
Ini merupakan kelanjutan dari bagian pertama artikel.
Pada bagian pertama artikel, penulis berbicara tentang kondisi kontes untuk game Agario di mail.ru, struktur dunia game dan sebagian tentang struktur bot. Sebagian, karena mereka hanya mempengaruhi perangkat sensor input dan perintah pada output dari jaringan saraf (selanjutnya dalam gambar dan teks akan ada singkatan NN). Jadi mari kita coba membuka kotak hitam dan memahami bagaimana semuanya diatur di sana.
Dan inilah gambar pertama:
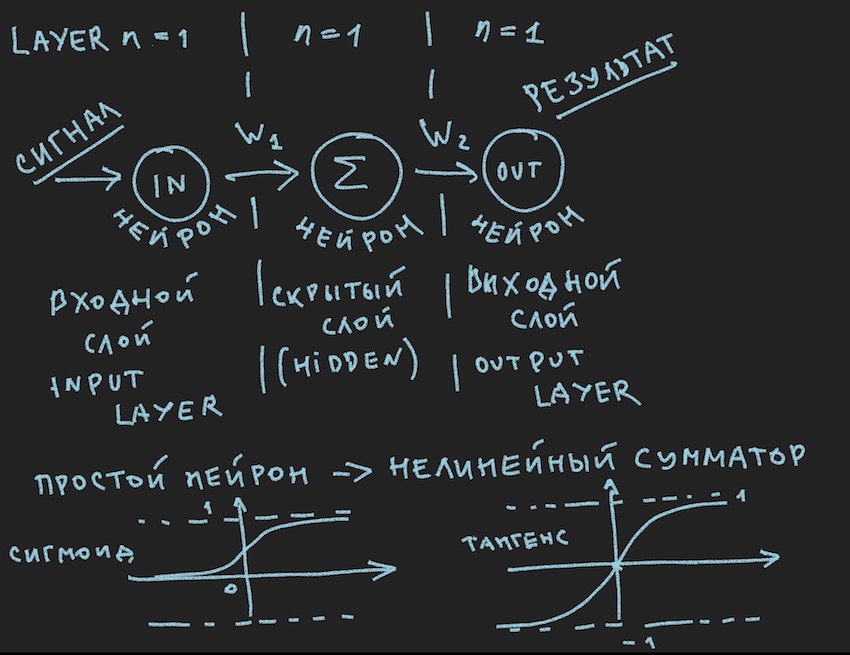
Secara skematis menggambarkan apa yang seharusnya menyebabkan senyum bosan dari pembaca saya, kata mereka lagi di kelas satu, mereka telah dilihat berkali-kali di berbagai sumber . Tapi kami benar-benar ingin menerapkan gambar ini secara praktis ke manajemen bot, jadi setelah Catatan Penting kami melihat lebih dekat.
Catatan penting: ada sejumlah besar solusi siap pakai (kerangka kerja) untuk bekerja dengan jaringan saraf:

Semua paket ini menyelesaikan tugas utama untuk pengembang jaringan saraf: konstruksi dan pelatihan NN atau pencarian bobot "optimal". Dan metode utama pencarian ini adalah Backpropagation . Itu diciptakan pada tahun 70-an abad terakhir, seperti yang ditunjukkan oleh artikel di tautan di atas, selama ini, sebagai bagian bawah kapal, ia telah memperoleh berbagai peningkatan, tetapi intinya sama: menemukan koefisien bobot dengan basis contoh pelatihan dan sangat diinginkan bahwa setiap orang contoh-contoh ini berisi jawaban yang sudah jadi dalam bentuk sinyal keluaran dari jaringan saraf. Pembaca mungkin keberatan dengan saya. bahwa jaringan belajar mandiri dari berbagai kelas dan prinsip telah ditemukan, tetapi semuanya tidak berjalan lancar di sana, sejauh yang saya mengerti. Tentu saja, ada rencana untuk mempelajari kebun binatang ini lebih terinci, tetapi saya pikir saya akan menemukan orang-orang yang berpikiran sama bahwa sepeda buatan DIY, bahkan yang paling melengkung, lebih dekat ke hati pencipta daripada klon pengantar sepeda yang ideal.
Memahami bahwa server game kemungkinan besar tidak akan memiliki perpustakaan ini dan daya komputasi yang dialokasikan oleh penyelenggara karena 1 inti prosesor jelas tidak cukup untuk kerangka kerja yang berat, penulis kemudian membuat sepeda motornya sendiri. Komentar penting tentang ini berakhir.
Mari kita kembali ke gambar yang menggambarkan mungkin jaringan syaraf yang paling sederhana dengan lapisan tersembunyi (alias lapisan tersembunyi atau lapisan tersembunyi). Sekarang penulis sendiri terus menatap gambar dengan ide-ide pada contoh sederhana ini untuk mengungkapkan kepada pembaca kedalaman jaringan saraf tiruan. Ketika semuanya disederhanakan menjadi primitif, lebih mudah untuk memahami esensinya. Intinya adalah bahwa neuron lapisan tersembunyi tidak memiliki apa-apa untuk diringkas. Dan kemungkinan besar ini bahkan bukan jaringan saraf, dalam buku teks NN yang paling sederhana adalah jaringan dengan dua input. Jadi di sinilah kita, seolah-olah, para penemu jaringan yang paling sederhana.
Mari kita coba gambarkan jaringan saraf ini (pseudocode):
Kami memperkenalkan topologi jaringan dalam bentuk array, di mana setiap elemen sesuai dengan lapisan dan jumlah neuron di dalamnya:
int array Topology= { 1, 1, 1}
Kita juga membutuhkan array float dari bobot jaringan saraf W, mengingat jaringan kami sebagai “feed forward neural networks (FF atau FFNN)”, di mana setiap neuron dari lapisan saat ini terhubung ke masing-masing neuron dari lapisan berikutnya, kita mendapatkan dimensi dari susunan W [jumlah lapisan] , jumlah neuron di lapisan, jumlah neuron di lapisan]. Tidak cukup penyandian yang optimal, tetapi mengingat nafas panas GPU di suatu tempat yang sangat dekat dalam teks, itu bisa dimengerti.
Prosedur CalculateSize singkat untuk menghitung jumlah neuron neuron dan jumlah koneksi mereka di jaringan saraf dendritecount , saya pikir akan menjelaskan lebih baik kepada penulis sifat dari koneksi ini:
void CalculateSize(array int Topology, int neuroncount, int dendritecount) { for (int i : Topology) // i neuroncount += i; for (int layer = 0, layer <Topology.Length - 1, layer++) // for (int i = 0, i < Topology[layer] + 1, i++) // for (int j = 0, j < Topology[layer + 1], j++) // dendritecount++; }
Pembaca saya, orang yang sudah mengetahui semua ini, penulis sampai pada pendapat ini pada artikel pertama, tentu tidak akan bertanya: mengapa pada loop ketiga bersarang Topologi [layer1 +1], bukan Topologi [layer1], yang memberi lebih banyak pada neuron daripada pada topologi jaringan . Saya tidak akan menjawab. Berguna juga bagi pembaca untuk bertanya pekerjaan rumah.
Kami hampir selangkah lagi dari membangun jaringan saraf yang berfungsi. Tetap menambahkan fungsi menjumlahkan sinyal pada input neuron dan aktivasi. Ada banyak fungsi aktivasi, tetapi yang paling dekat dengan sifat neuron adalah Sigmoid dan Tangensoid (mungkin lebih baik untuk menyebutnya bahwa, meskipun nama ini tidak digunakan dalam literatur, maksimumnya bersinggungan, tetapi ini adalah nama dari grafik, meskipun apa grafik jika itu bukan refleksi dari fungsi?)
Jadi di sini kita memiliki fungsi aktivasi neuron (mereka ada dalam gambar, di bagian bawahnya)
float Sigmoid(float x) { if (x < -10.0f) return 0.0f; else if (x > 10.0f) return 1.0f; return (float)(1.0f / (1.0f + expf(-x))); }
Sigmoid mengembalikan nilai dari 0 hingga 1.
float Tanh(float x) { if (x < -10.0f) return -1.0f; else if (x > 10.0f) return 1.0f; return (float)(tanhf(x)); }
Nilai tangentoid mengembalikan dari -1 ke 1.
Gagasan utama dari sinyal yang melewati jaringan saraf adalah gelombang: sinyal diumpankan ke neuron input -> melalui koneksi saraf sinyal menuju ke lapisan kedua -> neuron dari lapisan kedua merangkum sinyal yang telah mencapai mereka diubah oleh bobot interneuronal -> ditambahkan melalui bobot bias tambahan -> kita menggunakan fungsi aktivasi-> dan kita pergi ke lapisan berikutnya (baca siklus pertama dari contoh dengan lapisan), yaitu, mengulangi rantai dari awal hanya neuron dari lapisan berikutnya akan menjadi neuron input. Dalam penyederhanaan, Anda bahkan tidak perlu menyimpan nilai-nilai neuron dari seluruh jaringan, Anda hanya perlu menyimpan bobot NN dan nilai-nilai neuron dari lapisan aktif.
Sekali lagi, kami mengirim sinyal ke input NN, gelombang berlari melalui lapisan dan pada lapisan keluaran kami menghapus nilai yang diperoleh.
Di sini, dari selera pembaca, adalah mungkin untuk menyelesaikan pemrograman dengan menggunakan rekursi atau hanya siklus tiga seperti penulis, untuk mempercepat perhitungan, Anda tidak perlu pagar objek dalam bentuk neuron dan koneksi mereka dan OOP lainnya. Sekali lagi, ini adalah karena perasaan perhitungan GPU dekat, dan pada GPU, karena sifat paralelisme massa mereka, OOP sedikit terhenti, ini relatif terhadap c # dan C ++.
Lebih lanjut, pembaca diundang untuk secara independen menggunakan cara membangun jaringan saraf dalam kode, dengan keinginan pembacanya secara sukarela, ketidakhadiran yang cukup jelas dan akrab bagi penulis, seperti untuk contoh membangun NN dari awal, ada banyak contoh dalam jaringan, sehingga akan sulit untuk tersesat, seperti itu semudah jaringan saraf distribusi langsung pada gambar di atas.
Tetapi di mana pembaca akan berseru, yang belum meninggalkan bagian sebelumnya, dan akan benar, di masa kanak-kanak, penulis menentukan nilai buku dengan ilustrasi untuk itu. Anda disini:
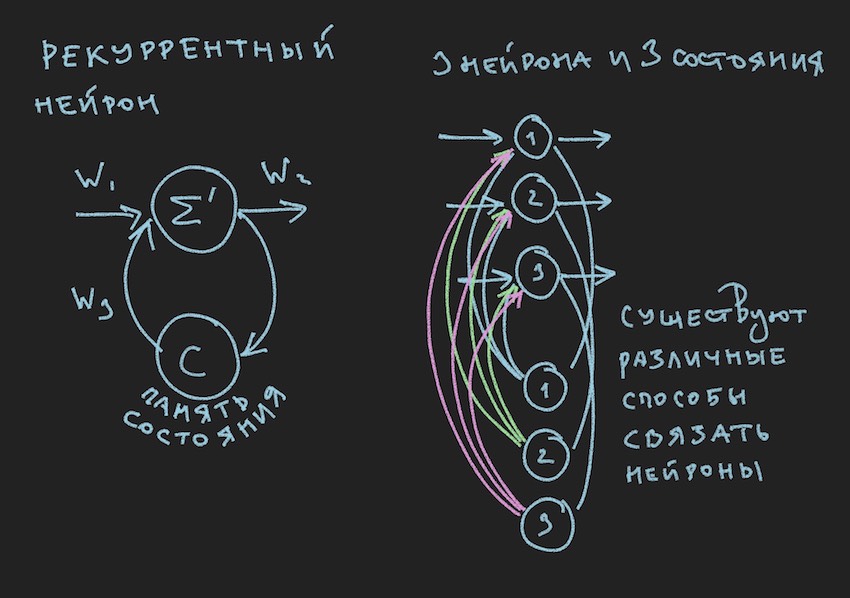
Dalam gambar kita melihat neuron berulang dan NN yang dibangun dari neuron seperti itu disebut berulang atau RNN. Jaringan saraf yang ditentukan memiliki memori jangka pendek dan dipilih oleh penulis untuk bot sebagai yang paling menjanjikan dalam hal adaptasi dengan proses permainan. Tentu saja, penulis membangun jaringan saraf distribusi langsung, tetapi dalam proses mencari solusi "efektif" ia beralih ke RNN.
Neuron rekuren memiliki status C tambahan, yang terbentuk setelah lewatnya sinyal pertama melalui neuron, Centang + 0 pada timeline. Dengan kata sederhana, ini adalah salinan sinyal keluaran dari neuron. Pada langkah kedua, baca Tick + 1 (karena jaringan beroperasi pada frekuensi bot permainan dan server), nilai C kembali ke input dari layer saraf melalui bobot tambahan dan dengan demikian berpartisipasi dalam pembentukan sinyal, tetapi sudah pada Tick + 1 waktu.
Catatan: dalam karya kelompok penelitian tentang pengelolaan bot game NN , ada kecenderungan untuk menggunakan dua ritme untuk jaringan saraf, satu ritme adalah frekuensi gim Tick, ritme kedua, misalnya, dua kali lebih lambat dari yang pertama. Bagian NN yang berbeda beroperasi pada frekuensi yang berbeda, yang memberikan visi berbeda tentang situasi gim di dalam NN, sehingga meningkatkan fleksibilitasnya.
Untuk membangun RNN dalam kode bot, kami memperkenalkan array tambahan ke dalam topologi, di mana setiap elemen terkait dengan layer dan jumlah status saraf di dalamnya:
int array TopologyNN= { numberofSensors, 16, 8, 4}
int array TopologyRNN= { 0, 16, 0, 0 }
Dapat dilihat dari topologi di atas bahwa lapisan kedua berulang, karena mengandung keadaan saraf. Kami juga memperkenalkan bobot tambahan dalam bentuk pelampung dari array WRR, dimensi yang sama dengan array W.
Hitungan koneksi dalam jaringan saraf kita akan sedikit berubah:
for (int layer = 0, layer < TopologyNN.Length - 1, layer++) for (int i = 0, i < TopologyNN[layer] + 1, i++) for (int j = 0, j < TopologyNN[layer + 1] , j++) dendritecount++; for (int layer = 0, layer < TopologyRNN.Length - 1, layer++) for (int i = 0, i< TopologyRNN[layer] + 1 , i++) for (int j = 0, j< TopologyRNN[layer], j++) dendritecount++;
Penulis akan melampirkan kode umum untuk jaringan saraf berulang di akhir artikel ini, tetapi hal utama yang perlu dipahami adalah prinsip: bagian dari gelombang melalui lapisan dalam kasus NN berulang tidak mengubah apa pun secara mendasar, hanya satu istilah lagi ditambahkan ke fungsi aktivasi neuron. Ini adalah istilah keadaan neuron pada Tick sebelumnya dikalikan dengan berat koneksi saraf.
Kami berasumsi bahwa teori dan praktik jaringan saraf telah disegarkan, tetapi penulis jelas menyadari bahwa ia belum membawa pembaca lebih dekat untuk memahami bagaimana cara mengajarkan struktur sederhana jaringan saraf ini untuk membuat keputusan apa pun dalam permainan. Kami tidak memiliki perpustakaan dengan contoh untuk mengajar NN. Dalam kelompok Internet pengembang bot, ada pendapat: beri kami file log dalam bentuk koordinat bot dan informasi game lainnya untuk membentuk perpustakaan contoh. Tetapi penulis, sayangnya, tidak dapat menemukan cara menggunakan file log ini untuk pelatihan NN. Saya akan senang mendiskusikan hal ini dalam komentar di artikel. Oleh karena itu, satu-satunya metode yang tersedia bagi penulis untuk memahami metode pelatihan, atau lebih tepatnya menemukan keseimbangan saraf yang efektif (koneksi saraf), adalah algoritma genetika.
Mempersiapkan gambar tentang prinsip-prinsip algoritma genetika:
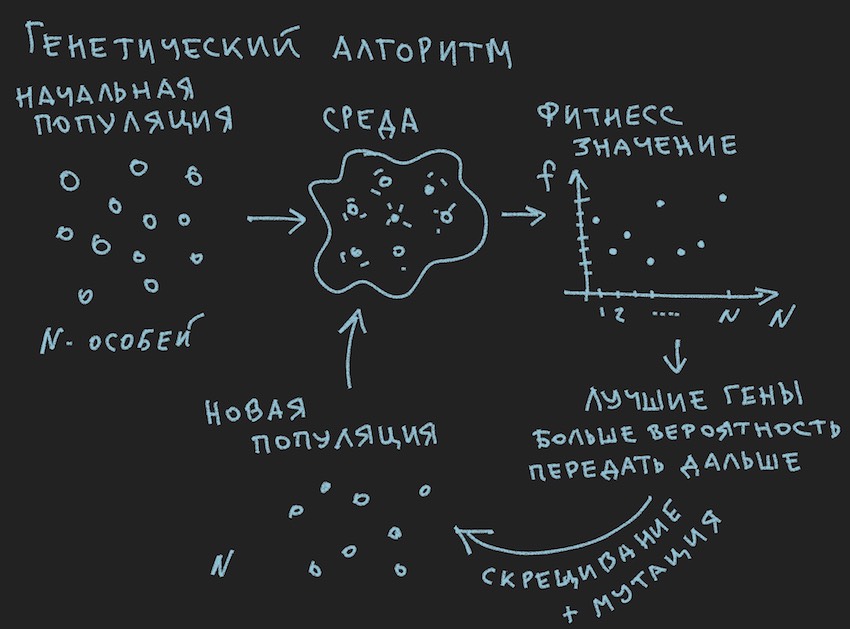
Jadi algoritma genetika .
Penulis akan mencoba untuk tidak mempelajari teori proses ini , tetapi hanya mengingat minimum yang diperlukan untuk melanjutkan membaca artikel secara penuh.
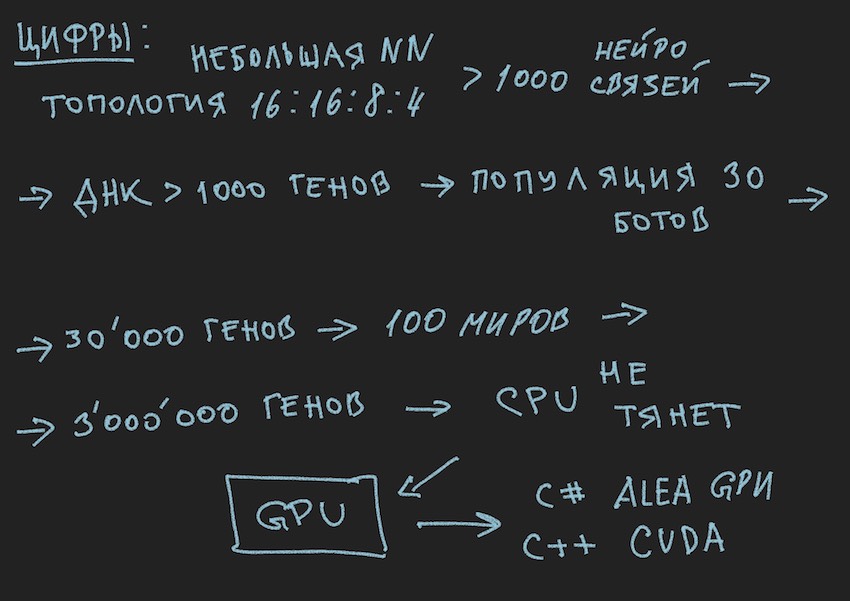
Dalam algoritma genetika, fluida kerja utama adalah gen (DNA adalah nama molekul). Genom dalam kasus kami adalah serangkaian gen berurutan atau array satu dimensi dari float panjang ...
Pada tahap awal pekerjaan dengan jaringan saraf yang baru dibangun, perlu menginisialisasi itu. Inisialisasi mengacu pada penugasan nilai acak dari -1 ke 1 untuk keseimbangan saraf.Penulis telah bertemu menyebutkan bahwa kisaran nilai dari -1 hingga 1 terlalu ekstrim dan jaringan terlatih memiliki bobot dalam kisaran yang lebih kecil, misalnya, dari -0,5 hingga 0,5 dan bahwa Anda harus mengambil rentang nilai awal yang sangat baik dari -1 hingga 1. Tetapi kita akan menggunakan cara klasik untuk mengumpulkan semua kesulitan dalam satu gerbang dan mengambil segmen seluas mungkin dari variabel acak awal sebagai dasar untuk menginisialisasi jaringan saraf.
Sekarang sebuah penambangan akan terjadi. Kami akan menganggap bahwa panjang (ukuran) genom bot akan sama dengan panjang total array dari jaringan saraf TopologiNN. Panjang + TopologiRNN. Panjang bukan apa-apa yang penulis habiskan waktu pembaca pada prosedur untuk menghitung koneksi saraf.
Catatan: Seperti yang telah dicatat oleh pembaca untuk dirinya sendiri, kami hanya mentransfer bobot jaringan saraf ke genotipe, struktur koneksi, fungsi aktivasi, dan status neuron tidak ditransmisikan. Untuk algoritma genetika, hanya koneksi saraf yang cukup, yang menunjukkan bahwa mereka adalah pembawa informasi. Ada perkembangan di mana algoritma genetika juga mengubah struktur koneksi dalam jaringan saraf dan cukup sederhana untuk mengimplementasikannya. Di sini, penulis menyisakan ruang untuk kreativitas bagi pembaca, meskipun ia sendiri akan memikirkannya dengan minat: Anda perlu memahami menggunakan dua genom independen dan dua fungsi kebugaran (disederhanakan dua algoritma genetika independen) atau Anda semua dapat menggunakan gen dan algoritma yang sama.
Dan karena kami menginisialisasi NN dengan variabel acak, kami menginisialisasi genom. Proses sebaliknya juga dimungkinkan: inisialisasi genotipe dengan variabel acak dan selanjutnya disalin ke bobot saraf. Pilihan kedua adalah umum. Karena algoritma genetika dalam program sering kali ada terlepas dari esensi itu sendiri dan dikaitkan dengannya hanya oleh data genom dan nilai fungsi kebugaran ... Hentikan, hentikan, pembaca akan berkata, gambar dengan jelas menunjukkan populasi dan bukan kata tentang genom individu.
Oke, tambahkan beberapa gambar ke tungku pikiran pembaca:
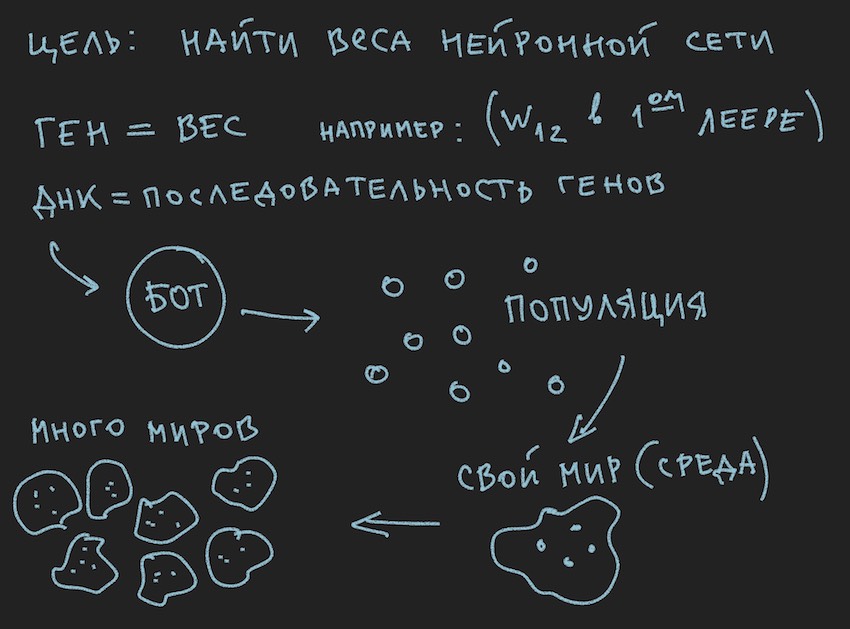
Karena penulis melukis gambar-gambar sebelum menulis teks artikel, mereka mendukung teks, tetapi tidak mengikuti huruf ke huruf dari cerita saat ini.
Dari informasi yang diambil dapat disimpulkan bahwa badan kerja utama dari algoritma genetika adalah populasi genom . Ini agak bertentangan dengan apa yang penulis katakan sebelumnya, tetapi bagaimana di dunia nyata melakukannya tanpa kontradiksi kecil. Kemarin, matahari berputar mengelilingi bumi, dan hari ini penulis berbicara tentang jaringan saraf di dalam bot perangkat lunak. Tidak heran dia ingat oven alasan.
Saya percaya pembaca sendiri untuk memilah masalah kontradiksi dunia. Dunia bot sepenuhnya mandiri untuk artikel ini.
Tetapi apa yang penulis telah berhasil lakukan, pada bagian artikel ini, adalah membentuk populasi bot.
Mari kita melihatnya dari sisi perangkat lunak:
Ada Bot (bisa berupa objek di OOP, struktur, meskipun mungkin juga objek atau hanya array data). Di dalam, Bot berisi informasi tentang koordinatnya, kecepatan, massa, dan informasi lain yang berguna dalam proses permainan, tetapi hal utama bagi kami sekarang adalah bahwa ia berisi tautan ke genotipe atau genotipe itu sendiri, tergantung pada implementasinya. Kemudian Anda dapat pergi dengan cara yang berbeda, membatasi diri pada array bobot jaringan saraf atau memperkenalkan susunan genotipe tambahan, karena akan lebih mudah bagi pembaca untuk membayangkan ini dalam imajinasi mereka. Pada tahap pertama, penulis dalam program ini mengalokasikan susunan neurobalansi dan genotipe. Kemudian dia menolak untuk menggandakan informasi dan membatasi dirinya pada bobot jaringan saraf.
Mengikuti logika cerita, Anda harus memberi tahu bahwa populasi bot adalah array dari bot di atas. Game apa itu ... Hentikan lagi, siklus game apa? para pengembang dengan sopan menyediakan tempat untuk hanya satu Bot di program simulasi dunia game di server atau maksimum empat bot dalam simulator lokal. Dan jika Anda mengingat topologi jaringan saraf yang dipilih oleh penulis:
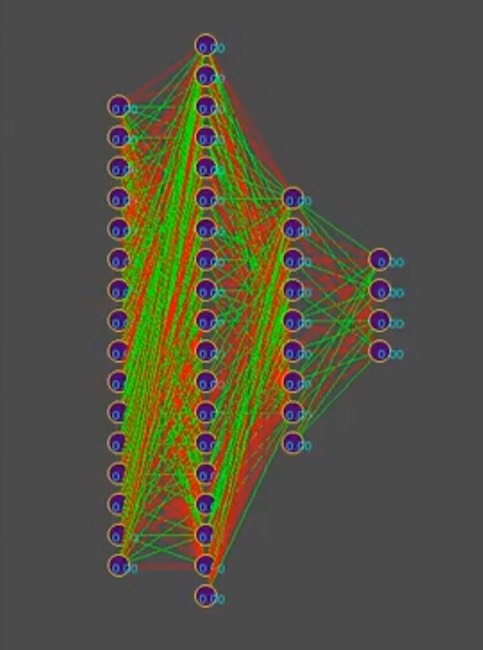
Dan untuk menyederhanakan cerita, anggaplah bahwa genotipe berisi sekitar 1000 koneksi saraf, omong-omong, dalam simulator, genotipe terlihat seperti ini (merah adalah nilai gen negatif, hijau adalah nilai positif, setiap baris adalah genom terpisah):

Catatan untuk foto: seiring waktu, pola berubah ke arah dominasi salah satu solusi, garis vertikal adalah gen genotipe yang umum.
Jadi, kami memiliki 1000 gen dalam genotipe dan maksimum empat bot dalam program simulator dunia game dari penyelenggara kompetisi. Berapa kali Anda perlu menjalankan simulasi pertempuran bots sehingga dengan kekerasan, bahkan yang paling cerdas, lebih dekat dalam mencari "efektif"
genotipe, baca kombinasi "efektif" koneksi saraf, asalkan masing-masing koneksi saraf bervariasi dari -1 hingga 1 dalam langkah, dan langkah mana? inisialisasi adalah float acak, itu adalah 15 tempat desimal. Langkahnya belum jelas bagi kami. Pada jumlah varian kombinasi bobot saraf, penulis mengasumsikan bahwa ini adalah angka tak terbatas, ketika memilih ukuran langkah tertentu, mungkin angka terbatas, tetapi dalam kasus apa pun, angka-angka ini jauh lebih dari 4 tempat di simulator, bahkan mempertimbangkan peluncuran berurutan dari antrian bot ditambah peluncuran simultan simultan, hingga 10 pada satu komputer (untuk penggemar pemrograman vintage: komputer).
Saya harap gambar-gambar ini membantu pembaca.
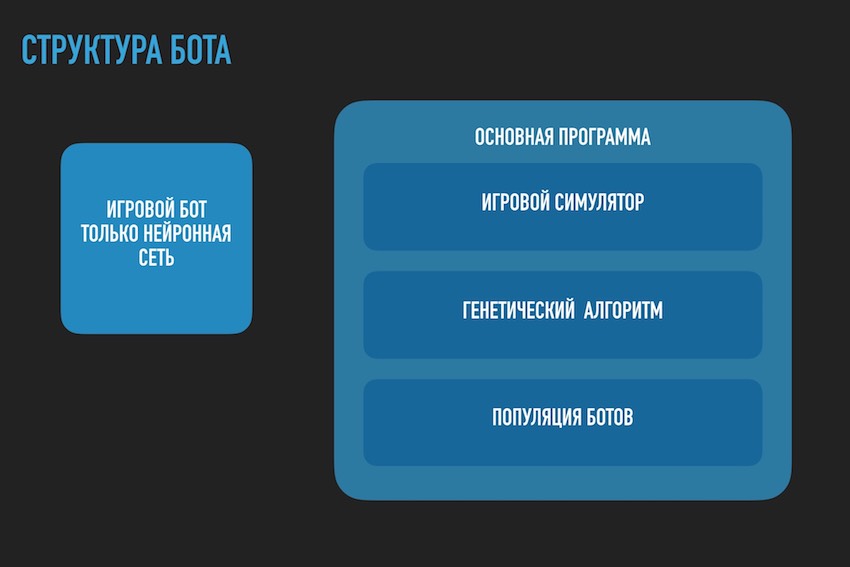
Di sini Anda perlu berhenti sejenak dan berbicara tentang arsitektur solusi perangkat lunak. Karena solusi dalam bentuk bot perangkat lunak terpisah yang diunggah ke situs kompetisi tidak lagi cocok. Itu perlu untuk memisahkan bermain bot sesuai dengan aturan kompetisi dalam kerangka ekosistem penyelenggara dan program yang mencoba untuk menemukan konfigurasi jaringan saraf untuknya. Diagram berikut diambil dari presentasi untuk konferensi, tetapi umumnya mencerminkan gambaran nyata.
Dia mengingat sebuah lelucon berjanggut:
Organisasi besar.
Waktu 18.00, semua karyawan bekerja sebagai satu. Tiba-tiba, salah satu karyawan mematikan komputer, berpakaian dan pergi.
Semua orang mengikutinya dengan ekspresi terkejut.
Hari berikutnya Pada pukul 18.00 karyawan yang sama mematikan komputer dan pergi. Semua orang terus bekerja dan mulai berbisik dengan perasaan tidak senang.
Keesokan harinya. Pada pukul 18.00 karyawan yang sama mematikan komputer ...
Seorang kolega mendekatinya:
-Seperti Anda tidak malu, kami bekerja, akhir kuartal, begitu banyak laporan, kami juga ingin pulang tepat waktu dan Anda adalah individu seperti ...
- Guys, saya pada umumnya LIBURAN!
... untuk dilanjutkan.
Ya, saya hampir lupa melampirkan kode prosedur perhitungan RNN, ini valid dan ditulis secara independen, jadi mungkin ada kesalahan di dalamnya. Untuk amplifikasi, saya akan membawanya apa adanya, itu dalam c ++ sebagaimana diterapkan pada CUDA (perpustakaan untuk menghitung pada GPU).
Catatan: array multidimensi tidak cocok dengan GPU, tentu saja ada tekstur dan perhitungan matriks, tetapi mereka merekomendasikan menggunakan array satu dimensi.
Contoh larik [i, j] dimensi M oleh j berubah menjadi larik bentuk [i * M + j].
Kode sumber dari prosedur perhitungan RNN __global__ void cudaRNN(Bot *bot, argumentsRNN *RNN, ConstantStruct *Const, int *Topology, int *TopologyRNN, int numElements, int gameTick) { int tid = blockIdx.x * blockDim.x + threadIdx.x; int threadN = gridDim.x * blockDim.x; int TopologySize = Const->TopologySize; for (int pos = tid; pos < numElements; pos += threadN) { const int ii = pos; const int iiA = pos*Const->ArrayDim; int ArrayDim = Const->ArrayDim; const int iiAT = ii*TopologySize*ArrayDim; if (bot[pos].TTF != 0 && bot[pos].Mass>0) { RNN->outputs[iiA + Topology[0]] = 1.f; //bias int neuroncount7 = Topology[0]; neuroncount7++; for (int layer1 = 0; layer1 < TopologySize - 1; layer1++) { for (int j4 = 0; j4 < Topology[layer1 + 1]; j4++) { for (int i5 = 0; i5 < Topology[layer1] + 1; i5++) { RNN->sums[iiA + j4] = RNN->sums[iiA + j4] + RNN->outputs[iiA + i5] * RNN->NNweights[((ii*TopologySize + layer1)*ArrayDim + i5)*ArrayDim + j4]; } } if (TopologyRNN[layer1] > 0) { for (int j14 = 0; j14 < Topology[layer1]; j14++) { for (int i15 = 0; i15 < Topology[layer1]; i15++) { RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] + RNN->neuronContext[iiAT + ArrayDim * layer1 + i15] * RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + i15)*ArrayDim + j14]; } RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] + 1.0f* RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + Topology[layer1])*ArrayDim + j14]; //bias=1 } for (int t = 0; t < Topology[layer1 + 1]; t++) { RNN->outputs[iiA + t] = Tanh(RNN->sums[iiA + t] + RNN->sumsContext[iiA + t]); RNN->neuronContext[iiAT + ArrayDim * layer1 + t] = RNN->outputs[iiA + t]; } //SoftMax /* double sum = 0.0; for (int k = 0; k <ArrayDim; ++k) sum += exp(RNN->outputs[iiA + k]); for (int k = 0; k < ArrayDim; ++k) RNN->outputs[iiA + k] = exp(RNN->outputs[iiA + k]) / sum; */ } else { for (int i1 = 0; i1 < Topology[layer1 + 1]; i1++) { RNN->outputs[iiA + i1] = Sigmoid(RNN->sums[iiA + i1]); //sigma } } if (layer1 + 1 != TopologySize - 1) { RNN->outputs[iiA + Topology[layer1 + 1]] = 1.f; } for (int i2 = 0; i2 < ArrayDim; i2++) { RNN->sums[iiA + i2] = 0.f; RNN->sumsContext[iiA + i2] = 0.f; } } } } }