Hanya sedikit orang yang memiliki Glaster di Rusia, dan pengalaman apa pun menarik. Kami memilikinya besar dan industri dan, dilihat dari diskusi di
posting terakhir , laris. Saya berbicara tentang awal pengalaman memigrasikan cadangan dari penyimpanan Enterprise ke Glusterfs.
Ini tidak cukup hardcore. Kami tidak berhenti dan memutuskan untuk mengumpulkan sesuatu yang lebih serius. Oleh karena itu, di sini kita akan berbicara tentang hal-hal seperti pengkodean penghapusan, pengabaian, penyeimbangan kembali dan pelambatannya, pengujian tekanan dan sebagainya.

- Lebih banyak teori volum / subwolum
- cadangan panas
- menyembuhkan / menyembuhkan penuh / menyeimbangkan kembali
- Kesimpulan setelah reboot 3 node (tidak pernah melakukan ini)
- Bagaimana cara merekam dengan kecepatan berbeda dari VM yang berbeda dan on / off shard mempengaruhi beban subvolume?
- menyeimbangkan kembali setelah kepergian disk
- penyeimbangan kembali cepat
Apa yang kamu inginkan
Tugasnya sederhana: untuk mengumpulkan toko yang murah tapi dapat diandalkan. Murah mungkin, dapat diandalkan - sehingga tidak menakutkan untuk menyimpan file kita sendiri untuk dijual. Sampai jumpa. Kemudian, setelah tes panjang dan cadangan ke sistem penyimpanan lain - juga yang klien.
Aplikasi (IO berurutan) :
- Cadangan
- Uji infrastruktur
- Uji penyimpanan untuk file media berat.
Kita disini
- File pertempuran dan infrastruktur pengujian serius
- Penyimpanan untuk data penting.
Seperti terakhir kali, persyaratan utama adalah kecepatan jaringan antara instance Glaster. 10G pada awalnya baik-baik saja.
Teori: apa volume terdispersi?
Volume yang didistribusikan didasarkan pada teknologi erasure coding (EC), yang memberikan perlindungan yang cukup efektif terhadap kegagalan disk atau server. Ini seperti RAID 5 atau 6, tetapi tidak juga. Ia menyimpan fragmen yang disandikan dari file untuk setiap bata sedemikian rupa sehingga hanya sebagian dari fragmen yang disimpan dalam briks yang tersisa diperlukan untuk mengembalikan file. Jumlah batu bata yang mungkin tidak tersedia tanpa kehilangan akses ke data dikonfigurasikan oleh administrator selama pembuatan volume.
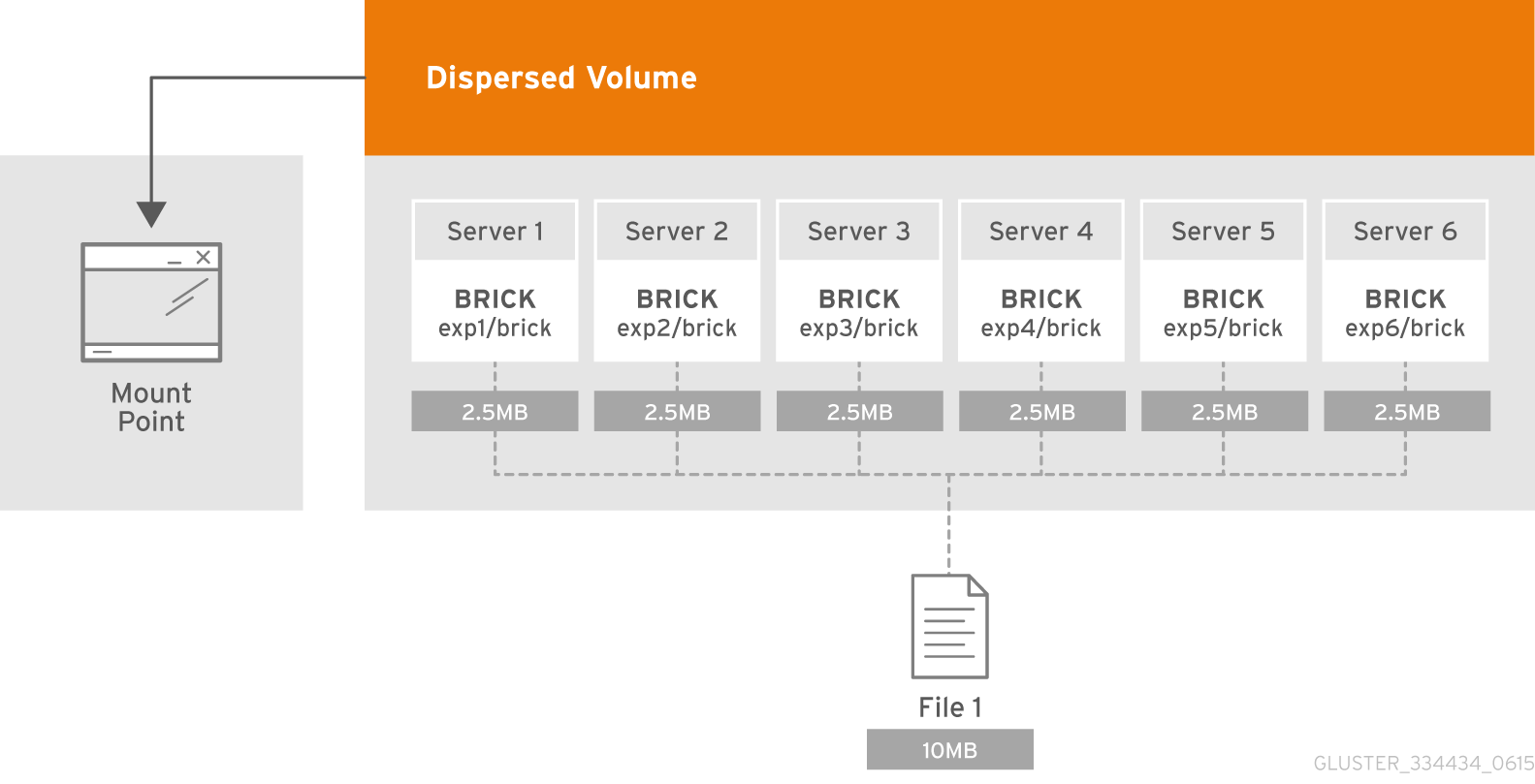
Apa itu subvolume?
Esensi dari subvolume dalam terminologi GlusterFS dimanifestasikan bersama dengan volume yang didistribusikan. Dalam coding penghapusan terdistribusi-disperced akan bekerja hanya dalam kerangka subwoofer. Dan dalam hal ini, misalnya, dengan data terdistribusi-direplikasi akan direplikasi dalam kerangka subwoofer.
Masing-masing didistribusikan pada server yang berbeda, yang memungkinkan mereka untuk secara bebas kehilangan atau menyinkronkan output. Pada gambar, server (fisik) ditandai dengan warna hijau, subwolves bertitik. Masing-masing disajikan sebagai disk (volume) ke server aplikasi:

Diputuskan bahwa konfigurasi 4 + 2 yang terdistribusi tersebar pada 6 node terlihat cukup andal, kita bisa kehilangan 2 server atau 2 disk dalam setiap subwoofer, sambil terus memiliki akses ke data.
Kami memiliki 6 DELL PowerEdge R510 tua dengan 12 slot disk dan 48x2TB 3,5 drive SATA. Pada prinsipnya, jika ada server dengan 12 slot disk, dan memiliki hingga 12 TB drive di pasaran, kami dapat mengumpulkan penyimpanan hingga 576 TB ruang yang dapat digunakan. Tetapi jangan lupa bahwa meskipun ukuran HDD maksimum terus tumbuh dari tahun ke tahun, kinerjanya tetap diam dan pembangunan kembali disk 10-12TB dapat membawa Anda seminggu.
 Pembuatan volume:
Pembuatan volume:Penjelasan terperinci tentang cara menyiapkan batu bata, dapat Anda baca di
posting saya
sebelumnyagluster volume create freezer disperse-data 4 redundancy 2 transport tcp \ $(for i in {0..7} ; do echo {sl051s,sl052s,sl053s,sl064s,sl075s,sl078s}:/export/brick$i/freezer ; done)
Kami membuat, tetapi kami tidak terburu-buru untuk meluncurkan dan memasang, karena kami masih harus menerapkan beberapa parameter penting.
Apa yang kita dapatkan: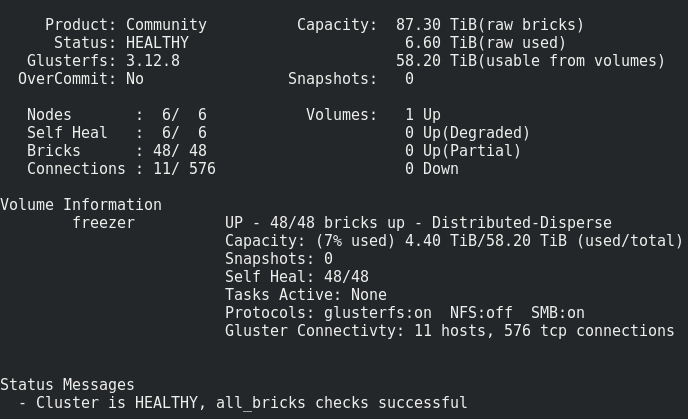
Semuanya terlihat cukup normal, tetapi ada satu peringatan.
Terdiri dari rekaman volume seperti itu pada batu bata:File ditempatkan satu per satu di subwolves, dan tidak tersebar merata di mereka, oleh karena itu, cepat atau lambat kita akan lari ke ukurannya, dan bukan ukuran seluruh volume. Ukuran file maksimum yang dapat kita tempatkan dalam repositori ini adalah ukuran subwoofer yang dapat digunakan dikurangi ruang yang sudah ditempati di dalamnya. Dalam kasus saya, ini <8 Tb.
Apa yang harus dilakukan Bagaimana menjadi?Masalah ini diselesaikan dengan volume beling atau garis, tetapi, seperti yang telah ditunjukkan oleh praktik, garis bekerja sangat buruk.
Karena itu, kami akan mencoba sharding.
Apa yang sharding, secara detail di sini .
Singkatnya, apa yang sharding :
Setiap file yang Anda masukkan ke dalam volume akan dibagi menjadi beberapa bagian (pecahan), yang secara relatif diatur dalam subwolves. Ukuran beling ditentukan oleh administrator, nilai standarnya adalah 4 MB.
Hidupkan sharding setelah membuat volume, tetapi sebelum dimulai :
gluster volume set freezer features.shard on
Kami mengatur ukuran beling (yang optimal? Dudes dari oVirt merekomendasikan 512MB) :
gluster volume set freezer features.shard-block-size 512MB
Secara empiris, ternyata ukuran sebenarnya dari pecahan dalam batu bata ketika menggunakan volume terdispersi 4 + 2 sama dengan ukuran blok-shard / 4, dalam kasus kami 512M / 4 = 128M.
Setiap pecahan sesuai dengan logika pengkodean erasure didekomposisi sesuai dengan batu bata dalam kerangka dunia bawah dengan potongan-potongan ini: 4 * 128M + 2 * 128M
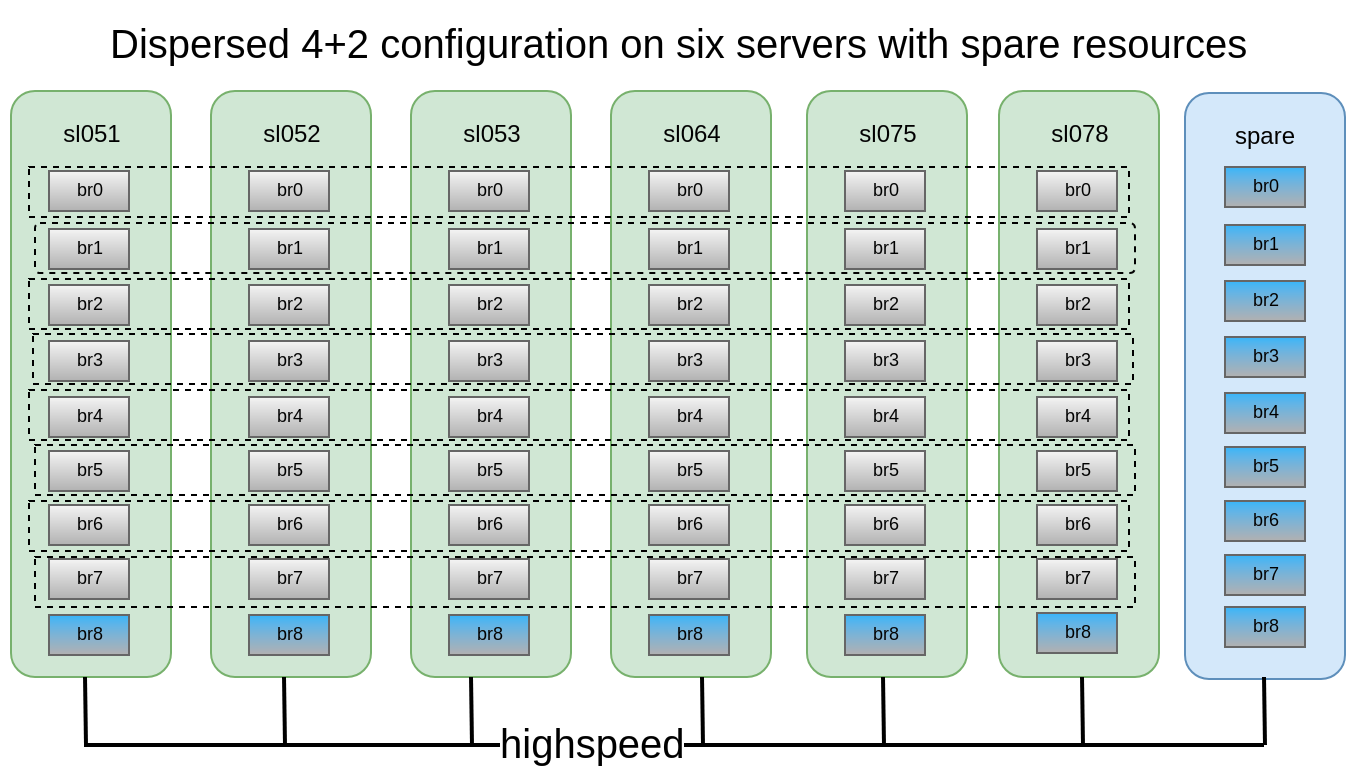
Gambar kasus kegagalan yang gluster bertahan dengan konfigurasi ini:Dalam konfigurasi ini, kita dapat selamat dari jatuhnya 2 node atau 2 disk apa pun dalam subvolume yang sama.
Untuk pengujian, kami memutuskan untuk menyelipkan penyimpanan yang dihasilkan di bawah cloud kami dan menjalankan fio dari mesin virtual.
Kami mengaktifkan rekaman berurutan dari 15 VM dan melakukan hal berikut.
Reboot dari node 1:17:09
Itu terlihat tidak kritis (~ 5 detik tidak tersedianya parameter ping.timeout).
17:19
Diluncurkan menyembuhkan penuh.
Jumlah entri penyembuhan hanya bertambah, mungkin karena tingginya tingkat penulisan ke cluster.
17:32
Diputuskan untuk mematikan rekaman dari VM.
Jumlah entri penyembuhan mulai menurun.
17:50
sembuh sudah selesai.
Mulai ulang 2 node:Hasil yang sama diamati seperti pada simpul ke-1.Mulai ulang 3 node:Titik akhir yang dikeluarkan Titik akhir transportasi tidak terhubung, VM menerima ioerror.
Setelah menyalakan node, Glaster memulihkan diri, tanpa gangguan dari pihak kami, dan proses perawatan dimulai.Tapi 4 dari 15 VM tidak bisa naik. Saya melihat kesalahan pada hypervisor:
2018.04.27 13:21:32.719 ( volumes.py:0029): I: Attaching volume vol-BA3A1BE1 (/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1) with attach type generic... 2018.04.27 13:21:32.721 ( qmp.py:0166): D: Querying QEMU: __com.redhat_drive_add({'file': u'/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1', 'iops_rd': 400, 'media': 'disk', 'format': 'qcow2', 'cache': 'none', 'detect-zeroes': 'unmap', 'id': 'qdev_1k7EzY85TIWm6-gTBorE3Q', 'iops_wr': 400, 'discard': 'unmap'})... 2018.04.27 13:21:32.784 ( instance.py:0298): E: Failed to attach volume vol-BA3A1BE1 to the instance: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized Traceback (most recent call last): File "/usr/lib64/python2.7/site-packages/ic/instance.py", line 292, in emulation_started c2.qemu.volumes.attach(controller.qemu(), device) File "/usr/lib64/python2.7/site-packages/c2/qemu/volumes.py", line 36, in attach c2.qemu.query(qemu, drive_meth, drive_args) File "/usr/lib64/python2.7/site-packages/c2/qemu/_init_.py", line 247, in query return c2.qemu.qmp.query(qemu.pending_messages, qemu.qmp_socket, command, args, suppress_logging) File "/usr/lib64/python2.7/site-packages/c2/qemu/qmp.py", line 194, in query message["error"].get("desc", "Unknown error") QmpError: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized qemu-img: Could not open '/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1': Could not read image for determining its format: Input/output error
Sulit melunasi 3 node dengan sharding dimatikan Transport endpoint is not connected (107) /GLU/volumes/e0/e0bf9a42-8915-48f7-b509-2f6dd3f17549: ERROR: cannot read (Input/output error)
Kami juga kehilangan data, tidak mungkin untuk memulihkan.
Bayar 3 node dengan sharding dengan lembut, apakah akan ada kerusakan data?Ada, tetapi jauh lebih sedikit (kebetulan?), Saya kehilangan 3 dari 30 drive.
Kesimpulan:- Sembuhkan file-file ini hang tanpa henti, penyeimbangan kembali tidak membantu. Kami menyimpulkan bahwa file yang merekam aktif terjadi ketika simpul ke-3 dimatikan hilang selamanya.
- Jangan pernah memuat ulang lebih dari 2 node dalam konfigurasi 4 + 2 dalam produksi!
- Bagaimana tidak kehilangan data jika Anda benar-benar ingin me-reboot 3+ node? P Berhenti merekam pada titik pemasangan dan / atau menghentikan volume.
- Node atau bata harus diganti sesegera mungkin. Untuk ini, sangat diinginkan untuk memiliki, misalnya, 1-2 a la batu bata cadangan panas di setiap simpul untuk penggantian cepat. Dan satu lagi node cadangan dengan batu bata dalam kasus dump node.
Penting juga untuk menguji kasus penggantian drive
Keberangkatan briks (disk):
17:20Kami merobohkan bata:
/dev/sdh 1.9T 598G 1.3T 33% /export/brick6
17:22 gluster volume replace-brick freezer sl051s:/export/brick_spare_1/freezer sl051s:/export/brick2/freezer commit force
Anda dapat melihat penarikan seperti itu pada saat mengganti bata (catatan dari 1 sumber):

Proses penggantian cukup lama, dengan tingkat perekaman kecil per kluster dan pengaturan default 1 TB, dibutuhkan sekitar satu hari untuk pulih.
Parameter yang dapat disesuaikan untuk perawatan: gluster volume set cluster.background-self-heal-count 20
Opsi: disperse.background-heals
Nilai Default: 8
Deskripsi: Opsi ini dapat digunakan untuk mengontrol jumlah penyembuhan paralel
Opsi: disperse.heal-wait-qlength
Nilai Default: 128
Deskripsi: Opsi ini dapat digunakan untuk mengontrol jumlah penyembuhan yang bisa menunggu
Opsi: disperse.shd-max-uts
Nilai Default: 1
Deskripsi: Jumlah maksimum penyembuhan paralel yang bisa dilakukan SHD per bata lokal. Ini secara substansial dapat menurunkan waktu penyembuhan, tetapi juga dapat menghancurkan batu bata Anda jika Anda tidak memiliki perangkat keras penyimpanan untuk mendukung ini.
Opsi: disperse.shd-wait-qlength
Nilai Default: 1024
Deskripsi: Opsi ini dapat digunakan untuk mengontrol jumlah penyembuhan yang bisa menunggu dalam SHD per subvolume
Opsi: disperse.cpu-extensions
Nilai Default: otomatis
Deskripsi: memaksa ekstensi cpu untuk digunakan untuk mempercepat perhitungan bidang galois.
Opsi: disperse.self-heal-window-size
Nilai Default: 1
Deskripsi: Blok angka maksimum (128KB) per file yang proses penyembuhan sendiri akan diterapkan secara bersamaan.Berdiri:
disperse.shd-max-threads: 6 disperse.self-heal-window-size: 4 cluster.self-heal-readdir-size: 2KB cluster.data-self-heal-algorithm: diff cluster.self-heal-window-size: 2 cluster.heal-timeout: 500 cluster.background-self-heal-count: 20 cluster.disperse-self-heal-daemon: enable disperse.background-heals: 18
Dengan parameter baru, 1 TB data selesai dalam 8 jam (3 kali lebih cepat!)
Momen yang tidak menyenangkan adalah bahwa hasilnya adalah brik yang lebih besar daripada sebelumnyaadalah: Filesystem Size Used Avail Use% Mounted on /dev/sdd 1.9T 645G 1.2T 35% /export/brick2
menjadi: Filesystem Size Used Avail Use% Mounted on /dev/sdj 1.9T 1019G 843G 55% /export/hot_spare_brick_0
Ini perlu dipahami. Mungkin masalahnya adalah menggembungkan cakram tipis. Dengan penggantian berikutnya dari peningkatan bata, ukurannya tetap sama.
Penyeimbangan ulang:Setelah memperluas atau mengecilkan (tanpa memigrasi data) volume (menggunakan perintah add-brick dan remove-brick masing-masing), Anda perlu menyeimbangkan kembali data di antara server. Dalam volume non-direplikasi, semua batu bata harus bangun untuk melakukan operasi penggantian bata (opsi mulai). Dalam volume yang direplikasi, setidaknya salah satu bata di replika harus naik.Membentuk penyeimbangan kembali:Opsi: cluster.rebal-throttle
Nilai Default: normal
Deskripsi: Menetapkan jumlah maksimum migrasi file paralel yang diizinkan pada sebuah node selama operasi penyeimbangan kembali. Nilai default adalah normal dan memungkinkan maksimal file [($ (unit pemrosesan) - 4) / 2), 2] ke
Kami bermigrasi pada satu waktu. Malas hanya akan memungkinkan satu file untuk dimigrasi pada satu waktu dan agresif akan memungkinkan maksimum [($ (unit pemrosesan) - 4) / 2), 4]Opsi: cluster.lock-migrasi
Nilai Default: tidak aktif
Deskripsi: Jika diaktifkan, fitur ini akan memigrasi kunci posix yang terkait dengan file selama penyeimbangan kembaliOpsi: cluster.weighted-rebalance
Nilai Default: pada
Deskripsi: Saat diaktifkan, file akan dialokasikan ke batu bata dengan probabilitas yang sebanding dengan ukurannya. Kalau tidak, semua batu bata akan memiliki probabilitas yang sama (perilaku warisan).Perbandingan penulisan, dan kemudian membaca parameter fio yang sama (hasil tes kinerja lebih rinci - dalam PM): fio --fallocate=keep --ioengine=libaio --direct=1 --buffered=0 --iodepth=1 --bs=64k --name=test --rw=write/read --filename=/dev/vdb --runtime=6000


 Jika menarik, bandingkan kecepatan rsync dengan lalu lintas ke node Glaster:
Jika menarik, bandingkan kecepatan rsync dengan lalu lintas ke node Glaster: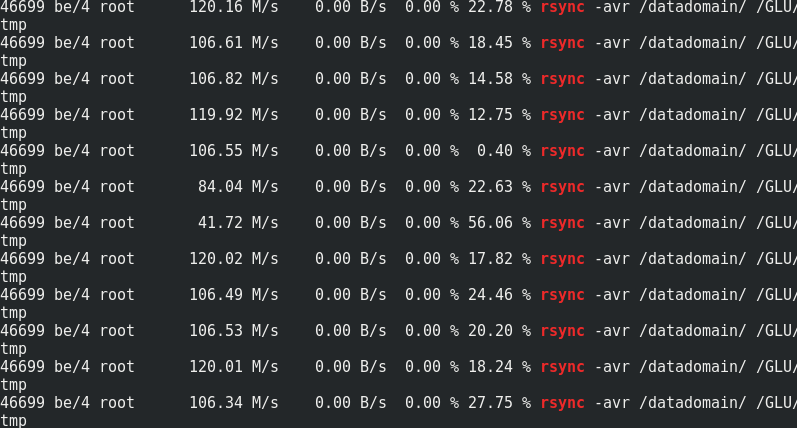
 Dapat dilihat bahwa sekitar 170 MB / s / traffic hingga 110 MB / s / payload. Ternyata ini adalah 33% dari lalu lintas tambahan, serta 1/3 dari redundansi Coding Erasure.Konsumsi memori di sisi server dengan dan tanpa memuat tidak berubah:
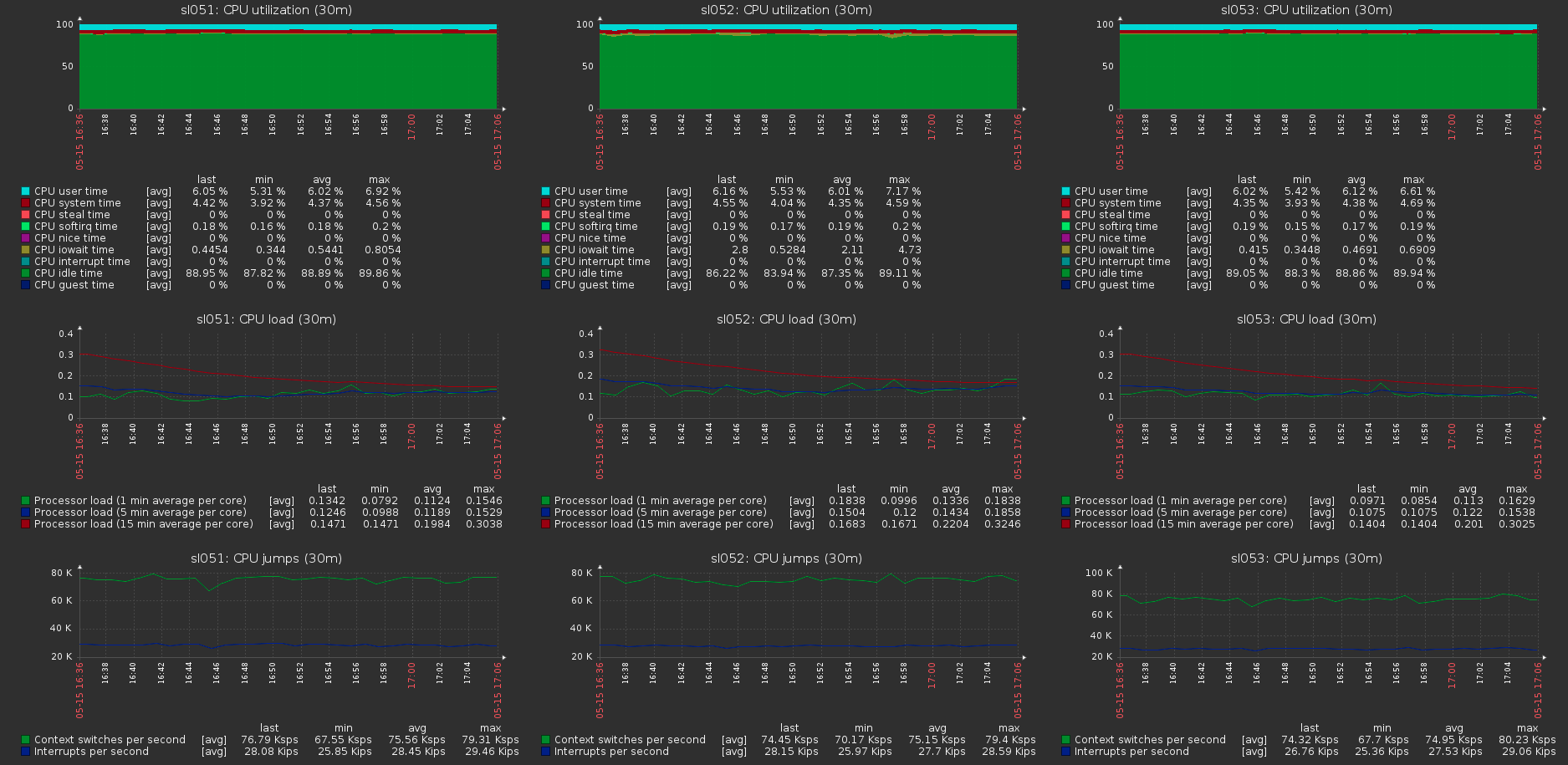
Dapat dilihat bahwa sekitar 170 MB / s / traffic hingga 110 MB / s / payload. Ternyata ini adalah 33% dari lalu lintas tambahan, serta 1/3 dari redundansi Coding Erasure.Konsumsi memori di sisi server dengan dan tanpa memuat tidak berubah: Beban pada host cluster dengan beban maksimum pada volume:
Beban pada host cluster dengan beban maksimum pada volume: