Halo semuanya! Nama saya Misha Kamenshchikov, saya terlibat dalam Ilmu Data dan pengembangan layanan mikro di tim rekomendasi Avito. Dalam artikel ini, saya akan berbicara tentang rekomendasi kami untuk iklan serupa dan bagaimana kami memperbaikinya dengan bandit multi-bersenjata. Saya membuat presentasi tentang topik ini di konferensi Highload ++ Siberia dan di acara "Data & Sains: Pemasaran" .

Garis besar artikel
Rekomendasi tentang Avito
Pertama, gambaran singkat tentang semua jenis rekomendasi yang ada di Avito.
Rekomendasi Barang Pengguna yang Dipersonalisasi
Rekomendasi Barang Pengguna didasarkan pada tindakan pengguna dan dirancang untuk membantunya dengan cepat menemukan produk yang diminati, atau menunjukkan sesuatu yang berpotensi menarik. Mereka dapat dilihat di halaman utama situs dan aplikasi atau di milis. Untuk membuat rekomendasi semacam itu, kami menggunakan dua jenis model: offline dan online.
Model offline didasarkan pada algoritma faktorisasi matriks yang dilatih pada semua data dalam beberapa hari, dan rekomendasinya disimpan dalam repositori cepat untuk didistribusikan kepada pengguna. Model online mempertimbangkan rekomendasi dengan cepat menggunakan konten iklan dari riwayat pengguna. Keuntungan dari model offline adalah mereka memberikan rekomendasi yang lebih akurat dan berkualitas tinggi, tetapi mereka tidak memperhitungkan tindakan pengguna terbaru yang dapat terjadi selama pelatihan model, ketika sampel pelatihan diperbaiki. Model online segera merespons tindakan pengguna, dan rekomendasi dapat berubah dengan setiap tindakan.
Rekomendasi mulai dingin
Semua sistem rekomendasi memiliki masalah yang disebut "mulai dingin". Artinya adalah bahwa model yang dijelaskan di atas tidak dapat memberikan rekomendasi kepada pengguna baru tanpa riwayat tindakan. Dalam kasus seperti itu, lebih baik berkenalan dengan pengguna dengan apa yang ada di situs, sambil memilih tidak hanya iklan acak, tetapi, misalnya, iklan dari kategori yang populer di wilayah pengguna.
Rekomendasi Pencarian
Untuk pengguna yang sering menggunakan pencarian, kami membuat pintasan yang disarankan untuk pencarian - mereka mengirim pengguna ke kategori tertentu dan mengatur filter. Rekomendasi semacam itu dapat ditemukan di bagian atas halaman utama aplikasi.
Rekomendasi Barang-Barang
Rekomendasi Barang-Barang disajikan di situs dalam bentuk pengumuman serupa pada kartu produk. Mereka dapat dilihat di semua platform di bawah deskripsi iklan. Model rekomendasi saat ini adalah konten eksklusif dan tidak menggunakan informasi tentang tindakan pengguna, sehingga kami dapat segera mengambil yang serupa di antara iklan aktif di situs untuk iklan baru. Nanti di artikel saya akan berbicara tentang jenis rekomendasi khusus ini.
Secara lebih rinci tentang semua jenis rekomendasi tentang Avito yang sudah kami tulis di blog kami. Baca jika Anda tertarik.
Iklan serupa
Di sini terlihat seperti apa blok dengan iklan serupa:

Jenis rekomendasi ini muncul di situs pertama-tama, dan logika diimplementasikan pada mesin pencari Sphinx . Faktanya, model ini adalah kombinasi linear dari berbagai faktor: pencocokan kata, jarak, perbedaan harga dan parameter lainnya.
Berdasarkan parameter iklan target, permintaan dihasilkan dalam Sphinx, dan peringkat bawaan digunakan untuk menentukan peringkat.
Contoh permintaan:
SELECT id, weight as ranker_weight, ranker_weight * 10 + (metro_id=42) * 5 + (location_id=2525) * 10 + (110000 / (abs(price - 1100000) + 110000)) * 5 as rel FROM items WHERE MATCH('@title |scott|scale|700|premium') AND microcat_id=100 ORDER BY rel DESC, sort_time DESC LIMIT 0,32 OPTION max_matches=32, ranker=expr('sum(word_count)')
Jika Anda mencoba menggambarkan pendekatan ini secara lebih formal, maka Anda dapat membayangkan peringkat dalam bentuk beberapa bobot , dan parameter iklan (sumber adalah iklan asli) dan (iklan yang ditargetkan). Untuk setiap parameter kami memperkenalkan fungsi kesamaan . Mereka bisa biner (misalnya, kebetulan kota iklan), bisa diskrit (jarak antara iklan) dan kontinu (misalnya, perbedaan harga relatif). Kemudian untuk dua pengumuman, skor akhir akan dinyatakan dengan rumus
Dengan menggunakan mesin pencari, Anda dapat dengan cepat membaca nilai formula ini untuk jumlah iklan yang cukup besar dan memberi peringkat pengiriman secara real time.
Pendekatan ini menunjukkan dirinya dengan cukup baik dalam bentuk aslinya, tetapi memiliki kelemahan yang signifikan.
Masalah pendekatan
Pertama, bobot awalnya dipilih secara ahli dan tidak diragukan. Terkadang ada perubahan bobot, tetapi dilakukan berdasarkan umpan balik titik, dan bukan berdasarkan analisis perilaku pengguna secara umum.
Kedua, bobot tersebut di-hardcode di situs, dan membuat perubahan pada mereka sangat merepotkan.
Langkah menuju otomatisasi
Langkah pertama menuju peningkatan model rekomendasi adalah menghapus semua logika dalam microservice terpisah di Python. Layanan ini sudah sepenuhnya menjadi milik tim rekomendasi kami, dan kami dapat melakukan eksperimen dengan cukup sering.
Setiap percobaan dapat dikarakterisasi dengan apa yang disebut "config" - satu set bobot untuk peringkat. Kami ingin membuat konfigurasi dan memilih yang terbaik berdasarkan tindakan pengguna. Bagaimana konfigurasi ini dapat dihasilkan?
Opsi pertama, yang sejak awal, adalah generasi ahli konfigurasi. Artinya, dengan menggunakan pengetahuan dari bidang subjek, kami mengasumsikan bahwa, misalnya, ketika mencari mobil, orang tertarik pada opsi harga yang mendekati harga yang mereka lihat, dan bukan hanya model yang serupa, yang dapat lebih mahal secara signifikan.
Opsi kedua adalah konfigurasi acak. Kami menetapkan beberapa jenis distribusi untuk setiap parameter dan kemudian hanya mengambil sampel dari distribusi ini. Metode ini lebih cepat karena Anda tidak perlu memikirkan setiap parameter untuk semua kategori.
Opsi yang lebih rumit adalah menggunakan algoritma genetika. Kami tahu konfigurasi mana yang memberi kami efek terbaik dalam hal tindakan pengguna, sehingga pada setiap iterasi kami dapat meninggalkannya dan menambahkan yang baru: acak atau ahli.
Opsi yang bahkan lebih kompleks, yang membutuhkan sejarah panjang percobaan, adalah penggunaan pembelajaran mesin. Kami dapat mewakili sekumpulan parameter sebagai vektor fitur, dan metrik target sebagai variabel target. Kemudian kita akan menemukan seperangkat parameter yang, menurut penilaian model, akan memaksimalkan metrik target kita.
Dalam kasus kami, kami menetapkan dua pendekatan pertama, serta algoritma genetika dalam bentuk yang paling sederhana: kami meninggalkan yang terbaik, menghapus yang terburuk.
Sekarang kita sampai pada bagian paling menarik dari artikel: kita dapat menghasilkan konfigurasi, tetapi bagaimana melakukan eksperimen sehingga cepat dan efisien?
Eksperimen
Eksperimen dapat dilakukan dalam format tes A / B / .... Untuk melakukan ini, kita perlu menghasilkan N konfigurasi, menunggu hasil yang signifikan secara statistik, dan akhirnya, pilih konfigurasi terbaik. Ini bisa memakan waktu yang cukup lama, dan selama pengujian sekelompok pengguna tetap dapat menerima rekomendasi kualitas yang buruk - dengan konfigurasi acak, ini sangat mungkin. Selain itu, jika kami ingin menambahkan beberapa konfigurasi baru ke percobaan, kami harus memulai kembali pengujian. Tetapi kami ingin melakukan eksperimen dengan cepat, untuk dapat mengubah kondisi percobaan. Dan agar pengguna tidak menderita dari konfigurasi yang sengaja buruk. Banyak bandit bersenjata akan membantu kami dalam hal ini.
Bandit multi-bersenjata
Nama metode ini berasal dari "bandit satu tangan" - mesin slot di kasino dengan tuas yang dapat Anda tarik dan dapatkan kemenangan. Bayangkan Anda berada di ruangan dengan selusin mesin ini, dan Anda memiliki N usaha gratis untuk bermain di salah satu dari mereka. Tentu saja, Anda ingin memenangkan lebih banyak uang, tetapi Anda tidak tahu sebelumnya mesin mana yang memberikan kemenangan terbesar. Masalah dengan banyak bandit bersenjata terletak pada menemukan mesin yang paling menguntungkan dengan kerugian minimal (bermain pada mesin yang tidak menguntungkan).
Jika kami merumuskan ini dalam hal tugas rekomendasi kami, ternyata mesin tersebut adalah konfigurasi, setiap upaya merupakan pilihan konfigurasi untuk menghasilkan rekomendasi, dan keuntungannya adalah beberapa metrik target tergantung pada umpan balik pengguna.
Keuntungan bandit dibandingkan tes A / B / ...
Keuntungan utama mereka adalah bahwa mereka memungkinkan kita untuk mengubah jumlah lalu lintas tergantung pada keberhasilan konfigurasi tertentu. Ini hanya memecahkan masalah bahwa orang akan mendapatkan rekomendasi buruk selama percobaan. Jika mereka tidak mengklik rekomendasi, bandit akan dengan cepat memahami ini dan tidak akan memilih konfigurasi ini. Selain itu, kami selalu dapat menambahkan konfigurasi baru ke percobaan atau cukup menghapus salah satu yang saat ini. Semua bersama memberi kita fleksibilitas untuk melakukan percobaan dan menyelesaikan masalah pendekatan dengan pengujian A / B / ....

Strategi gangster
Ada banyak strategi untuk menyelesaikan masalah bandit multi-bersenjata. Selanjutnya, saya akan menjelaskan beberapa kelas strategi yang mudah diterapkan yang kami coba terapkan dalam tugas kami. Tetapi pertama-tama Anda perlu memahami bagaimana membandingkan efektivitas strategi. Jika kita tahu sebelumnya pena mana yang memberikan keuntungan maksimal, maka strategi optimal akan selalu menarik pena ini. Kami memperbaiki jumlah langkah dan menghitung hadiah yang optimal . Untuk strategi, kami juga akan menghitung hadiah. dan memperkenalkan konsepnya :
Strategi lebih lanjut dapat dibandingkan hanya dengan nilai ini. Saya perhatikan bahwa strategi memiliki sifat perubahan
mungkin berbeda, dan satu strategi mungkin lebih baik untuk sejumlah kecil langkah, dan yang lain untuk yang besar.
Strategi serakah
Seperti namanya, strategi serakah didasarkan pada satu prinsip sederhana - selalu pilih pena yang rata-rata memberikan hadiah terbesar. Strategi kelas ini berbeda dalam cara kami menjelajahi lingkungan untuk menentukan pena ini. Ada, misalnya, strategi Dia memiliki satu parameter - , yang menentukan probabilitas yang kami pilih bukan pena terbaik, tetapi acak, sehingga menjelajahi lingkungan kami. Anda juga dapat mengurangi kemungkinan penelitian dari waktu ke waktu. Strategi ini disebut . Strategi serakah sangat mudah diimplementasikan dan dimengerti, tetapi tidak selalu efektif.
UCB1
Strategi ini sepenuhnya deterministik - pena ditentukan secara unik dari informasi yang tersedia saat ini. Berikut ini rumusnya:
Bagian dari rumus dengan
berarti tengah dari j-th dan bertanggung jawab atas eksploitasi, seperti dalam strategi serakah. Bagian kedua dari formula ini bertanggung jawab untuk eksplorasi,
Apakah jumlah total tindakan
- jumlah aksi pena j-th. Ada perkiraan yang terbukti untuk strategi ini pada
. Anda dapat membacanya di
sini .
Thompson Sampling
Dalam strategi ini, kami menetapkan distribusi acak untuk setiap pena, dan pada setiap langkah, kami mengambil sampel dari distribusi ini, memilih pena sesuai dengan maksimum. Berdasarkan umpan balik, kami memperbarui parameter distribusi sehingga pena terbaik sesuai dengan distribusi dengan rata-rata besar, dan penyebarannya berkurang dengan jumlah tindakan. Anda dapat membaca lebih lanjut tentang strategi ini di artikel yang bagus.
Perbandingan Strategi
Mari kita mensimulasikan strategi yang dijelaskan di atas pada lingkungan buatan dengan tiga pegangan, yang masing-masing sesuai dengan distribusi Bernoulli dengan parameter sesuai. Strategi kami:
- dengan ;
- UCB1;
- Sampling Thompson Beta
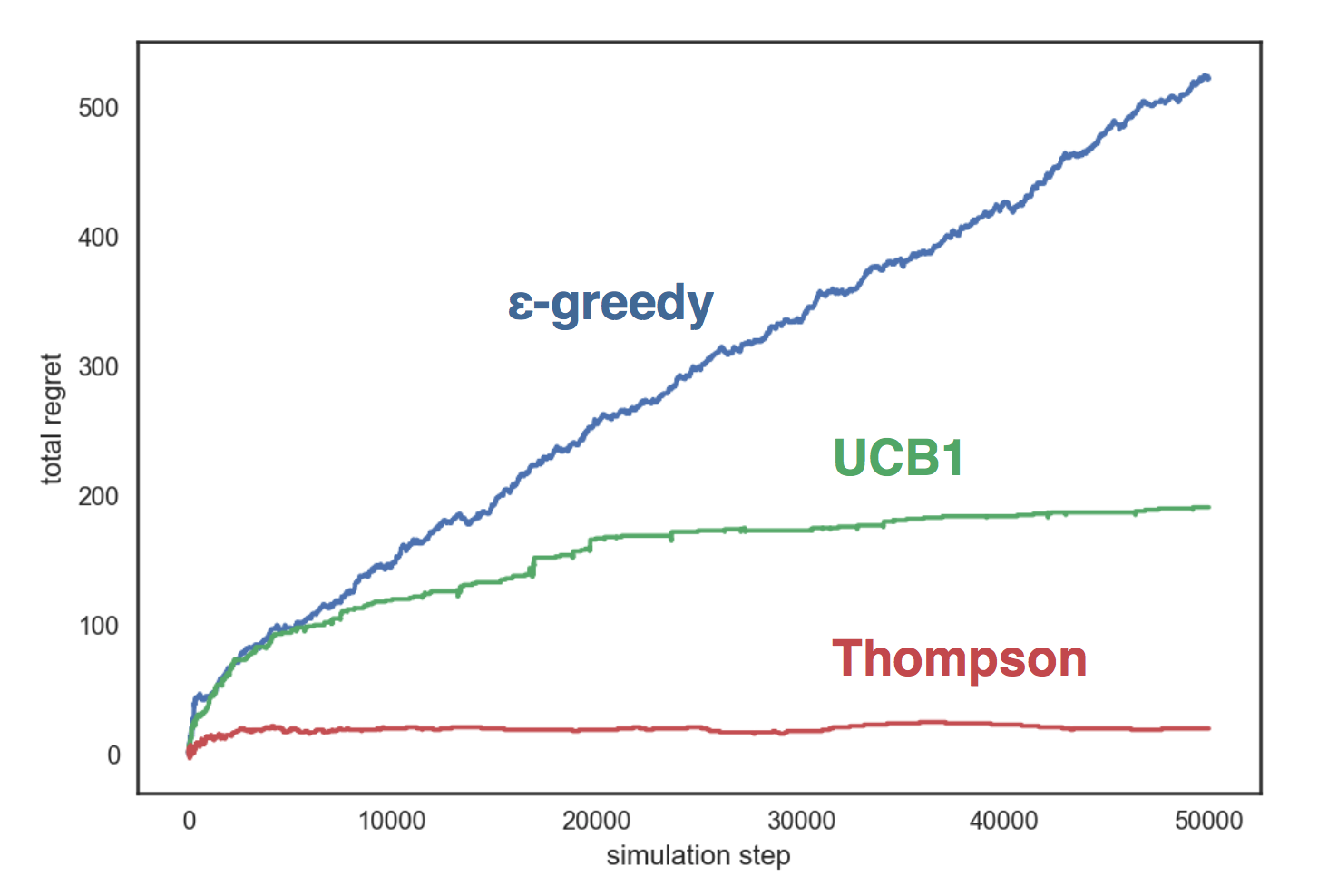
Grafik menunjukkan bahwa strategi serakah tumbuh secara linear, dan dalam dua strategi lainnya - secara logaritma, dan pengambilan sampel Thompson menunjukkan dirinya jauh lebih baik daripada yang lain dan dia hampir tidak bertambah dengan jumlah langkah.
Kode perbandingan tersedia di GitHub .
Saya memperkenalkan Anda dengan bandit multi-bersenjata dan sekarang saya dapat memberi tahu Anda bagaimana kami menggunakannya.
Bandit multi-bersenjata di Avito
Jadi, kami memiliki beberapa konfigurasi (set parameter), dan kami ingin memilih yang terbaik dari mereka dengan bantuan bandit multi-bersenjata. Untuk dipelajari para bandit, kita perlu satu detail penting - umpan balik pengguna. Pada saat yang sama, pilihan tindakan yang kami latih harus sesuai dengan tujuan kami - Saya ingin pengguna melakukan lebih banyak transaksi dengan rekomendasi yang lebih baik.
Pilih tindakan target
Pendekatan pertama untuk pemilihan tindakan yang ditargetkan cukup sederhana dan naif. Sebagai metrik target, kami memilih jumlah tampilan, dan para bandit belajar cara mengoptimalkan metrik ini dengan baik. Tapi ada masalah: lebih banyak pandangan tidak selalu baik. Misalnya, dalam kategori "Otomatis", kami berhasil meningkatkan jumlah penayangan sebesar 15%, tetapi pada saat yang sama jumlah permintaan kontak turun sekitar jumlah yang sama. Setelah diperiksa lebih dekat, ternyata bandit memilih pena di mana filter berdasarkan wilayah dimatikan. Karena itu, blok tersebut menampilkan iklan dari seluruh Rusia, di mana pilihan iklan serupa, tentu saja, lebih besar. Ini menyebabkan peningkatan jumlah tampilan: di luar, rekomendasi tersebut tampaknya memiliki kualitas yang lebih baik, tetapi ketika mereka memasukkan kartu produk, orang-orang menyadari bahwa mobil itu sangat jauh dari mereka dan tidak membuat permintaan kontak.
Pendekatan kedua adalah mempelajari cara mengkonversi dari melihat blok ke permintaan kontak. Pendekatan ini tampak lebih baik daripada yang sebelumnya, jika hanya karena metrik ini hampir secara langsung bertanggung jawab atas kualitas rekomendasi. Tetapi masalah lain muncul - musiman musiman. Tergantung pada waktu hari, nilai konversi dapat berbeda dengan empat (!) Kali (ini sering lebih dari efek konfigurasi yang lebih baik), dan pena yang beruntung dipilih pada interval pertama dengan konversi tinggi terus dipilih lebih sering daripada yang lain.
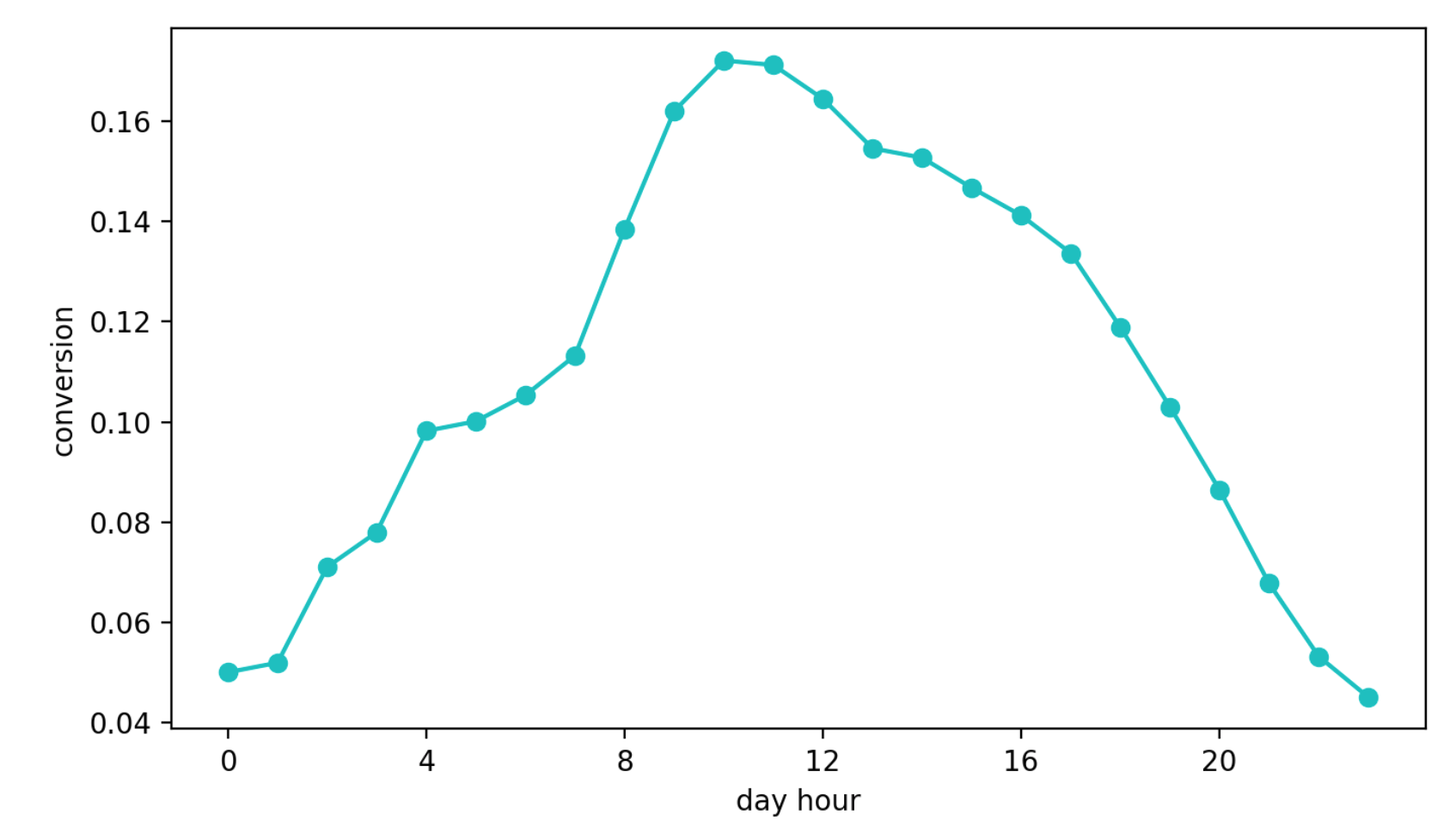
Dinamika Konversi Harian (Nilai sumbu Y berubah)
Akhirnya, pendekatan ketiga. Kami menggunakannya sekarang. Kami memilih grup referensi, yang selalu menerima rekomendasi pada algoritma yang sama dan tidak tunduk pada pengaruh bandit. Selanjutnya, kami melihat jumlah kontak absolut dalam kelompok target dan referensi kami. Hubungan mereka tidak tunduk pada musiman, karena kami memilih kelompok referensi secara acak, dan pendekatan ini dengan nyaman bertumpu pada pengambilan sampel Thompson.
Strategi kami
Kami membedakan kelompok referensi dan target, seperti dijelaskan di atas. Kemudian inisialisasi pegangan N (masing-masing sesuai dengan konfigurasi) dengan distribusi beta
Di setiap langkah:
- untuk setiap pena, kami mengambil sampel dari distribusi yang terkait dan memilih pena sesuai dengan maksimum;
- hitung jumlah tindakan dalam kelompok dan untuk kuantum waktu tertentu (dalam kasus kami adalah 10 detik) dan perbarui parameter distribusi untuk pena yang dipilih: , .
Dengan menggunakan strategi ini, kami mengoptimalkan metrik yang kami butuhkan, jumlah permintaan kontak di grup target, dan menghindari masalah yang saya jelaskan di atas. Selain itu, dalam tes A / B global, pendekatan ini menunjukkan hasil terbaik.
Hasil
Tes A / B global diselenggarakan sebagai berikut: semua iklan dibagi secara acak menjadi dua kelompok. Untuk pengumuman salah satu dari mereka, kami menunjukkan rekomendasi dengan bantuan bandit, dan yang lain - dengan algoritma ahli yang lama. Kemudian kami mengukur jumlah permintaan kontak konversi di masing-masing grup (permintaan yang dibuat setelah beralih ke iklan dari blok yang sama). Rata-rata, di semua kategori, grup dengan bandit menerima sekitar 10% lebih banyak tindakan yang ditargetkan daripada kontrol, tetapi dalam beberapa kategori perbedaan ini bisa mencapai 30%.
Dan platform yang dibuat memungkinkan Anda untuk dengan cepat mengubah logika, menambahkan konfigurasi ke bandit, dan memvalidasi hipotesis.
Jika Anda memiliki pertanyaan tentang layanan rekomendasi kami atau bandit multi-bersenjata, tanyakan di komentar. Saya akan dengan senang hati menjawab.