Pendahuluan
Beberapa waktu yang lalu, saya menjadi anggota proyek untuk mengembangkan produk perangkat lunak yang dirancang untuk menganalisis catatan pasien dan data tentang keadaan kesehatan mereka yang berasal dari organisasi medis untuk membuat rekam medis terpadu. Untuk waktu yang lama, tim tidak dapat mengembangkan pendekatan untuk menggabungkan data pasien. Titik awalnya adalah studi tentang kode sumber solusi Open EMPI (Open Enterprise Master Patient Index), yang mendorong kami untuk merangkai algoritma analisis kesamaan. Sejak saat itu, studi yang lebih mendalam tentang bahan dimulai, yang memungkinkan untuk membuat tata letak terlebih dahulu, dan kemudian solusi yang berfungsi.
Sampai sekarang, di berbagai jenis presentasi, kita harus mendengar banyak pertanyaan tentang logika karya produk tersebut, dari mana saya menyimpulkan bahwa tinjauan metode untuk menghubungkan catatan teks akan menarik bagi banyak pembaca.
Bahannya adalah terjemahan dari artikel wikipedia " Rekam tautan " dengan hak cipta dan tambahan.
Apa itu penautan teks?
Istilah " hubungan rekaman" menggambarkan proses melampirkan catatan teks dari satu sumber data ke catatan dari yang lain, asalkan mereka menggambarkan objek yang sama. Dalam ilmu komputer, ini disebut "pemetaan data" atau "masalah identitas objek" . Definisi alternatif kadang-kadang digunakan, seperti "identifikasi" , "mengikat , " deteksi duplikat " , " deduplikasi " , " catatan yang cocok " , " identifikasi objek " , yang menggambarkan konsep yang sama. Kelimpahan terminologis ini telah menyebabkan pemisahan pendekatan pemrosesan informasi dan penataan - pengikatan catatan dan pengikatan data . Meskipun keduanya menentukan identifikasi objek yang cocok dengan set parameter yang berbeda, istilah "menghubungkan catatan teks" biasanya digunakan ketika merujuk pada "esensi" seseorang, sedangkan "data menghubungkan" berarti kemungkinan menghubungkan sumber daya web apa pun antara set data, menggunakan, masing-masing, konsep yang lebih luas dari pengidentifikasi, yaitu URI.
Mengapa ini dibutuhkan?
Ketika mengembangkan produk perangkat lunak untuk membangun sistem otomatis yang digunakan dalam berbagai bidang yang terkait dengan pemrosesan data pribadi seseorang (layanan kesehatan, sejarah, statistik, pendidikan, dll.), Tugas muncul untuk mengidentifikasi data tentang mata pelajaran akuntansi yang berasal dari berbagai sumber.
Namun, ketika mengumpulkan deskripsi dari sejumlah besar sumber, muncul masalah yang membuat identifikasi mereka tidak sulit. Masalah-masalah ini meliputi:
- kesalahan ketik;
- permutasi bidang (misalnya, dengan nama depan);
- penggunaan singkatan dan singkatan;
- penggunaan format pengidentifikasi yang berbeda (tanggal, nomor dokumen, dll.).
- distorsi fonetik;
- dll.
Kualitas data mentah secara langsung mempengaruhi hasil dari proses pengikatan. Karena masalah ini, kumpulan data sering ditransfer ke pemrosesan, yang, meskipun mereka menggambarkan objek yang sama, terlihat seperti catatan ini terlihat berbeda. Oleh karena itu, di satu sisi, semua pengidentifikasi catatan yang ditransmisikan dievaluasi untuk penerapan untuk digunakan dalam proses identifikasi, dan di sisi lain, catatan itu sendiri dinormalisasi atau distandarisasi untuk membawanya ke format tunggal.
Tur sejarah
Ide asli menghubungkan catatan dikemukakan oleh Halbert L. Dunn, yang menerbitkan sebuah artikel berjudul "Catatan Tautan" dalam American Journal of Public Health pada tahun 1946.
Kemudian, pada tahun 1959, dalam sebuah artikel tentang Hubungan Otomatis dari Vital Records di majalah Science, Howard B. Newcombe meletakkan dasar probabilistik dari teori pengikatan tali modern, yang dikembangkan dan diperkuat pada tahun 1969 oleh Ivan Fellegi dan Alan Santer (Alan Sunter). Karya mereka "A Theory For Record Linkage" masih merupakan dasar matematika untuk banyak algoritma penghubung.
Perkembangan utama dari algoritma adalah di tahun 90-an abad terakhir. Kemudian, dari berbagai bidang (statistik, pengarsipan, epidemiologi, sejarah dan lain-lain), algoritma yang sering digunakan sekarang dalam produk perangkat lunak mendatangi kami, seperti kesamaan (jarak) jarak Jaro-Winkler dan jarak Levenshtein , namun, beberapa solusi, misalnya, algoritma Soundex fonetis, muncul jauh lebih awal - pada 20-an abad terakhir.
Algoritma Perbandingan Entri Teks
Bedakan antara algoritma deterministik dan probabilistik untuk membandingkan catatan teks. Algoritme deterministik didasarkan pada kebetulan lengkap atribut rekaman. Algoritma probabilistik memungkinkan untuk menghitung tingkat korespondensi atribut rekaman dan, berdasarkan ini, memutuskan kemungkinan hubungan mereka.
Algoritma Deterministik
Cara termudah untuk membandingkan string didasarkan pada aturan yang jelas ketika tautan antara objek dihasilkan berdasarkan jumlah kecocokan atribut dari kumpulan data. Yaitu, dua catatan saling berhubungan satu sama lain melalui algoritma deterministik jika semua atau beberapa atributnya identik. Algoritme deterministik cocok untuk membandingkan subjek yang dideskripsikan dengan serangkaian data yang diidentifikasi oleh pengidentifikasi umum (misalnya, nomor Asuransi dari akun pribadi perorangan di Dana Pensiun - SNILS) atau memiliki beberapa pengidentifikasi representatif (tanggal lahir, jenis kelamin, dll.) Yang dapat dipercaya.
Algoritme deterministik dapat diterapkan ketika set data terstruktur (terstandarisasi) ditransfer ke pemrosesan.
Misalnya, ia memiliki serangkaian entri teks berikut:
| Tidak. | GAGAL | Nama depan | Tanggal lahir | Gender |
|---|
| A1 | 163-648-564 96 | Zhvanetsky Mikhail | 03/06/1934 | M. |
| A2 | 163-648-564 96 | Zhvanetsky Mikhail | 03/06/1934 | M. |
| A3 | 126-029-036 24 | Ilchenko Victor | 01/02/1937 | M. |
| A4 | | Novikova Klara | 12.26.1946 | F |
| Tidak. | GAGAL | Nama depan | Tanggal lahir | Gender |
|---|
| B1 | 126-029-036 24 | Ilyichenko Victor | 01/02/1937 | M. |
| B2 | | Zhivanetsky Mikhail | 03/06/1934 | M. |
| B3 | | Zerchaninova Klara | 12.26.1946 | 2 |
Sebelumnya dikatakan bahwa algoritma deterministik yang paling sederhana adalah penggunaan pengidentifikasi unik, yang seharusnya mengidentifikasi seseorang secara unik. Sebagai contoh, kami mengasumsikan bahwa semua catatan yang memiliki nilai pengidentifikasi yang sama (SNILS) menggambarkan subjek yang sama, jika tidak mereka adalah subyek yang berbeda. Koneksi deterministik dalam hal ini akan menghasilkan pasangan berikut: A1 dan A2, A3 dan B1. B2 tidak akan dikaitkan dengan A1 dan A2, karena pengidentifikasi tidak masalah, meskipun bertepatan konten dengan catatan yang ditentukan.
Pengecualian ini mengarah pada kebutuhan untuk melengkapi algoritma deterministik dengan aturan baru. Misalnya, jika tidak ada pengidentifikasi unik, Anda dapat menggunakan atribut lain seperti nama, tanggal lahir, dan jenis kelamin. Dalam contoh yang diberikan, aturan tambahan ini lagi tidak akan memberikan korespondensi B2 dan A1 / A2, karena sekarang namanya berbeda - ada distorsi fonetik dari nama keluarga.
Masalah ini dapat diselesaikan dengan menggunakan metode analisis fonetik, tetapi jika Anda mengubah nama keluarga (misalnya, dalam kasus pernikahan), Anda harus menggunakan aplikasi aturan baru, misalnya, membandingkan tanggal lahir atau untuk memungkinkan perbedaan dalam atribut yang tersedia dari catatan (misalnya, jenis kelamin).
Contoh dengan jelas menggambarkan bahwa algoritma deterministik sangat sensitif terhadap kualitas data, dan peningkatan jumlah atribut rekaman dapat menyebabkan peningkatan substansial dalam jumlah aturan yang diterapkan, yang sangat menyulitkan penggunaan algoritma deterministik.
Selain itu, penggunaan algoritma deterministik dimungkinkan jika ada kumpulan data yang diverifikasi (referensi utama) yang digunakan untuk membandingkan informasi yang masuk. Namun, dalam kasus pengisian ulang direktori master itu sendiri secara konstan, diperlukan perbaikan menyeluruh dari hubungan yang ada, yang membuat penggunaan algoritma deterministik memakan waktu atau tidak mungkin.
Algoritma Probabilistik
Algoritma probabilistik untuk menghubungkan catatan string menggunakan serangkaian atribut yang lebih luas daripada yang deterministik, dan untuk setiap atribut dihitung koefisien bobot yang menentukan kemampuan untuk mempengaruhi koneksi dalam penilaian akhir tentang kemungkinan kesesuaian catatan yang diperkirakan. Catatan yang memiliki akumulasi berat total di atas ambang tertentu dianggap terkait, catatan yang telah mengumpulkan berat total di bawah ambang batas dianggap tidak terkait. Pasangan yang telah mendapatkan nilai bobot total dari tengah kisaran dianggap sebagai kandidat untuk dihubungkan dan dapat dipertimbangkan kemudian (misalnya, oleh operator), yang akan memutuskan serikat mereka (tautan) atau membiarkannya tidak terikat. Dengan demikian, tidak seperti algoritma deterministik, yang merupakan seperangkat sejumlah besar aturan yang jelas (terprogram), algoritma probabilistik dapat disesuaikan dengan kualitas data dengan memilih nilai ambang dan tidak memerlukan pemrograman ulang.
Jadi, algoritma probabilistik menetapkan koefisien bobot ( u dan m ) untuk atribut catatan, dengan bantuan yang korespondensi atau ketidakkonsistenan satu sama lain akan ditentukan.
Koefisien u menentukan probabilitas bahwa pengidentifikasi dari dua catatan independen bertepatan secara acak. Misalnya, probabilitas u bulan kelahiran (ketika ada dua belas nilai yang terdistribusi seragam) adalah 1 \ 12 = 0,083. Pengidentifikasi dengan nilai yang tidak terdistribusi secara merata akan memiliki probabilitas berbeda untuk nilai yang berbeda (kadang-kadang, termasuk nilai yang hilang).
Koefisien m adalah probabilitas bahwa pengidentifikasi dalam pasangan yang dibandingkan saling bersesuaian atau sangat mirip - misalnya, dalam kasus probabilitas tinggi oleh algoritma Jaro-Winkler atau rendah oleh algoritma Levenshtein. Jika atribut catatan sepenuhnya konsisten, nilai ini harus memiliki nilai 1,0, tetapi mengingat probabilitasnya yang rendah, koefisien harus dievaluasi secara berbeda. Penilaian ini dapat dilakukan atas dasar analisis awal dari kumpulan data, misalnya, dengan secara manual “mempelajari” algoritma probabilistik untuk mengidentifikasi sejumlah besar pasangan yang cocok dan tidak cocok atau dengan meluncurkan algoritma secara iteratif untuk memilih nilai koefisien-m yang paling cocok.
Jika probabilitas-m didefinisikan sebagai 0,95, maka koefisien kepatuhan / tidak-kepatuhan untuk bulan kelahiran akan terlihat seperti ini:
| Metrik | Bagikan tautan | Bagikan nilai, bukan referensi | Frekuensi | Berat |
|---|
| Kepatuhan | m = 0,95 | u = 0,083 | m \ u = 11.4 | Dalam (m / u) / ln (2) ≈ 3.51 |
| Ketidakcocokan | 1-m = 0,05 | 1-u = 0,917 | (1-m) / (1-u) ≈ 0,0545 | ln ((1-m) / (1-u)) / ln (2) ≈ -4.20 |
Perhitungan serupa harus dibuat untuk pengidentifikasi rekaman lain untuk menentukan koefisien kepatuhan dan ketidakpatuhan mereka. Kemudian, masing-masing pengidentifikasi dari satu rekaman dibandingkan dengan pengidentifikasi yang sesuai dari catatan lain untuk menentukan berat total pasangan: berat pasangan yang sesuai ditambahkan ke hasil total dengan total kumulatif, sedangkan berat pasangan yang tidak tepat dikurangkan dari total hasil. Jumlah yang dihasilkan dibandingkan dengan nilai ambang batas yang diidentifikasi untuk menentukan apakah akan memasangkan pasangan yang dianalisis secara otomatis atau mentransfernya ke operator untuk dipertimbangkan.
Memblokir
Penentuan ambang kepatuhan / ketidakpatuhan adalah keseimbangan antara memperoleh sensitivitas yang dapat diterima (bagian catatan terkait yang terdeteksi oleh algoritma) dan nilai prediksi hasil (mis. Akurasi, sebagai ukuran catatan yang benar-benar cocok yang dihubungkan oleh algoritma). Karena mendefinisikan ambang batas bisa menjadi tugas yang sangat sulit, terutama untuk set data besar, metode yang dikenal sebagai pemblokiran sering digunakan untuk meningkatkan efisiensi komputasi. Upaya dilakukan untuk melakukan perbandingan antara catatan yang perbedaannya signifikan ( diskriminasi ) dalam nilai atribut dasar diungkapkan. Ini mengarah pada peningkatan akurasi karena penurunan sensitivitas.
Misalnya, penguncian berdasarkan pengkodean fonetik dari nama keluarga mengurangi jumlah total perbandingan yang diperlukan dan meningkatkan kemungkinan bahwa hubungan antara catatan akan benar, karena dua atribut sudah konsisten, tetapi berpotensi melewatkan catatan yang terkait dengan orang yang sama dengan nama keluarga berubah (misalnya, sebagai hasil dari pernikahan). Pemblokiran berdasarkan bulan kelahiran adalah indikator yang lebih stabil yang hanya dapat disesuaikan jika ada kesalahan dalam data sumber, tetapi memberikan manfaat yang lebih sederhana dalam nilai prediksi positif dan hilangnya sensitivitas, karena hal itu menciptakan dua belas kelompok kumpulan data yang sangat besar dan tidak mengarah pada peningkatan kecepatan. komputasi.
Dengan demikian, sistem penghubung entri teks yang paling efisien sering menggunakan beberapa lintasan pemblokiran untuk mengelompokkan data dengan berbagai cara untuk mempersiapkan kelompok catatan yang nantinya harus diserahkan untuk dianalisis.
Pembelajaran mesin
Baru-baru ini, berbagai metode pembelajaran mesin telah digunakan untuk menghubungkan catatan teks. Dalam makalah 2011, Randall Wilson menunjukkan bahwa algoritma klasik menghubungkan probabilistik untuk catatan teks setara dengan algoritma Bayes naif dan menderita masalah yang sama dari asumsi bahwa fitur klasifikasi independen. Untuk meningkatkan akurasi analisis, penulis mengusulkan untuk menggunakan model dasar jaringan saraf yang disebut perceptron lapisan tunggal, yang penggunaannya memungkinkan seseorang untuk secara signifikan melebihi hasil yang diperoleh dengan menggunakan algoritma probabilistik tradisional.
Pengkodean Fonetik
Algoritma fonetik cocok dengan dua kata yang diucapkan sama dengan kode yang sama, yang memungkinkan Anda untuk membandingkan kata-kata tersebut berdasarkan kesamaan fonetisnya.
Sebagian besar algoritma fonetik dirancang untuk menganalisis kata-kata bahasa Inggris, meskipun baru-baru ini beberapa algoritma telah dimodifikasi untuk digunakan dengan bahasa lain, atau pada awalnya dibuat sebagai solusi nasional (misalnya, Caverphone).
Soundex
Algoritma klasik untuk membandingkan dua string oleh suara mereka adalah Soundex (kependekan dari Sound index). Ini menetapkan kode yang sama untuk string yang memiliki suara serupa dalam bahasa Inggris. Soundex pada awalnya digunakan oleh Administrasi Arsip Nasional AS pada 1930-an untuk secara retrospektif menganalisis sensus dari tahun 1890 hingga 1920.
Para penulis algoritma adalah Robert C. Russel dan Margaret King Odell, yang mematenkannya di tahun 20-an abad terakhir. Algoritme itu sendiri mendapatkan popularitas pada paruh kedua abad terakhir ketika menjadi subjek dari beberapa artikel di jurnal sains populer di Amerika Serikat dan diterbitkan dalam monograf D. Knut "The Art of Programming".
Daitch-Mokotoff Soundex
Karena Soundex hanya cocok untuk bahasa Inggris, beberapa peneliti telah berusaha untuk memodifikasinya. Pada tahun 1985, Gary Mokotoff dan Randy Daitch mengusulkan varian dari algoritma Soundex, yang dirancang untuk membandingkan nama keluarga Eropa Timur (termasuk Rusia) dengan kualitas yang cukup tinggi.
Pada tahun 90-an, Lawrence Philips (Lawrence Philips) mengusulkan versi alternatif dari algoritma Soundex, yang disebut Metaphone. Algoritma baru menggunakan seperangkat aturan yang lebih besar untuk pengucapan bahasa Inggris karena lebih akurat. Kemudian, algoritma tersebut dimodifikasi untuk digunakan dalam bahasa lain berdasarkan transkripsi menggunakan huruf-huruf alfabet Latin.
Pada tahun 2002, edisi ke-8 majalah Programmer menerbitkan sebuah artikel oleh Peter Kankowski yang menceritakan tentang adaptasinya terhadap versi bahasa Inggris dari algoritma Metaphone. Versi algoritma ini mengubah kata-kata sumber sesuai dengan aturan dan norma-norma bahasa Rusia, dengan mempertimbangkan suara fonetik dari huruf-huruf vokal yang tidak ditekan dan kemungkinan "penggabungan" konsonan dalam pengucapan.
Alih-alih sebuah kesimpulan
Sebagai hasil dari beberapa iterasi, tim proyek dari proyek pengembangan produk perangkat lunak, yang disebutkan dalam pendahuluan, mengembangkan solusi arsitektur, skema yang ditunjukkan pada gambar.
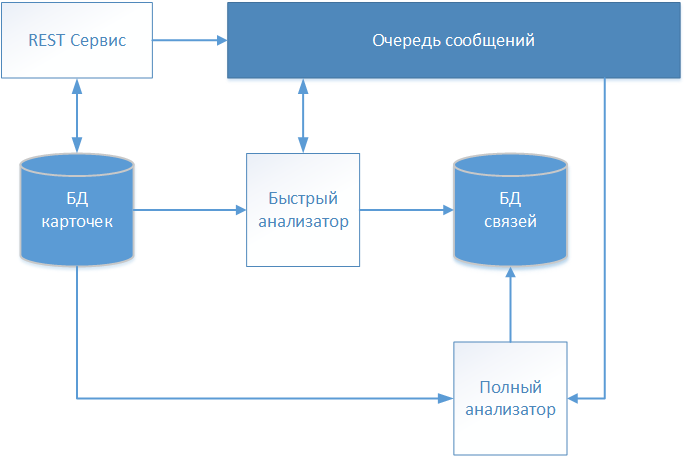
Deskripsi tekstual pasien diterima melalui layanan REST dan disimpan dalam repositori (basis data kartu) tanpa perubahan apa pun. Karena sistem kami bekerja dengan data medis, standar FHIR (Fast Healthcare Interoperability Resources) dipilih untuk pertukaran informasi. Informasi tentang kartu pasien yang diterima ditransfer ke antrian pesan untuk analisis lebih lanjut dan pengambilan keputusan dalam menjalin komunikasi.
Kartu pertama yang diproses adalah "Penganalisis Cepat" yang beroperasi pada algoritma deterministik. Jika semua aturan algoritma deterministik berhasil, maka ia akan membuat catatan dengan tautan ke kartu yang diproses dalam penyimpanan terpisah (tautan basis data). Catatan tersebut berisi tambahan untuk pengidentifikasi kartu yang dianalisis, tanggal pendirian komunikasi dan pengidentifikasi bersyarat yang mengidentifikasi pasien yang diidentifikasi secara global. Kartu lebih lanjut selanjutnya disebut pengenal global yang ditentukan, sehingga membentuk sebuah array yang menggambarkan individu tertentu.
Jika algoritma deterministik tidak menemukan kecocokan, maka informasi kartu ditransmisikan melalui antrian pesan ke "Full Analyzer".
( ). . :

1. -
, . 2.
2.
- , ().
3.
, , ( ) , .
4.
, . . , , . , , , .