Sampai saat ini, di Odnoklassniki, sekitar 50 TB data waktu-nyata disimpan dalam SQL Server. Untuk volume seperti itu, hampir tidak mungkin untuk menyediakan akses pusat data yang cepat, andal, dan bahkan gagal-aman menggunakan SQL DBMS. Biasanya dalam kasus seperti itu mereka menggunakan salah satu repositori NoSQL, tetapi tidak semuanya dapat ditransfer ke NoSQL: beberapa entitas memerlukan jaminan transaksi ACID.
Ini mendorong kami untuk menggunakan penyimpanan NewSQL, yaitu, DBMS yang memberikan toleransi kesalahan, skalabilitas, dan kinerja sistem NoSQL, tetapi pada saat yang sama menjaga jaminan ACID yang akrab dengan sistem klasik. Ada beberapa sistem industri yang berfungsi di kelas baru ini, jadi kami menerapkan sistem itu sendiri dan menjalankannya secara komersial.
Cara kerjanya dan apa yang terjadi - baca di bawah potongan.
Hari ini, pemirsa bulanan Odnoklassniki adalah lebih dari 70 juta pengunjung unik. Kami adalah
salah satu dari lima jejaring sosial terbesar di dunia, dan dua puluh situs tempat pengguna menghabiskan waktu paling banyak. Infrastruktur "OK" menangani beban yang sangat tinggi: lebih dari satu juta permintaan HTTP / detik ke garis depan. Bagian dari armada server dalam jumlah lebih dari 8000 keping terletak berdekatan satu sama lain - di empat pusat data Moskow, yang memungkinkan latensi jaringan kurang dari 1 ms di antaranya.
Kami telah menggunakan Cassandra sejak 2010, dimulai dengan versi 0.6. Saat ini, beberapa lusin cluster sedang beroperasi. Cluster tercepat memproses lebih dari 4 juta operasi per detik, dan yang terbesar menyimpan 260 TB.
Namun, semua ini adalah kluster NoSQL biasa yang digunakan untuk menyimpan data yang
lemah konsisten . Tetapi kami ingin mengganti penyimpanan konsisten utama, Microsoft SQL Server, yang telah digunakan sejak berdirinya Odnoklassniki. Penyimpanan terdiri dari lebih dari 300 mesin SQL Server Standard Edition, yang berisi 50 TB data - entitas bisnis. Data ini dimodifikasi sebagai bagian dari transaksi ACID dan membutuhkan
konsistensi yang tinggi .
Untuk mendistribusikan data di antara node SQL Server, kami menggunakan
partisi vertikal dan horizontal (sharding). Secara historis, kami menggunakan skema berbagi data sederhana: setiap entitas dikaitkan dengan token - fungsi ID entitas. Entitas dengan token yang sama ditempatkan di server SQL yang sama. Hubungan tipe master-detail diimplementasikan sehingga token dari catatan utama dan yang dihasilkan selalu bertepatan dan berada di server yang sama. Di jejaring sosial, hampir semua catatan dihasilkan atas nama pengguna - yang berarti bahwa semua data pengguna dalam satu subsistem fungsional disimpan di satu server. Artinya, tabel dari satu server SQL hampir selalu berpartisipasi dalam transaksi bisnis, yang memungkinkan untuk memastikan konsistensi data menggunakan transaksi ACID lokal, tanpa perlu transaksi ACID yang didistribusikan secara
lambat dan tidak dapat diandalkan .
Berkat sharding dan untuk mempercepat SQL:
- Kami tidak menggunakan batasan kunci Asing, karena ketika sharding, ID entitas dapat di server lain.
- Kami tidak menggunakan prosedur tersimpan dan pemicu karena beban tambahan pada CPU DBMS.
- Kami tidak menggunakan BERGABUNG karena semua hal di atas dan banyak membaca acak dari disk.
- Di luar transaksi, untuk mengurangi kebuntuan, kami menggunakan level isolasi Read Uncommitted.
- Kami hanya melakukan transaksi singkat (rata-rata, lebih pendek dari 100 ms).
- Kami tidak menggunakan UPDATE dan DELETE multi-baris karena banyaknya kebuntuan - kami hanya memperbarui satu catatan.
- Kami selalu menjalankan kueri hanya dengan indeks - kueri dengan rencana untuk pemindaian tabel lengkap bagi kami berarti kelebihan database dan kegagalannya.
Langkah-langkah ini memungkinkan untuk memeras kinerja maksimum hampir dari server SQL. Namun, masalahnya menjadi semakin banyak. Mari lihat mereka.
Masalah SQL
- Karena kami menggunakan sharding berpemilik, administrator secara manual menambahkan pecahan baru. Selama ini, replika data yang dapat diskalakan tidak melayani permintaan.
- Saat jumlah catatan dalam tabel meningkat, kecepatan penyisipan dan modifikasi menurun, saat menambahkan indeks ke tabel yang ada, kecepatan turun beberapa kali, pembuatan dan pembuatan ulang indeks berjalan dengan waktu henti.
- Memiliki sedikit Windows untuk SQL Server dalam produksi membuat mengelola infrastruktur Anda sulit
Namun masalah utamanya adalah
Toleransi kesalahan
SQL Server klasik memiliki toleransi kesalahan yang buruk. Misalkan Anda hanya memiliki satu server basis data, dan itu gagal setiap tiga tahun sekali. Saat ini, situs tidak berfungsi selama 20 menit, ini dapat diterima. Jika Anda memiliki 64 server, maka situs tersebut tidak berfungsi setiap tiga minggu sekali. Dan jika Anda memiliki 200 server, maka situs tersebut tidak berfungsi setiap minggu. Ini masalah.
Apa yang dapat dilakukan untuk meningkatkan ketahanan SQL Server? Wikipedia menawarkan kita untuk membangun sebuah
kluster yang sangat mudah diakses : di mana jika terjadi kegagalan salah satu komponen ada duplikat.
Ini membutuhkan armada peralatan mahal: redundansi berganda, serat, penyimpanan bersama, dan penyertaan cadangan tidak berfungsi dengan andal: sekitar 10% inklusi gagal dengan simpul cadangan oleh mesin di belakang simpul utama.
Tetapi kelemahan utama dari cluster yang sangat mudah diakses adalah ketersediaan nol jika terjadi kegagalan pusat data di mana ia berdiri. Odnoklassniki memiliki empat pusat data, dan kami harus menyediakan pekerjaan jika terjadi kecelakaan lengkap di salah satu di antaranya.
Untuk melakukan ini, Anda bisa menggunakan replikasi
Multi-Master yang dibangun ke dalam SQL Server. Solusi ini jauh lebih mahal karena biaya perangkat lunak dan menderita masalah terkenal dengan replikasi - keterlambatan transaksi yang tidak dapat diprediksi selama replikasi sinkron dan keterlambatan dalam penggunaan replikasi (dan, akibatnya, kehilangan modifikasi) selama asinkron.
Resolusi konflik yang tersirat secara
manual membuat opsi ini benar-benar tidak dapat diterapkan kepada kami.
Semua masalah ini memerlukan solusi radikal dan kami melanjutkan ke analisis terperinci dari mereka. Di sini kita perlu berkenalan dengan apa yang SQL Server lakukan - transaksi.
Transaksi sederhana
Pertimbangkan yang paling sederhana, dari sudut pandang programmer SQL yang diterapkan, transaksi: menambahkan foto ke album. Album dan foto disimpan dalam piring yang berbeda. Album ini memiliki penghitung foto publik. Kemudian transaksi semacam itu dibagi menjadi langkah-langkah berikut:
- Kami mengunci album dengan kunci.
- Buat entri di tabel foto.
- Jika foto memiliki status publik, maka kami akan membuat penghitung foto publik di album, memperbarui catatan, dan melakukan transaksi.
Atau dalam bentuk pseudo-code:
TX.start("Albums", id); Album album = albums.lock(id); Photo photo = photos.create(…); if (photo.status == PUBLIC ) { album.incPublicPhotosCount(); } album.update(); TX.commit();
Kami melihat bahwa skenario transaksi bisnis yang paling umum adalah membaca data dari database ke dalam memori server aplikasi, mengubah sesuatu, dan menyimpan nilai-nilai baru kembali ke database. Biasanya dalam transaksi seperti itu kami memperbarui beberapa entitas, beberapa tabel.
Ketika melakukan transaksi, modifikasi kompetitif dari data yang sama dari sistem lain dapat terjadi. Sebagai contoh, Antispam dapat memutuskan bahwa pengguna mencurigakan dan oleh karena itu semua foto pengguna tidak boleh lagi publik, mereka harus dikirim untuk moderasi, yang berarti mengubah photo.status ke beberapa nilai lain dan membuka konter yang sesuai. Jelas, jika operasi ini terjadi tanpa jaminan atomicity aplikasi dan isolasi modifikasi yang bersaing, seperti pada
ACID , hasilnya tidak akan menjadi apa yang dibutuhkan - baik penghitung foto akan menunjukkan nilai yang salah, atau tidak semua foto akan dikirim untuk moderasi.
Ada banyak kode serupa yang memanipulasi berbagai entitas bisnis dalam kerangka satu transaksi selama seluruh keberadaan Odnoklassniki. Dari pengalaman bermigrasi ke NoSQL dengan
Konsistensi Akhir, kita tahu bahwa kesulitan terbesar (dan biaya waktu) adalah kebutuhan untuk mengembangkan kode yang bertujuan menjaga konsistensi data. Oleh karena itu, kami mempertimbangkan persyaratan utama untuk repositori baru untuk menyediakan transaksi ACID logika nyata untuk logika aplikasi.
Persyaratan lain yang sama pentingnya adalah:
- Jika pusat data gagal, baik membaca dan menulis ke penyimpanan baru harus tersedia.
- Menjaga kecepatan pengembangan saat ini. Artinya, ketika bekerja dengan repositori baru, jumlah kode harus kira-kira sama, seharusnya tidak perlu menambahkan sesuatu ke repositori, mengembangkan algoritma untuk menyelesaikan konflik, mempertahankan indeks sekunder, dll.
- Kecepatan penyimpanan baru harus cukup tinggi baik ketika membaca data dan ketika memproses transaksi, yang secara efektif berarti ketidakmampuan solusi yang ketat secara akademis, universal, tetapi lambat, seperti, misalnya, komitmen dua fase .
- Penskalaan otomatis dengan cepat.
- Menggunakan server murah biasa, tanpa perlu membeli besi eksotis.
- Kemungkinan mengembangkan penyimpanan oleh pengembang perusahaan. Dengan kata lain, prioritas diberikan kepada solusi mereka sendiri atau berbasis sumber terbuka, lebih disukai di Jawa.
Keputusan, Keputusan
Menganalisis kemungkinan solusi, kami sampai pada dua pilihan arsitektur yang mungkin:
Yang pertama adalah mengambil server SQL apa pun dan mengimplementasikan toleransi kesalahan yang diperlukan, mekanisme penskalaan, kluster failover, resolusi konflik dan transaksi ACID yang terdistribusi, andal dan cepat. Kami menilai opsi ini sangat tidak sepele dan memakan waktu.
Opsi kedua adalah mengambil repositori NoSQL yang sudah jadi dengan penskalaan yang diimplementasikan, kluster failover, resolusi konflik, dan implementasikan transaksi dan SQL sendiri. Sekilas, bahkan tugas mengimplementasikan SQL, belum lagi transaksi ACID, tampak seperti tugas selama bertahun-tahun. Tapi kemudian kami menyadari bahwa set fitur SQL yang kami gunakan dalam praktiknya adalah jauh dari ANSI SQL seperti
Cassandra CQL jauh dari ANSI SQL. Melihat lebih dekat pada CQL, kami menyadari bahwa itu cukup dekat dengan apa yang kami butuhkan.
Cassandra dan CQL
Jadi, apa yang menarik dari Cassandra, kemampuan apa yang dimilikinya?
Pertama, di sini Anda dapat membuat tabel dengan dukungan untuk berbagai tipe data, Anda dapat melakukan SELECT atau UPDATE pada kunci utama.
CREATE TABLE photos (id bigint KEY, owner bigint,…); SELECT * FROM photos WHERE id=?; UPDATE photos SET … WHERE id=?;
Untuk memastikan data replika yang konsisten, Cassandra menggunakan
pendekatan kuorum . Dalam kasus yang paling sederhana, ini berarti bahwa ketika tiga replika dari baris yang sama ditempatkan pada node yang berbeda dari cluster, catatan dianggap berhasil jika sebagian besar node (yaitu dua dari tiga) mengkonfirmasi keberhasilan operasi penulisan ini. Data dari suatu seri dianggap konsisten jika, ketika membaca, sebagian besar node diinterogasi dan dikonfirmasi. Dengan demikian, dengan adanya tiga replika, konsistensi data penuh dan instan dijamin dalam kasus kegagalan satu node. Pendekatan ini memungkinkan kami untuk menerapkan skema yang bahkan lebih andal: selalu mengirim permintaan ke ketiga replika, menunggu jawaban dari dua yang tercepat. Respons terlambat dari replika ketiga kemudian dibuang. Sebuah node yang terlambat dengan jawaban dapat memiliki masalah serius - rem, pengumpulan sampah di JVM, reklamasi memori langsung di kernel linux, kegagalan perangkat keras, terputusnya jaringan. Namun, ini tidak memengaruhi operasi atau data klien.
Pendekatan ketika kita beralih ke tiga node dan mendapatkan jawaban dari dua disebut
spekulasi : permintaan komentar tambahan dikirim bahkan sebelum itu "jatuh".
Keuntungan lain dari Cassandra adalah Batchlog - sebuah mekanisme yang menjamin aplikasi penuh atau non-aplikasi lengkap dari paket perubahan yang Anda buat. Ini memungkinkan kita untuk memecahkan A dalam ACID - atomicity di luar kotak.
Yang paling dekat dengan transaksi di Cassandra adalah apa yang disebut "
transaksi ringan ". Tetapi mereka jauh dari transaksi ACID "nyata": pada kenyataannya, ini adalah kesempatan untuk membuat
CAS pada data hanya satu catatan, menggunakan konsensus pada protokol berat Paxos. Karena itu, kecepatan transaksi seperti itu rendah.
Apa yang kami lewatkan di Cassandra
Jadi, kami harus menerapkan transaksi ACID nyata di Cassandra. Dengan menggunakan itu kita dapat dengan mudah mengimplementasikan dua fitur nyaman lainnya dari DBMS klasik: indeks cepat yang konsisten, yang akan memungkinkan kita untuk melakukan pengambilan sampel data tidak hanya pada kunci primer dan generator yang biasa digunakan ID kenaikan otomatis monoton.
C * satu
Jadi
C * One DBMS baru lahir, terdiri dari tiga jenis node server:
- Penyimpanan - server Cassandra standar (hampir) yang bertanggung jawab untuk menyimpan data pada drive lokal. Ketika beban dan jumlah data bertambah, jumlah mereka dapat dengan mudah ditingkatkan menjadi puluhan atau ratusan.
- Koordinator Transaksi - Memungkinkan eksekusi transaksi.
- Klien adalah server aplikasi yang menerapkan operasi bisnis dan memulai transaksi. Mungkin ada ribuan pelanggan seperti itu.
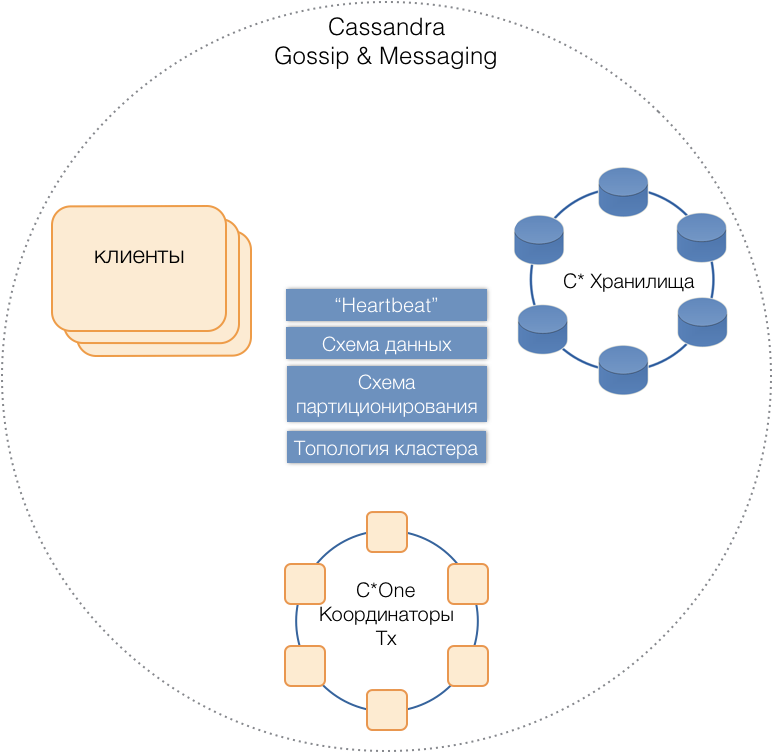
Semua jenis server berada di cluster umum, gunakan protokol pesan Cassandra internal untuk berkomunikasi satu sama lain dan
gosip untuk bertukar informasi cluster. Dengan bantuan Heartbeat, server belajar tentang kegagalan timbal balik, mendukung skema data tunggal - tabel, struktur dan replikasi mereka; skema partisi, topologi klaster, dll.
Pelanggan
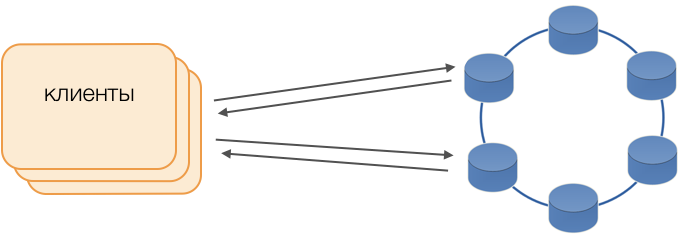
Alih-alih driver standar, mode Fat Client digunakan. Node tersebut tidak menyimpan data, tetapi dapat bertindak sebagai koordinator pelaksanaan kueri, yaitu, Klien sendiri melakukan fungsi koordinator permintaannya: ia mengumpulkan repositori replika dan menyelesaikan konflik. Ini tidak hanya lebih dapat diandalkan dan lebih cepat daripada driver standar yang memerlukan komunikasi dengan koordinator jarak jauh, tetapi juga memungkinkan Anda untuk mengontrol transfer permintaan. Di luar transaksi terbuka pada klien, permintaan dikirim ke penyimpanan. Jika klien membuka transaksi, maka semua permintaan dalam transaksi dikirim ke koordinator transaksi.

C * Satu Koordinator Transaksi
Koordinator adalah apa yang kami terapkan untuk C * One dari awal. Dia bertanggung jawab untuk mengelola transaksi, mengunci, dan urutan transaksi diterapkan.
Untuk setiap transaksi yang dilayani, koordinator membuat stempel waktu: masing-masing transaksi berikutnya lebih besar dari transaksi sebelumnya. Karena sistem resolusi konflik di Cassandra didasarkan pada stempel waktu (dari dua catatan yang saling bertentangan, yang saat ini dengan stempel waktu terakhir dianggap relevan), konflik akan selalu diselesaikan untuk transaksi berikutnya. Karena itu, kami menerapkan
jam tangan Lamport - cara murah untuk menyelesaikan konflik dalam sistem terdistribusi.
Kunci
Untuk memastikan isolasi, kami memutuskan untuk menggunakan metode paling sederhana - kunci pesimis pada kunci utama catatan. Dengan kata lain, dalam suatu transaksi, catatan harus dikunci terlebih dahulu, baru kemudian dibaca, diubah, dan disimpan. Hanya setelah komit yang berhasil dapat catatan dibuka kuncinya sehingga transaksi yang bersaing dapat menggunakannya.
Menerapkan kunci ini sederhana di lingkungan yang tidak terisi. Ada dua cara utama dalam sistem terdistribusi: menerapkan penguncian terdistribusi pada kluster, atau mendistribusikan transaksi sehingga transaksi yang melibatkan catatan tunggal selalu dilayani oleh koordinator yang sama.
Karena dalam kasus kami, data sudah didistribusikan oleh grup transaksi lokal dalam SQL, diputuskan untuk menetapkan grup transaksi lokal ke koordinator: satu koordinator melakukan semua transaksi dengan token dari 0 hingga 9, yang kedua dengan token dari 10 hingga 19, dan seterusnya. Akibatnya, setiap instance koordinator menjadi master grup transaksi.
Kemudian kunci dapat diimplementasikan sebagai HashMap dangkal dalam memori koordinator.
Kegagalan Koordinator
Karena satu koordinator secara eksklusif melayani sekelompok transaksi, sangat penting untuk segera menentukan fakta kegagalannya, sehingga upaya berulang untuk mengeksekusi transaksi akan berakhir. Untuk membuatnya cepat dan andal, kami menerapkan protokol kuorum pendengaran yang sepenuhnya terhubung:
Setiap pusat data memiliki setidaknya dua simpul koordinator. Secara berkala, masing-masing koordinator mengirimkan pesan detak jantung ke koordinator lain dan memberi tahu mereka tentang fungsinya, serta pesan detak jantung dari mana koordinator di cluster untuk terakhir kalinya.

Setelah menerima informasi serupa dari yang lain dalam komposisi pesan detak jantung mereka, masing-masing koordinator memutuskan sendiri fungsi gugus simpul mana yang tidak, dipandu oleh prinsip kuorum: jika simpul X menerima informasi dari mayoritas simpul dalam gugus tentang penerimaan pesan yang normal dari simpul Y, maka , Y bekerja. Sebaliknya, segera setelah mayoritas melaporkan hilangnya pesan dari simpul Y, maka Y telah gagal. Sangat mengherankan bahwa jika kuorum memberi tahu simpul X bahwa ia tidak menerima lebih banyak pesan darinya, maka simpul X sendiri akan menganggap dirinya gagal.
Pesan detak jantung dikirim pada frekuensi tinggi, sekitar 20 kali per detik, dengan periode 50 ms. Di Jawa, sulit untuk menjamin respons aplikasi 50 ms karena panjang jeda yang sebanding yang disebabkan oleh pengumpul sampah. Kami dapat mencapai waktu respons seperti itu dengan menggunakan pengumpul sampah G1, yang memungkinkan kami menentukan target untuk durasi jeda GC. Namun, kadang-kadang, sangat jarang, jeda kolektor melampaui 50 ms, yang dapat menyebabkan kesalahan deteksi kesalahan. Untuk mencegah hal ini, koordinator tidak melaporkan kegagalan node jauh ketika pesan detak jantung pertama menghilang darinya, hanya jika beberapa secara berurutan menghilang. Jadi kami berhasil mendeteksi kegagalan simpul koordinator dalam 200 ms.
Tapi itu tidak cukup untuk dengan cepat memahami simpul mana yang berhenti berfungsi. Anda perlu melakukan sesuatu tentang itu.
Reservasi
Skema klasik mengasumsikan bahwa jika terjadi penolakan master untuk meluncurkan pemilihan baru menggunakan salah satu algoritma
universal yang modis . Namun, algoritma tersebut memiliki masalah yang terkenal dengan konvergensi waktu dan lamanya proses pemilihan itu sendiri. Kami berhasil menghindari penundaan tambahan tersebut dengan menggunakan rangkaian koordinator yang setara dalam jaringan yang sepenuhnya terhubung:
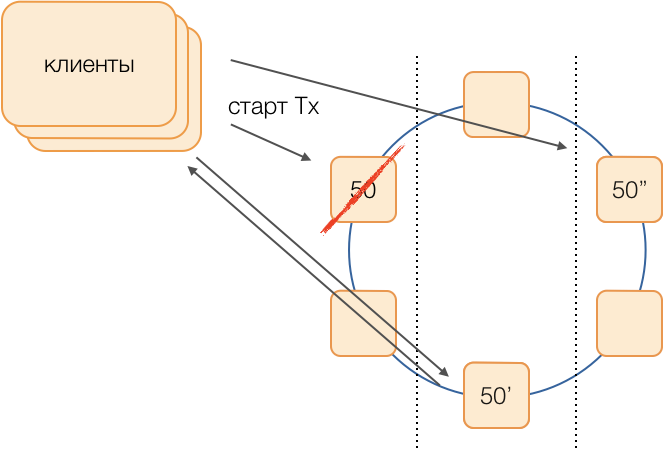
Misalkan kita ingin melakukan transaksi dalam grup 50. Kami akan menentukan terlebih dahulu skema substitusi, yaitu, node mana yang akan melakukan transaksi grup 50 jika terjadi kegagalan koordinator utama. Tujuan kami adalah menjaga sistem tetap beroperasi jika terjadi kegagalan pusat data. Kami menentukan bahwa cadangan pertama akan menjadi simpul dari pusat data lain, dan cadangan kedua akan menjadi simpul dari yang ketiga. Skema ini dipilih sekali dan tidak berubah sampai topologi klaster berubah, yaitu, sampai node baru memasukinya (yang jarang terjadi). Prosedur untuk memilih master aktif baru jika terjadi kegagalan yang lama akan selalu seperti ini: cadangan pertama akan menjadi tuan aktif, dan jika telah berhenti berfungsi, cadangan kedua akan menjadi.
Skema seperti itu lebih dapat diandalkan daripada algoritma universal, karena untuk mengaktifkan master baru cukup untuk menentukan fakta kegagalan yang lama.
Tetapi bagaimana pelanggan akan memahami master mana yang bekerja sekarang? Selama 50 ms, tidak mungkin mengirim informasi ke ribuan pelanggan. Situasi mungkin terjadi ketika klien mengirim permintaan untuk membuka transaksi, belum mengetahui bahwa wisaya ini tidak lagi berfungsi, dan permintaan akan hangout. Untuk mencegah hal ini terjadi, klien secara spekulatif mengirim permintaan untuk segera membuka transaksi ke master grup dan kedua cadangannya, tetapi hanya orang yang merupakan master aktif saat ini yang akan menjawab permintaan ini. Klien akan melakukan semua komunikasi selanjutnya dalam transaksi hanya dengan master aktif.
Master cadangan menerima permintaan untuk transaksi non-sendiri dalam antrian transaksi yang belum lahir, di mana mereka disimpan selama beberapa waktu. Jika master aktif mati, master baru memproses permintaan untuk membuka transaksi dari antriannya dan merespons ke klien. Jika klien sudah berhasil membuka transaksi dengan master lama, maka respons kedua diabaikan (dan, jelas, transaksi seperti itu tidak akan selesai dan akan diulangi oleh klien).
Bagaimana suatu transaksi bekerja
Misalkan klien mengirim permintaan kepada koordinator untuk membuka transaksi untuk entitas dengan kunci utama tersebut. Koordinator mengunci entitas ini dan menempatkannya di tabel kunci dalam memori. Jika perlu, koordinator membaca entitas ini dari toko dan menyimpan data yang diterima dalam status transaksi dalam memori koordinator.
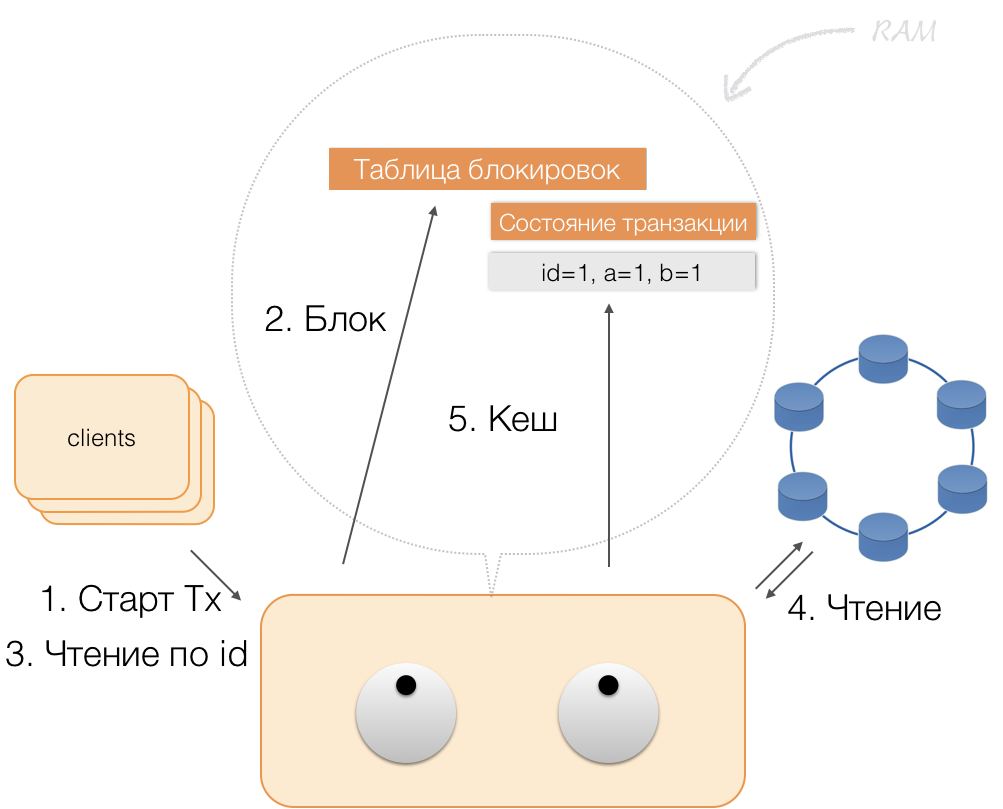
Ketika klien ingin mengubah data dalam transaksi, ia mengirim permintaan koordinator untuk memperbarui entitas, dan ia menempatkan data baru dalam tabel status transaksi dalam memori. Ini melengkapi perekaman - perekaman tidak dilakukan dalam repositori.
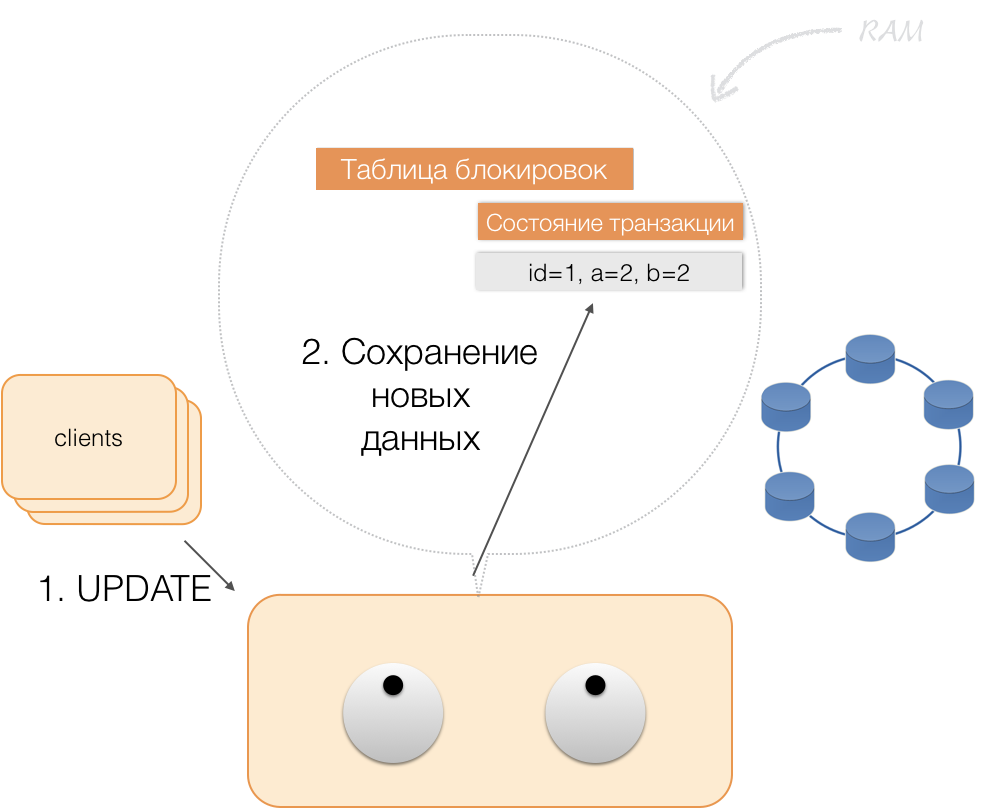
Ketika klien meminta, dalam kerangka transaksi aktif, data mereka sendiri yang berubah, koordinator bertindak seperti ini:
- jika ID sudah ada dalam transaksi, maka data diambil dari memori;
- jika tidak ada ID dalam memori, maka data yang hilang dibaca dari node penyimpanan, dikombinasikan dengan yang sudah ada dalam memori, dan hasilnya dikembalikan ke klien.
Dengan demikian, klien dapat membaca perubahannya sendiri, sementara klien lain tidak melihat perubahan ini, karena mereka disimpan hanya dalam memori koordinator, mereka belum berada dalam node Cassandra.
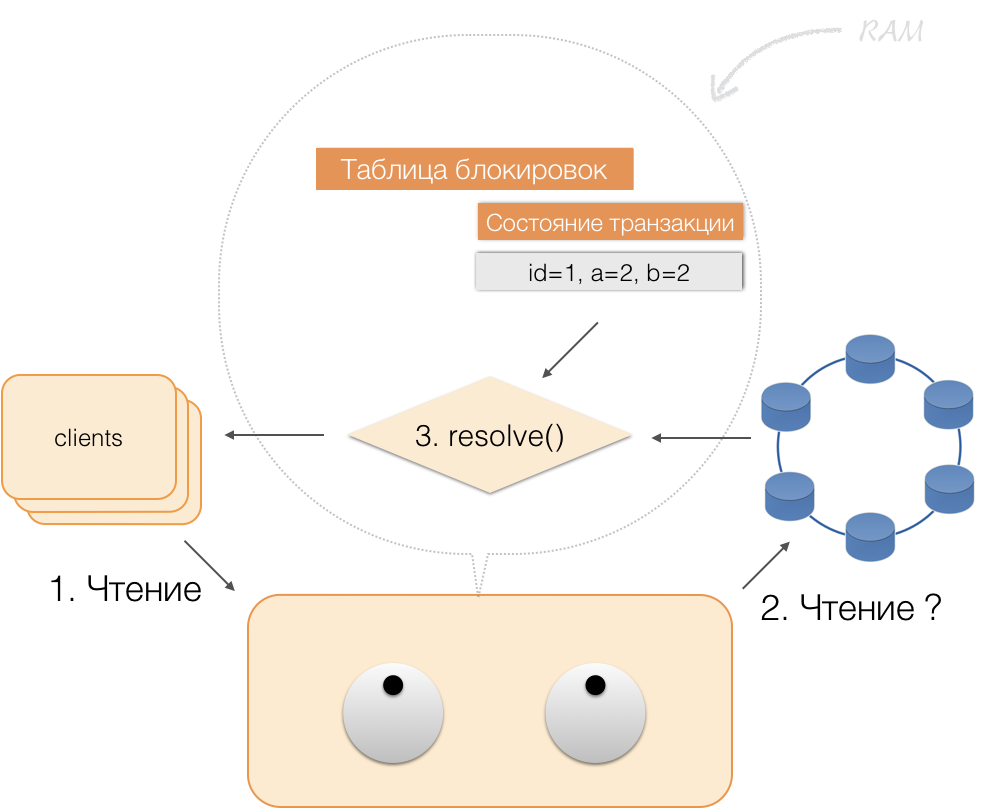
Ketika klien mengirim komit, status dalam memori layanan disimpan oleh koordinator dalam batch yang dicatat, dan sudah dalam bentuk batch yang telah dikirim, dikirim ke repositori Cassandra. Repositori melakukan segala yang diperlukan agar paket ini diterapkan secara atom (sepenuhnya), dan mengembalikan respons kepada koordinator, yang melepaskan kunci dan mengonfirmasi keberhasilan transaksi kepada klien.

Dan untuk kembali ke koordinator, cukup membebaskan memori yang ditempati oleh keadaan transaksi.
Sebagai hasil dari perbaikan di atas, kami menerapkan prinsip-prinsip ACID:
- Atomicity . Ini adalah jaminan bahwa tidak ada transaksi yang akan dilakukan sebagian untuk sistem, semua sub-operasinya akan selesai, atau tidak satu pun akan dieksekusi. Kami mematuhi prinsip ini karena batch yang dicatat di Cassandra.
- Koherensi Setiap transaksi yang berhasil, menurut definisi, hanya menangkap hasil yang dapat diterima. Jika, setelah membuka transaksi dan melakukan bagian dari operasi, ternyata hasilnya tidak valid, rollback dilakukan.
- Isolasi . Ketika suatu transaksi dieksekusi, transaksi paralel seharusnya tidak mempengaruhi hasilnya. Transaksi yang bersaing diisolasi menggunakan kunci pesimistik pada koordinator. Untuk bacaan di luar transaksi, prinsip isolasi pada tingkat Komitmen Baca dihormati.
- Keberlanjutan . Terlepas dari masalah di tingkat bawah - penghentian sistem, kegagalan perangkat keras, - perubahan yang dilakukan oleh transaksi yang berhasil diselesaikan harus tetap disimpan setelah melanjutkan operasi.
Pembacaan indeks
Ambil tabel sederhana:
CREATE TABLE photos ( id bigint primary key, owner bigint, modified timestamp, …)
Dia memiliki ID (kunci utama), pemilik dan tanggal perubahan. Anda perlu membuat permintaan yang sangat sederhana - pilih data pemilik dengan tanggal perubahan "untuk hari terakhir".
SELECT * WHERE owner=? AND modified>?
Agar kueri tersebut bekerja dengan cepat, dalam SQL DBMS klasik, Anda perlu membuat indeks menurut kolom (pemilik, dimodifikasi). Kami dapat melakukan ini dengan cukup sederhana, karena sekarang kami memiliki jaminan ACID!
Indeks dalam C * One
Ada tabel sumber dengan foto, di mana ID rekaman adalah kunci utama.

Untuk indeks C *, One membuat tabel baru, yang merupakan salinan dari aslinya. Kunci cocok dengan ekspresi indeks, dan itu juga termasuk kunci utama catatan dari tabel sumber:
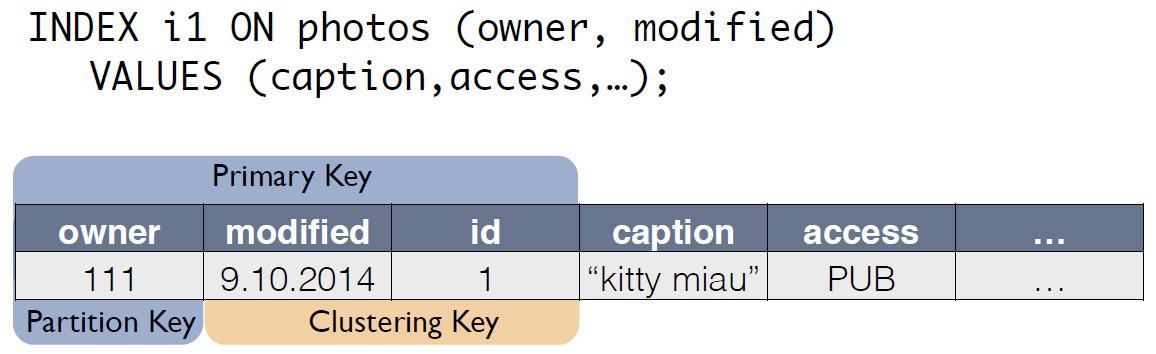
Sekarang permintaan untuk "pemilik untuk hari terakhir" dapat ditulis ulang sebagai pilih dari tabel lain:
SELECT * FROM i1_test WHERE owner=? AND modified>?
Konsistensi data dari tabel foto asli dan indeks i1 dikelola secara otomatis oleh koordinator. Berdasarkan skema data saja, ketika perubahan diterima, koordinator menghasilkan dan mengingat perubahan tidak hanya di tabel utama, tetapi juga di salinan perubahan. Tidak ada tindakan tambahan yang dilakukan dengan tabel indeks, log tidak dibaca, kunci tidak digunakan. Artinya, menambahkan indeks hampir tidak memakan sumber daya dan praktis tidak mempengaruhi kecepatan penerapan modifikasi.
Menggunakan ACID, kami dapat menerapkan indeks "seperti dalam SQL". Mereka memiliki konsistensi, dapat diskalakan, bekerja dengan cepat, dapat digabungkan dan dibangun ke dalam bahasa query CQL.
Untuk mendukung indeks, Anda tidak perlu membuat perubahan pada kode aplikasi. Semuanya sederhana, seperti dalam SQL. Dan yang paling penting, indeks tidak mempengaruhi kecepatan eksekusi modifikasi ke tabel transaksi asli.Apa yang terjadi
Kami mengembangkan C * Satu tiga tahun lalu dan memasukkannya ke dalam operasi komersial.Apa yang kita dapatkan pada akhirnya? Mari kita evaluasi ini menggunakan contoh subsistem untuk memproses dan menyimpan foto, salah satu jenis data yang paling penting dalam jejaring sosial. Ini bukan tentang tubuh foto itu sendiri, tetapi tentang semua jenis meta-informasi. Sekarang di Odnoklassniki ada sekitar 20 miliar catatan seperti itu, sistem memproses 80 ribu permintaan baca per detik, hingga 8 ribu transaksi ACID per detik yang terkait dengan modifikasi data.Ketika kami menggunakan SQL dengan faktor replikasi = 1 (tetapi dalam RAID 10), informasi meta foto disimpan pada kelompok 32 mesin yang sangat mudah diakses dengan Microsoft SQL Server (plus 11 cadangan). Ini juga mengalokasikan 10 server untuk menyimpan cadangan. Sebanyak 50 mobil mahal. Pada saat yang sama, sistem bekerja pada beban terukur, tanpa cadangan.Setelah bermigrasi ke sistem baru, kami mendapat faktor replikasi = 3 - salinan di setiap pusat data. Sistem ini terdiri dari 63 node penyimpanan Cassandra dan 6 mesin koordinator, dengan total 69 server. Tetapi mesin ini jauh lebih murah, total biaya mereka adalah sekitar 30% dari biaya sistem dalam SQL. Dalam hal ini, beban disimpan pada 30%.Dengan diperkenalkannya C * One, penundaan juga menurun: dalam SQL, operasi penulisan memakan waktu sekitar 4,5 ms. Dalam C * One - sekitar 1,6 ms. Durasi transaksi rata-rata kurang dari 40 ms, komit dilakukan dalam 2 ms, durasi baca dan tulis rata-rata 2 ms. Persentil ke-99 - hanya 3-3,1 ms, jumlah waktu habis berkurang 100 kali - semua karena penggunaan spekulasi yang meluas.Sampai saat ini, sebagian besar node SQL Server telah dinonaktifkan; produk baru dikembangkan hanya menggunakan C * One. Kami mengadaptasi C * One untuk bekerja di cloud satu kami , yang memungkinkan kami untuk mempercepat penyebaran cluster baru, menyederhanakan konfigurasi dan mengotomatisasi operasi. Tanpa kode sumber, itu akan jauh lebih sulit dan pembuatan kruk.Sekarang kami sedang berupaya mentransfer fasilitas penyimpanan kami yang lain ke cloud - tetapi ini adalah kisah yang sangat berbeda.