Persyaratan apa yang harus dipenuhi oleh penyimpanan metadata untuk layanan cloud? Ya, bukan yang paling biasa, tetapi untuk perusahaan dengan dukungan untuk pusat data yang didistribusikan secara geografis dan Aktif-Aktif. Jelas, sistem harus berskala baik,
toleran terhadap kesalahan, dan ingin dapat mengimplementasikan konsistensi operasi yang dapat disesuaikan.Hanya Cassandra yang cocok untuk semua persyaratan ini, dan tidak ada yang cocok. Perlu dicatat bahwa Cassandra benar-benar keren, tetapi bekerja dengannya menyerupai roller coaster.
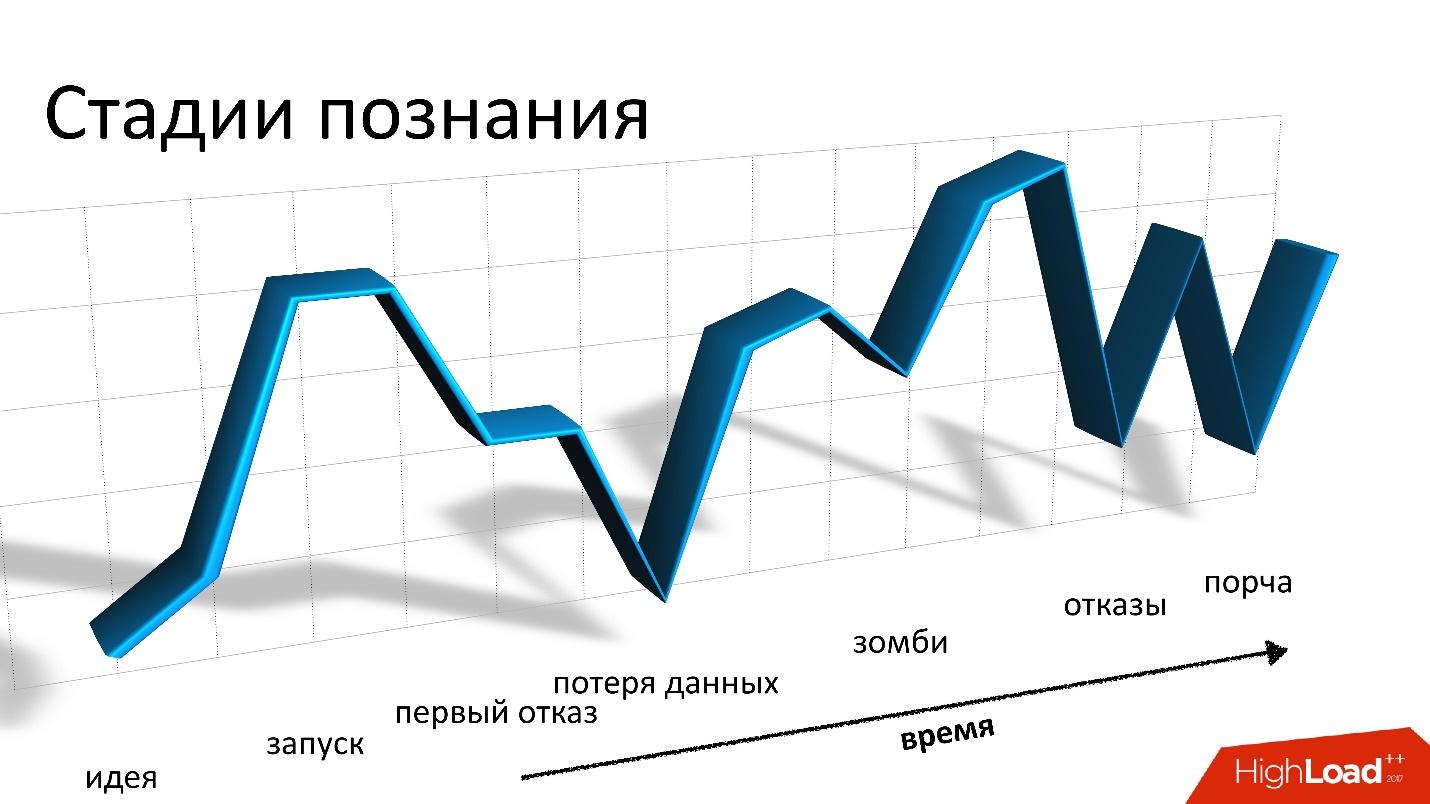
Dalam sebuah laporan di Highload ++ 2017,
Andrei Smirnov (
smira ) memutuskan bahwa tidak menarik untuk berbicara tentang yang baik, tetapi ia berbicara secara rinci tentang setiap masalah yang harus dihadapi: tentang kehilangan data dan korupsi, tentang zombie dan kehilangan kinerja. Kisah-kisah ini benar-benar mengingatkan kita pada roller coaster, tetapi untuk semua masalah ada solusinya, di mana Anda dipersilakan untuk melakukannya.
Tentang pembicara: Andrey Smirnov bekerja untuk Virtustream, sebuah perusahaan yang mengimplementasikan penyimpanan cloud untuk perusahaan. Idenya adalah bahwa secara kondisional Amazon melakukan cloud untuk semua orang, dan Virtustream melakukan hal-hal spesifik yang dibutuhkan perusahaan besar.
Beberapa kata tentang Virtustream
Kami bekerja dalam tim kecil yang sepenuhnya terpencil, dan kami terlibat dalam salah satu solusi cloud Virtustream. Ini adalah awan penyimpanan data.

Berbicara sangat sederhana, ini adalah API yang kompatibel S3 di mana Anda dapat menyimpan objek. Bagi mereka yang tidak tahu apa itu S3, itu hanya API HTTP yang dengannya Anda dapat mengunggah objek ke cloud di suatu tempat, mendapatkannya kembali, menghapusnya, mendapatkan daftar objek, dll. Selanjutnya - fitur yang lebih kompleks berdasarkan pada operasi sederhana ini.
Kami memiliki beberapa fitur khas yang tidak dimiliki Amazon. Salah satunya adalah yang disebut geo-region. Dalam situasi yang biasa, ketika Anda membuat repositori dan mengatakan bahwa Anda akan menyimpan objek di cloud, Anda harus memilih wilayah. Suatu wilayah pada dasarnya adalah pusat data, dan objek Anda tidak akan pernah meninggalkan pusat data ini. Jika sesuatu terjadi padanya, maka objek Anda tidak akan lagi tersedia.
Kami menawarkan geo-region di mana data secara bersamaan terletak di beberapa pusat data (DC), setidaknya dalam dua, seperti pada gambar. Klien dapat menghubungi pusat data apa saja, baginya itu transparan. Data di antara mereka direplikasi, yaitu, kami bekerja dalam mode Aktif-Aktif, dan terus-menerus. Ini memberikan klien dengan fitur tambahan, termasuk:
- keandalan penyimpanan, membaca dan menulis yang lebih besar jika terjadi kegagalan DC atau kehilangan konektivitas;
- ketersediaan data bahkan jika salah satu DC gagal;
- mengarahkan operasi ke DC "terdekat".
Ini adalah peluang yang menarik - bahkan jika DC ini secara geografis berjauhan, maka beberapa dari mereka mungkin lebih dekat dengan klien pada titik waktu yang berbeda. Dan mengakses data ke DC terdekat hanya lebih cepat.
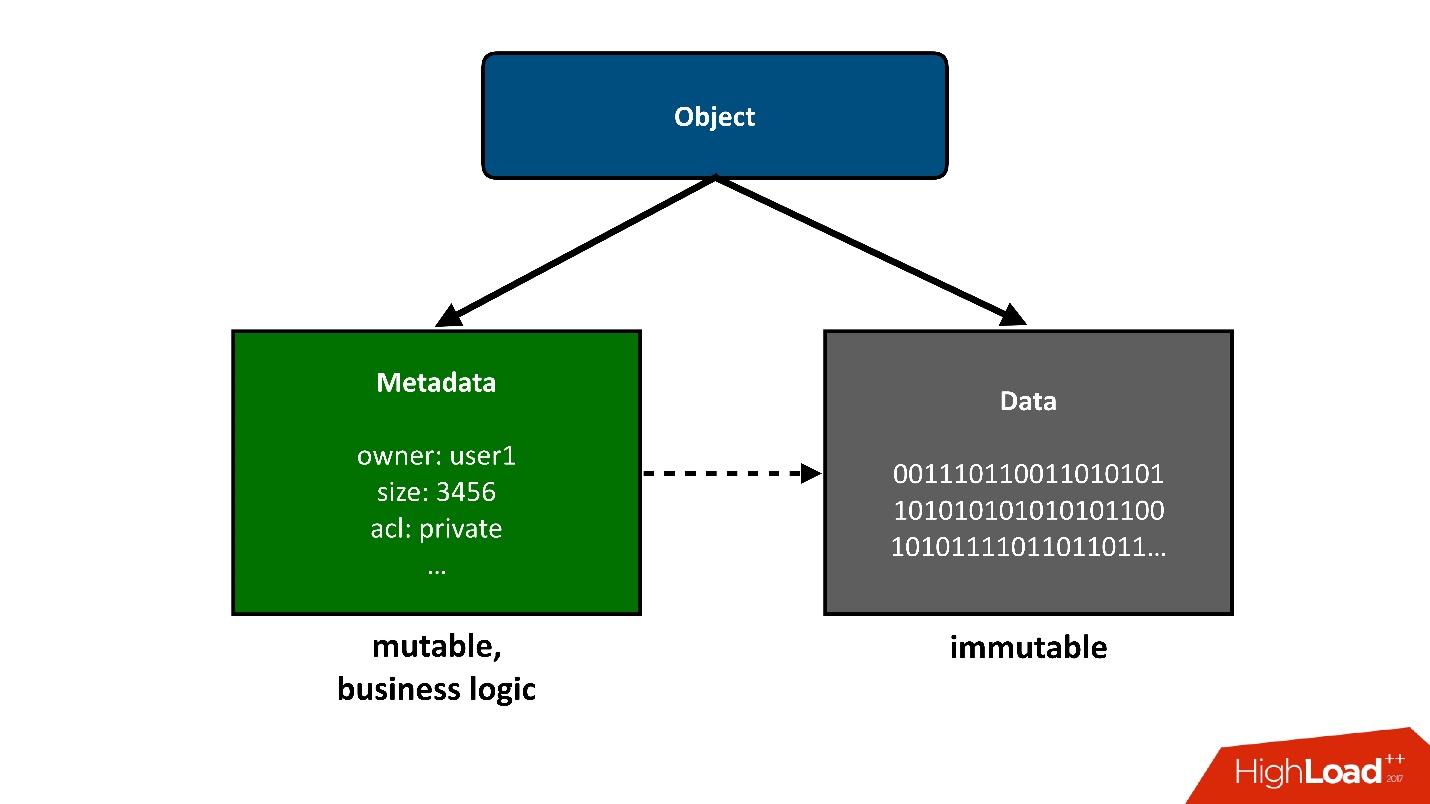
Untuk membagi konstruksi yang akan kita bicarakan menjadi beberapa bagian, saya akan menyajikan objek-objek yang disimpan di awan sebagai dua bagian besar:
1. Bagian sederhana pertama dari sebuah objek adalah
data . Mereka tidak berubah, mereka diunduh sekali dan itu saja. Satu-satunya hal yang dapat terjadi pada mereka nanti adalah kita dapat menghapusnya jika tidak diperlukan lagi.
Proyek kami sebelumnya terkait dengan penyimpanan exabytes data, jadi kami tidak punya masalah dengan penyimpanan data. Ini sudah merupakan tugas yang diselesaikan bagi kami.
2.
Metadata . Semua logika bisnis, semua yang paling menarik, terkait dengan kompetisi: akses, catatan, penulisan ulang - di area metadata.
Metadata tentang objek dengan sendirinya merupakan kompleksitas terbesar dari proyek, metadata menyimpan pointer ke blok data yang tersimpan dari objek.
Dari sudut pandang pengguna, ini adalah satu objek, tetapi kita dapat membaginya menjadi dua bagian. Hari ini saya
hanya akan berbicara
tentang metadata .
Tokoh
- Data : 4 Pbytes.
- Cluster Metadata : 3.
- Objek : 40 miliar.
- Ukuran metadata : 160 TB (termasuk replikasi).
- Tingkat perubahan (metadata): 3000 objek / s.
Jika Anda melihat indikator-indikator ini dengan cermat, hal pertama yang menarik perhatian Anda adalah ukuran rata-rata yang sangat kecil dari objek yang disimpan. Kami memiliki banyak metadata per unit volume data master. Bagi kami, itu tidak mengejutkan daripada mungkin untuk Anda sekarang.
Kami merencanakan bahwa kami akan memiliki setidaknya satu urutan data, jika tidak 2, lebih dari metadata. Artinya, setiap objek akan secara signifikan lebih besar, dan jumlah metadata akan lebih sedikit. Karena data lebih murah untuk disimpan, lebih sedikit operasi dengan mereka, dan metadata jauh lebih mahal baik dalam arti perangkat keras, dan dalam arti melayani dan melakukan berbagai operasi pada mereka.
Apalagi data ini berubah dengan kecepatan yang cukup tinggi. Saya telah memberikan nilai puncak di sini, nilai non-puncak tidak jauh lebih sedikit, tetapi, bagaimanapun, beban yang agak besar dapat diperoleh pada titik waktu tertentu.
Angka-angka ini sudah diperoleh dari sistem kerja, tetapi mari kita kembali sedikit, ke waktu merancang penyimpanan cloud.
Memilih repositori untuk metadata
Ketika kami menghadapi tantangan bahwa kami ingin memiliki geo-region, Active-Active, dan kami perlu menyimpan metadata di suatu tempat, kami pikir itu bisa terjadi?
Jelas, repositori (database) harus memiliki properti berikut:
- Dukungan Aktif-Aktif ;
- Skalabilitas.
Kami benar-benar ingin produk kami menjadi sangat populer, dan kami tidak tahu bagaimana itu akan tumbuh pada saat yang sama, sehingga sistemnya harus berkembang.
- Keseimbangan toleransi kesalahan dan keandalan penyimpanan.
Metadata harus disimpan dengan aman, karena jika kita kehilangan mereka, dan ada tautan ke data di dalamnya, maka kita akan kehilangan seluruh objek.
- Konsistensi operasi yang dapat disesuaikan.
Karena fakta bahwa kami bekerja di beberapa DC dan memungkinkan kemungkinan bahwa DC mungkin tidak tersedia, apalagi, DC jauh dari satu sama lain, kami tidak dapat, selama sebagian besar operasi API, mengharuskan operasi ini dilakukan secara bersamaan di dua DC. Itu hanya akan terlalu lambat dan tidak mungkin jika DC kedua tidak tersedia. Oleh karena itu, bagian dari operasi harus bekerja secara lokal dalam satu DC.
Tetapi, jelas, semacam konvergensi harus terjadi kapan-kapan, dan setelah menyelesaikan semua konflik, data harus terlihat di kedua pusat data. Karena itu, konsistensi operasi harus disesuaikan.
Dari sudut pandang saya, Cassandra cocok untuk persyaratan ini.
Cassandra
Saya akan sangat senang jika kami tidak harus menggunakan Cassandra, karena bagi kami itu adalah semacam pengalaman baru. Tapi tidak ada yang cocok. Bagi saya, ini adalah situasi yang paling menyedihkan di pasar untuk sistem penyimpanan semacam itu - tidak ada
alternatif .

Apa itu Cassandra?
Ini adalah basis data nilai kunci yang didistribusikan. Dari sudut pandang arsitektur dan ide-ide yang tertanam di dalamnya, tampak bagi saya bahwa semuanya keren. Jika saya melakukannya, saya akan melakukan hal yang sama. Ketika kami pertama kali mulai, kami berpikir untuk menulis sistem penyimpanan metadata kami sendiri. Tetapi semakin jauh, semakin kita menyadari bahwa kita harus melakukan sesuatu yang sangat mirip dengan Cassandra, dan upaya yang akan kita keluarkan untuk itu tidak sepadan. Untuk keseluruhan pengembangan
, kami hanya memiliki satu setengah bulan . Akan aneh menghabiskan mereka menulis basis data Anda.
Jika Cassandra berlapis seperti kue lapis, saya akan memilih 3 lapisan:
1.
Penyimpanan KV lokal pada setiap node.Ini adalah sekelompok node, yang masing-masing dapat menyimpan data nilai kunci secara lokal.
2.
Sharding data on node (hashing konsisten).Cassandra dapat mendistribusikan data di antara node cluster, termasuk replikasi, dan melakukannya sedemikian rupa sehingga cluster dapat tumbuh atau berkurang ukurannya, dan data akan didistribusikan kembali.
3.
Koordinator untuk mengalihkan permintaan ke node lain.Ketika kita mengakses data untuk beberapa kueri dari aplikasi kita, Cassandra dapat mendistribusikan kueri kita ke dalam node sehingga kita mendapatkan data yang kita inginkan dan dengan tingkat konsistensi yang kita butuhkan - kita hanya ingin membacanya kuorum, atau ingin kuorum dengan dua DC, dll.
Bagi kami, dua tahun bersama Cassandra - itu roller coaster atau roller coaster - apa pun yang Anda inginkan. Semuanya dimulai jauh di lubuk hati, kami tidak memiliki pengalaman dengan Cassandra. Kami takut. Kami mulai, dan semuanya baik-baik saja. Tapi kemudian jatuh dan tinggal landas terus-menerus dimulai: masalahnya, semuanya buruk, kami tidak tahu harus berbuat apa, kami mendapatkan kesalahan, lalu kami memecahkan masalah, dll.
Roller coaster ini, pada prinsipnya, tidak berakhir sampai hari ini.
Bagus
Bab pertama dan terakhir, di mana saya mengatakan bahwa Cassandra itu keren. Ini benar-benar keren, sistem yang hebat, tetapi jika saya terus mengatakan betapa bagusnya, saya pikir Anda tidak akan tertarik. Karena itu, kita akan lebih memperhatikan yang buruk, tetapi nanti.
Cassandra benar-benar bagus.
- Ini adalah salah satu sistem yang memungkinkan kita untuk memiliki waktu respons dalam milidetik , yaitu, jelas kurang dari 10 ms. Ini bagus untuk kita, karena waktu respons secara umum penting bagi kita. Operasi dengan metadata bagi kita hanyalah bagian dari operasi apa pun yang terkait dengan penyimpanan suatu objek, baik itu menerima atau merekam.
- Dari sudut pandang perekaman, skalabilitas tinggi tercapai. Anda dapat menulis di Cassandra dengan kecepatan yang gila, dan dalam beberapa situasi ini diperlukan, misalnya, saat kami memindahkan sejumlah besar data di antara catatan.
- Cassandra benar-benar toleran terhadap kesalahan . Jatuhnya satu node tidak langsung menyebabkan masalah, meskipun cepat atau lambat mereka akan mulai. Cassandra menyatakan bahwa ia tidak memiliki satu titik kegagalan, tetapi, pada kenyataannya, ada titik-titik kegagalan di mana-mana. Bahkan, orang yang bekerja dengan database tahu bahwa bahkan sebuah node crash bukanlah sesuatu yang biasanya diderita sampai pagi hari. Biasanya, situasi ini perlu diperbaiki lebih cepat.
- Kesederhanaan. Namun, dibandingkan dengan database relasional Cassandra standar lainnya, lebih mudah untuk memahami apa yang sedang terjadi. Sangat sering, terjadi kesalahan, dan kita perlu memahami apa yang terjadi. Cassandra memiliki lebih banyak peluang untuk mengetahuinya, sampai ke sekrup terkecil, mungkin, daripada dengan database lain.
Lima Cerita Buruk
Saya ulangi, Cassandra baik, itu bekerja untuk kita, tetapi saya akan menceritakan lima cerita tentang yang buruk. Saya pikir ini untuk apa Anda membacanya. Saya akan memberikan cerita dalam urutan kronologis, meskipun mereka tidak saling terhubung.

Kisah ini adalah yang paling menyedihkan bagi kami. Karena kami menyimpan data pengguna, hal terburuk yang mungkin terjadi adalah kehilangannya, dan
hilang selamanya , seperti yang terjadi dalam situasi ini. Kami telah menyediakan cara untuk memulihkan data jika kehilangannya di Cassandra, tetapi kami kehilangannya sehingga kami benar-benar tidak dapat memulihkannya.
Untuk menjelaskan bagaimana ini terjadi, saya harus berbicara sedikit tentang bagaimana semuanya diatur dalam diri kita.
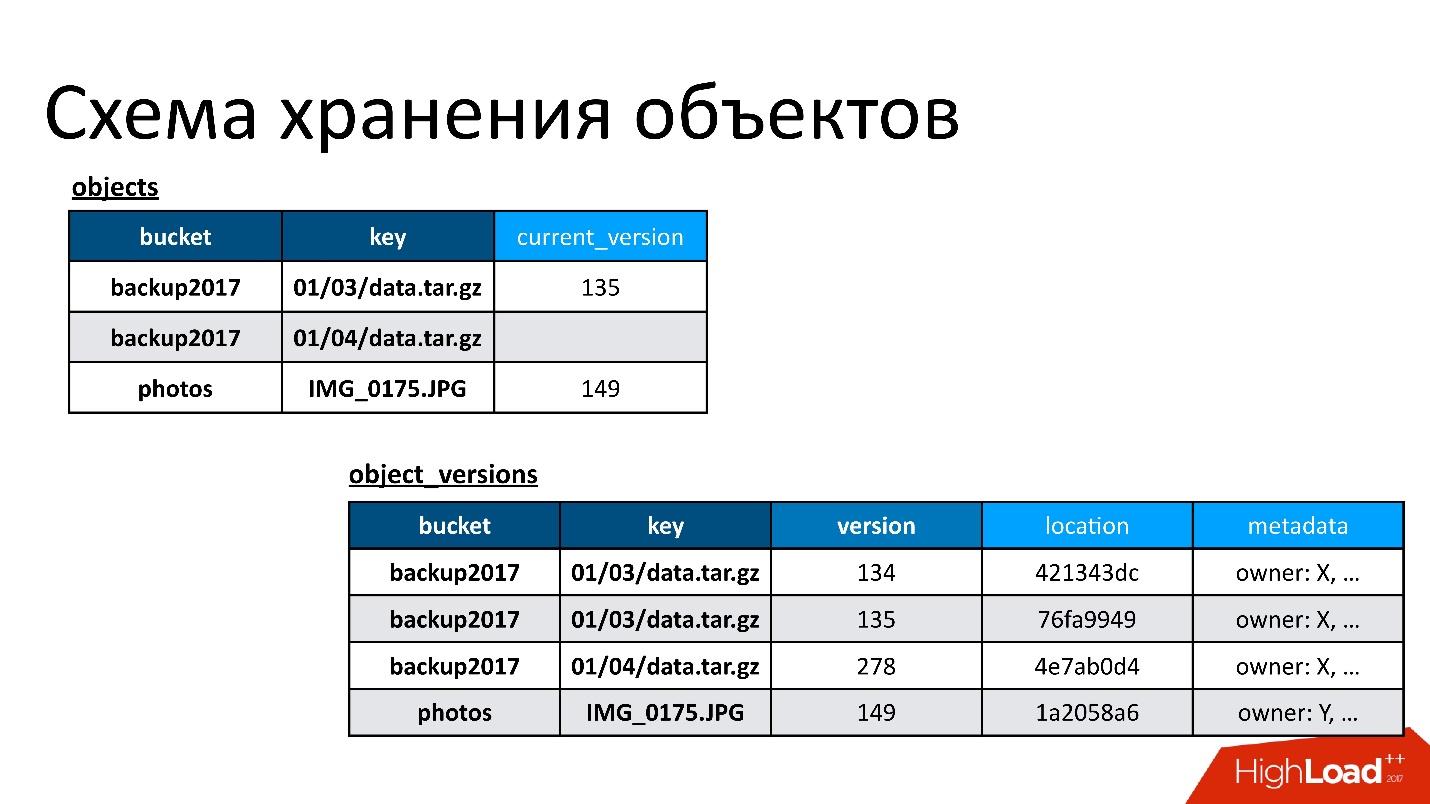
Dari perspektif S3, ada beberapa hal mendasar:
- Bucket - dapat dibayangkan sebagai katalog besar tempat pengguna mengunggah objek (selanjutnya disebut sebagai bucket).
- Setiap objek memiliki nama (kunci) dan metadata yang terkait dengannya: ukuran, tipe konten, dan penunjuk ke data objek. Pada saat yang sama, ukuran ember tidak dibatasi oleh apa pun. Artinya, bisa 10 kunci, mungkin 100 miliar kunci - tidak ada perbedaan.
- Setiap operasi kompetitif dimungkinkan, yaitu, mungkin ada beberapa isian kompetitif dalam kunci yang sama, mungkin ada penghapusan kompetitif, dll.
Dalam situasi kami, aktif-aktif, operasi dapat terjadi, termasuk secara kompetitif di berbagai DC, tidak hanya dalam satu. Oleh karena itu, kita memerlukan semacam skema konservasi yang memungkinkan kita untuk mengimplementasikan logika tersebut. Pada akhirnya, kami memilih kebijakan sederhana: versi yang terakhir direkam akan menang. Terkadang beberapa operasi kompetitif terjadi, tetapi pelanggan tidak perlu melakukan ini dengan sengaja. Mungkin saja itu permintaan yang dimulai, tetapi klien tidak menunggu jawaban, sesuatu yang lain terjadi, mencoba lagi, dll.
Oleh karena itu, kami memiliki dua tabel dasar:
- Daftar benda . Di dalamnya, sepasang - nama ember dan nama kunci - dikaitkan dengan versi saat ini. Jika objek dihapus, maka tidak ada dalam versi ini. Jika objek ada, ada versi saat ini. Bahkan, dalam tabel ini kami hanya mengubah bidang versi saat ini.
- Tabel versi objek . Kami hanya memasukkan versi baru ke dalam tabel ini. Setiap kali objek baru diunduh, kami menyisipkan versi baru ke dalam tabel versi, memberikan nomor unik, menyimpan semua informasi tentangnya, dan pada akhirnya memperbarui tautannya ke dalam tabel objek.
Gambar tersebut menunjukkan contoh bagaimana tabel objek dan versi objek saling berhubungan.

Berikut adalah objek yang memiliki dua versi - satu saat ini dan yang lama, ada objek yang telah dihapus, dan versinya masih ada. Kita perlu membersihkan versi yang tidak perlu dari waktu ke waktu, yaitu menghapus sesuatu yang tidak dirujuk orang lain. Selain itu, kami tidak perlu langsung menghapusnya, kami bisa melakukannya dalam mode ditangguhkan. Ini adalah pembersihan internal kami, kami hanya menghapus apa yang tidak lagi diperlukan.
Ada masalah.
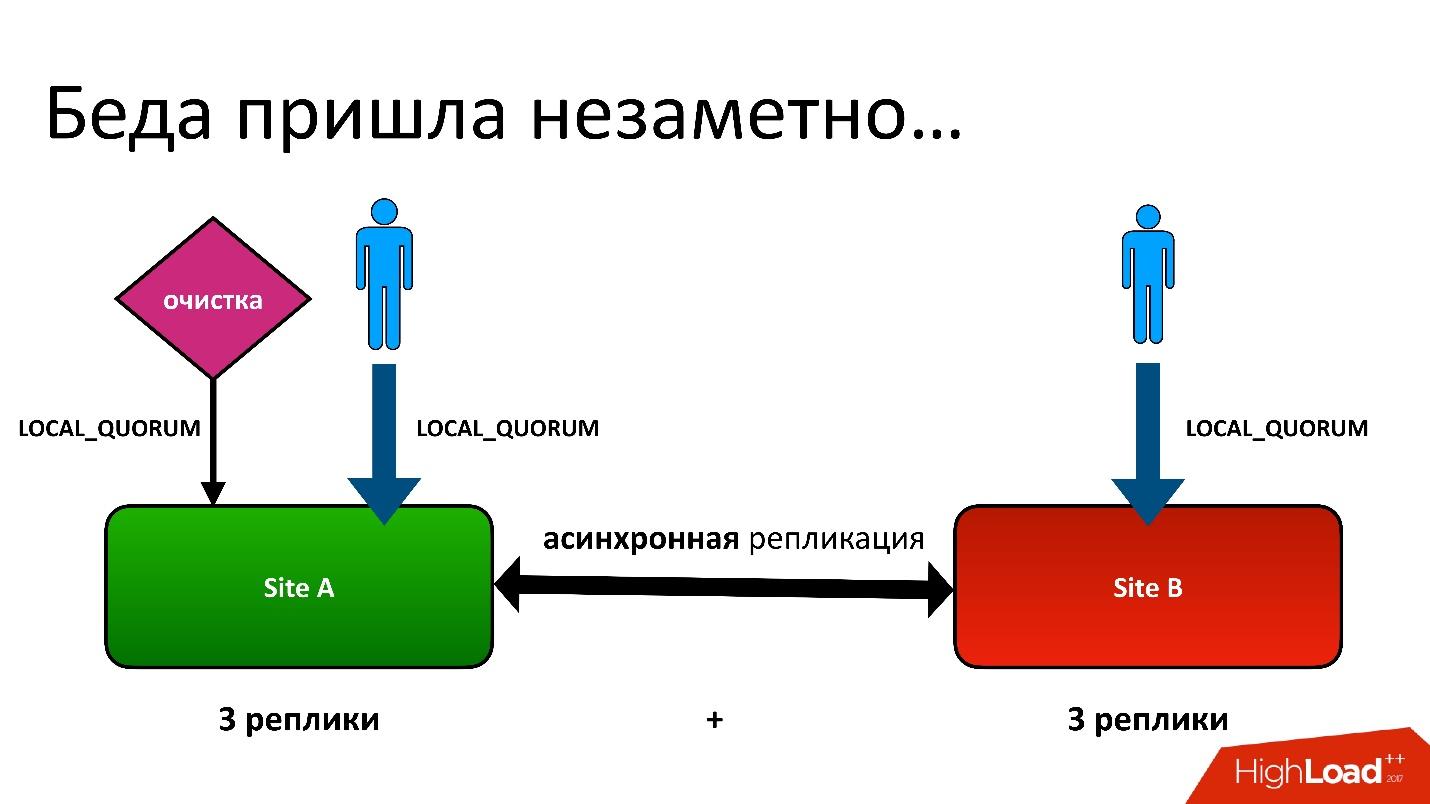
Masalahnya adalah ini: kami memiliki aktif-aktif, dua DC. Di setiap DC, metadata disimpan dalam tiga salinan, yaitu, kami memiliki 3 + 3 - hanya 6 replika. Ketika klien menghubungi kami, kami melakukan operasi dengan konsistensi (dari sudut pandang Cassandra disebut LOCAL_QUORUM). Artinya, dijamin bahwa catatan (atau baca) terjadi dalam 2 replika di DC lokal. Ini adalah jaminan - jika tidak operasi akan gagal.
Cassandra akan selalu mencoba untuk menulis di semua 6 baris - 99% dari waktu semuanya akan baik-baik saja. Bahkan, semua 6 replika akan sama, tetapi dijamin kepada kami 2.
Kami memiliki situasi yang sulit, meskipun itu bahkan bukan wilayah geografis. Bahkan untuk wilayah biasa yang berada dalam satu DC, kami masih menyimpan salinan kedua metadata di DC lain. Ini adalah cerita yang panjang, saya tidak akan memberikan semua detailnya. Tetapi pada akhirnya, kami memiliki proses pembersihan yang menghapus versi yang tidak perlu.
Dan kemudian muncul masalah yang sama. Proses pembersihan juga bekerja dengan konsistensi kuorum lokal di satu pusat data, karena tidak ada gunanya menjalankannya dalam dua - mereka akan saling bertarung.
Semuanya baik-baik saja sampai ternyata pengguna kami terkadang masih menulis ke pusat data lain, yang tidak kami duga. Semuanya diatur untuk berjaga-jaga untuk feylover, tetapi ternyata mereka sudah menggunakannya.
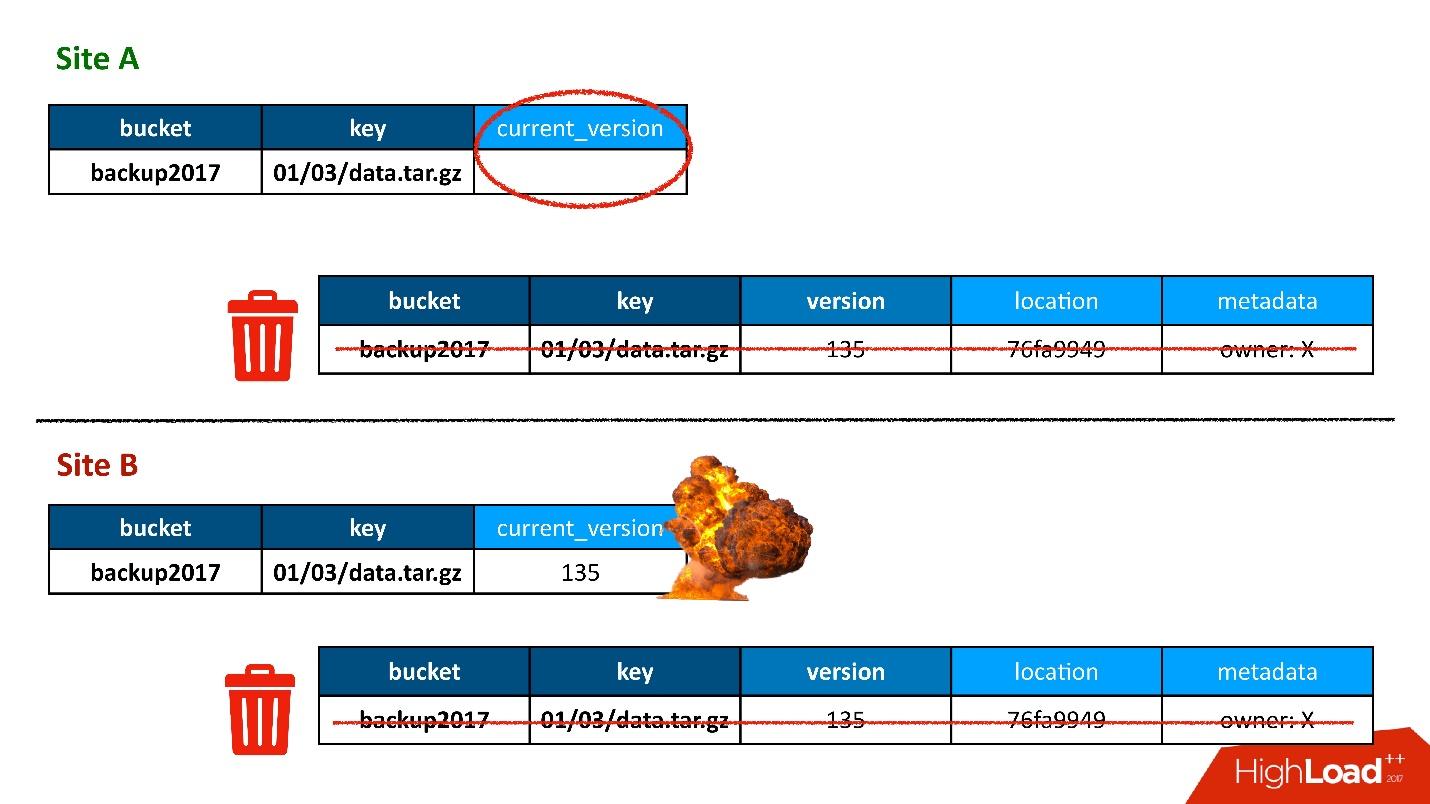
Sebagian besar waktu, semuanya baik-baik saja sampai suatu hari muncul situasi di mana entri dalam tabel versi direplikasi di kedua DC, tetapi catatan di tabel objek ternyata hanya dalam satu DC, dan tidak berakhir di yang kedua. Dengan demikian, prosedur pembersihan, diluncurkan di DC pertama (atas), melihat bahwa ada versi yang tidak ada yang merujuk dan menghapusnya. Dan saya tidak hanya menghapus versi, tetapi juga, tentu saja, data - semuanya benar-benar, karena itu hanya objek yang tidak perlu. Dan penghapusan ini tidak dapat dibatalkan.
Tentu saja, ada "booming" lebih lanjut, karena kita masih memiliki catatan dalam tabel objek yang merujuk ke versi yang tidak ada lagi.
Jadi pertama kali kami kehilangan data, dan kami kehilangan itu benar-benar tidak dapat dibatalkan - bagus, sedikit.
Solusi
Apa yang harus dilakukan Dalam situasi kita, semuanya sederhana.
Karena kami memiliki data yang disimpan di dua pusat data, proses pembersihan adalah proses konvergensi dan sinkronisasi. Kita harus membaca data dari kedua DC. Proses ini hanya akan berfungsi ketika kedua DC tersedia. Karena saya katakan bahwa ini adalah proses tertunda yang tidak terjadi selama pemrosesan API, ini tidak menakutkan.
Consistency ALL adalah fitur Cassandra 2. Dalam Cassandra 3, semuanya sedikit lebih baik - ada tingkat konsistensi, yang disebut kuorum di setiap DC. Tapi bagaimanapun, ada masalah yang
lambat , karena, pertama, kita harus beralih ke DC jarak jauh. Kedua, dalam hal konsistensi semua 6 node, ini berarti bahwa ia bekerja pada kecepatan yang terburuk dari 6 node ini.
Tetapi pada saat yang sama, proses
perbaikan-baca terjadi, ketika tidak semua replika sinkron. Artinya, ketika rekaman gagal di suatu tempat, proses ini secara bersamaan memperbaikinya. Begitulah cara kerja Cassandra.
Ketika ini terjadi, kami menerima keluhan dari klien bahwa objek tidak tersedia. Kami menemukan jawabannya, mengerti alasannya, dan hal pertama yang ingin kami lakukan adalah mencari tahu berapa banyak lagi benda yang kita miliki. Kami menjalankan skrip yang mencoba menemukan konstruksi yang mirip dengan ini ketika ada entri di satu tabel, tetapi tidak ada entri di yang lain.
Tiba-tiba kami menemukan bahwa kami memiliki
10% dari catatan tersebut . Tidak ada yang lebih buruk, mungkin, tidak akan terjadi jika kita tidak menduga bahwa ini bukan masalahnya. Masalahnya berbeda.

Zombi telah merayap ke dalam basis data kami. Ini adalah nama semi-resmi untuk masalah ini. Untuk memahami apa itu, Anda perlu berbicara tentang cara kerja penghapusan di Cassandra.
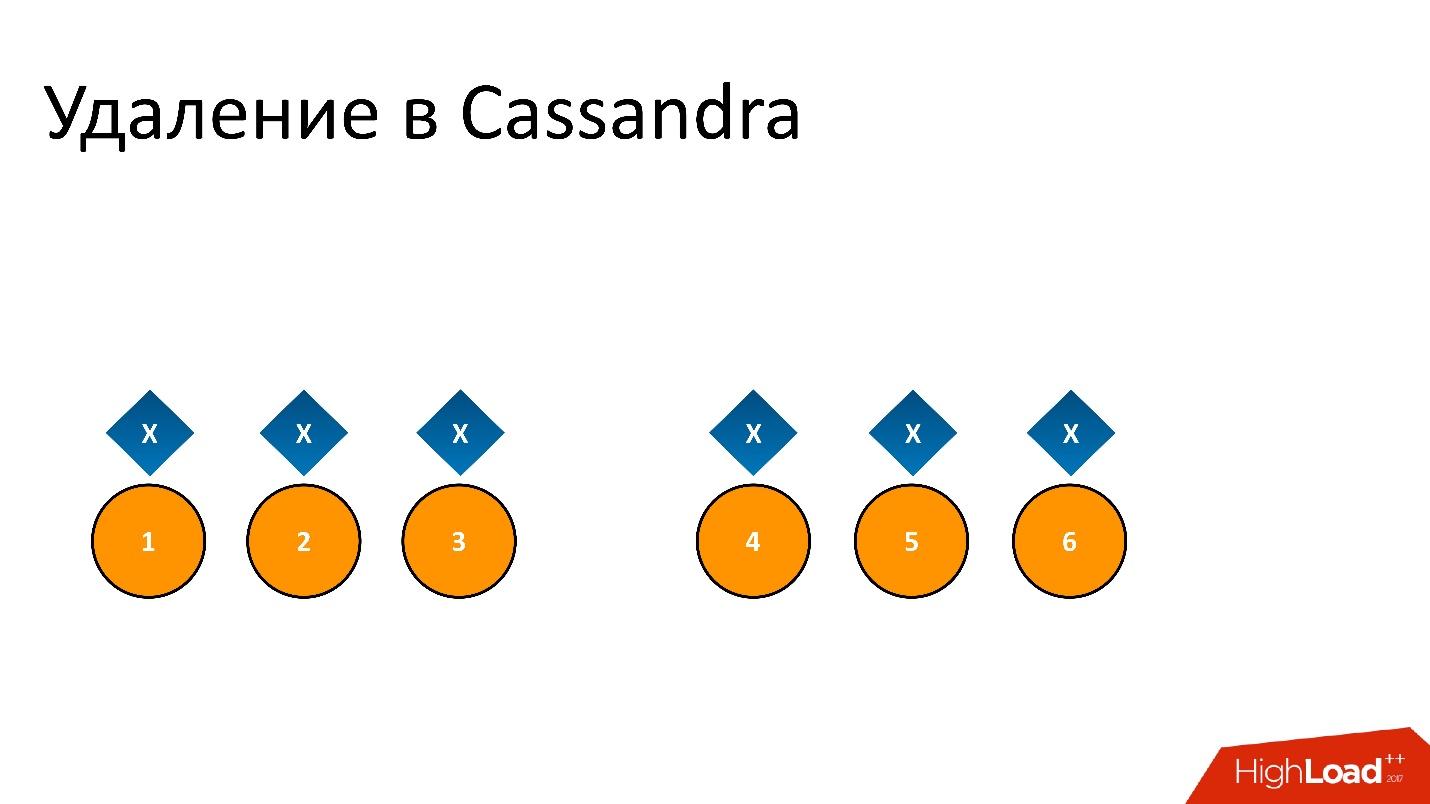
Sebagai contoh, kami memiliki beberapa data
x yang direkam dan direplikasi dengan sempurna untuk semua 6 replika. Jika kami ingin menghapusnya, penghapusan, seperti operasi apa pun di Cassandra, mungkin tidak dilakukan pada semua node.
Sebagai contoh, kami ingin menjamin konsistensi 2 dari 3 dalam satu DC. Biarkan operasi penghapusan dilakukan pada lima node, tetapi tetap pada satu catatan, misalnya, karena node tidak tersedia pada saat itu.
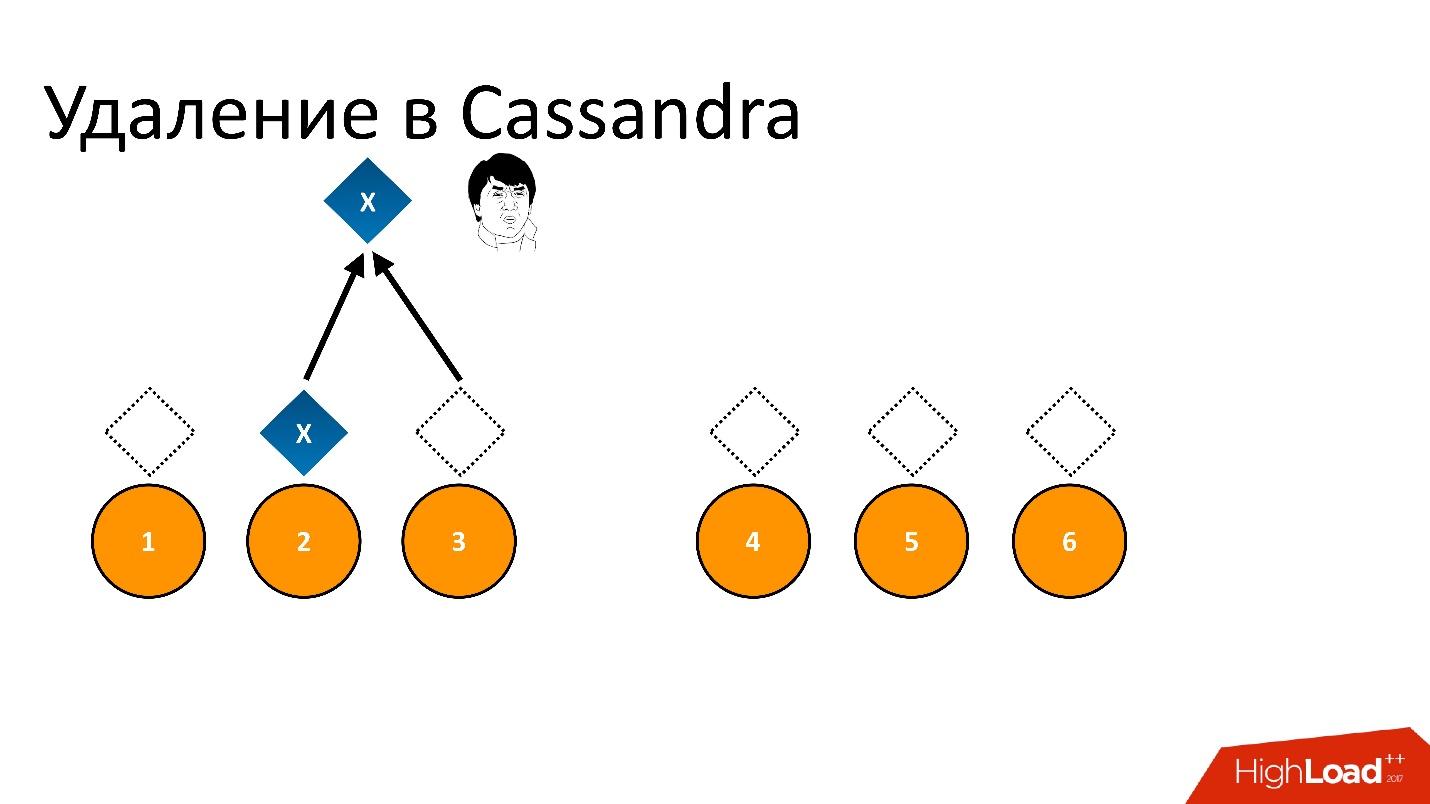
Jika kita menghapus ini dan kemudian mencoba membaca "Saya ingin 2 dari 3" dengan konsistensi yang sama, maka Cassandra, melihat nilai dan ketiadaannya, menafsirkan ini sebagai keberadaan data. Artinya, ketika membaca kembali, dia akan berkata: "Oh, ada data!", Meskipun kami menghapusnya. Karenanya, Anda tidak dapat menghapus dengan cara ini.

Cassandra menghapus secara berbeda.
Penghapusan sebenarnya sebuah catatan . Ketika kami menghapus data, Cassandra menulis beberapa penanda kecil yang disebut
Tombstone (batu nisan). Itu menandakan bahwa data dihapus. Jadi, jika kita membaca token penghapusan dan data pada saat yang sama, Cassandra selalu lebih suka token penghapusan dalam situasi ini dan mengatakan bahwa sebenarnya tidak ada data. Ini yang kamu butuhkan.
Tombstone — , , , , - , . Tombstone .
Tombstone gc_grace_period . , , .
?
Repair
Cassandra , Repair (). — , . , , , , / , , - - , .. . Repair , .

, - , - . Repair , , . - , — . , .

Repair, , , , — , . 6 . — , , .

, — , - . , . , - , , , .
Solusi
, :
, repair. , , .
repair — , repair. , , 10-20 , , 3 . Tombstone , . , , -.

Cassandra, . .
S3 . , — 10 , 100 . API, — . , , , , , . , , , — , . .
API?

, — , , — , , . . — . , , . , , Cassandra. , — , , , .
, , , , . , . , , . , - , .
Cassandra , . , , , , , .
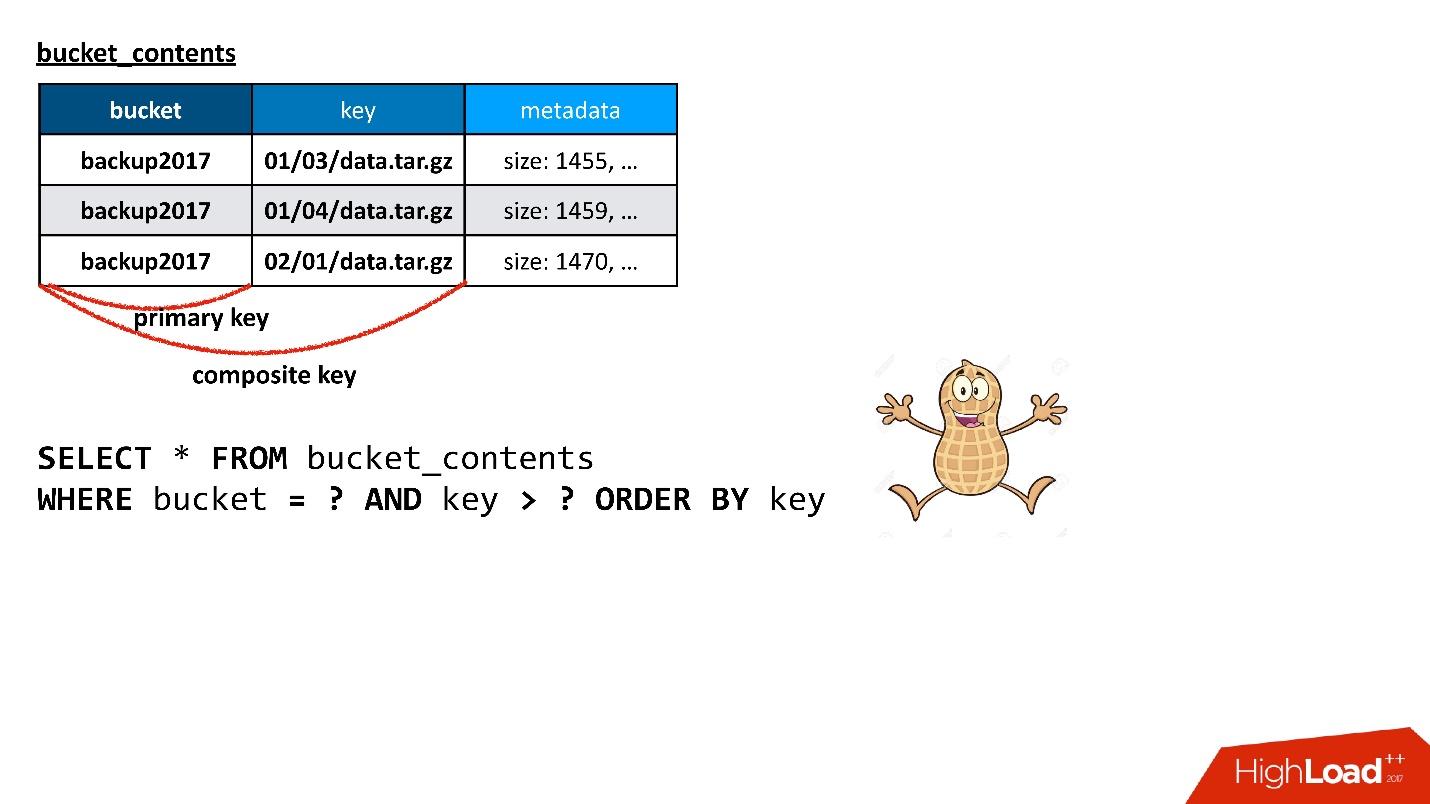
, Cassandra
composite key . , — , - , — . , . ? , , !
, , , , — , .
. Cassandra ,
Cassandra . , , Cassandra, : , , SQL .. !

. Cassandra ? , , API. , , , , ( ) .
, .
, . , , , . , — — . , , , .
Cassandra , . : « 100 », , , , , , 100, .
, ( ), — , , . , , , , , - . 100 , - , , . , SQL .
Cassandra , , Java, . ,
Large Partition , . — , , , , — . , , garbage collection .. .
, ,
, , .
, , - .

, , . . , Large Partition.
:
- ( , - );
- , , . , .
, , , key_hash 0. ,
, . , . , , .
, .

— , , , - - .
— , N ? , Large Partition, — . , . : . , , , , - . , . , , .

— , , - . - , , . , , . , , ..
— , ? , . ? - md5- — , - 30 — , - . . , , .

, , , , . — , . , . , - - - , - - — . , . .
, , , .
- .
- .
- Cassandra.
- Redistribusi online (tanpa menghentikan operasi dan kehilangan konsistensi).
Kami memiliki beberapa kondisi bucket sekarang, entah bagaimana dibagi menjadi beberapa partisi. Kemudian kami memahami bahwa beberapa partisi terlalu besar atau terlalu kecil. Kita perlu menemukan partisi baru, yang, di satu sisi, akan optimal, yaitu, ukuran setiap partisi akan kurang dari beberapa batas kami, dan mereka akan lebih atau kurang seragam. Dalam hal ini, transisi dari kondisi saat ini ke yang baru harus memerlukan jumlah tindakan minimum. Jelas bahwa setiap transisi memerlukan kunci yang bergerak di antara partisi, tetapi semakin sedikit kita memindahkannya, semakin baik.
Kami berhasil. Mungkin, bagian yang berhubungan dengan pemilihan distribusi adalah bagian paling sulit dari seluruh layanan, jika kita berbicara tentang bekerja dengan metadata secara umum. Kami menulis ulang, mengolahnya, dan masih melakukannya, karena beberapa klien atau pola tertentu membuat kunci selalu ditemukan yang mengenai titik lemah skema ini.
Misalnya, kami berasumsi bahwa ember akan tumbuh kurang lebih secara merata. Yaitu, kami mengambil beberapa jenis distribusi, dan berharap semua partisi akan tumbuh sesuai dengan distribusi ini. Tetapi kami menemukan klien yang selalu menulis pada akhirnya, dalam arti bahwa kuncinya selalu dalam urutan. Setiap saat ia berdetak di partisi terakhir, yang tumbuh dengan kecepatan sedemikian rupa sehingga dalam satu menit bisa mencapai 100 ribu kunci. Dan 100 ribu kira-kira nilai yang cocok menjadi satu partisi.
Kami tidak akan punya waktu untuk memproses penambahan kunci dengan algoritma kami, dan kami harus memperkenalkan distribusi pendahuluan khusus untuk klien ini. Karena kita tahu seperti apa kuncinya, jika kita melihat bahwa itu adalah dia, kita baru mulai membuat partisi kosong terlebih dahulu di akhir, sehingga dia dapat menulis dengan tenang di sana, dan untuk sekarang kita akan memiliki sedikit istirahat hingga iterasi berikutnya, ketika kita lagi harus mendistribusikan kembali semuanya.
Semua ini terjadi online dalam arti bahwa kami tidak menghentikan operasi. Mungkin ada operasi baca, tulis, kapan saja Anda dapat meminta daftar kunci. Itu akan selalu konsisten, bahkan jika kita sedang dalam proses partisi ulang.
Ini cukup menarik, dan ternyata dengan Cassandra. Di sini Anda dapat bermain dengan trik yang terkait dengan fakta bahwa Cassandra dapat menyelesaikan konflik. Jika kami menulis dua nilai berbeda pada baris yang sama, maka nilai yang memiliki stempel waktu yang lebih besar akan menang.
Biasanya timestamp adalah timestamp saat ini, tetapi dapat dilewati secara manual. Misalnya, kami ingin menulis nilai ke string, yang dalam hal apa pun harus dihapus jika klien menulis sesuatu sendiri. Artinya, kami menyalin beberapa data, tetapi kami menginginkan klien, jika dia tiba-tiba menulis bersama kami pada saat yang sama, dapat menimpanya. Lalu kita bisa menyalin data kita dengan cap waktu sedikit dari masa lalu. Kemudian rekaman apa pun saat ini akan sengaja dihancurkan, terlepas dari urutan pembuatan rekaman itu.
Trik semacam itu memungkinkan Anda melakukan ini secara online.
Solusi
- Jangan, jangan pernah mengizinkan penampilan partisi yang besar .
- Memecah data dengan kunci utama tergantung pada tugas.
Jika sesuatu yang mirip dengan partisi besar direncanakan dalam skema data, Anda harus segera mencoba melakukan sesuatu tentang hal itu - cari tahu cara memecahnya dan bagaimana cara menghindarinya. Cepat atau lambat, ini muncul, karena setiap indeks terbalik cepat atau lambat muncul di hampir semua tugas. Saya sudah memberi tahu Anda tentang cerita seperti itu - kami memiliki kunci ember di objek, dan kami perlu mendapatkan daftar kunci dari ember - sebenarnya, ini adalah indeks.
Selain itu, partisi bisa besar tidak hanya dari data, tetapi juga dari Tombstone (penanda penghapusan). Dari sudut pandang internal Cassandra (kita tidak pernah melihatnya dari luar), spidol penghapusan juga data, dan partisi dapat menjadi besar jika banyak hal dihapus di dalamnya, karena penghapusan adalah sebuah catatan. Anda seharusnya tidak melupakan ini juga.

Kisah lain yang sebenarnya konstan adalah bahwa ada yang tidak beres dari awal hingga akhir. Misalnya, Anda melihat bahwa waktu respons dari Cassandra telah meningkat, ia merespons dengan lambat. Bagaimana memahami dan memahami apa masalahnya? Tidak pernah ada sinyal eksternal bahwa masalahnya ada di sana.

Misalnya, saya akan memberikan grafik - ini adalah waktu respons rata-rata dari cluster secara keseluruhan. Ini menunjukkan bahwa kami memiliki masalah - waktu respons maksimum adalah 12 detik - ini adalah batas waktu internal Cassandra. Ini berarti dia akan menyendiri. Jika batas waktu di atas 12 detik, kemungkinan besar ini berarti bahwa pemulung bekerja, dan Cassandra bahkan tidak punya waktu untuk merespons pada waktu yang tepat. Dia menjawab sendiri dengan batas waktu, tetapi waktu respons untuk sebagian besar permintaan, seperti yang saya katakan, harus rata-rata dalam 10 ms.
Pada grafik, rata-rata telah melebihi ratusan milidetik - ada yang salah. Tetapi melihat gambar ini, tidak mungkin untuk memahami apa alasannya.

Tetapi jika Anda memperluas statistik yang sama pada node Cassandra, Anda dapat melihat bahwa, pada prinsipnya, semua node lebih atau kurang sama sekali, tetapi waktu respon untuk satu node berbeda berdasarkan urutan besarnya. Kemungkinan besar, ada beberapa masalah dengannya.
Statistik pada node mengubah gambar sepenuhnya. Statistik ini berasal dari sisi aplikasi. Tetapi di sini sebenarnya sangat sering sulit untuk memahami apa masalahnya. Ketika suatu aplikasi mengakses Cassandra, ia mengakses beberapa simpul, menggunakannya sebagai koordinator. Artinya, aplikasi memberikan permintaan, dan koordinator mengalihkannya ke replika dengan data. Mereka sudah menjawab, dan koordinator membentuk jawaban akhir.
Tetapi mengapa koordinator merespons dengan lambat? Mungkin masalahnya dengan dia, dengan demikian, yaitu, dia melambat dan menjawab perlahan? Atau mungkin dia melambat, karena replika meresponsnya dengan lambat? Jika replika merespons dengan lambat, dari sudut pandang aplikasi itu akan terlihat seperti respons lambat dari koordinator, meskipun tidak ada hubungannya dengan itu.
Inilah situasi yang membahagiakan - jelas bahwa hanya satu simpul yang merespons secara lambat, dan kemungkinan besar masalahnya ada di dalamnya.
Kompleksitas penafsiran
- Waktu respons koordinator (simpul vs. replika itu sendiri).
- Tabel spesifik atau seluruh simpul?
- Jeda GC? Pool Thread Tidak Memadai?
- Terlalu banyak SSTable yang tidak dikompilasi?
Selalu sulit untuk memahami apa yang salah. Itu hanya
membutuhkan banyak statistik dan pemantauan , baik dari sisi aplikasi dan dari Cassandra sendiri, karena jika itu benar-benar buruk, tidak ada yang terlihat dari Cassandra. Anda bisa melihat tingkat permintaan individu, di tingkat setiap tabel tertentu, di setiap node tertentu.
Mungkin ada, misalnya, situasi di mana satu tabel dari apa yang disebut dalam Cassandra SSTables (file terpisah) memiliki terlalu banyak. Untuk membaca, Cassandra secara kasar telah memilah-milah semua SSTable. Jika jumlah mereka terlalu banyak, maka proses penyortiran ini memakan waktu terlalu lama, dan membaca mulai melorot.
Solusinya adalah pemadatan, yang mengurangi jumlah SSTable ini, tetapi harus dicatat bahwa itu hanya pada satu node untuk satu tabel tertentu. Karena Cassandra, sayangnya, ditulis di Jawa dan dijalankan pada JVM, mungkin pemulung telah berhenti sehingga tidak punya waktu untuk merespons. Ketika pengumpul sampah berhenti, tidak hanya permintaan Anda melambat, tetapi
interaksi dalam gugus Cassandra antara node mulai melambat . Simpul satu sama lain mulai dianggap telah turun, yaitu, jatuh, mati.
Situasi yang lebih menyenangkan dimulai, karena ketika sebuah node menganggap bahwa node lain sedang down, itu, pertama, tidak mengirim permintaan ke sana, dan kedua, itu mulai mencoba untuk menyimpan data yang perlu direplikasi ke node lain di dirinya sendiri secara lokal, jadi dia mulai bunuh diri perlahan, dll.
Ada situasi di mana masalah ini dapat diselesaikan hanya dengan menggunakan pengaturan yang benar. Misalnya, mungkin ada sumber daya yang cukup, semuanya baik-baik saja dan luar biasa, tetapi hanya Thread Pool, yang jumlahnya adalah ukuran tetap, perlu ditingkatkan.
Akhirnya, mungkin kita perlu membatasi daya saing di sisi pengemudi. Kadang-kadang terjadi bahwa terlalu banyak permintaan kompetitif dikirim, dan seperti basis data apa pun, Cassandra tidak dapat menanganinya dan pergi ke klinik ketika waktu respons meningkat secara eksponensial, dan kami berusaha untuk memberikan lebih banyak pekerjaan.
Memahami konteksnya
Selalu ada beberapa konteks untuk masalah - apa yang terjadi di gugus, apakah Perbaikan berfungsi sekarang, pada simpul mana, di mana ruang-ruang utama, di tabel mana.
Misalnya, kami mengalami masalah yang agak konyol dengan zat besi. Kami melihat bahwa bagian dari node lambat. Kemudian ditemukan bahwa alasannya adalah bahwa di BIOS prosesor mereka berada dalam mode hemat energi. Untuk beberapa alasan, selama pemasangan awal besi, ini terjadi, dan sekitar 50% dari sumber daya prosesor digunakan dibandingkan dengan node lain.
Memahami masalah seperti itu bisa sulit, sebenarnya. Gejalanya adalah ini - tampaknya simpul melakukan pemadatan, tetapi melakukannya perlahan-lahan. Terkadang terhubung dengan besi, terkadang tidak, tapi ini hanyalah bug Cassandra.
Oleh karena itu, pemantauan adalah wajib dan perlu banyak. Semakin kompleks fitur di Cassandra, semakin jauh dari menulis sederhana dan membaca, semakin banyak masalah dengan itu, dan semakin cepat dapat membunuh database dengan jumlah pertanyaan yang cukup. Karena itu, jika mungkin, jangan melihat beberapa keripik "enak" dan mencoba menggunakannya, lebih baik hindari keripik sebanyak mungkin. Tidak selalu mungkin - tentu saja, cepat atau lambat itu perlu.

Kisah terakhir adalah tentang bagaimana Cassandra mengacaukan data. Dalam situasi ini, itu terjadi di dalam Cassandra. Itu menarik.
Kami melihat bahwa sekitar sekali seminggu di basis data kami beberapa lusin garis yang rusak muncul - mereka benar-benar tersumbat oleh sampah. Selain itu, Cassandra memvalidasi data yang masuk ke inputnya. Sebagai contoh, jika itu adalah string, maka harus dalam utf8. Tetapi di baris-baris ini adalah sampah, bukan utf8, dan Cassandra bahkan tidak mau berurusan dengan itu. Ketika saya mencoba untuk menghapus (atau melakukan sesuatu yang lain), saya tidak dapat menghapus nilai yang bukan utf8, karena, khususnya, saya tidak dapat memasukkannya di WHERE, karena kuncinya adalah utf8.
Garis manja muncul, seperti lampu kilat, di beberapa titik, dan kemudian hilang lagi selama beberapa hari atau minggu.
Kami mulai mencari masalah. Kami pikir mungkin ada masalah di simpul tertentu yang kami gunakan, melakukan sesuatu dengan data, menyalin SSTables. Mungkin, semua sama, Anda dapat melihat replika data ini? Mungkin replika ini memiliki simpul umum, faktor umum terkecil? Mungkin beberapa node crash? Tidak, tidak ada yang seperti itu.
Mungkin sesuatu dengan disk? Apakah data rusak pada disk? Tidak lagi
Mungkin ingatan? Tidak! Tersebar di sebuah cluster.
Mungkin ini semacam masalah replikasi? Satu simpul merusak segalanya dan selanjutnya mereplikasi nilai buruk? - Tidak.
Akhirnya, mungkin ini adalah masalah aplikasi?
Terlebih lagi, di beberapa titik, garis yang rusak mulai muncul dalam dua kelompok Cassandra. Satu bekerja pada versi 2.1, yang kedua pada yang ketiga. Tampaknya Cassandra berbeda, tetapi masalahnya sama. Mungkin layanan kami mengirim data buruk? Tapi itu sulit dipercaya. Cassandra memvalidasi input data, tidak bisa menulis sampah. Tapi tiba-tiba?
Tidak ada yang cocok.
Jarum ditemukan!
Kami berjuang lama dan keras sampai kami menemukan masalah kecil: mengapa kita memiliki semacam crash dump dari JVM pada node yang tidak kita perhatikan? Dan entah bagaimana itu terlihat mencurigakan di tumpukan sampah jejak pengumpul ... Dan untuk beberapa alasan beberapa jejak tumpukan juga tersumbat dengan sampah.
Pada akhirnya, kami menyadari - oh,
untuk beberapa alasan kami menggunakan JVM versi lama 2015 . Ini adalah satu-satunya hal umum yang menyatukan cluster Cassandra pada versi Cassandra yang berbeda.
Saya masih tidak tahu apa masalahnya, karena tidak ada yang ditulis tentang ini dalam catatan rilis resmi JVM. Namun setelah pembaruan, semuanya menghilang, masalahnya tidak lagi muncul. Selain itu, itu tidak terjadi di cluster sejak hari pertama, tetapi dari beberapa titik, meskipun bekerja pada JVM yang sama untuk waktu yang lama.
Pemulihan data
Pelajaran apa yang telah kita pelajari dari ini:
● Pencadangan tidak berguna.
Data, seperti yang kami ketahui, rusak saat data itu direkam. Pada saat data masuk ke koordinator, mereka sudah rusak.
● Pemulihan sebagian kolom yang tidak rusak adalah mungkin.
Beberapa kolom tidak rusak, kita bisa membaca data ini, mengembalikannya sebagian.
● Pada akhirnya, kami harus melakukan pemulihan dari berbagai sumber.
Kami memiliki metadata cadangan di objek, tetapi dalam data itu sendiri. Untuk menghubungkan kembali dengan objek, kami menggunakan log, dll.
● Log tidak ternilai harganya!
Kami dapat memulihkan semua data yang rusak, tetapi pada akhirnya sangat sulit untuk mempercayai basis data jika kehilangan data Anda bahkan tanpa tindakan apa pun dari pihak Anda.
Solusi
- Perbarui JVM setelah pengujian ekstensif.
- Pemantauan kecelakaan JVM.
- Memiliki salinan data Cassandra-independent.
Sebagai tip: Cobalah untuk memiliki semacam salinan data Cassandra-independent yang dapat Anda pulihkan jika perlu. Ini mungkin solusi tingkat terakhir. Biarkan mengambil banyak waktu, sumber daya, tetapi harus ada beberapa opsi yang akan memungkinkan Anda untuk mengembalikan data.
Bug
●
Kualitas pengujian rilis yang burukKetika Anda mulai bekerja dengan Cassandra, ada perasaan konstan (terutama jika Anda bergerak, relatif berbicara, dari database "baik", misalnya, PostgreSQL) bahwa jika Anda memperbaiki bug dalam rilis yang sebelumnya, Anda pasti akan menambahkan yang baru. Dan bug ini bukan omong kosong, biasanya data rusak atau perilaku salah lainnya.
●
Masalah yang terus-menerus dengan fitur yang kompleksSemakin kompleks fitur, semakin banyak masalah, bug, dll. Dengan itu.
●
Jangan gunakan perbaikan bertahap di 2.1Perbaikan terkenal, yang saya bicarakan, yang memperbaiki konsistensi data, dalam mode standar, ketika melakukan polling semua node, bekerja dengan baik. Tetapi tidak dalam mode incremental yang disebut (ketika perbaikan melewatkan data yang tidak berubah sejak perbaikan sebelumnya, yang cukup logis). Sudah lama diumumkan, secara formal, ketika fitur ada, tetapi semua orang mengatakan: “Tidak, dalam versi 2.1, tidak pernah menggunakannya! Dia pasti akan kehilangan sesuatu. Di 3 kita memperbaikinya. "
●
Tapi jangan gunakan perbaikan bertahap di 3.xKetika versi ketiga keluar, beberapa hari kemudian mereka berkata: “Tidak, Anda tidak dapat menggunakannya di versi ke-3. Ada daftar 15 bug, jadi jangan gunakan perbaikan tambahan. Di kelas 4 kita akan melakukan yang lebih baik! "
Saya tidak percaya mereka. Dan ini adalah masalah besar, terutama dengan bertambahnya ukuran cluster. Karena itu, Anda harus terus memantau bugtracker mereka dan melihat apa yang terjadi. Sayangnya, tidak mungkin untuk hidup bersama mereka tanpa itu.
●
Perlu melacak JIRA
Jika Anda menyebarkan semua database pada spektrum prediktabilitas, bagi saya, Cassandra ada di sebelah kiri di area merah. Ini tidak berarti bahwa itu buruk, Anda hanya harus siap untuk fakta bahwa Cassandra tidak dapat diprediksi dalam arti kata apa pun: baik dalam cara kerjanya maupun dalam kenyataan bahwa sesuatu dapat terjadi.

Saya berharap Anda menemukan garu lain dan menginjaknya, karena, dari sudut pandang saya, tidak peduli apa, Cassandra baik dan, tentu saja, tidak membosankan. Ingat saja gundukan di jalan!
Buka rapat aktivis HighLoad ++
Pada tanggal 31 Juli di Moskow, pada pukul 19:00, sebuah pertemuan para pembicara, Komite Program dan para aktivis dari konferensi para pengembang sistem beban tinggi HighLoad ++ 2018 akan diadakan . Kami akan mengadakan brainstorming kecil tentang program tahun ini agar tidak ketinggalan sesuatu yang baru dan penting. Rapat terbuka, tetapi Anda harus mendaftar .
Panggilan untuk surat-surat
Secara aktif menerima aplikasi untuk laporan di Highload ++ 2018. Komite Program sedang menunggu abstrak Anda sampai akhir musim panas.