Bayangkan Anda memiliki paragraf teks. Mungkinkah untuk memahami emosi apa yang dibawa teks ini: kegembiraan, kesedihan, kemarahan? Kamu bisa. Kami menyederhanakan tugas kami dan akan mengklasifikasikan emosi sebagai positif atau negatif, tanpa spesifikasi. Ada banyak cara untuk mengatasi masalah ini, dan salah satunya adalah
jaringan saraf convolutional (Convolutional Neural Networks). CNN pada awalnya dikembangkan untuk pemrosesan gambar, tetapi mereka berhasil mengatasi tugas-tugas di bidang pemrosesan kata otomatis. Saya akan memperkenalkan Anda pada analisis biner dari nada suara teks-teks berbahasa Rusia menggunakan jaringan saraf convolutional, di mana representasi vektor kata-kata dibentuk berdasarkan model
Word2Vec yang terlatih.
Artikel ini bersifat ikhtisar, saya menekankan komponen praktis. Dan saya ingin segera memperingatkan Anda bahwa keputusan yang dibuat pada setiap tahap mungkin tidak optimal. Sebelum membaca, saya sarankan Anda membiasakan diri dengan
artikel pengantar tentang penggunaan CNN dalam tugas pemrosesan bahasa alami, serta membaca
materi tentang metode representasi vektor kata-kata.
Arsitektur
Arsitektur CNN yang dipertimbangkan didasarkan pada pendekatan [1] dan [2]. Pendekatan [1], yang menggunakan ansambel jaringan konvolusional dan berulang, pada kompetisi tahunan terbesar dalam linguistik komputer SemEval-2017 mengambil tempat pertama [3] dalam lima nominasi dalam tugas untuk analisis nada suara
Tugas 4 .
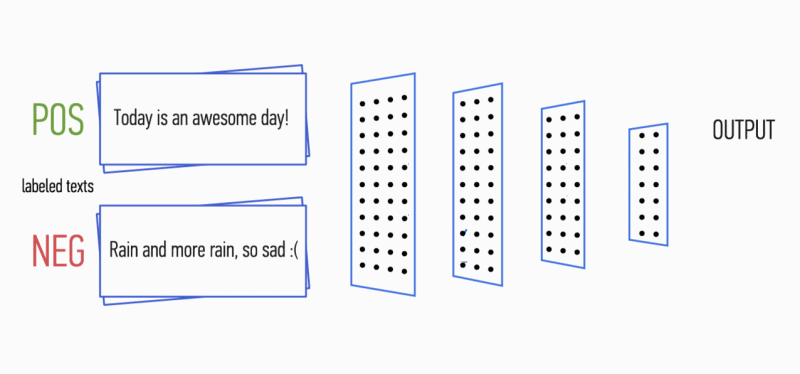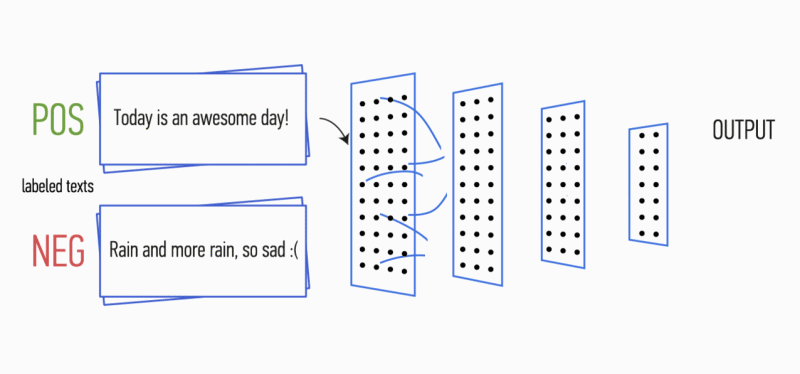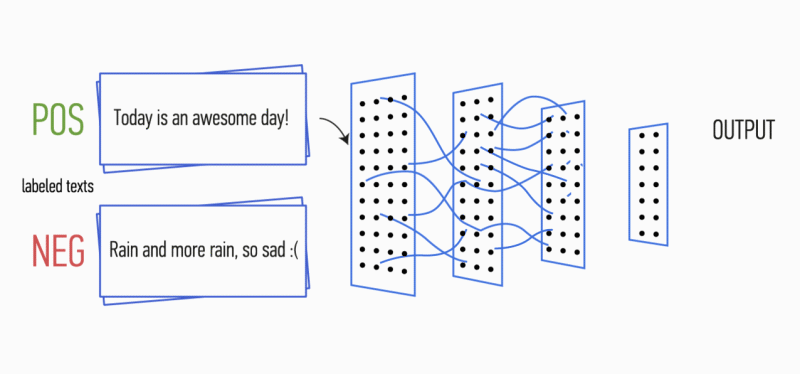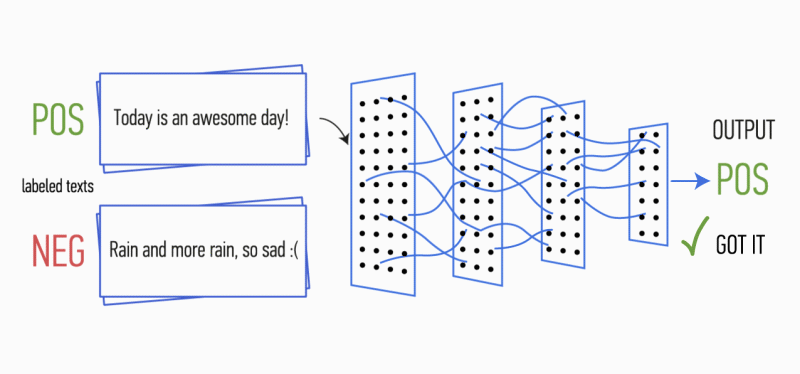
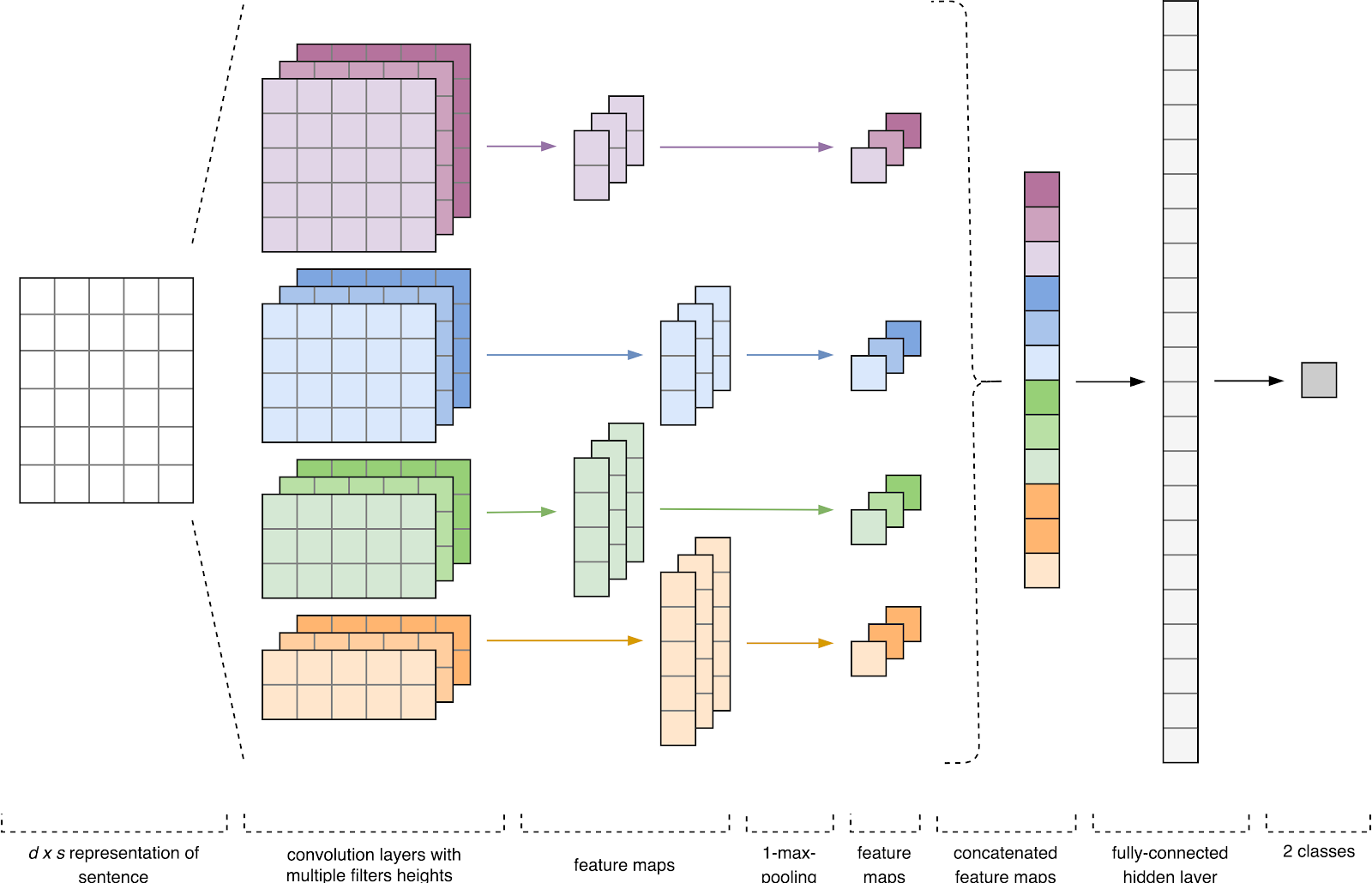 Gambar 1. Arsitektur CNN [2].
Gambar 1. Arsitektur CNN [2].Input CNN (Gbr. 1) adalah matriks dengan ketinggian tetap
n , di mana setiap baris adalah pemetaan vektor token ke ruang fitur dimensi
k . Alat semantik distribusi seperti Word2Vec, Glove, FastText, dll. Sering digunakan untuk membentuk ruang fitur.
Pada tahap pertama, matriks input diproses oleh lapisan konvolusi. Sebagai aturan, filter memiliki lebar tetap yang sama dengan dimensi ruang atribut, dan hanya satu parameter yang dikonfigurasi untuk ukuran filter - tinggi
h . Ternyata
h adalah ketinggian garis yang berdekatan yang dipertimbangkan bersama oleh filter. Dengan demikian, dimensi matriks fitur keluaran untuk setiap filter bervariasi tergantung pada ketinggian filter ini
h dan tinggi matriks asli
n .
Selanjutnya, peta fitur yang diperoleh pada output setiap filter diproses oleh lapisan subsampling dengan fungsi pemadatan tertentu (penyatuan 1-maks dalam gambar), yaitu. mengurangi dimensi peta fitur yang dihasilkan. Dengan demikian, informasi yang paling penting diekstraksi untuk setiap konvolusi, terlepas dari posisinya dalam teks. Dengan kata lain, untuk tampilan vektor yang digunakan, kombinasi lapisan konvolusi dan lapisan sub-sampling memungkinkan untuk mengekstrak
n- gram paling signifikan dari teks.
Setelah ini, peta fitur dihitung pada output dari setiap lapisan sub-sampling digabungkan menjadi satu vektor fitur umum. Ia diumpankan ke input lapisan tersembunyi, yang terhubung penuh, dan kemudian diumpankan ke lapisan keluaran jaringan saraf, tempat label kelas akhir dihitung.
Data Pelatihan
Untuk pelatihan, saya memilih
kumpulan teks pendek oleh Yulia Rubtsova , yang dibentuk berdasarkan pesan-pesan berbahasa Rusia dari Twitter [4]. Ini berisi 114 991 tweet positif, 111 923 negatif, serta basis tweet yang tidak terisi dengan volume 17 639 674 pesan.
import pandas as pd import numpy as np
Sebelum pelatihan, teks-teks tersebut melewati proses pendahuluan:
- dilemparkan ke huruf kecil;
- penggantian "e" dengan "e";
- Penggantian tautan ke token “URL”;
- penggantian penyebutan pengguna dengan token USER;
- menghapus tanda baca.
import re def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
Selanjutnya, saya membagi set data menjadi pelatihan dan menguji sampel dalam rasio 4: 1.
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=1)
Tampilan kata-kata vektor
Data input dari jaringan saraf convolutional adalah matriks dengan tinggi tetap
n , di mana setiap baris adalah pemetaan vektor dari suatu kata ke dalam ruang fitur dimensi
k . Untuk membentuk lapisan embedding jaringan saraf, saya menggunakan utilitas semantik distributif Word2Vec yang dirancang untuk memetakan makna semantik kata ke dalam ruang vektor. Word2Vec menemukan hubungan antara kata-kata dengan mengasumsikan bahwa kata-kata yang berhubungan secara semantik ditemukan dalam konteks yang sama. Anda dapat membaca lebih lanjut tentang Word2Vec di
artikel asli , dan juga di
sini dan di
sini . Karena tweet ditandai oleh tanda baca dan emotikon penulis, menentukan batas kalimat menjadi tugas yang agak memakan waktu. Dalam karya ini, saya berasumsi bahwa setiap tweet hanya berisi satu kalimat.
Basis tweet yang tidak terisi disimpan dalam format SQL dan berisi lebih dari 17,5 juta catatan. Untuk kenyamanan, saya mengubahnya menjadi SQLite menggunakan skrip
ini .
import sqlite3
Kemudian, menggunakan perpustakaan Gensim, saya melatih model Word2Vec dengan parameter berikut:
- size = 200 - dimensi ruang atribut;
- window = 5 - jumlah kata dari konteks yang dianalisis algoritma;
- min_count = 3 - kata itu harus muncul setidaknya tiga kali sehingga model memperhitungkannya.
import logging import multiprocessing import gensim from gensim.models import Word2Vec logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
 Gambar 2. Visualisasi kelompok kata-kata yang mirip menggunakan t-SNE.
Gambar 2. Visualisasi kelompok kata-kata yang mirip menggunakan t-SNE.Untuk pemahaman yang lebih rinci tentang pengoperasian Word2Vec pada Gambar.
Gambar 2 menunjukkan visualisasi beberapa kelompok kata-kata serupa dari model terlatih, dipetakan ke dalam ruang dua dimensi menggunakan
algoritma visualisasi t-SNE .
Tampilan vektor teks
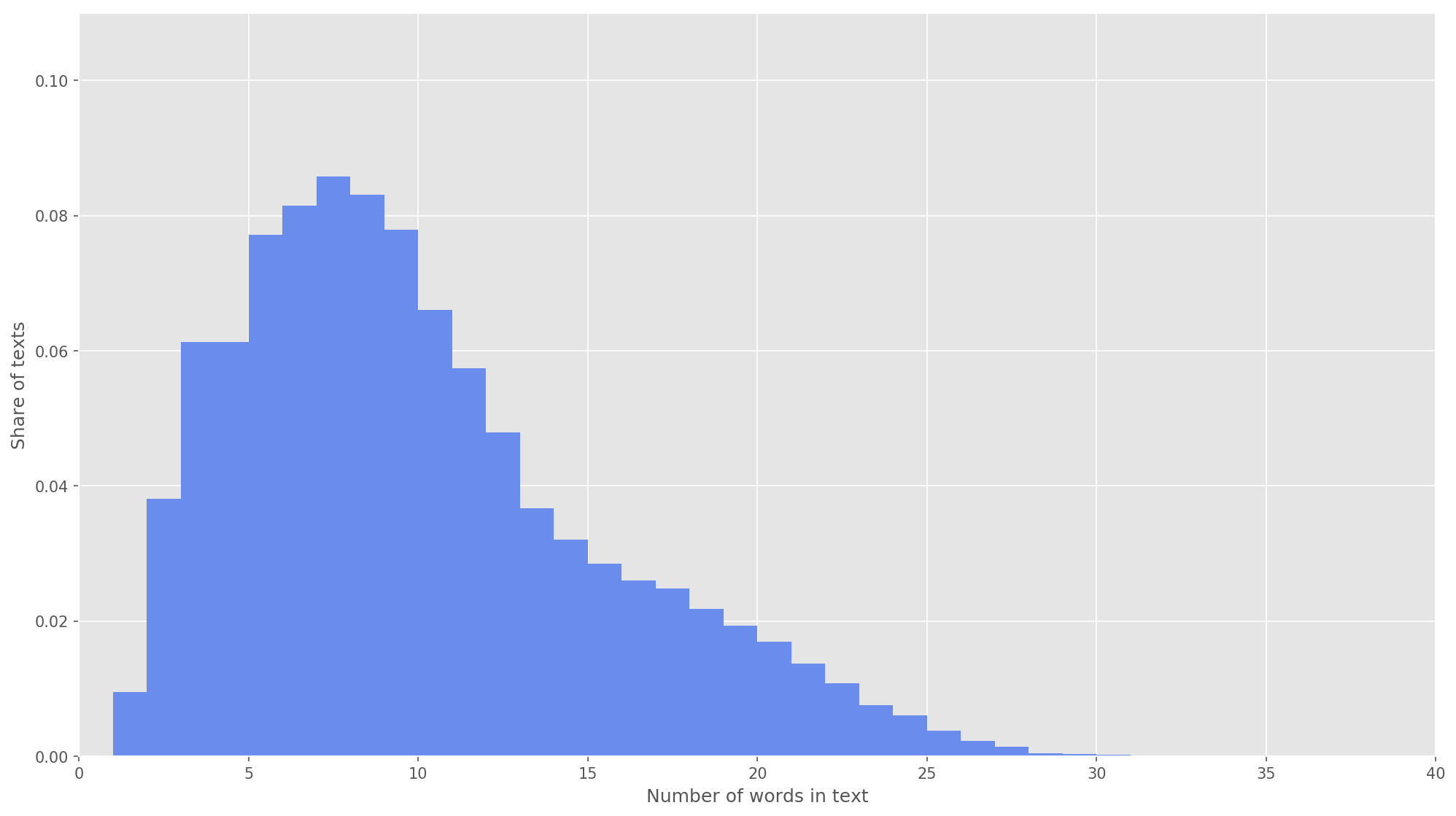 Gambar 3. Distribusi panjang teks.
Gambar 3. Distribusi panjang teks.Pada langkah berikutnya, setiap teks dipetakan ke array pengenal token. Saya memilih dimensi vektor teks
s = 26 , karena pada nilai ini 99,71% dari semua teks dalam tubuh yang terbentuk tertutup sepenuhnya (Gbr. 3). Jika selama analisis jumlah kata dalam tweet melebihi ketinggian matriks, kata-kata yang tersisa dibuang dan tidak diperhitungkan dalam klasifikasi. Dimensi akhir dari matriks proposal adalah
s × d = 26 × 200 .
from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences
Jaringan Saraf Konvolusional
Untuk membangun jaringan saraf, saya menggunakan perpustakaan Keras, yang bertindak sebagai add-on tingkat tinggi untuk TensorFlow, CNTK, dan Theano. Keras memiliki dokumentasi yang sangat baik, serta blog yang mencakup banyak tugas pembelajaran mesin, seperti
menginisialisasi lapisan penyematan . Dalam kasus kami, lapisan embedding diprakarsai oleh bobot yang diperoleh dengan mempelajari Word2Vec. Untuk meminimalkan perubahan pada lapisan penyematan, saya membekukannya pada tahap pertama pelatihan.
from keras.layers import Input from keras.layers.embeddings import Embedding tweet_input = Input(shape=(SENTENCE_LENGTH,), dtype='int32') tweet_encoder = Embedding(NUM, DIM, input_length=SENTENCE_LENGTH, weights=[embedding_matrix], trainable=False)(tweet_input)
Dalam arsitektur yang dikembangkan, filter dengan ketinggian
h = (2, 3, 4, 5) digunakan, yang dirancang untuk pemrosesan paralel bigrams, trigram, 4-gram dan 5-gram, masing-masing. Menambahkan 10 lapisan konvolusional ke setiap jaringan saraf untuk setiap ketinggian filter, fungsi aktivasi adalah ReLU. Rekomendasi untuk menemukan ketinggian optimal dan jumlah filter dapat ditemukan di [2].
Setelah diproses oleh lapisan konvolusi, peta atribut diumpankan ke lapisan subsampling, di mana operasi 1-max-pooling diterapkan pada mereka, sehingga mengekstraksi n-gram paling signifikan dari teks. Pada tahap berikutnya, mereka bergabung menjadi vektor fitur umum (menggabungkan lapisan), yang dimasukkan ke dalam lapisan yang terhubung sepenuhnya tersembunyi dengan 30 neuron. Pada tahap terakhir, peta fitur akhir diumpankan ke lapisan output jaringan saraf dengan fungsi aktivasi sigmoidal.
Karena jaringan saraf rentan terhadap pelatihan ulang, setelah lapisan embedding dan sebelum lapisan yang terhubung sepenuhnya tersembunyi, saya menambahkan regularisasi dropout dengan probabilitas ejeksi vertex p = 0,2.
from keras import optimizers from keras.layers import Dense, concatenate, Activation, Dropout from keras.models import Model from keras.layers.convolutional import Conv1D from keras.layers.pooling import GlobalMaxPooling1D branches = []
Saya mengkonfigurasi model akhir dengan fungsi optimasi Adam (Adaptive Moment Estimation) dan binary cross-entropy sebagai fungsi kesalahan. Kualitas penggolong dievaluasi dalam hal akurasi rata-rata makro, kelengkapan dan ukuran-f.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[precision, recall, f1]) model.summary()
Pada tahap pertama pelatihan, lapisan penanaman dibekukan, semua lapisan lainnya dilatih selama 10 era:
- Ukuran kelompok contoh yang digunakan untuk pelatihan adalah 32.
- Ukuran sampel validasi: 25%.
from keras.callbacks import ModelCheckpoint checkpoint = ModelCheckpoint("models/cnn/cnn-frozen-embeddings-{epoch:02d}-{val_f1:.2f}.hdf5", monitor='val_f1', save_best_only=True, mode='max', period=1) history = model.fit(x_train_seq, y_train, batch_size=32, epochs=10, validation_split=0.25, callbacks = [checkpoint])
LogTrain on 134307 samples, validate on 44769 samples
Epoch 1/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.5703 - precision: 0.7006 - recall: 0.6854 - f1: 0.6839 - val_loss: 0.5014 - val_precision: 0.7538 - val_recall: 0.7493 - val_f1: 0.7452
Epoch 2/10
134307/134307 [==============================] - 218s 2ms/step - loss: 0.5157 - precision: 0.7422 - recall: 0.7258 - f1: 0.7263 - val_loss: 0.4911 - val_precision: 0.7413 - val_recall: 0.7924 - val_f1: 0.7602
Epoch 3/10
134307/134307 [==============================] - 213s 2ms/step - loss: 0.5023 - precision: 0.7502 - recall: 0.7337 - f1: 0.7346 - val_loss: 0.4825 - val_precision: 0.7750 - val_recall: 0.7411 - val_f1: 0.7512
Epoch 4/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4956 - precision: 0.7545 - recall: 0.7412 - f1: 0.7407 - val_loss: 0.4747 - val_precision: 0.7696 - val_recall: 0.7590 - val_f1: 0.7584
Epoch 5/10
134307/134307 [==============================] - 229s 2ms/step - loss: 0.4891 - precision: 0.7587 - recall: 0.7492 - f1: 0.7473 - val_loss: 0.4781 - val_precision: 0.8014 - val_recall: 0.7004 - val_f1: 0.7409
Epoch 6/10
134307/134307 [==============================] - 217s 2ms/step - loss: 0.4830 - precision: 0.7620 - recall: 0.7566 - f1: 0.7525 - val_loss: 0.4749 - val_precision: 0.7877 - val_recall: 0.7411 - val_f1: 0.7576
Epoch 7/10
134307/134307 [==============================] - 219s 2ms/step - loss: 0.4802 - precision: 0.7632 - recall: 0.7568 - f1: 0.7532 - val_loss: 0.4730 - val_precision: 0.7969 - val_recall: 0.7241 - val_f1: 0.7522
Epoch 8/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4769 - precision: 0.7644 - recall: 0.7605 - f1: 0.7558 - val_loss: 0.4680 - val_precision: 0.7829 - val_recall: 0.7542 - val_f1: 0.7619
Epoch 9/10
134307/134307 [==============================] - 227s 2ms/step - loss: 0.4741 - precision: 0.7657 - recall: 0.7663 - f1: 0.7598 - val_loss: 0.4672 - val_precision: 0.7695 - val_recall: 0.7784 - val_f1: 0.7682
Epoch 10/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.4727 - precision: 0.7670 - recall: 0.7647 - f1: 0.7590 - val_loss: 0.4673 - val_precision: 0.7833 - val_recall: 0.7561 - val_f1: 0.7636
Kemudian ia memilih model dengan ukuran-F tertinggi pada set data validasi, yaitu. model yang diperoleh dalam zaman pendidikan kedelapan (F
1 = 0,7791). Model mencairkan lapisan embedding, setelah itu meluncurkan lima era pelatihan lagi.
from keras import optimizers
LogTrain on 134307 samples, validate on 44769 samples
Epoch 1/5
134307/134307 [==============================] - 2042s 15ms/step - loss: 0.4495 - precision: 0.7806 - recall: 0.7797 - f1: 0.7743 - val_loss: 0.4560 - val_precision: 0.7858 - val_recall: 0.7671 - val_f1: 0.7705
Epoch 2/5
134307/134307 [==============================] - 2253s 17ms/step - loss: 0.4432 - precision: 0.7857 - recall: 0.7842 - f1: 0.7794 - val_loss: 0.4543 - val_precision: 0.7923 - val_recall: 0.7572 - val_f1: 0.7683
Epoch 3/5
134307/134307 [==============================] - 2018s 15ms/step - loss: 0.4372 - precision: 0.7899 - recall: 0.7879 - f1: 0.7832 - val_loss: 0.4519 - val_precision: 0.7805 - val_recall: 0.7838 - val_f1: 0.7767
Epoch 4/5
134307/134307 [==============================] - 1901s 14ms/step - loss: 0.4324 - precision: 0.7943 - recall: 0.7904 - f1: 0.7869 - val_loss: 0.4504 - val_precision: 0.7825 - val_recall: 0.7808 - val_f1: 0.7762
Epoch 5/5
134307/134307 [==============================] - 1924s 14ms/step - loss: 0.4256 - precision: 0.7986 - recall: 0.7947 - f1: 0.7913 - val_loss: 0.4497 - val_precision: 0.7989 - val_recall: 0.7549 - val_f1: 0.7703
Indikator tertinggi
F 1 = 76,80% dalam sampel validasi dicapai pada pelatihan era ketiga. Kualitas model yang terlatih pada data uji adalah
F1 = 78,1% .
Tabel 1. Kualitas analisis sentimen pada data uji.
Hasil
Sebagai solusi dasar, saya
melatih classifier Bayes naif dengan model distribusi multinomial, hasil perbandingan disajikan dalam tabel. 2.
Tabel 2. Perbandingan kualitas analisis nada suara.
Seperti yang Anda lihat, kualitas klasifikasi CNN melebihi MNB beberapa persen. Nilai metrik dapat ditingkatkan lebih banyak lagi jika Anda berupaya mengoptimalkan hyperparameter dan arsitektur jaringan. Misalnya, Anda dapat mengubah jumlah era pelatihan, memeriksa efektivitas penggunaan berbagai representasi vektor kata dan kombinasinya, pilih jumlah filter dan ketinggiannya, menerapkan pemrosesan teks yang lebih efektif (koreksi kesalahan ketik, normalisasi, stamping), sesuaikan jumlah lapisan dan neuron yang terhubung penuh yang tersembunyi di dalamnya .
Kode sumber
tersedia di Github , model CNN dan Word2Vec yang terlatih dapat diunduh di
sini .
Sumber
- Cliche M. BB_twtr di SemEval-2017 Tugas 4: Analisis Sentimen Twitter dengan CNN dan LSTMs // Prosiding Lokakarya Internasional ke-11 tentang Evaluasi Semantik (SemEval-2017). - 2017 .-- S. 573-580.
- Zhang Y., Wallace B. Analisis Sensitivitas (dan Panduan Praktisi untuk) Jaringan Syaraf Konvolusional untuk Klasifikasi Kalimat // arXiv preprint arXiv: 1510.03820. - 2015.
- Rosenthal S., Farra N., Nakov P. SemEval-2017 tugas 4: Analisis Sentimen di Twitter // Prosiding Lokakarya Internasional ke-11 tentang Evaluasi Semantik (SemEval-2017). - 2017 .-- S. 502-518.
- Yu V. V. Rubtsova. Membangun kumpulan teks untuk mengatur pengelompokan nada // Produk dan Sistem Perangkat Lunak, 2015, No. 1 (109), —C.72-78.
- Mikolov T. et al. Representasi Kata-kata dan Frasa Terdistribusi serta Komposisionalitasnya // Kemajuan dalam Sistem Pemrosesan Informasi Saraf Tiruan. - 2013 .-- S. 3111-3119.