Dalam artikel sebelumnya,
Tinjauan Jaringan Saraf untuk Klasifikasi Gambar , kami membiasakan diri dengan konsep dasar jaringan saraf convolutional, serta ide-ide yang mendasarinya. Pada artikel ini, kita akan melihat beberapa arsitektur jaringan saraf yang dalam dengan kekuatan pemrosesan yang hebat - seperti AlexNet, ZFNet, VGG, GoogLeNet, dan ResNet - dan merangkum keuntungan utama dari masing-masing arsitektur ini. Struktur artikel didasarkan pada entri blog
Konsep dasar dari jaringan saraf convolutional, bagian 3 .
Saat ini,
ImageNet Challenge adalah insentif utama yang mendasari pengembangan sistem pengenalan alat berat dan klasifikasi gambar. Kampanye ini adalah kompetisi untuk bekerja dengan data, di mana peserta diberikan seperangkat data besar (lebih dari satu juta gambar). Tugas kompetisi adalah mengembangkan algoritma yang memungkinkan Anda untuk mengklasifikasikan gambar yang diperlukan menjadi objek dalam 1000 kategori - seperti anjing, kucing, mobil, dan lainnya - dengan jumlah kesalahan minimum.
Menurut aturan resmi kontes, algoritma harus memberikan daftar tidak lebih dari lima kategori objek dalam urutan kepercayaan menurun untuk setiap kategori gambar. Kualitas penandaan gambar dievaluasi berdasarkan label yang paling cocok dengan properti ground truth dari gambar. Idenya adalah untuk memungkinkan algoritma untuk mengidentifikasi beberapa objek dalam gambar dan tidak menambah poin penalti jika salah satu objek yang terdeteksi benar-benar hadir dalam gambar tetapi tidak termasuk dalam properti ground ground.
Pada tahun pertama kompetisi, peserta diberikan atribut gambar yang telah dipilih sebelumnya untuk pelatihan model. Ini bisa berupa, misalnya, tanda-tanda algoritma
SIFT diproses menggunakan kuantisasi vektor dan cocok untuk digunakan dalam metode kata tas atau untuk presentasi sebagai piramida spasial. Namun, pada 2012 ada terobosan nyata di bidang ini: sekelompok ilmuwan dari University of Toronto menunjukkan bahwa jaringan saraf yang dalam dapat mencapai hasil yang jauh lebih baik dibandingkan dengan model pembelajaran mesin tradisional yang dibangun berdasarkan vektor dari properti gambar yang sebelumnya dipilih. Pada bagian berikut, arsitektur inovatif pertama yang diusulkan pada 2012 akan dipertimbangkan, serta arsitektur yang menjadi pengikutnya hingga 2015.
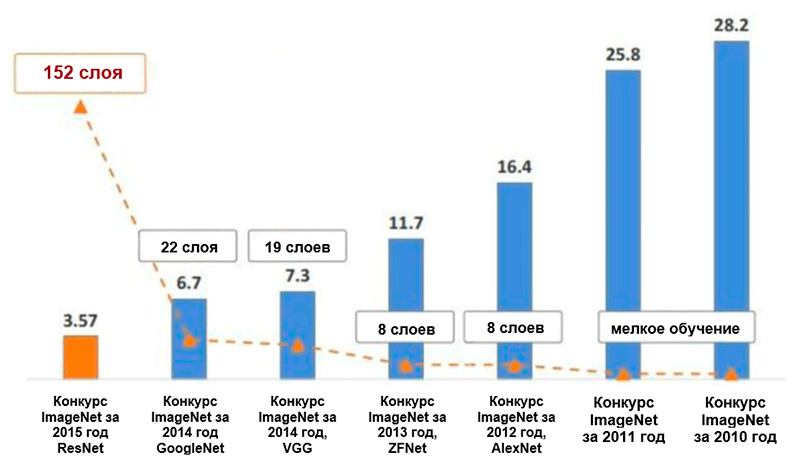 Diagram perubahan jumlah kesalahan (dalam persen) dalam klasifikasi gambar ImageNet * untuk lima kategori utama. Gambar diambil dari presentasi Kaiming He, Deep Residual Learning untuk Image Recognition
Diagram perubahan jumlah kesalahan (dalam persen) dalam klasifikasi gambar ImageNet * untuk lima kategori utama. Gambar diambil dari presentasi Kaiming He, Deep Residual Learning untuk Image RecognitionAlexnet
Arsitektur
AlexNet diusulkan pada 2012 oleh sekelompok ilmuwan (A. Krizhevsky, I. Sutskever dan J. Hinton) dari University of Toronto. Ini adalah karya inovatif di mana penulis pertama kali menggunakan (pada waktu itu) jaringan saraf convolutional yang mendalam dengan total kedalaman delapan lapisan (lima convolutional dan tiga lapisan yang terhubung penuh).
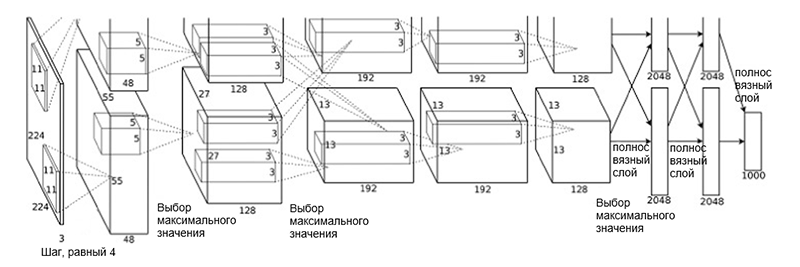 Arsitektur AlexNet
Arsitektur AlexNetArsitektur jaringan terdiri dari lapisan-lapisan berikut:
- [Lapisan konvolusi + pemilihan nilai maksimum + normalisasi] x 2
- [Lapisan Konvolusi] x 3
- [Memilih nilai maksimum]
- [Lapisan penuh] x 3
Skema seperti itu mungkin terlihat sedikit aneh, karena proses pembelajaran dibagi antara dua GPU karena kompleksitas komputasinya yang tinggi. Pemisahan kerja antara GPU ini membutuhkan pemisahan manual model menjadi blok vertikal yang saling berinteraksi.
Arsitektur AlexNet telah mengurangi jumlah kesalahan untuk lima kategori utama menjadi 16,4 persen - hampir setengah dibandingkan dengan perkembangan maju sebelumnya! Juga dalam kerangka arsitektur ini diperkenalkan fungsi aktivasi seperti unit pembetulan linier (
ReLU ), yang saat ini menjadi standar industri. Berikut ini adalah ringkasan singkat dari fitur-fitur utama lainnya dari arsitektur AlexNet dan proses pembelajarannya:
- Augmentasi data intensif
- Metode pengecualian
- Pengoptimalan menggunakan momen SGD (lihat panduan pengoptimalan “Tinjauan umum algoritma optimasi penurunan gradien”)
- Penyesuaian kecepatan pembelajaran secara manual (pengurangan koefisien ini sebesar 10 dengan stabilisasi akurasi)
- Model terakhir adalah kumpulan tujuh jaringan saraf convolutional
- Pelatihan ini dilakukan pada dua prosesor grafis NVIDIA * GeForce GTX * 580 dengan total memori video 3 GB.
Zfnet
Arsitektur jaringan
ZFNet yang diusulkan oleh peneliti M. Zeiler dan R. Fergus dari New York University hampir identik dengan arsitektur AlexNet. Satu-satunya perbedaan yang signifikan di antara mereka adalah sebagai berikut:
- Ukuran dan langkah filter pada lapisan konvolusional pertama (di AlexNet, ukuran filter adalah 11 × 11, dan langkahnya adalah 4; di ZFNet - masing-masing 7x7 dan 2)
- Jumlah filter dalam lapisan convolutional yang bersih (3, 4, 5).
 Arsitektur ZFNet
Arsitektur ZFNetBerkat arsitektur ZFNet, jumlah kesalahan untuk lima kategori utama turun menjadi 11,4 persen. Mungkin peran utama dalam hal ini dimainkan oleh penyetelan hyperparameters yang tepat (ukuran dan jumlah filter, ukuran paket, kecepatan belajar, dll.). Namun, ada kemungkinan bahwa ide-ide arsitektur ZFNet telah menjadi kontribusi yang sangat signifikan untuk pengembangan jaringan saraf convolutional. Ziller dan Fergus mengusulkan sistem untuk memvisualisasikan inti, bobot, dan pandangan tersembunyi gambar yang disebut DeconvNet. Berkat dia, pemahaman yang lebih baik dan pengembangan lebih lanjut dari jaringan saraf convolutional menjadi mungkin.
VGG Net
Pada tahun 2014, K. Simonyan dan E. Zisserman dari Oxford University mengusulkan arsitektur yang disebut
VGG . Ide utama dan khas dari struktur ini adalah untuk
menjaga filter sesederhana mungkin . Oleh karena itu, semua operasi konvolusi dilakukan menggunakan filter ukuran 3 dan langkah ukuran 1, dan semua operasi subsampling dilakukan menggunakan filter ukuran 2 dan langkah ukuran 2. Namun, ini tidak semua. Seiring dengan kesederhanaan modul konvolusional, jaringan telah tumbuh secara signifikan dalam - sekarang memiliki 19 lapisan! Gagasan paling penting, yang pertama kali diusulkan dalam karya ini, adalah untuk
memaksakan lapisan konvolusional tanpa lapisan subsampling . Gagasan yang mendasarinya adalah bahwa overlay seperti itu masih menyediakan bidang reseptif yang cukup besar (misalnya, tiga lapisan konvolusional yang ditumpangkan ukuran 3 × 3 dalam langkah-langkah 1 memiliki bidang reseptif mirip dengan satu lapisan konvolusional 7 × 7), Namun, jumlah parameter secara signifikan lebih sedikit daripada di jaringan dengan filter besar (berfungsi sebagai regulator). Selain itu, dimungkinkan untuk memperkenalkan transformasi nonlinier tambahan.
Pada dasarnya, penulis telah menunjukkan bahwa bahkan dengan blok bangunan yang sangat sederhana, Anda dapat mencapai hasil kualitas unggul dalam kontes ImageNet. Jumlah kesalahan untuk lima kategori utama dikurangi menjadi 7,3 persen.
 Arsitektur VGG. Harap perhatikan bahwa jumlah filter berbanding terbalik dengan ukuran spasial gambar.
Arsitektur VGG. Harap perhatikan bahwa jumlah filter berbanding terbalik dengan ukuran spasial gambar.GoogleNet
Sebelumnya, seluruh pengembangan arsitektur adalah untuk menyederhanakan filter dan meningkatkan kedalaman jaringan. Pada tahun 2014, C. Szegedy, bersama dengan peserta lain, mengusulkan pendekatan yang sama sekali berbeda dan menciptakan arsitektur paling kompleks pada waktu itu, yang disebut GoogLeNet.
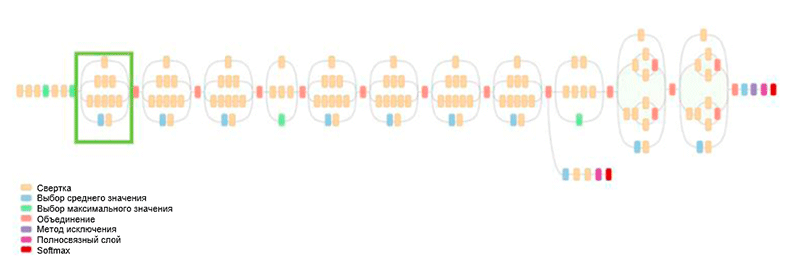 Arsitektur GoogLeNet. Ini menggunakan modul Inception, disorot dengan warna hijau pada gambar; pembangunan jaringan didasarkan pada modul-modul ini
Arsitektur GoogLeNet. Ini menggunakan modul Inception, disorot dengan warna hijau pada gambar; pembangunan jaringan didasarkan pada modul-modul iniSalah satu pencapaian utama dari karya ini adalah apa yang disebut modul Inception, yang ditunjukkan pada gambar di bawah ini. Jaringan arsitektur lain memproses input data secara berurutan, lapis demi lapis, saat menggunakan modul Inception,
input data diproses secara paralel . Ini memungkinkan Anda untuk mempercepat keluaran, serta meminimalkan
jumlah total parameter .
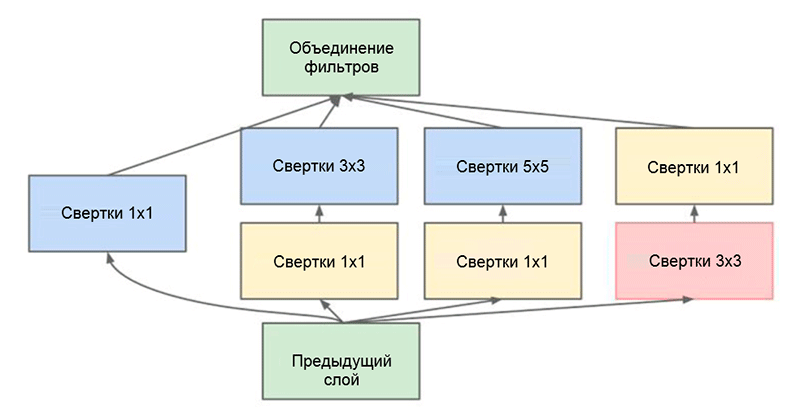 Modul awal. Perhatikan bahwa modul menggunakan beberapa cabang paralel, yang menghitung properti berbeda berdasarkan data input yang sama, dan kemudian menggabungkan hasilnya
Modul awal. Perhatikan bahwa modul menggunakan beberapa cabang paralel, yang menghitung properti berbeda berdasarkan data input yang sama, dan kemudian menggabungkan hasilnyaTrik lain yang menarik yang digunakan dalam modul Inception adalah menggunakan lapisan konvolusional ukuran 1 × 1. Ini mungkin tampak tidak berguna sampai kita mengingat fakta bahwa filter tersebut mencakup seluruh dimensi kedalaman. Dengan demikian, konvolusi 1 × 1 adalah cara sederhana untuk mengurangi dimensi peta properti. Jenis lapisan konvolusional ini pertama kali disajikan dalam
Network oleh M. Lin et al., Penjelasan yang komprehensif dan dapat dimengerti juga dapat ditemukan di blog post
Convolution [1 × 1] - utilitas yang bertentangan dengan intuisi oleh A. Prakash.
Pada akhirnya, arsitektur ini mengurangi jumlah kesalahan untuk lima kategori utama hingga setengah persen lagi - menjadi nilai 6,7 persen.
Resnet
Pada tahun 2015, sekelompok peneliti (Cuming Hee dan lainnya) dari Microsoft Research Asia datang dengan ide yang saat ini dianggap oleh sebagian besar komunitas sebagai salah satu tahap paling penting dalam pengembangan pembelajaran yang mendalam.
Salah satu masalah utama dari jaringan saraf yang dalam adalah masalah gradien yang hilang. Singkatnya, ini adalah masalah teknis yang muncul ketika menggunakan metode propagasi kesalahan kembali untuk algoritma perhitungan gradien. Saat bekerja dengan propagasi kesalahan kembali, aturan rantai digunakan. Selain itu, jika gradien memiliki nilai kecil di akhir jaringan, maka dapat mengambil nilai yang jauh lebih kecil pada saat mencapai awal jaringan. Hal ini dapat menyebabkan masalah yang sifatnya sangat berbeda, termasuk ketidakmungkinan mempelajari jaringan pada prinsipnya (untuk informasi lebih lanjut, lihat entri blog oleh R. Kapur
Masalah gradien memudar ).
Untuk mengatasi masalah ini, Caiming Hee dan kelompoknya mengusulkan ide berikut - untuk memungkinkan jaringan mempelajari pemetaan residual (elemen yang harus ditambahkan ke input) alih-alih tampilan itu sendiri. Secara teknis, ini dilakukan dengan menggunakan koneksi bypass yang ditunjukkan pada gambar.
 Diagram skematik dari blok residual: data input ditransmisikan melalui koneksi singkat melewati lapisan konversi dan ditambahkan ke hasilnya. Harap dicatat bahwa koneksi "identik" tidak menambahkan parameter tambahan ke jaringan, oleh karena itu strukturnya tidak rumit
Diagram skematik dari blok residual: data input ditransmisikan melalui koneksi singkat melewati lapisan konversi dan ditambahkan ke hasilnya. Harap dicatat bahwa koneksi "identik" tidak menambahkan parameter tambahan ke jaringan, oleh karena itu strukturnya tidak rumitGagasan ini sangat sederhana, tetapi pada saat yang sama sangat efektif. Ini memecahkan masalah gradien menghilang, memungkinkan untuk bergerak tanpa perubahan dari lapisan atas ke yang lebih rendah melalui koneksi "identik". Berkat ide ini, Anda dapat melatih jaringan yang sangat dalam, sangat dalam.
Jaringan yang memenangkan Tantangan ImageNet pada tahun 2015 berisi 152 lapisan (penulis dapat melatih jaringan yang berisi 1001 lapisan, tetapi menghasilkan hasil yang kira-kira sama, sehingga mereka berhenti bekerja dengannya). Selain itu, ide ini memungkinkan untuk mengurangi jumlah kesalahan untuk lima kategori utama secara harfiah menjadi setengah - menjadi nilai 3,6 persen. Menurut sebuah studi tentang
Apa yang saya pelajari dengan bersaing dengan jaringan saraf convolutional dalam kontes ImageNet oleh A. Karpathy, kinerja manusia untuk tugas ini adalah sekitar 5 persen. Ini berarti bahwa arsitektur ResNet mampu melampaui hasil manusia, setidaknya dalam tugas klasifikasi gambar ini.