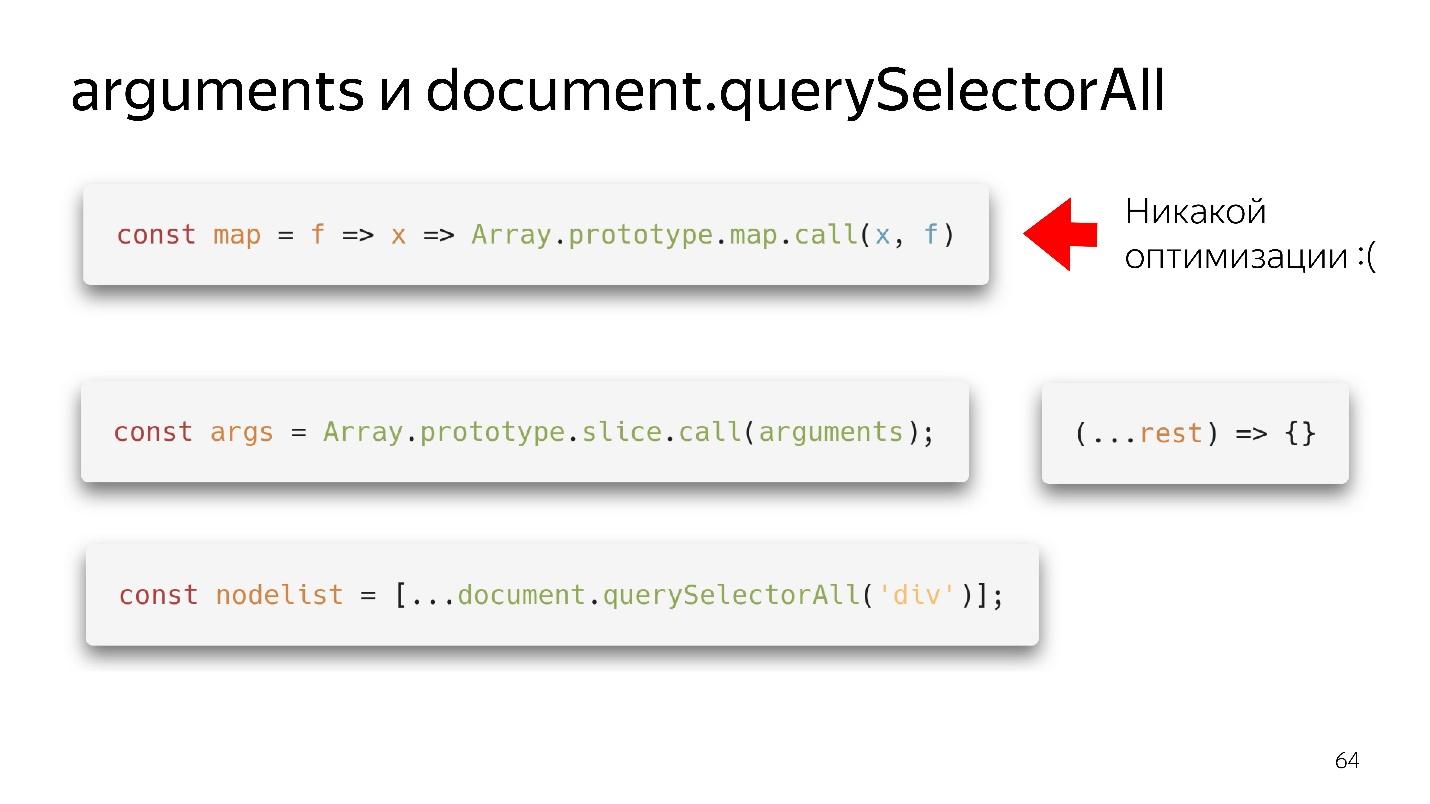
Kami punya peta - kami merobeknya dari prototipe dan tampaknya bisa menggunakannya. Tetapi jika bukan array yang masuk ke inputnya, tidak akan ada optimasi. Mesin kami tidak dapat melakukan optimasi pada objek.
Apa yang perlu dilakukan?
- Opsi old-school - melalui slice.call () berubah menjadi array nyata.
- Opsi modern bahkan lebih baik: tulis (... istirahat), dapatkan array bersih - bukan argumen - semuanya baik-baik saja!
Dengan querySelectorSemua hal yang sama - karena penyebaran kami dapat mengubahnya menjadi array yang lengkap dan bekerja dengan semua optimisasi.
Array besar
Riddle: new Array (1000) vs array = []
Opsi mana yang lebih baik: segera buat array besar dan isi dengan 1000 objek dalam satu lingkaran, atau buat yang kosong dan isi secara bertahap?
Jawaban yang benar: tergantung pada.
Apa bedanya?
- Saat kami membuat array dengan cara pertama dan mengisi 1000 elemen, kami membuat 1000 lubang. Array ini tidak akan dioptimalkan. Tapi dia akan menulis dengan cepat.
- Membuat array sesuai dengan varian kedua, sedikit memori dialokasikan, kita menulis, misalnya, 60 elemen, sedikit lebih banyak memori dialokasikan, dll.
Artinya, pada kasus pertama kita menulis dengan cepat - kita bekerja lambat; di detik kita menulis perlahan - kita bekerja dengan cepat.
Pengumpul sampah
Pengumpul sampah juga makan sedikit waktu dan sumber daya. Tanpa menyelam dalam-dalam, saya akan memberikan dasar yang paling umum.

Model generatif kami memiliki
ruang benda muda dan tua . Objek yang dibuat jatuh ke ruang benda muda. Setelah beberapa waktu, pembersihan dimulai. Jika objek tidak dapat dijangkau oleh tautan dari root, maka itu dapat dikumpulkan dalam sampah. Jika objek masih digunakan, ia bergerak ke ruang objek lama, yang kurang sering dibersihkan. Namun, pada titik tertentu, objek lama dihapus.

Ini adalah cara kerja pengumpul sampah otomatis - ia membersihkan benda-benda berdasarkan tidak ada tautan ke sana. Ini adalah dua algoritma yang berbeda.
- Mengais adalah cepat tetapi tidak efektif.
- Mark-Sweep lambat tapi efisien.
Jika Anda mulai membuat profil konsumsi memori di Node.js, Anda mendapatkan sesuatu seperti ini.

Pada awalnya, itu tumbuh secara tiba-tiba - ini adalah karya dari algoritma Scavenge. Kemudian terjadi penurunan tajam - algoritma Mark-Sweep ini telah mengumpulkan sampah di ruang objek lama. Pada saat ini, semuanya mulai melambat sedikit.
Anda tidak dapat mengendalikannya , karena Anda tidak tahu kapan itu akan terjadi. Anda hanya dapat menyesuaikan ukurannya.
Oleh karena itu, pipa memiliki tahap pengumpulan sampah yang menghabiskan waktu.
Lebih cepat lagi?
Mari kita melihat masa depan. Apa yang harus dilakukan selanjutnya, bagaimana menjadi lebih cepat?
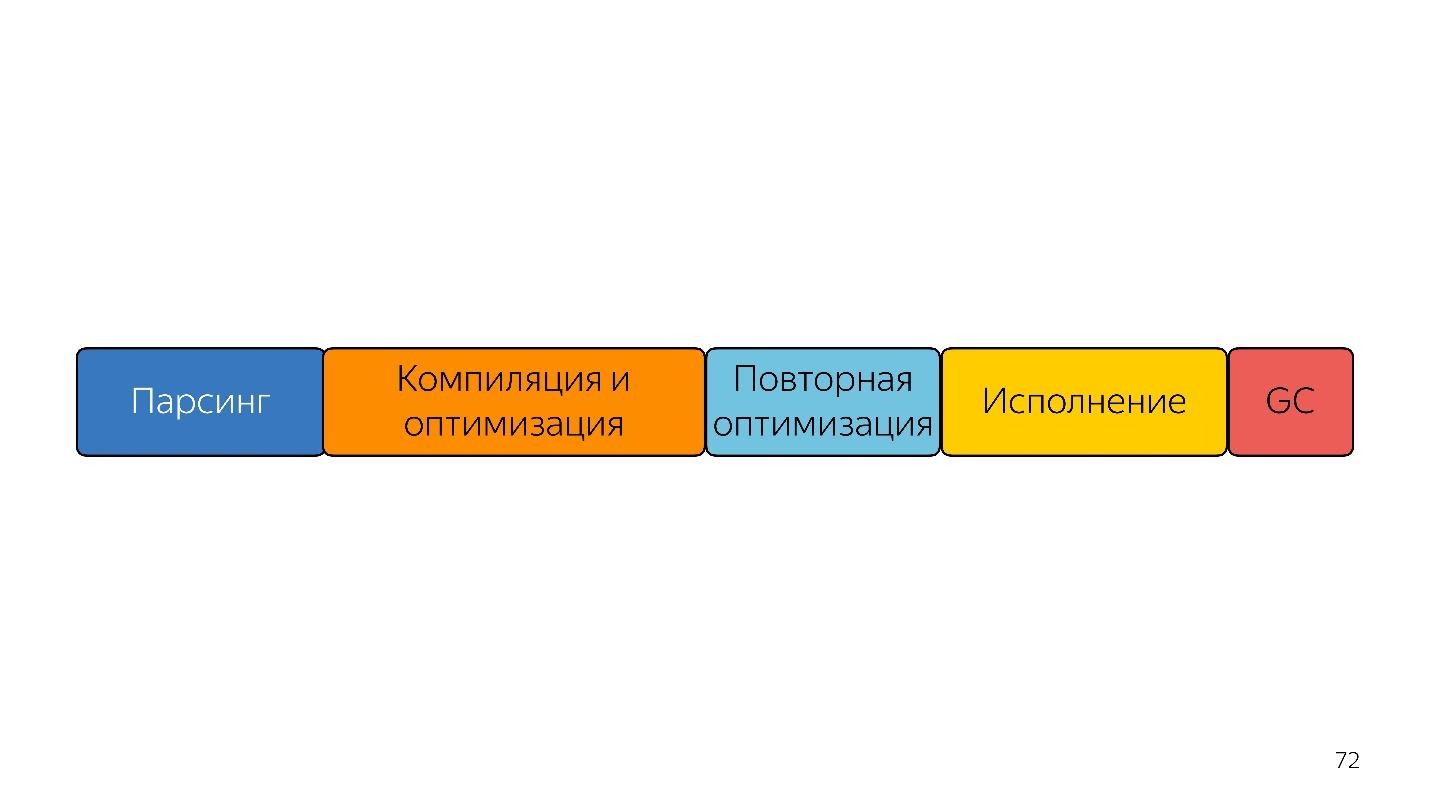
Pada baris ini, ukuran blok kira-kira terkait dalam waktu yang dibutuhkan.
Hal pertama yang terlintas dalam pikiran bagi orang-orang yang telah mendengar tentang bytecode - segera kirimkan bytecode ke input dan decode, daripada menguraikannya - akan lebih cepat!

Masalahnya adalah bahwa bytecode berbeda sekarang. Seperti yang saya katakan: di Safari satu, di FireFox yang lain, di Chrome ketiga. Meskipun demikian, pengembang dari Mozilla, Bloomberg dan Facebook telah mengajukan
Proposal semacam itu, tetapi ini adalah masa depan.
Ada masalah lain - kompilasi, optimasi, dan optimasi ulang, jika kompiler tidak menebak. Bayangkan ada bahasa yang diketik secara statis pada input yang menghasilkan kode efektif, yang berarti bahwa optimasi ulang tidak lagi diperlukan, karena apa yang kami dapatkan sudah efisien. Masukan semacam itu hanya dapat dikompilasi dan dioptimalkan satu kali. Kode yang dihasilkan akan lebih efisien dan dieksekusi lebih cepat.
Apa lagi yang bisa dilakukan? Bayangkan bahwa bahasa ini memiliki manajemen memori manual. Maka tidak perlu pemulung. Garis menjadi lebih pendek dan lebih cepat.

Coba tebak seperti apa?
WebMerkirakan sekitar
ini cara kerjanya: manajemen memori manual, diketik secara statis
bahasa dan eksekusi cepat.

Apakah WebSsembly peluru perak?

Tidak, karena ini singkatan dari JavaScript. WASM belum bisa melakukan apa pun. Dia tidak memiliki akses ke DOM API. Itu ada di dalam mesin JavaScript - di dalam mesin yang sama! Itu melakukan semuanya melalui JavaScript, jadi
WASM tidak akan mempercepat kode Anda . Ini dapat mempercepat perhitungan individual, tetapi pertukaran Anda antara JavaScript dan WASM akan menjadi hambatan.
Karena itu, sementara bahasa kita adalah JavaScript dan hanya itu, dan beberapa bantuan dari kotak hitam.
Total
Tiga jenis pengoptimalan dapat dibedakan.
●
Optimalisasi algoritmaAda sebuah artikel "
Mungkin Anda tidak perlu Rust untuk mempercepat JS Anda " oleh Vyacheslav Egorov, yang pernah mengembangkan V8 dan sekarang mengembangkan Dart. Ceritakan kembali kisahnya dengan singkat.
Ada perpustakaan JavaScript yang tidak berfungsi dengan sangat cepat. Beberapa orang menulis ulang di Rust, dikompilasi dan mendapat WebAssembly, dan aplikasi mulai bekerja lebih cepat. Vyacheslav Egorov sebagai pengembang JS berpengalaman memutuskan untuk menjawabnya. Dia menerapkan optimasi algoritmik, dan solusi JavaScript menjadi jauh lebih cepat daripada solusi Rust. Pada gilirannya, orang-orang itu melihat ini, melakukan optimasi yang sama, dan menang lagi, tetapi tidak terlalu banyak - itu tergantung pada mesin: di Mozilla mereka menang, di Chrome mereka tidak.
Hari ini kami tidak berbicara tentang optimasi algoritmik, dan render front-end biasanya tidak membicarakannya. Ini sangat buruk, karena
algoritma juga memungkinkan kode berjalan lebih cepat . Anda cukup menghapus siklus yang tidak Anda butuhkan.
●
Optimalisasi khusus bahasaInilah yang kita bicarakan hari ini: bahasa kita ditafsirkan diketik secara dinamis. Memahami cara kerja array, objek, dan monomorfisme
memungkinkan Anda menulis kode yang efisien . Ini harus diketahui dan ditulis dengan benar.
●
Optimalisasi khusus engineIni adalah optimasi yang paling berbahaya. Jika pengembang Anda sangat pintar, tetapi tidak terlalu ramah, yang menerapkan banyak optimasi seperti itu dan tidak memberi tahu siapa pun tentangnya, tidak menulis dokumentasi, maka jika Anda membuka kode, Anda tidak akan melihat JavaScript, tetapi, misalnya, Crankshaft Script. Artinya, JavaScript ditulis dengan pemahaman mendalam tentang cara kerja mesin Crankshaft dua tahun lalu. Semuanya berfungsi, tetapi sekarang tidak lagi diperlukan.
Oleh karena itu, optimasi tersebut harus didokumentasikan, ditutupi dengan tes yang membuktikan keefektifannya saat ini. Mereka harus dipantau. Anda harus mengunjungi mereka hanya pada saat Anda benar-benar melambat di suatu tempat - Anda tidak bisa melakukannya tanpa sepengetahuan perangkat yang begitu mendalam. Karena itu, frasa terkenal Donald Knuth tampaknya logis.

Tidak perlu mencoba menerapkan optimasi keras apa pun hanya karena Anda membaca ulasan positif tentangnya.
Orang harus takut dengan optimasi seperti itu, pastikan untuk mendokumentasikan dan meninggalkan metrik. Umumnya selalu mengumpulkan metrik.
Metrik itu penting!Tautan yang bermanfaat:Frontend Conf Moscow 4 5 . 15 , , :
- (KeepSolid) , Offline First Persistent Storage
- (TradingView) WebGL WebAssembly , , API .
- , Google Docs.